Detailed Project Solution: K-Means Clustering with MapReduce Framework
VerifiedAdded on 2023/05/27
|12
|1961
|97
Project
AI Summary
This project solution details the implementation of the K-Means clustering algorithm using the MapReduce framework. It begins with an overview of the K-Means algorithm and its application in data mining, followed by an explanation of the MapReduce paradigm for handling large datasets in a distributed computing environment. The project outlines the algorithm's design, including mapper and reducer functions, and provides a step-by-step guide to implementing the K-Means algorithm using Weka, a data mining tool. The solution also includes the steps for inserting the improved algorithm into the Weka tool, modifying class names, compiling files, and integrating the new algorithm into the Weka GUI. The project concludes with references to relevant research papers and articles.

K-Means Algorithm using Map reduce
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
1 Project Description........................................................................................................................3
2 Data set collection.........................................................................................................................3
3 K-Means Algorithm.......................................................................................................................4
4 Map Reduce...................................................................................................................................4
5 Algorithm......................................................................................................................................5
5.1 Algorithm 1: Mapper Design for K-means Clustering...........................................................5
5.2 Algorithm 2: Reducer Design for K-means Clustering..........................................................6
5.3 Algorithm 3: Implementation of K-means Function..............................................................6
6 Weka Implementation - K-Means algorithm................................................................................6
References...........................................................................................................................................12
2
1 Project Description........................................................................................................................3
2 Data set collection.........................................................................................................................3
3 K-Means Algorithm.......................................................................................................................4
4 Map Reduce...................................................................................................................................4
5 Algorithm......................................................................................................................................5
5.1 Algorithm 1: Mapper Design for K-means Clustering...........................................................5
5.2 Algorithm 2: Reducer Design for K-means Clustering..........................................................6
5.3 Algorithm 3: Implementation of K-means Function..............................................................6
6 Weka Implementation - K-Means algorithm................................................................................6
References...........................................................................................................................................12
2
1 Project Description
The k-Means Clustering is an exceptionally straightforward and well known data mining
algorithm that has its application spread over an extremely expansive range. MapReduce is a
programming style that is utilized for dealing with high volume data over an appropriated
processing condition. This paper proposes an enhanced and effective strategy to execute the
k-Means Clustering Technique utilizing the MapReduce worldview. The usage of Improved
MapReduce k-Means Clustering has been obviously talked about and its viability is
contrasted with the standard execution in an exploratory investigation. The outcomes merge
this exploration by inferring that the Improved MapReduce Implementation of k-Means
Clustering Algorithm out plays out the normal usage.
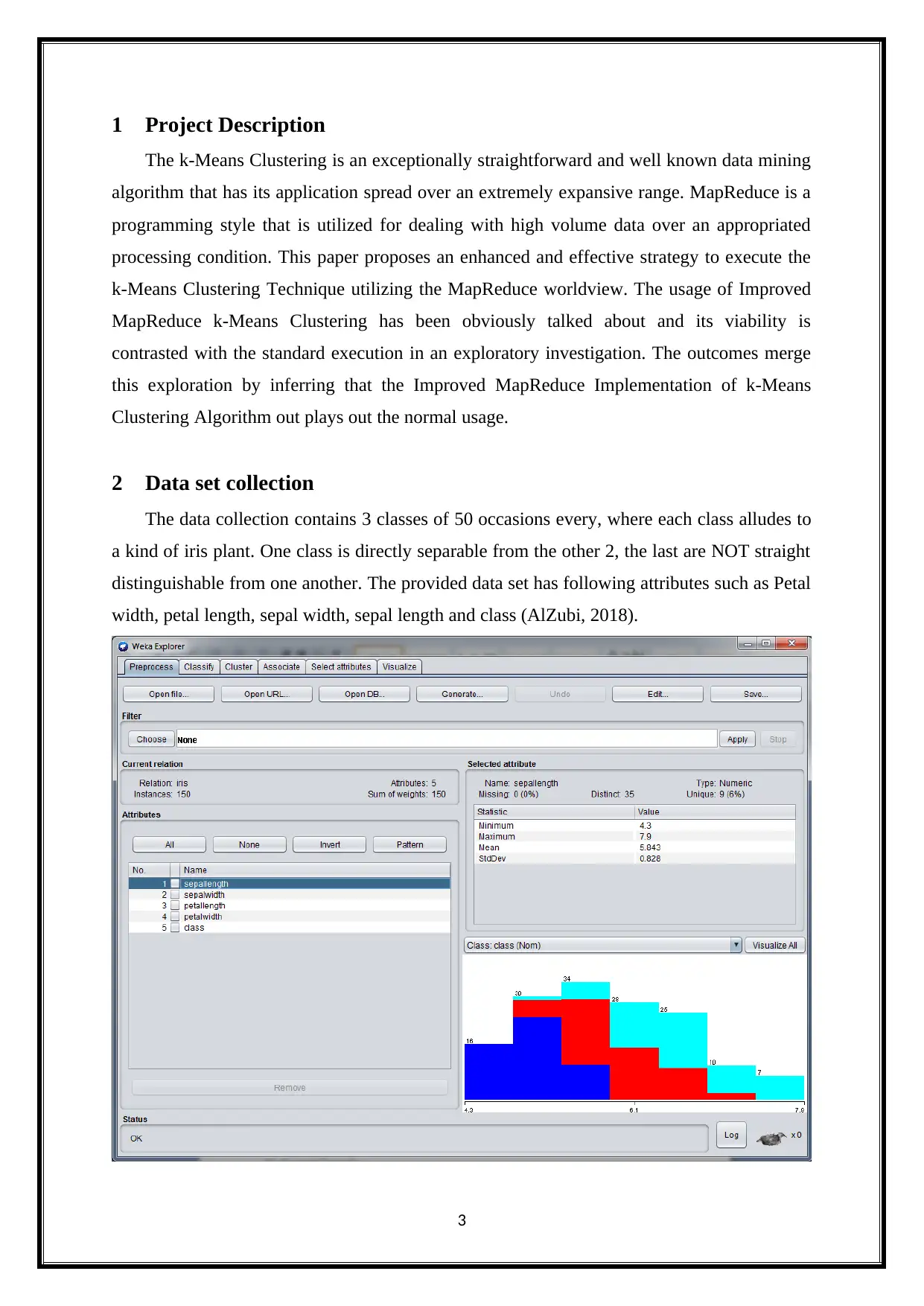
2 Data set collection
The data collection contains 3 classes of 50 occasions every, where each class alludes to
a kind of iris plant. One class is directly separable from the other 2, the last are NOT straight
distinguishable from one another. The provided data set has following attributes such as Petal
width, petal length, sepal width, sepal length and class (AlZubi, 2018).
3
The k-Means Clustering is an exceptionally straightforward and well known data mining
algorithm that has its application spread over an extremely expansive range. MapReduce is a
programming style that is utilized for dealing with high volume data over an appropriated
processing condition. This paper proposes an enhanced and effective strategy to execute the
k-Means Clustering Technique utilizing the MapReduce worldview. The usage of Improved
MapReduce k-Means Clustering has been obviously talked about and its viability is
contrasted with the standard execution in an exploratory investigation. The outcomes merge
this exploration by inferring that the Improved MapReduce Implementation of k-Means
Clustering Algorithm out plays out the normal usage.
2 Data set collection
The data collection contains 3 classes of 50 occasions every, where each class alludes to
a kind of iris plant. One class is directly separable from the other 2, the last are NOT straight
distinguishable from one another. The provided data set has following attributes such as Petal
width, petal length, sepal width, sepal length and class (AlZubi, 2018).
3
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
3 K-Means Algorithm
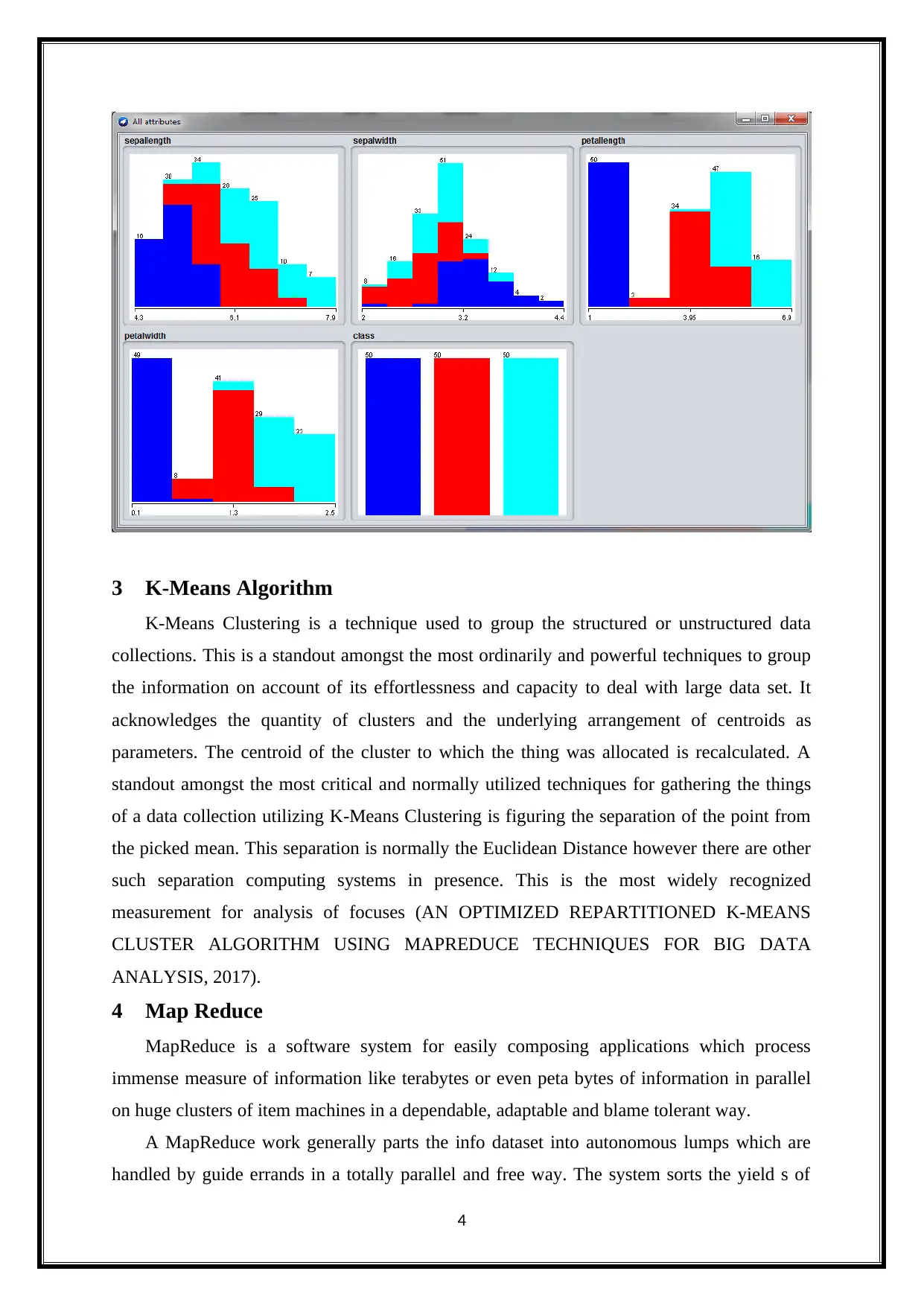
K-Means Clustering is a technique used to group the structured or unstructured data
collections. This is a standout amongst the most ordinarily and powerful techniques to group
the information on account of its effortlessness and capacity to deal with large data set. It
acknowledges the quantity of clusters and the underlying arrangement of centroids as
parameters. The centroid of the cluster to which the thing was allocated is recalculated. A
standout amongst the most critical and normally utilized techniques for gathering the things
of a data collection utilizing K-Means Clustering is figuring the separation of the point from
the picked mean. This separation is normally the Euclidean Distance however there are other
such separation computing systems in presence. This is the most widely recognized
measurement for analysis of focuses (AN OPTIMIZED REPARTITIONED K-MEANS
CLUSTER ALGORITHM USING MAPREDUCE TECHNIQUES FOR BIG DATA
ANALYSIS, 2017).
4 Map Reduce
MapReduce is a software system for easily composing applications which process
immense measure of information like terabytes or even peta bytes of information in parallel
on huge clusters of item machines in a dependable, adaptable and blame tolerant way.
A MapReduce work generally parts the info dataset into autonomous lumps which are
handled by guide errands in a totally parallel and free way. The system sorts the yield s of
4
K-Means Clustering is a technique used to group the structured or unstructured data
collections. This is a standout amongst the most ordinarily and powerful techniques to group
the information on account of its effortlessness and capacity to deal with large data set. It
acknowledges the quantity of clusters and the underlying arrangement of centroids as
parameters. The centroid of the cluster to which the thing was allocated is recalculated. A
standout amongst the most critical and normally utilized techniques for gathering the things
of a data collection utilizing K-Means Clustering is figuring the separation of the point from
the picked mean. This separation is normally the Euclidean Distance however there are other
such separation computing systems in presence. This is the most widely recognized
measurement for analysis of focuses (AN OPTIMIZED REPARTITIONED K-MEANS
CLUSTER ALGORITHM USING MAPREDUCE TECHNIQUES FOR BIG DATA
ANALYSIS, 2017).
4 Map Reduce
MapReduce is a software system for easily composing applications which process
immense measure of information like terabytes or even peta bytes of information in parallel
on huge clusters of item machines in a dependable, adaptable and blame tolerant way.
A MapReduce work generally parts the info dataset into autonomous lumps which are
handled by guide errands in a totally parallel and free way. The system sorts the yield s of
4
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

maps, which are then contribution to the lessen assignment. Guide and Reduce steps are
discrete and particular and finish opportunity is given to the developer to plan them.
Every one of the Map and Reduce steps are performed in parallel on sets of information
individuals. Along these lines the program is fragmented into two particular and very much
characterized stages specifically Map and Reduce.
The Map organize includes execution of a capacity on a given data index as value and
key and produces the moderate data collection.
The created middle of the road data collection is then sorted out for the usage of the
Reduce activity. Each MapReduce Framework has a performance Job Tracker and numerous
assignment trackers.
Every hub associated with the system has the privilege to act as a slave Task Tracker.
The issues like division of information to different hubs, errand booking, hub
disappointments, assignment disappointment the board, correspondence of hubs, checking the
undertaking progress is altogether taken consideration by the master hub.
5 Algorithm
5.1 Algorithm 1: Mapper Design for K-means Clustering
5
discrete and particular and finish opportunity is given to the developer to plan them.
Every one of the Map and Reduce steps are performed in parallel on sets of information
individuals. Along these lines the program is fragmented into two particular and very much
characterized stages specifically Map and Reduce.
The Map organize includes execution of a capacity on a given data index as value and
key and produces the moderate data collection.
The created middle of the road data collection is then sorted out for the usage of the
Reduce activity. Each MapReduce Framework has a performance Job Tracker and numerous
assignment trackers.
Every hub associated with the system has the privilege to act as a slave Task Tracker.
The issues like division of information to different hubs, errand booking, hub
disappointments, assignment disappointment the board, correspondence of hubs, checking the
undertaking progress is altogether taken consideration by the master hub.
5 Algorithm
5.1 Algorithm 1: Mapper Design for K-means Clustering
5

5.2 Algorithm 2: Reducer Design for K-means Clustering
5.3 Algorithm 3: Implementation of K-means Function
6 Weka Implementation - K-Means algorithm
K-Means algorithm is implemented on Weka. So, first user needs to install the weka. After,
open the weka. Then, upload the data to clustering the provided data. It is illustrated as below
(Kumar, Verma and Saxena, 2013).
6
5.3 Algorithm 3: Implementation of K-means Function
6 Weka Implementation - K-Means algorithm
K-Means algorithm is implemented on Weka. So, first user needs to install the weka. After,
open the weka. Then, upload the data to clustering the provided data. It is illustrated as below
(Kumar, Verma and Saxena, 2013).
6
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
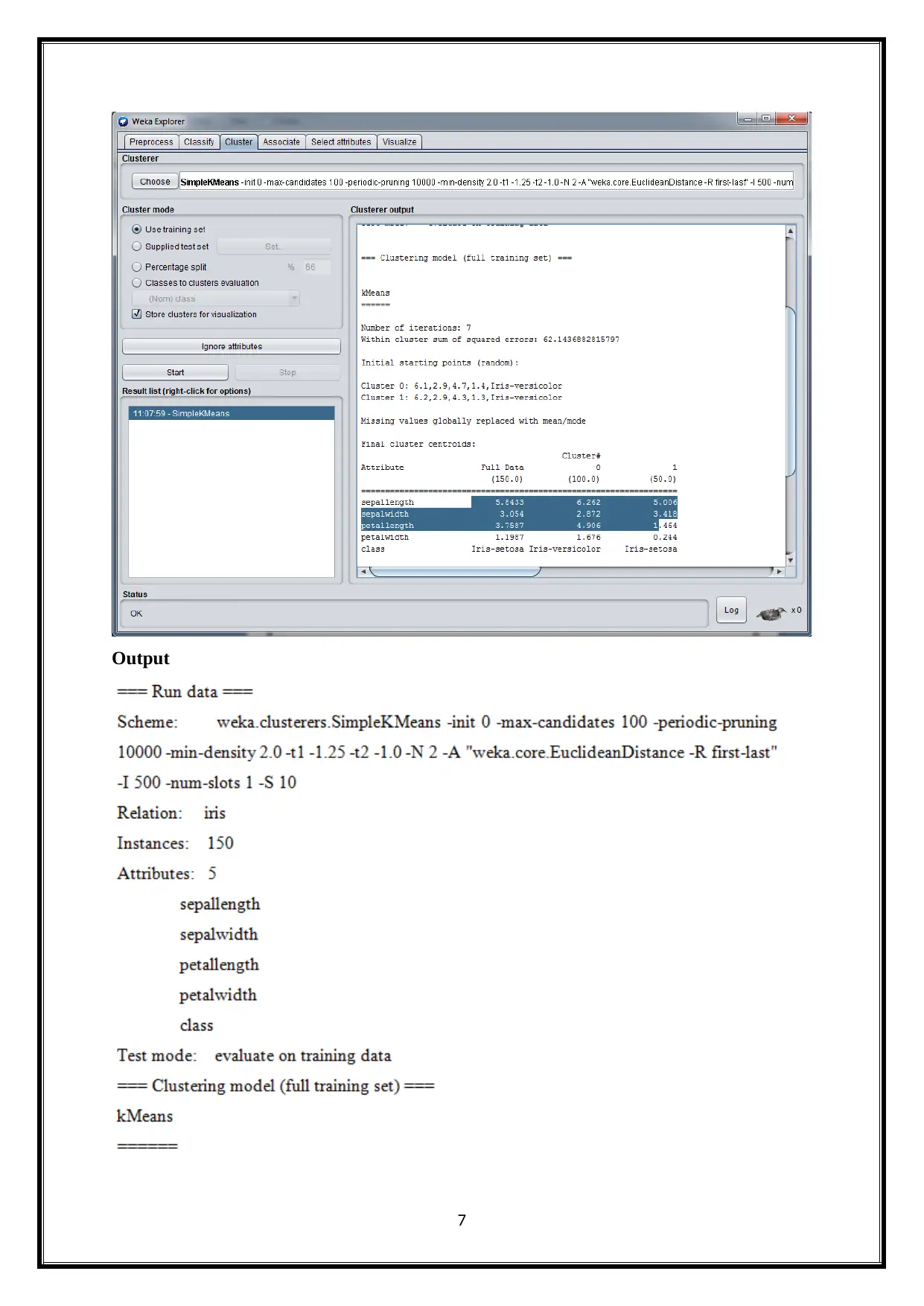
Output
7
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

8
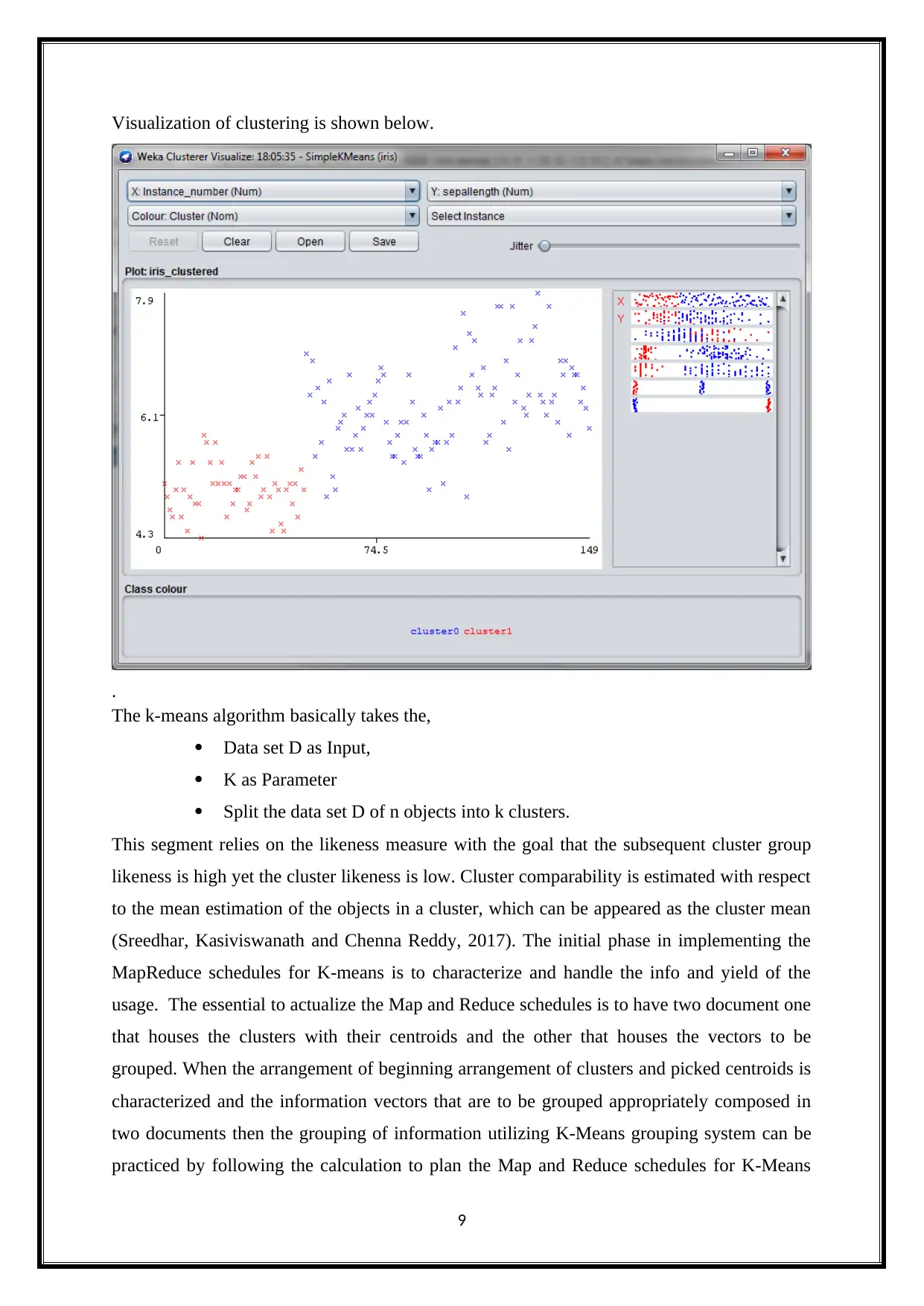
Visualization of clustering is shown below.
.
The k-means algorithm basically takes the,
Data set D as Input,
K as Parameter
Split the data set D of n objects into k clusters.
This segment relies on the likeness measure with the goal that the subsequent cluster group
likeness is high yet the cluster likeness is low. Cluster comparability is estimated with respect
to the mean estimation of the objects in a cluster, which can be appeared as the cluster mean
(Sreedhar, Kasiviswanath and Chenna Reddy, 2017). The initial phase in implementing the
MapReduce schedules for K-means is to characterize and handle the info and yield of the
usage. The essential to actualize the Map and Reduce schedules is to have two document one
that houses the clusters with their centroids and the other that houses the vectors to be
grouped. When the arrangement of beginning arrangement of clusters and picked centroids is
characterized and the information vectors that are to be grouped appropriately composed in
two documents then the grouping of information utilizing K-Means grouping system can be
practiced by following the calculation to plan the Map and Reduce schedules for K-Means
9
.
The k-means algorithm basically takes the,
Data set D as Input,
K as Parameter
Split the data set D of n objects into k clusters.
This segment relies on the likeness measure with the goal that the subsequent cluster group
likeness is high yet the cluster likeness is low. Cluster comparability is estimated with respect
to the mean estimation of the objects in a cluster, which can be appeared as the cluster mean
(Sreedhar, Kasiviswanath and Chenna Reddy, 2017). The initial phase in implementing the
MapReduce schedules for K-means is to characterize and handle the info and yield of the
usage. The essential to actualize the Map and Reduce schedules is to have two document one
that houses the clusters with their centroids and the other that houses the vectors to be
grouped. When the arrangement of beginning arrangement of clusters and picked centroids is
characterized and the information vectors that are to be grouped appropriately composed in
two documents then the grouping of information utilizing K-Means grouping system can be
practiced by following the calculation to plan the Map and Reduce schedules for K-Means
9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Clustering. The Mapper is organized so that it figures the separation between the vector
esteem and every one of the cluster focuses referenced in the group set and at the same time
monitoring the cluster to which the given vector is nearest. When the calculation of
separations is finished the vector ought to be doled out to the closest group. When Mapper is
conjured the given vector is appointed to the group that it is nearest identified with
(Venkatesh and Arunesh, 2018). After the task is done the centroid of that specific group is
recalculated.
7 Steps for inserting the algorithm into weka tool
1. Create a folder in D:\ drive called mytmp
2. Open E:\Weka3.4 folder. we can view all the extracted from weka-3-4-16jre.exe;
3. We will find a file called weka-src.java, Copy and paste it in D:\mytmp
4. Extract all the files using WinZip in to D:\mytmp
5. We will find the folders like lib, src, meta-inf, test and build.xml file
6. Create a folder in D:\ drive called tmp
7. Open Net beans IDE.
8. Go to D:\mytemp\src\main\java and copy the folder weka and paste it in D:\tmp\
weka\src.
a. A dialog appears that folder name is existing, overwrite yes or cancel
b. Click on yes to all buttons.
9. Now switch to Net beans and click on Weka project and Source Package, we can
observe that all the earlier files such as classification, gui, clustering, filters etc are
dumped in to it.
10. Click on Build Menu\Build Main Project
11. Click on Run Menu \Run Main Project
12. Go to D:\tmp\weka\src\weka\clusterers and select SimpleKMeans.java
13. Copy SimpleKMeans.java in the same folder (i.e. D:\tmp\weka\src\weka\clusterers) it
appears as Copy of SimpleKMeans.java
14. Rename this Copy of SimpleKMeans.java as ImprovedSimpleKmeans .java
15. Switch to Net Beans and double click on source package, and open weka.clusters we
can see the ImprovedSimpleKmeans.java file in that package.
16. Double click on this file, the source code will be opened
a. Modify the class name, constructor name and where ever you feel it is
appropriate as ImprovedSimpleKmeans
10
esteem and every one of the cluster focuses referenced in the group set and at the same time
monitoring the cluster to which the given vector is nearest. When the calculation of
separations is finished the vector ought to be doled out to the closest group. When Mapper is
conjured the given vector is appointed to the group that it is nearest identified with
(Venkatesh and Arunesh, 2018). After the task is done the centroid of that specific group is
recalculated.
7 Steps for inserting the algorithm into weka tool
1. Create a folder in D:\ drive called mytmp
2. Open E:\Weka3.4 folder. we can view all the extracted from weka-3-4-16jre.exe;
3. We will find a file called weka-src.java, Copy and paste it in D:\mytmp
4. Extract all the files using WinZip in to D:\mytmp
5. We will find the folders like lib, src, meta-inf, test and build.xml file
6. Create a folder in D:\ drive called tmp
7. Open Net beans IDE.
8. Go to D:\mytemp\src\main\java and copy the folder weka and paste it in D:\tmp\
weka\src.
a. A dialog appears that folder name is existing, overwrite yes or cancel
b. Click on yes to all buttons.
9. Now switch to Net beans and click on Weka project and Source Package, we can
observe that all the earlier files such as classification, gui, clustering, filters etc are
dumped in to it.
10. Click on Build Menu\Build Main Project
11. Click on Run Menu \Run Main Project
12. Go to D:\tmp\weka\src\weka\clusterers and select SimpleKMeans.java
13. Copy SimpleKMeans.java in the same folder (i.e. D:\tmp\weka\src\weka\clusterers) it
appears as Copy of SimpleKMeans.java
14. Rename this Copy of SimpleKMeans.java as ImprovedSimpleKmeans .java
15. Switch to Net Beans and double click on source package, and open weka.clusters we
can see the ImprovedSimpleKmeans.java file in that package.
16. Double click on this file, the source code will be opened
a. Modify the class name, constructor name and where ever you feel it is
appropriate as ImprovedSimpleKmeans
10
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

b. Compile this file separately by pressing f9.
c. Run this file separately by pressing shift+f6
17. Now as a whole Compile and Run the Weka project again as mentioned in steps 14,
15, since new algorithm is added.
18. We need to make Weka aware that clusters package is added with new algorithm, in
order to be able to use it in the GUI as well: to do so add the appropriate
superclass/interface key into the weka/gui/GenericProperitesCreator.props file.
a. Double click on weka.gui package
b. We can view GenericProperitesCreator.props text file.
c. Double click on GenericProperitesCreator.props text file
d. Add the code “weka.clusterers.ImprovedSimpleKMeans,\” above the
“weka.clusterers.SimpleKMeans” line.
e. Save the file
f. Compile and run the weka project again as mentioned steps 15-25.
19. Now we have to make a java archive files for both java code and java class files.
Because our new algorithm is in D:\tmp\weka\src\weka\clusters folder but original
execution has to be done in E:\Weka3.4. So, we have to make a jar file with the same
file name java-src.java and replace the existing file in E:\weka3.4
a. Cmd
b. Go to directory D:\tmp\weka\src\weka
c. Type the command as follows: jar –cvf weka-src.jar *.*
d. Now we can observe weka-src.jar file existing in the directory D:\tmp\weka\
src\weka
e. Copy the file and paste it in E:\weka3.4 folder
f. It will ask whether to the replace the existing file, Click on Ok button
20. We have to copy the weka.class file in to E:\weka3.4. By Default Net Beans builds
the class file as weka.class and archives it into weka.jar.
a. The class file is located in D:\tmp\weka\dist folder as java.jar
b. Copy the file and paste it in E:\weka3.4 folder
c. It will ask whether to the replace the existing file, Click on Ok button
21. Switch to E:\weka3.4 folder and double click on the weka3.4(with console) shortcut
to execute weka software and check whether our new algorithm is added or not.
22. Now we can observe that ImprovedSimpleKMeans is added in weka.cluster package
along with SimpleKMeans algorithm and is functioning properly.
11
c. Run this file separately by pressing shift+f6
17. Now as a whole Compile and Run the Weka project again as mentioned in steps 14,
15, since new algorithm is added.
18. We need to make Weka aware that clusters package is added with new algorithm, in
order to be able to use it in the GUI as well: to do so add the appropriate
superclass/interface key into the weka/gui/GenericProperitesCreator.props file.
a. Double click on weka.gui package
b. We can view GenericProperitesCreator.props text file.
c. Double click on GenericProperitesCreator.props text file
d. Add the code “weka.clusterers.ImprovedSimpleKMeans,\” above the
“weka.clusterers.SimpleKMeans” line.
e. Save the file
f. Compile and run the weka project again as mentioned steps 15-25.
19. Now we have to make a java archive files for both java code and java class files.
Because our new algorithm is in D:\tmp\weka\src\weka\clusters folder but original
execution has to be done in E:\Weka3.4. So, we have to make a jar file with the same
file name java-src.java and replace the existing file in E:\weka3.4
a. Cmd
b. Go to directory D:\tmp\weka\src\weka
c. Type the command as follows: jar –cvf weka-src.jar *.*
d. Now we can observe weka-src.jar file existing in the directory D:\tmp\weka\
src\weka
e. Copy the file and paste it in E:\weka3.4 folder
f. It will ask whether to the replace the existing file, Click on Ok button
20. We have to copy the weka.class file in to E:\weka3.4. By Default Net Beans builds
the class file as weka.class and archives it into weka.jar.
a. The class file is located in D:\tmp\weka\dist folder as java.jar
b. Copy the file and paste it in E:\weka3.4 folder
c. It will ask whether to the replace the existing file, Click on Ok button
21. Switch to E:\weka3.4 folder and double click on the weka3.4(with console) shortcut
to execute weka software and check whether our new algorithm is added or not.
22. Now we can observe that ImprovedSimpleKMeans is added in weka.cluster package
along with SimpleKMeans algorithm and is functioning properly.
11

References
AlZubi, A. (2018). Big data analytic diabetics using map reduce and classification
techniques. The Journal of Supercomputing.
AN OPTIMIZED REPARTITIONED K-MEANS CLUSTER ALGORITHM USING
MAPREDUCE TECHNIQUES FOR BIG DATA ANALYSIS. (2017). International Journal
of Advance Engineering and Research Development, 4(10).
Kumar, N., Verma, V. and Saxena, V. (2013). Cluster Analysis in Data Mining using K-
Means Method. International Journal of Computer Applications, 76(12), pp.11-14.
Sreedhar, C., Kasiviswanath, N. and Chenna Reddy, P. (2017). Clustering large datasets
using K-means modified inter and intra clustering (KM-I2C) in Hadoop. Journal of Big Data,
4(1).
Venkatesh, G. and Arunesh, K. (2018). Map Reduce for big data processing based on traffic
aware partition and aggregation. Cluster Computing.
12
AlZubi, A. (2018). Big data analytic diabetics using map reduce and classification
techniques. The Journal of Supercomputing.
AN OPTIMIZED REPARTITIONED K-MEANS CLUSTER ALGORITHM USING
MAPREDUCE TECHNIQUES FOR BIG DATA ANALYSIS. (2017). International Journal
of Advance Engineering and Research Development, 4(10).
Kumar, N., Verma, V. and Saxena, V. (2013). Cluster Analysis in Data Mining using K-
Means Method. International Journal of Computer Applications, 76(12), pp.11-14.
Sreedhar, C., Kasiviswanath, N. and Chenna Reddy, P. (2017). Clustering large datasets
using K-means modified inter and intra clustering (KM-I2C) in Hadoop. Journal of Big Data,
4(1).
Venkatesh, G. and Arunesh, K. (2018). Map Reduce for big data processing based on traffic
aware partition and aggregation. Cluster Computing.
12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 12


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.