K-means Algorithm and Data Mining Techniques Report
VerifiedAdded on 2020/05/11
|12
|2824
|58
Report
AI Summary
This report provides a detailed analysis of the K-means algorithm within the context of data mining. It begins with an executive summary highlighting the algorithm's significance in clustering large datasets, its simple mechanism, and its applications in pattern identification and data segmentation. The introduction explains the algorithm's iterative nature, partitioning approach, and its importance in various fields like optical character recognition and biometrics. The report outlines the steps involved in K-means clustering, including initialization, classification, centroid calculation, and convergence criteria. A literature review explores existing research on K-means, its advantages, such as speed and ease of understanding, and disadvantages, such as the need to specify the number of clusters. The methodology section details the application of the K-means algorithm using the MATLAB function and the Iris plant dataset, including experimental setup, and results, such as time complexity and the sum of distances. The report concludes with a discussion of the algorithm's performance and its relevance in data mining.

K-means algorithm in Data Mining 1
K-MEANS ALGORITHM IN DATA MINING
By
Course:
Tutor:
University:
Date:
K-MEANS ALGORITHM IN DATA MINING
By
Course:
Tutor:
University:
Date:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

2
Executive summary
K-means is one of the most popular set of rules or procedures. It is actually perpetuated by its
austerity and consistency in the field of data mining (Cui 2014). Its trails a very naive and
relatively simple mechanisms to organize data sets over guaranteed sum of cluster. Processing of
large-scale data using k-means algorithm helps in grouping of related observations without any
prior knowledge of the relationships. It actually selects K points as the beginning cluster centers.
It is useful in identification of patterns of large volumes of data. Clustering is also very
important in exploration of data, detection and maybe informed ways of how to handle
anomalies, and some aspects of data segmentation. Interpreting of various clusters can be
difficult and certain algorithms can be very useful in the course of this particularly.
Clustering is very fundamental for instance in certain particular issues such as building of
regulatory networks, discovery of the various subtypes of a disease in medicine, maybe inferring
of unknown gene functions in medicine as well and reduction of dimensionality.
The objective of the project is to get generous outcome while giving accreditation of the
disclosure of data. K-means cluster algorithm works by deriving solutions without initial counts
on data. This algorithm is a computational discipline that is valuable in data analysis, reliable
decision making and knowledge discovery. Algorithms determine the overall outcomes of
domain clustering of data and its processing. When using k-means, one of the drawbacks is that,
you must specify the number of clusters as raw data to the algorithm, due to this, it is advisable
to experiment using diverse k values in order to identify the value that perfectly suits the data
that you have.
2
Executive summary
K-means is one of the most popular set of rules or procedures. It is actually perpetuated by its
austerity and consistency in the field of data mining (Cui 2014). Its trails a very naive and
relatively simple mechanisms to organize data sets over guaranteed sum of cluster. Processing of
large-scale data using k-means algorithm helps in grouping of related observations without any
prior knowledge of the relationships. It actually selects K points as the beginning cluster centers.
It is useful in identification of patterns of large volumes of data. Clustering is also very
important in exploration of data, detection and maybe informed ways of how to handle
anomalies, and some aspects of data segmentation. Interpreting of various clusters can be
difficult and certain algorithms can be very useful in the course of this particularly.
Clustering is very fundamental for instance in certain particular issues such as building of
regulatory networks, discovery of the various subtypes of a disease in medicine, maybe inferring
of unknown gene functions in medicine as well and reduction of dimensionality.
The objective of the project is to get generous outcome while giving accreditation of the
disclosure of data. K-means cluster algorithm works by deriving solutions without initial counts
on data. This algorithm is a computational discipline that is valuable in data analysis, reliable
decision making and knowledge discovery. Algorithms determine the overall outcomes of
domain clustering of data and its processing. When using k-means, one of the drawbacks is that,
you must specify the number of clusters as raw data to the algorithm, due to this, it is advisable
to experiment using diverse k values in order to identify the value that perfectly suits the data
that you have.
2

3
The analyzation of data into patterns is accomplished upon scrutinizing data points together with
the cluster numbers (Aggarwal 2013)
Introduction
Description of the K-means Algorithm.
Data analysis is using algorithm software is considered very important especially when dealing
with large volume of data. The gathering is actually a method aimed at discovery of resemblance
sets in a data, called clusters. Data clustering brings an order in the data and hence further
processing on this data is made easier. It is actually involving the processes of organization of
data into high end intra-class similarities and lower intra-class similarities and it is very
essential in avenues such as the optical character recognition, biometrics, diagnostics systems
and it even extends to military operations in any case it helps in data extraction. Data clustering
algorithm in itself has some very necessary steps such as the process should be in a uniform
manner, should actually be able to handle certain diverse features, distribution of data clusters
should be such that data items in a unique constellation should be comparable and it should also
be able to remove all noise and outliers from data sets.
The process is actually the scrutiny of the observed datasheets aimed at obtaining the
relationship among datasets. The method is a partitioning means used to verify information and
its results. The K-means algorithm is in a high-level data analysis. It can’t be summarized in a
formula and is actually also iterative. K-means approach is a partitioning approach, the data
are partitioned into groups at each iteration of the given algorithm. The greatest objective of
this given algorithm is to obtain the various groups in the data. Data mining focuses so much
on goal identification and creation of the target data to be collected for a given use in some given
3
The analyzation of data into patterns is accomplished upon scrutinizing data points together with
the cluster numbers (Aggarwal 2013)
Introduction
Description of the K-means Algorithm.
Data analysis is using algorithm software is considered very important especially when dealing
with large volume of data. The gathering is actually a method aimed at discovery of resemblance
sets in a data, called clusters. Data clustering brings an order in the data and hence further
processing on this data is made easier. It is actually involving the processes of organization of
data into high end intra-class similarities and lower intra-class similarities and it is very
essential in avenues such as the optical character recognition, biometrics, diagnostics systems
and it even extends to military operations in any case it helps in data extraction. Data clustering
algorithm in itself has some very necessary steps such as the process should be in a uniform
manner, should actually be able to handle certain diverse features, distribution of data clusters
should be such that data items in a unique constellation should be comparable and it should also
be able to remove all noise and outliers from data sets.
The process is actually the scrutiny of the observed datasheets aimed at obtaining the
relationship among datasets. The method is a partitioning means used to verify information and
its results. The K-means algorithm is in a high-level data analysis. It can’t be summarized in a
formula and is actually also iterative. K-means approach is a partitioning approach, the data
are partitioned into groups at each iteration of the given algorithm. The greatest objective of
this given algorithm is to obtain the various groups in the data. Data mining focuses so much
on goal identification and creation of the target data to be collected for a given use in some given
3
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

4
order or plan. This forms a very essential aspect of the process of Interpretation and decision
making. The data collected on observation is treated as objects basing arguments on positions
and space which exists between input data points. Segregating of the entities into high-class
masses (K) is achieved through having the objects remain as close to each other as possible. The
clusters are characterized by the center points of each of them, the center points are generally
referred to us centroids. K-means is applicable mainly exploratory data evacuation where one
must examine the gathering results to determine which clusters make sense. Clustering distances
used in most times do not clearly show the three dimensional distances. The available answer to
the challenge of getting least global is the tiring selection of preliminary points.
It is through computing of the average of every coordinate that a centroid whose co-ordinates are
obtained is assigned clusters. There exist steps to follow when computing k-means clustering,
below are some of the steps followed;
Steps followed:
Step 1: Set K- in a way to choose a number of desired clusters, k.
Step 2: Initialization - This is executed in order to select k preliminary points that are prior
estimates of centroids.
Step 3: Classification - This step is used to establish every object in the set of data and put it to
the cluster.
Step 4: Calculation of centroids - When each of the datasets is allocated to a cluster, it is needed
to reconstitute the new k centroids.
4
order or plan. This forms a very essential aspect of the process of Interpretation and decision
making. The data collected on observation is treated as objects basing arguments on positions
and space which exists between input data points. Segregating of the entities into high-class
masses (K) is achieved through having the objects remain as close to each other as possible. The
clusters are characterized by the center points of each of them, the center points are generally
referred to us centroids. K-means is applicable mainly exploratory data evacuation where one
must examine the gathering results to determine which clusters make sense. Clustering distances
used in most times do not clearly show the three dimensional distances. The available answer to
the challenge of getting least global is the tiring selection of preliminary points.
It is through computing of the average of every coordinate that a centroid whose co-ordinates are
obtained is assigned clusters. There exist steps to follow when computing k-means clustering,
below are some of the steps followed;
Steps followed:
Step 1: Set K- in a way to choose a number of desired clusters, k.
Step 2: Initialization - This is executed in order to select k preliminary points that are prior
estimates of centroids.
Step 3: Classification - This step is used to establish every object in the set of data and put it to
the cluster.
Step 4: Calculation of centroids - When each of the datasets is allocated to a cluster, it is needed
to reconstitute the new k centroids.
4
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

5
Step 5: Convergence criteria – steps 3 and 4 are supposed to be redone until a moment where no
point changes.
The authentic data models are to be collected before the solicitation of the clustering algorithm.
Primacy is assumed to be the features that define each of the data samples in the record. The
ideals of these given structures constitute a vector (Fi1, Fi2, Fi3, Fim) where Fim is the value of
the dimensional space. As for the other clustering algorithms, K- means requires that the metric
distance between points is distinct. This metric distance is used in the above stated step (iii) of
the algorithm. A mutual metric distance is the Euclidean distance. In case the different factors
used in the feature vector have diverse comparative values and varies, the distance calculation
may be biased and might be clambered. The bounds of the clustering algorithm are the number
of bunches that are to be found along with the preliminary starting point values. When the initial
values are stated, the distance from each trial data point to each initial starting value is
calculated. Every data point is positioned in the cluster related with the adjacent starting point.
After all the data points are consigned to a cluster, new cluster centroids are computed. For each
aspect in each cluster, new centroid value is then premeditated.
Literature review
In this literature review, more knowledge is going to be explained on the data mining algorithm
s. This review will explore more about k-means algorithm, the experimental set up, research
questions and the result. The journal (Srivastava 2016) clearly points out that clustering enhances
predictive decisions and placement process. It is important to examine a large number of raw
data in order to come up with more reliable predictive results, the study (Aggarwal 2013)
indicates that, many cluster algorithms like k-means comes up with clustering representatives as
5
Step 5: Convergence criteria – steps 3 and 4 are supposed to be redone until a moment where no
point changes.
The authentic data models are to be collected before the solicitation of the clustering algorithm.
Primacy is assumed to be the features that define each of the data samples in the record. The
ideals of these given structures constitute a vector (Fi1, Fi2, Fi3, Fim) where Fim is the value of
the dimensional space. As for the other clustering algorithms, K- means requires that the metric
distance between points is distinct. This metric distance is used in the above stated step (iii) of
the algorithm. A mutual metric distance is the Euclidean distance. In case the different factors
used in the feature vector have diverse comparative values and varies, the distance calculation
may be biased and might be clambered. The bounds of the clustering algorithm are the number
of bunches that are to be found along with the preliminary starting point values. When the initial
values are stated, the distance from each trial data point to each initial starting value is
calculated. Every data point is positioned in the cluster related with the adjacent starting point.
After all the data points are consigned to a cluster, new cluster centroids are computed. For each
aspect in each cluster, new centroid value is then premeditated.
Literature review
In this literature review, more knowledge is going to be explained on the data mining algorithm
s. This review will explore more about k-means algorithm, the experimental set up, research
questions and the result. The journal (Srivastava 2016) clearly points out that clustering enhances
predictive decisions and placement process. It is important to examine a large number of raw
data in order to come up with more reliable predictive results, the study (Aggarwal 2013)
indicates that, many cluster algorithms like k-means comes up with clustering representatives as
5

6
a way of computing simple data points. Mixing of data brings about more problems that the real
problem to be solved.
Data Mining contains a very big group of various set of processes and the area is actually really
in the course of expanding, because researchers are on the working tirelessly to make better the
performance of the existing algorithms, and thus this makes higher the chances of new
approaches increasing very fast with the changes in time and technology to some extent. A good
number of the researchers in data mining area focus on improving the efficiency and accuracy of
applications, not so much of efforts have been committed into the discussion of applications. K-
means has problems when clusters are of differing sizes, densities and non-globular shapes.
The K-means algorithm is a heuristic method of K-means algorithm (MacQueen’67) where each
cluster is represented by the center of the cluster and the algorithm converges to stable centroid
of clusters.
Clustering has highly been very applicable most so in fields such as data mining, engineering,
medicine, and some aspects of biology fields and given this, the complexity of a given large
volume of data is very high.
Data mining and its aspects such as customer management activities are needed most so in the
banking and the various retail industries since it is not only essential but also very necessary in
the process of decision making and has several advantages especially with focus to the
competition which is in the market for example in such industries. This technique is used to
analyse the data from different dimensions and categorize the data. The given technique is
affected by some of the factors such as the selection of the first centroids and the calculations of
distances which are involved in the particular cases.
6
a way of computing simple data points. Mixing of data brings about more problems that the real
problem to be solved.
Data Mining contains a very big group of various set of processes and the area is actually really
in the course of expanding, because researchers are on the working tirelessly to make better the
performance of the existing algorithms, and thus this makes higher the chances of new
approaches increasing very fast with the changes in time and technology to some extent. A good
number of the researchers in data mining area focus on improving the efficiency and accuracy of
applications, not so much of efforts have been committed into the discussion of applications. K-
means has problems when clusters are of differing sizes, densities and non-globular shapes.
The K-means algorithm is a heuristic method of K-means algorithm (MacQueen’67) where each
cluster is represented by the center of the cluster and the algorithm converges to stable centroid
of clusters.
Clustering has highly been very applicable most so in fields such as data mining, engineering,
medicine, and some aspects of biology fields and given this, the complexity of a given large
volume of data is very high.
Data mining and its aspects such as customer management activities are needed most so in the
banking and the various retail industries since it is not only essential but also very necessary in
the process of decision making and has several advantages especially with focus to the
competition which is in the market for example in such industries. This technique is used to
analyse the data from different dimensions and categorize the data. The given technique is
affected by some of the factors such as the selection of the first centroids and the calculations of
distances which are involved in the particular cases.
6
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

7
Research question
The major objective of the project is to come up with a more reliable k-means clustering
algorithm. Below are the project goals
1. Determining the implementation worthiness of k-means algorithm
2. Bring fourth easier and simpler methods of k-means computational ability
3. Examine the k-modes algorithm in comparison with k-means
4. Provide a step by step procedure on how k-means works
5. To come up with a graphical representation of analyzed data safe for better decision
making
6. Carry out a deeper analysis of the in order to come up with more accurate results
The K-means algorithm has several advantages such as being fast, robust, and easier to
understand and it’s also efficient and it is also actually very easy to implement and it can also
find pure sub clusters if a large number of large clusters is satisfied. It has several demerits for
instance the algorithm requires a prior specification of the number of cluster centres, the use
of exclusive assignment, if there are two highly overlapping data then K-means will not be able
to resolve that there are two clusters, the set of processes is not invariant to non-linear
transformations that is with different representation of data we get different results. K-means is
an approximation to an NP-hard combinatorial optimization problem and it works mostly mainly
for numerical sort of observations. K-means is really very appropriate when we can work with
Euclidean distances whereby some variables are categorical and outliers can be found to be a
very potential threat to the process. Although the computational ability of K-Means is much
more intensive.
7
Research question
The major objective of the project is to come up with a more reliable k-means clustering
algorithm. Below are the project goals
1. Determining the implementation worthiness of k-means algorithm
2. Bring fourth easier and simpler methods of k-means computational ability
3. Examine the k-modes algorithm in comparison with k-means
4. Provide a step by step procedure on how k-means works
5. To come up with a graphical representation of analyzed data safe for better decision
making
6. Carry out a deeper analysis of the in order to come up with more accurate results
The K-means algorithm has several advantages such as being fast, robust, and easier to
understand and it’s also efficient and it is also actually very easy to implement and it can also
find pure sub clusters if a large number of large clusters is satisfied. It has several demerits for
instance the algorithm requires a prior specification of the number of cluster centres, the use
of exclusive assignment, if there are two highly overlapping data then K-means will not be able
to resolve that there are two clusters, the set of processes is not invariant to non-linear
transformations that is with different representation of data we get different results. K-means is
an approximation to an NP-hard combinatorial optimization problem and it works mostly mainly
for numerical sort of observations. K-means is really very appropriate when we can work with
Euclidean distances whereby some variables are categorical and outliers can be found to be a
very potential threat to the process. Although the computational ability of K-Means is much
more intensive.
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

8
Methodology
K-means is widely used for machine learning. It is a collection of groups of data mostly used by
people conducting research. In Iris plant dataset, for instance a summation of five attributes of
which four are numeric, the four numeric include: sepal length, petal length, sepal width and
petal width. The other attribute is non-numeric, even though non-numeric, it has got three classes
with close to 150 instances. The three classes in the non-numeric attribute are: setosa, Iris
Versicolour and Iris Virginica with one separate from the other linearly.
Experimental Set Up
When conducting implementation of the k-means clustering algorithm, metlab function method
is applied. This partitioning reduces the overall number of clusters that are within the total
clusters, the rows of data go together to points, columns to variables and kmeans turn to n-by-1
idx. When data is a vector, K-means takes it as an n-by-1 data matrix, overriding its orientation.
The iris dataset for three clusters, five ‘replicates’ have been specified and the ‘display’
parameters are used to print out the final sum of distances for each of the solutions. The sum
total of distances covering 13 iterations that have taken into considerations in this paper comes to
7897.88. The total elapsed time is 0.443755 seconds. Following scattered KMeans graph for iris
data set (sepal length, sepal width and petal length) represents three clusters.
8
Methodology
K-means is widely used for machine learning. It is a collection of groups of data mostly used by
people conducting research. In Iris plant dataset, for instance a summation of five attributes of
which four are numeric, the four numeric include: sepal length, petal length, sepal width and
petal width. The other attribute is non-numeric, even though non-numeric, it has got three classes
with close to 150 instances. The three classes in the non-numeric attribute are: setosa, Iris
Versicolour and Iris Virginica with one separate from the other linearly.
Experimental Set Up
When conducting implementation of the k-means clustering algorithm, metlab function method
is applied. This partitioning reduces the overall number of clusters that are within the total
clusters, the rows of data go together to points, columns to variables and kmeans turn to n-by-1
idx. When data is a vector, K-means takes it as an n-by-1 data matrix, overriding its orientation.
The iris dataset for three clusters, five ‘replicates’ have been specified and the ‘display’
parameters are used to print out the final sum of distances for each of the solutions. The sum
total of distances covering 13 iterations that have taken into considerations in this paper comes to
7897.88. The total elapsed time is 0.443755 seconds. Following scattered KMeans graph for iris
data set (sepal length, sepal width and petal length) represents three clusters.
8

9
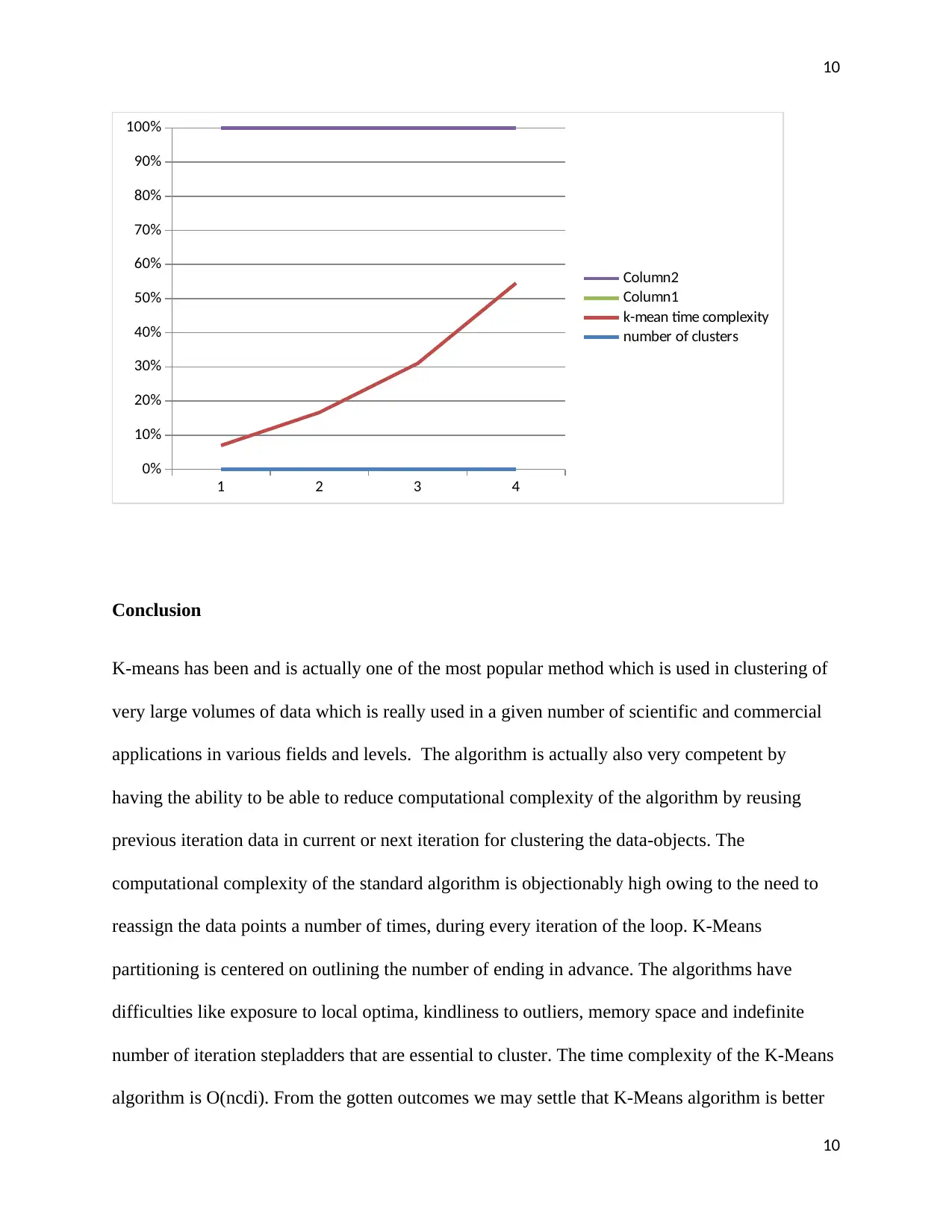
The K-means time complexity is 0(ncdi), if we keep the number of data points we can assume
that n=100, d=3, i=20 and varying cluster number where n=data points number, d=dimension
number and i=iterations number. The table below represents the data points in details
s. no. Number of clusters k-means time complexity
1 1 6000
2 2 12000
3 3 18000
4 4 24000
The graphical representation is as below
9
The K-means time complexity is 0(ncdi), if we keep the number of data points we can assume
that n=100, d=3, i=20 and varying cluster number where n=data points number, d=dimension
number and i=iterations number. The table below represents the data points in details
s. no. Number of clusters k-means time complexity
1 1 6000
2 2 12000
3 3 18000
4 4 24000
The graphical representation is as below
9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
10
1 2 3 4
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Column2
Column1
k-mean time complexity
number of clusters
Conclusion
K-means has been and is actually one of the most popular method which is used in clustering of
very large volumes of data which is really used in a given number of scientific and commercial
applications in various fields and levels. The algorithm is actually also very competent by
having the ability to be able to reduce computational complexity of the algorithm by reusing
previous iteration data in current or next iteration for clustering the data-objects. The
computational complexity of the standard algorithm is objectionably high owing to the need to
reassign the data points a number of times, during every iteration of the loop. K-Means
partitioning is centered on outlining the number of ending in advance. The algorithms have
difficulties like exposure to local optima, kindliness to outliers, memory space and indefinite
number of iteration stepladders that are essential to cluster. The time complexity of the K-Means
algorithm is O(ncdi). From the gotten outcomes we may settle that K-Means algorithm is better
10
1 2 3 4
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Column2
Column1
k-mean time complexity
number of clusters
Conclusion
K-means has been and is actually one of the most popular method which is used in clustering of
very large volumes of data which is really used in a given number of scientific and commercial
applications in various fields and levels. The algorithm is actually also very competent by
having the ability to be able to reduce computational complexity of the algorithm by reusing
previous iteration data in current or next iteration for clustering the data-objects. The
computational complexity of the standard algorithm is objectionably high owing to the need to
reassign the data points a number of times, during every iteration of the loop. K-Means
partitioning is centered on outlining the number of ending in advance. The algorithms have
difficulties like exposure to local optima, kindliness to outliers, memory space and indefinite
number of iteration stepladders that are essential to cluster. The time complexity of the K-Means
algorithm is O(ncdi). From the gotten outcomes we may settle that K-Means algorithm is better
10
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

11
placed for conducting dependable analysis. In fact, K-means clustering which institute the oldest
element of software calculating, are really appropriate for handling the issues related to
understand the aptitude of patterns, unfinished and/or noisy data, mixed broadcasting
information, human collaboration and it can provide estimated solutions faster. They have been
largely used for ascertaining association guidelines and functional needs as well as image
repossession. So, the overall deduction is that K-Means algorithm looks to be superior to all
other algorithms. Its simplicity and reliability is key to accurate data analysis.
It’s actually also quite important to note that given the fact that K-means is also having an
optimization problem therefore the K-means has a tendency of assuming the variances of
distribution of each of its attributes are spherical in nature, that all the variables are of the same
variance and that the occurrences of chances for all the clusters of k is the same such that each of
the various clusters has roughly a given equal number of observations in any case.
Below is a sample Gantt Chart for such a particular project.
ACTIVITY
Data collection
Data Analysis
Implementation
and report
TIMELINE(months
)
January February March April
11
placed for conducting dependable analysis. In fact, K-means clustering which institute the oldest
element of software calculating, are really appropriate for handling the issues related to
understand the aptitude of patterns, unfinished and/or noisy data, mixed broadcasting
information, human collaboration and it can provide estimated solutions faster. They have been
largely used for ascertaining association guidelines and functional needs as well as image
repossession. So, the overall deduction is that K-Means algorithm looks to be superior to all
other algorithms. Its simplicity and reliability is key to accurate data analysis.
It’s actually also quite important to note that given the fact that K-means is also having an
optimization problem therefore the K-means has a tendency of assuming the variances of
distribution of each of its attributes are spherical in nature, that all the variables are of the same
variance and that the occurrences of chances for all the clusters of k is the same such that each of
the various clusters has roughly a given equal number of observations in any case.
Below is a sample Gantt Chart for such a particular project.
ACTIVITY
Data collection
Data Analysis
Implementation
and report
TIMELINE(months
)
January February March April
11

12
References
Aggarwal, CCARCKE, 2013, Data clustering algorithms and applications, CRC press.
Aggarwal, CCARCKE 2013, 'Data Clustering: algorithms and applications', CRC press.
Cui, X,ZP,YX,LKAJC, 2014, 'Optimized big data K-means Clustering using Mapreduce', The
Journal of Supercomputing, vol 70(3), pp. pp. 1249-1259.
Srivastava, J,SAKAKS, 2016, 'A Road Map to Enhance Employability Index and Selection
Prediction of Management Students Using K-means Clustering and Binary Regression',
International Journal of Data Mining and Emerging Technologies, vol 6(2), pp. pp. 61-69.
Wu, X., Zhu, X., Wu, G.Q. and Ding, W., 2014. Data mining with big data. IEEE transactions
on knowledge and data engineering, 26(1), pp.97-107.
Shmueli, G. and Lichtendahl Jr, K.C., 2017. Data Mining for Business Analytics: Concepts,
Techniques, and Applications in R. John Wiley & Sons.
Zaki, M.J., Meira Jr, W. and Meira, W., 2014. Data mining and analysis: fundamental concepts
and algorithms. Cambridge University Press.
12
References
Aggarwal, CCARCKE, 2013, Data clustering algorithms and applications, CRC press.
Aggarwal, CCARCKE 2013, 'Data Clustering: algorithms and applications', CRC press.
Cui, X,ZP,YX,LKAJC, 2014, 'Optimized big data K-means Clustering using Mapreduce', The
Journal of Supercomputing, vol 70(3), pp. pp. 1249-1259.
Srivastava, J,SAKAKS, 2016, 'A Road Map to Enhance Employability Index and Selection
Prediction of Management Students Using K-means Clustering and Binary Regression',
International Journal of Data Mining and Emerging Technologies, vol 6(2), pp. pp. 61-69.
Wu, X., Zhu, X., Wu, G.Q. and Ding, W., 2014. Data mining with big data. IEEE transactions
on knowledge and data engineering, 26(1), pp.97-107.
Shmueli, G. and Lichtendahl Jr, K.C., 2017. Data Mining for Business Analytics: Concepts,
Techniques, and Applications in R. John Wiley & Sons.
Zaki, M.J., Meira Jr, W. and Meira, W., 2014. Data mining and analysis: fundamental concepts
and algorithms. Cambridge University Press.
12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.