Comprehensive Data Analysis Assignment: Statistics and Forecasting
VerifiedAdded on 2023/01/12
|10
|1666
|76
Homework Assignment
AI Summary
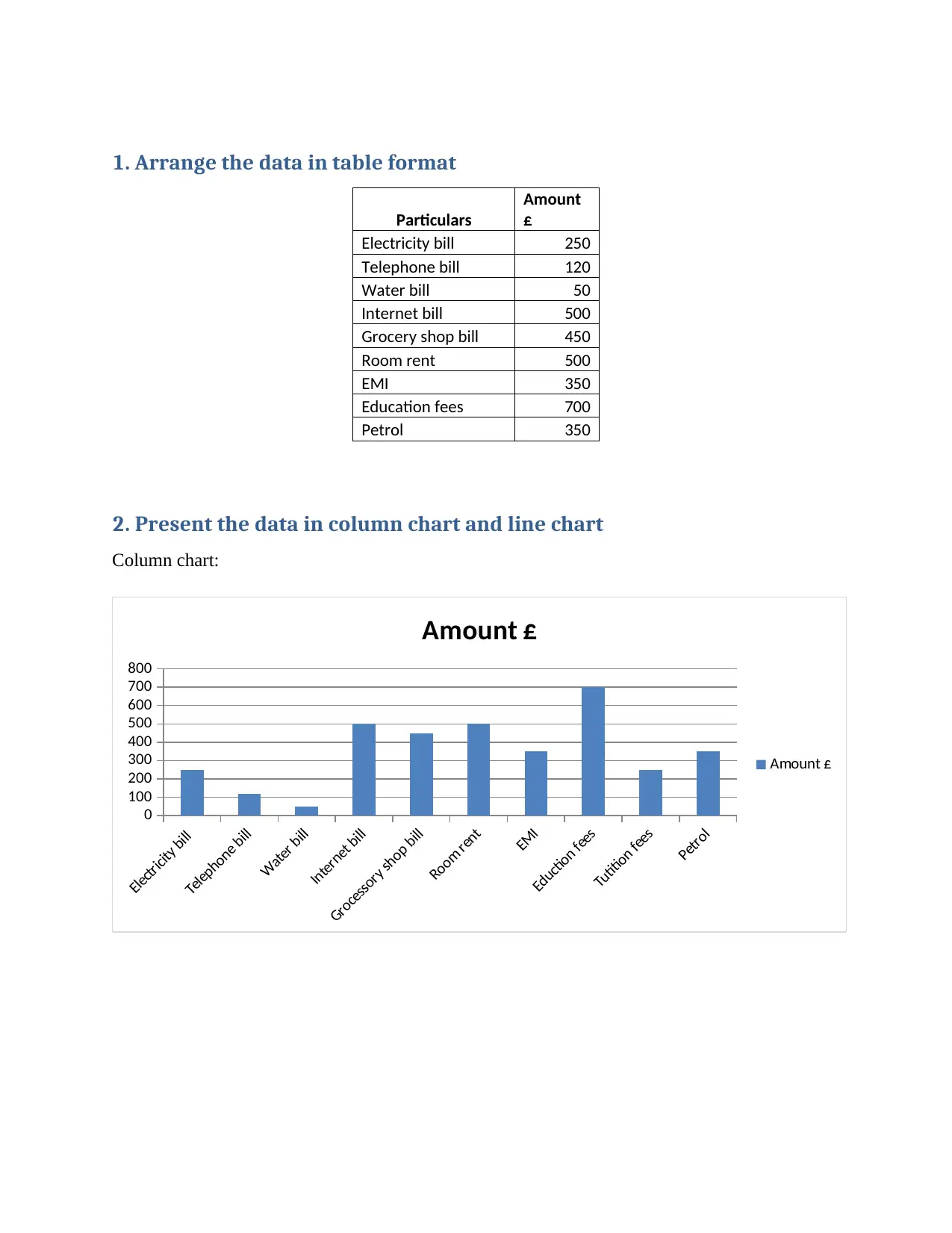
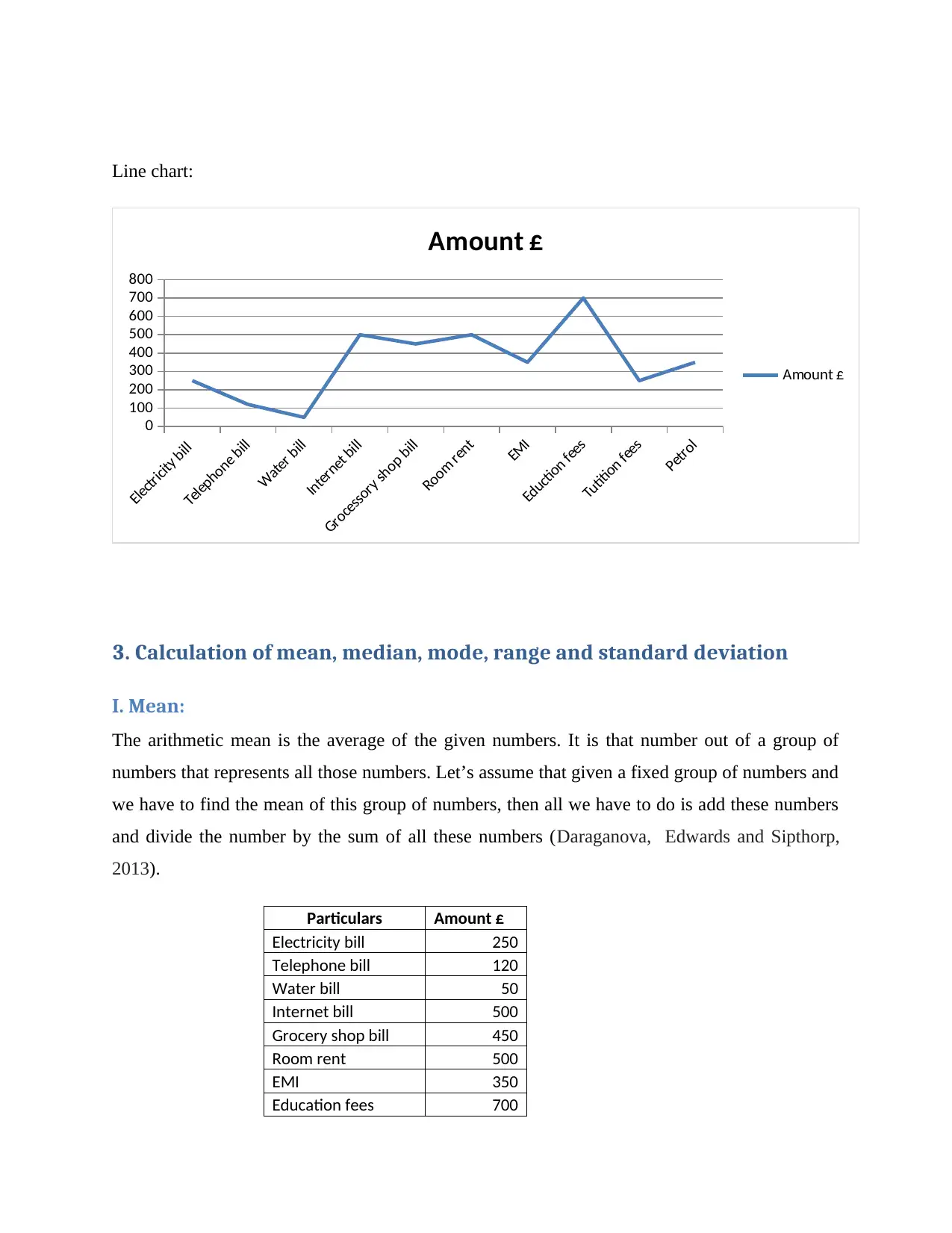
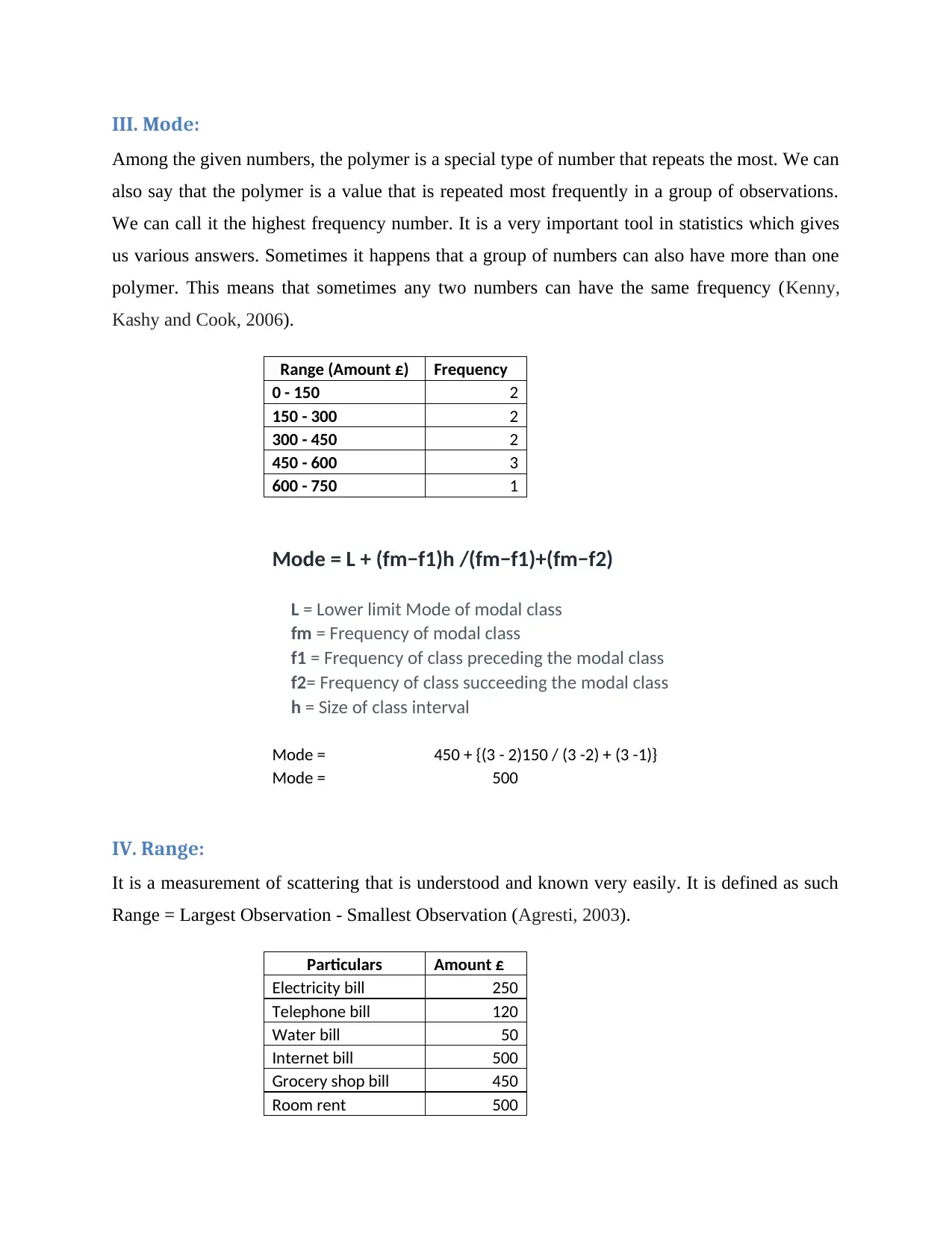
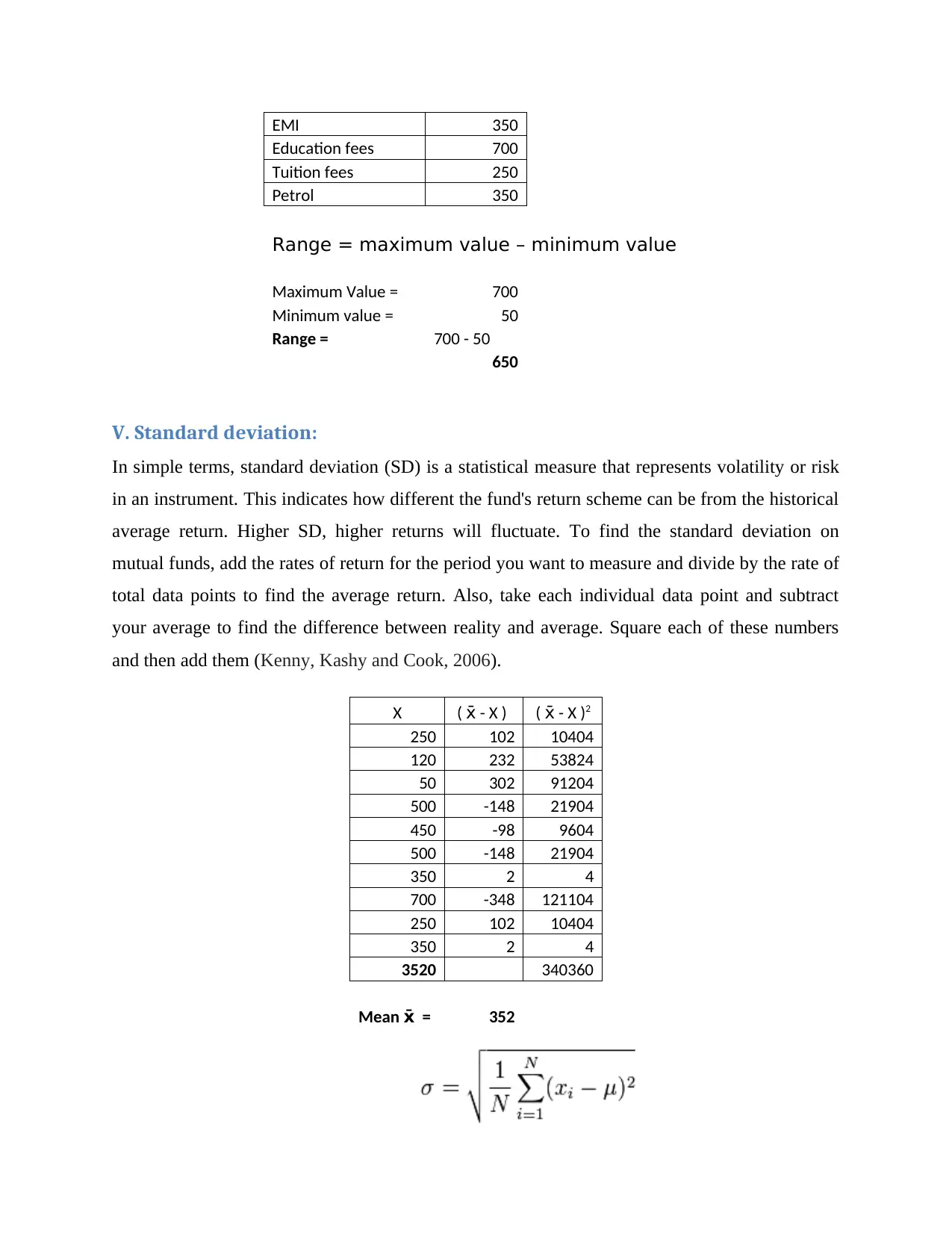
This homework assignment focuses on numeracy and data analysis, covering various statistical concepts and calculations. The assignment begins with arranging data in a table format, followed by presenting the data using column and line charts for visual representation. The core of the assignment involves calculating key statistical measures, including the mean, median, mode, range, and standard deviation. Furthermore, the assignment delves into linear forecasting using the y = mx + c model, calculating the slope (m), y-intercept (c), and making predictions for future expenses. The assignment includes detailed explanations of each calculation, providing a comprehensive understanding of data analysis techniques. This assignment is available on Desklib, a platform that provides AI-based study tools for students.






1 out of 10


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.