Mathematics and Programming of AI | Report
VerifiedAdded on 2022/09/05
|9
|3268
|20
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Running head: MATHEMATICS AND PROGRAMMING OF AI
Mathematics and Programming of AI
Student Name:
Student ID:
University Name:
Subject Code:
Mathematics and Programming of AI
Student Name:
Student ID:
University Name:
Subject Code:
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

2Mathematics and Programming of AI
Executive Summary
Machine learning is one of the recent buzz in the industries. With machine learning it’s now
possible to recognize images and videos in real-time. The main motive of machine learning is to
learn from previous analysis itself for classification and prediction purposes. There are different
machine learning algorithm out of which Convolutional Neural Network is considered to be one
of the best algorithm to classify and predict the outcomes of the dataset. A CNN is a part of
deep learning algorithms where inputs are taken in the form of images and are assigned with
some importance to differentiate each images respectively. In this analysis two dataset have
been used which consist of images. One dataset consist the images of the street digits and
another dataset consist of images with facial expression. Both the dataset have been trained
using CNN model and at the end the accuracy of the model have been identified. A step by step
analysis have been performed over the datasets with in-depth investigation. At the end
conclusion will be concluded over the performance of the models that were built for classifying
the objects and some future scope for improving the accuracy of the model over same dataset.
Executive Summary
Machine learning is one of the recent buzz in the industries. With machine learning it’s now
possible to recognize images and videos in real-time. The main motive of machine learning is to
learn from previous analysis itself for classification and prediction purposes. There are different
machine learning algorithm out of which Convolutional Neural Network is considered to be one
of the best algorithm to classify and predict the outcomes of the dataset. A CNN is a part of
deep learning algorithms where inputs are taken in the form of images and are assigned with
some importance to differentiate each images respectively. In this analysis two dataset have
been used which consist of images. One dataset consist the images of the street digits and
another dataset consist of images with facial expression. Both the dataset have been trained
using CNN model and at the end the accuracy of the model have been identified. A step by step
analysis have been performed over the datasets with in-depth investigation. At the end
conclusion will be concluded over the performance of the models that were built for classifying
the objects and some future scope for improving the accuracy of the model over same dataset.

3Mathematics and Programming of AI
Table of Contents
Executive Summary..................................................................................................................... 2
Introduction.................................................................................................................................. 4
Discussion................................................................................................................................... 4
Conclusion................................................................................................................................... 8
References.................................................................................................................................. 9
Table of Contents
Executive Summary..................................................................................................................... 2
Introduction.................................................................................................................................. 4
Discussion................................................................................................................................... 4
Conclusion................................................................................................................................... 8
References.................................................................................................................................. 9

4Mathematics and Programming of AI
Introduction
CNN are the neural network that shares their parameters. Convolutional layer consist
few sets of learnable filters (Abadi, 2016). The CNN is a kind of deep learning algorithm which
have the ability to take input in the form of images then each images have been assigned with
some importance to various aspects which can be differentiate from one another (Abadi et al.,
2016). It can be said that for the preprocessing in CNN, it’s much lower in comparison with other
classification algorithms. The architecture of CNN is analogous. There are various layers
available which is used to build the model (Alwzwazy et al., 2016).
There are various types of machine learning algorithms available which includes
supervised learning and unsupervised learning (Cai, Fan & Feris, 2016). The dataset used are
image dataset, SVHN dataset which consist of house numbers in Google street view images
and is a multiclass classification problem with 10 classes and the other dataset is the CK+
which consist of images in the form of facial expression which consist of seven emotion which
are mainly angry, happy, disgust, surprise, afraid, contempt and sad (Boyko, Basystiuk &
Shakhovska, 2018). The CNN model will be used to classify each image and will be evaluated
to find the accuracy between actual labels and predicted labels.
Discussion
The CNN consist of different layers which helps the building of the model (Fagan, 2017).
Different layers used are listed below-
Input layer- The function of the layer is to holds the value of raw pixel values of the
images with the width and height both as 32 and depth as 3.
Convolution Layer- The layer wich is used in the local region in the input to compute the
output of neuron that are connected here are termed as convolutional layers, mainly it
computes between the image patches and the filters with mainly the dot products
available.
ReLu- This function is used for activation function which is applied as element wise,
such as max (0,x), Sigmoid: 1/(1+e^-x) (Ketkar, 2017). Using this function the size of the
volume remain unchanged throughout the function.
Pooling layer- For reducing the spatial size of the convolved feature this layer plays a
vital role and also responsible for the happenings.
Fully connected layer- The purpose of the layer is to produce the results in the form of
class scores and provide the output in one dimensional array of size which is equivalent
to the number of classes present in the dataset by taking the inputs from previous layers.
For the first dataset that is street View House Numbers dataset the steps involved from
importing the library to getting the accuracy of the dataset will be afterwards (Gatys, Ecker &
Bethge, 2016).
At first all the necessary libraries were imported for different purpose, then the dataset are
loaded into train and test sets which will be used for further analysis. From here the pre-
processing stage actually starts where further, the test and train dataset has been splitted (Gulli
& Pal, 2017). After all the pre-processing and analyzing the dataset, it’s time to build the model,
for task 1 implementation of linear and ReLu layers were designed. The below code indicates
the same-
Introduction
CNN are the neural network that shares their parameters. Convolutional layer consist
few sets of learnable filters (Abadi, 2016). The CNN is a kind of deep learning algorithm which
have the ability to take input in the form of images then each images have been assigned with
some importance to various aspects which can be differentiate from one another (Abadi et al.,
2016). It can be said that for the preprocessing in CNN, it’s much lower in comparison with other
classification algorithms. The architecture of CNN is analogous. There are various layers
available which is used to build the model (Alwzwazy et al., 2016).
There are various types of machine learning algorithms available which includes
supervised learning and unsupervised learning (Cai, Fan & Feris, 2016). The dataset used are
image dataset, SVHN dataset which consist of house numbers in Google street view images
and is a multiclass classification problem with 10 classes and the other dataset is the CK+
which consist of images in the form of facial expression which consist of seven emotion which
are mainly angry, happy, disgust, surprise, afraid, contempt and sad (Boyko, Basystiuk &
Shakhovska, 2018). The CNN model will be used to classify each image and will be evaluated
to find the accuracy between actual labels and predicted labels.
Discussion
The CNN consist of different layers which helps the building of the model (Fagan, 2017).
Different layers used are listed below-
Input layer- The function of the layer is to holds the value of raw pixel values of the
images with the width and height both as 32 and depth as 3.
Convolution Layer- The layer wich is used in the local region in the input to compute the
output of neuron that are connected here are termed as convolutional layers, mainly it
computes between the image patches and the filters with mainly the dot products
available.
ReLu- This function is used for activation function which is applied as element wise,
such as max (0,x), Sigmoid: 1/(1+e^-x) (Ketkar, 2017). Using this function the size of the
volume remain unchanged throughout the function.
Pooling layer- For reducing the spatial size of the convolved feature this layer plays a
vital role and also responsible for the happenings.
Fully connected layer- The purpose of the layer is to produce the results in the form of
class scores and provide the output in one dimensional array of size which is equivalent
to the number of classes present in the dataset by taking the inputs from previous layers.
For the first dataset that is street View House Numbers dataset the steps involved from
importing the library to getting the accuracy of the dataset will be afterwards (Gatys, Ecker &
Bethge, 2016).
At first all the necessary libraries were imported for different purpose, then the dataset are
loaded into train and test sets which will be used for further analysis. From here the pre-
processing stage actually starts where further, the test and train dataset has been splitted (Gulli
& Pal, 2017). After all the pre-processing and analyzing the dataset, it’s time to build the model,
for task 1 implementation of linear and ReLu layers were designed. The below code indicates
the same-
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

5Mathematics and Programming of AI
model.add(Conv2D(32, (3,3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
In this layer implementation of forward and backward passes for linear layers and ReLU
activation have been done which is the initial layer of the model.
Then for the task 2 implementation of dropout layer which is used to prevent the neural
network from overfitting (Howse, Joshi and Beyeler, 2016). A common probability for the
dropout layer are 0.25 or 0.50 in both visible and hidden layers. Dropout layer can be used with
most of the layers such as dense layer and many more. The code below shows the
implementation of dropout with different layers.
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
The above code shows the implementation of dropout with maxpool2D layer.
model.add(Dense(512,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
The above code shows the implementation of dropout with dense layer.
Then for task 3 softmax activation function have been implemented because softmax
converts the result or output of the last layer of the neural network into a probability distribution
which provides this function a great advantage (Ketkar, 2017). The issue with softmax is that
this function can’t handle the overflow and underflow condition. Generally, an overflow condition
arises when the data is too large and most of the number are tends to infinity and overflow
condition arises when very small numbers are rounded to zero (Phaisangittisagul, 2016). The
code below shows the implementation of softmax function in the dense layer.
model.add(Dense(nb_classes,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('softmax'))
At the end task 4 is the summation of all the task described above with some extra modification.
In addition, the model consists of l2 regularizer which increase the accuracy further.
In this model the optimizer used is the SGD mainly stochastic gradient descent optimizer which
is the update rule (Rampasek & Goldenberg, 2016).
The learning rate was kept 0.01 for our analysis then decay is 1e-6, epochs is 20 and the batch
size is kept 128.
These values totally depend on personal assumption, these values may vary (Rawat &
Wang, 2017). With these values the model has been evaluated and it have been observed that
the model built performed really well with an accuracy of 93.52% which is quite impressive.
model.add(Conv2D(32, (3,3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
In this layer implementation of forward and backward passes for linear layers and ReLU
activation have been done which is the initial layer of the model.
Then for the task 2 implementation of dropout layer which is used to prevent the neural
network from overfitting (Howse, Joshi and Beyeler, 2016). A common probability for the
dropout layer are 0.25 or 0.50 in both visible and hidden layers. Dropout layer can be used with
most of the layers such as dense layer and many more. The code below shows the
implementation of dropout with different layers.
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
The above code shows the implementation of dropout with maxpool2D layer.
model.add(Dense(512,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
The above code shows the implementation of dropout with dense layer.
Then for task 3 softmax activation function have been implemented because softmax
converts the result or output of the last layer of the neural network into a probability distribution
which provides this function a great advantage (Ketkar, 2017). The issue with softmax is that
this function can’t handle the overflow and underflow condition. Generally, an overflow condition
arises when the data is too large and most of the number are tends to infinity and overflow
condition arises when very small numbers are rounded to zero (Phaisangittisagul, 2016). The
code below shows the implementation of softmax function in the dense layer.
model.add(Dense(nb_classes,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('softmax'))
At the end task 4 is the summation of all the task described above with some extra modification.
In addition, the model consists of l2 regularizer which increase the accuracy further.
In this model the optimizer used is the SGD mainly stochastic gradient descent optimizer which
is the update rule (Rampasek & Goldenberg, 2016).
The learning rate was kept 0.01 for our analysis then decay is 1e-6, epochs is 20 and the batch
size is kept 128.
These values totally depend on personal assumption, these values may vary (Rawat &
Wang, 2017). With these values the model has been evaluated and it have been observed that
the model built performed really well with an accuracy of 93.52% which is quite impressive.

6Mathematics and Programming of AI
Most of the images were classified correctly by the model (Russ, 2016). The code for the model
built-up is shown below-
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same',input_shape=(64, 64, 3)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same',input_shape=(64, 64, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('softmax'))
batch_size = 128
epoch = 20
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epoch,
verbose=1, validation_data=(X_test, y_test))
Now for the second dataset that is the CK+ dataset which consist of images of facial
expression which includes angry, happy, disgust, surprise, afraid, contempt and sad. At first
different libraries which will be required to build the model have been imported after that
different preprocessing steps are been done which includes loading of all the images from the
specific directories (Tussy, 2018). Here OpenCV is used as because the analysis is being done
on the image dataset not on any values. Mainly OpenCV library is used to solve computer vision
problems (Zhang et al., 2016).
A total of 981 images are there in the dataset with seven types of facial expression. The
images are then converted to 48*48 size. After which each image is then separated according to
their respective expression (Wang et al., 2017). Then further splitting of data is done which will
be required to build and train the model.
Here the model use SGD optimizer which is termed to be as one of the best optimizers
available in Keras network library, and it is been used with momentum. For building the model
different hidden layers were used to build the model, thus the model is shown below with
different hidden layer and fully connected neural network-
model = Sequential()
model.add(Conv2D(6, (5, 5), input_shape=(48,48,3), padding='same',
activation = 'relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
Most of the images were classified correctly by the model (Russ, 2016). The code for the model
built-up is shown below-
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same',input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same',input_shape=(64, 64, 3)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same',input_shape=(64, 64, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes,kernel_regularizer=regularizers.l2(0.0001)))
model.add(Activation('softmax'))
batch_size = 128
epoch = 20
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epoch,
verbose=1, validation_data=(X_test, y_test))
Now for the second dataset that is the CK+ dataset which consist of images of facial
expression which includes angry, happy, disgust, surprise, afraid, contempt and sad. At first
different libraries which will be required to build the model have been imported after that
different preprocessing steps are been done which includes loading of all the images from the
specific directories (Tussy, 2018). Here OpenCV is used as because the analysis is being done
on the image dataset not on any values. Mainly OpenCV library is used to solve computer vision
problems (Zhang et al., 2016).
A total of 981 images are there in the dataset with seven types of facial expression. The
images are then converted to 48*48 size. After which each image is then separated according to
their respective expression (Wang et al., 2017). Then further splitting of data is done which will
be required to build and train the model.
Here the model use SGD optimizer which is termed to be as one of the best optimizers
available in Keras network library, and it is been used with momentum. For building the model
different hidden layers were used to build the model, thus the model is shown below with
different hidden layer and fully connected neural network-
model = Sequential()
model.add(Conv2D(6, (5, 5), input_shape=(48,48,3), padding='same',
activation = 'relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
7Mathematics and Programming of AI
model.add(Conv2D(16, (5, 5), padding='same', activation = 'relu'))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation = 'softmax'))
From the above code it can be said that for building a CNN requires many layers for proper
classification.
A proper network architecture has been built with momentum as 0.9 and a learning rate
of 0.01. Also, with different learning rate the model has been fitted and found that the 0.01 is the
best fit. Also, it has been observed that with l2 regularization the accuracy of the model is much
lower as compared to without using the l2 regularization. Dropout layer is a crucial layer which is
needed for better accuracy of the model hence Dropout layer is added but without l2
regularization. Finally, an optimization of the topology of the network have been done which
produces a better accuracy.
It have been observed that the accuracy percentage of the model is not always constant,
it changes depending upon the kernel and system requirement. Also shuffle function is used to
shuffle the dataset which will be challenging for the model. Every time the model will produce
different accuracy based on the performance of the model.
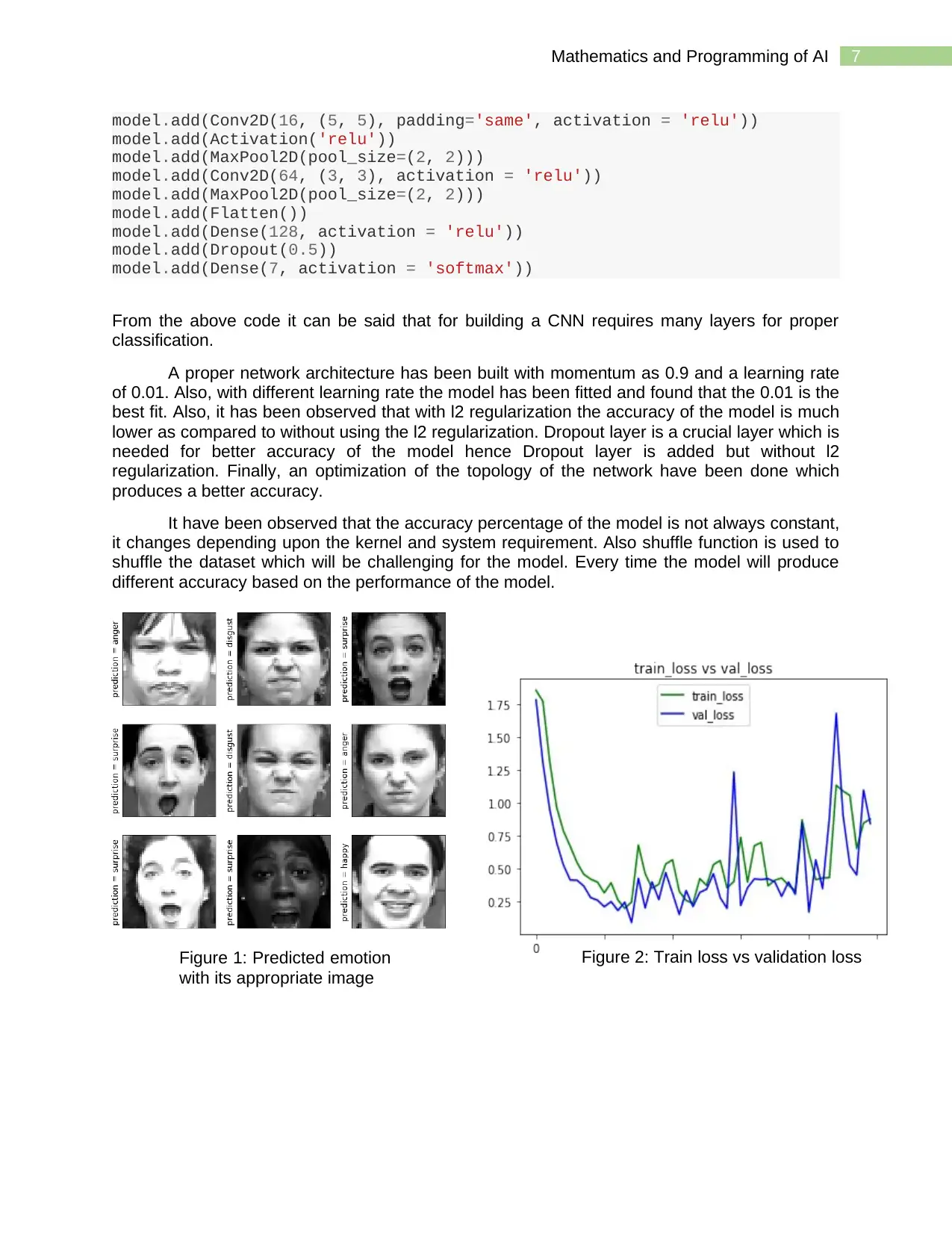
Figure 1: Predicted emotion
with its appropriate image
Figure 2: Train loss vs validation loss
model.add(Conv2D(16, (5, 5), padding='same', activation = 'relu'))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation = 'softmax'))
From the above code it can be said that for building a CNN requires many layers for proper
classification.
A proper network architecture has been built with momentum as 0.9 and a learning rate
of 0.01. Also, with different learning rate the model has been fitted and found that the 0.01 is the
best fit. Also, it has been observed that with l2 regularization the accuracy of the model is much
lower as compared to without using the l2 regularization. Dropout layer is a crucial layer which is
needed for better accuracy of the model hence Dropout layer is added but without l2
regularization. Finally, an optimization of the topology of the network have been done which
produces a better accuracy.
It have been observed that the accuracy percentage of the model is not always constant,
it changes depending upon the kernel and system requirement. Also shuffle function is used to
shuffle the dataset which will be challenging for the model. Every time the model will produce
different accuracy based on the performance of the model.
Figure 1: Predicted emotion
with its appropriate image
Figure 2: Train loss vs validation loss
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

8Mathematics and Programming of AI
Figure 1 shows the predicted labels with its appropriate images. Most of the images
were correctly predicted as seen from the figure and figure 2 depicts the train and validation loss
of the model that was trained with the dataset. For the second dataset the accuracy may vary as
shuffle function has been used in the pre-processing part. The average accuracy was observed
to be above 50% without using regularization and using regularization it has been observed that
the model performed poor and produces a low accuracy.
Conclusion
Two different dataset have been analyzed and trained using CNN model that have been
build according to the requirement. For the first dataset the accuracy was achieved by the
model was pretty good which is above 90% hence most of the digits were classified correctly
and for the second dataset the accuracy of the model was observed to be above 70% which is a
fair accuracy for the model. To get better accuracy at first the images should be prominent not
hazy which can gradually drop the accuracy for the classification model and the second factor is
utilizing the hidden layers correctly at the right position which will increase the classification
accuracy of the model. Neural network produces best accuracy from all other classification
available in machine learning thus building layers carefully and correctly will boost the accuracy
of the model for better classification of objects and images.
Further these improvements should be taken to consideration and better model need to
be build and a clean and more visually prominent dataset need to gather for better results. More
research should be done to get accurate and prominent images which will be further processed
by machine learning models for classification purposes. Also using these dataset different other
machine learning algorithms need to be developed in order to find the best model which
classifies more accurately in the near future.
Figure 1 shows the predicted labels with its appropriate images. Most of the images
were correctly predicted as seen from the figure and figure 2 depicts the train and validation loss
of the model that was trained with the dataset. For the second dataset the accuracy may vary as
shuffle function has been used in the pre-processing part. The average accuracy was observed
to be above 50% without using regularization and using regularization it has been observed that
the model performed poor and produces a low accuracy.
Conclusion
Two different dataset have been analyzed and trained using CNN model that have been
build according to the requirement. For the first dataset the accuracy was achieved by the
model was pretty good which is above 90% hence most of the digits were classified correctly
and for the second dataset the accuracy of the model was observed to be above 70% which is a
fair accuracy for the model. To get better accuracy at first the images should be prominent not
hazy which can gradually drop the accuracy for the classification model and the second factor is
utilizing the hidden layers correctly at the right position which will increase the classification
accuracy of the model. Neural network produces best accuracy from all other classification
available in machine learning thus building layers carefully and correctly will boost the accuracy
of the model for better classification of objects and images.
Further these improvements should be taken to consideration and better model need to
be build and a clean and more visually prominent dataset need to gather for better results. More
research should be done to get accurate and prominent images which will be further processed
by machine learning models for classification purposes. Also using these dataset different other
machine learning algorithms need to be developed in order to find the best model which
classifies more accurately in the near future.

9Mathematics and Programming of AI
References
Abadi, M. (2016, September). TensorFlow: learning functions at scale. In Acm Sigplan Notices
(Vol. 51, No. 9, pp. 1-1). ACM.
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., ... & Kudlur, M. (2016).
Tensorflow: A system for large-scale machine learning. In 12th {USENIX} Symposium on
Operating Systems Design and Implementation ({OSDI} 16) (pp. 265-283).
Alwzwazy, H. A., Albehadili, H. M., Alwan, Y. S., & Islam, N. E. (2016). Handwritten digit
recognition using convolutional neural networks. International Journal of Innovative
Research in Computer and Communication Engineering, 4(2), 1101-1106.
Boyko, N., Basystiuk, O., & Shakhovska, N. (2018, August). Performance Evaluation and
Comparison of Software for Face Recognition, Based on Dlib and Opencv Library. In
2018 IEEE Second International Conference on Data Stream Mining & Processing
(DSMP) (pp. 478-482). IEEE.
Cai, Z., Fan, Q., Feris, R. S., & Vasconcelos, N. (2016, October). A unified multi-scale deep
convolutional neural network for fast object detection. In european conference on
computer vision (pp. 354-370). Springer, Cham.
Fagan, J. F. (2017). The origins of facial pattern recognition. In Psychological development from
infancy (pp. 83-113). Routledge.
Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural
networks. In Proceedings of the IEEE conference on computer vision and pattern
recognition (pp. 2414-2423).
Gulli, A., & Pal, S. (2017). Deep Learning with Keras. Packt Publishing Ltd.
Howse, J., Joshi, P., & Beyeler, M. (2016). Opencv: computer vision projects with python. Packt
Publishing Ltd.
Ketkar, N. (2017). Deep Learning with Python (pp. 159-194). Apress.
Ketkar, N. (2017). Introduction to keras. In Deep Learning with Python (pp. 97-111). Apress,
Berkeley, CA.
Phaisangittisagul, E. (2016, January). An analysis of the regularization between L2 and dropout
in single hidden layer neural network. In 2016 7th International Conference on Intelligent
Systems, Modelling and Simulation (ISMS) (pp. 174-179). IEEE.
Rampasek, L., & Goldenberg, A. (2016). Tensorflow: Biology’s gateway to deep learning?. Cell
systems, 2(1), 12-14.
Rawat, W., & Wang, Z. (2017). Deep convolutional neural networks for image classification: A
comprehensive review. Neural computation, 29(9), 2352-2449.
Russ, J. C. (2016). The image processing handbook. CRC press.
Tussy, K. A. (2018). U.S. Patent No. 9,953,149. Washington, DC: U.S. Patent and Trademark
Office.
Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., ... & Tang, X. (2017). Residual
attention network for image classification. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (pp. 3156-3164).
References
Abadi, M. (2016, September). TensorFlow: learning functions at scale. In Acm Sigplan Notices
(Vol. 51, No. 9, pp. 1-1). ACM.
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., ... & Kudlur, M. (2016).
Tensorflow: A system for large-scale machine learning. In 12th {USENIX} Symposium on
Operating Systems Design and Implementation ({OSDI} 16) (pp. 265-283).
Alwzwazy, H. A., Albehadili, H. M., Alwan, Y. S., & Islam, N. E. (2016). Handwritten digit
recognition using convolutional neural networks. International Journal of Innovative
Research in Computer and Communication Engineering, 4(2), 1101-1106.
Boyko, N., Basystiuk, O., & Shakhovska, N. (2018, August). Performance Evaluation and
Comparison of Software for Face Recognition, Based on Dlib and Opencv Library. In
2018 IEEE Second International Conference on Data Stream Mining & Processing
(DSMP) (pp. 478-482). IEEE.
Cai, Z., Fan, Q., Feris, R. S., & Vasconcelos, N. (2016, October). A unified multi-scale deep
convolutional neural network for fast object detection. In european conference on
computer vision (pp. 354-370). Springer, Cham.
Fagan, J. F. (2017). The origins of facial pattern recognition. In Psychological development from
infancy (pp. 83-113). Routledge.
Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural
networks. In Proceedings of the IEEE conference on computer vision and pattern
recognition (pp. 2414-2423).
Gulli, A., & Pal, S. (2017). Deep Learning with Keras. Packt Publishing Ltd.
Howse, J., Joshi, P., & Beyeler, M. (2016). Opencv: computer vision projects with python. Packt
Publishing Ltd.
Ketkar, N. (2017). Deep Learning with Python (pp. 159-194). Apress.
Ketkar, N. (2017). Introduction to keras. In Deep Learning with Python (pp. 97-111). Apress,
Berkeley, CA.
Phaisangittisagul, E. (2016, January). An analysis of the regularization between L2 and dropout
in single hidden layer neural network. In 2016 7th International Conference on Intelligent
Systems, Modelling and Simulation (ISMS) (pp. 174-179). IEEE.
Rampasek, L., & Goldenberg, A. (2016). Tensorflow: Biology’s gateway to deep learning?. Cell
systems, 2(1), 12-14.
Rawat, W., & Wang, Z. (2017). Deep convolutional neural networks for image classification: A
comprehensive review. Neural computation, 29(9), 2352-2449.
Russ, J. C. (2016). The image processing handbook. CRC press.
Tussy, K. A. (2018). U.S. Patent No. 9,953,149. Washington, DC: U.S. Patent and Trademark
Office.
Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., ... & Tang, X. (2017). Residual
attention network for image classification. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (pp. 3156-3164).
1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.