(PDF) Text Mining Business Intelligence
VerifiedAdded on 2021/06/18
|13
|2719
|119
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Institution
Student Name
Business Intelligence
Student Name
Business Intelligence
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

TEXT MINING
Text mining is the process of mining or deriving information of high quality from text
(Cousssement Kristof, et al., 2008). Such information is arrived at by devising trends and
patterns through means like statistical pattern learning.
In text mining, high quality refers to a combination of novelty or relevance. Text mining tasks
include sentiment analysis and document summarization. Data mining however is the process of
obtaining patterns in data sets (Han, et al., 2011). Overall goal of this is to extract relevant
information from a dataset and transform it into a structure that is understandable.
Data mining is a general process that includes text mining. However, data mining is the
extraction of relationships from structured data e.g., pie charts or tables whereas text mining
involves extraction of insights from a dataset.
Text retrieval processes range from a preparatory step to the final step of compiling the high-
quality information.
Information retrieval involves identifying and collecting a corpus in a database for analysis
(Pang Bo & Lee Lilian, 2002).
Text analytic systems apply natural language processing e.g., syntactic parsing and other forms
of linguistic analysis.
Named entity recognition involves statistical techniques, gazetteers etc. for identifying named
text features; abbreviations and stock ticker symbols (Quinlan, 1996).
Disambiguation involves use of clues that are contextual.
Recognition of Pattern Entities involves features like email addresses, telephone numbers, which
are discerned through regular expression or other kinds of pattern matching.
Text mining also involves co-referencing, the identification of terms that refer to a similar object.
This is followed by Fact, Relationship or Event Extraction through which associations among
entities in a text is identified.
Sentiment analysis encompasses discernment of subjective material and extraction of various
levels of attitudinal information: mood, sentiment etc.(M. Kuhn & K. Johnson, 2013).
Quantitative text analysis involves techniques like social sciences, where either a computer or a
human judge/analyst extracts semantic relationships between text-data so as to find out the
stylistic patterns, meaning of a casual text that may be personal for the aim of psychological
profiling (Quinlan, 1996).
Text mining is the process of mining or deriving information of high quality from text
(Cousssement Kristof, et al., 2008). Such information is arrived at by devising trends and
patterns through means like statistical pattern learning.
In text mining, high quality refers to a combination of novelty or relevance. Text mining tasks
include sentiment analysis and document summarization. Data mining however is the process of
obtaining patterns in data sets (Han, et al., 2011). Overall goal of this is to extract relevant
information from a dataset and transform it into a structure that is understandable.
Data mining is a general process that includes text mining. However, data mining is the
extraction of relationships from structured data e.g., pie charts or tables whereas text mining
involves extraction of insights from a dataset.
Text retrieval processes range from a preparatory step to the final step of compiling the high-
quality information.
Information retrieval involves identifying and collecting a corpus in a database for analysis
(Pang Bo & Lee Lilian, 2002).
Text analytic systems apply natural language processing e.g., syntactic parsing and other forms
of linguistic analysis.
Named entity recognition involves statistical techniques, gazetteers etc. for identifying named
text features; abbreviations and stock ticker symbols (Quinlan, 1996).
Disambiguation involves use of clues that are contextual.
Recognition of Pattern Entities involves features like email addresses, telephone numbers, which
are discerned through regular expression or other kinds of pattern matching.
Text mining also involves co-referencing, the identification of terms that refer to a similar object.
This is followed by Fact, Relationship or Event Extraction through which associations among
entities in a text is identified.
Sentiment analysis encompasses discernment of subjective material and extraction of various
levels of attitudinal information: mood, sentiment etc.(M. Kuhn & K. Johnson, 2013).
Quantitative text analysis involves techniques like social sciences, where either a computer or a
human judge/analyst extracts semantic relationships between text-data so as to find out the
stylistic patterns, meaning of a casual text that may be personal for the aim of psychological
profiling (Quinlan, 1996).

Text mining is applied for a variety of research, business or government needs (S. B. Kotsiantis,
2007). Application categories include E-discovery and Enterprise Business Management.
2007). Application categories include E-discovery and Enterprise Business Management.

ARTIFICIAL INTELLIGENCE
1. Why artificial Intelligence is important for supporting business to build smart
systems.
Artificial intelligence is slowly changing the course of engineering in this century. Accuracy and
precision of artificial intelligence based systems has made companies make unimaginable returns
on investment (Ford Martin & Colvin Geoff, 2018). Artificial systems are reliable and not
subject to bias as in humans hence facts and figures presented using these software is the truth.
2. How artificial intelligence helps to transform companies
HANA analyses transaction data for trends. When used with supportive applications, decision
making is faster. Operational costs are saved enormously as anomalies in sales that could cause
losses is identified and appropriate resolution suggestions made. AIs make data-driven decisions
which are better informed. Walmart uses this software in its excess of 11,000 stores to monitor
transactions in real time (Mena Jesus, 2011).
A report sponsored by SAP gives a revelation, that companies incorporating their cloud platform,
HANA, expect an investment return higher than 575%.
Domo, another cloud based platform collects data from third-party platforms like Facebook,
Square, and uses that data to give insights and provide context to intelligence. By monitoring the
performance of the product at sales points, this AI spots rising trends in real-time and generates
reports on these trends, offering suggestions on action to take for improvement.
Apptus another AI, interestingly learns patterns of customers and enables them to purchase
products by automatically giving them suggestions on the products they search. It also
recommends actions to be taken to boost sales after analyzing the consumers’ preferences for
related products. Working using the same principle of predictive analytics is Avanade which is a
joint venture by Accenture and Microsoft leveraging on Cortana Intelligence Suite for data-based
insights (Witten Ian H & Frank Eibe, 2011).
General Electric’s Predix, working with industrial applications, processes historic performance
information of equipment and uses this data to predict operational outcomes i.e., when
equipment may fail. It still uses the principle of predictive analytics. By calculating the time an
equipment can work before maintenance and giving alerts on maintenance (Pang Bo & Lee
Lilian, 2002).
Siemens’ MindSphere like Predix monitors fleets of machines for service needs using drive train
analytics. Unlike Predix, it can work with machines from any manufacturer.
1. Why artificial Intelligence is important for supporting business to build smart
systems.
Artificial intelligence is slowly changing the course of engineering in this century. Accuracy and
precision of artificial intelligence based systems has made companies make unimaginable returns
on investment (Ford Martin & Colvin Geoff, 2018). Artificial systems are reliable and not
subject to bias as in humans hence facts and figures presented using these software is the truth.
2. How artificial intelligence helps to transform companies
HANA analyses transaction data for trends. When used with supportive applications, decision
making is faster. Operational costs are saved enormously as anomalies in sales that could cause
losses is identified and appropriate resolution suggestions made. AIs make data-driven decisions
which are better informed. Walmart uses this software in its excess of 11,000 stores to monitor
transactions in real time (Mena Jesus, 2011).
A report sponsored by SAP gives a revelation, that companies incorporating their cloud platform,
HANA, expect an investment return higher than 575%.
Domo, another cloud based platform collects data from third-party platforms like Facebook,
Square, and uses that data to give insights and provide context to intelligence. By monitoring the
performance of the product at sales points, this AI spots rising trends in real-time and generates
reports on these trends, offering suggestions on action to take for improvement.
Apptus another AI, interestingly learns patterns of customers and enables them to purchase
products by automatically giving them suggestions on the products they search. It also
recommends actions to be taken to boost sales after analyzing the consumers’ preferences for
related products. Working using the same principle of predictive analytics is Avanade which is a
joint venture by Accenture and Microsoft leveraging on Cortana Intelligence Suite for data-based
insights (Witten Ian H & Frank Eibe, 2011).
General Electric’s Predix, working with industrial applications, processes historic performance
information of equipment and uses this data to predict operational outcomes i.e., when
equipment may fail. It still uses the principle of predictive analytics. By calculating the time an
equipment can work before maintenance and giving alerts on maintenance (Pang Bo & Lee
Lilian, 2002).
Siemens’ MindSphere like Predix monitors fleets of machines for service needs using drive train
analytics. Unlike Predix, it can work with machines from any manufacturer.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

3. The thread of artificial intelligence and the limitations of smart systems
Current research companies are working on AIs that think like human beings, meaning they can
make improvements to their hardware or design hardware for other AIs. This could be the
beginning of extinction of the human race.
When data collected by machines like Apptus is accessed by other parties, it could sabotage the
company’s operations and violate consumers’ privacy.
Current research companies are working on AIs that think like human beings, meaning they can
make improvements to their hardware or design hardware for other AIs. This could be the
beginning of extinction of the human race.
When data collected by machines like Apptus is accessed by other parties, it could sabotage the
company’s operations and violate consumers’ privacy.

BANK DATA ANALYSIS USING WEKA (WAIKATO ENVIRONMENT FOR
KNOWLEDGE ANALYSIS) SOFTWARE
Data mining is an interdisciplinary subfield in computer science (Masys & R, 2001). It is a
process (computational) in discovering patterns in datasets.
Analysis type used for the dataset is the decision tree j48 classifier. It is the Weka
implementation of C4.5 algorithms, successor of ID3. Weka gives a visual representation of the
generated decision tree from the j48 algorithms. The basic algorithm for the decision tree is:
Beginning with the whole training data, which gives the maximum possible accuracy for
the data-set analysis.
Selecting attributes or values along the dimensions that will give the best split.
Creation of child nodes.
Recusing on every child node using the child data until a stopping criterion is reached.
This is known when the amount of data arrived at is too small, or when the class reached
is the same, or if the tree has become too large.
A decision tree is a recursive partition of instance space (M. Kuhn & K. Johnson, 2013). It
consists of nodes forming a rooted tree, meaning that it’s a directed tree having nodes called
“roots” which have no incoming edges. All other nodes only have one incoming node. Nodes
with outgoing edges are called internal nodes. All the other nodes are leaves, usually referred to
as decision nodes or terminals. Each internal node splits instant space into sub-spaces, usually
two or more, according to a specified discrete function of input attributes values.
The main challenge when building a decision tree comes on the decision on the attribute on
which to split data at a particular stage so as to get the best split. Information gain is used, which
is the difference between entropies before, and after the decision has been made. Entropy is the
measure of uncertainty that arises from a decision or some information. So, the attribute with the
highest amount of information gain is picked. In our case, it is the number of children.
The algorithms go ahead to build a fairly accurate decision tree by evaluating the attributes that
remain under the initial attribute (Number of children).
Whenever a number such as YES 124.0/3.0 appears, it means that the data has been correctly
classified 124 times and wrongly classified 3 times, or has a RIGHT to WRONG classification
ratio of 124.0/3.0.
KNOWLEDGE ANALYSIS) SOFTWARE
Data mining is an interdisciplinary subfield in computer science (Masys & R, 2001). It is a
process (computational) in discovering patterns in datasets.
Analysis type used for the dataset is the decision tree j48 classifier. It is the Weka
implementation of C4.5 algorithms, successor of ID3. Weka gives a visual representation of the
generated decision tree from the j48 algorithms. The basic algorithm for the decision tree is:
Beginning with the whole training data, which gives the maximum possible accuracy for
the data-set analysis.
Selecting attributes or values along the dimensions that will give the best split.
Creation of child nodes.
Recusing on every child node using the child data until a stopping criterion is reached.
This is known when the amount of data arrived at is too small, or when the class reached
is the same, or if the tree has become too large.
A decision tree is a recursive partition of instance space (M. Kuhn & K. Johnson, 2013). It
consists of nodes forming a rooted tree, meaning that it’s a directed tree having nodes called
“roots” which have no incoming edges. All other nodes only have one incoming node. Nodes
with outgoing edges are called internal nodes. All the other nodes are leaves, usually referred to
as decision nodes or terminals. Each internal node splits instant space into sub-spaces, usually
two or more, according to a specified discrete function of input attributes values.
The main challenge when building a decision tree comes on the decision on the attribute on
which to split data at a particular stage so as to get the best split. Information gain is used, which
is the difference between entropies before, and after the decision has been made. Entropy is the
measure of uncertainty that arises from a decision or some information. So, the attribute with the
highest amount of information gain is picked. In our case, it is the number of children.
The algorithms go ahead to build a fairly accurate decision tree by evaluating the attributes that
remain under the initial attribute (Number of children).
Whenever a number such as YES 124.0/3.0 appears, it means that the data has been correctly
classified 124 times and wrongly classified 3 times, or has a RIGHT to WRONG classification
ratio of 124.0/3.0.

Ten-fold cross validation with 15 minimum number of objects gives a fairly accurate and
realistic tree (M. Kuhn & K. Johnson, 2013). The training set will give a more accurate analysis
as it analyses the data based on all of the attributes. However, the tree in such a case is too long
and hard to follow through.
Figure 1 Attributes and Decision Tree
realistic tree (M. Kuhn & K. Johnson, 2013). The training set will give a more accurate analysis
as it analyses the data based on all of the attributes. However, the tree in such a case is too long
and hard to follow through.
Figure 1 Attributes and Decision Tree
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Figure 2 Continuation of decision tree
Figure 3 Confusion matrix, continuation of decision tree
The confusion matrix gives the number of times an evaluation was done correctly, in this case
245 times, while 29 is the number of times an error is made.
Figure 3 Confusion matrix, continuation of decision tree
The confusion matrix gives the number of times an evaluation was done correctly, in this case
245 times, while 29 is the number of times an error is made.

Figure 4 Decision tree visualization
The above decision tree generated has children as the initial attribute (Ramiro H Galvez &
Agustin Gravano, 2017). If the number of children is less or equal to 1, it splits the attribute into
two, married and income, based on low entropy; married when number of children is equal to or
less than 0, and income when number of children is greater than 0 but less than 1. Income
attribute is stopped at the comparison of the amount, where income less than or equal to 15538.8
has a RIGHT to WRONG classification ratio of 24.0/4.0, and income greater than 15538.8 has a
RIGHT to WRONG classification ratio of 111.0/5.0.
Under married attribute, if the return is a YES, then save_act attribute is chosen. If the return is a
NO, mortgage attribute is chosen. The save_act attribute is further split into having savings or
not. In the case of a YES return, there is a WRONG to RIGHT classification ratio of 119.0/12.0.
If a NO return is the case, then mortgage attribute is chosen, which is split into whether one has a
mortgage or not. The NO return has a WRONG to RIGHT classification ratio of 36.0/5.0 and a
RIGHT to WRONG classification ratio of 25.0/3.0. Under mortgage attribute, which a result of
the split of married attribute, NO has a RIGHT to WRONG classification ratio of 48.0/3.0. If one
has mortgage, in which case the return is a YES, the lowest entropy attribute chosen is age. Age
of less than or equal to 40 has a RIGHT to WRONG classification ratio of 19.0/8.0 while that
greater than 40 has a WRONG to RIGHT classification ratio of 16.0/1.0.
Back to the initial attribute, for those with a number children greater than 1, the next attribute is
income. Income less or equal to 30404.3 has a WRONG to RIGHT classification ratio of
The above decision tree generated has children as the initial attribute (Ramiro H Galvez &
Agustin Gravano, 2017). If the number of children is less or equal to 1, it splits the attribute into
two, married and income, based on low entropy; married when number of children is equal to or
less than 0, and income when number of children is greater than 0 but less than 1. Income
attribute is stopped at the comparison of the amount, where income less than or equal to 15538.8
has a RIGHT to WRONG classification ratio of 24.0/4.0, and income greater than 15538.8 has a
RIGHT to WRONG classification ratio of 111.0/5.0.
Under married attribute, if the return is a YES, then save_act attribute is chosen. If the return is a
NO, mortgage attribute is chosen. The save_act attribute is further split into having savings or
not. In the case of a YES return, there is a WRONG to RIGHT classification ratio of 119.0/12.0.
If a NO return is the case, then mortgage attribute is chosen, which is split into whether one has a
mortgage or not. The NO return has a WRONG to RIGHT classification ratio of 36.0/5.0 and a
RIGHT to WRONG classification ratio of 25.0/3.0. Under mortgage attribute, which a result of
the split of married attribute, NO has a RIGHT to WRONG classification ratio of 48.0/3.0. If one
has mortgage, in which case the return is a YES, the lowest entropy attribute chosen is age. Age
of less than or equal to 40 has a RIGHT to WRONG classification ratio of 19.0/8.0 while that
greater than 40 has a WRONG to RIGHT classification ratio of 16.0/1.0.
Back to the initial attribute, for those with a number children greater than 1, the next attribute is
income. Income less or equal to 30404.3 has a WRONG to RIGHT classification ratio of

124.0/12.0. Income greater than 30404.3 is further split into whether the number of children is
less than or equal to 2, or greater than 2. For the latter case, the RIGHT to WRONG
classification ratio is 51.0/5.0 while the former case has a NO to YES ratio of27.0/10.0.
CONCLUSION
Individuals with no children more likely have an income of over 15538.8. Some of the married
individuals have savings while those with no savings have no mortgage. Those who are not
married are not likely to have mortgage, and when evaluated considering age of 40; greater, less
or same as 40 years, those at the age of 40 or less than 40 have mortgages.
Individuals with children have an income of more than 30404.3, most of them having at most 2
children.
less than or equal to 2, or greater than 2. For the latter case, the RIGHT to WRONG
classification ratio is 51.0/5.0 while the former case has a NO to YES ratio of27.0/10.0.
CONCLUSION
Individuals with no children more likely have an income of over 15538.8. Some of the married
individuals have savings while those with no savings have no mortgage. Those who are not
married are not likely to have mortgage, and when evaluated considering age of 40; greater, less
or same as 40 years, those at the age of 40 or less than 40 have mortgages.
Individuals with children have an income of more than 30404.3, most of them having at most 2
children.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
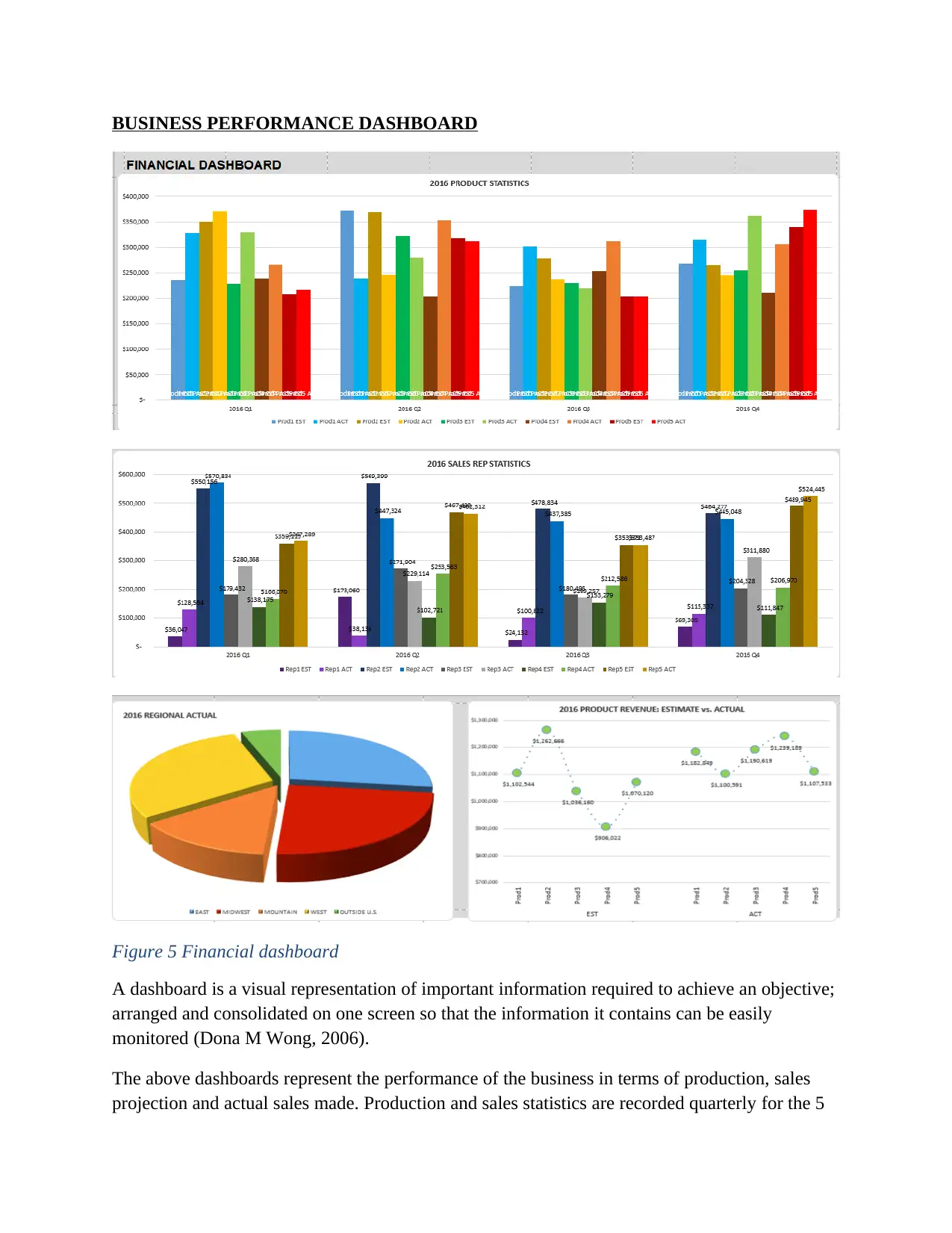
BUSINESS PERFORMANCE DASHBOARD
Figure 5 Financial dashboard
A dashboard is a visual representation of important information required to achieve an objective;
arranged and consolidated on one screen so that the information it contains can be easily
monitored (Dona M Wong, 2006).
The above dashboards represent the performance of the business in terms of production, sales
projection and actual sales made. Production and sales statistics are recorded quarterly for the 5
Figure 5 Financial dashboard
A dashboard is a visual representation of important information required to achieve an objective;
arranged and consolidated on one screen so that the information it contains can be easily
monitored (Dona M Wong, 2006).
The above dashboards represent the performance of the business in terms of production, sales
projection and actual sales made. Production and sales statistics are recorded quarterly for the 5

products using bar graphs. Estimated sales are compared to the actual sales using sales curves.
Regional performance of the products is also captured on a pie chart.
The estimated and actual sales curves illustrate the good performance of the business as most of
the target sales are made and exceeded. It’s only product 2 that falls short of its projected sales
target. All the graphs show the estimated and actual production (first graph) and sales (second
and third graphs) (Steven Faw, 2006).
The dashboard above is for analytical purposes (Steven Faw, 2006). It has greater context in
terms of subtle performance evaluators, rich comparisons and extensive history. It is simple in
design and easy to understand and can also be used by savvy technical users like researchers and
data analysts.
However, the preoccupation with functionally and superficially distracting visual features on the
dashboard has undermined its usefulness (Tufte, 2003). Color has been grossly misused on the
production dashboard, it is too bright.
There is excessive precision on the data represented. Too much precision or showing exact
values as they are, slows the viewer down with little benefit. For example, using figures like
$1,670,824 instead of $1.6M (Dona M Wong, 2006).
For comparison purposes, it would have been better if a percentage deviation is given, between
the projected value of sales and the actual sales made (Tufte, 2003). This is not provided for in
the dashboard example above.
References
Regional performance of the products is also captured on a pie chart.
The estimated and actual sales curves illustrate the good performance of the business as most of
the target sales are made and exceeded. It’s only product 2 that falls short of its projected sales
target. All the graphs show the estimated and actual production (first graph) and sales (second
and third graphs) (Steven Faw, 2006).
The dashboard above is for analytical purposes (Steven Faw, 2006). It has greater context in
terms of subtle performance evaluators, rich comparisons and extensive history. It is simple in
design and easy to understand and can also be used by savvy technical users like researchers and
data analysts.
However, the preoccupation with functionally and superficially distracting visual features on the
dashboard has undermined its usefulness (Tufte, 2003). Color has been grossly misused on the
production dashboard, it is too bright.
There is excessive precision on the data represented. Too much precision or showing exact
values as they are, slows the viewer down with little benefit. For example, using figures like
$1,670,824 instead of $1.6M (Dona M Wong, 2006).
For comparison purposes, it would have been better if a percentage deviation is given, between
the projected value of sales and the actual sales made (Tufte, 2003). This is not provided for in
the dashboard example above.
References

Dona M Wong, 2006. The Wall Street Journal Guide to Information Graphics. 1st ed. Arkansas: s.n.
Eckerson, W. W., 2010. Performance Dashboards: Measuring, Monitoring and Managing your Business.
s.l.:Wiley.
Fayyad, Piatetsky-Shapiro & Padhraic, 1996. From Data Mining to Knowledge Discovery in Database.
s.l.:Smyth and Co..
Ford Martin, F. & Colvin Geoff, 2018. Will robots create more jobs than they destroy. s.l.:s.n.
Han, Kamber, Pei & Jaiwei, 2011. Data Mining: Concepts and techniques. s.l.:s.n.
M. Kuhn & K. Johnson, 2013. Applied Predictive Modelling. s.l.:Springer.
Masys & R, D., 2001. Linking microarray data to the literature. Nature Genetics, pp. 9-10.
Mena Jesus, 2011. Machine Learning Forensics for Law Enforcement, Security and Intelligence. Boca
Raton: CRC Press (Taylor and Francis Group).
Pang Bo & Lee Lilian, 2002. Proceedings of the ACL-02 conference on empirical methods in natural
language processing. pp. 79-86.
Quinlan J. R., 1993. Programs for Machine Learning. s.l.:Morgan Kaufmann Publishers .
Quinlan, J. R., 1996. Improved use of continuous attributes in C4.5. Journal of Artificial Intelligence
Research, pp. 77-90.
Ramiro H Galvez & Agustin Gravano, 2017. Assessing the usefulness of online message board mining in
automatic stock prediction systems. Journal of Computational Sciences, pp. 1877-7503.
S. B. Kotsiantis, 2007. Supervised Machine Learning: A review of classification techniques. Informatica,
pp. 249-268.
Steven Faw, 2006. Information Dashboard Design: The effective Visual Communication of Data.
s.l.:O'Reilly.
Tufte, E., 2003. Envisioning Information, The Visual Display of Quantitative Information, and Beautiful
Evidence. 2nd ed. New york: s.n.
Witten Ian H & Frank Eibe, 2011. Data Mining: Practical Machine Learning Tools and Techniques.
Waikato: Elsevier.
Eckerson, W. W., 2010. Performance Dashboards: Measuring, Monitoring and Managing your Business.
s.l.:Wiley.
Fayyad, Piatetsky-Shapiro & Padhraic, 1996. From Data Mining to Knowledge Discovery in Database.
s.l.:Smyth and Co..
Ford Martin, F. & Colvin Geoff, 2018. Will robots create more jobs than they destroy. s.l.:s.n.
Han, Kamber, Pei & Jaiwei, 2011. Data Mining: Concepts and techniques. s.l.:s.n.
M. Kuhn & K. Johnson, 2013. Applied Predictive Modelling. s.l.:Springer.
Masys & R, D., 2001. Linking microarray data to the literature. Nature Genetics, pp. 9-10.
Mena Jesus, 2011. Machine Learning Forensics for Law Enforcement, Security and Intelligence. Boca
Raton: CRC Press (Taylor and Francis Group).
Pang Bo & Lee Lilian, 2002. Proceedings of the ACL-02 conference on empirical methods in natural
language processing. pp. 79-86.
Quinlan J. R., 1993. Programs for Machine Learning. s.l.:Morgan Kaufmann Publishers .
Quinlan, J. R., 1996. Improved use of continuous attributes in C4.5. Journal of Artificial Intelligence
Research, pp. 77-90.
Ramiro H Galvez & Agustin Gravano, 2017. Assessing the usefulness of online message board mining in
automatic stock prediction systems. Journal of Computational Sciences, pp. 1877-7503.
S. B. Kotsiantis, 2007. Supervised Machine Learning: A review of classification techniques. Informatica,
pp. 249-268.
Steven Faw, 2006. Information Dashboard Design: The effective Visual Communication of Data.
s.l.:O'Reilly.
Tufte, E., 2003. Envisioning Information, The Visual Display of Quantitative Information, and Beautiful
Evidence. 2nd ed. New york: s.n.
Witten Ian H & Frank Eibe, 2011. Data Mining: Practical Machine Learning Tools and Techniques.
Waikato: Elsevier.
1 out of 13





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.