NBA Win Prediction: Building a Predictive Model Using Excel Data
VerifiedAdded on 2023/05/29
|15
|2515
|444
Project
AI Summary
This project focuses on predicting NBA win statistics for the 2016-2017 and 2017-2018 seasons using Excel data analysis techniques. The project involves data collection from the NBA website, model building using multiple linear regression, and model deployment to predict win totals and playoff qualifications. The analysis skips the assumptions and hypotheses steps to increase model precision, dropping win-loss proxy statistics. Multiple regression models are tested, with the final model utilizing age, offensive rating, and defensive rating as significant variables. The classification modeling is used to predict which teams qualified for the playoffs for each season as well as the ongoing season. The project concludes with an application of the model to the ongoing 2018-2019 season, comparing predicted results with conference standings.

Introduction
Since the beginning of civilization as we know it, being able to predict the future has always
been an active endeavor for humans. From seers, prophets, to the modern times where data is the
new gold and forms the basis of statistical analyses, prediction is still important for preparation
of what might be. Pat Research (2018) argues that, predictive analytics can be viewed as a data
analytics sub-branch which mainly deals with prediction of a specific future event which is often
unknown through employing collected data. Further, their paper notes that the process of
predictive analytics involves:
i. Data collection
ii. Data analysis
iii. Statistical analyses to ascertain assumptions and hypotheses
iv. Modeling
v. Deployment of the model
vi. Model monitoring
In this project, the above processes are used in predicting the win statistics of the seasons 2016-
2017 and 2017-2018 of the NBA which have been lost due to an a tragedy. Additionally, the
project aims to predict teams that get to enter into the playoffs.
Data collection
Data for this project is obtained from the NBA website for the seasons from 2011 to 2019. The
data is divided into source data which contains statistics for the seasons 2011-2012, 2012-2013,
Since the beginning of civilization as we know it, being able to predict the future has always
been an active endeavor for humans. From seers, prophets, to the modern times where data is the
new gold and forms the basis of statistical analyses, prediction is still important for preparation
of what might be. Pat Research (2018) argues that, predictive analytics can be viewed as a data
analytics sub-branch which mainly deals with prediction of a specific future event which is often
unknown through employing collected data. Further, their paper notes that the process of
predictive analytics involves:
i. Data collection
ii. Data analysis
iii. Statistical analyses to ascertain assumptions and hypotheses
iv. Modeling
v. Deployment of the model
vi. Model monitoring
In this project, the above processes are used in predicting the win statistics of the seasons 2016-
2017 and 2017-2018 of the NBA which have been lost due to an a tragedy. Additionally, the
project aims to predict teams that get to enter into the playoffs.
Data collection
Data for this project is obtained from the NBA website for the seasons from 2011 to 2019. The
data is divided into source data which contains statistics for the seasons 2011-2012, 2012-2013,
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

2014-2015 and 2015-2016 while the subject data contains statistics for the seasons 2016-2017
and 2017-2018. Further, the project uses the statistics for the ongoing season 2018-2019.
Some new variables that were added to the miscellaneous data include the 2018-2019 data with
the probability of teams to be in the playoffs.
Modeling
Since the main purpose of the project is to conduct predictive modeling on given historical data,
the data analysis and statistical analyses to ascertain assumptions and hypotheses steps are
skipped. In order to increase the precision of the models, columns with win-loss proxy statistics
are dropped altogether, i.e. losses, winning percentage, Pythagorean wins/losses, margin of
victory and SRS.
Multiple linear regression
In multiple linear regression, the model uses two or more predictor variables in predicting a
single outcome of the response variable. Therefore, in predicting winning, I adopt the following
model:
Yi = β0+ β1X1 + · · · + βkXk + εi Where, β0= Coefficient regression, βi, i=1,2,
…, k are the regressors coefficients and Xi are the
independent variables and εi is the random error
term.
The model assumes a linear relationship between the independent variables and the dependent
variable have a. Now in applying the model to the data, the following model is obtained:
and 2017-2018. Further, the project uses the statistics for the ongoing season 2018-2019.
Some new variables that were added to the miscellaneous data include the 2018-2019 data with
the probability of teams to be in the playoffs.
Modeling
Since the main purpose of the project is to conduct predictive modeling on given historical data,
the data analysis and statistical analyses to ascertain assumptions and hypotheses steps are
skipped. In order to increase the precision of the models, columns with win-loss proxy statistics
are dropped altogether, i.e. losses, winning percentage, Pythagorean wins/losses, margin of
victory and SRS.
Multiple linear regression
In multiple linear regression, the model uses two or more predictor variables in predicting a
single outcome of the response variable. Therefore, in predicting winning, I adopt the following
model:
Yi = β0+ β1X1 + · · · + βkXk + εi Where, β0= Coefficient regression, βi, i=1,2,
…, k are the regressors coefficients and Xi are the
independent variables and εi is the random error
term.
The model assumes a linear relationship between the independent variables and the dependent
variable have a. Now in applying the model to the data, the following model is obtained:

Win= β0 + β1Age+ β2 OffensiveRating+ β3DefensiveRating+ β4 OffensiveRebound+ β4Pace+...+
β16Turnover
The model is then applied on the historical data using Excel’s data analysis tool.
Results of the model
91 64.98753 -4.98753 -1.89204 75.41667 50
92 65.22847 0.771529 0.292682 76.25 51
93 58.71736 -0.71736 -0.27213 77.08333 51
94 59.56017 -3.56017 -1.35056 77.91667 53
95 54.1821 2.817895 1.068978 78.75 53
96 52.82816 3.171839 1.203247 79.58333 54
97 55.05247 -1.05247 -0.39926 80.41667 54
98 47.81351 -2.81351 -1.06731 81.25 54
99 51.91123 -2.91123 -1.10439 82.08333 54
100 46.77688 -1.77688 -0.67406 82.91667 55
101 42.79365 4.206345 1.59569 83.75 55
102 46.85518 2.144818 0.813644 84.58333 55
103 40.59056 2.409445 0.914031 85.41667 56
104 43.0065 1.993504 0.756242 86.25 56
105 42.44751 1.552487 0.588941 87.08333 56
106 42.70779 -1.70779 -0.64785 87.91667 56
107 42.71689 -1.71689 -0.65131 88.75 56
108 38.33147 -0.33147 -0.12575 89.58333 56
109 34.40149 -3.40149 -1.29037 90.41667 57
110 36.02079 -2.02079 -0.76659 91.25 57
111 31.44281 1.557187 0.590724 92.08333 57
112 33.78899 -4.78899 -1.81672 92.91667 58
113 28.93727 -1.93727 -0.73491 93.75 59
114 32.94979 1.050209 0.3984 94.58333 60
115 28.43773 -0.43773 -0.16605 95.41667 60
116 30.1489 -1.1489 -0.43584 96.25 62
117 26.58165 -2.58165 -0.97936 97.08333 66
118 24.91932 0.080676 0.030605 97.91667 67
119 22.34117 -2.34117 -0.88813 98.75 67
120 15.77135 5.228649 1.983505 99.58333 73
1: Multiple regression model
β16Turnover
The model is then applied on the historical data using Excel’s data analysis tool.
Results of the model
91 64.98753 -4.98753 -1.89204 75.41667 50
92 65.22847 0.771529 0.292682 76.25 51
93 58.71736 -0.71736 -0.27213 77.08333 51
94 59.56017 -3.56017 -1.35056 77.91667 53
95 54.1821 2.817895 1.068978 78.75 53
96 52.82816 3.171839 1.203247 79.58333 54
97 55.05247 -1.05247 -0.39926 80.41667 54
98 47.81351 -2.81351 -1.06731 81.25 54
99 51.91123 -2.91123 -1.10439 82.08333 54
100 46.77688 -1.77688 -0.67406 82.91667 55
101 42.79365 4.206345 1.59569 83.75 55
102 46.85518 2.144818 0.813644 84.58333 55
103 40.59056 2.409445 0.914031 85.41667 56
104 43.0065 1.993504 0.756242 86.25 56
105 42.44751 1.552487 0.588941 87.08333 56
106 42.70779 -1.70779 -0.64785 87.91667 56
107 42.71689 -1.71689 -0.65131 88.75 56
108 38.33147 -0.33147 -0.12575 89.58333 56
109 34.40149 -3.40149 -1.29037 90.41667 57
110 36.02079 -2.02079 -0.76659 91.25 57
111 31.44281 1.557187 0.590724 92.08333 57
112 33.78899 -4.78899 -1.81672 92.91667 58
113 28.93727 -1.93727 -0.73491 93.75 59
114 32.94979 1.050209 0.3984 94.58333 60
115 28.43773 -0.43773 -0.16605 95.41667 60
116 30.1489 -1.1489 -0.43584 96.25 62
117 26.58165 -2.58165 -0.97936 97.08333 66
118 24.91932 0.080676 0.030605 97.91667 67
119 22.34117 -2.34117 -0.88813 98.75 67
120 15.77135 5.228649 1.983505 99.58333 73
1: Multiple regression model
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

From the above model, the R-squared value is 0.9962 which implies that the model explains
99.62% of the variability in the model. An equally high adjusted R-squared statistic of 0.986087
implies that the variables in the model improve the model. The standard error of the residuals is
2.8315. However, from the model results at 0.05 level of significance, the Opp Effective Field
Goal% variable has a p-value of 0.046612<0.05. We therefore fail to reject the null hypothesis
and conclude that Opp Effective Field Goal% is the only significant variable in predicting wins
in the original model. We therefore apply linear regression to determine the significant variables
which have a p-value of less than 0.05. The significant variables are:
i. Age
ii. Offensive rebound
iii. Defensive rebound
iv. Free throw opponent
v. Opponent turnover
vi. Opp Effective Field Goal%
vii. Free Throws Pa Field Goal Attempt
viii. 3-Point Attempt Rate
99.62% of the variability in the model. An equally high adjusted R-squared statistic of 0.986087
implies that the variables in the model improve the model. The standard error of the residuals is
2.8315. However, from the model results at 0.05 level of significance, the Opp Effective Field
Goal% variable has a p-value of 0.046612<0.05. We therefore fail to reject the null hypothesis
and conclude that Opp Effective Field Goal% is the only significant variable in predicting wins
in the original model. We therefore apply linear regression to determine the significant variables
which have a p-value of less than 0.05. The significant variables are:
i. Age
ii. Offensive rebound
iii. Defensive rebound
iv. Free throw opponent
v. Opponent turnover
vi. Opp Effective Field Goal%
vii. Free Throws Pa Field Goal Attempt
viii. 3-Point Attempt Rate
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
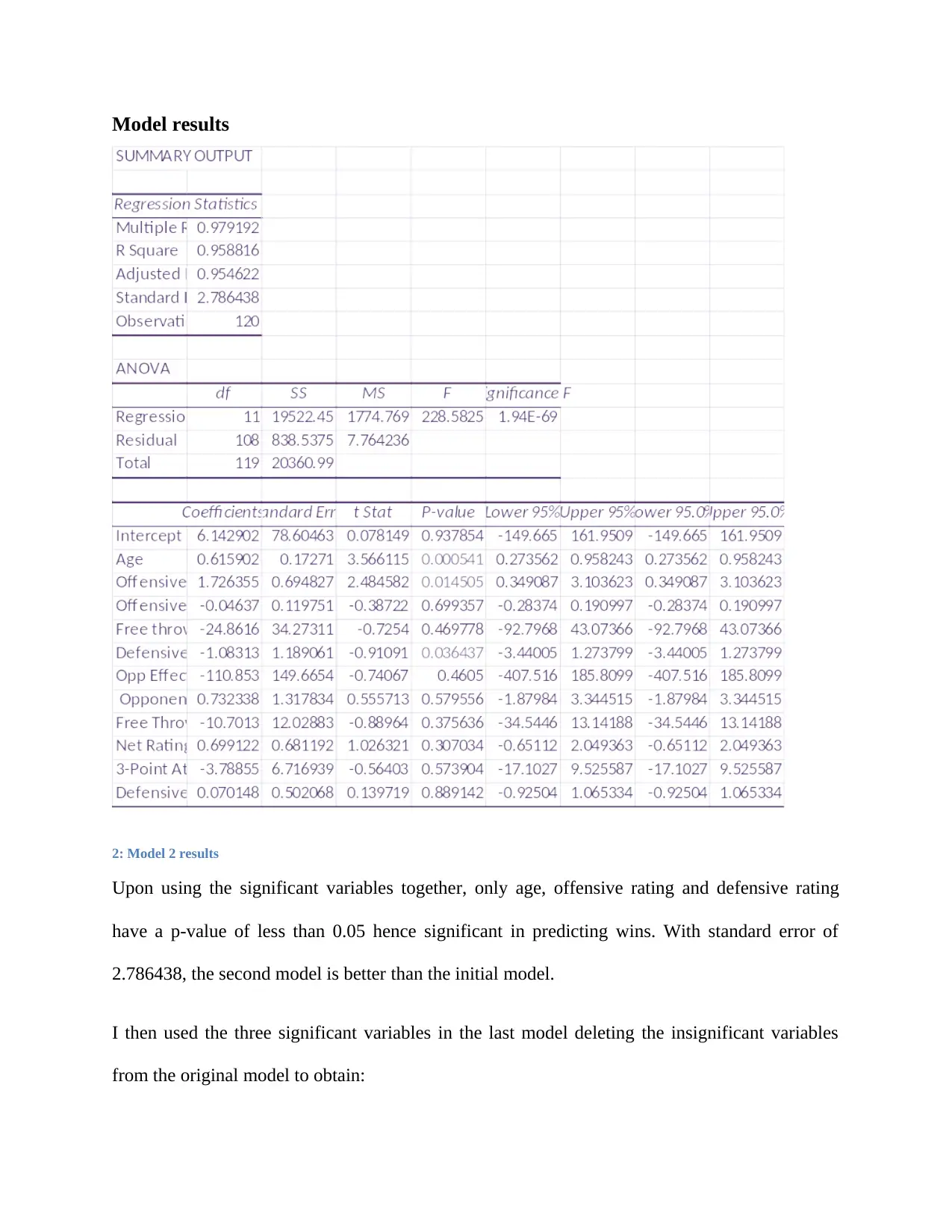
Model results
2: Model 2 results
Upon using the significant variables together, only age, offensive rating and defensive rating
have a p-value of less than 0.05 hence significant in predicting wins. With standard error of
2.786438, the second model is better than the initial model.
I then used the three significant variables in the last model deleting the insignificant variables
from the original model to obtain:
2: Model 2 results
Upon using the significant variables together, only age, offensive rating and defensive rating
have a p-value of less than 0.05 hence significant in predicting wins. With standard error of
2.786438, the second model is better than the initial model.
I then used the three significant variables in the last model deleting the insignificant variables
from the original model to obtain:

Win= β0 + β1Age+ β2 OffensiveRating+ β3DefensiveRating and hence the results in figure 3 are
obtained.
In the third model, the standard error is 2.759 which is less than that of model 1 and 2. In
addition, the R-squared is 0.9566, thence the model explains for 95.66% of the variability which
is relatively high while the adjusted R-squared is relatively high at 0.955506 both the R-squared
and adjusted R-squared are close to 1 which indicates that the model is good for predicting wins
hence the best of the three models given that it has the least standard error. When using 0 as a
constant with the variables remaining the same, the model yields:
obtained.
In the third model, the standard error is 2.759 which is less than that of model 1 and 2. In
addition, the R-squared is 0.9566, thence the model explains for 95.66% of the variability which
is relatively high while the adjusted R-squared is relatively high at 0.955506 both the R-squared
and adjusted R-squared are close to 1 which indicates that the model is good for predicting wins
hence the best of the three models given that it has the least standard error. When using 0 as a
constant with the variables remaining the same, the model yields:
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

SUMMARY OUTPUT
Regression Statistics
Multiple R 0.997938
R Square 0.99588
Adjusted R Square0.987262
Standard Error2.796102
Observations 120
ANOVA
df SS MS F Significance F
Regression 3 221084.3 73694.76 9426.065 2.4E-138
Residual 117 914.7281 7.818189
Total 120 221999
CoefficientsStandard Error t Stat P-value Lower 95%Upper 95%Lower 95.0%Upper 95.0%
Intercept 0 #N/A #N/A #N/A #N/A #N/A #N/A #N/A
Age 0.734326 0.146056 5.027716 1.81E-06 0.44507 1.023581 0.44507 1.023581
Offensive Rating2.487747 0.066637 37.33275 7.77E-67 2.355776 2.619718 2.355776 2.619718
Defensive Rating-2.2859 0.051369 -44.4995 3.56E-75 -2.38763 -2.18416 -2.38763 -2.18416
Whereas the R-squared and the adjusted R-squared statistics are higher than the third model, the
standard error is higher hence the model is not better than the third.
Therefore the model used is the third multiple regression model, i.e.
Win= 29.65+ 0.6489Age+2.3906Offensie rating- 2.4465Defensive rating
Margin of error calculation
Margin of error= Stndard error
2 √n . Z α
But the standard error is 2.759, Z α statistic is 1.96 at 95% confidence interval and n is the sample
size which is 120. Hence the Margin of error is 0.04506.
Regression Statistics
Multiple R 0.997938
R Square 0.99588
Adjusted R Square0.987262
Standard Error2.796102
Observations 120
ANOVA
df SS MS F Significance F
Regression 3 221084.3 73694.76 9426.065 2.4E-138
Residual 117 914.7281 7.818189
Total 120 221999
CoefficientsStandard Error t Stat P-value Lower 95%Upper 95%Lower 95.0%Upper 95.0%
Intercept 0 #N/A #N/A #N/A #N/A #N/A #N/A #N/A
Age 0.734326 0.146056 5.027716 1.81E-06 0.44507 1.023581 0.44507 1.023581
Offensive Rating2.487747 0.066637 37.33275 7.77E-67 2.355776 2.619718 2.355776 2.619718
Defensive Rating-2.2859 0.051369 -44.4995 3.56E-75 -2.38763 -2.18416 -2.38763 -2.18416
Whereas the R-squared and the adjusted R-squared statistics are higher than the third model, the
standard error is higher hence the model is not better than the third.
Therefore the model used is the third multiple regression model, i.e.
Win= 29.65+ 0.6489Age+2.3906Offensie rating- 2.4465Defensive rating
Margin of error calculation
Margin of error= Stndard error
2 √n . Z α
But the standard error is 2.759, Z α statistic is 1.96 at 95% confidence interval and n is the sample
size which is 120. Hence the Margin of error is 0.04506.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Model deployment
After successful model development, the model was deployed using 2016-2017 and 2017-2018
historical data. I obtained the results in figure 3 from excel:
After successful model development, the model was deployed using 2016-2017 and 2017-2018
historical data. I obtained the results in figure 3 from excel:

ObservationPredicted winResidualsStandard Residuals Percentile win
1 64.12928 0.870721 0.261173 0.833333 20
2 61.23478 -2.23478 -0.67032 2.5 21
3 57.40126 0.598745 0.179594 4.166667 22
4 51.69483 -3.69483 -1.10827 5.833333 24
5 51.83235 0.16765 0.050287 7.5 24
6 50.21376 -2.21376 -0.66402 9.166667 24
7 49.07329 5.926706 1.777719 10.83333 25
8 48.85012 -1.85012 -0.55494 12.5 26
9 47.40765 1.59235 0.477626 14.16667 27
10 48.19785 -1.19785 -0.35929 15.83333 27
11 45.54429 0.455706 0.136689 17.5 28
12 44.73999 3.260007 0.977841 19.16667 28
13 44.61013 3.389869 1.016793 20.83333 29
14 45.80384 4.196164 1.258642 22.5 29
15 42.82463 0.175368 0.052602 24.16667 31
16 41.98837 0.011626 0.003487 25.83333 31
17 41.6928 2.307201 0.692046 27.5 32
18 42.07694 -6.07694 -1.82278 29.16667 33
19 40.26145 -1.26145 -0.37837 30.83333 34
20 40.62174 3.37826 1.013311 32.5 35
21 36.20791 -1.20791 -0.36231 34.16667 36
22 33.08499 -9.08499 -2.72505 35.83333 36
23 32.063 -3.063 -0.91875 37.5 37
24 31.47672 -3.47672 -1.04285 39.16667 39
25 28.21909 -3.21909 -0.96557 40.83333 40
26 26.45499 -2.45499 -0.73638 42.5 41
27 24.31354 -2.31354 -0.69395 44.16667 41
28 22.0045 4.995498 1.498403 45.83333 41
29 22.29153 4.708474 1.412309 47.5 42
30 16.83538 4.164617 1.249179 49.16667 42
31 60.25898 6.741016 2.021971 50.83333 42
32 60.56851 0.431493 0.129426 52.5 43
33 56.71137 -1.71137 -0.51333 54.16667 43
34 53.85853 -2.85853 -0.85742 55.83333 43
35 51.63076 -0.63076 -0.1892 57.5 44
36 52.80033 -1.80033 -0.54001 59.16667 44
37 51.12325 -0.12325 -0.03697 60.83333 46
38 48.38757 4.612428 1.3835 62.5 47
39 46.28695 2.713048 0.81378 64.16667 47
40 42.45189 4.548113 1.364209 65.83333 47
41 42.93248 0.067516 0.020251 67.5 48
42 43.42926 -2.42926 -0.72866 69.16667 48
43 43.43173 -3.43173 -1.02935 70.83333 48
44 41.74424 -0.74424 -0.22323 72.5 48
45 41.62495 -5.62495 -1.68721 74.16667 49
46 40.04736 0.952636 0.285744 75.83333 49
47 40.56214 1.437864 0.431288 77.5 50
48 40.73596 1.264042 0.37915 79.16667 51
49 38.36428 -7.36428 -2.20892 80.83333 51
50 38.34973 4.650272 1.394852 82.5 51
51 37.39749 -0.39749 -0.11923 84.16667 51
52 34.61635 -0.61635 -0.18487 85.83333 52
53 32.83703 0.162968 0.048882 87.5 53
54 31.54057 0.459426 0.137805 89.16667 55
55 32.02149 -1.02149 -0.3064 90.83333 55
56 26.87184 -2.87184 -0.86141 92.5 58
57 25.45186 2.548135 0.764315 94.16667 59
58 23.39886 2.601137 0.780212 95.83333 61
59 23.18232 5.817684 1.745018 97.5 65
60 23.94943 -3.94943 -1.18463 99.16667 67
3:Prediction results
1 64.12928 0.870721 0.261173 0.833333 20
2 61.23478 -2.23478 -0.67032 2.5 21
3 57.40126 0.598745 0.179594 4.166667 22
4 51.69483 -3.69483 -1.10827 5.833333 24
5 51.83235 0.16765 0.050287 7.5 24
6 50.21376 -2.21376 -0.66402 9.166667 24
7 49.07329 5.926706 1.777719 10.83333 25
8 48.85012 -1.85012 -0.55494 12.5 26
9 47.40765 1.59235 0.477626 14.16667 27
10 48.19785 -1.19785 -0.35929 15.83333 27
11 45.54429 0.455706 0.136689 17.5 28
12 44.73999 3.260007 0.977841 19.16667 28
13 44.61013 3.389869 1.016793 20.83333 29
14 45.80384 4.196164 1.258642 22.5 29
15 42.82463 0.175368 0.052602 24.16667 31
16 41.98837 0.011626 0.003487 25.83333 31
17 41.6928 2.307201 0.692046 27.5 32
18 42.07694 -6.07694 -1.82278 29.16667 33
19 40.26145 -1.26145 -0.37837 30.83333 34
20 40.62174 3.37826 1.013311 32.5 35
21 36.20791 -1.20791 -0.36231 34.16667 36
22 33.08499 -9.08499 -2.72505 35.83333 36
23 32.063 -3.063 -0.91875 37.5 37
24 31.47672 -3.47672 -1.04285 39.16667 39
25 28.21909 -3.21909 -0.96557 40.83333 40
26 26.45499 -2.45499 -0.73638 42.5 41
27 24.31354 -2.31354 -0.69395 44.16667 41
28 22.0045 4.995498 1.498403 45.83333 41
29 22.29153 4.708474 1.412309 47.5 42
30 16.83538 4.164617 1.249179 49.16667 42
31 60.25898 6.741016 2.021971 50.83333 42
32 60.56851 0.431493 0.129426 52.5 43
33 56.71137 -1.71137 -0.51333 54.16667 43
34 53.85853 -2.85853 -0.85742 55.83333 43
35 51.63076 -0.63076 -0.1892 57.5 44
36 52.80033 -1.80033 -0.54001 59.16667 44
37 51.12325 -0.12325 -0.03697 60.83333 46
38 48.38757 4.612428 1.3835 62.5 47
39 46.28695 2.713048 0.81378 64.16667 47
40 42.45189 4.548113 1.364209 65.83333 47
41 42.93248 0.067516 0.020251 67.5 48
42 43.42926 -2.42926 -0.72866 69.16667 48
43 43.43173 -3.43173 -1.02935 70.83333 48
44 41.74424 -0.74424 -0.22323 72.5 48
45 41.62495 -5.62495 -1.68721 74.16667 49
46 40.04736 0.952636 0.285744 75.83333 49
47 40.56214 1.437864 0.431288 77.5 50
48 40.73596 1.264042 0.37915 79.16667 51
49 38.36428 -7.36428 -2.20892 80.83333 51
50 38.34973 4.650272 1.394852 82.5 51
51 37.39749 -0.39749 -0.11923 84.16667 51
52 34.61635 -0.61635 -0.18487 85.83333 52
53 32.83703 0.162968 0.048882 87.5 53
54 31.54057 0.459426 0.137805 89.16667 55
55 32.02149 -1.02149 -0.3064 90.83333 55
56 26.87184 -2.87184 -0.86141 92.5 58
57 25.45186 2.548135 0.764315 94.16667 59
58 23.39886 2.601137 0.780212 95.83333 61
59 23.18232 5.817684 1.745018 97.5 65
60 23.94943 -3.94943 -1.18463 99.16667 67
3:Prediction results
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

0 2 4 6 8 10 12
0
2
4
6
8
10
12
Predicted wins and True wins for
2016-2017, 2017-2018
Predicted Wins
True wins
4: Comparison graph for true and predicted Wins for 2016-2017 and 2017-2018
Application of model to the ongoing 2018-2019 season
0 2 4 6 8 10 12
0
2
4
6
8
10
12
Predicted winnings and conference
standins for the 2018-2019 season
Predicted win
conference standings
The predicted results that I obtained using the final predictive model are reflective of the
conference standings results that is, they align.
0
2
4
6
8
10
12
Predicted wins and True wins for
2016-2017, 2017-2018
Predicted Wins
True wins
4: Comparison graph for true and predicted Wins for 2016-2017 and 2017-2018
Application of model to the ongoing 2018-2019 season
0 2 4 6 8 10 12
0
2
4
6
8
10
12
Predicted winnings and conference
standins for the 2018-2019 season
Predicted win
conference standings
The predicted results that I obtained using the final predictive model are reflective of the
conference standings results that is, they align.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Classification modeling
One notable difference existing between classification and multiple regression is that, generally,
classification is aims at predicting classes whereas regression aims at quantitative prediction.
(Gupta and Jagga, 2014). The purpose of classification modeling is to predict which teams
qualified for the playoffs for each seasons as well as the ongoing season.
Data training
The Complete dataset is divided into source and subject data which then is spitted into training
and test data for classification purpose where training data makes up 65% with test data making
up 35%.
The rules for the decision tree classification are:
0 10 20 30
-1
0
1
2
3
How well do the Rules separate the Classes
Observations
Rule ID
Therefore the criteria for a team’s inclusion in the playoff is that, a team is included if and only if
the true wins are greater than 47, while it fails to enter the playoffs if the true wins are less than
41.
One notable difference existing between classification and multiple regression is that, generally,
classification is aims at predicting classes whereas regression aims at quantitative prediction.
(Gupta and Jagga, 2014). The purpose of classification modeling is to predict which teams
qualified for the playoffs for each seasons as well as the ongoing season.
Data training
The Complete dataset is divided into source and subject data which then is spitted into training
and test data for classification purpose where training data makes up 65% with test data making
up 35%.
The rules for the decision tree classification are:
0 10 20 30
-1
0
1
2
3
How well do the Rules separate the Classes
Observations
Rule ID
Therefore the criteria for a team’s inclusion in the playoff is that, a team is included if and only if
the true wins are greater than 47, while it fails to enter the playoffs if the true wins are less than
41.

1
3
5
7
9
11
13
15
17
19
21
23
25
27
29
0
20
40
60
80
100
120
Comparison of predicted playoff and
true playoff
Predicted Play off
Play off
Root
TRUE
Node 1
True w ins<41 2 out Support: 30% Conf: 100%
TRUE
Node 2
True w ins>=41
FALSE
Node 3
True w ins<47
FALSE
Node 5
Net Rating<0.78
FALSE
Node 7
Pace Factor: An
estimate of
possessions per 48
minutes<97.6 0 in Support: 18% Conf: 100%
FALSE
Node 8
Pace Factor: An
estimate of
possessions per 48
minutes>=97.6 0 out Support: 2% Conf: 100%
FALSE
Node 6
Net Rating>=0.78 0 out Support: 4% Conf: 100%
FALSE
Node 4
True w ins>=47 0 in Support: 46% Conf: 100%
FALSE
5: Decision tree
3
5
7
9
11
13
15
17
19
21
23
25
27
29
0
20
40
60
80
100
120
Comparison of predicted playoff and
true playoff
Predicted Play off
Play off
Root
TRUE
Node 1
True w ins<41 2 out Support: 30% Conf: 100%
TRUE
Node 2
True w ins>=41
FALSE
Node 3
True w ins<47
FALSE
Node 5
Net Rating<0.78
FALSE
Node 7
Pace Factor: An
estimate of
possessions per 48
minutes<97.6 0 in Support: 18% Conf: 100%
FALSE
Node 8
Pace Factor: An
estimate of
possessions per 48
minutes>=97.6 0 out Support: 2% Conf: 100%
FALSE
Node 6
Net Rating>=0.78 0 out Support: 4% Conf: 100%
FALSE
Node 4
True w ins>=47 0 in Support: 46% Conf: 100%
FALSE
5: Decision tree
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.