Statistical Analysis Report: Data Interpretation and Findings
VerifiedAdded on 2021/01/02
|14
|2848
|425
Report
AI Summary
This report presents a comprehensive statistical analysis, delving into various datasets and employing diverse statistical methods. The analysis begins with an examination of data distribution, including frequency tables and histograms, to understand the characteristics of the data. The report proceeds to explore the determination of sample size and the relationship between variables, such as demand and unit price, using techniques like the coefficient of determination and correlation. Further, it constructs and interprets ANOVA tables to analyze variance, offering insights for statistical consulting. The report also includes the development and interpretation of regression equations to model relationships between variables like sales, price, and advertising, evaluating the significance of each factor. The analysis is supported by the use of MS Excel and SPSS tools, providing a detailed understanding of the data and the statistical techniques employed. The report concludes with interpretations and recommendations based on the findings, offering practical implications for decision-making.

STATISTICS
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

TABLE OF CONTENTS
INTRODUCTION...........................................................................................................................1
QUESTION 1...................................................................................................................................1
A. Analysing the data set as per distributions........................................................................1
B. Histogram of Percent Frequency distribution....................................................................2
QUESTION 2...................................................................................................................................2
A. Determining the sample size..............................................................................................2
B. Identifying the relevance between demand and unit price................................................3
C. Computing the coefficient of determination with interpretation.......................................3
D. Analysing the relationship between supply and unit price as per computing coefficient of
correlation...............................................................................................................................3
E. Predicting the supply in units.............................................................................................4
QUESTION 3...................................................................................................................................4
A. Constructing ANOVA Table.............................................................................................4
B. Advising statistical consultant...........................................................................................5
QUESTION 4...................................................................................................................................6
A. Estimated regression equation...........................................................................................6
B. determination of significant model Significance level 10%..............................................7
C. Ascertaining the competitor’s price and advertising individually relevant with sales......8
D. Re-estimating data set by insignificant independent variable...........................................9
E. Interpretation of slope co-efficiency of model.................................................................10
CONCLUSION..............................................................................................................................11
REFERENCES..............................................................................................................................12
INTRODUCTION...........................................................................................................................1
QUESTION 1...................................................................................................................................1
A. Analysing the data set as per distributions........................................................................1
B. Histogram of Percent Frequency distribution....................................................................2
QUESTION 2...................................................................................................................................2
A. Determining the sample size..............................................................................................2
B. Identifying the relevance between demand and unit price................................................3
C. Computing the coefficient of determination with interpretation.......................................3
D. Analysing the relationship between supply and unit price as per computing coefficient of
correlation...............................................................................................................................3
E. Predicting the supply in units.............................................................................................4
QUESTION 3...................................................................................................................................4
A. Constructing ANOVA Table.............................................................................................4
B. Advising statistical consultant...........................................................................................5
QUESTION 4...................................................................................................................................6
A. Estimated regression equation...........................................................................................6
B. determination of significant model Significance level 10%..............................................7
C. Ascertaining the competitor’s price and advertising individually relevant with sales......8
D. Re-estimating data set by insignificant independent variable...........................................9
E. Interpretation of slope co-efficiency of model.................................................................10
CONCLUSION..............................................................................................................................11
REFERENCES..............................................................................................................................12
INTRODUCTION
Statistical analysis plays main role in analysing the large data base and bringing accurate
outcomes. Implication of various tools and techniques in identifying the actual result will be
beneficial in proper decision making. In the present report, there will be analysis and discussion
based on various methods which is presented accurate results of the variables. There will be use
of simple statistical measurement and make proper operational analysis with the help of MS
excel and SPSS tools. There will be analysis of correlation coefficient, regression as well as
variations methods which are involved in analysing the outcomes.
QUESTION 1
A. Analysing the data set as per distributions
Analysing the marks scored by a class in a respective period which can be through
determining frequencies of data base (Pope and Stanistreet, 2017). With respect to analysing
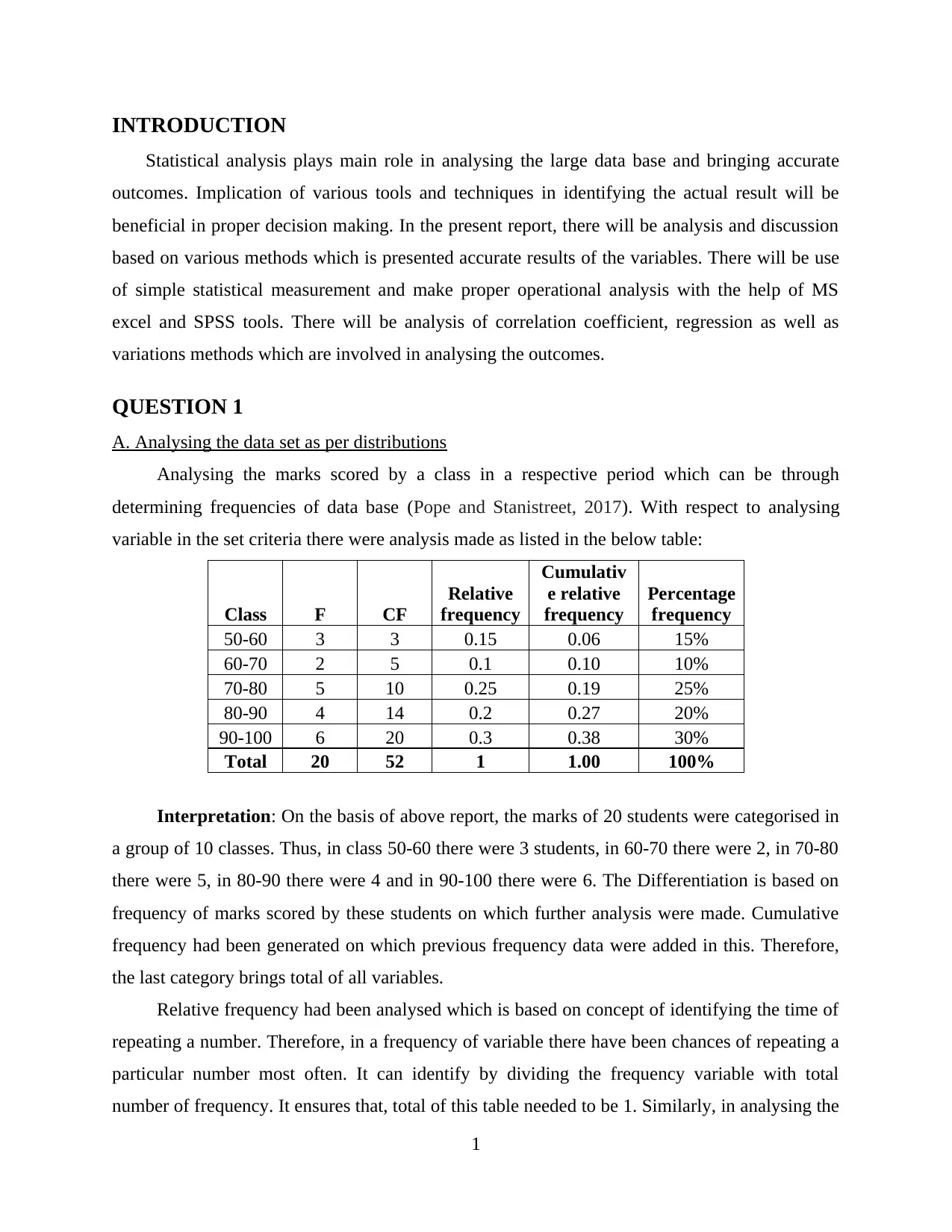
variable in the set criteria there were analysis made as listed in the below table:
Class F CF
Relative
frequency
Cumulativ
e relative
frequency
Percentage
frequency
50-60 3 3 0.15 0.06 15%
60-70 2 5 0.1 0.10 10%
70-80 5 10 0.25 0.19 25%
80-90 4 14 0.2 0.27 20%
90-100 6 20 0.3 0.38 30%
Total 20 52 1 1.00 100%
Interpretation: On the basis of above report, the marks of 20 students were categorised in
a group of 10 classes. Thus, in class 50-60 there were 3 students, in 60-70 there were 2, in 70-80
there were 5, in 80-90 there were 4 and in 90-100 there were 6. The Differentiation is based on
frequency of marks scored by these students on which further analysis were made. Cumulative
frequency had been generated on which previous frequency data were added in this. Therefore,
the last category brings total of all variables.
Relative frequency had been analysed which is based on concept of identifying the time of
repeating a number. Therefore, in a frequency of variable there have been chances of repeating a
particular number most often. It can identify by dividing the frequency variable with total
number of frequency. It ensures that, total of this table needed to be 1. Similarly, in analysing the
1
Statistical analysis plays main role in analysing the large data base and bringing accurate
outcomes. Implication of various tools and techniques in identifying the actual result will be
beneficial in proper decision making. In the present report, there will be analysis and discussion
based on various methods which is presented accurate results of the variables. There will be use
of simple statistical measurement and make proper operational analysis with the help of MS
excel and SPSS tools. There will be analysis of correlation coefficient, regression as well as
variations methods which are involved in analysing the outcomes.
QUESTION 1
A. Analysing the data set as per distributions
Analysing the marks scored by a class in a respective period which can be through
determining frequencies of data base (Pope and Stanistreet, 2017). With respect to analysing
variable in the set criteria there were analysis made as listed in the below table:
Class F CF
Relative
frequency
Cumulativ
e relative
frequency
Percentage
frequency
50-60 3 3 0.15 0.06 15%
60-70 2 5 0.1 0.10 10%
70-80 5 10 0.25 0.19 25%
80-90 4 14 0.2 0.27 20%
90-100 6 20 0.3 0.38 30%
Total 20 52 1 1.00 100%
Interpretation: On the basis of above report, the marks of 20 students were categorised in
a group of 10 classes. Thus, in class 50-60 there were 3 students, in 60-70 there were 2, in 70-80
there were 5, in 80-90 there were 4 and in 90-100 there were 6. The Differentiation is based on
frequency of marks scored by these students on which further analysis were made. Cumulative
frequency had been generated on which previous frequency data were added in this. Therefore,
the last category brings total of all variables.
Relative frequency had been analysed which is based on concept of identifying the time of
repeating a number. Therefore, in a frequency of variable there have been chances of repeating a
particular number most often. It can identify by dividing the frequency variable with total
number of frequency. It ensures that, total of this table needed to be 1. Similarly, in analysing the
1
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
cumulative relative frequency table which considers cumulative frequency for analysing this data
base. Percentage frequency demonstrates the total weightage in a category is hold by a variable.
It was analysed by considering the denominator as total of the frequency table.
B. Histogram of Percent Frequency distribution
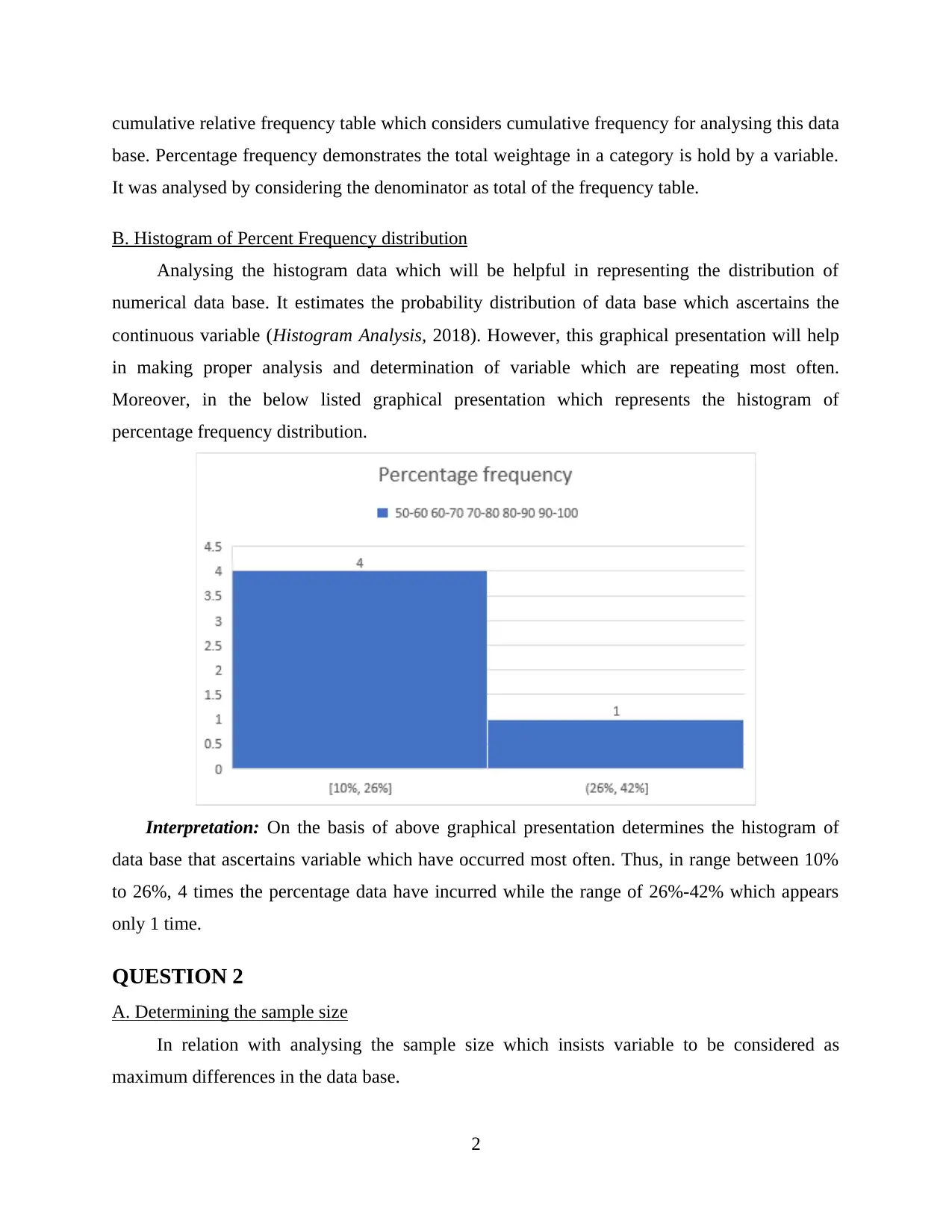
Analysing the histogram data which will be helpful in representing the distribution of
numerical data base. It estimates the probability distribution of data base which ascertains the
continuous variable (Histogram Analysis, 2018). However, this graphical presentation will help
in making proper analysis and determination of variable which are repeating most often.
Moreover, in the below listed graphical presentation which represents the histogram of
percentage frequency distribution.
Interpretation: On the basis of above graphical presentation determines the histogram of
data base that ascertains variable which have occurred most often. Thus, in range between 10%
to 26%, 4 times the percentage data have incurred while the range of 26%-42% which appears
only 1 time.
QUESTION 2
A. Determining the sample size
In relation with analysing the sample size which insists variable to be considered as
maximum differences in the data base.
2
base. Percentage frequency demonstrates the total weightage in a category is hold by a variable.
It was analysed by considering the denominator as total of the frequency table.
B. Histogram of Percent Frequency distribution
Analysing the histogram data which will be helpful in representing the distribution of
numerical data base. It estimates the probability distribution of data base which ascertains the
continuous variable (Histogram Analysis, 2018). However, this graphical presentation will help
in making proper analysis and determination of variable which are repeating most often.
Moreover, in the below listed graphical presentation which represents the histogram of
percentage frequency distribution.
Interpretation: On the basis of above graphical presentation determines the histogram of
data base that ascertains variable which have occurred most often. Thus, in range between 10%
to 26%, 4 times the percentage data have incurred while the range of 26%-42% which appears
only 1 time.
QUESTION 2
A. Determining the sample size
In relation with analysing the sample size which insists variable to be considered as
maximum differences in the data base.
2
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Maximum Difference Sample size Power
39 40 0.975
Interpretation: On the basis of above table, it can be said that, maximum difference in
ANOVA table was 39 and to determine sample size the formula will be used here as (n+1).
Therefore (39+1) which brings that 40 is the sample size of this outcome. Along with this, the
power of such result is analysed as 0.975
B. Identifying the relevance between demand and unit price
df SS MS F P
1 354.689 354.689 1.96622 0.508590155
39 7035.262 180.391
Coefficients
Standard
error t Stat P-value Lower 95% Upper 95%
54.076 2.358 22.933 0.00054 0.05895 0.112005
0.029 0.021 1.38095 0.000525 0.0009975
C. Computing the coefficient of determination with interpretation
Coefficient of determination:
This technique is helpful in analysing the outputs for regression. It can be interpreted as per
determining the variances between independent and dependent variables (Bethapudi and Desai,
2017). Moreover, in simple terms it can be said that Coefficient of determination is basically
square of correlation of x and y variables.
D. Analysing the relationship between supply and unit price as per computing coefficient of
correlation
Coefficient of correlation:
In a linear regression analysis this technique has been denoted as a relation between two
variables such as independent and dependent (Bennett and et.al., 2017). However, if the prices of
3
39 40 0.975
Interpretation: On the basis of above table, it can be said that, maximum difference in
ANOVA table was 39 and to determine sample size the formula will be used here as (n+1).
Therefore (39+1) which brings that 40 is the sample size of this outcome. Along with this, the
power of such result is analysed as 0.975
B. Identifying the relevance between demand and unit price
df SS MS F P
1 354.689 354.689 1.96622 0.508590155
39 7035.262 180.391
Coefficients
Standard
error t Stat P-value Lower 95% Upper 95%
54.076 2.358 22.933 0.00054 0.05895 0.112005
0.029 0.021 1.38095 0.000525 0.0009975
C. Computing the coefficient of determination with interpretation
Coefficient of determination:
This technique is helpful in analysing the outputs for regression. It can be interpreted as per
determining the variances between independent and dependent variables (Bethapudi and Desai,
2017). Moreover, in simple terms it can be said that Coefficient of determination is basically
square of correlation of x and y variables.
D. Analysing the relationship between supply and unit price as per computing coefficient of
correlation
Coefficient of correlation:
In a linear regression analysis this technique has been denoted as a relation between two
variables such as independent and dependent (Bennett and et.al., 2017). However, if the prices of
3
the commodities rise, it will have reverse impacts over sales. Increment in rates will reduce
consumption of products.
E. Predicting the supply in units
It can be said that, if the unit prices will be $50000 which will reflect a decline in the supply
of units. It will affect economically over consumers in consuming commodities which in turn
affect the reduction in sales of products.
QUESTION 3
A. Constructing ANOVA Table
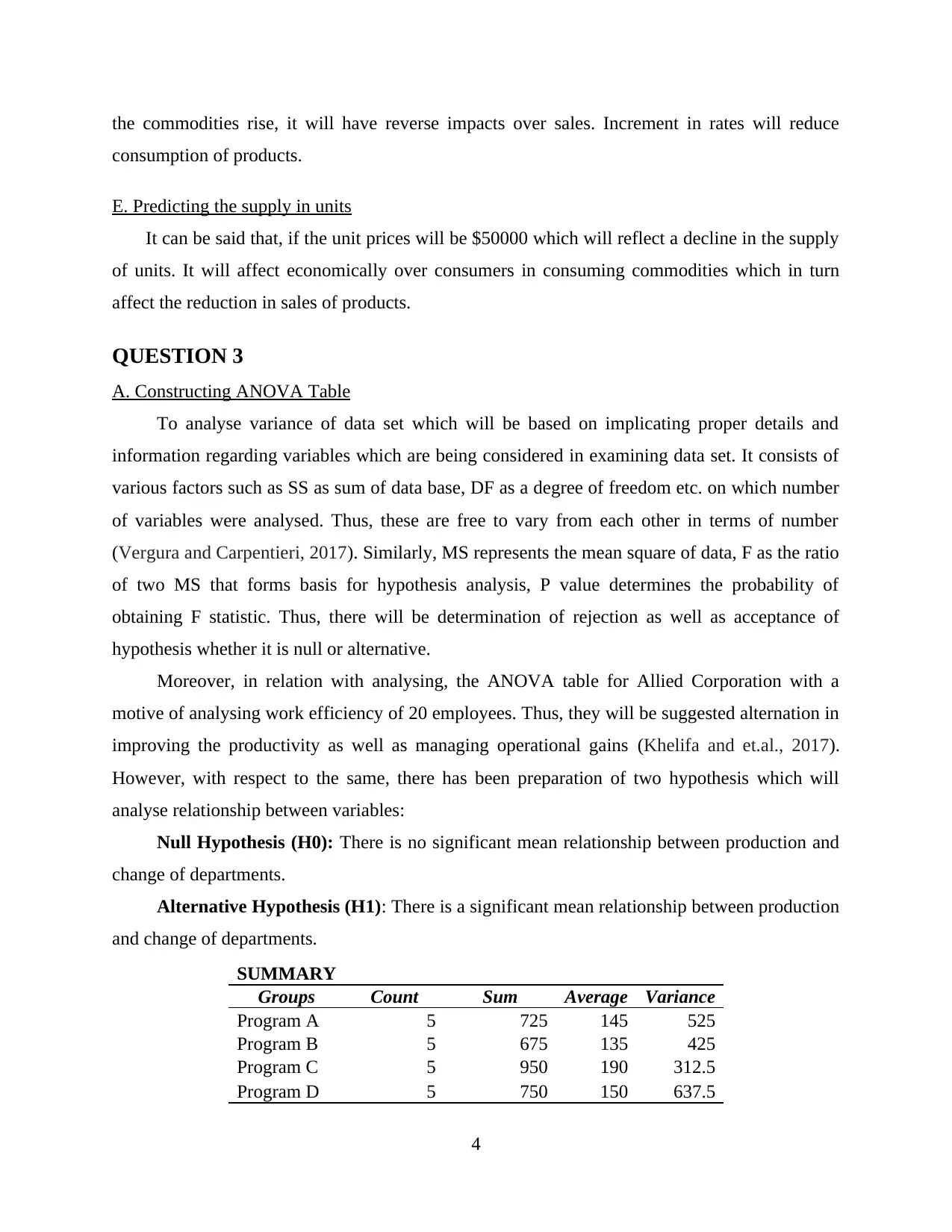
To analyse variance of data set which will be based on implicating proper details and
information regarding variables which are being considered in examining data set. It consists of
various factors such as SS as sum of data base, DF as a degree of freedom etc. on which number
of variables were analysed. Thus, these are free to vary from each other in terms of number
(Vergura and Carpentieri, 2017). Similarly, MS represents the mean square of data, F as the ratio
of two MS that forms basis for hypothesis analysis, P value determines the probability of
obtaining F statistic. Thus, there will be determination of rejection as well as acceptance of
hypothesis whether it is null or alternative.
Moreover, in relation with analysing, the ANOVA table for Allied Corporation with a
motive of analysing work efficiency of 20 employees. Thus, they will be suggested alternation in
improving the productivity as well as managing operational gains (Khelifa and et.al., 2017).
However, with respect to the same, there has been preparation of two hypothesis which will
analyse relationship between variables:
Null Hypothesis (H0): There is no significant mean relationship between production and
change of departments.
Alternative Hypothesis (H1): There is a significant mean relationship between production
and change of departments.
SUMMARY
Groups Count Sum Average Variance
Program A 5 725 145 525
Program B 5 675 135 425
Program C 5 950 190 312.5
Program D 5 750 150 637.5
4
consumption of products.
E. Predicting the supply in units
It can be said that, if the unit prices will be $50000 which will reflect a decline in the supply
of units. It will affect economically over consumers in consuming commodities which in turn
affect the reduction in sales of products.
QUESTION 3
A. Constructing ANOVA Table
To analyse variance of data set which will be based on implicating proper details and
information regarding variables which are being considered in examining data set. It consists of
various factors such as SS as sum of data base, DF as a degree of freedom etc. on which number
of variables were analysed. Thus, these are free to vary from each other in terms of number
(Vergura and Carpentieri, 2017). Similarly, MS represents the mean square of data, F as the ratio
of two MS that forms basis for hypothesis analysis, P value determines the probability of
obtaining F statistic. Thus, there will be determination of rejection as well as acceptance of
hypothesis whether it is null or alternative.
Moreover, in relation with analysing, the ANOVA table for Allied Corporation with a
motive of analysing work efficiency of 20 employees. Thus, they will be suggested alternation in
improving the productivity as well as managing operational gains (Khelifa and et.al., 2017).
However, with respect to the same, there has been preparation of two hypothesis which will
analyse relationship between variables:
Null Hypothesis (H0): There is no significant mean relationship between production and
change of departments.
Alternative Hypothesis (H1): There is a significant mean relationship between production
and change of departments.
SUMMARY
Groups Count Sum Average Variance
Program A 5 725 145 525
Program B 5 675 135 425
Program C 5 950 190 312.5
Program D 5 750 150 637.5
4
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

ANOVA
Source of
Variation SS df MS F P-value F crit
Between
Groups 8750 3 2916.667 6.140351 0.00557 3.238872
Within Groups 7600 16 475
Total 16350 19
Interpretation: On the basis of above listed ANOVA table which represents the outcomes
of workers which are performing in 4 different departments. In analyzing the duties performed
by individual in these departments which presents that, Program A as sum of 725 units on which
average number 145 and variance as 525. In program B, sum of units are 675 and the average of
135. Thus, it can be said that 20 employees in this program are making production with the mean
efforts of 135.
Similarly, the variance of this data set had been analyzed as 425. In consideration with
Program C, the sum of details is 950 while average of analyzed data set is 190. Therefore, this is
comparatively higher than other departments. Thus, employees in this department are making
higher efforts which has been reflected in the average gains such as 190. In Program D, the sum
of data base is 750 while average is of 150 and variance of 637.5. However, with respect with
this data base and analysis on which it can be said that there are employees in this department,
which are making production of 150 unit on an average.
B. Advising statistical consultant
As per analyzing ANOVA table of data set from outcomes of four departments in the
corporation. Thus, to enhance the productivity of business there are two department such as
Program C and D will be helpful in bringing effective volume of products. Moreover, in
consideration with the table, P value of data set is 0.00557 had been addressed (Jairaman, Zamri
and Rahim, 2018). Thus, it represents that there will be rejection to the null hypothesis as well as
acceptance to the alternative hypothesis.
It can be said that there is a significant mean relationship between production and change of
departments. Therefore, it represents that there is a relationship between changing department
and production of the units. Thus, employees will have positive influences which results in
5
Source of
Variation SS df MS F P-value F crit
Between
Groups 8750 3 2916.667 6.140351 0.00557 3.238872
Within Groups 7600 16 475
Total 16350 19
Interpretation: On the basis of above listed ANOVA table which represents the outcomes
of workers which are performing in 4 different departments. In analyzing the duties performed
by individual in these departments which presents that, Program A as sum of 725 units on which
average number 145 and variance as 525. In program B, sum of units are 675 and the average of
135. Thus, it can be said that 20 employees in this program are making production with the mean
efforts of 135.
Similarly, the variance of this data set had been analyzed as 425. In consideration with
Program C, the sum of details is 950 while average of analyzed data set is 190. Therefore, this is
comparatively higher than other departments. Thus, employees in this department are making
higher efforts which has been reflected in the average gains such as 190. In Program D, the sum
of data base is 750 while average is of 150 and variance of 637.5. However, with respect with
this data base and analysis on which it can be said that there are employees in this department,
which are making production of 150 unit on an average.
B. Advising statistical consultant
As per analyzing ANOVA table of data set from outcomes of four departments in the
corporation. Thus, to enhance the productivity of business there are two department such as
Program C and D will be helpful in bringing effective volume of products. Moreover, in
consideration with the table, P value of data set is 0.00557 had been addressed (Jairaman, Zamri
and Rahim, 2018). Thus, it represents that there will be rejection to the null hypothesis as well as
acceptance to the alternative hypothesis.
It can be said that there is a significant mean relationship between production and change of
departments. Therefore, it represents that there is a relationship between changing department
and production of the units. Thus, employees will have positive influences which results in
5
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

raising the production (Shutt and et.al., 2017). To enhance business efficiencies there will be
implication of various strategies and techniques to make positive changes. However, it will be
advised to the professionals of Allied Corporation that they must implicate these strategies which
result in making proper increment.
QUESTION 4
A. Estimated regression equation
Regression equation: This helps in model relationship between 2 variables by putting
them in a linear equation to analyse data. To analyse the equation on which one variable is said
to be explanatory variable which will be used in making appropriate observation relevant with a
dependent variable (Pope and Stanistreet, 2017). Moreover, regression is basically based on
predicting the value of variables which will be based on making appropriate analysis on the data
set. However, to enhance the sale of products, it will be based on two factors such as prices and
advertisement. Therefore, to analyse the relation of sales outcomes along with these elements
which have been analysed and addressed as below:
Null Hypothesis (H0): There is no mean significant differences between price
advertisement and sales of units.
Alternative Hypothesis (H1): There is a mean significant difference between price
advertisement and sales of units.
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.9572
R Square 0.91623
Adjusted R
Square 0.86038
Standard Error 1.23742
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 2 50.2397 25.1199 16.4053 0.02425
6
implication of various strategies and techniques to make positive changes. However, it will be
advised to the professionals of Allied Corporation that they must implicate these strategies which
result in making proper increment.
QUESTION 4
A. Estimated regression equation
Regression equation: This helps in model relationship between 2 variables by putting
them in a linear equation to analyse data. To analyse the equation on which one variable is said
to be explanatory variable which will be used in making appropriate observation relevant with a
dependent variable (Pope and Stanistreet, 2017). Moreover, regression is basically based on
predicting the value of variables which will be based on making appropriate analysis on the data
set. However, to enhance the sale of products, it will be based on two factors such as prices and
advertisement. Therefore, to analyse the relation of sales outcomes along with these elements
which have been analysed and addressed as below:
Null Hypothesis (H0): There is no mean significant differences between price
advertisement and sales of units.
Alternative Hypothesis (H1): There is a mean significant difference between price
advertisement and sales of units.
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.9572
R Square 0.91623
Adjusted R
Square 0.86038
Standard Error 1.23742
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 2 50.2397 25.1199 16.4053 0.02425
6
Residual 3 4.5936 1.5312
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept 2.35227 2.77741 0.84693 0.45925 -6.4867 11.1912 -6.4867 11.1912
Price 41.9148 8.98553 4.6647 0.0186 13.3188 70.5107 13.3188 70.5107
Advertisement 0.10326 0.22375 0.46148 0.67586 -0.6088 0.81534 -0.6088 0.81534
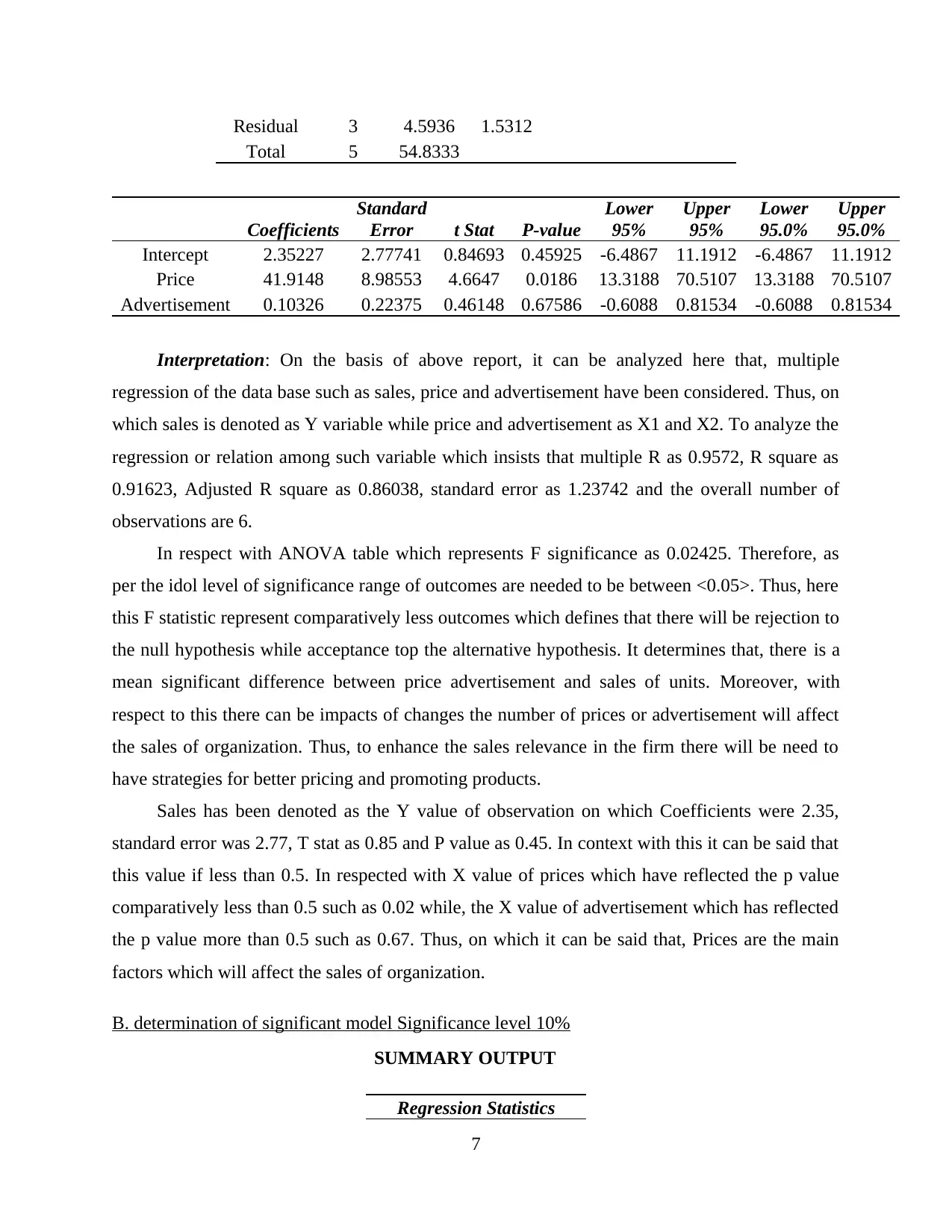
Interpretation: On the basis of above report, it can be analyzed here that, multiple
regression of the data base such as sales, price and advertisement have been considered. Thus, on
which sales is denoted as Y variable while price and advertisement as X1 and X2. To analyze the
regression or relation among such variable which insists that multiple R as 0.9572, R square as
0.91623, Adjusted R square as 0.86038, standard error as 1.23742 and the overall number of
observations are 6.
In respect with ANOVA table which represents F significance as 0.02425. Therefore, as
per the idol level of significance range of outcomes are needed to be between <0.05>. Thus, here
this F statistic represent comparatively less outcomes which defines that there will be rejection to
the null hypothesis while acceptance top the alternative hypothesis. It determines that, there is a
mean significant difference between price advertisement and sales of units. Moreover, with
respect to this there can be impacts of changes the number of prices or advertisement will affect
the sales of organization. Thus, to enhance the sales relevance in the firm there will be need to
have strategies for better pricing and promoting products.
Sales has been denoted as the Y value of observation on which Coefficients were 2.35,
standard error was 2.77, T stat as 0.85 and P value as 0.45. In context with this it can be said that
this value if less than 0.5. In respected with X value of prices which have reflected the p value
comparatively less than 0.5 such as 0.02 while, the X value of advertisement which has reflected
the p value more than 0.5 such as 0.67. Thus, on which it can be said that, Prices are the main
factors which will affect the sales of organization.
B. determination of significant model Significance level 10%
SUMMARY OUTPUT
Regression Statistics
7
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept 2.35227 2.77741 0.84693 0.45925 -6.4867 11.1912 -6.4867 11.1912
Price 41.9148 8.98553 4.6647 0.0186 13.3188 70.5107 13.3188 70.5107
Advertisement 0.10326 0.22375 0.46148 0.67586 -0.6088 0.81534 -0.6088 0.81534
Interpretation: On the basis of above report, it can be analyzed here that, multiple
regression of the data base such as sales, price and advertisement have been considered. Thus, on
which sales is denoted as Y variable while price and advertisement as X1 and X2. To analyze the
regression or relation among such variable which insists that multiple R as 0.9572, R square as
0.91623, Adjusted R square as 0.86038, standard error as 1.23742 and the overall number of
observations are 6.
In respect with ANOVA table which represents F significance as 0.02425. Therefore, as
per the idol level of significance range of outcomes are needed to be between <0.05>. Thus, here
this F statistic represent comparatively less outcomes which defines that there will be rejection to
the null hypothesis while acceptance top the alternative hypothesis. It determines that, there is a
mean significant difference between price advertisement and sales of units. Moreover, with
respect to this there can be impacts of changes the number of prices or advertisement will affect
the sales of organization. Thus, to enhance the sales relevance in the firm there will be need to
have strategies for better pricing and promoting products.
Sales has been denoted as the Y value of observation on which Coefficients were 2.35,
standard error was 2.77, T stat as 0.85 and P value as 0.45. In context with this it can be said that
this value if less than 0.5. In respected with X value of prices which have reflected the p value
comparatively less than 0.5 such as 0.02 while, the X value of advertisement which has reflected
the p value more than 0.5 such as 0.67. Thus, on which it can be said that, Prices are the main
factors which will affect the sales of organization.
B. determination of significant model Significance level 10%
SUMMARY OUTPUT
Regression Statistics
7
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
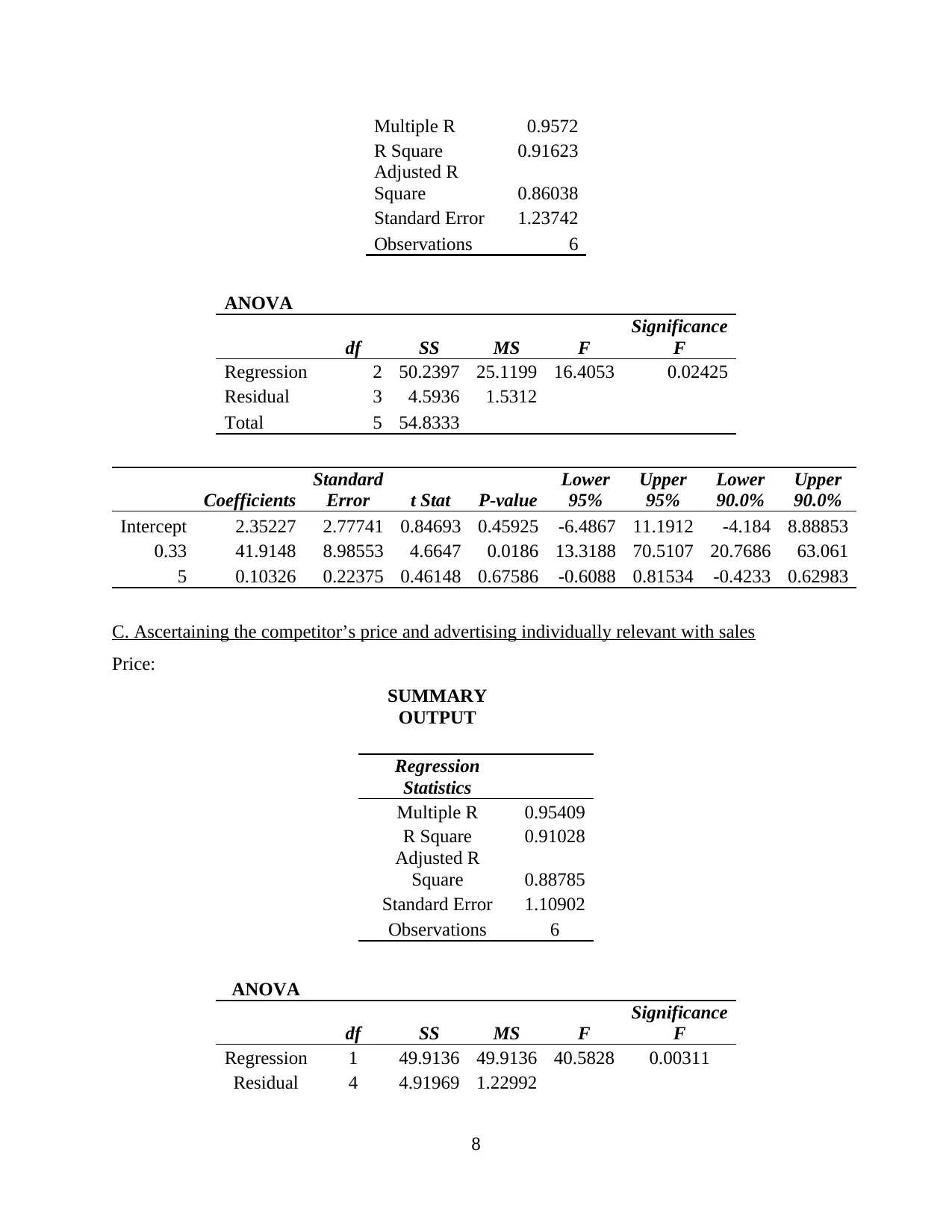
Multiple R 0.9572
R Square 0.91623
Adjusted R
Square 0.86038
Standard Error 1.23742
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 2 50.2397 25.1199 16.4053 0.02425
Residual 3 4.5936 1.5312
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 2.35227 2.77741 0.84693 0.45925 -6.4867 11.1912 -4.184 8.88853
0.33 41.9148 8.98553 4.6647 0.0186 13.3188 70.5107 20.7686 63.061
5 0.10326 0.22375 0.46148 0.67586 -0.6088 0.81534 -0.4233 0.62983
C. Ascertaining the competitor’s price and advertising individually relevant with sales
Price:
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.95409
R Square 0.91028
Adjusted R
Square 0.88785
Standard Error 1.10902
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 1 49.9136 49.9136 40.5828 0.00311
Residual 4 4.91969 1.22992
8
R Square 0.91623
Adjusted R
Square 0.86038
Standard Error 1.23742
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 2 50.2397 25.1199 16.4053 0.02425
Residual 3 4.5936 1.5312
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 2.35227 2.77741 0.84693 0.45925 -6.4867 11.1912 -4.184 8.88853
0.33 41.9148 8.98553 4.6647 0.0186 13.3188 70.5107 20.7686 63.061
5 0.10326 0.22375 0.46148 0.67586 -0.6088 0.81534 -0.4233 0.62983
C. Ascertaining the competitor’s price and advertising individually relevant with sales
Price:
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.95409
R Square 0.91028
Adjusted R
Square 0.88785
Standard Error 1.10902
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 1 49.9136 49.9136 40.5828 0.00311
Residual 4 4.91969 1.22992
8
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
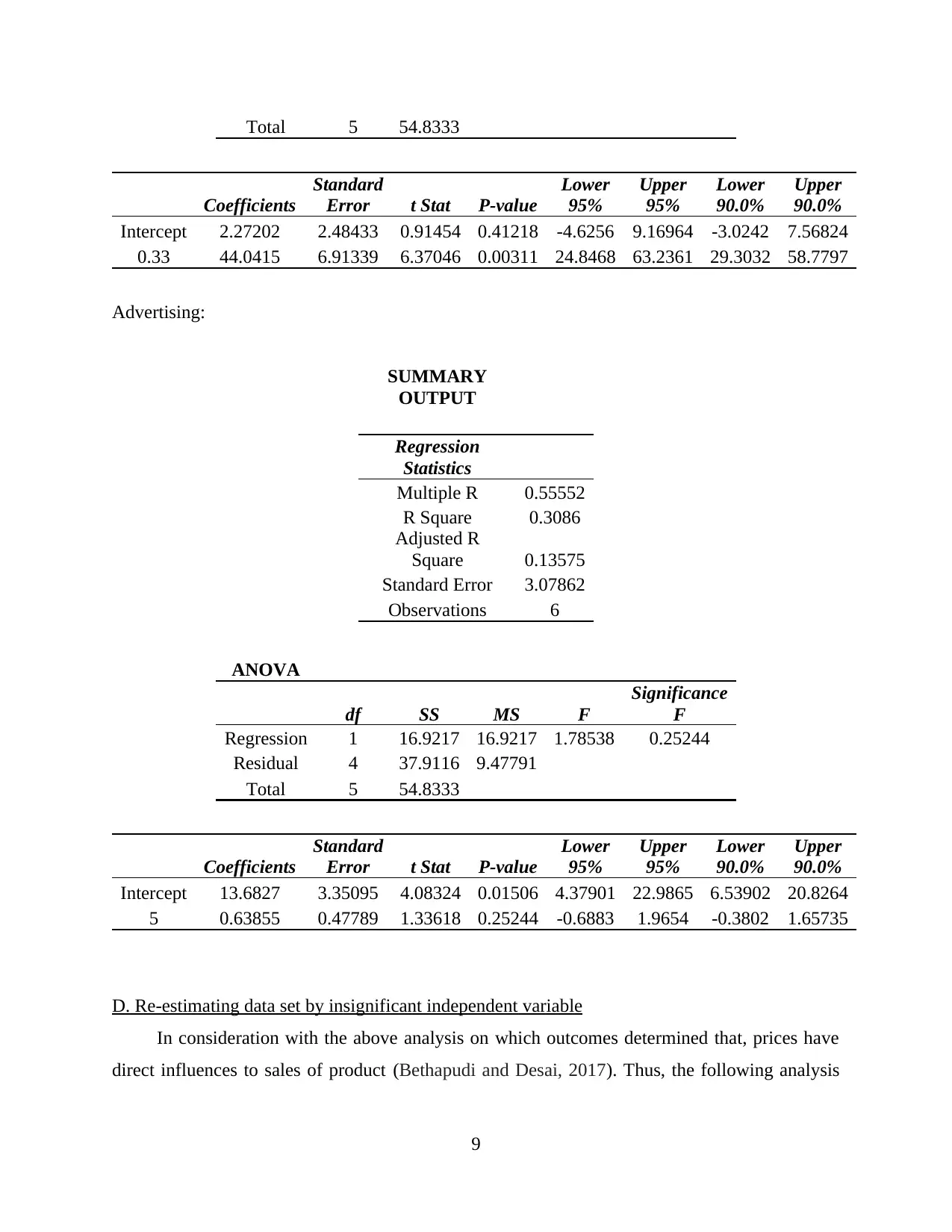
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 2.27202 2.48433 0.91454 0.41218 -4.6256 9.16964 -3.0242 7.56824
0.33 44.0415 6.91339 6.37046 0.00311 24.8468 63.2361 29.3032 58.7797
Advertising:
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.55552
R Square 0.3086
Adjusted R
Square 0.13575
Standard Error 3.07862
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 1 16.9217 16.9217 1.78538 0.25244
Residual 4 37.9116 9.47791
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 13.6827 3.35095 4.08324 0.01506 4.37901 22.9865 6.53902 20.8264
5 0.63855 0.47789 1.33618 0.25244 -0.6883 1.9654 -0.3802 1.65735
D. Re-estimating data set by insignificant independent variable
In consideration with the above analysis on which outcomes determined that, prices have
direct influences to sales of product (Bethapudi and Desai, 2017). Thus, the following analysis
9
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 2.27202 2.48433 0.91454 0.41218 -4.6256 9.16964 -3.0242 7.56824
0.33 44.0415 6.91339 6.37046 0.00311 24.8468 63.2361 29.3032 58.7797
Advertising:
SUMMARY
OUTPUT
Regression
Statistics
Multiple R 0.55552
R Square 0.3086
Adjusted R
Square 0.13575
Standard Error 3.07862
Observations 6
ANOVA
df SS MS F
Significance
F
Regression 1 16.9217 16.9217 1.78538 0.25244
Residual 4 37.9116 9.47791
Total 5 54.8333
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 13.6827 3.35095 4.08324 0.01506 4.37901 22.9865 6.53902 20.8264
5 0.63855 0.47789 1.33618 0.25244 -0.6883 1.9654 -0.3802 1.65735
D. Re-estimating data set by insignificant independent variable
In consideration with the above analysis on which outcomes determined that, prices have
direct influences to sales of product (Bethapudi and Desai, 2017). Thus, the following analysis
9
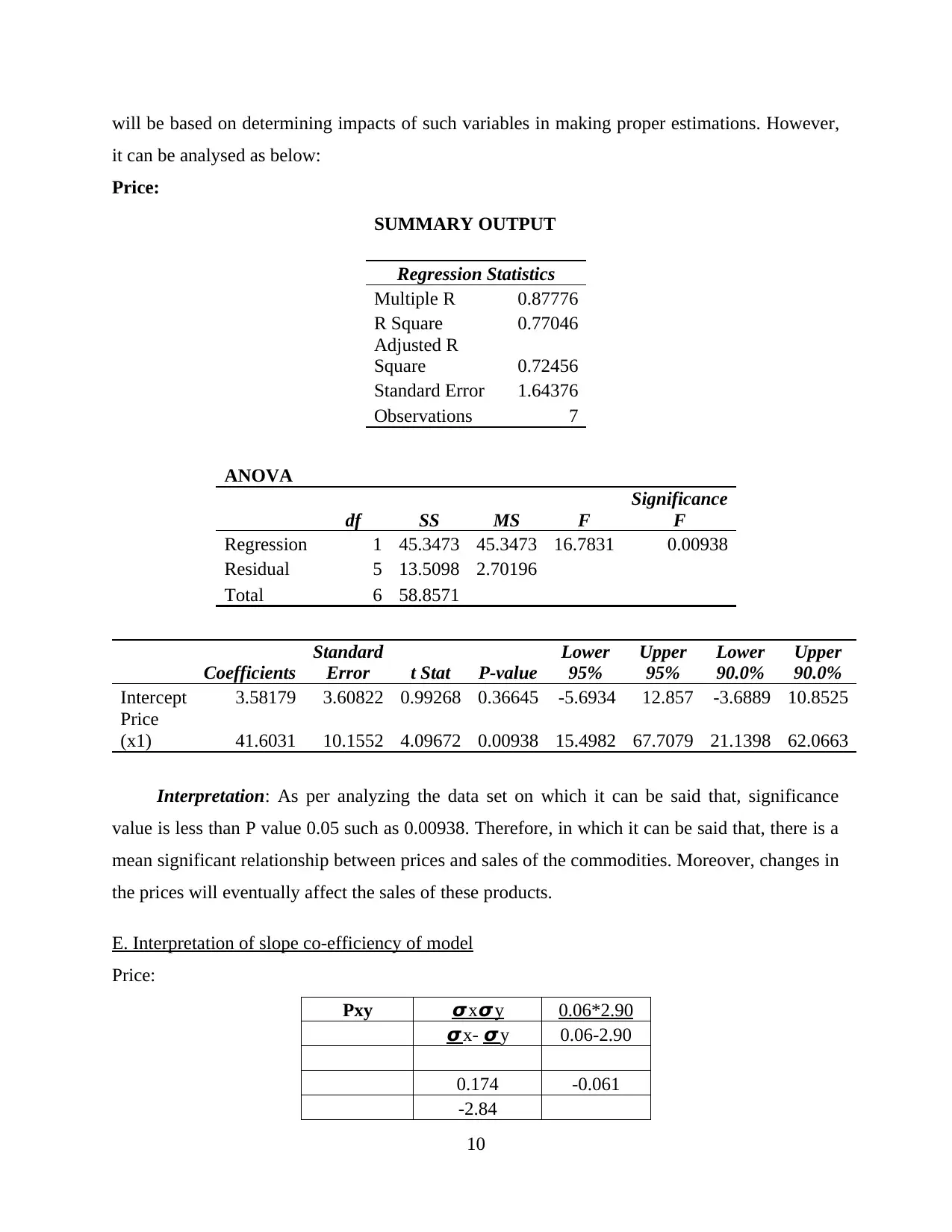
will be based on determining impacts of such variables in making proper estimations. However,
it can be analysed as below:
Price:
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.87776
R Square 0.77046
Adjusted R
Square 0.72456
Standard Error 1.64376
Observations 7
ANOVA
df SS MS F
Significance
F
Regression 1 45.3473 45.3473 16.7831 0.00938
Residual 5 13.5098 2.70196
Total 6 58.8571
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 3.58179 3.60822 0.99268 0.36645 -5.6934 12.857 -3.6889 10.8525
Price
(x1) 41.6031 10.1552 4.09672 0.00938 15.4982 67.7079 21.1398 62.0663
Interpretation: As per analyzing the data set on which it can be said that, significance
value is less than P value 0.05 such as 0.00938. Therefore, in which it can be said that, there is a
mean significant relationship between prices and sales of the commodities. Moreover, changes in
the prices will eventually affect the sales of these products.
E. Interpretation of slope co-efficiency of model
Price:
Pxy 𝞼x𝞼y 0.06*2.90
𝞼x- 𝞼y 0.06-2.90
0.174 -0.061
-2.84
10
it can be analysed as below:
Price:
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.87776
R Square 0.77046
Adjusted R
Square 0.72456
Standard Error 1.64376
Observations 7
ANOVA
df SS MS F
Significance
F
Regression 1 45.3473 45.3473 16.7831 0.00938
Residual 5 13.5098 2.70196
Total 6 58.8571
Coefficients
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
90.0%
Upper
90.0%
Intercept 3.58179 3.60822 0.99268 0.36645 -5.6934 12.857 -3.6889 10.8525
Price
(x1) 41.6031 10.1552 4.09672 0.00938 15.4982 67.7079 21.1398 62.0663
Interpretation: As per analyzing the data set on which it can be said that, significance
value is less than P value 0.05 such as 0.00938. Therefore, in which it can be said that, there is a
mean significant relationship between prices and sales of the commodities. Moreover, changes in
the prices will eventually affect the sales of these products.
E. Interpretation of slope co-efficiency of model
Price:
Pxy 𝞼x𝞼y 0.06*2.90
𝞼x- 𝞼y 0.06-2.90
0.174 -0.061
-2.84
10
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 14
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.