MBA 5652: Data Analysis of Sun Coast Data using Parametric Tools
VerifiedAdded on 2022/11/03
|9
|1364
|341
Project
AI Summary
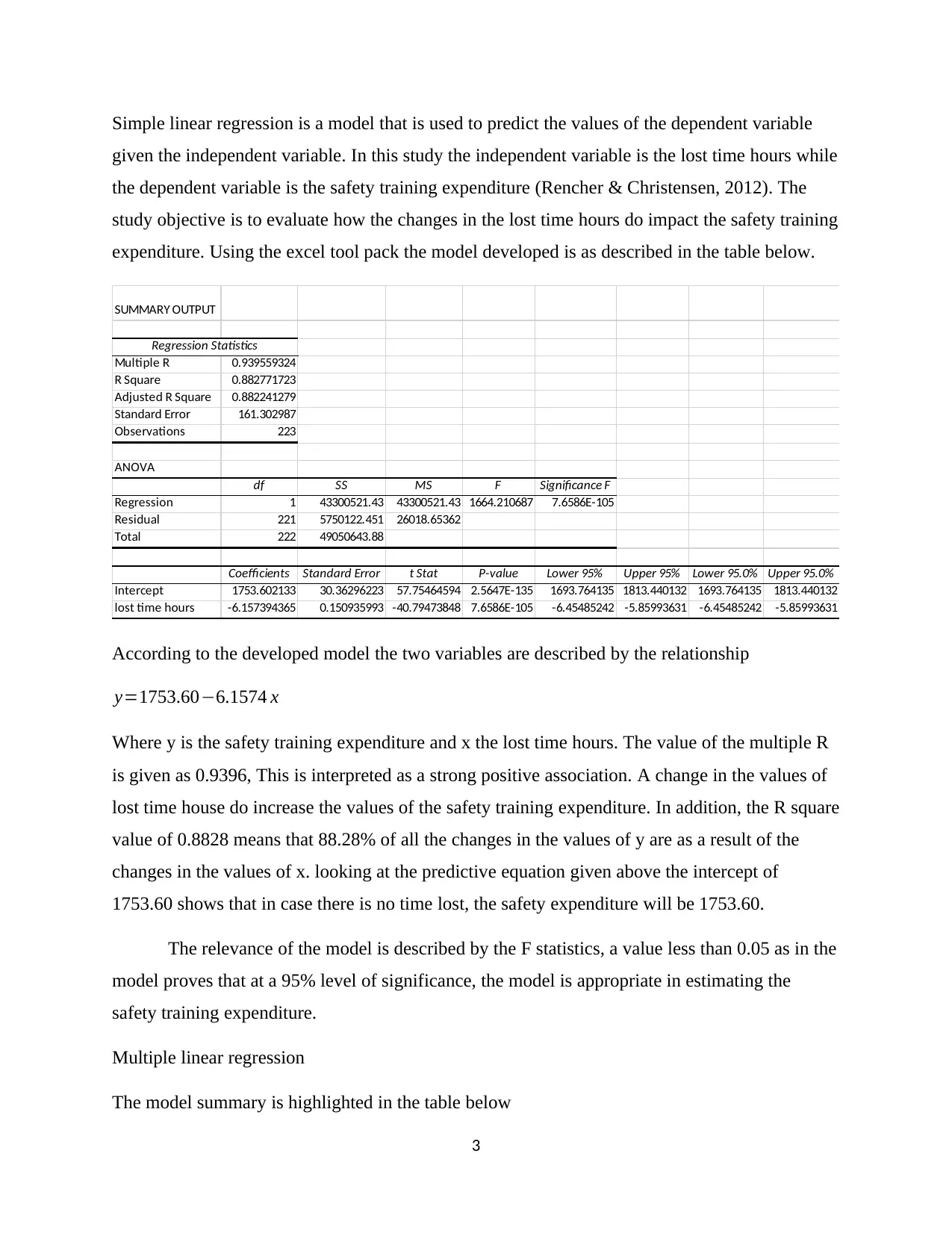
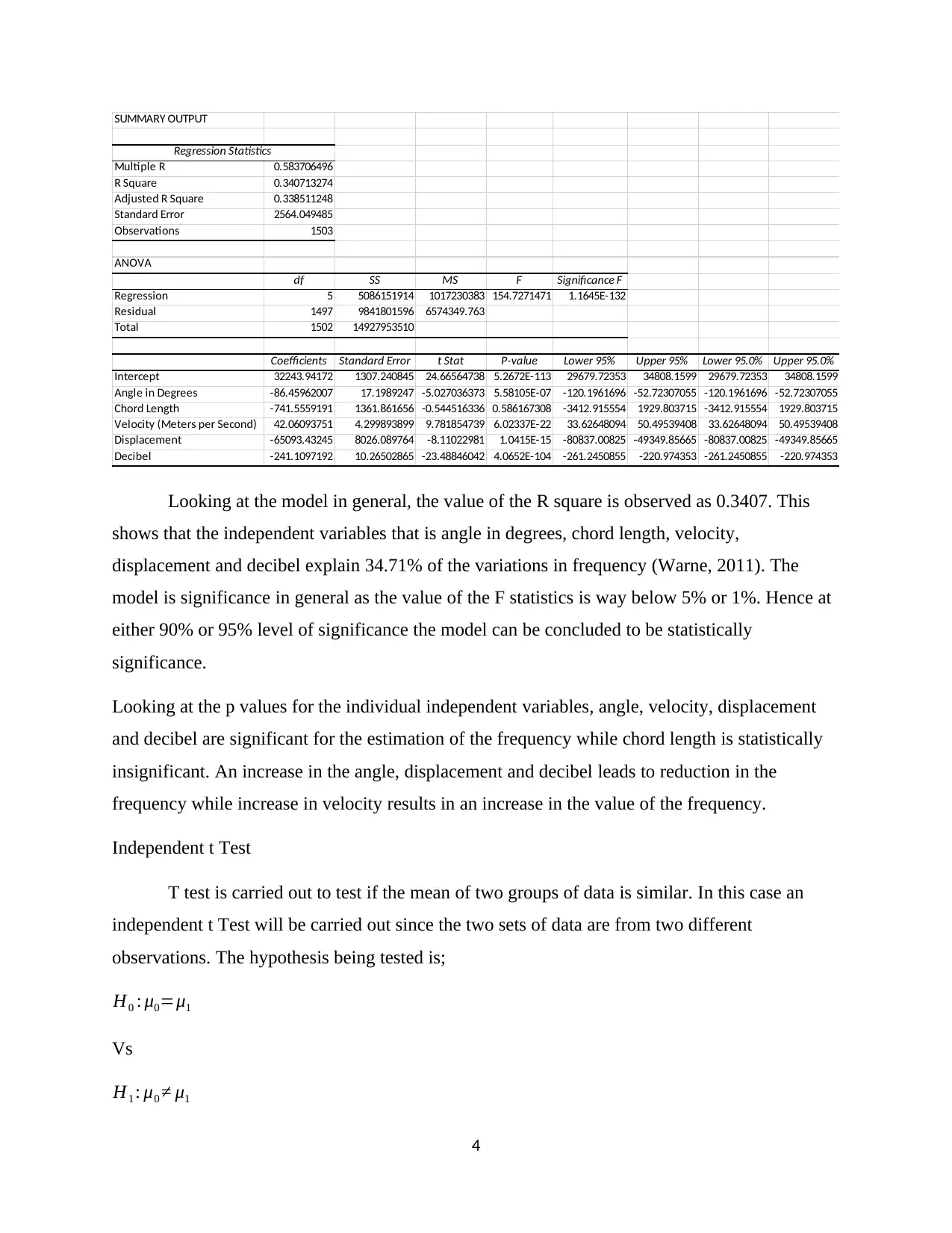
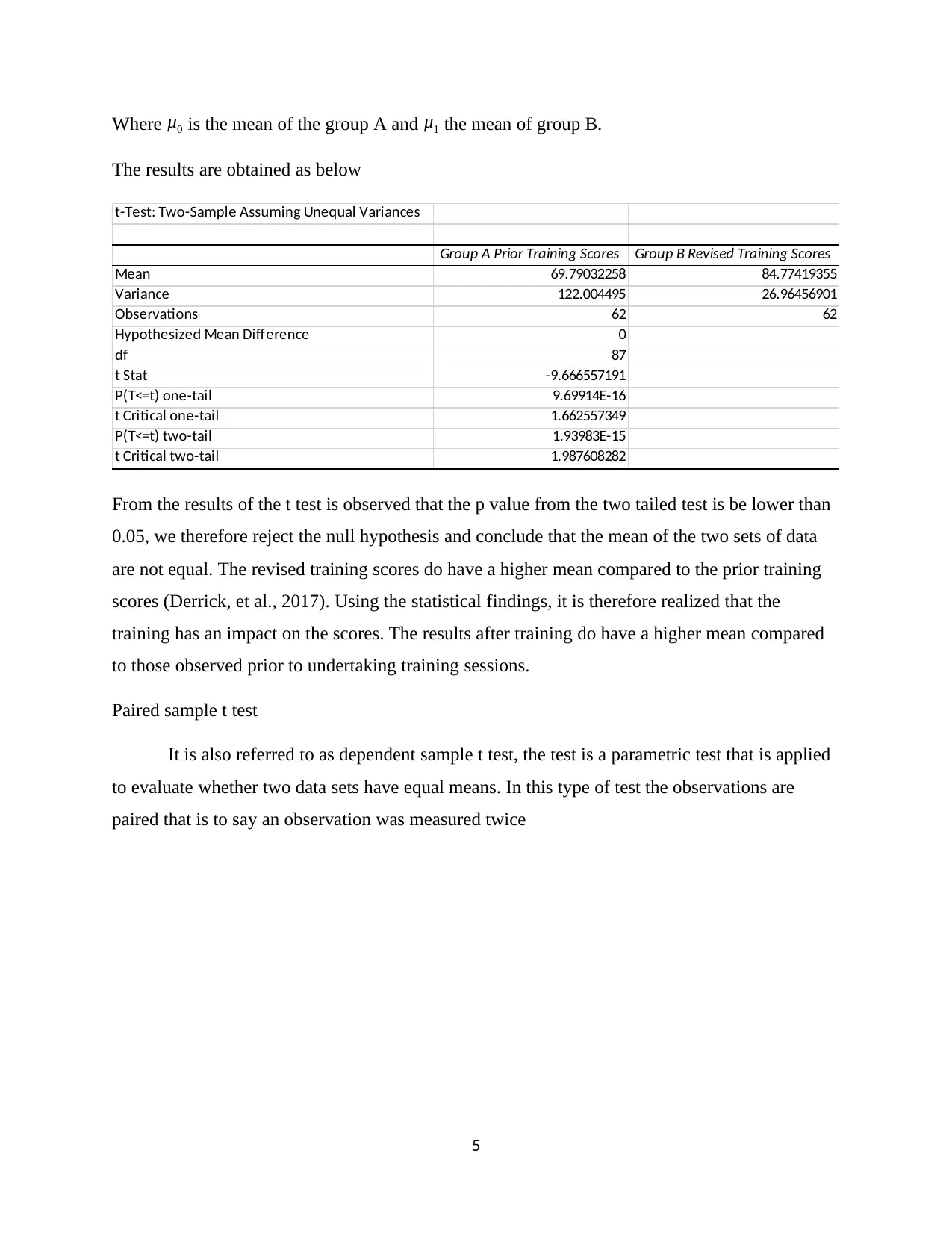
This project analyzes the Sun Coast data using parametric statistical tools within Excel. It begins with an introduction to parametric statistics, outlining the assumptions required for its application. The analysis covers correlation, examining the relationship between microns and mean annual sick days per employee, revealing a strong negative correlation. Simple linear regression is used to predict safety training expenditure based on lost time hours, showing a strong positive association. Multiple linear regression explores the relationship between frequency and multiple independent variables. Furthermore, the project employs independent and paired sample t-tests to compare means, and a one-way ANOVA test to compare the means of multiple groups. Each analysis includes interpretations of the results, providing insights into the data and the effectiveness of various training programs. The document concludes with a comprehensive list of references.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.