Module 4: Logical Modeling and Design of Data Warehouses Notes
VerifiedAdded on 2019/10/18
|25
|3038
|492
Homework Assignment
AI Summary
This document presents comprehensive lecture notes from Module 4, focusing on Logical Modeling and Design (LM&D) within the context of data warehouses. The notes emphasize the relational model, star schema, and its variations (snowflake and constellation schemas) for DW design. It covers topics such as dimensional dynamics, translating DFM to DM, aggregate views, and logical design steps, including translating fact schemas, representing application-oriented views, and specifying logical solutions for archiving and replication. The document includes self-assessment exercises with detailed solutions, exploring storage space estimations for different logical design options. Furthermore, the notes refer to various case studies, including Walmart and retail examples, to illustrate practical applications of dimensional modeling. The material also covers key concepts like surrogate keys, bridge tables, and outriggers and provides insights into view materialization and fragmentation techniques. The document concludes with a list of recommended readings for DW professionals, offering a thorough overview of data warehouse design principles and best practices.

Lecture Notes- Module 4 Logical Modeling and Design
What is LM&D and what we will cover in this module?
Logical Modeling and Design of Data Warehouses is centered on the analysis and creation of an
implementation neutral representation for a future DW known as Dimensional Model. Technically
LM&D can be aligned with relational model (RM), multidimensional model (MM) or a hybrid model, a
combination of RM and MM. For two fundamental reasons our course will be to prepare DW design for
relational model implementation: a) educational benefits of building on theoretically grounded and well
standardized technology (our students are familiar with RM theory and the SQL from a pre-requisite
database course), and b) relational implementation scales much better (due to avoiding sparsity and to
stability/services of a proven mature relational database technology). Furthermore, evolution of relational
DW implementation technologies exploits data sourcing from RDBMS and on the other hand RDBMS
engines evolution itself incorporates successful concepts from multidimensional technology (both Oracle
and MS SQL Server included MM capabilities into their DB engines).
The textbook coverage (from chapters 8 and 9) provides excellent background with focus on transitioning
from DFM to Dimensional Models (DM) and grounded treatment of aggregate views (materialized views
candidates) and will be further supported in our lectures and assignments by industrial strength models
and experiences (including extensive case studies presented among the additional M4 readings)
following insights primarily from the Kimball’s The Data Warehouse Toolkit”-2ed and the Adamson’s
“Mastering Warehouse Aggregates” so that substantial value is added in terms of realistic examples. In
terms of visual representation our practice will include Dimensional Model diagrams and visualization
(specification of) logical views, both using the case tool ERwin. This module covers both Logical
Modeling and Logical Design for DW strictly in a relational implementation setting. Before outlining
steps and techniques to be elaborated a few terminology/definitional notes are in place.
The multidimensional modeling in relational systems is based on a star-schema and variations known as
snowflake and constellation (multiple-stars sharing dimensions) schemas. See definitions from the
textbook’s pp 221 and on.
Star schema consists of a fact table (typically with a set of measurement attributes) and a set of
corresponding dimensional tables referencing the fact table. A multidimensional view of data is obtained
by combining (SQL joins) fact table with related dimensional tables.
Snowflake schema involves at least partially normalized dimensions, and a constellation schema involves
several starts (facts tables). An outrigger is a secondary dimension not connected to any fact entities.
Logical Modeling
Logical modeling is covered by the textbook’s chapter 8 and elements from additional examples,
industrial case studies, from supplemented cases. The key point in LM with DM is a treatment of
dimensional dynamics (types of changes and modeling alternatives to support various temporal
scenarios). Additional practical solutions for DFM translation into DM require mastery of star schema
model upgrades with bridges, outriggers, mini-dimensions etc. and will require not only careful reading of
ch8 but also a thorough review of selected cases relevant to your term project work.
What is LM&D and what we will cover in this module?
Logical Modeling and Design of Data Warehouses is centered on the analysis and creation of an
implementation neutral representation for a future DW known as Dimensional Model. Technically
LM&D can be aligned with relational model (RM), multidimensional model (MM) or a hybrid model, a
combination of RM and MM. For two fundamental reasons our course will be to prepare DW design for
relational model implementation: a) educational benefits of building on theoretically grounded and well
standardized technology (our students are familiar with RM theory and the SQL from a pre-requisite
database course), and b) relational implementation scales much better (due to avoiding sparsity and to
stability/services of a proven mature relational database technology). Furthermore, evolution of relational
DW implementation technologies exploits data sourcing from RDBMS and on the other hand RDBMS
engines evolution itself incorporates successful concepts from multidimensional technology (both Oracle
and MS SQL Server included MM capabilities into their DB engines).
The textbook coverage (from chapters 8 and 9) provides excellent background with focus on transitioning
from DFM to Dimensional Models (DM) and grounded treatment of aggregate views (materialized views
candidates) and will be further supported in our lectures and assignments by industrial strength models
and experiences (including extensive case studies presented among the additional M4 readings)
following insights primarily from the Kimball’s The Data Warehouse Toolkit”-2ed and the Adamson’s
“Mastering Warehouse Aggregates” so that substantial value is added in terms of realistic examples. In
terms of visual representation our practice will include Dimensional Model diagrams and visualization
(specification of) logical views, both using the case tool ERwin. This module covers both Logical
Modeling and Logical Design for DW strictly in a relational implementation setting. Before outlining
steps and techniques to be elaborated a few terminology/definitional notes are in place.
The multidimensional modeling in relational systems is based on a star-schema and variations known as
snowflake and constellation (multiple-stars sharing dimensions) schemas. See definitions from the
textbook’s pp 221 and on.
Star schema consists of a fact table (typically with a set of measurement attributes) and a set of
corresponding dimensional tables referencing the fact table. A multidimensional view of data is obtained
by combining (SQL joins) fact table with related dimensional tables.
Snowflake schema involves at least partially normalized dimensions, and a constellation schema involves
several starts (facts tables). An outrigger is a secondary dimension not connected to any fact entities.
Logical Modeling
Logical modeling is covered by the textbook’s chapter 8 and elements from additional examples,
industrial case studies, from supplemented cases. The key point in LM with DM is a treatment of
dimensional dynamics (types of changes and modeling alternatives to support various temporal
scenarios). Additional practical solutions for DFM translation into DM require mastery of star schema
model upgrades with bridges, outriggers, mini-dimensions etc. and will require not only careful reading of
ch8 but also a thorough review of selected cases relevant to your term project work.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

An outrigger is a secondary dimension attached to a dimension, and a mini dimension is a separated
(cleaved out attributes from) a large dimension (million of records).
Before elaborating details of Dimensional Modeling and Design, let us review principal options for
logical models within relational model (ROLAP) approach and the OMA selection of MVs:
dimens ion
dimens ions
dimension
Logical Modeli ng - D M oti ons
wi thi n R DB MS (ROLAP) D Ws
STORE
storeKey
StoreDesc riptiv eAt tr
country _k ey
country _des criptiv eAtt r
region_key
region_desc riptiv eAt tr
REGION
region_key
region_desc riptiv eAt tr
COUN TR Y
country _key
country _des criptiv eAtt r
region_key (FK)
region_descriptiv eAt tr
STORE
st oreKey
StoreDesc riptiv eAt tr
country _k ey (FK)
country _des criptiv eAtt r
region_key
region_desc riptiv eAt tr
Dimensional elaborate,
easier to conform in DW
Dimensional (DW) consolidated
Traditional (DB) Normalized
STORE
st oreKey
StoreDesc riptiv eAt tr
country _k ey (FK)
COUN TR Y
country _k ey
country _des criptiv eAtt r
region_key (FK)
REGION
region_key
region_desc riptiv eAt tr
(cleaved out attributes from) a large dimension (million of records).
Before elaborating details of Dimensional Modeling and Design, let us review principal options for
logical models within relational model (ROLAP) approach and the OMA selection of MVs:
dimens ion
dimens ions
dimension
Logical Modeli ng - D M oti ons
wi thi n R DB MS (ROLAP) D Ws
STORE
storeKey
StoreDesc riptiv eAt tr
country _k ey
country _des criptiv eAtt r
region_key
region_desc riptiv eAt tr
REGION
region_key
region_desc riptiv eAt tr
COUN TR Y
country _key
country _des criptiv eAtt r
region_key (FK)
region_descriptiv eAt tr
STORE
st oreKey
StoreDesc riptiv eAt tr
country _k ey (FK)
country _des criptiv eAtt r
region_key
region_desc riptiv eAt tr
Dimensional elaborate,
easier to conform in DW
Dimensional (DW) consolidated
Traditional (DB) Normalized
STORE
st oreKey
StoreDesc riptiv eAt tr
country _k ey (FK)
COUN TR Y
country _k ey
country _des criptiv eAtt r
region_key (FK)
REGION
region_key
region_desc riptiv eAt tr
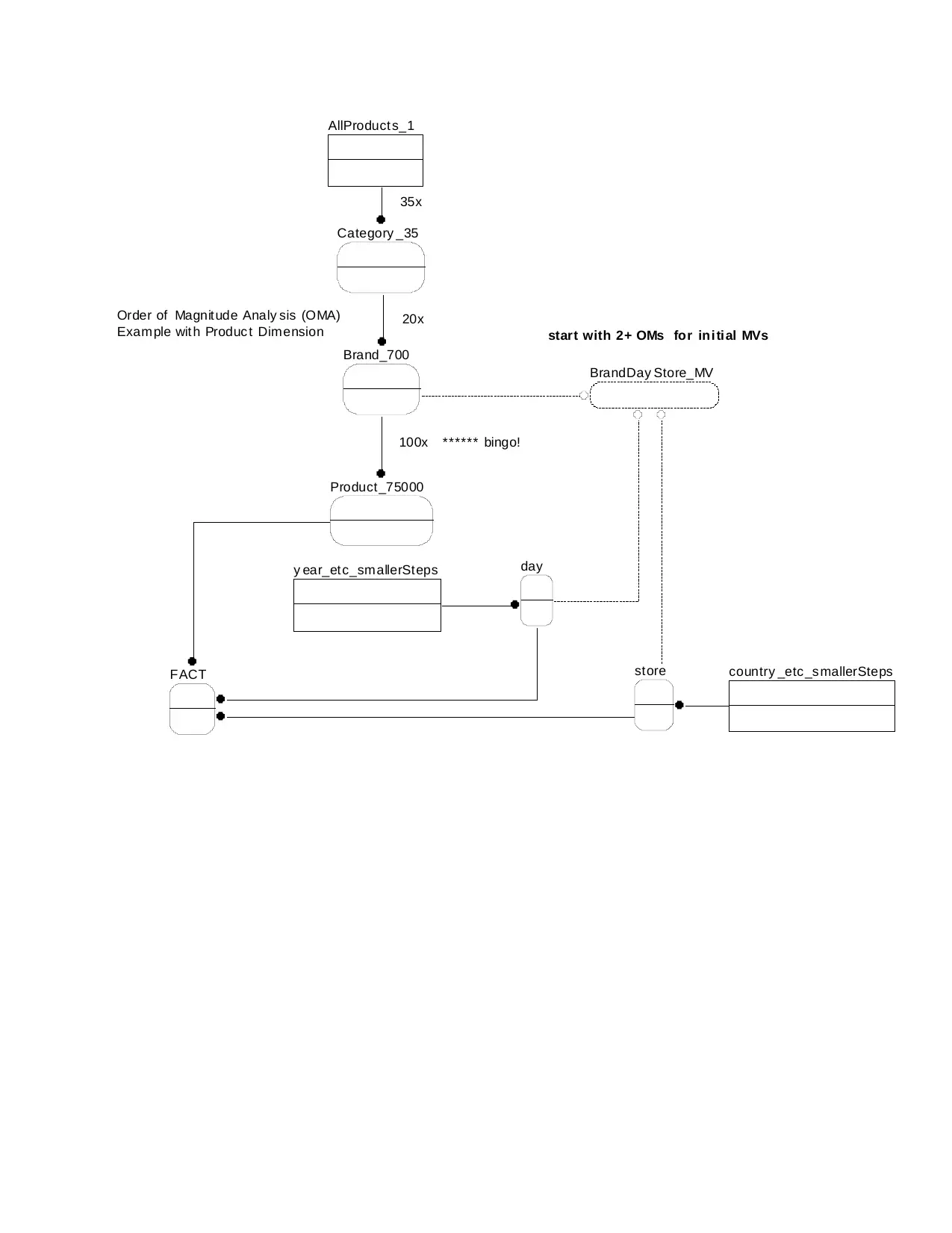
Order of Magnit ude Analy sis (OMA)
Example wit h Produc t Dimension
AllProduct s_1
Category _35
Brand_700
Product _75000
35x
20x
100x ****** bingo!
FACT
day
store country _etc _s mallerSteps
y ear_et c_smallerSteps
BrandDay Store_MV
start with 2+ OMs for ini ti al MVs
Example wit h Produc t Dimension
AllProduct s_1
Category _35
Brand_700
Product _75000
35x
20x
100x ****** bingo!
FACT
day
store country _etc _s mallerSteps
y ear_et c_smallerSteps
BrandDay Store_MV
start with 2+ OMs for ini ti al MVs
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
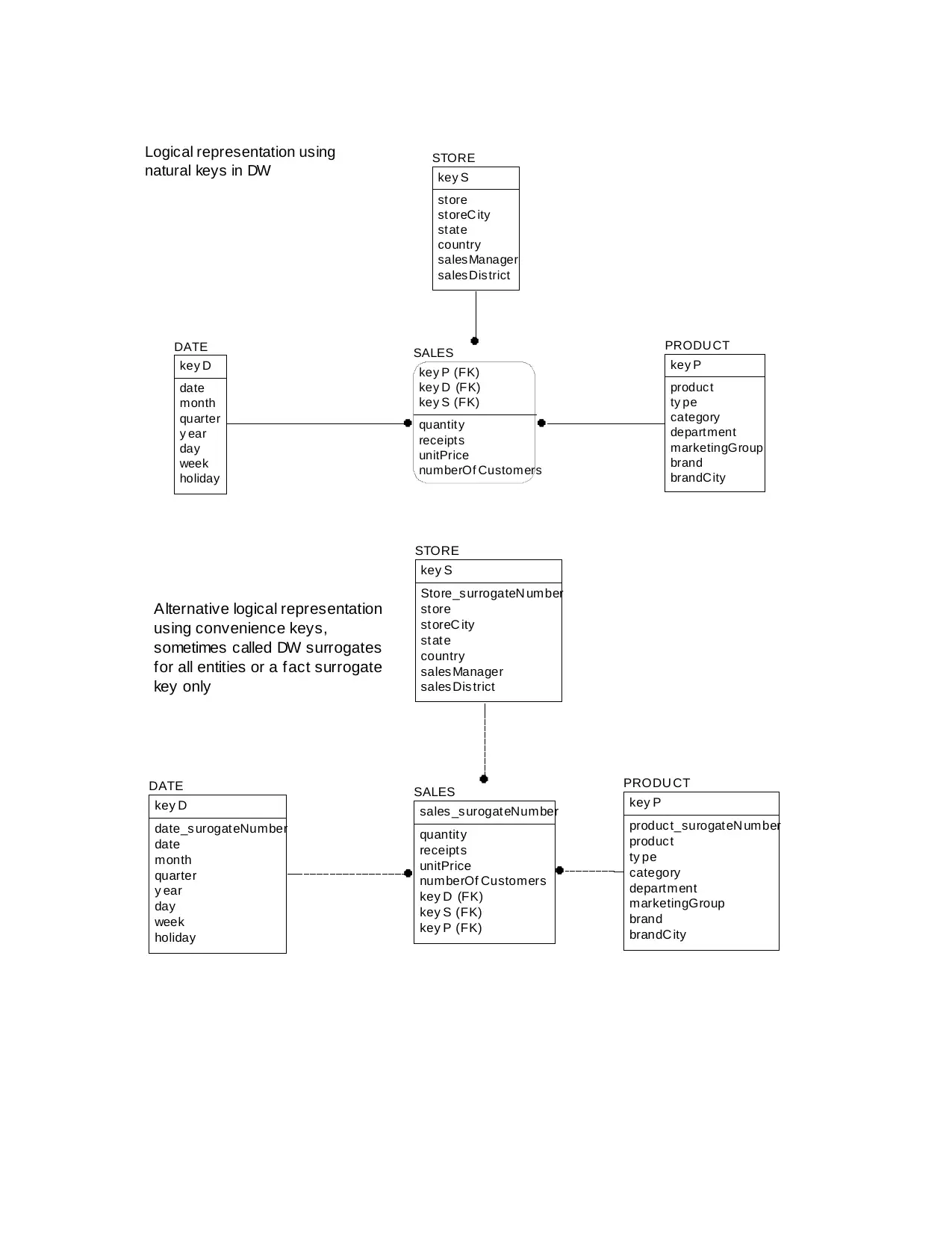
SALES
key P (FK)
key D (FK)
key S (FK)
quantity
receipts
unitPrice
numberOf Customers
DATE
key D
date
month
quarter
y ear
day
week
holiday
STORE
key S
store
storeC ity
state
country
sales Manager
sales Dis trict
PRODU CT
key P
produc t
ty pe
category
department
marketingGroup
brand
brandC ity
Logical representation using
natural keys in DW
Alternative logical representation
using convenience keys,
sometimes called DW surrogates
for all entities or a fact surrogate
key only
STORE
key S
Store_s urrogateN umber
store
storeC ity
state
country
sales Manager
sales Dis trict
SALES
key P (FK)
key D (FK)
key S (FK)
quantit y
receipt s
unitPrice
numberOf Customers
DATE
key D
date
month
quarter
y ear
day
week
holiday
PRODU CT
key P
produc t
ty pe
category
depart ment
marketingGroup
brand
brandC ity
Alternative logical representation
using convenience keys,
sometimes called DW surrogates
for all entities or a fact surrogate
key only
PRODU CT
key P
produc t_surogat eN umber
produc t
ty pe
category
depart ment
marketingGroup
brand
brandC ity
STORE
key S
Store_s urrogateN umber
st ore
st oreC ity
st at e
country
sales Manager
sales Dis trict
DATE
key D
date_s urogat eNumber
date
month
quarter
y ear
day
week
holiday
SALES
sales _s urogat eNumber
quantit y
receipt s
unitPrice
numberOf Customers
key D (FK)
key S (FK)
key P (FK)
key P (FK)
key D (FK)
key S (FK)
quantity
receipts
unitPrice
numberOf Customers
DATE
key D
date
month
quarter
y ear
day
week
holiday
STORE
key S
store
storeC ity
state
country
sales Manager
sales Dis trict
PRODU CT
key P
produc t
ty pe
category
department
marketingGroup
brand
brandC ity
Logical representation using
natural keys in DW
Alternative logical representation
using convenience keys,
sometimes called DW surrogates
for all entities or a fact surrogate
key only
STORE
key S
Store_s urrogateN umber
store
storeC ity
state
country
sales Manager
sales Dis trict
SALES
key P (FK)
key D (FK)
key S (FK)
quantit y
receipt s
unitPrice
numberOf Customers
DATE
key D
date
month
quarter
y ear
day
week
holiday
PRODU CT
key P
produc t
ty pe
category
depart ment
marketingGroup
brand
brandC ity
Alternative logical representation
using convenience keys,
sometimes called DW surrogates
for all entities or a fact surrogate
key only
PRODU CT
key P
produc t_surogat eN umber
produc t
ty pe
category
depart ment
marketingGroup
brand
brandC ity
STORE
key S
Store_s urrogateN umber
st ore
st oreC ity
st at e
country
sales Manager
sales Dis trict
DATE
key D
date_s urogat eNumber
date
month
quarter
y ear
day
week
holiday
SALES
sales _s urogat eNumber
quantit y
receipt s
unitPrice
numberOf Customers
key D (FK)
key S (FK)
key P (FK)
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
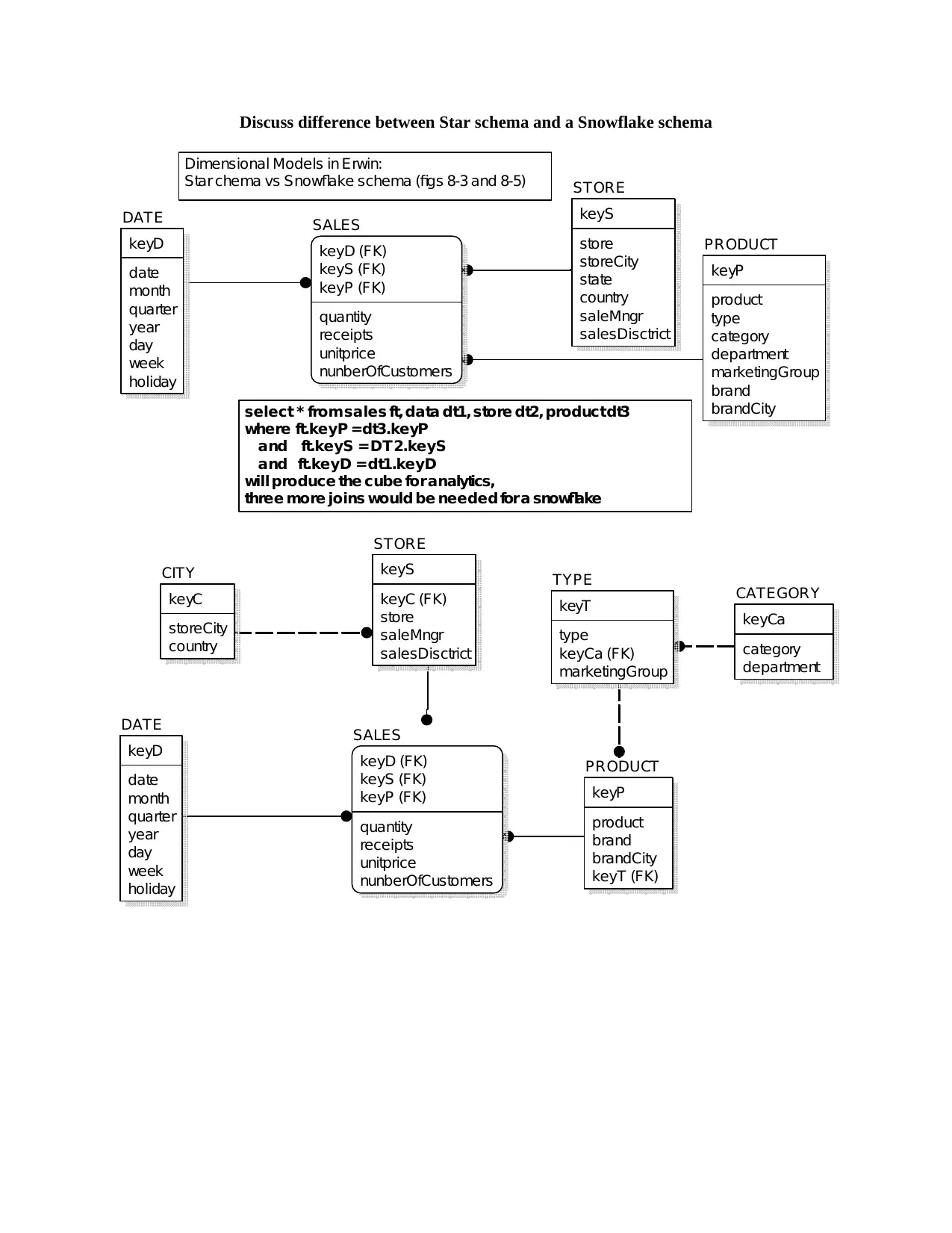
Discuss difference between Star schema and a Snowflake schema
Dimensional Models in Erwin:
Star chema vs Snowflake schema (figs 8-3 and 8-5)
select * from sales ft, data dt1, store dt2, productdt3
where ft.keyP =dt3.keyP
and ft.keyS =DT2.keyS
and ft.keyD =dt1.keyD
will produce the cube for analytics,
three more joins would be needed for a snowflake
DATE
keyD
date
month
quarter
year
day
week
holiday
SALES
keyD (FK)
keyS (FK)
keyP (FK)
quantity
receipts
unitprice
nunberOfCustomers
STORE
keyS
store
storeCity
state
country
saleMngr
salesDisctrict
PRODUCT
keyP
product
type
category
department
marketingGroup
brand
brandCity
DATE
keyD
date
month
quarter
year
day
week
holiday
SALES
keyD (FK)
keyS (FK)
keyP (FK)
quantity
receipts
unitprice
nunberOfCustomers
PRODUCT
keyP
product
brand
brandCity
keyT (FK)
STORE
keyS
keyC (FK)
store
saleMngr
salesDisctrict
CITY
keyC
storeCity
country
TYPE
keyT
type
keyCa (FK)
marketingGroup
CATEGORY
keyCa
category
department
Dimensional Models in Erwin:
Star chema vs Snowflake schema (figs 8-3 and 8-5)
select * from sales ft, data dt1, store dt2, productdt3
where ft.keyP =dt3.keyP
and ft.keyS =DT2.keyS
and ft.keyD =dt1.keyD
will produce the cube for analytics,
three more joins would be needed for a snowflake
DATE
keyD
date
month
quarter
year
day
week
holiday
SALES
keyD (FK)
keyS (FK)
keyP (FK)
quantity
receipts
unitprice
nunberOfCustomers
STORE
keyS
store
storeCity
state
country
saleMngr
salesDisctrict
PRODUCT
keyP
product
type
category
department
marketingGroup
brand
brandCity
DATE
keyD
date
month
quarter
year
day
week
holiday
SALES
keyD (FK)
keyS (FK)
keyP (FK)
quantity
receipts
unitprice
nunberOfCustomers
PRODUCT
keyP
product
brand
brandCity
keyT (FK)
STORE
keyS
keyC (FK)
store
saleMngr
salesDisctrict
CITY
keyC
storeCity
country
TYPE
keyT
type
keyCa (FK)
marketingGroup
CATEGORY
keyCa
category
department
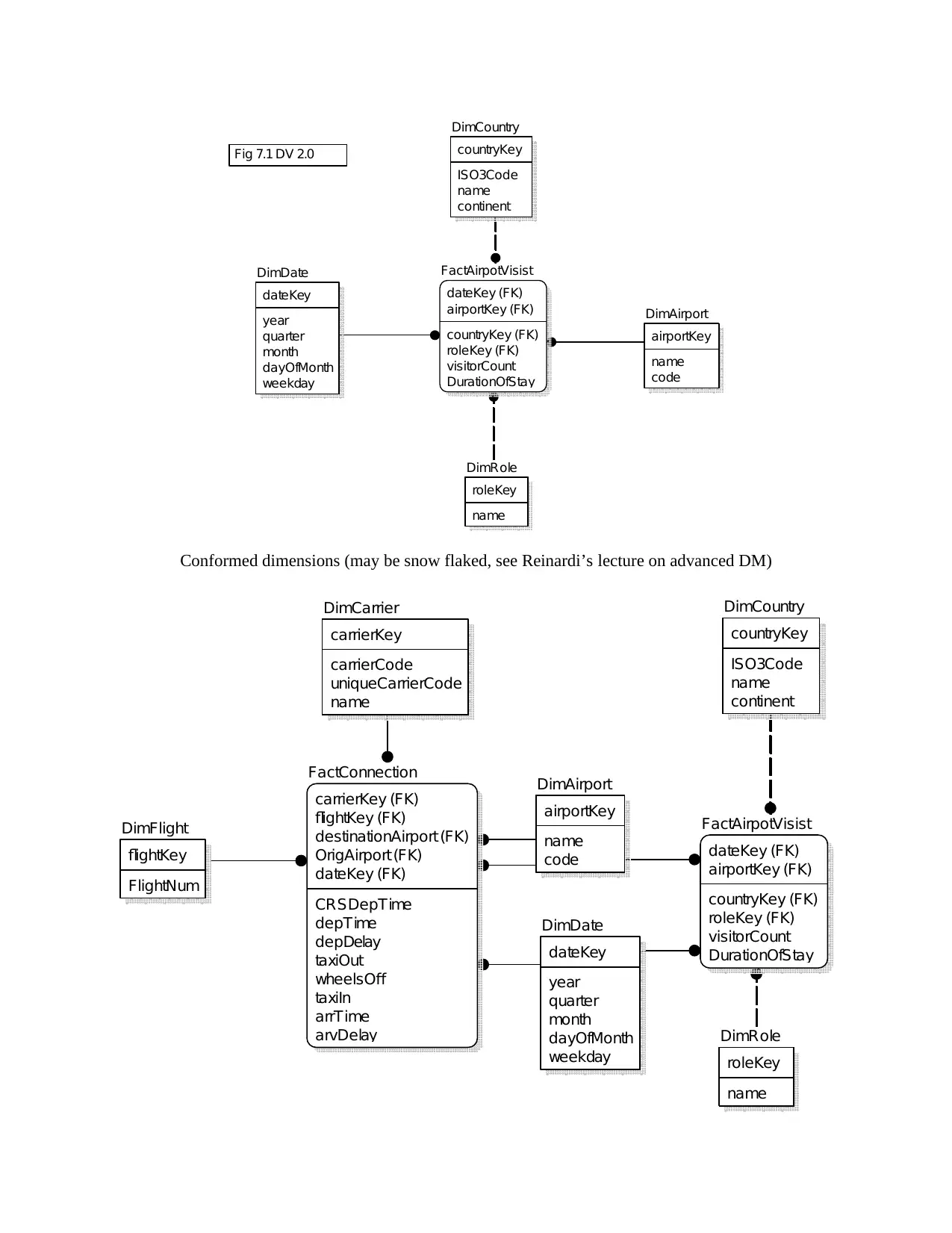
Fig 7.1 DV 2.0
DimCountry
countryKey
ISO3Code
name
continent
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimAirport
airportKey
name
code
DimRole
roleKey
name
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
Conformed dimensions (may be snow flaked, see Reinardi’s lecture on advanced DM)
DimCarrier
carrierKey
carrierCode
uniqueCarrierCode
name
FactConnection
carrierKey (FK)
flightKey (FK)
destinationAirport (FK)
OrigAirport (FK)
dateKey (FK)
CRSDepTime
depTime
depDelay
taxiOut
wheelsOff
taxiIn
arrTime
arvDelay
DimFlight
flightKey
FlightNum
DimAirport
airportKey
name
code
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimRole
roleKey
name
DimCountry
countryKey
ISO3Code
name
continent
DimCountry
countryKey
ISO3Code
name
continent
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimAirport
airportKey
name
code
DimRole
roleKey
name
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
Conformed dimensions (may be snow flaked, see Reinardi’s lecture on advanced DM)
DimCarrier
carrierKey
carrierCode
uniqueCarrierCode
name
FactConnection
carrierKey (FK)
flightKey (FK)
destinationAirport (FK)
OrigAirport (FK)
dateKey (FK)
CRSDepTime
depTime
depDelay
taxiOut
wheelsOff
taxiIn
arrTime
arvDelay
DimFlight
flightKey
FlightNum
DimAirport
airportKey
name
code
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimRole
roleKey
name
DimCountry
countryKey
ISO3Code
name
continent
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
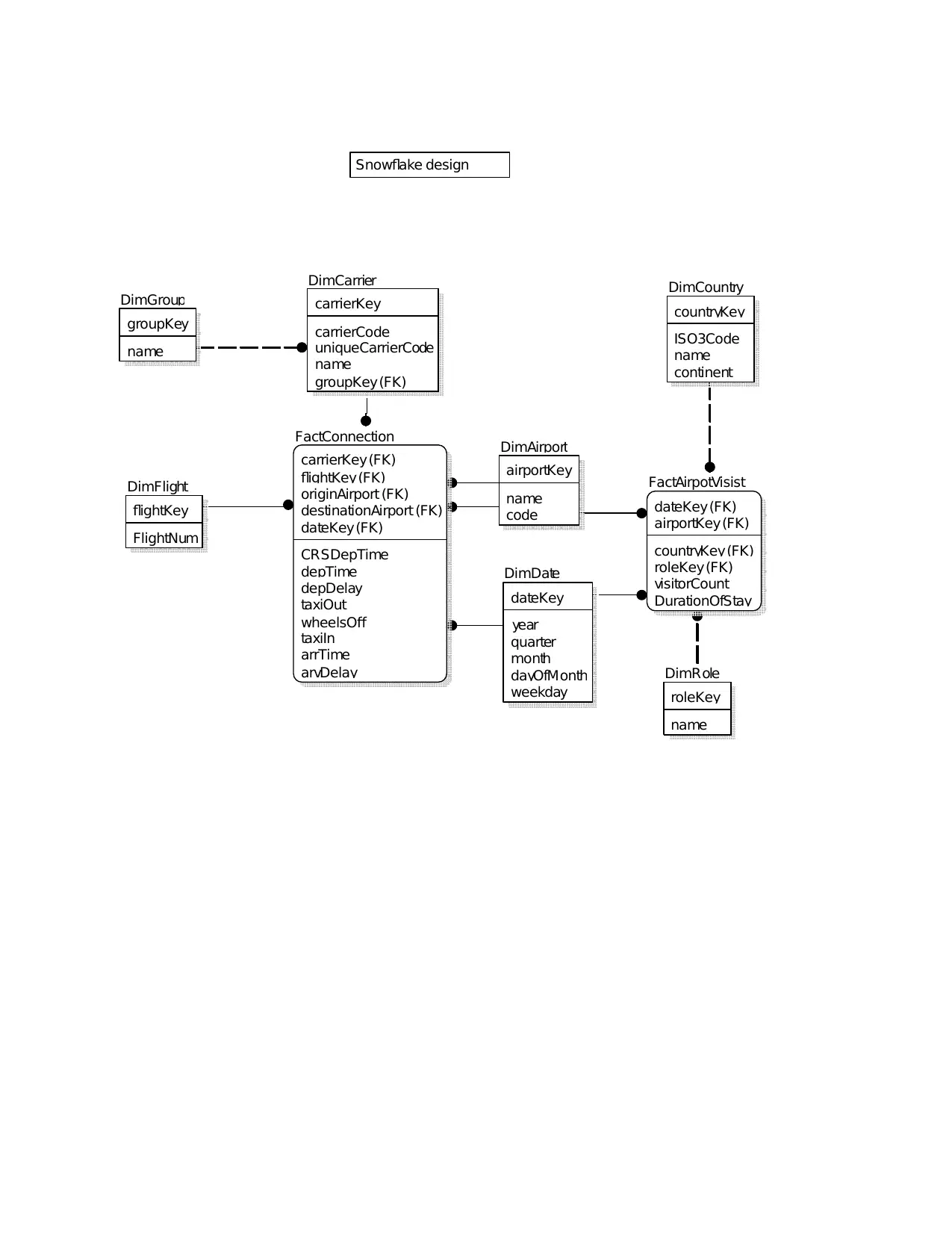
Snowflake design
DimCarrier
carrierKey
carrierCode
uniqueCarrierCode
name
groupKey (FK)
FactConnection
carrierKey (FK)
flightKey (FK)
originAirport (FK)
destinationAirport (FK)
dateKey (FK)
CRSDepTime
depTime
depDelay
taxiOut
wheelsOff
taxiIn
arrTime
arvDelay
DimFlight
flightKey
FlightNum
DimAirport
airportKey
name
code
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimRole
roleKey
name
DimCountry
countryKey
ISO3Code
name
continent
DimGroup
groupKey
name
DimCarrier
carrierKey
carrierCode
uniqueCarrierCode
name
groupKey (FK)
FactConnection
carrierKey (FK)
flightKey (FK)
originAirport (FK)
destinationAirport (FK)
dateKey (FK)
CRSDepTime
depTime
depDelay
taxiOut
wheelsOff
taxiIn
arrTime
arvDelay
DimFlight
flightKey
FlightNum
DimAirport
airportKey
name
code
DimDate
dateKey
year
quarter
month
dayOfMonth
weekday
FactAirpotVisist
dateKey (FK)
airportKey (FK)
countryKey (FK)
roleKey (FK)
visitorCount
DurationOfStay
DimRole
roleKey
name
DimCountry
countryKey
ISO3Code
name
continent
DimGroup
groupKey
name
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
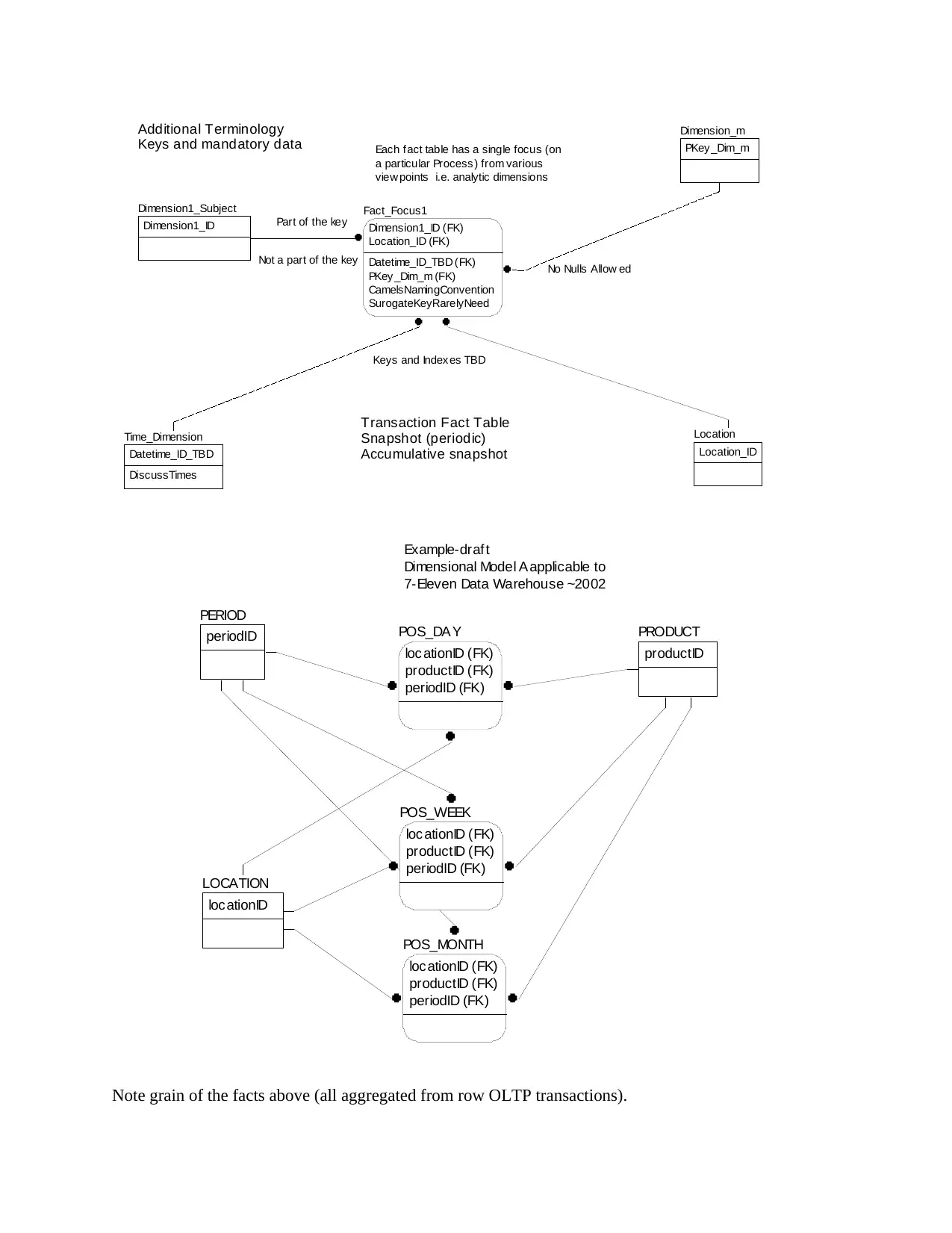
Each fact table has a single focus (on
a particular Process ) from various
view points i.e. analytic dimensions
Not a part of the key
Part of the key
No Nulls Allow ed
Dimension_m
PKey _Dim_m
Location
Location_ID
Additional Terminology
Keys and mandatory data
Keys and Index es TBD
Time_Dimension
Datetime_ID_TBD
DiscussTimes
Dimension1_Subject
Dimension1_ID
Transaction Fact Table
Snapshot (periodic)
Accumulative snapshot
Fact_Focus1
Dimension1_ID (FK)
Location_ID (FK)
Datetime_ID_TBD (FK)
PKey _Dim_m (FK)
CamelsNamingConvention
SurogateKeyRarelyNeed
Example-draf t
Dimensional Model A applicable to
7-Eleven Data Warehouse ~2002
POS_MONTH
loc ationID (FK)
productID (FK)
periodID (FK)
POS_WEEK
loc ationID (FK)
productID (FK)
periodID (FK)
LOCATION
loc ationID
POS_DAY
loc ationID (FK)
productID (FK)
periodID (FK)
PRODUCT
productID
PERIOD
periodID
Note grain of the facts above (all aggregated from row OLTP transactions).
a particular Process ) from various
view points i.e. analytic dimensions
Not a part of the key
Part of the key
No Nulls Allow ed
Dimension_m
PKey _Dim_m
Location
Location_ID
Additional Terminology
Keys and mandatory data
Keys and Index es TBD
Time_Dimension
Datetime_ID_TBD
DiscussTimes
Dimension1_Subject
Dimension1_ID
Transaction Fact Table
Snapshot (periodic)
Accumulative snapshot
Fact_Focus1
Dimension1_ID (FK)
Location_ID (FK)
Datetime_ID_TBD (FK)
PKey _Dim_m (FK)
CamelsNamingConvention
SurogateKeyRarelyNeed
Example-draf t
Dimensional Model A applicable to
7-Eleven Data Warehouse ~2002
POS_MONTH
loc ationID (FK)
productID (FK)
periodID (FK)
POS_WEEK
loc ationID (FK)
productID (FK)
periodID (FK)
LOCATION
loc ationID
POS_DAY
loc ationID (FK)
productID (FK)
periodID (FK)
PRODUCT
productID
PERIOD
periodID
Note grain of the facts above (all aggregated from row OLTP transactions).
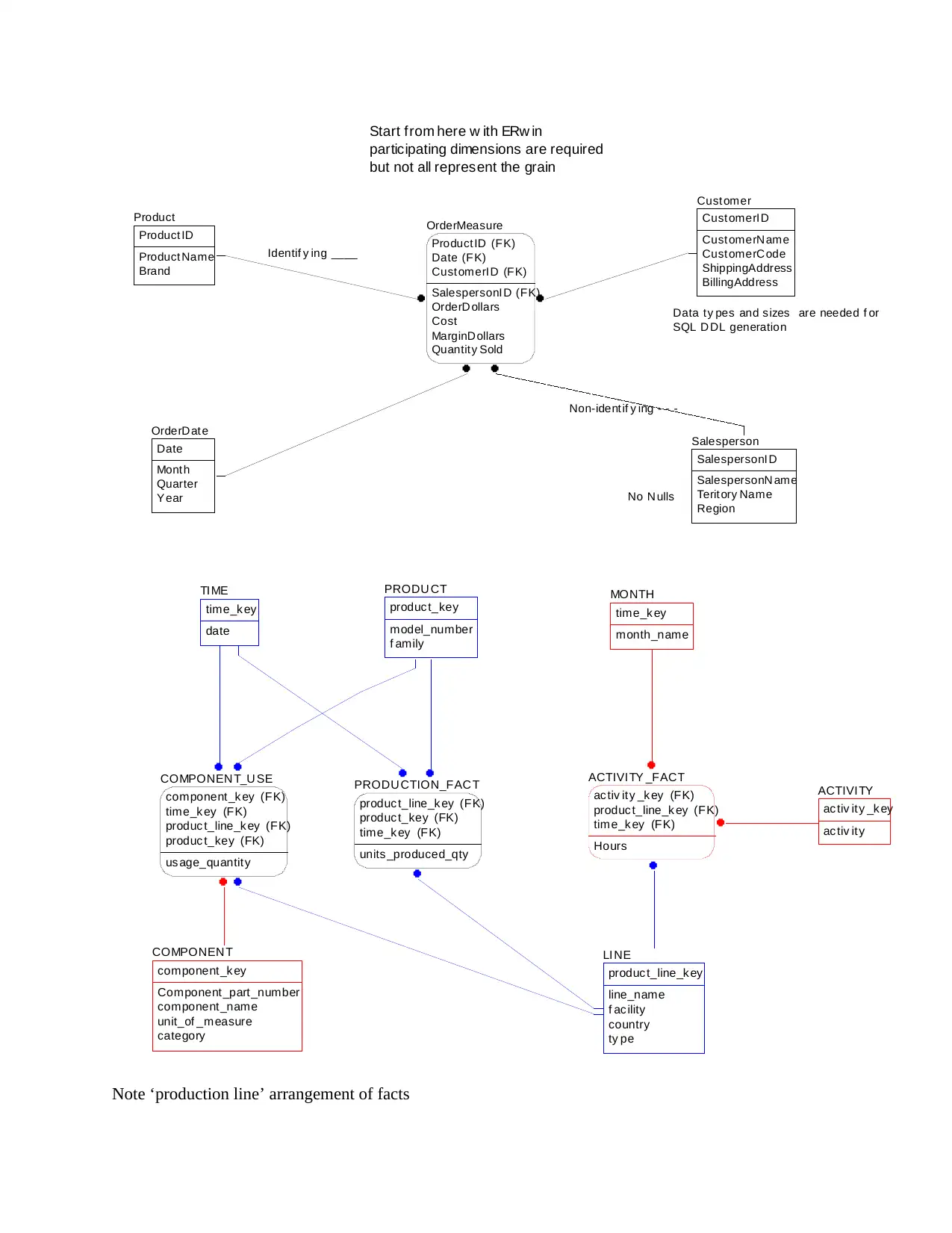
Data ty pes and s izes are needed f or
SQL D DL generation
No N ulls
Identif y ing ____
Non-ident if y ing - - -
Start from here w ith ERw in
participating dimensions are required
but not all represent the grain
Salesperson
SalespersonI D
SalespersonN ame
Terit ory Name
Region
Cust omer
Cust omerID
Cust omerN ame
Cust omerC ode
ShippingAddress
BillingAddress
OrderD at e
Date
Mont h
Quarter
Y ear
Product
Product ID
Product Name
Brand
OrderMeasure
Product ID (FK)
Date (FK)
Cust omerID (FK)
SalespersonI D (FK)
OrderD ollars
Cost
MarginD ollars
Quantity Sold
COMPONEN T
component _k ey
Component _part _number
component _name
unit_of _measure
category
COMPONEN T_U SE
component _k ey (FK)
time_k ey (FK)
produc t_line_k ey (FK)
produc t_key (FK)
us age_quantit y
MONTH
time_k ey
month_name
ACTIVI TY _FACT
ac tiv it y _k ey (FK)
produc t_line_k ey (FK)
time_k ey (FK)
Hours
TI ME
time_k ey
date
ACTIVI TY
ac tiv it y _k ey
ac tiv it y
LI NE
produc t_line_k ey
line_name
f ac ility
country
ty pe
PRODU CT
produc t_key
model_number
f amily
PRODU CTION_FAC T
produc t_line_k ey (FK)
produc t_key (FK)
time_k ey (FK)
units _produced_qty
Note ‘production line’ arrangement of facts
SQL D DL generation
No N ulls
Identif y ing ____
Non-ident if y ing - - -
Start from here w ith ERw in
participating dimensions are required
but not all represent the grain
Salesperson
SalespersonI D
SalespersonN ame
Terit ory Name
Region
Cust omer
Cust omerID
Cust omerN ame
Cust omerC ode
ShippingAddress
BillingAddress
OrderD at e
Date
Mont h
Quarter
Y ear
Product
Product ID
Product Name
Brand
OrderMeasure
Product ID (FK)
Date (FK)
Cust omerID (FK)
SalespersonI D (FK)
OrderD ollars
Cost
MarginD ollars
Quantity Sold
COMPONEN T
component _k ey
Component _part _number
component _name
unit_of _measure
category
COMPONEN T_U SE
component _k ey (FK)
time_k ey (FK)
produc t_line_k ey (FK)
produc t_key (FK)
us age_quantit y
MONTH
time_k ey
month_name
ACTIVI TY _FACT
ac tiv it y _k ey (FK)
produc t_line_k ey (FK)
time_k ey (FK)
Hours
TI ME
time_k ey
date
ACTIVI TY
ac tiv it y _k ey
ac tiv it y
LI NE
produc t_line_k ey
line_name
f ac ility
country
ty pe
PRODU CT
produc t_key
model_number
f amily
PRODU CTION_FAC T
produc t_line_k ey (FK)
produc t_key (FK)
time_k ey (FK)
units _produced_qty
Note ‘production line’ arrangement of facts
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
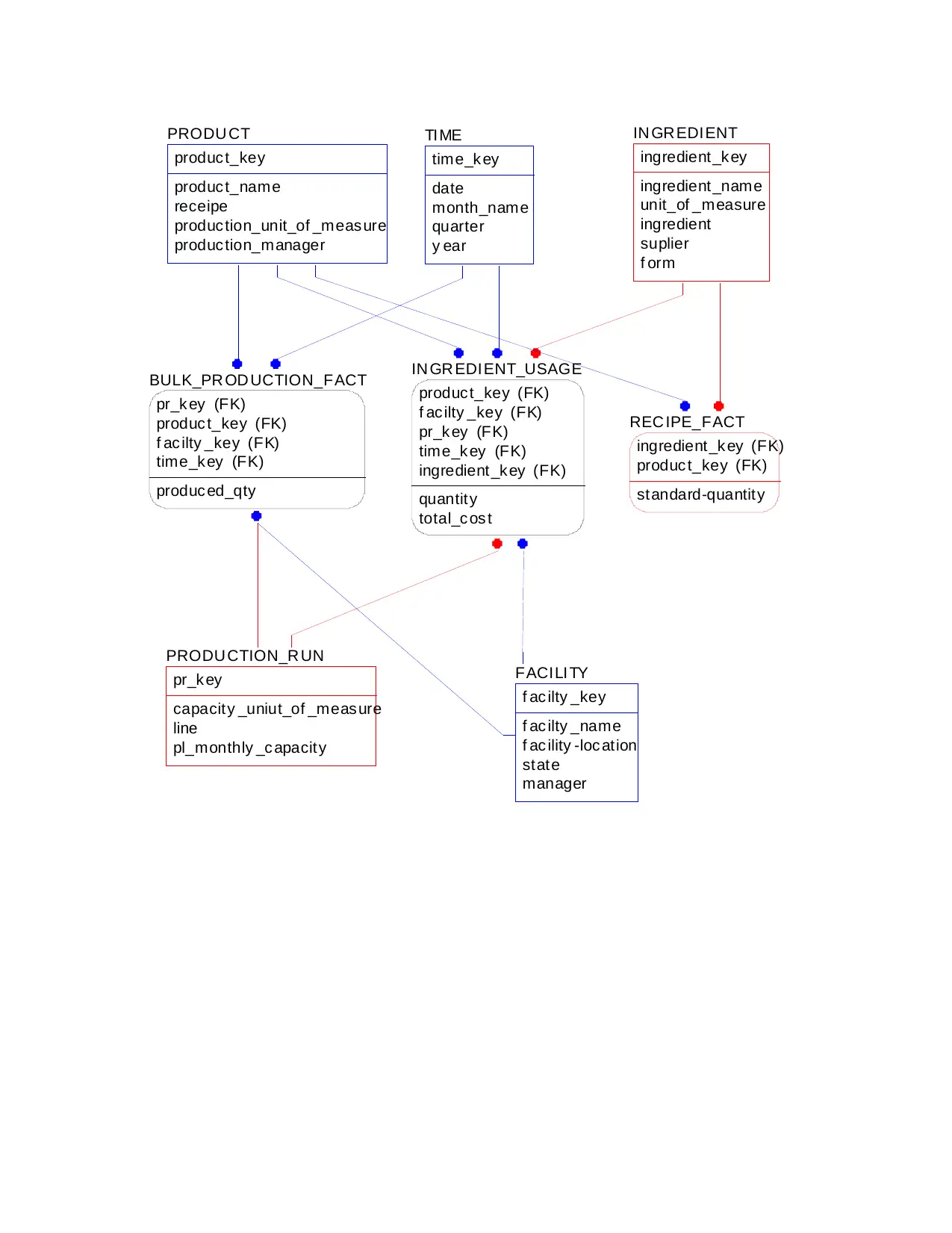
BULK_PR OD UCTION_FACT
pr_k ey (FK)
produc t_key (FK)
f ac ilty _key (FK)
time_k ey (FK)
produc ed_qty
PRODU CT
produc t_key
produc t_name
receipe
produc tion_unit_of _meas ure
produc tion_manager
FACILI TY
f ac ilty _key
f ac ilty _name
f ac ility -loc ation
stat e
manager
IN GR EDI ENT
ingredient _k ey
ingredient _name
unit_of _measure
ingredient
suplier
f orm
TIME
time_k ey
date
month_name
quarter
y ear
REC IPE_FACT
ingredient _k ey (FK)
produc t_key (FK)
standard-quantit y
IN GR EDI ENT_USAGE
produc t_key (FK)
f ac ilty _key (FK)
pr_k ey (FK)
time_k ey (FK)
ingredient _k ey (FK)
quantit y
total_c os t
PRODU CTION_R UN
pr_k ey
capacit y _uniut_of _meas ure
line
pl_monthly _c apacity
pr_k ey (FK)
produc t_key (FK)
f ac ilty _key (FK)
time_k ey (FK)
produc ed_qty
PRODU CT
produc t_key
produc t_name
receipe
produc tion_unit_of _meas ure
produc tion_manager
FACILI TY
f ac ilty _key
f ac ilty _name
f ac ility -loc ation
stat e
manager
IN GR EDI ENT
ingredient _k ey
ingredient _name
unit_of _measure
ingredient
suplier
f orm
TIME
time_k ey
date
month_name
quarter
y ear
REC IPE_FACT
ingredient _k ey (FK)
produc t_key (FK)
standard-quantit y
IN GR EDI ENT_USAGE
produc t_key (FK)
f ac ilty _key (FK)
pr_k ey (FK)
time_k ey (FK)
ingredient _k ey (FK)
quantit y
total_c os t
PRODU CTION_R UN
pr_k ey
capacit y _uniut_of _meas ure
line
pl_monthly _c apacity
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
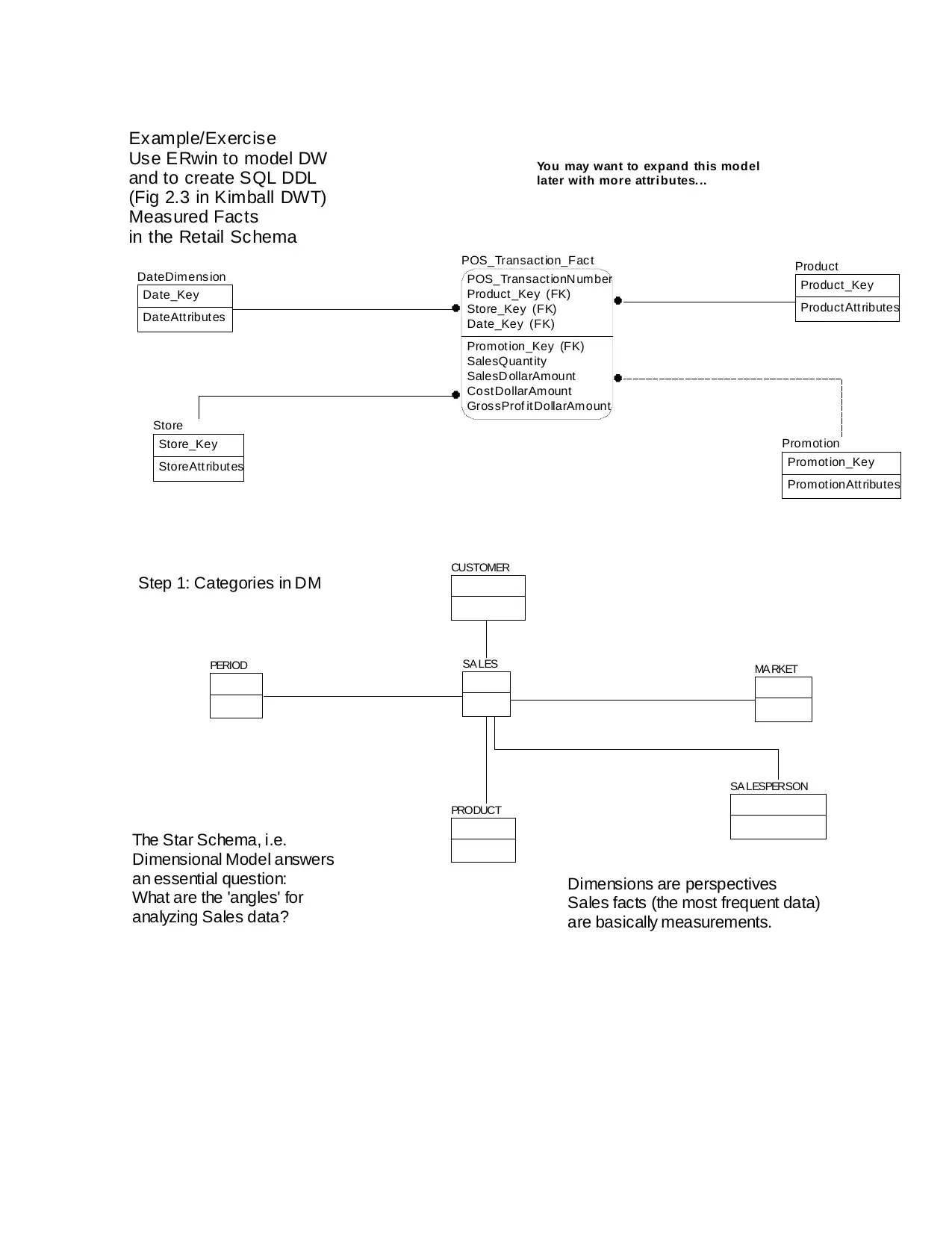
You may want to expand this model
later with more attri butes. ..
Example/Exercise
Use ERwin to model DW
and to create SQL DDL
(Fig 2.3 in Kimball DWT)
Measured Facts
in the Retail Schema
Promot ion
Promot ion_Key
Promot ionAtt ributes
Store
Store_Key
StoreAtt ribut es
Product
Product _Key
Product Att ributes
POS_Transact ion_Fac t
POS_Transact ionN umber
Product _Key (FK)
Store_Key (FK)
Date_Key (FK)
Promot ion_Key (FK)
SalesQuant ity
SalesD ollarAmount
CostDollarAmount
GrossProf it DollarAmount
DateDimens ion
Date_Key
DateAtt ribut es
CUSTOMER
MA RKET
PRODUCT
PERIOD SALES
The Star Schema, i.e.
Dimensional Model answers
an essential question:
What are the 'angles' for
analyzing Sales data?
Dimensions are perspectives
Sales facts (the most frequent data)
are basically measurements.
Step 1: Categories in DM
SALESPERSON
later with more attri butes. ..
Example/Exercise
Use ERwin to model DW
and to create SQL DDL
(Fig 2.3 in Kimball DWT)
Measured Facts
in the Retail Schema
Promot ion
Promot ion_Key
Promot ionAtt ributes
Store
Store_Key
StoreAtt ribut es
Product
Product _Key
Product Att ributes
POS_Transact ion_Fac t
POS_Transact ionN umber
Product _Key (FK)
Store_Key (FK)
Date_Key (FK)
Promot ion_Key (FK)
SalesQuant ity
SalesD ollarAmount
CostDollarAmount
GrossProf it DollarAmount
DateDimens ion
Date_Key
DateAtt ribut es
CUSTOMER
MA RKET
PRODUCT
PERIOD SALES
The Star Schema, i.e.
Dimensional Model answers
an essential question:
What are the 'angles' for
analyzing Sales data?
Dimensions are perspectives
Sales facts (the most frequent data)
are basically measurements.
Step 1: Categories in DM
SALESPERSON
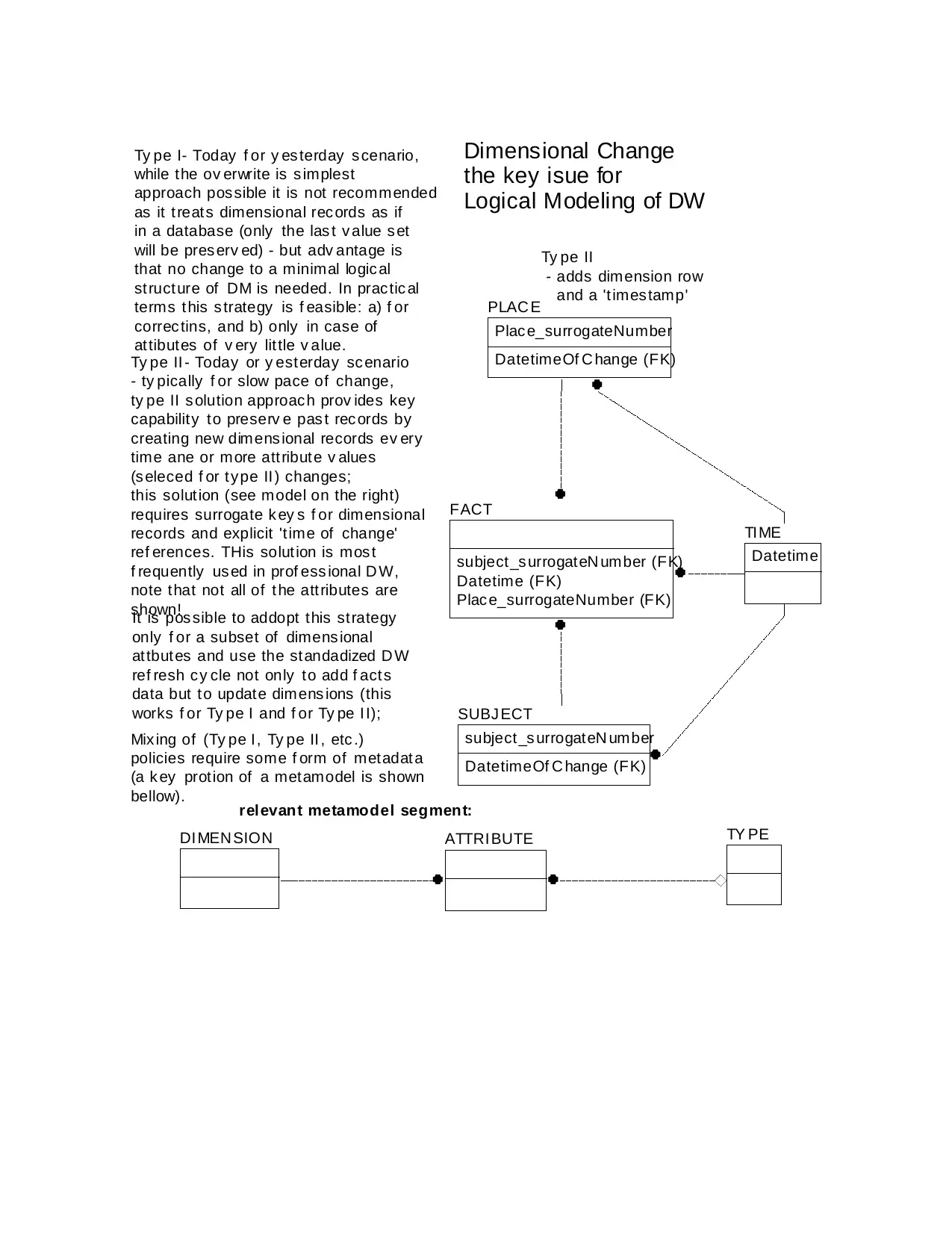
Ty pe II
- adds dimension row
and a 'times tamp'
rel evant metamodel segment:
Mix ing of (Ty pe I , Ty pe II , etc .)
policies require some f orm of met adat a
(a k ey prot ion of a met amodel is shown
bellow).
Ty pe II - Today or y est erday sc enario
- ty pically f or slow pace of change,
ty pe II s olution approac h prov ides key
capability t o preserv e pas t rec ords by
creating new dimens ional records ev ery
time ane or more att ribut e v alues
(s eleced f or t y pe II ) changes;
this solut ion (see model on the right)
requires surrogate k ey s f or dimensional
records and explicit 't ime of change'
ref erences. THis solut ion is mos t
f requently us ed in prof ess ional D W,
note that not all of t he att ributes are
shown!
TY PEATTRI BUTEDIMEN SION
It is pos sible to addopt t his st rategy
only f or a subset of dimens ional
attbut es and use the st andadized D W
ref resh c y cle not only t o add f act s
data but t o updat e dimens ions (this
works f or Ty pe I and f or Ty pe I I);
Ty pe I- Today f or y es terday s cenario,
while the ov erwrite is s implest
approach pos sible it is not recommended
as it t reat s dimensional rec ords as if
in a database (only the las t v alue s et
will be pres erv ed) - but adv antage is
that no change to a minimal logic al
st ruct ure of DM is needed. In prac tic al
terms t his s trategy is f easible: a) f or
correc tins, and b) only in case of
at tibutes of v ery lit tle v alue.
Dimensional Change
the key isue for
Logical Modeling of DW
FACT
subject _s urrogateN umber (FK)
Datetime (FK)
Plac e_surrogateNumber (FK)
SUBJ ECT
subject _s urrogateN umber
DatetimeOf C hange (FK)
TIME
Datetime
PLAC E
Plac e_surrogateNumber
DatetimeOf C hange (FK)
- adds dimension row
and a 'times tamp'
rel evant metamodel segment:
Mix ing of (Ty pe I , Ty pe II , etc .)
policies require some f orm of met adat a
(a k ey prot ion of a met amodel is shown
bellow).
Ty pe II - Today or y est erday sc enario
- ty pically f or slow pace of change,
ty pe II s olution approac h prov ides key
capability t o preserv e pas t rec ords by
creating new dimens ional records ev ery
time ane or more att ribut e v alues
(s eleced f or t y pe II ) changes;
this solut ion (see model on the right)
requires surrogate k ey s f or dimensional
records and explicit 't ime of change'
ref erences. THis solut ion is mos t
f requently us ed in prof ess ional D W,
note that not all of t he att ributes are
shown!
TY PEATTRI BUTEDIMEN SION
It is pos sible to addopt t his st rategy
only f or a subset of dimens ional
attbut es and use the st andadized D W
ref resh c y cle not only t o add f act s
data but t o updat e dimens ions (this
works f or Ty pe I and f or Ty pe I I);
Ty pe I- Today f or y es terday s cenario,
while the ov erwrite is s implest
approach pos sible it is not recommended
as it t reat s dimensional rec ords as if
in a database (only the las t v alue s et
will be pres erv ed) - but adv antage is
that no change to a minimal logic al
st ruct ure of DM is needed. In prac tic al
terms t his s trategy is f easible: a) f or
correc tins, and b) only in case of
at tibutes of v ery lit tle v alue.
Dimensional Change
the key isue for
Logical Modeling of DW
FACT
subject _s urrogateN umber (FK)
Datetime (FK)
Plac e_surrogateNumber (FK)
SUBJ ECT
subject _s urrogateN umber
DatetimeOf C hange (FK)
TIME
Datetime
PLAC E
Plac e_surrogateNumber
DatetimeOf C hange (FK)
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 25
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.