Numeracy and Data Analysis: Assignment for University of Suffolk
VerifiedAdded on 2023/01/11
|8
|1342
|80
Homework Assignment
AI Summary
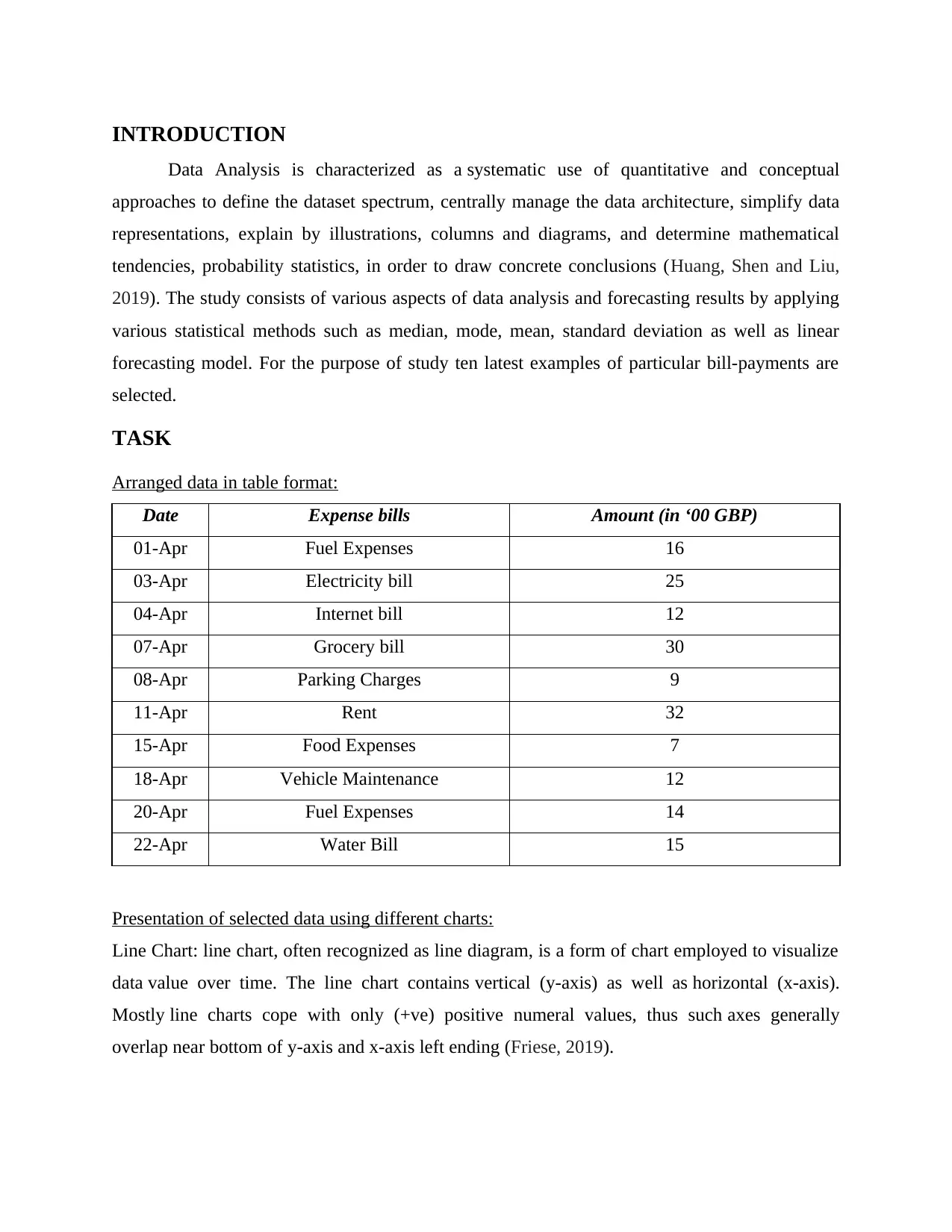
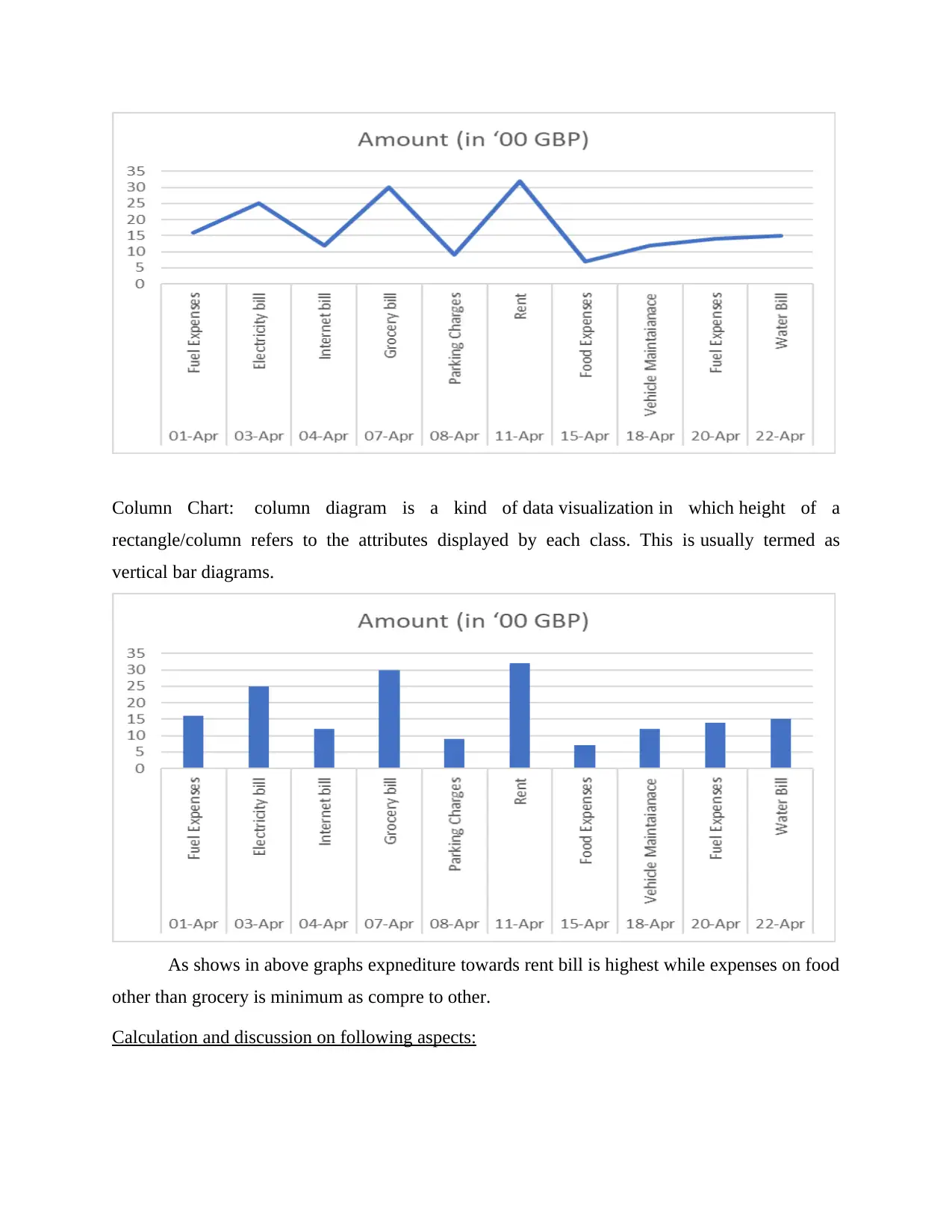
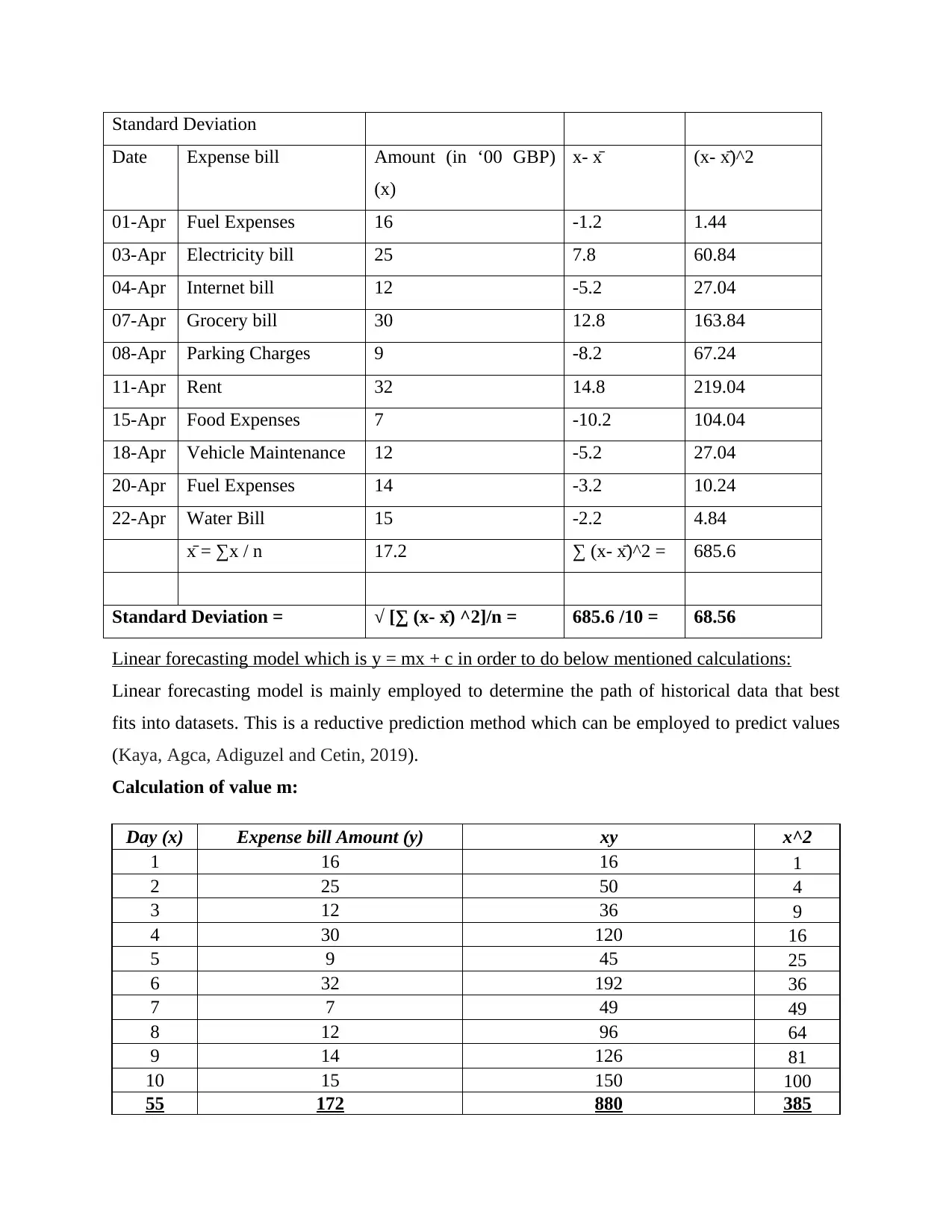
This document presents a comprehensive solution to a Numeracy and Data Analysis assignment. The solution begins with an introduction to data analysis and its significance, followed by a task that involves arranging data in a table format and presenting selected data using line and column charts. The assignment includes detailed calculations and discussions on various statistical aspects, such as mean, median, mode, range, and standard deviation. Furthermore, it incorporates a linear forecasting model to predict future values. The assignment also includes the calculation of values for the linear forecasting model (y = mx + c) to forecast expenses for day 12 and day 14, and concludes with a summary of findings and references to relevant sources. The solution provides a step-by-step breakdown of the calculations and interpretations, making it a valuable resource for students studying data analysis and forecasting techniques.





1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.