Introduction to Biostatistics 401077: Assignment 1, Autumn 2020
VerifiedAdded on 2022/09/07
|6
|892
|17
Homework Assignment
AI Summary
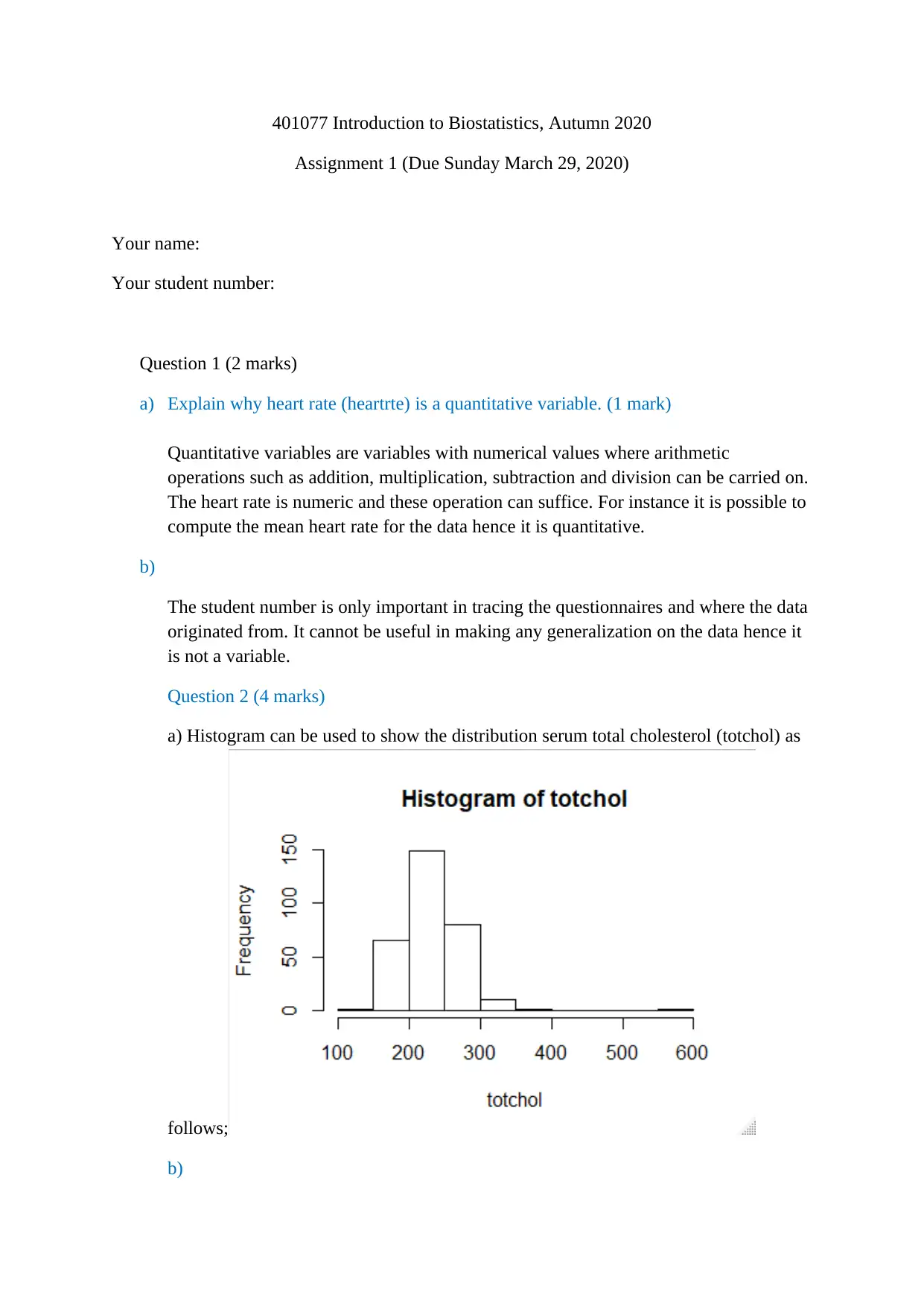
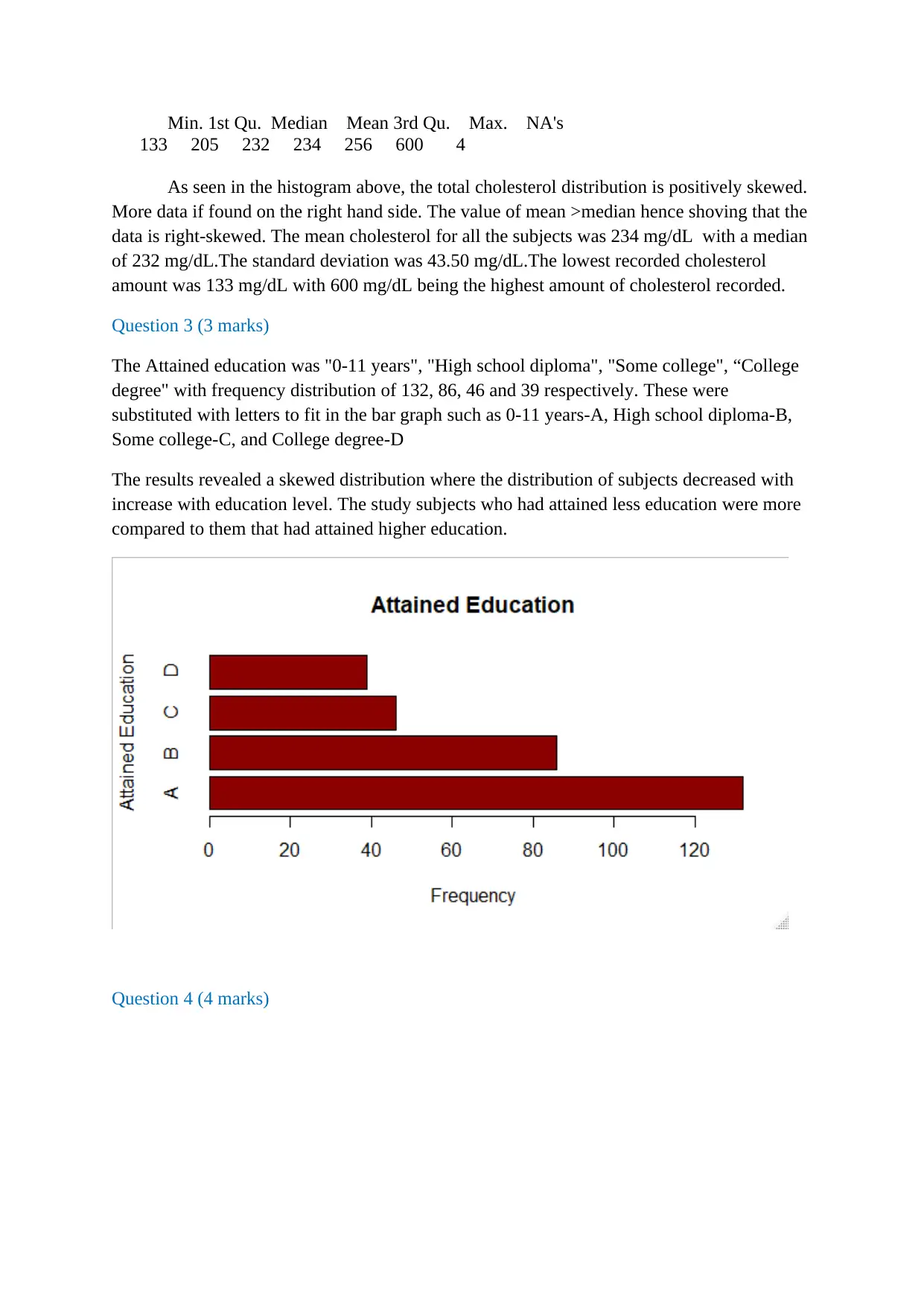
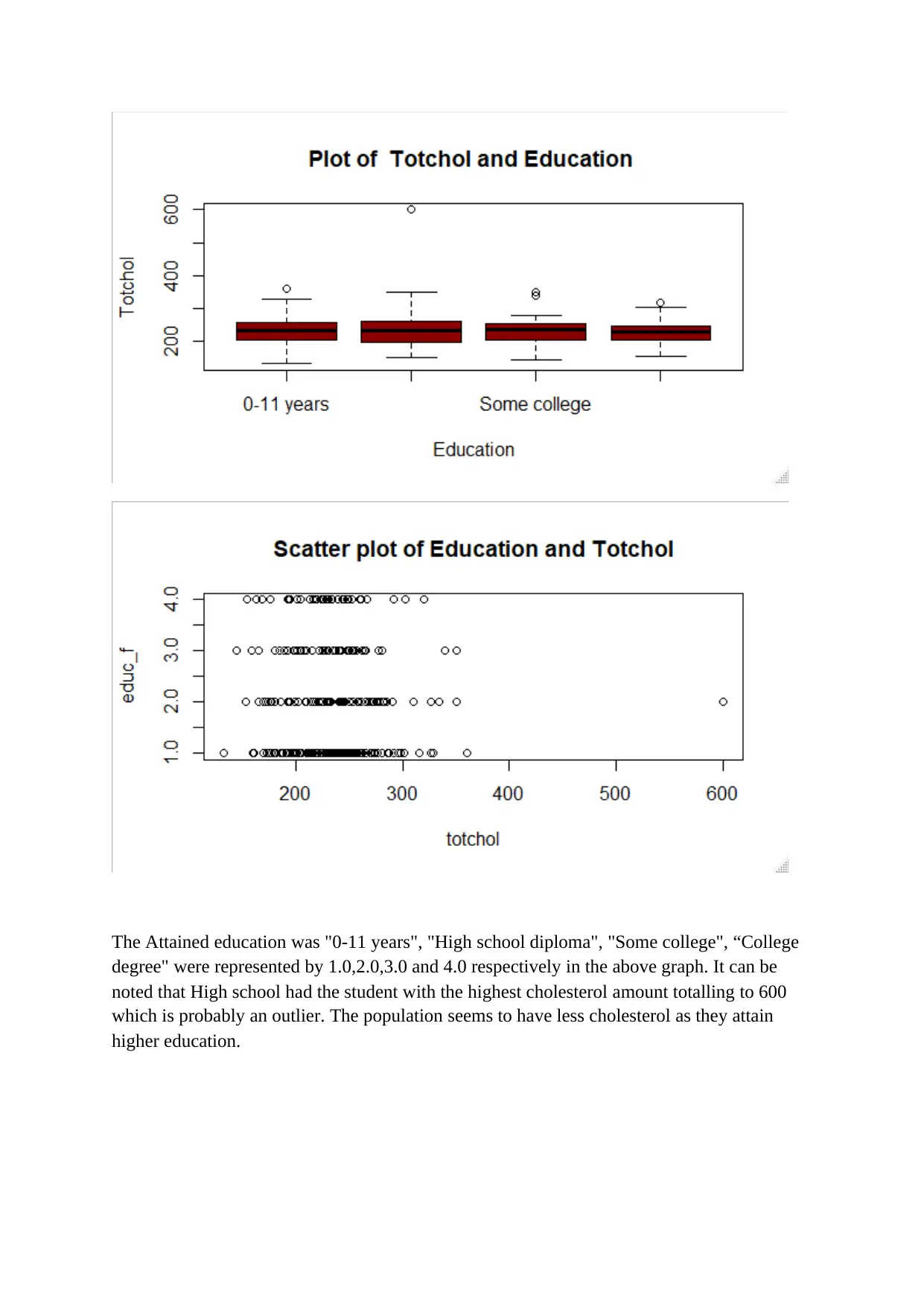
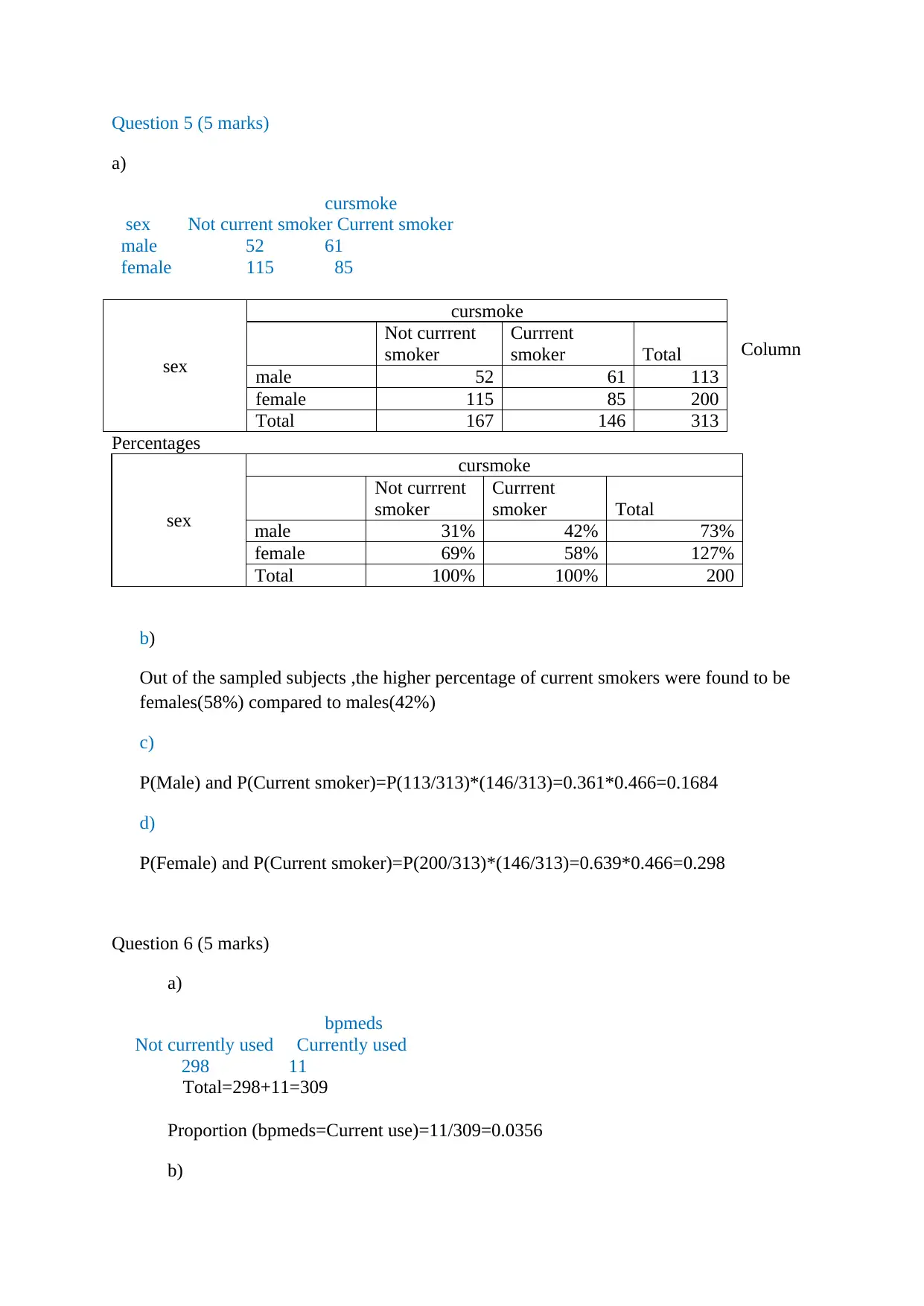
This document presents a comprehensive solution to a biostatistics assignment. The assignment analyzes a dataset from the Framingham Study, exploring quantitative variables like heart rate and serum cholesterol, and explaining why student numbers are not variables. It includes the creation of histograms to visualize data distributions, specifically addressing skewness and the mean versus median relationship. The solution analyzes categorical data, such as attained education and smoking habits, using bar graphs and frequency distributions. Contingency tables are used to examine the relationship between sex and smoking status, including the calculation of conditional probabilities. The solution also delves into the application of the binomial model to analyze the use of blood pressure medication and calculates relevant probabilities. Furthermore, the solution calculates z-scores and discusses methods for computing the mean and standard deviation, along with the percentage of individuals with systolic blood pressure below a certain threshold. The assignment provides a detailed analysis of the data and employs various statistical techniques and concepts.


1 out of 6


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.