Statistical Analysis of Car Fuel Consumption and Engine Performance
VerifiedAdded on 2022/09/29
|9
|1835
|23
Report
AI Summary
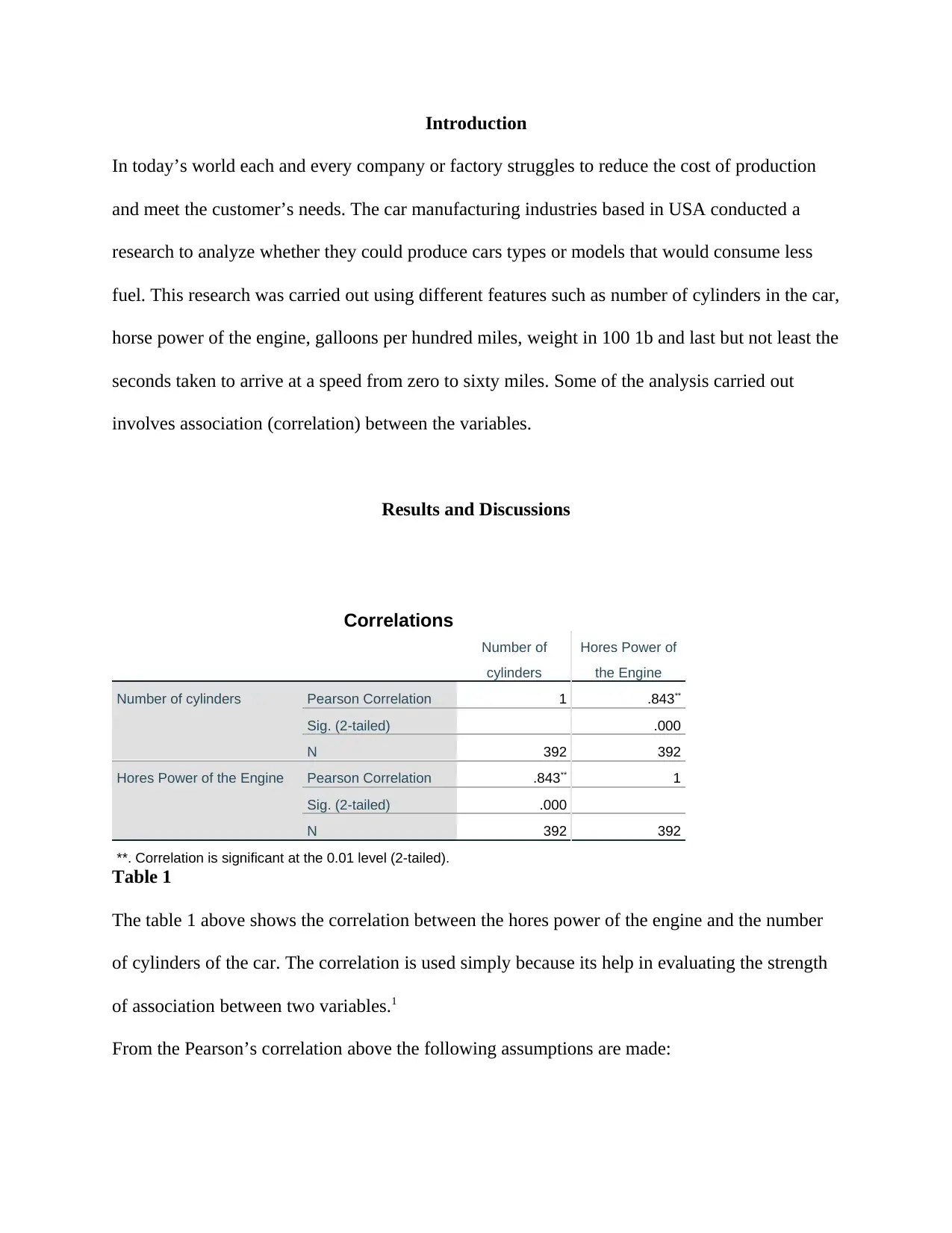
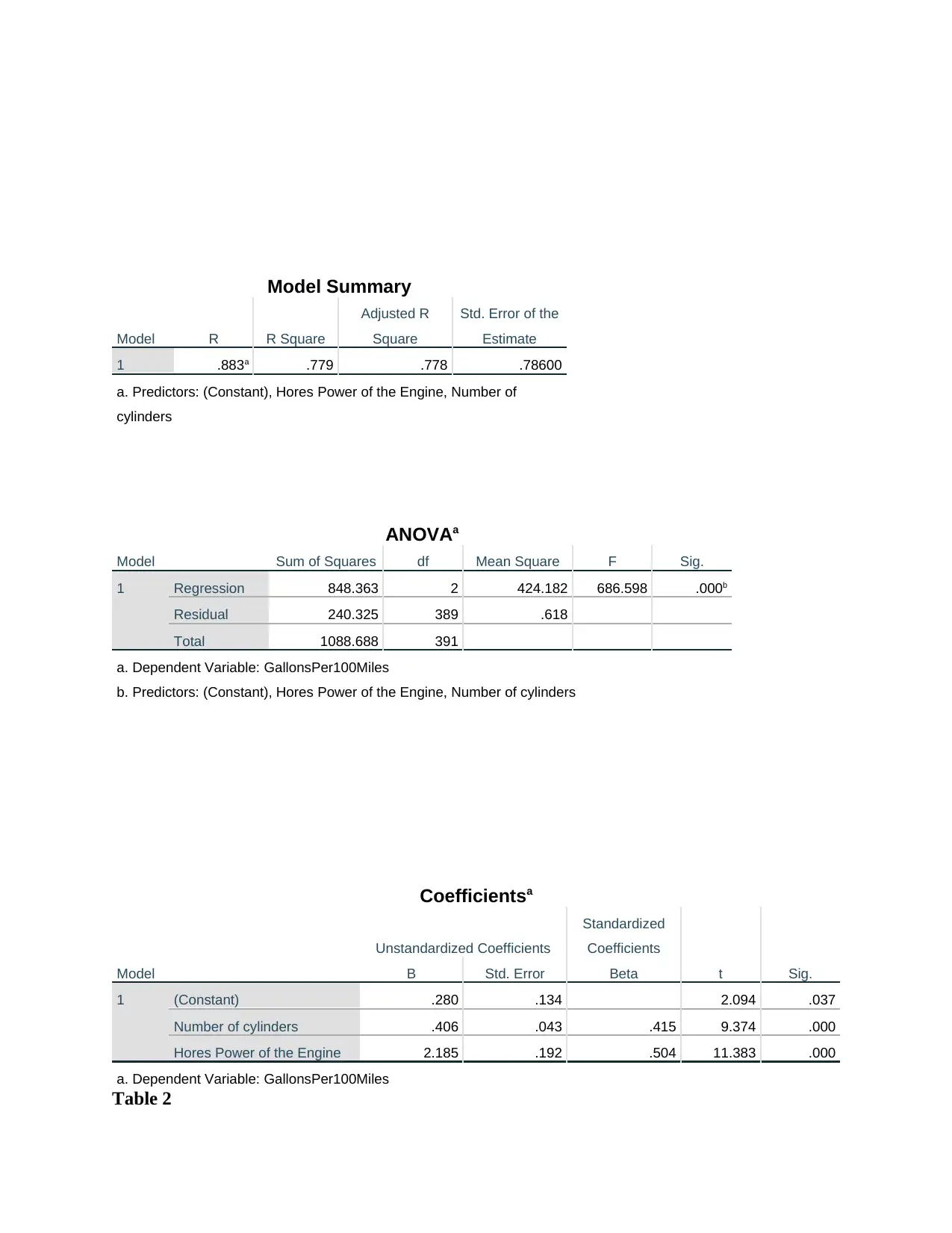
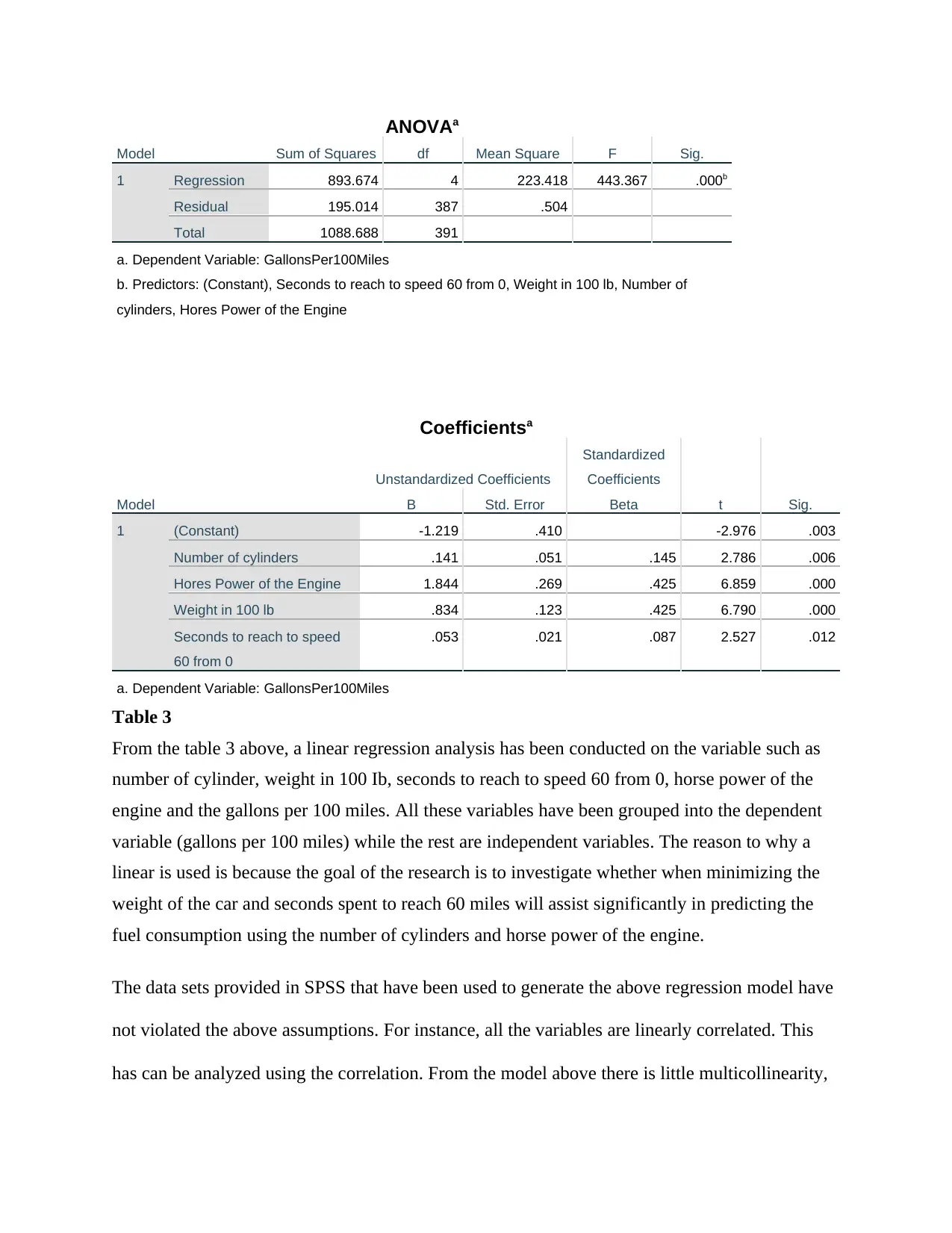
This report presents a statistical analysis of car fuel consumption, focusing on data from the USA car manufacturing industry. The study investigates the relationship between fuel consumption (gallons per 100 miles) and several car features, including the number of cylinders, horsepower of the engine, weight, and the time taken to reach a speed of 60 miles per hour. The analysis utilizes correlation and linear regression techniques to determine the strength and nature of these relationships. The report includes correlation tables and model summaries, with a detailed discussion of the assumptions underlying the statistical methods used, such as the normality of data, multicollinearity, and the linear relationship between variables. The findings reveal significant correlations between engine power, number of cylinders, and fuel consumption, with regression models providing insights into the predictive power of these variables. The report concludes with a discussion of the practical implications of the findings, aiming to aid car manufacturers in understanding and optimizing fuel efficiency.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.