Statistics Assignment: Mean, Median, Mode, Regression Analysis, ANOVA
VerifiedAdded on 2020/03/01
|10
|1180
|65
Homework Assignment
AI Summary
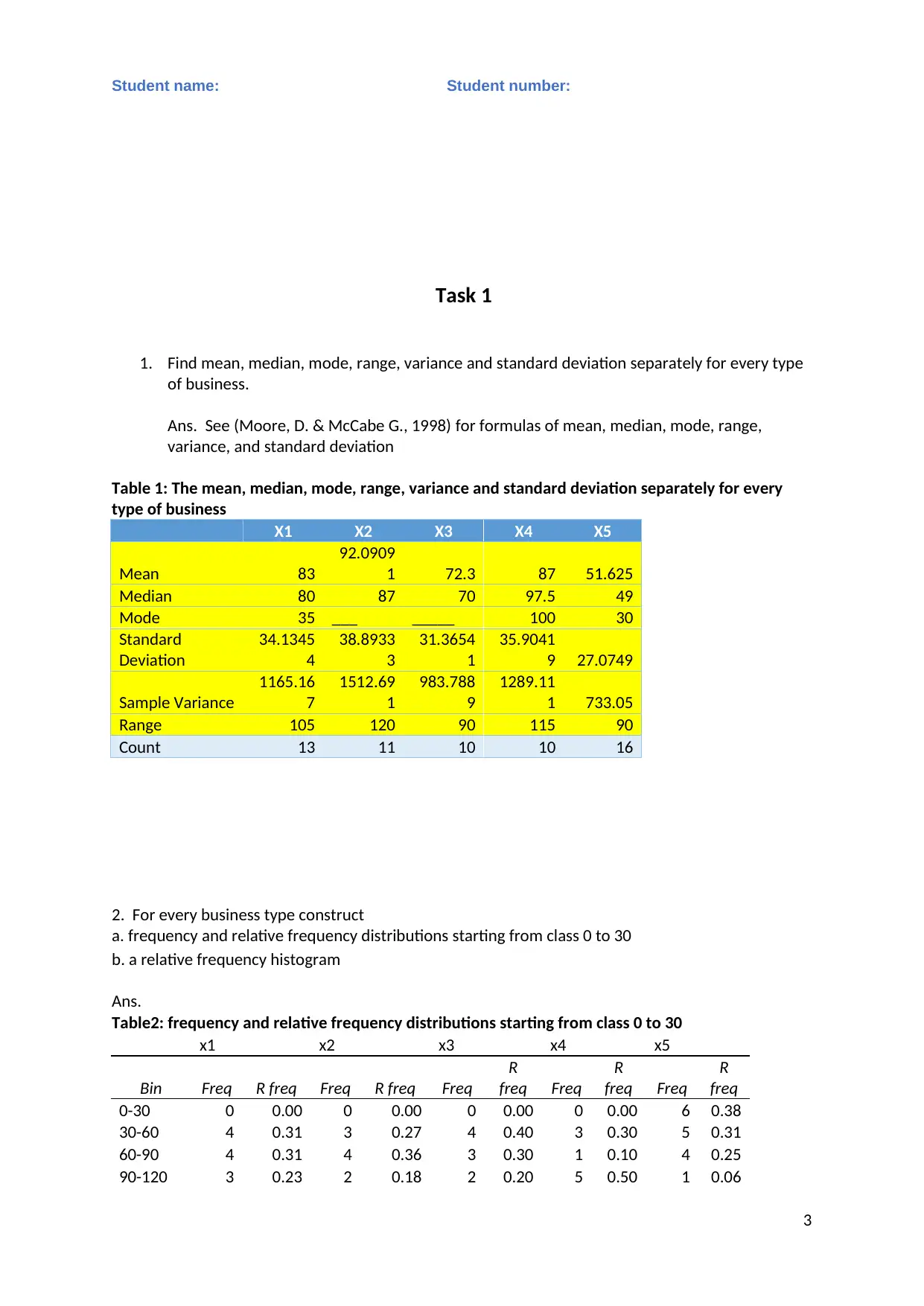
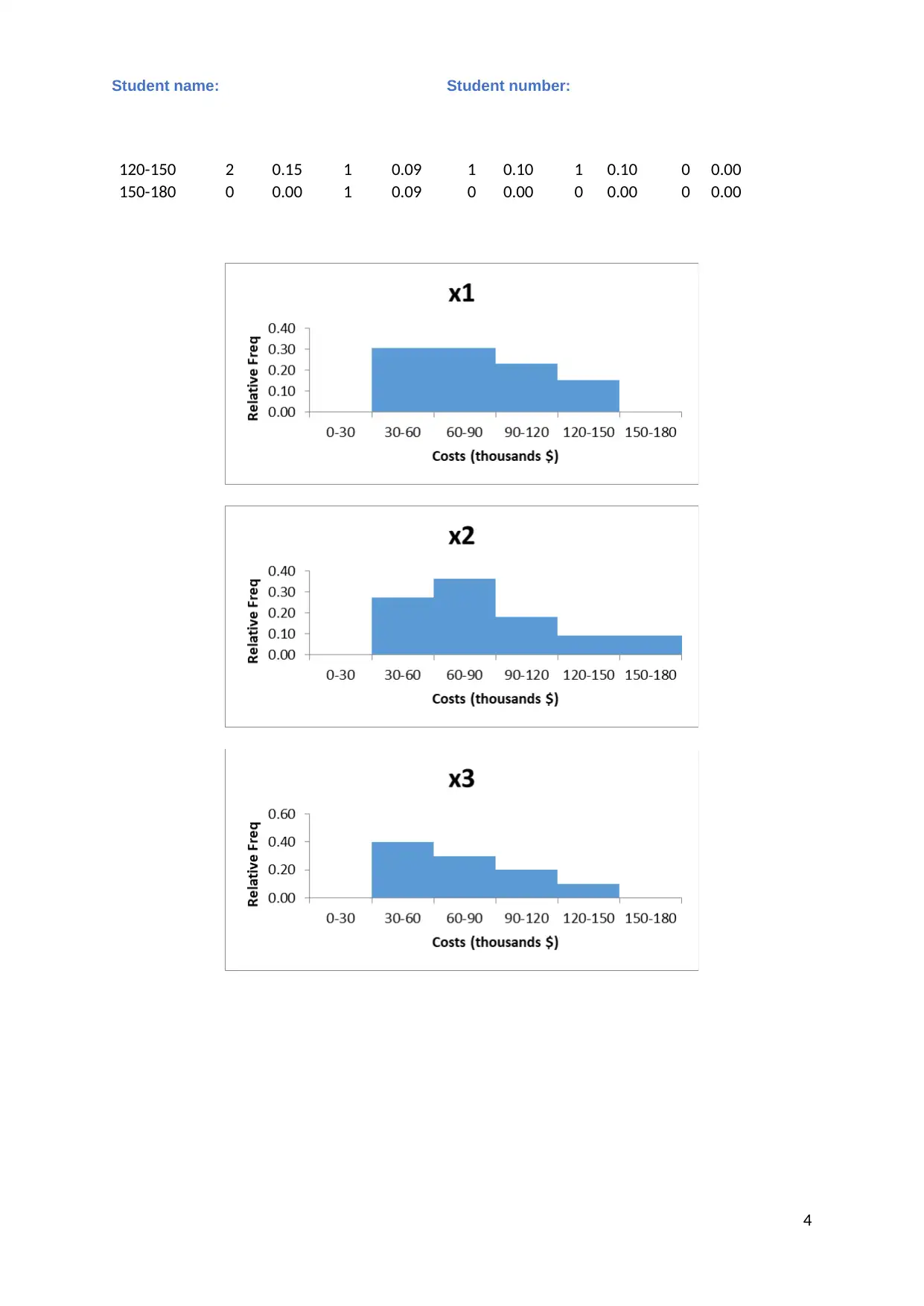
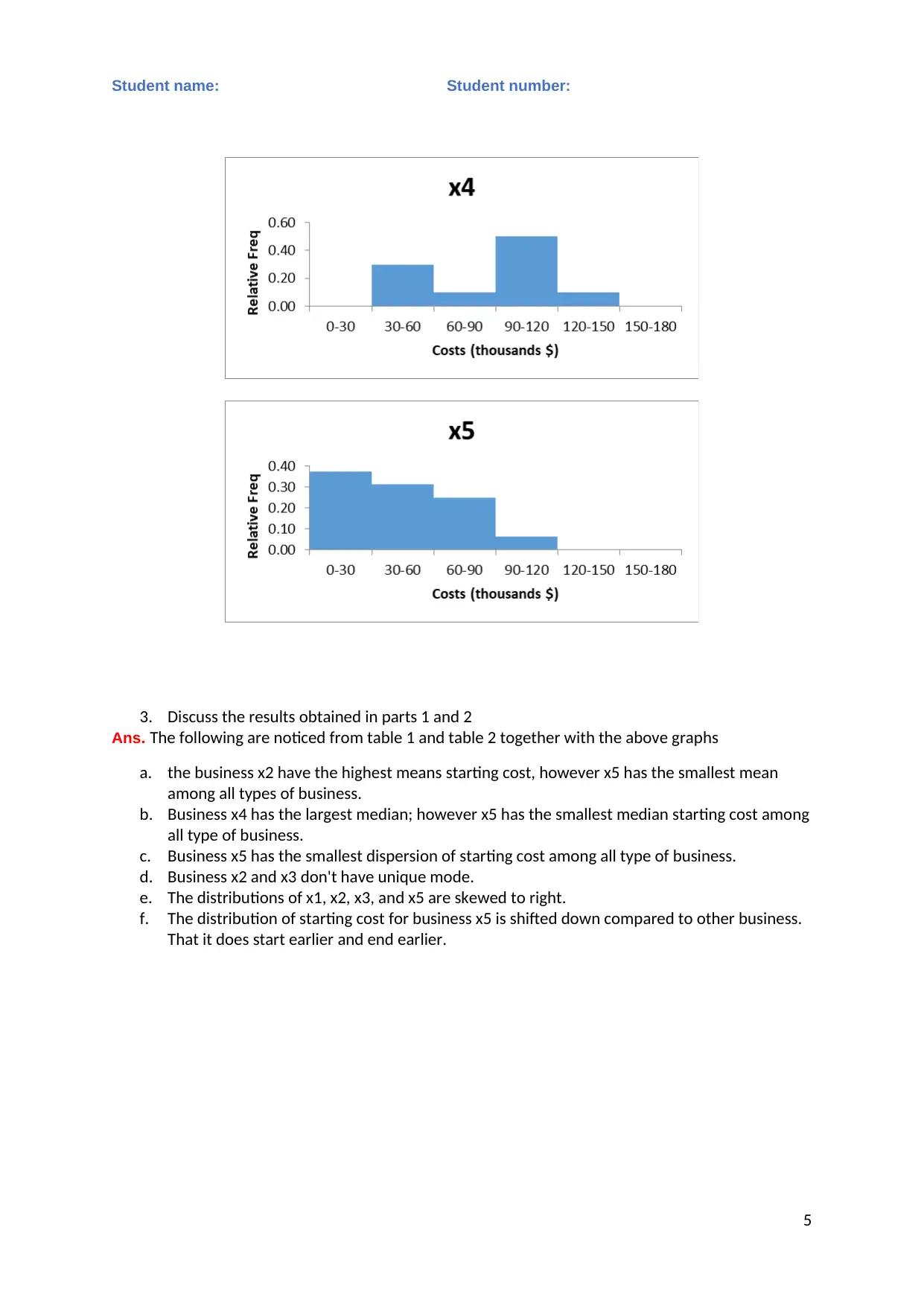
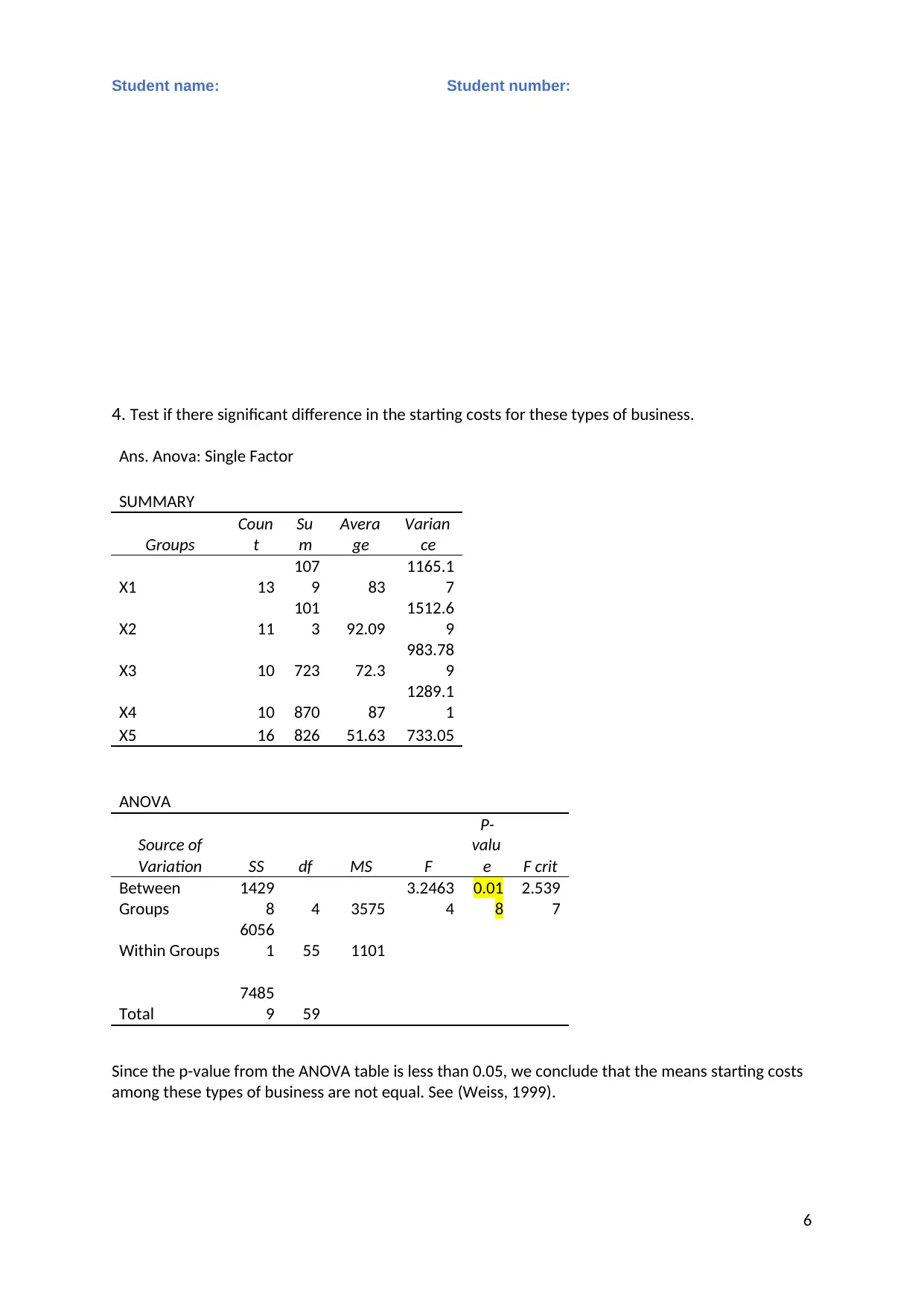
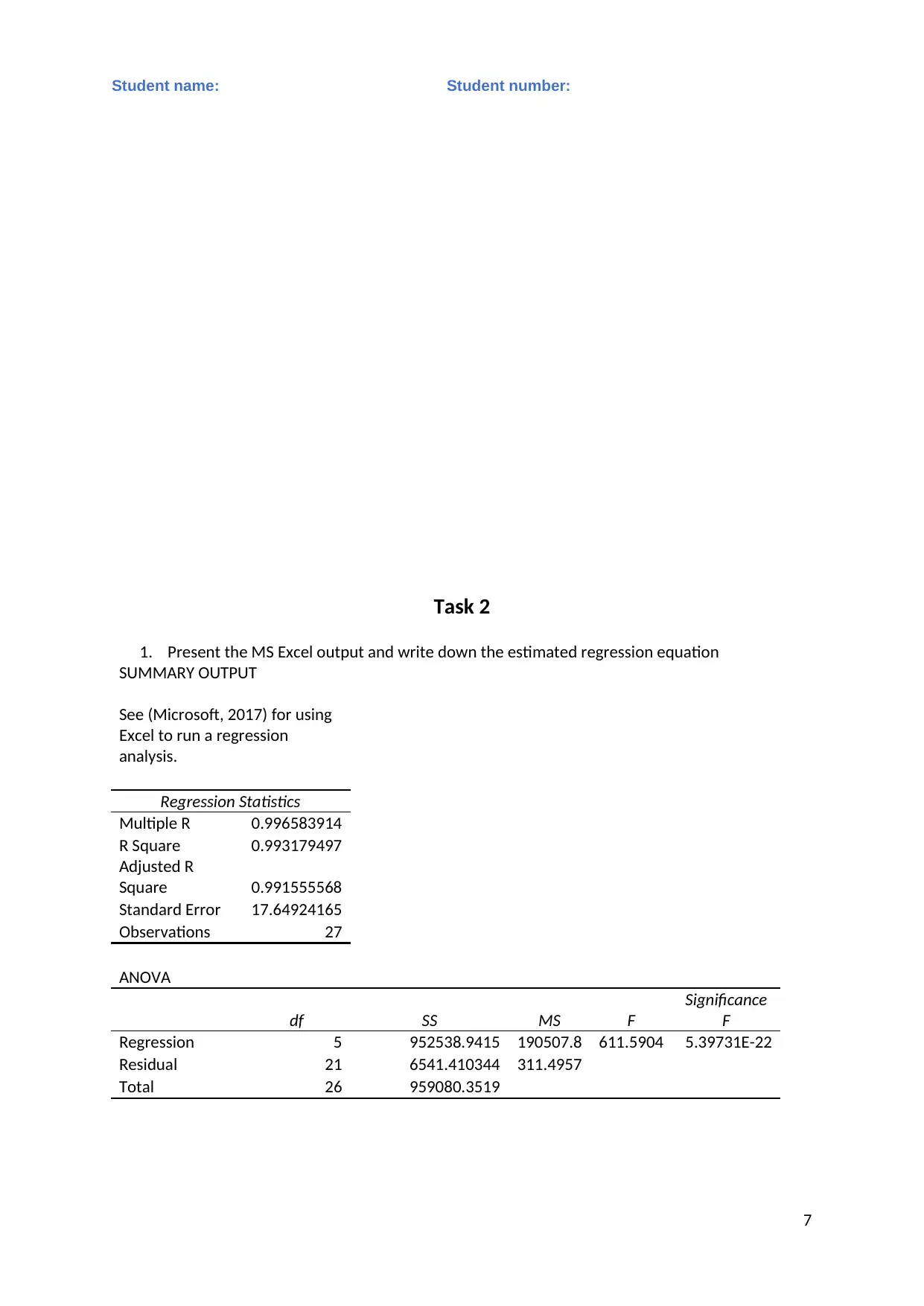
This statistics assignment analyzes business data using various statistical methods. Task 1 involves calculating descriptive statistics (mean, median, mode, range, variance, and standard deviation) for different business types. Frequency and relative frequency distributions, along with relative frequency histograms, are constructed and discussed. An ANOVA test is performed to determine if there are significant differences in starting costs among the business types. Task 2 focuses on regression analysis, including the presentation of MS Excel output, writing the estimated regression equation, assessing model fit, testing hypotheses, interpreting slope coefficients, constructing confidence intervals, and testing the significance of individual variables. The assignment concludes with the removal of insignificant variables (if any) and re-estimation of the model, and the use of the regression equation for predictions. The student provides a detailed analysis, interpretation, and conclusion based on the statistical results, supported by relevant literature.





1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.