MIS772 Predictive Analytics: RapidMiner for Fraudulent Claim Analysis
VerifiedAdded on 2023/06/10
|9
|2518
|112
Report
AI Summary
This report addresses the problem of fraudulent workers' compensation claims at Righteous Compensation Lawyers (RCL). The objective is to develop a classification model using RapidMiner to identify these fraudulent claims from a dataset of over 3000 claims, described by injured body part, nature and cause of injury, and adjustor notes. The analysis involves discovering relationships between variables, creating K-NN and Decision Tree models, evaluating their performance, and proposing an integrated solution. The K-NN model shows slightly better confidence than the Decision Tree. Further research suggests exploring Logistic Regression in R for potentially improved prediction. This document is available on Desklib, where students can find a wealth of resources, including past papers and solved assignments.
MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Assignment A1-LP2: Classification
Student Name
(as per record)
Student No Your official student number
My other group members A1
Group No
As per CloudDeakin group
number
Student Name
(as per record)
Student Nos Student number or a note that
the member left
Student number or a note that
the member left
Student number or a note that
the member left
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments Hints and Suggestions (we will not go to this length in the future submissions):
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
You can use the above form to estimate the expected mark against the rubric (see the assignment
“info” document). Be realistic and note that we will find many problems you may not be aware of.
Be clear, and use charts and tables as evidence, describe all visuals, cross-reference analysis with
evidence. Font should be no less than Arial 10 points. Ensure report completeness but Include only
those results that are significant for your analysis. Do not deviate from the structure of this template.
Submit this report in PDF format to avoid any accidental reformatting of the document contents.
Submit all RapidMiner processes (.RMP files) in a separate ZIP archive, so that if there is any doubt
we could load your work and replicate your results (we will not do this to find missing report parts).
You will be able to submit your work once only so make sure you get it right – check these before
posting on CloudDeakin: Is this your document? Is this the correct unit, assignment, year and
trimester? Is your name entered above? Is the group number included and is it correct? Are names
of your group members entered as well? Are all pages included? Does it all fit into the required page
limit? Have you zipped all RapidMiner files (.RMP / R / Python files)? Is this all yours work?
Then after the submission – check these: Has the PDF report been submitted? Has the Zip archive
of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
Note that the late penalty will be calculated on the date and time of the last submitted file.
Finally, your submission will be inspected for plagiarism, so ensure its uniqueness. If you work in a
team compare your report and RM files to those of your team members to ensure they are distinct in
contents and form. Any resemblance to another students’ report, part of some other assessment, or
information sourced from elsewhere without acknowledgement will be treated as plagiarism.
Total
Executive summary (one page)
1 of 9
Assignment A1-LP2: Classification
Student Name
(as per record)
Student No Your official student number
My other group members A1
Group No
As per CloudDeakin group
number
Student Name
(as per record)
Student Nos Student number or a note that
the member left
Student number or a note that
the member left
Student number or a note that
the member left
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments Hints and Suggestions (we will not go to this length in the future submissions):
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
You can use the above form to estimate the expected mark against the rubric (see the assignment
“info” document). Be realistic and note that we will find many problems you may not be aware of.
Be clear, and use charts and tables as evidence, describe all visuals, cross-reference analysis with
evidence. Font should be no less than Arial 10 points. Ensure report completeness but Include only
those results that are significant for your analysis. Do not deviate from the structure of this template.
Submit this report in PDF format to avoid any accidental reformatting of the document contents.
Submit all RapidMiner processes (.RMP files) in a separate ZIP archive, so that if there is any doubt
we could load your work and replicate your results (we will not do this to find missing report parts).
You will be able to submit your work once only so make sure you get it right – check these before
posting on CloudDeakin: Is this your document? Is this the correct unit, assignment, year and
trimester? Is your name entered above? Is the group number included and is it correct? Are names
of your group members entered as well? Are all pages included? Does it all fit into the required page
limit? Have you zipped all RapidMiner files (.RMP / R / Python files)? Is this all yours work?
Then after the submission – check these: Has the PDF report been submitted? Has the Zip archive
of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
Note that the late penalty will be calculated on the date and time of the last submitted file.
Finally, your submission will be inspected for plagiarism, so ensure its uniqueness. If you work in a
team compare your report and RM files to those of your team members to ensure they are distinct in
contents and form. Any resemblance to another students’ report, part of some other assessment, or
information sourced from elsewhere without acknowledgement will be treated as plagiarism.
Total
Executive summary (one page)
1 of 9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Expectation
There has been a lot of fraudulent claims for the insurance of the workers working in the firm Righteous
Compensation Lawyers (RCL). This is Legal firm and the management of the firm is thus highly concerned about the
matter. Thus, they have appointed business analysts to look into the matter from the claims that has been made by
over 3000 workers. These claims dome by more than 3000 workers of the firm are mainly described by their injured
body part, the nature and the case of the injury and by the adjustor notes that has been taken by the employees in
the insurance department when they have come across contact with the claimants of the insurance or with the
employees of the claimants or with the respective representatives of the claimants. A very lengthy process has been
applied to verify these claims made and following the process, the claims has been identified as three different types
of claims, some of which are valid and some others are fraudulent. There claims include if the injury that has taken
place was due to the involvement of a vehicle (this might or might not have been stated in the claim), whether the
injury was recovered within the paid entitlements and costs by the company and whether the claim made was
indicated as fraudulent or not and eventually, the applicant has been sued or not.
The main objective of this research is thus to explore the data and evaluate the significant characteristics
present in the data so that the data can be used for further evaluations.
After the exploration of the data, the data has to be classified so that it is possible to identify the Fraudulent
claims.
Business Problem
The main objective of this business problem is to evaluate a classification model with the help of which the
fraudulent claims made by the workers or their employees and representatives can be identified.
2 of 9
Expectation
There has been a lot of fraudulent claims for the insurance of the workers working in the firm Righteous
Compensation Lawyers (RCL). This is Legal firm and the management of the firm is thus highly concerned about the
matter. Thus, they have appointed business analysts to look into the matter from the claims that has been made by
over 3000 workers. These claims dome by more than 3000 workers of the firm are mainly described by their injured
body part, the nature and the case of the injury and by the adjustor notes that has been taken by the employees in
the insurance department when they have come across contact with the claimants of the insurance or with the
employees of the claimants or with the respective representatives of the claimants. A very lengthy process has been
applied to verify these claims made and following the process, the claims has been identified as three different types
of claims, some of which are valid and some others are fraudulent. There claims include if the injury that has taken
place was due to the involvement of a vehicle (this might or might not have been stated in the claim), whether the
injury was recovered within the paid entitlements and costs by the company and whether the claim made was
indicated as fraudulent or not and eventually, the applicant has been sued or not.
The main objective of this research is thus to explore the data and evaluate the significant characteristics
present in the data so that the data can be used for further evaluations.
After the exploration of the data, the data has to be classified so that it is possible to identify the Fraudulent
claims.
Business Problem
The main objective of this business problem is to evaluate a classification model with the help of which the
fraudulent claims made by the workers or their employees and representatives can be identified.
2 of 9
MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Discovering Relationships and Data Transformation in RapidMiner (one page)
Expectation
The dataset provided by the law firm Righteous Compensation Lawyers (RCL) contains information about the
claim number of the employees, the notes given by the adjustor on each of the claims, the injured body part for which
the claim has been made, the nature of the injury that the employee is suffering from, the cause of the injury and the
dummies generated after evaluation of these factors such as whether any motor vehicle is involved or not, whether
recovery could be completed within the entitled payments and costs and whether the claim has been indicated as
fraud or not. The relationship between the generated dummy variables has been evaluated. These variables have
been generated based on the information received from the previous variables described.
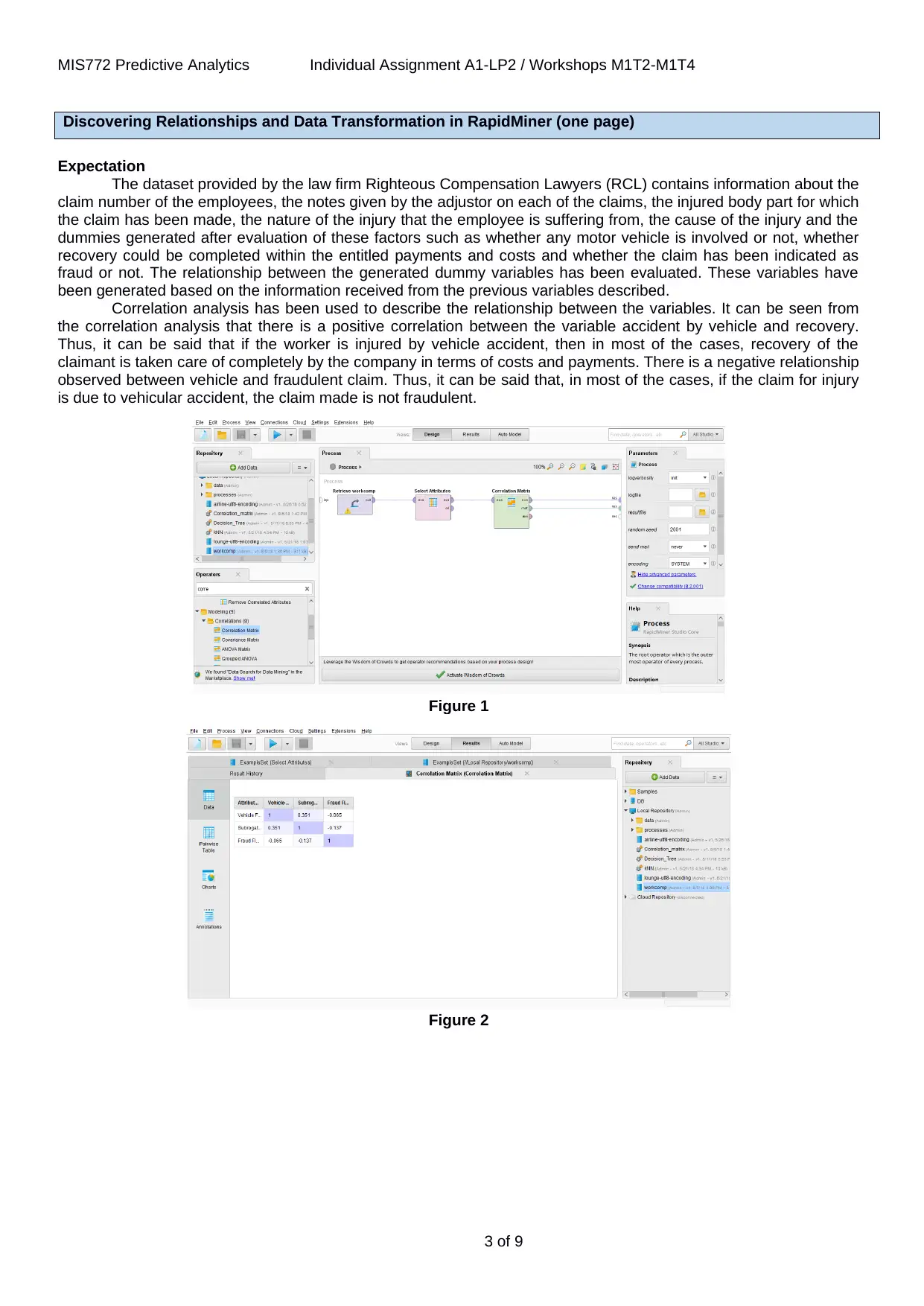
Correlation analysis has been used to describe the relationship between the variables. It can be seen from
the correlation analysis that there is a positive correlation between the variable accident by vehicle and recovery.
Thus, it can be said that if the worker is injured by vehicle accident, then in most of the cases, recovery of the
claimant is taken care of completely by the company in terms of costs and payments. There is a negative relationship
observed between vehicle and fraudulent claim. Thus, it can be said that, in most of the cases, if the claim for injury
is due to vehicular accident, the claim made is not fraudulent.
Figure 1
Figure 2
3 of 9
Discovering Relationships and Data Transformation in RapidMiner (one page)
Expectation
The dataset provided by the law firm Righteous Compensation Lawyers (RCL) contains information about the
claim number of the employees, the notes given by the adjustor on each of the claims, the injured body part for which
the claim has been made, the nature of the injury that the employee is suffering from, the cause of the injury and the
dummies generated after evaluation of these factors such as whether any motor vehicle is involved or not, whether
recovery could be completed within the entitled payments and costs and whether the claim has been indicated as
fraud or not. The relationship between the generated dummy variables has been evaluated. These variables have
been generated based on the information received from the previous variables described.
Correlation analysis has been used to describe the relationship between the variables. It can be seen from
the correlation analysis that there is a positive correlation between the variable accident by vehicle and recovery.
Thus, it can be said that if the worker is injured by vehicle accident, then in most of the cases, recovery of the
claimant is taken care of completely by the company in terms of costs and payments. There is a negative relationship
observed between vehicle and fraudulent claim. Thus, it can be said that, in most of the cases, if the claim for injury
is due to vehicular accident, the claim made is not fraudulent.
Figure 1
Figure 2
3 of 9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Create a Model(s) in RapidMiner (one page limit)
Expectation
In order to classify the data provided by the Law Firm, the first classification model that has been used to
identify the fraudulent claims is the K-NN Model. The K-NN model is the K nearest neighbour model. This is a very
simple algorithm in which all the cases that are available are stored and the cases are classified on the basis of a
measure of similarity.
To form the K-NN model in rapidminer, at first, the data has been pre-processed, the missing values in the
data has been replaced and manipulated, the attributes has been reordered and the respective examples has been
filtered. Following all the steps to pre-process the data, the K-NN classifier model has been framed. The process for
the K-NN model is provided in figure 3.
Figure 3
Extension
Another Classifier model has been constructed for the identification of the fraudulent claims is the decision
tree model. The Decision Tree classification model is a simpler classification model which models the data in a tree
shaped format by including a probability analysis. Usually this model is used to simplify complex problems and
visualize them in a manner which can be easily understood by any person. In this model also, the same pre-
processing of the data has been used as used in case of the K-NN model. The model development is attached in
figure 4.
Figure 4
4 of 9
Create a Model(s) in RapidMiner (one page limit)
Expectation
In order to classify the data provided by the Law Firm, the first classification model that has been used to
identify the fraudulent claims is the K-NN Model. The K-NN model is the K nearest neighbour model. This is a very
simple algorithm in which all the cases that are available are stored and the cases are classified on the basis of a
measure of similarity.
To form the K-NN model in rapidminer, at first, the data has been pre-processed, the missing values in the
data has been replaced and manipulated, the attributes has been reordered and the respective examples has been
filtered. Following all the steps to pre-process the data, the K-NN classifier model has been framed. The process for
the K-NN model is provided in figure 3.
Figure 3
Extension
Another Classifier model has been constructed for the identification of the fraudulent claims is the decision
tree model. The Decision Tree classification model is a simpler classification model which models the data in a tree
shaped format by including a probability analysis. Usually this model is used to simplify complex problems and
visualize them in a manner which can be easily understood by any person. In this model also, the same pre-
processing of the data has been used as used in case of the K-NN model. The model development is attached in
figure 4.
Figure 4
4 of 9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
5 of 9
5 of 9
MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Evaluate and Improve the Model(s) in RapidMiner (one page)
Expectation
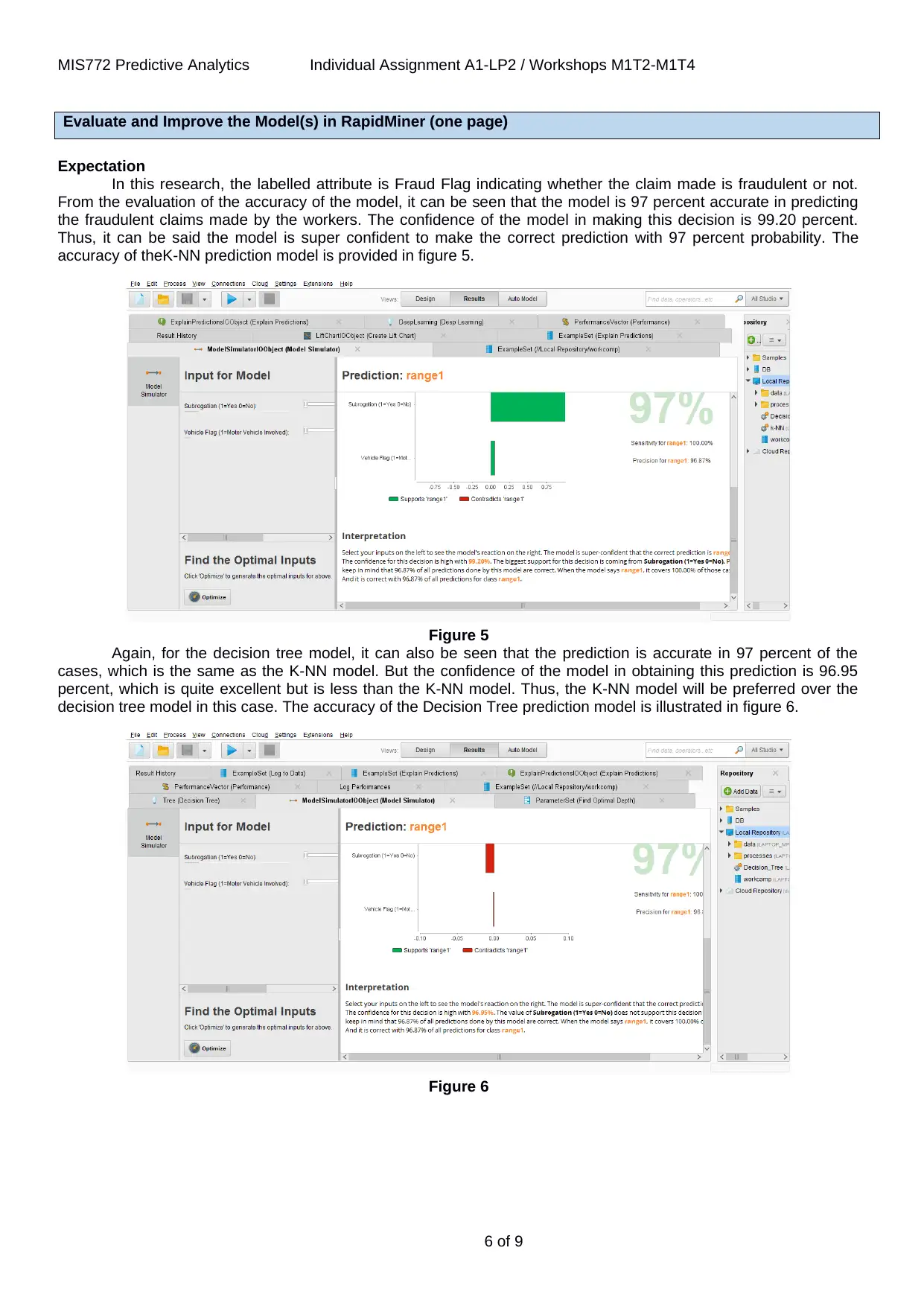
In this research, the labelled attribute is Fraud Flag indicating whether the claim made is fraudulent or not.
From the evaluation of the accuracy of the model, it can be seen that the model is 97 percent accurate in predicting
the fraudulent claims made by the workers. The confidence of the model in making this decision is 99.20 percent.
Thus, it can be said the model is super confident to make the correct prediction with 97 percent probability. The
accuracy of theK-NN prediction model is provided in figure 5.
Figure 5
Again, for the decision tree model, it can also be seen that the prediction is accurate in 97 percent of the
cases, which is the same as the K-NN model. But the confidence of the model in obtaining this prediction is 96.95
percent, which is quite excellent but is less than the K-NN model. Thus, the K-NN model will be preferred over the
decision tree model in this case. The accuracy of the Decision Tree prediction model is illustrated in figure 6.
Figure 6
6 of 9
Evaluate and Improve the Model(s) in RapidMiner (one page)
Expectation
In this research, the labelled attribute is Fraud Flag indicating whether the claim made is fraudulent or not.
From the evaluation of the accuracy of the model, it can be seen that the model is 97 percent accurate in predicting
the fraudulent claims made by the workers. The confidence of the model in making this decision is 99.20 percent.
Thus, it can be said the model is super confident to make the correct prediction with 97 percent probability. The
accuracy of theK-NN prediction model is provided in figure 5.
Figure 5
Again, for the decision tree model, it can also be seen that the prediction is accurate in 97 percent of the
cases, which is the same as the K-NN model. But the confidence of the model in obtaining this prediction is 96.95
percent, which is quite excellent but is less than the K-NN model. Thus, the K-NN model will be preferred over the
decision tree model in this case. The accuracy of the Decision Tree prediction model is illustrated in figure 6.
Figure 6
6 of 9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Provide an Integrated Solution in RapidMiner (one page)
Expectation
The steps followed to deploy the Decision Tree prediction model are given as follows:
The data is loaded in the RapidMiner interphase.
All the general pre-processing steps have been performed
Missing values have been replaced.
The data columns have been arranged alphabetically.
Model on the cases with label value. This model is applied to the cases with the missing values.
The sample is restricted to 250,000 examples, in case there are more than that in the data.
The data is then split into training set and validation set.
Following that the decision tree has been constructed.
The same steps have been applied as in the Decision Tree model for the K-NN model. The steps are discussed as
follows:
The data is loaded in the RapidMiner interphase.
All the general pre-processing steps have been performed
Missing values have been replaced.
The data columns have been arranged alphabetically.
Model on the cases with label value. This model is applied to the cases with the missing values.
The sample is restricted to 250,000 examples, in case there are more than that in the data.
The data is then split into training set and validation set.
Following that the K-NN has been constructed.
7 of 9
Provide an Integrated Solution in RapidMiner (one page)
Expectation
The steps followed to deploy the Decision Tree prediction model are given as follows:
The data is loaded in the RapidMiner interphase.
All the general pre-processing steps have been performed
Missing values have been replaced.
The data columns have been arranged alphabetically.
Model on the cases with label value. This model is applied to the cases with the missing values.
The sample is restricted to 250,000 examples, in case there are more than that in the data.
The data is then split into training set and validation set.
Following that the decision tree has been constructed.
The same steps have been applied as in the Decision Tree model for the K-NN model. The steps are discussed as
follows:
The data is loaded in the RapidMiner interphase.
All the general pre-processing steps have been performed
Missing values have been replaced.
The data columns have been arranged alphabetically.
Model on the cases with label value. This model is applied to the cases with the missing values.
The sample is restricted to 250,000 examples, in case there are more than that in the data.
The data is then split into training set and validation set.
Following that the K-NN has been constructed.
7 of 9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Further Research and Extensions in RM (one page)
Expectation
In this research, the analysis has been performed using two classification models such as K-NN model and
Decision Tree model. It has been found from the analysis that the K-NN model is a better prediction model than the
Decision Tree model as the K-NN model provides the correct prediction with more level of confidence. Thus, the
chance of misclassification is less in case of the K-NN model.
Despite of these two models used. More prediction models can be used as prediction models when the
predictor is binary. One such model is the Logistic regression model. Further, it can be said that RapidMiner is not
the only data analytics tool or platform which can be used for the analysis. Other platforms are also available such as
the R. R is another statistical platform which can be used for data analytics. In this case, the prediction model
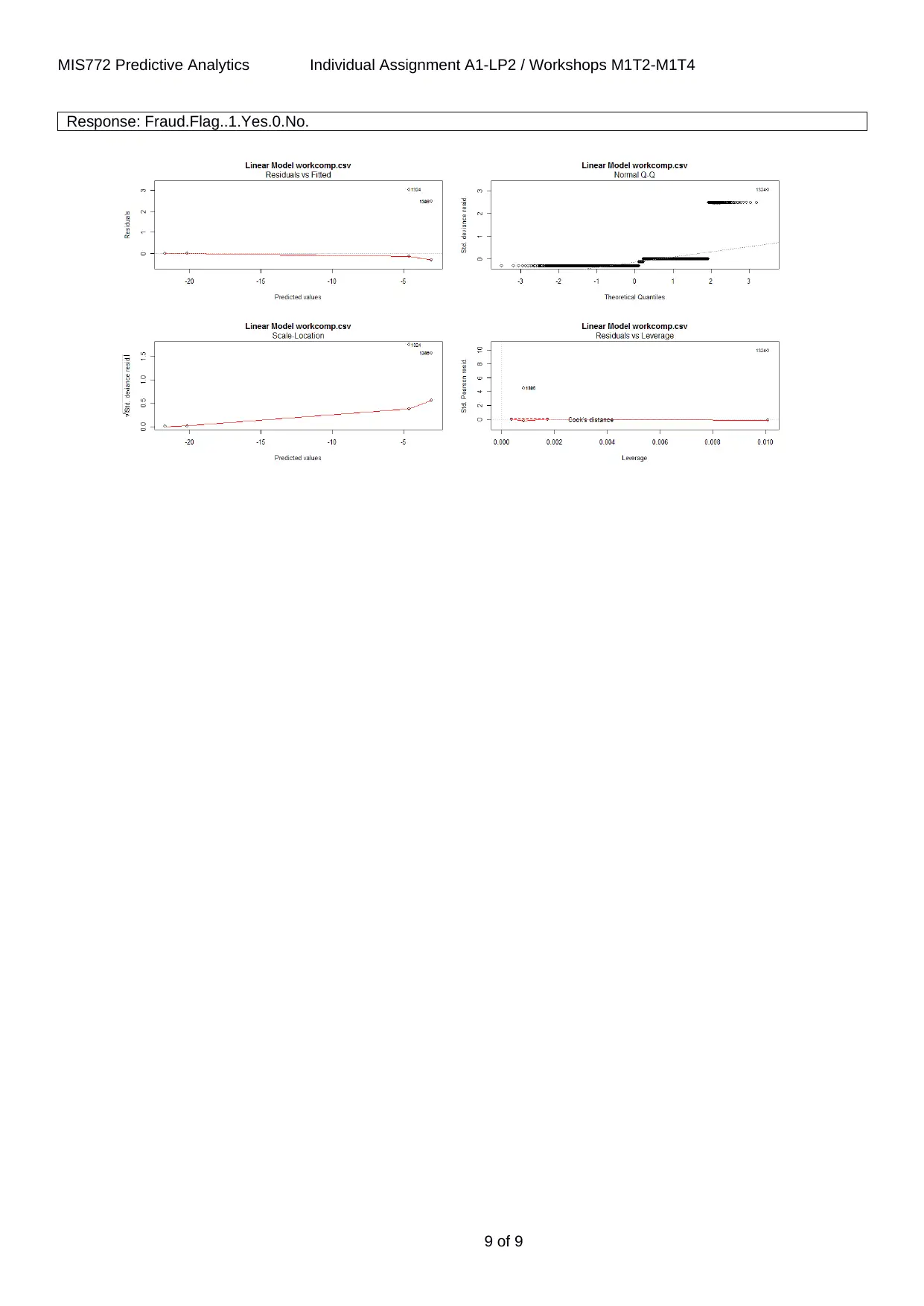
Logistic Regression will be evaluated with the help of the R software. The model results are shown diagrammatically
in figure 7. From the residuals vs fitted graph in figure 7, it can be seen that the predicted values are quite close to
the original values. Thus, it can be said that the model logistic regression has provided a very good fit for the
prediction variable which is fraudulent claims. The precision for the model as found from the r-Square value given in
the results is 13 percent which is extremely low. Thus, for this case, logistic regression cannot be considered as a
good prediction model as the precision of the prediction is very less though the model has been found to be
significant (p-value <0.001).
The R-Codes for the logistic regression model and the results are provided in table 1 and table 2
respectively.
Table 1
glm(formula = Fraud.Flag..1.Yes.0.No. ~ ., family = binomial(link = "logit"),
data = crs$dataset[crs$train, c(crs$input, crs$target)])
Table 2
Deviance Residuals:
Min 1Q Median 3Q Max
-0.30811 -0.30811 -0.30811 -0.00006 3.03154
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.0239 0.1368 -22.098 <2e-16
Vehicle.Flag..1.Motor.Vehicle.Involved. -1.5611 1.0144 -1.539 0.124
Subrogation..1.Yes.0.No. -17.1467 607.3560 -0.028 0.977
(Intercept) ***
Vehicle.Flag..1.Motor.Vehicle.Involved.
Subrogation..1.Yes.0.No.
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 524.96 on 2124 degrees of freedom
Residual deviance: 464.54 on 2122 degrees of freedom
AIC: 470.54
Number of Fisher Scoring iterations: 19
Log likelihood: -232.268 (3 df)
Null/Residual deviance difference: 60.427 (2 df)
Chi-square p-value: 0.00000000
Pseudo R-Square (optimistic): 0.13935167
==== ANOVA ====
Analysis of Deviance Table
Model: binomial, link: logit
8 of 9
Further Research and Extensions in RM (one page)
Expectation
In this research, the analysis has been performed using two classification models such as K-NN model and
Decision Tree model. It has been found from the analysis that the K-NN model is a better prediction model than the
Decision Tree model as the K-NN model provides the correct prediction with more level of confidence. Thus, the
chance of misclassification is less in case of the K-NN model.
Despite of these two models used. More prediction models can be used as prediction models when the
predictor is binary. One such model is the Logistic regression model. Further, it can be said that RapidMiner is not
the only data analytics tool or platform which can be used for the analysis. Other platforms are also available such as
the R. R is another statistical platform which can be used for data analytics. In this case, the prediction model
Logistic Regression will be evaluated with the help of the R software. The model results are shown diagrammatically
in figure 7. From the residuals vs fitted graph in figure 7, it can be seen that the predicted values are quite close to
the original values. Thus, it can be said that the model logistic regression has provided a very good fit for the
prediction variable which is fraudulent claims. The precision for the model as found from the r-Square value given in
the results is 13 percent which is extremely low. Thus, for this case, logistic regression cannot be considered as a
good prediction model as the precision of the prediction is very less though the model has been found to be
significant (p-value <0.001).
The R-Codes for the logistic regression model and the results are provided in table 1 and table 2
respectively.
Table 1
glm(formula = Fraud.Flag..1.Yes.0.No. ~ ., family = binomial(link = "logit"),
data = crs$dataset[crs$train, c(crs$input, crs$target)])
Table 2
Deviance Residuals:
Min 1Q Median 3Q Max
-0.30811 -0.30811 -0.30811 -0.00006 3.03154
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.0239 0.1368 -22.098 <2e-16
Vehicle.Flag..1.Motor.Vehicle.Involved. -1.5611 1.0144 -1.539 0.124
Subrogation..1.Yes.0.No. -17.1467 607.3560 -0.028 0.977
(Intercept) ***
Vehicle.Flag..1.Motor.Vehicle.Involved.
Subrogation..1.Yes.0.No.
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 524.96 on 2124 degrees of freedom
Residual deviance: 464.54 on 2122 degrees of freedom
AIC: 470.54
Number of Fisher Scoring iterations: 19
Log likelihood: -232.268 (3 df)
Null/Residual deviance difference: 60.427 (2 df)
Chi-square p-value: 0.00000000
Pseudo R-Square (optimistic): 0.13935167
==== ANOVA ====
Analysis of Deviance Table
Model: binomial, link: logit
8 of 9
MIS772 Predictive Analytics Individual Assignment A1-LP2 / Workshops M1T2-M1T4
Response: Fraud.Flag..1.Yes.0.No.
9 of 9
Response: Fraud.Flag..1.Yes.0.No.
9 of 9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.