MN405 Managing Data in Databases
VerifiedAdded on 2021/06/18
|10
|1312
|19
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

MN405 Managing Data in Databases
Assignment 1 (T1 2018)
Student ID:
Student Name:
Date:
Module Tutor:
Assignment 1 (T1 2018)
Student ID:
Student Name:
Date:
Module Tutor:
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
Part B
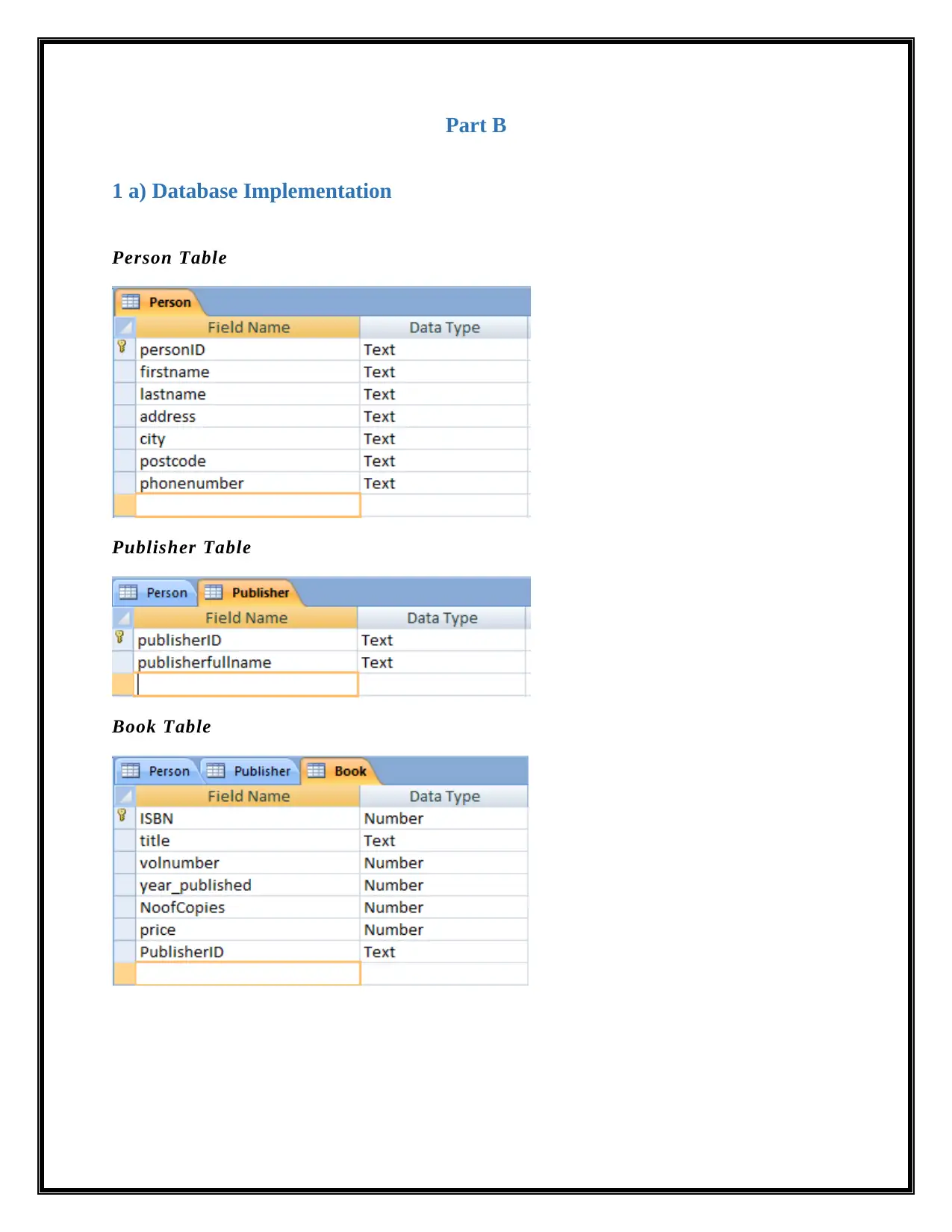
1 a) Database Implementation
Person Table
Publisher Table
Book Table
1 a) Database Implementation
Person Table
Publisher Table
Book Table
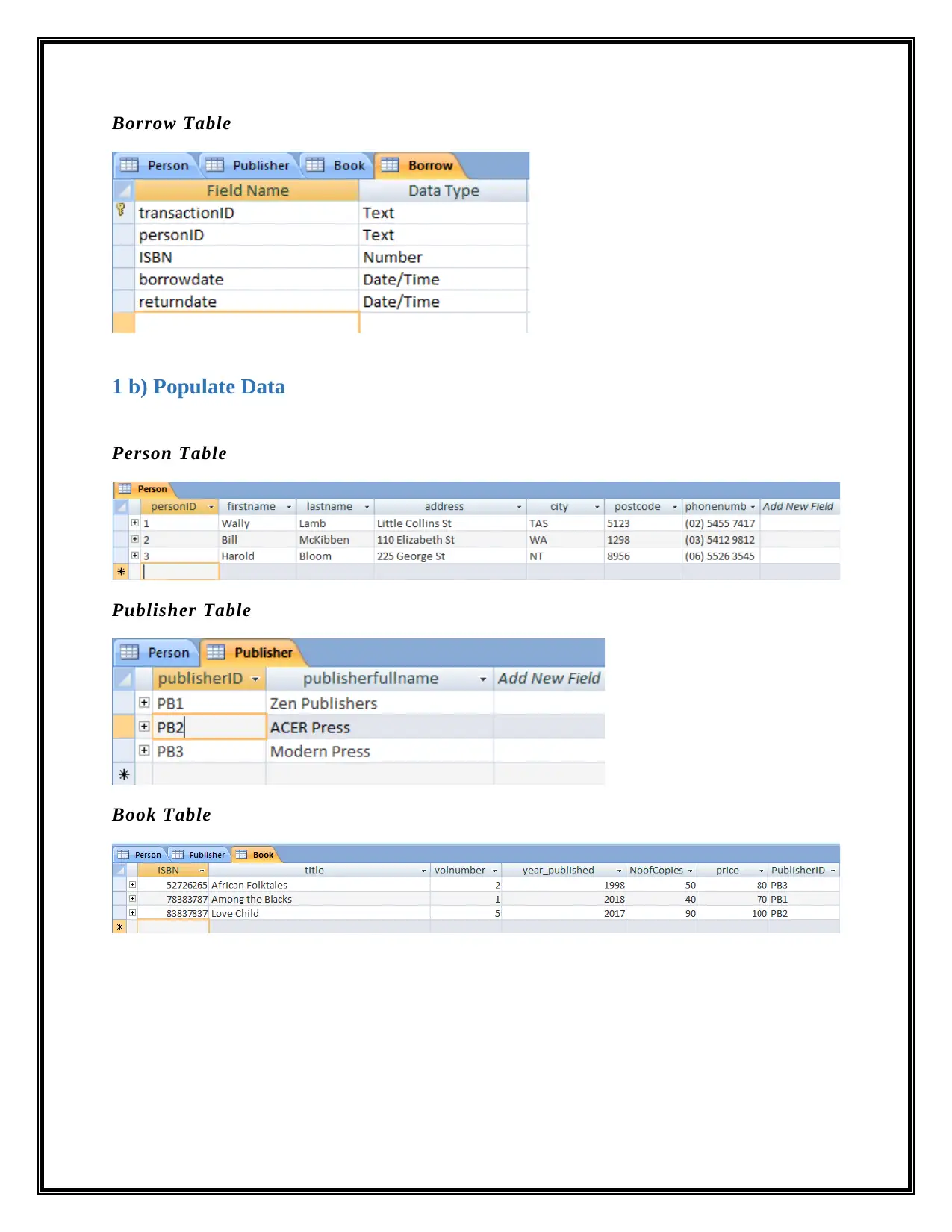
Borrow Table
1 b) Populate Data
Person Table
Publisher Table
Book Table
1 b) Populate Data
Person Table
Publisher Table
Book Table
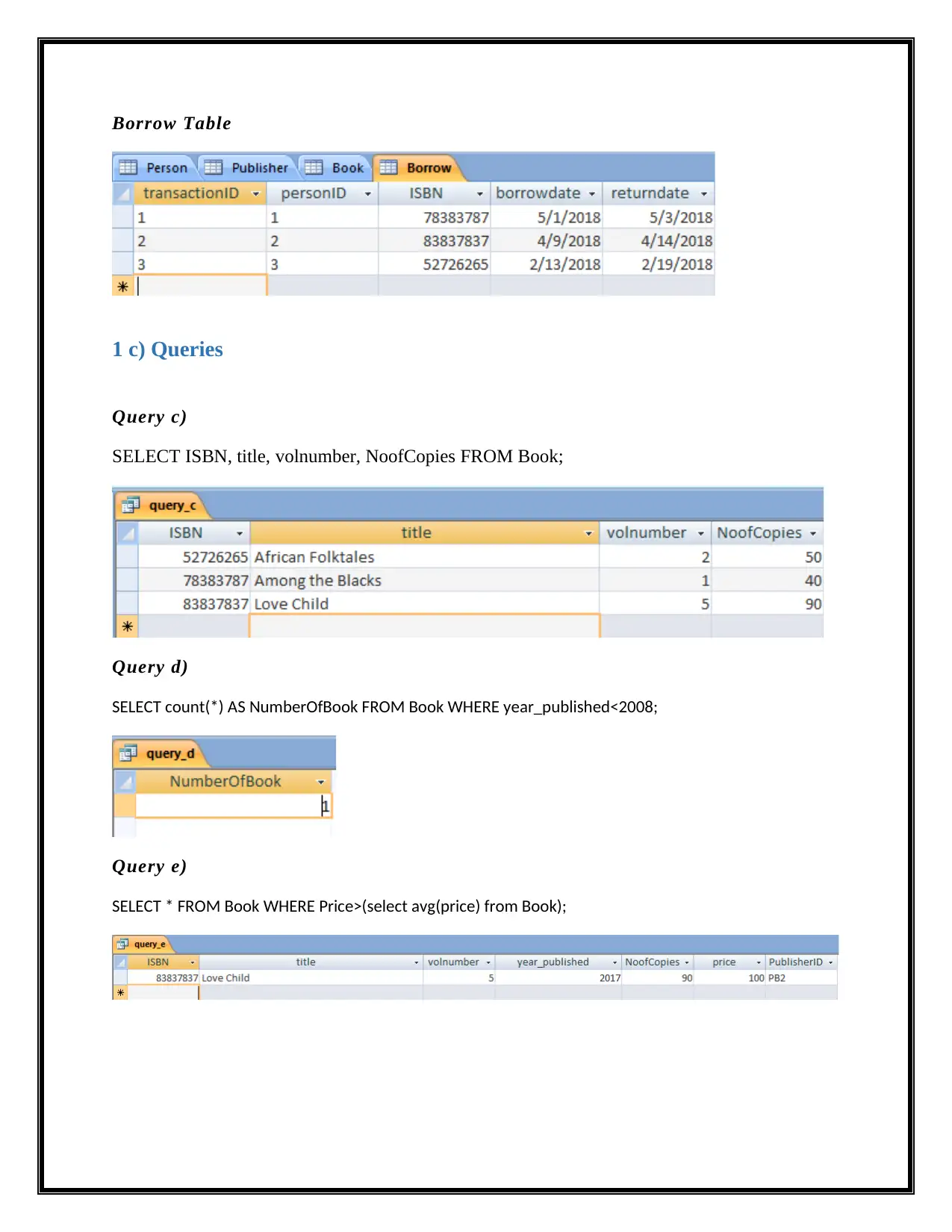
Borrow Table
1 c) Queries
Query c)
SELECT ISBN, title, volnumber, NoofCopies FROM Book;
Query d)
SELECT count(*) AS NumberOfBook FROM Book WHERE year_published<2008;
Query e)
SELECT * FROM Book WHERE Price>(select avg(price) from Book);
1 c) Queries
Query c)
SELECT ISBN, title, volnumber, NoofCopies FROM Book;
Query d)
SELECT count(*) AS NumberOfBook FROM Book WHERE year_published<2008;
Query e)
SELECT * FROM Book WHERE Price>(select avg(price) from Book);
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Query f)
SELECT ISBN, title, volnumber, year_published, NoofCopies, price, publisherfullname FROM
Publisher INNER JOIN Book ON Publisher.publisherID = Book.PublisherID WHERE
(((Book.year_published)=2017) AND ((Publisher.publisherfullname)="ACER Press"));
Query g)
SELECT Person.personID, Person.firstname, Person.lastname, Person.address,
Borrow.borrowdate, Borrow.returndate INTO Borrower FROM Person INNER JOIN Borrow
ON Person.personID = Borrow.personID;
2 a) Relational Database Schema
TablePublisher (Fieldname: text, Fieldaddress: text, Fieldphone: text, FieldURL: text)
TableAuthor (Fieldname: text, Fieldaddress: text, FieldURL: text)
TableBook (FieldISBN: number, Fieldtitle: text, Fieldprice: currency, Fieldyear: number,
FieldauthorName*: text, FieldpublisherName*: text)
TableCustomer (Fieldemail: text, Fieldname: text, Fieldaddress: text, Fieldphone: text)
TableShoppingBasket (FieldbasketID: number, FieldcustomerEmail*: text, FieldISBN*: number,
FieldNoOfBooks: number)
TableWarehouse (Fieldcode: text, Fieldaddress:text, Fieldphone:text)
TableStocks (FieldwarehouseCode*: text, FieldISBN*:number, FieldNoOfBooks: number)
(teratrax.com n.d.)
SELECT ISBN, title, volnumber, year_published, NoofCopies, price, publisherfullname FROM
Publisher INNER JOIN Book ON Publisher.publisherID = Book.PublisherID WHERE
(((Book.year_published)=2017) AND ((Publisher.publisherfullname)="ACER Press"));
Query g)
SELECT Person.personID, Person.firstname, Person.lastname, Person.address,
Borrow.borrowdate, Borrow.returndate INTO Borrower FROM Person INNER JOIN Borrow
ON Person.personID = Borrow.personID;
2 a) Relational Database Schema
TablePublisher (Fieldname: text, Fieldaddress: text, Fieldphone: text, FieldURL: text)
TableAuthor (Fieldname: text, Fieldaddress: text, FieldURL: text)
TableBook (FieldISBN: number, Fieldtitle: text, Fieldprice: currency, Fieldyear: number,
FieldauthorName*: text, FieldpublisherName*: text)
TableCustomer (Fieldemail: text, Fieldname: text, Fieldaddress: text, Fieldphone: text)
TableShoppingBasket (FieldbasketID: number, FieldcustomerEmail*: text, FieldISBN*: number,
FieldNoOfBooks: number)
TableWarehouse (Fieldcode: text, Fieldaddress:text, Fieldphone:text)
TableStocks (FieldwarehouseCode*: text, FieldISBN*:number, FieldNoOfBooks: number)
(teratrax.com n.d.)

2 b) Composite Attributes
The attribute which can be split into another significant attributes is called composite attribute.
The database ‘BookStore’ contains the composite attribute -
Address – it may be divided into Street, City, and Postcode etc. So, this is the composite
attribute.
Name – it may be divided into FirstName, LastName etc. So, this is the composite attribute.
The attribute which can be split into another significant attributes is called composite attribute.
The database ‘BookStore’ contains the composite attribute -
Address – it may be divided into Street, City, and Postcode etc. So, this is the composite
attribute.
Name – it may be divided into FirstName, LastName etc. So, this is the composite attribute.
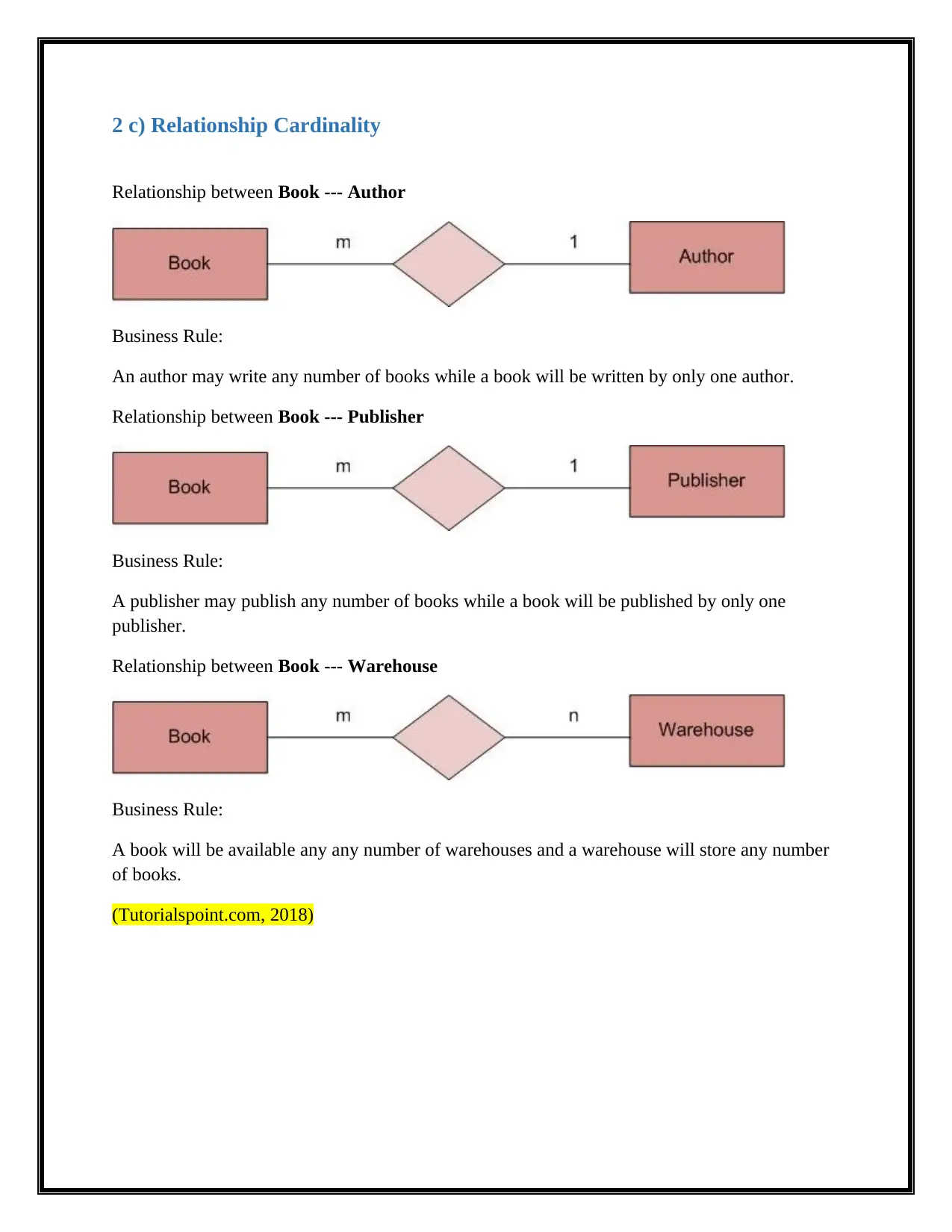
2 c) Relationship Cardinality
Relationship between Book --- Author
Business Rule:
An author may write any number of books while a book will be written by only one author.
Relationship between Book --- Publisher
Business Rule:
A publisher may publish any number of books while a book will be published by only one
publisher.
Relationship between Book --- Warehouse
Business Rule:
A book will be available any any number of warehouses and a warehouse will store any number
of books.
(Tutorialspoint.com, 2018)
Relationship between Book --- Author
Business Rule:
An author may write any number of books while a book will be written by only one author.
Relationship between Book --- Publisher
Business Rule:
A publisher may publish any number of books while a book will be published by only one
publisher.
Relationship between Book --- Warehouse
Business Rule:
A book will be available any any number of warehouses and a warehouse will store any number
of books.
(Tutorialspoint.com, 2018)
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

3 a) Hadoop
Introduction
Hadoop is an open source system of Apache that works on Big Data. It is used in distributed
environment on cluster systems. It works on the technology developed by Google – MapReduce.
The Big Data does not get accessed easily by Relational Database Management System
(RDBMS) easily. Therefore, to resolve this issue MapReduce is designed and Hadoop is
developed on the MapReduce algorithm.
In Hadoop, the big task is shared among clustered systems and each system process its assigned
task. When all the tasks are processed, Hadoop collects them and arrange them to produce final
result.
Capabilities
Hadoop has lots of skills that make it different and efficient from RDBMS like below-
1. It may works upon any platform. It is platform independent.
2. A server can be removed or added dynamically in the cluster systems. It will not disrupt
the working of the process.
3. It is fault tolerance. It detects the fault itself by its library and is not dependent upon any
hardware to warn before the fault occurrence.
4. It is not expensive at all.
Limitations
Hadoop has little bit limitations like below-
1. It works well only on Big Data. It is suitable for the small data because of its technology
that is not required to process the small data.
2. It supports only batch processing.
3. The real time applications does not work on Hadoop as it takes so much time and real
time applications do not required Big Data all the time.
4. It does not work well in iterative processes.
5. The process speed is very slow in it because of the technology used in it.
Conclusion
Hadoop is one of the best technology for Big Data. It is appropriate for Big Data applications as
all the data gets divided into small chunks and processes and later combined for desired output.
There are lots of features that are very usefull in Hadoop for Big Data processing but for small
Introduction
Hadoop is an open source system of Apache that works on Big Data. It is used in distributed
environment on cluster systems. It works on the technology developed by Google – MapReduce.
The Big Data does not get accessed easily by Relational Database Management System
(RDBMS) easily. Therefore, to resolve this issue MapReduce is designed and Hadoop is
developed on the MapReduce algorithm.
In Hadoop, the big task is shared among clustered systems and each system process its assigned
task. When all the tasks are processed, Hadoop collects them and arrange them to produce final
result.
Capabilities
Hadoop has lots of skills that make it different and efficient from RDBMS like below-
1. It may works upon any platform. It is platform independent.
2. A server can be removed or added dynamically in the cluster systems. It will not disrupt
the working of the process.
3. It is fault tolerance. It detects the fault itself by its library and is not dependent upon any
hardware to warn before the fault occurrence.
4. It is not expensive at all.
Limitations
Hadoop has little bit limitations like below-
1. It works well only on Big Data. It is suitable for the small data because of its technology
that is not required to process the small data.
2. It supports only batch processing.
3. The real time applications does not work on Hadoop as it takes so much time and real
time applications do not required Big Data all the time.
4. It does not work well in iterative processes.
5. The process speed is very slow in it because of the technology used in it.
Conclusion
Hadoop is one of the best technology for Big Data. It is appropriate for Big Data applications as
all the data gets divided into small chunks and processes and later combined for desired output.
There are lots of features that are very usefull in Hadoop for Big Data processing but for small

data it is not suitable. There are so many applications that use Big Data like railways, airlines etc.
It works very well in that industries. In today’s world it is in high demand.
(Apache Software, 2014)
3 b) MapReduce
Introduction
MapReduce is the algorithm that is the base of the technology developed to process the Big Data. It is
the software framework used to develop applications to process Big Data like Hadoop.
It works very well and in a very organized way to process the Big Data. It divides the big task and
distributes to the clustered system to process that data. After taking the results from all vluster
machines, it sort them and combine them to make final output.
The Map is the term used to divide the task and Reduce is the term sued to sort and arrange the outputs
and make the final output for the users.
It work in the pair of <key, value>. The input and output both are in the same format- <key, value>
Capabilities
MapReduce works very well in the following fields-
1. It is highly scalable and proficient. It does not rely on any platform.
2. It is not so much expensive. It is very affordable by organizations.
3. It is suitable for all data types like structured, or unstructured etc.
4. It uses the HBase security techniques.
5. It uses the highly secure techniques for backup. It takes the backup of data at the time
when the data comes at the main node and stores it for the future use.
Limitations
MapReduce has little bit limitations with lots of benefits-
1. It is well only for Big Data applications. It cannot work for small data applications.
2. The processing time is very high in it.
3. Iterative processing is not done well by this technology.
4. Real time applications do not work well on it.
5. It is not easy to understand.
It works very well in that industries. In today’s world it is in high demand.
(Apache Software, 2014)
3 b) MapReduce
Introduction
MapReduce is the algorithm that is the base of the technology developed to process the Big Data. It is
the software framework used to develop applications to process Big Data like Hadoop.
It works very well and in a very organized way to process the Big Data. It divides the big task and
distributes to the clustered system to process that data. After taking the results from all vluster
machines, it sort them and combine them to make final output.
The Map is the term used to divide the task and Reduce is the term sued to sort and arrange the outputs
and make the final output for the users.
It work in the pair of <key, value>. The input and output both are in the same format- <key, value>
Capabilities
MapReduce works very well in the following fields-
1. It is highly scalable and proficient. It does not rely on any platform.
2. It is not so much expensive. It is very affordable by organizations.
3. It is suitable for all data types like structured, or unstructured etc.
4. It uses the HBase security techniques.
5. It uses the highly secure techniques for backup. It takes the backup of data at the time
when the data comes at the main node and stores it for the future use.
Limitations
MapReduce has little bit limitations with lots of benefits-
1. It is well only for Big Data applications. It cannot work for small data applications.
2. The processing time is very high in it.
3. Iterative processing is not done well by this technology.
4. Real time applications do not work well on it.
5. It is not easy to understand.

Conclusion
MapReduce is very good and effective framework for Big Data applications. It does not suits
well for small applications. Everything is very systematic in it. All the data gets processed with
easy by it in the cluster systems in a distributed environment.
References
[1] Tutorialspoint.com, DBMS – Normalization, 2018. [Online]. Available:
https://www.tutorialspoint.com/dbms/database_normalization.htm. [Accessed: 11-May-
2018]
[2] teratrax.com, SQL Server Data Types and Ranges, n.d. [Online]. Available:
http://www.teratrax.com/sql-server-data-types-ranges/ [Accessed 11 May 2018].
[3] Apache Software, What is Apache Hadoop, 2014. [Online]. Available:
http://hadoop.apache.org// [Accessed 11 May 2018].
MapReduce is very good and effective framework for Big Data applications. It does not suits
well for small applications. Everything is very systematic in it. All the data gets processed with
easy by it in the cluster systems in a distributed environment.
References
[1] Tutorialspoint.com, DBMS – Normalization, 2018. [Online]. Available:
https://www.tutorialspoint.com/dbms/database_normalization.htm. [Accessed: 11-May-
2018]
[2] teratrax.com, SQL Server Data Types and Ranges, n.d. [Online]. Available:
http://www.teratrax.com/sql-server-data-types-ranges/ [Accessed 11 May 2018].
[3] Apache Software, What is Apache Hadoop, 2014. [Online]. Available:
http://hadoop.apache.org// [Accessed 11 May 2018].
1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.