Intrusion Detection using WEKA Data Analytics Technique
VerifiedAdded on 2022/11/26
|12
|2158
|211
AI Summary
This paper discusses the use of WEKA data analytics technique for intrusion detection and examines the performance of Random Forest and Logistic Regression algorithms. The dataset used is collected from U2R and R2L attacks on networks. The results show that Random Forest outperforms Logistic Regression in terms of classification accuracy, precision, and recall.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Introduction
Background
Over the years, firms have had to deal with cyber threats such as ransomwares. However, as of
2017 new threats begun to emerge and did so in a fast rate which saw the introduction of threats
such as Cryptojacking which was motivated with the popularity of the cryptocurrency where
business computers are hacked to be used for mining cryptocurrency [1]. Other threats include:
Internet of Things (IoT) device threats, Geopolitical risks, Cross-site scripting, and Mobile
malware. With the increasing number of threats to the cyber protection of organizations, the
issue of how to protect company resources such as data, finances, intrusion, etcetera remains of
concern to business executives. An article written in 2018 suggests security analytics as a
solution to cyber threats. “…Security Analytics is an approach to cybersecurity focused on the
analysis of data to produce proactive security measures.” [2]. The whole point of security
analytics lies in its ability to enable the transition from protection to detection and provide a
unified view of the enterprise which offers the firm a means through which to detect external
threats and gather intelligence [2].
Objective
In this paper, we will conduct intrusion detection using WEKA data analytic technique to
examine the intelligent security solutions based on data analytics and report on our findings.
Data analytics tools and techniques
Data analytic tools
We will be using the WEKA tool on windows 10 which is basically a standard Java tool used in
performing both machine learning experiments as well as embedding trained models in Java
Background
Over the years, firms have had to deal with cyber threats such as ransomwares. However, as of
2017 new threats begun to emerge and did so in a fast rate which saw the introduction of threats
such as Cryptojacking which was motivated with the popularity of the cryptocurrency where
business computers are hacked to be used for mining cryptocurrency [1]. Other threats include:
Internet of Things (IoT) device threats, Geopolitical risks, Cross-site scripting, and Mobile
malware. With the increasing number of threats to the cyber protection of organizations, the
issue of how to protect company resources such as data, finances, intrusion, etcetera remains of
concern to business executives. An article written in 2018 suggests security analytics as a
solution to cyber threats. “…Security Analytics is an approach to cybersecurity focused on the
analysis of data to produce proactive security measures.” [2]. The whole point of security
analytics lies in its ability to enable the transition from protection to detection and provide a
unified view of the enterprise which offers the firm a means through which to detect external
threats and gather intelligence [2].
Objective
In this paper, we will conduct intrusion detection using WEKA data analytic technique to
examine the intelligent security solutions based on data analytics and report on our findings.
Data analytics tools and techniques
Data analytic tools
We will be using the WEKA tool on windows 10 which is basically a standard Java tool used in
performing both machine learning experiments as well as embedding trained models in Java
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

applications. Weka therefore is the best tool for us based on our research objectives which
intends to perform intrusion detection and given the wide usage of java applications in
technological products including operating systems [3].
Data analytics techniques
Our main focus is to compare different intrusion detection methods. Our objective is to classify
an activity as either normal or an anomaly, which makes it a binary problem that can be tackled
using classification techniques or prediction. As such, we will use Random Forest and Logistic
regression machine learning algorithms.
Random Forest
One of the best algorithms in classical machine learning is the random forest model which
according to the words of Niklas Donges is, “a flexible, easy to use machine learning algorithm
that produces, even without hyper-parameter tuning, a great result most of the time.” [4].
Classified under supervised learning algorithms, the Random Forest follows a simple application
which can be summarized as building multiple decision trees then merging them to obtain more
accurate and stable prediction results [4].
Perhaps the biggest merit of this algorithm is the fact that it can be used for both prediction and
regression problems making it suitable when the objective is to determine how different
predictor attributes affect a response attribute and how different attributes are grouped together.
Since decision trees are developed using the greedy algorithm which selects an optimum split
over each split process, the Random forest is an improvement of bagged decision trees and
disrupts the greedy splitting algorithm. When applying the model to our data, our main focus will
lie on the number of attributes we use for each split point.
intends to perform intrusion detection and given the wide usage of java applications in
technological products including operating systems [3].
Data analytics techniques
Our main focus is to compare different intrusion detection methods. Our objective is to classify
an activity as either normal or an anomaly, which makes it a binary problem that can be tackled
using classification techniques or prediction. As such, we will use Random Forest and Logistic
regression machine learning algorithms.
Random Forest
One of the best algorithms in classical machine learning is the random forest model which
according to the words of Niklas Donges is, “a flexible, easy to use machine learning algorithm
that produces, even without hyper-parameter tuning, a great result most of the time.” [4].
Classified under supervised learning algorithms, the Random Forest follows a simple application
which can be summarized as building multiple decision trees then merging them to obtain more
accurate and stable prediction results [4].
Perhaps the biggest merit of this algorithm is the fact that it can be used for both prediction and
regression problems making it suitable when the objective is to determine how different
predictor attributes affect a response attribute and how different attributes are grouped together.
Since decision trees are developed using the greedy algorithm which selects an optimum split
over each split process, the Random forest is an improvement of bagged decision trees and
disrupts the greedy splitting algorithm. When applying the model to our data, our main focus will
lie on the number of attributes we use for each split point.

Logistic Regression
Logistic regression is a machine learning classification algorithm adopted when the problem
involves the need to “…assign observations to a discrete set of classes” [5] in which the outcome
is either binary or dichotomous. The objective of a logistic regression model is to explain the
relationship between the response (outcome) and explanatory variables. A logistic model follows
the formula:
Where p is the probability that the characteristic of interest is present. In addition, the models
logit transformation is defined as:
And
The problem with logistic regression is that it is not a very good classifier even though it is a
good prediction algorithm.
Data
To address our research objective, we will use observations on U2R and R2L attacks on
networks which was collected in 2009 for application in Computational Intelligence for Security
and Defense Applications [6]. The dataset which is divided into training and test set is stored
under ARFF and text formats and can obtained from https://www.unb.ca/cic/datasets/nsl.html.
Logistic regression is a machine learning classification algorithm adopted when the problem
involves the need to “…assign observations to a discrete set of classes” [5] in which the outcome
is either binary or dichotomous. The objective of a logistic regression model is to explain the
relationship between the response (outcome) and explanatory variables. A logistic model follows
the formula:
Where p is the probability that the characteristic of interest is present. In addition, the models
logit transformation is defined as:
And
The problem with logistic regression is that it is not a very good classifier even though it is a
good prediction algorithm.
Data
To address our research objective, we will use observations on U2R and R2L attacks on
networks which was collected in 2009 for application in Computational Intelligence for Security
and Defense Applications [6]. The dataset which is divided into training and test set is stored
under ARFF and text formats and can obtained from https://www.unb.ca/cic/datasets/nsl.html.

Data Analytic for Network Intrusion Detection
In this section we carry out the tasks specified in the requirements file and report on our findings.
Which will include: discussion on the data file format, feature selection for our two algorithms,
creation of training and testing sets if necessary and finally implementation of the models and
examining their performance.
Text and ARFF file formats
As the name suggests, a text file contains textual information. Our focus is on our file which is
stored in a .txt extension, commonly used to store information which is intended to be opened by
a wide range of different other applications. On the other hand, an Attribute-Relation File Format
(ARFF) is an ASCII text file used to describe a list of instances that share a set of attributes [7].
ARFF files are often the default files in WEKA and since we already have our data file in the
ARFF format, there is no need for conversion.
To conduct our analysis, we follow the following steps:
In this section we carry out the tasks specified in the requirements file and report on our findings.
Which will include: discussion on the data file format, feature selection for our two algorithms,
creation of training and testing sets if necessary and finally implementation of the models and
examining their performance.
Text and ARFF file formats
As the name suggests, a text file contains textual information. Our focus is on our file which is
stored in a .txt extension, commonly used to store information which is intended to be opened by
a wide range of different other applications. On the other hand, an Attribute-Relation File Format
(ARFF) is an ASCII text file used to describe a list of instances that share a set of attributes [7].
ARFF files are often the default files in WEKA and since we already have our data file in the
ARFF format, there is no need for conversion.
To conduct our analysis, we follow the following steps:
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
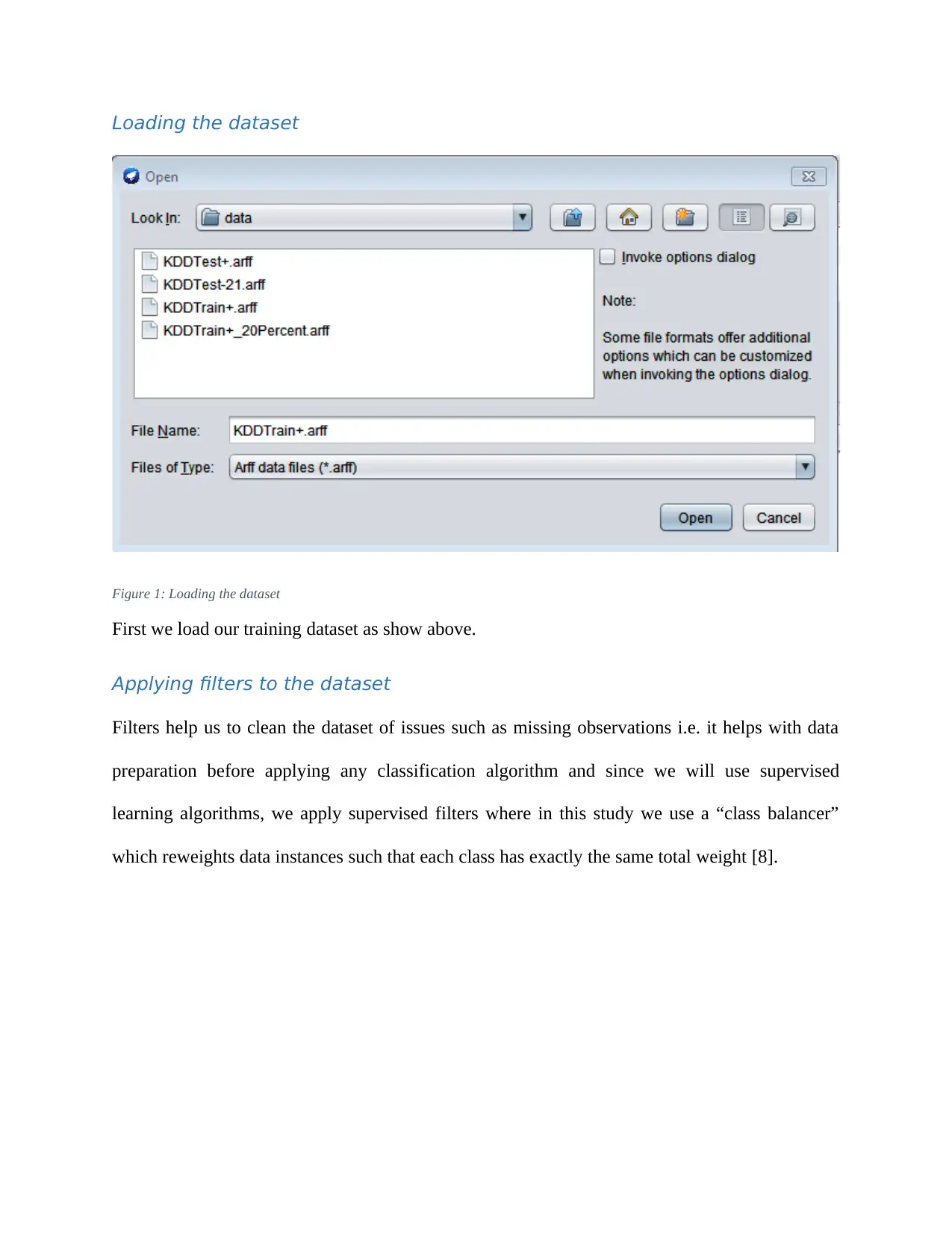
Loading the dataset
Figure 1: Loading the dataset
First we load our training dataset as show above.
Applying filters to the dataset
Filters help us to clean the dataset of issues such as missing observations i.e. it helps with data
preparation before applying any classification algorithm and since we will use supervised
learning algorithms, we apply supervised filters where in this study we use a “class balancer”
which reweights data instances such that each class has exactly the same total weight [8].
Figure 1: Loading the dataset
First we load our training dataset as show above.
Applying filters to the dataset
Filters help us to clean the dataset of issues such as missing observations i.e. it helps with data
preparation before applying any classification algorithm and since we will use supervised
learning algorithms, we apply supervised filters where in this study we use a “class balancer”
which reweights data instances such that each class has exactly the same total weight [8].
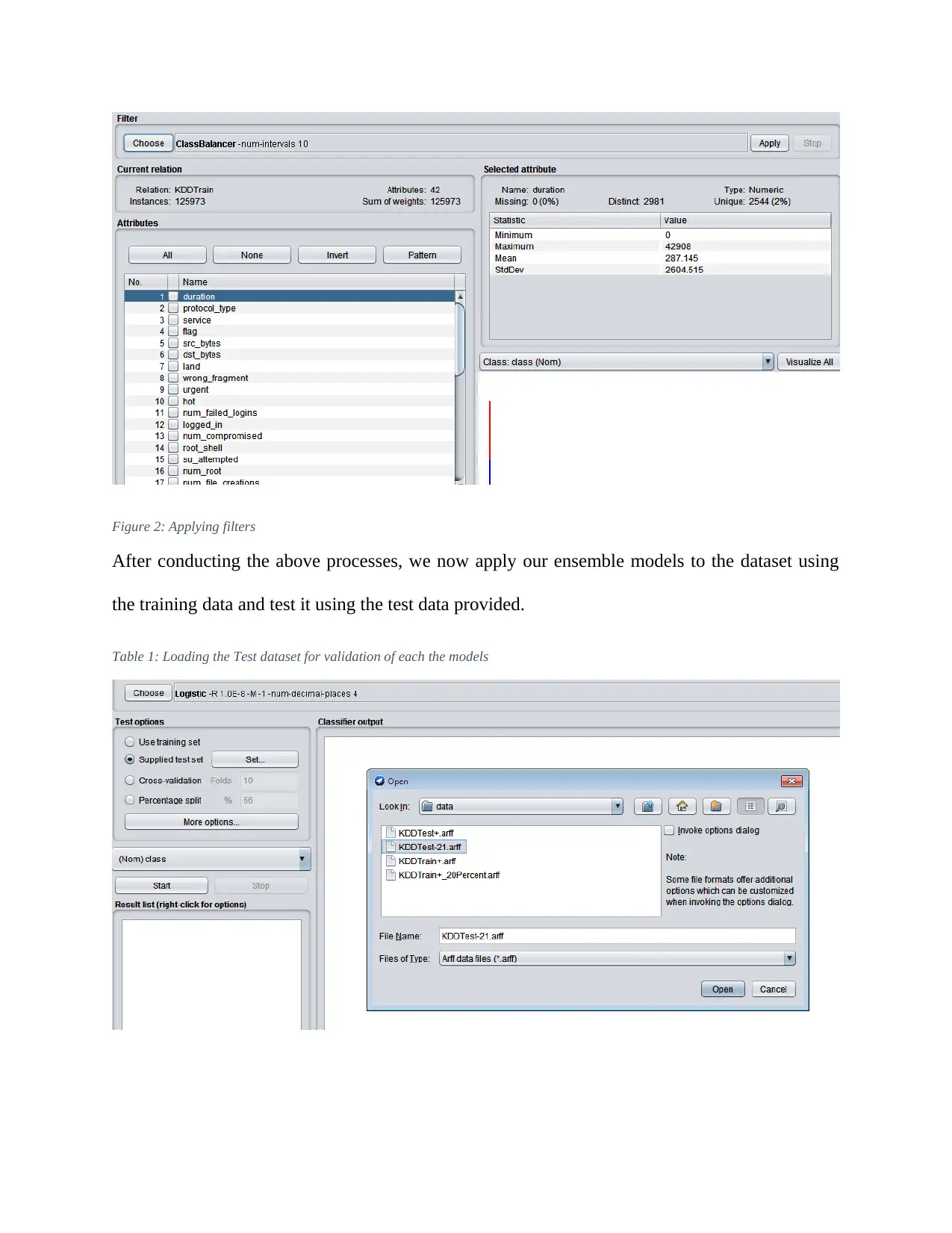
Figure 2: Applying filters
After conducting the above processes, we now apply our ensemble models to the dataset using
the training data and test it using the test data provided.
Table 1: Loading the Test dataset for validation of each the models
After conducting the above processes, we now apply our ensemble models to the dataset using
the training data and test it using the test data provided.
Table 1: Loading the Test dataset for validation of each the models

Results
Features
Network activities can either fall into normal or anomalous categories. According to an article
in Network World, the main focus leading to the mastering and securing of data is understanding
the features of anomalous network activities [9]. The features used in this paper are drawn from
those suggested at the time of data collection to define network activities.
Logistic regression
Table 2: Logistic regression performance metrics
From table 1 it is noted that there are only two classes in the data. From the table, we can analyze
the performance of the logistic regression intrusion detection method as follows:
The model has a classification accuracy of 97.5558% and incorrectly classifies 615.7312
instances. In addition, the model’s RMSE is 0.0366 which is relatively low indicating that the
Features
Network activities can either fall into normal or anomalous categories. According to an article
in Network World, the main focus leading to the mastering and securing of data is understanding
the features of anomalous network activities [9]. The features used in this paper are drawn from
those suggested at the time of data collection to define network activities.
Logistic regression
Table 2: Logistic regression performance metrics
From table 1 it is noted that there are only two classes in the data. From the table, we can analyze
the performance of the logistic regression intrusion detection method as follows:
The model has a classification accuracy of 97.5558% and incorrectly classifies 615.7312
instances. In addition, the model’s RMSE is 0.0366 which is relatively low indicating that the
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

model has very few errors. Moreover, the precision (how well the model predicts true positives),
true positive (the values predicted as positive and are actually positive) and recall (how well the
model can repeat the same results if implemented again) have a score of 97%, 98.1%, and 98.1%
respectively.
The confusion matrix indicates that 236.02 instances of normal network activities were classified
under anomalies when they were not anomalies and 379.71 instances of anomalous behavior was
classified under normal behavior when they were actually anomalies.
Random Forest
Table 3: Random Forest intrusion detection method
We report the same statistics as the ones in the Logistic regression so that we can compare the
performance of the two models fairly. The confusion matrix in table 2 indicates that only 0.94
instances of normal activities were classified under anomalies and no anomalous behavior was
true positive (the values predicted as positive and are actually positive) and recall (how well the
model can repeat the same results if implemented again) have a score of 97%, 98.1%, and 98.1%
respectively.
The confusion matrix indicates that 236.02 instances of normal network activities were classified
under anomalies when they were not anomalies and 379.71 instances of anomalous behavior was
classified under normal behavior when they were actually anomalies.
Random Forest
Table 3: Random Forest intrusion detection method
We report the same statistics as the ones in the Logistic regression so that we can compare the
performance of the two models fairly. The confusion matrix in table 2 indicates that only 0.94
instances of normal activities were classified under anomalies and no anomalous behavior was

classified as normal. In addition, we not that, the Random Forest’s accuracy is 99.9963% with a
TP rate 0f 100%, a precision of 100%, and a recall of 100%.
Discussion
Overfitting
Random forests are grouped under the best classifiers due to their ability to handle the problem
of overfitting when increasing the number of trees. Generally, ensemble methods minimize
prediction variance to almost zero thus improving the models performance as in the case of
Random Forests [4]. In Logistic regression, over fitting is quite an issue where the model
performs well on training set but poorly on test set. Overfitting can be handle and was handled
by regularization which is used to handle collinearity, filters out the noise from the data hence
preventing overfitting [10].
Comparison of the Models and Recommendation
From our results section, the Random Forest has the best performance with a classification
accuracy of 99.9963% compared to that of the logistic regression of 97.5558%. Since the
classification accuracy can be misleading, examining the precision and recall of the models, the
Random Forest still outperforms the Logistic regression model. As such, we recommend the use
of Random Forest ensemble method for analysis in intrusion detection.
Future Work
Intrusion detection is an interesting field. Coupled with the ever developing networks
frameworks such as the current 4.5G and the recently proposed 5G network pioneered by
technology firms such as Huawei and Samsung, the relevance of intrusion detection will always
be relevant if firms are to keep their security tight. Given time and resources, this study proposes
TP rate 0f 100%, a precision of 100%, and a recall of 100%.
Discussion
Overfitting
Random forests are grouped under the best classifiers due to their ability to handle the problem
of overfitting when increasing the number of trees. Generally, ensemble methods minimize
prediction variance to almost zero thus improving the models performance as in the case of
Random Forests [4]. In Logistic regression, over fitting is quite an issue where the model
performs well on training set but poorly on test set. Overfitting can be handle and was handled
by regularization which is used to handle collinearity, filters out the noise from the data hence
preventing overfitting [10].
Comparison of the Models and Recommendation
From our results section, the Random Forest has the best performance with a classification
accuracy of 99.9963% compared to that of the logistic regression of 97.5558%. Since the
classification accuracy can be misleading, examining the precision and recall of the models, the
Random Forest still outperforms the Logistic regression model. As such, we recommend the use
of Random Forest ensemble method for analysis in intrusion detection.
Future Work
Intrusion detection is an interesting field. Coupled with the ever developing networks
frameworks such as the current 4.5G and the recently proposed 5G network pioneered by
technology firms such as Huawei and Samsung, the relevance of intrusion detection will always
be relevant if firms are to keep their security tight. Given time and resources, this study proposes

to conduct research on the relationship between reported cases of successful network intrusion
and the development of new networks so as to determine if security is a key component of new
of new featured networks. This way we will determine the growth trends of issues such as
unethical hacking. Our research outcomes are projected to form a basis of policy formulation by
firms to ensure network development firms put in place strategic measures to ensure top-notch
security features in their products depending on our results.
and the development of new networks so as to determine if security is a key component of new
of new featured networks. This way we will determine the growth trends of issues such as
unethical hacking. Our research outcomes are projected to form a basis of policy formulation by
firms to ensure network development firms put in place strategic measures to ensure top-notch
security features in their products depending on our results.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

References
[1] A. DeNisco-Rayome, "Five emerging cybersecurity threats you should take very seriously
in 2019," ZedNet, 15 February 2019. [Online]. Available:
https://www.zdnet.com/article/five-emerging-cybersecurity-threats-you-should-take-very-
seriously-in-2019/. [Accessed 22 May 2019].
[2] CYBER EDU, "What is Security Analytics?," Force Point, 26 June 2018. [Online].
Available: https://www.forcepoint.com/cyber-edu/security-analytics. [Accessed 22 May
2019].
[3] T. Emara, "How to use Weka in your Java code," Emaraic, 2 July 2017. [Online].
Available: http://www.emaraic.com/blog/weka-java-example. [Accessed 22 May 2019].
[4] N. Donges, "The Random Forest Algorithm," Towards Data Science, 22 February 2018.
[Online]. Available: https://towardsdatascience.com/the-random-forest-algorithm-
d457d499ffcd. [Accessed 22 May 2019].
[5] Machine Learning, "Logistic Regression," Read the Docs, 12 April 2017. [Online].
Available: https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html.
[Accessed 22 May 2019].
[6] M. Tavallaee, E. Bagheri, W. Lu and A. Ghorbani, "A Detailed Analysis of the KDD CUP
99 Data Set," in econd IEEE Symposium on Computational Intelligence for Security and
[1] A. DeNisco-Rayome, "Five emerging cybersecurity threats you should take very seriously
in 2019," ZedNet, 15 February 2019. [Online]. Available:
https://www.zdnet.com/article/five-emerging-cybersecurity-threats-you-should-take-very-
seriously-in-2019/. [Accessed 22 May 2019].
[2] CYBER EDU, "What is Security Analytics?," Force Point, 26 June 2018. [Online].
Available: https://www.forcepoint.com/cyber-edu/security-analytics. [Accessed 22 May
2019].
[3] T. Emara, "How to use Weka in your Java code," Emaraic, 2 July 2017. [Online].
Available: http://www.emaraic.com/blog/weka-java-example. [Accessed 22 May 2019].
[4] N. Donges, "The Random Forest Algorithm," Towards Data Science, 22 February 2018.
[Online]. Available: https://towardsdatascience.com/the-random-forest-algorithm-
d457d499ffcd. [Accessed 22 May 2019].
[5] Machine Learning, "Logistic Regression," Read the Docs, 12 April 2017. [Online].
Available: https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html.
[Accessed 22 May 2019].
[6] M. Tavallaee, E. Bagheri, W. Lu and A. Ghorbani, "A Detailed Analysis of the KDD CUP
99 Data Set," in econd IEEE Symposium on Computational Intelligence for Security and

Defense Applications (CISDA), Verona, 2009.
[7] Waikato, "Attribute-Relation File Format (ARFF)," University of Waikato, 1 November
2008. [Online]. Available: https://www.cs.waikato.ac.nz/~ml/weka/arff.html. [Accessed 22
May 2019].
[8] Waikato, "Class ClassBalancer," The University of Waikato, 12 June 2009. [Online].
Available: http://weka.sourceforge.net/doc.dev/weka/filters/supervised/instance/
ClassBalancer.html. [Accessed 22 May 2019].
[9] P. MeLampy, "Netwroking Anomalies," Network World, 9 July 2018. [Online]. Available:
https://www.networkworld.com/article/3284939/networking-anomalies.html. [Accessed 22
May 2019].
[10] B. T, "LOGISTIC REGRESSION, OVERFITTING & REGULARIZATION,"
BogoToBogo, 23 August 2015. [Online]. Available:
https://www.bogotobogo.com/python/scikit-learn/scikit-learn_logistic_regression.php.
[Accessed 22 May 2019].
[7] Waikato, "Attribute-Relation File Format (ARFF)," University of Waikato, 1 November
2008. [Online]. Available: https://www.cs.waikato.ac.nz/~ml/weka/arff.html. [Accessed 22
May 2019].
[8] Waikato, "Class ClassBalancer," The University of Waikato, 12 June 2009. [Online].
Available: http://weka.sourceforge.net/doc.dev/weka/filters/supervised/instance/
ClassBalancer.html. [Accessed 22 May 2019].
[9] P. MeLampy, "Netwroking Anomalies," Network World, 9 July 2018. [Online]. Available:
https://www.networkworld.com/article/3284939/networking-anomalies.html. [Accessed 22
May 2019].
[10] B. T, "LOGISTIC REGRESSION, OVERFITTING & REGULARIZATION,"
BogoToBogo, 23 August 2015. [Online]. Available:
https://www.bogotobogo.com/python/scikit-learn/scikit-learn_logistic_regression.php.
[Accessed 22 May 2019].
1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.