Linear Modeling Assignment: Data Analysis and Model Building
VerifiedAdded on 2022/08/19
|12
|1549
|9
Homework Assignment
AI Summary
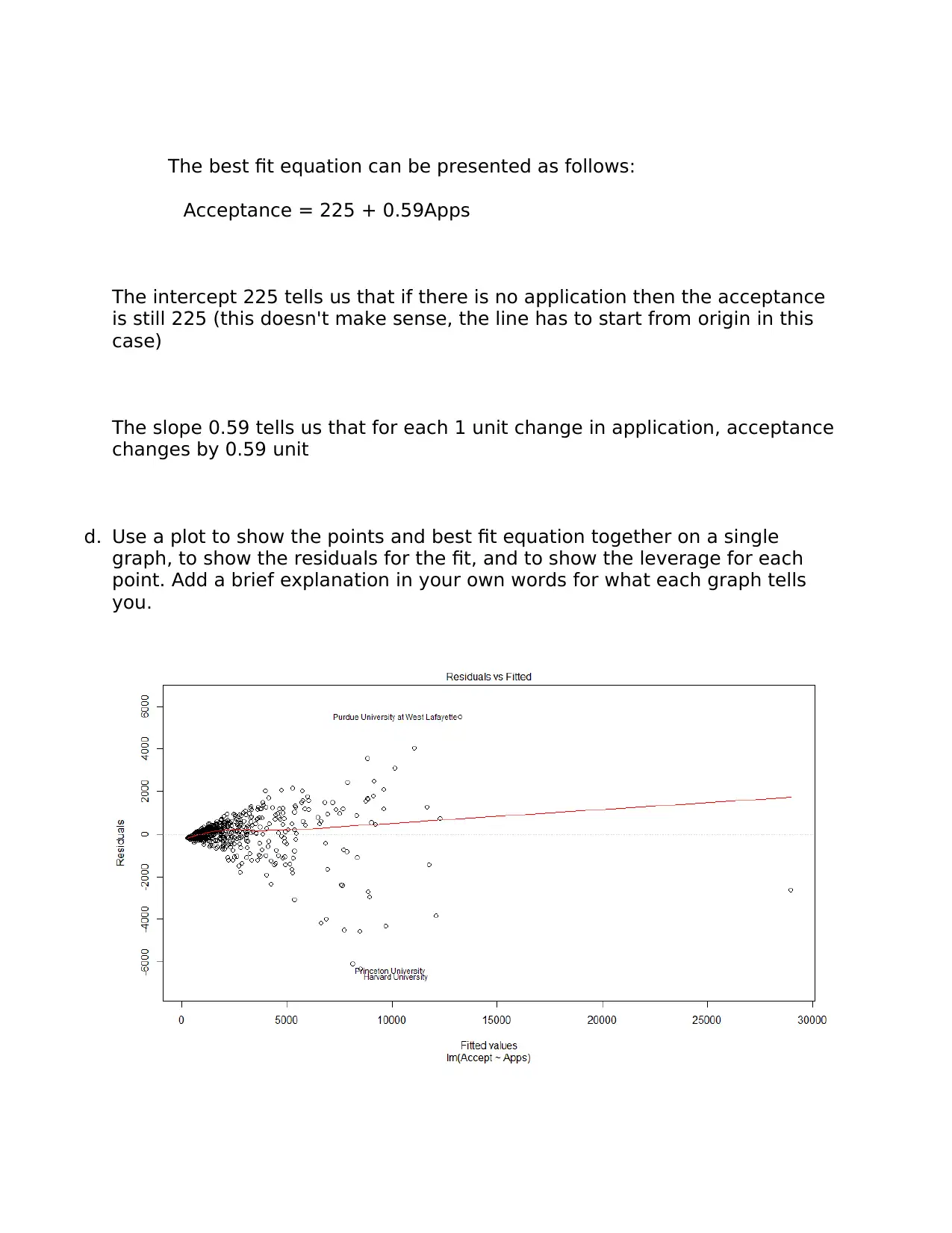
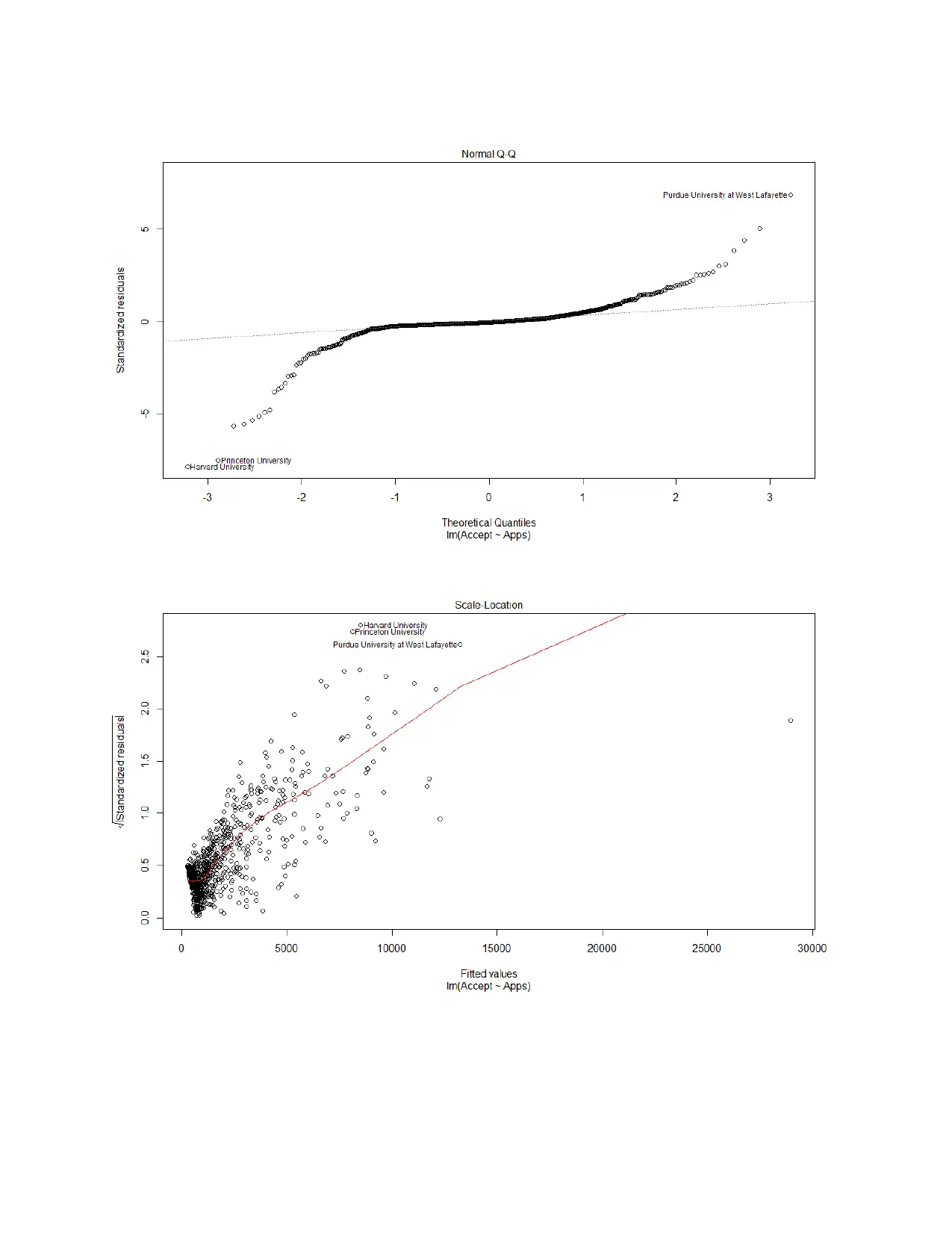
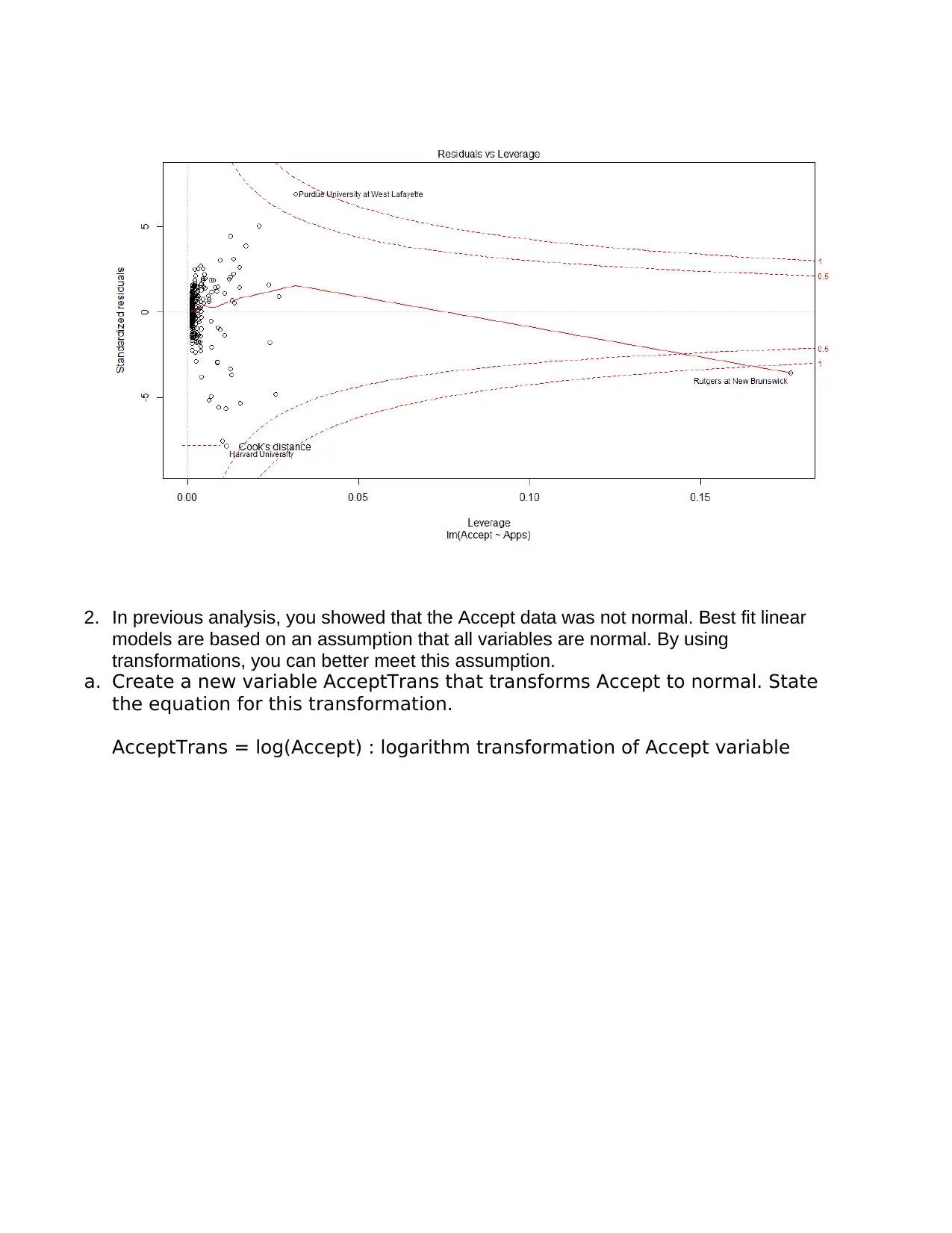
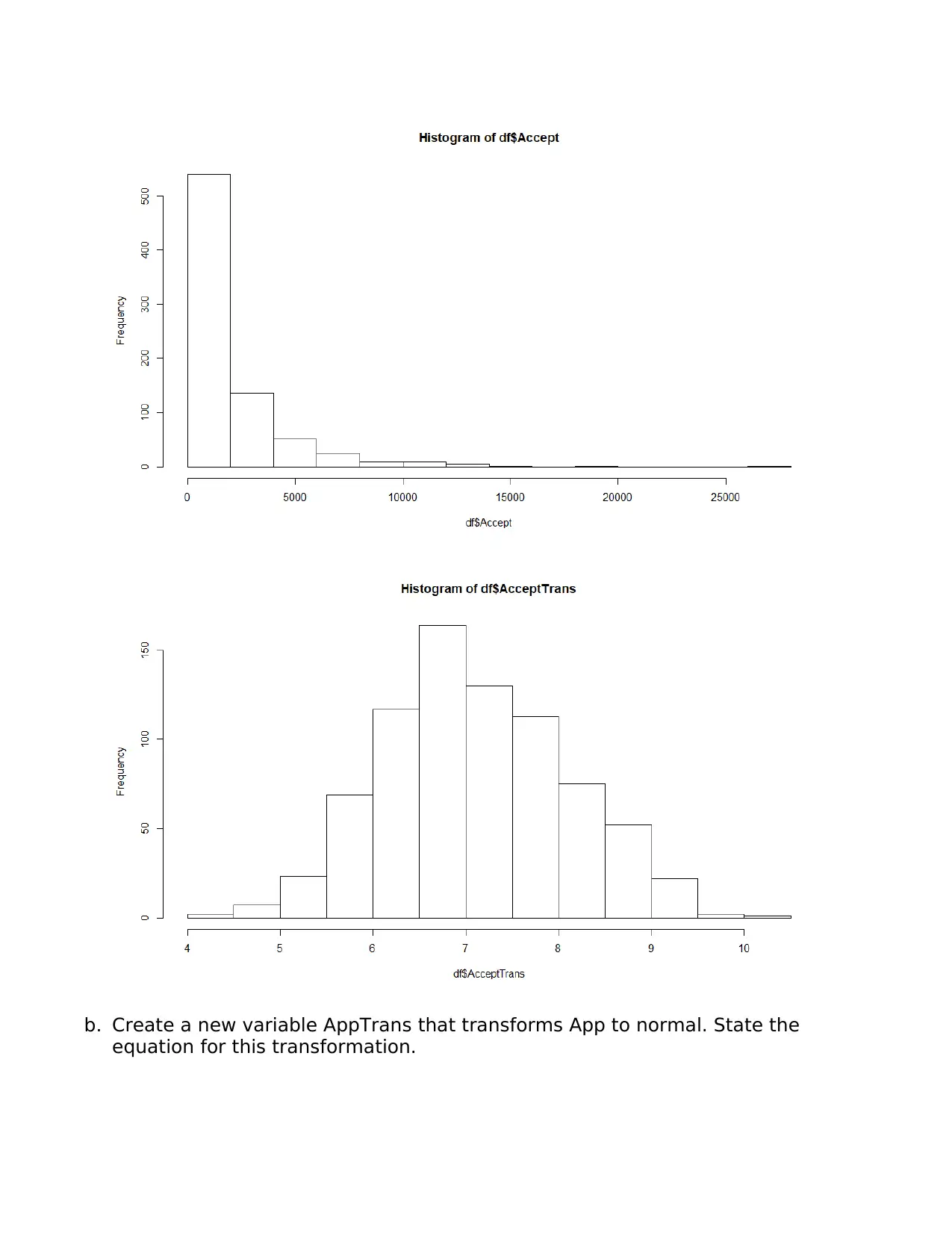
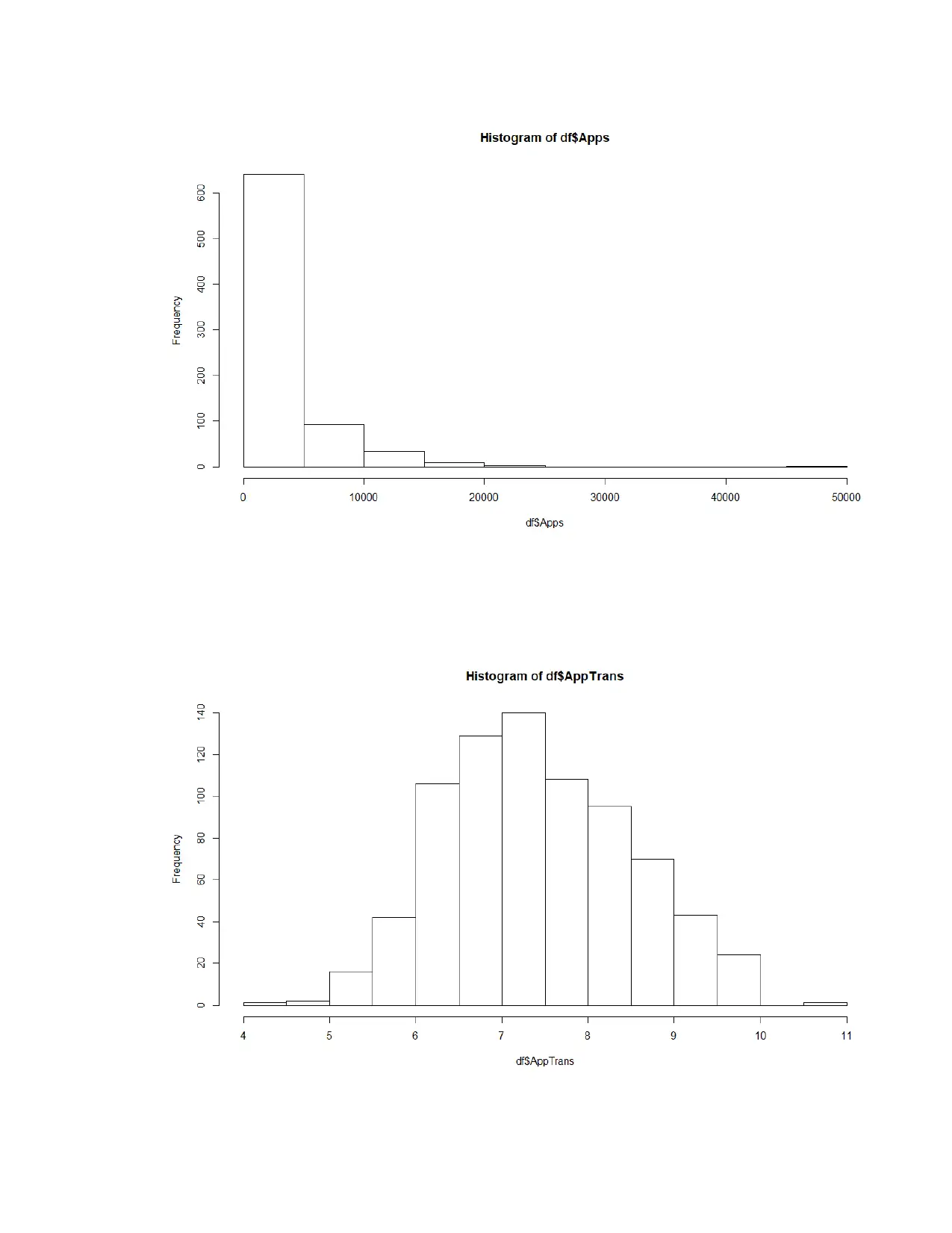
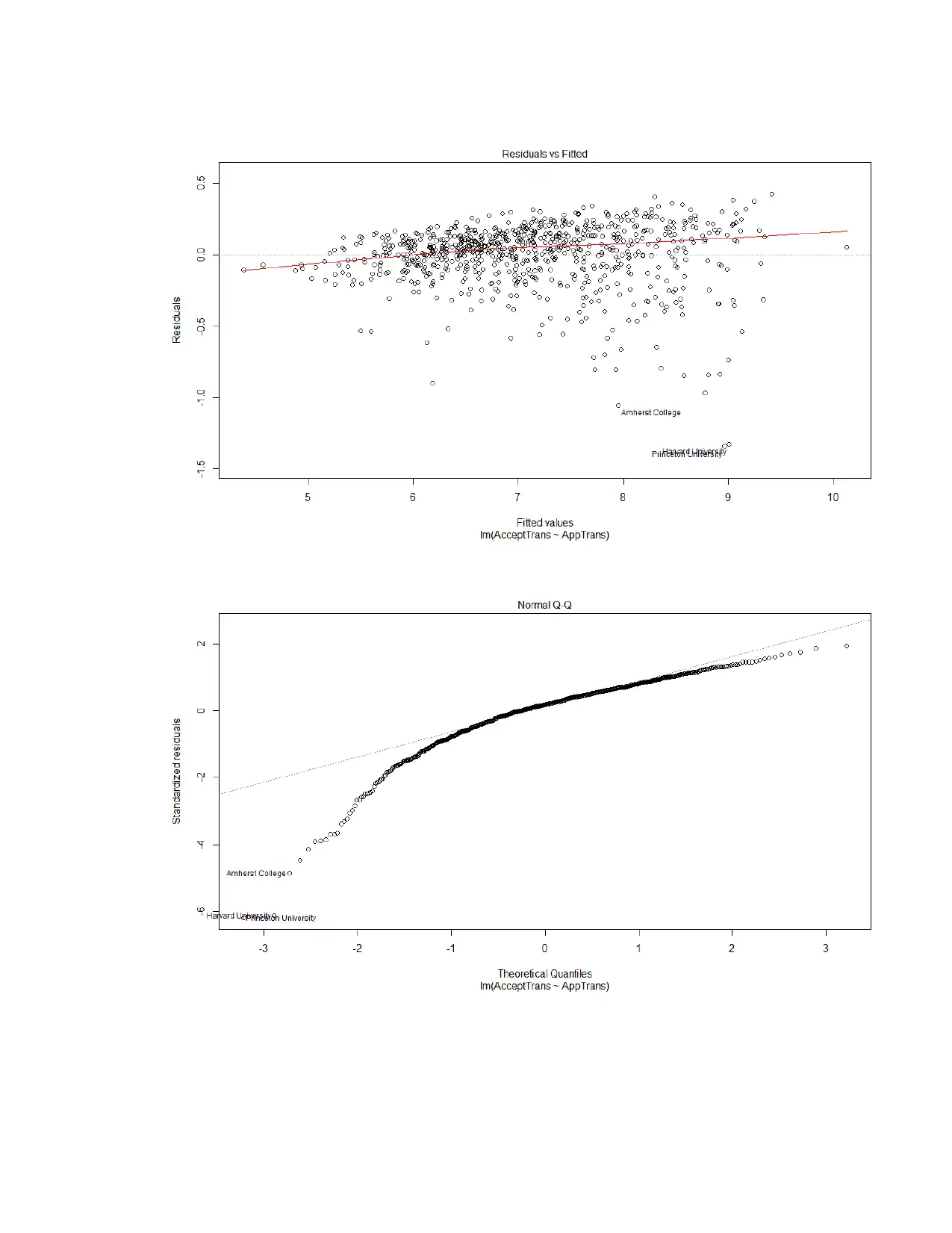
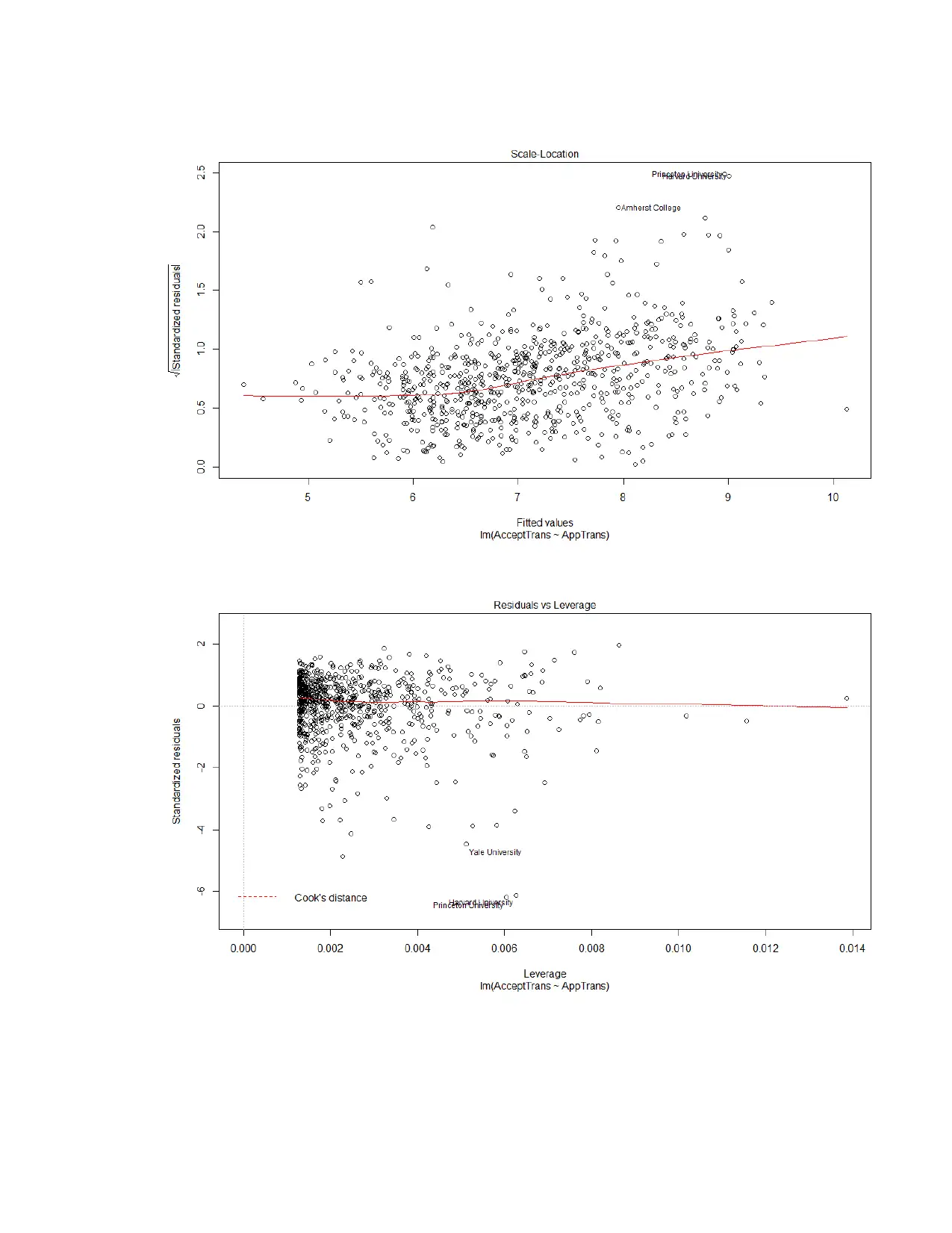
This assignment delves into linear modeling using the ISLR College dataset. It begins by examining the relationship between the number of applicants and acceptances, calculating the correlation coefficient, and constructing a best-fit linear model. The assignment explores the interpretation of the model's equation, including the intercept and slope. It then addresses the non-normality of the data by applying transformations to both the acceptance and application variables to meet the assumptions of linear regression. The analysis includes a second linear model using the transformed variables, alongside an analysis of the assumptions of linear regression. Finally, the assignment concludes with the creation of a model to predict the graduation rate based on various college-related variables, emphasizing the process of model building, variable selection, and the evaluation of the final model's fit. The student utilizes R programming language and statistical concepts throughout the assignment.





1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.