Postgraduate potential Applicants on Data Analysis using (AWS) Serverless Cloud Technology
VerifiedAdded on 2023/01/16
|82
|11633
|75
AI Summary
This report focuses on the analysis of postgraduate potential applicants using data analysis and AWS serverless cloud technology. It discusses the growth of big data, the use of cloud servers, and the challenges and benefits of using analytical tools. The report also outlines the objectives, research questions, and methodology of the project.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Postgraduate potential Applicants on Data
Analysis using (AWS) Server less Cloud
Technology
1
Analysis using (AWS) Server less Cloud
Technology
1
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

ABSTRACT
It has summarised about the unprecedented growth of information or data whether they are
centralised of oncoming for handling huge data set through relational database management
system. The project has concerned about the big data technology such as Amazon web server,
which are collecting or gathering large amount of data on cloud server. In order to increasing the
storage processing of enterprise and also derived the value from using big data analytics.
However, it has rapidly changing the demand of enterprise in global marketplace, because it has
automatically flowing large data or information. Therefore, it obvious to bring new challenges
but it could be managed or handled by analytical tool or platform. Afterwards, it has planned or
selected an appropriate architecture to storage of infrastructure, processing and visualize in
proper manner.
2
It has summarised about the unprecedented growth of information or data whether they are
centralised of oncoming for handling huge data set through relational database management
system. The project has concerned about the big data technology such as Amazon web server,
which are collecting or gathering large amount of data on cloud server. In order to increasing the
storage processing of enterprise and also derived the value from using big data analytics.
However, it has rapidly changing the demand of enterprise in global marketplace, because it has
automatically flowing large data or information. Therefore, it obvious to bring new challenges
but it could be managed or handled by analytical tool or platform. Afterwards, it has planned or
selected an appropriate architecture to storage of infrastructure, processing and visualize in
proper manner.
2

Contents
ABSTRACT....................................................................................................................................2
CHAPTER-1 INTRODUCTION.....................................................................................................4
CHAPTER-2 LITERATURE REVIEW AND THEORETHICAL BACK GROUND..................6
CHAPTER-3 METHODOLOGY, TECHNOLOGY AND OUTCOME......................................18
CHAPTER-4 DESIGN, IMPLEMENTATION AND TESTING.................................................24
CHAPTER-5 CONCLUSION AND RECOMMENDATION......................................................40
REFERENCES..............................................................................................................................42
3
ABSTRACT....................................................................................................................................2
CHAPTER-1 INTRODUCTION.....................................................................................................4
CHAPTER-2 LITERATURE REVIEW AND THEORETHICAL BACK GROUND..................6
CHAPTER-3 METHODOLOGY, TECHNOLOGY AND OUTCOME......................................18
CHAPTER-4 DESIGN, IMPLEMENTATION AND TESTING.................................................24
CHAPTER-5 CONCLUSION AND RECOMMENDATION......................................................40
REFERENCES..............................................................................................................................42
3

CHAPTER-1 INTRODUCTION
Data analysis is based on the process or method which mainly consider for purpose of
analytics. Sometimes, it is composed with process which help for performed different
functionality (Trudgian and Mirzaei, 2012). Data analytics is a practice concerned about the
entire business because this process will help for managing and controlling behaviour or data
generated by different activities.
In this report, it will be concerned about the different functions that performed by Data
analytical technology such as Amazon web service. Furthermore, it is a proper modelling of
information or data. The project will help for identifying the specific rate of potential applicants
on analysis the data by using server less cloud technology.
Aim
Aims to provide a solution on a data analytics dashboard that universities can use to
predict and analyse the behaviour of postgraduate applicant by gathering dataset from different
organisations such UCAS, HESA and Universities and integrate with non-relation architecture.
Back ground
Big data is based on the modern technology in term of data analytics. It consists of large
amount of information or data. Therefore, it is able to collect, store or maintain the data and then
processing software. Initially, it has identified the various type of challenges factors that always
support for collecting data and also sharing files between one or more devices. Through big data
technology, it can easily modify, structure and maintain the specific privacy or security aspects.
This modern technology will support for involving the all unstructured or structure data but
arranging through big data into structure format.
Server less technology is mainly used for identifying the potential applicants which
always supports for maintain the scalability and flexibility in data management. AWS is consider
an appropriate server less technology that applicable in the different organizations. Furthermore,
server less technology will be performed the process and also represented through use cases.
AWS can be used the effective components in achieving the accurate result or technology
(Backes and et al., 2019). Generally, this technology has been considered the Python
programming language. By using server less technology, it has been reducing the risk, threat
4
Data analysis is based on the process or method which mainly consider for purpose of
analytics. Sometimes, it is composed with process which help for performed different
functionality (Trudgian and Mirzaei, 2012). Data analytics is a practice concerned about the
entire business because this process will help for managing and controlling behaviour or data
generated by different activities.
In this report, it will be concerned about the different functions that performed by Data
analytical technology such as Amazon web service. Furthermore, it is a proper modelling of
information or data. The project will help for identifying the specific rate of potential applicants
on analysis the data by using server less cloud technology.
Aim
Aims to provide a solution on a data analytics dashboard that universities can use to
predict and analyse the behaviour of postgraduate applicant by gathering dataset from different
organisations such UCAS, HESA and Universities and integrate with non-relation architecture.
Back ground
Big data is based on the modern technology in term of data analytics. It consists of large
amount of information or data. Therefore, it is able to collect, store or maintain the data and then
processing software. Initially, it has identified the various type of challenges factors that always
support for collecting data and also sharing files between one or more devices. Through big data
technology, it can easily modify, structure and maintain the specific privacy or security aspects.
This modern technology will support for involving the all unstructured or structure data but
arranging through big data into structure format.
Server less technology is mainly used for identifying the potential applicants which
always supports for maintain the scalability and flexibility in data management. AWS is consider
an appropriate server less technology that applicable in the different organizations. Furthermore,
server less technology will be performed the process and also represented through use cases.
AWS can be used the effective components in achieving the accurate result or technology
(Backes and et al., 2019). Generally, this technology has been considered the Python
programming language. By using server less technology, it has been reducing the risk, threat
4
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

within data management in order to maintain a proper security as well as privacy. Furthermore,
different organizations that has been adopted the data protection regulation (GDPR) which
always help for providing the better way to strengthening all essential provision in regards of
information.
Problem statement
The problem has been occurred when government introduced new PG loan in 2016. Its
primary aim is to influence or encourage towards the postgraduate enrolment number. In order to
show the evidence in regards of domestic recruitment. On the other hand, it has identified the
universities face issue because they are able to follow the proper threat within postgraduate
applicants (BaiJhaney and Wells, 2019). Therefore, it is very difficult for managing the large
amount of data in regarding the recruitment. That’s why, universities are planning to use server
less modern technology which always supports for analysis large amount of data or information.
Course leader
The research project is mainly focused on the improve the necessary requirement for
business so that it should be identified the problem at different level. The majority is that when
overseas applications but they do not materialize. The problem has been occurred when receiving
the application throughout the years. It would be better for considering the offer on the basis
annually. When resolved the problem so that overseas application and also accumulate the
multiple application in order to create the attention at the time of advertisement.
Objective
To build a data analytics visual environment to predict postgraduate applicants based on
previous data that can be used for management decision-making.
Using algorithm analysis to understand the demographics of applicants and
recommendations on where to focus on recruitment and advertisement for postgraduate
applicants.
Review best Technologies AWS platform or tools and infrastructure to use for data
analytics.
To develop postgraduate recruiting dashboard to collect, transform, store, and process
data streaming using latest technologies Amazon web server.
5
different organizations that has been adopted the data protection regulation (GDPR) which
always help for providing the better way to strengthening all essential provision in regards of
information.
Problem statement
The problem has been occurred when government introduced new PG loan in 2016. Its
primary aim is to influence or encourage towards the postgraduate enrolment number. In order to
show the evidence in regards of domestic recruitment. On the other hand, it has identified the
universities face issue because they are able to follow the proper threat within postgraduate
applicants (BaiJhaney and Wells, 2019). Therefore, it is very difficult for managing the large
amount of data in regarding the recruitment. That’s why, universities are planning to use server
less modern technology which always supports for analysis large amount of data or information.
Course leader
The research project is mainly focused on the improve the necessary requirement for
business so that it should be identified the problem at different level. The majority is that when
overseas applications but they do not materialize. The problem has been occurred when receiving
the application throughout the years. It would be better for considering the offer on the basis
annually. When resolved the problem so that overseas application and also accumulate the
multiple application in order to create the attention at the time of advertisement.
Objective
To build a data analytics visual environment to predict postgraduate applicants based on
previous data that can be used for management decision-making.
Using algorithm analysis to understand the demographics of applicants and
recommendations on where to focus on recruitment and advertisement for postgraduate
applicants.
Review best Technologies AWS platform or tools and infrastructure to use for data
analytics.
To develop postgraduate recruiting dashboard to collect, transform, store, and process
data streaming using latest technologies Amazon web server.
5

To build non-relational architecture on a real-time predictive analytics system to identify
the applicants before they become a student using previous data statistics.
Integrate data between the various system and store data on cloud system for processing
and streaming.
The aim is to develop a dashboard for universities to predict student’s behaviors on real
time to allow management teams to make effective decisions based on those insights.
Develop and design data Analytics dashboard on cloud service environment using a cloud
company such as Amazon Web Service or Azure platform.
Research questions
What are different type of data analytical tool or platform used?
What do you understand concept of AWS modern technology?
What are advantage and disadvantage of server less technology in organization?
What is the relationship between data analytics and predicting the potential applicants?
CHAPTER-2 LITERATURE REVIEW AND THEORETHICAL BACK
GROUND
Theme: 1 cloud computing
Church, Schmidt and Ajayi (2020) Cloud computing is based in the on-demand
availability of service from different application to storage and processing power, especially used
for data storage without establishing the direct management by user. It is the most effective
conceptual innovation in which describing the data centers available to different users over
internet. Moreover, Cloud computing service is mainly covered wide range of options which
always giving the basic storage, networking and process by using natural language processing.
There are various fundamental concept behind the cloud computing. It is mainly storage data
from particular location of service. Many other detail includes as operating system, hardware. In
this way, it become easier for running the entire cloud services in proper manner. Universities or
educational institution also focused on adopting the cloud computing service. This will provide
the better way to manage or store large amount of data. It is very effective in term of security or
privacy so that large number of institution create their own cloud environment.
6
the applicants before they become a student using previous data statistics.
Integrate data between the various system and store data on cloud system for processing
and streaming.
The aim is to develop a dashboard for universities to predict student’s behaviors on real
time to allow management teams to make effective decisions based on those insights.
Develop and design data Analytics dashboard on cloud service environment using a cloud
company such as Amazon Web Service or Azure platform.
Research questions
What are different type of data analytical tool or platform used?
What do you understand concept of AWS modern technology?
What are advantage and disadvantage of server less technology in organization?
What is the relationship between data analytics and predicting the potential applicants?
CHAPTER-2 LITERATURE REVIEW AND THEORETHICAL BACK
GROUND
Theme: 1 cloud computing
Church, Schmidt and Ajayi (2020) Cloud computing is based in the on-demand
availability of service from different application to storage and processing power, especially used
for data storage without establishing the direct management by user. It is the most effective
conceptual innovation in which describing the data centers available to different users over
internet. Moreover, Cloud computing service is mainly covered wide range of options which
always giving the basic storage, networking and process by using natural language processing.
There are various fundamental concept behind the cloud computing. It is mainly storage data
from particular location of service. Many other detail includes as operating system, hardware. In
this way, it become easier for running the entire cloud services in proper manner. Universities or
educational institution also focused on adopting the cloud computing service. This will provide
the better way to manage or store large amount of data. It is very effective in term of security or
privacy so that large number of institution create their own cloud environment.
6

Over the past decade, it has been concluded that interest in adoption of cloud computing
within organization. It always supports for promises the potential to reshape the different way of
acquire or manage need for different efficient resources. In particularly, the line with notion of
different shared services so that cloud computing is consider as innovative model in term of IT
infrastructure. Usually, it enabled to focus on the specific core requirement of enterprise
activities. Thus, it support for increasing the productivity as well as profitability in global
marketplace. The adoption of cloud computing means that automatically improve the simplicity,
scalability and flexibility. Afterwards, it provide the better offers to increase demand of cloud
computing in global marketplace. In recently, it has been reported that 76% of large corporation
are adopting the cloud services whereas 60% of SME are also adopting cloud computing.
Moghaddam (2020) there are lot of definition of cloud computing that has been relevant
to the AWS technology. In order to provide the efficient IT sourcing model for improving the
performance of enterprise application on regular basis. it became wider as internet based service
offering while comprised large amount data storage, hosting network infrastructure. Moreover, it
also added the cloud service consumer which despite that there might be offering better services.
Usually, it is depending the enterprise need and requirement whereas considerable as Saas. It
help for improve the capability of consumer when they can enterprise applications. These are
running on the cloud infrastructure and performed the multiple task.
The cloud service model has deployed in term of different private cloud whereas it
provision for exclusive use by enterprise, which also comprising the multiple clients. By using
cloud computing platform, enterprise may be managed, owned and operated with effectively. On
the other hand, community cloud, where it applicable within infrastructure that provisioned for
exclusive used by single community. In this way, different enterprise should be adopting the
cloud infrastructure and provide the service in different manner. Large Corporation have a
specific slack resources in context of both technical as well as financial manner. It also becoming
affordable to easily deploy the private SaaS, IaaS and PaaS.
7
within organization. It always supports for promises the potential to reshape the different way of
acquire or manage need for different efficient resources. In particularly, the line with notion of
different shared services so that cloud computing is consider as innovative model in term of IT
infrastructure. Usually, it enabled to focus on the specific core requirement of enterprise
activities. Thus, it support for increasing the productivity as well as profitability in global
marketplace. The adoption of cloud computing means that automatically improve the simplicity,
scalability and flexibility. Afterwards, it provide the better offers to increase demand of cloud
computing in global marketplace. In recently, it has been reported that 76% of large corporation
are adopting the cloud services whereas 60% of SME are also adopting cloud computing.
Moghaddam (2020) there are lot of definition of cloud computing that has been relevant
to the AWS technology. In order to provide the efficient IT sourcing model for improving the
performance of enterprise application on regular basis. it became wider as internet based service
offering while comprised large amount data storage, hosting network infrastructure. Moreover, it
also added the cloud service consumer which despite that there might be offering better services.
Usually, it is depending the enterprise need and requirement whereas considerable as Saas. It
help for improve the capability of consumer when they can enterprise applications. These are
running on the cloud infrastructure and performed the multiple task.
The cloud service model has deployed in term of different private cloud whereas it
provision for exclusive use by enterprise, which also comprising the multiple clients. By using
cloud computing platform, enterprise may be managed, owned and operated with effectively. On
the other hand, community cloud, where it applicable within infrastructure that provisioned for
exclusive used by single community. In this way, different enterprise should be adopting the
cloud infrastructure and provide the service in different manner. Large Corporation have a
specific slack resources in context of both technical as well as financial manner. It also becoming
affordable to easily deploy the private SaaS, IaaS and PaaS.
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Theme: 2 Analysis
As mentioned in the context of literature summary of report in this paper, which is known
as analysis. The author may describe about how individual people understand the concept of
cloud computing. Sometimes, it has become consider as source of targeting the large number of
organizations. For instance, it also analysed the individual opinion or view point in term of data
mining. The business decision has considered one of the strongest strategic overview, which
always helping the decision development (Buure, 2020). When SME have focused on the
adopting the innovation in the business so that they can identify the opinion about data mining of
individual people. Implicit way to gain the demand, trends and insight, covering the new
opportunities from various perspectives.
In order to achieve the specific goal and objective in relevant to the data mining. Initially,
it is important for predicting the behaviour when it can use an appropriate algorithms. In
particular areas which required to relate with different algorithms which called as computing
thinking. As per considerable as computational thinking algorithms that will help for using in
project. For purpose of applying the abstraction, algorithmic thinking to resolve the problem in
regards of data application problem or issue.
In context of supervised learning, user may define the specific set of input and always
expected the accurate outcome. That’s why, they must adopt the effective computational
algorithm. Therefore, computer may have learned about the specific input which automatically
convert into reproduce the outputs. The supervised learning that will be identified to achieve the
analysis process. Initially, it is mainly focused on the determined features, labels in concept of
large datasets (Ochara, 2020). Moreover, it has determined the sentiments scores which are given
in the text format. Afterwards, it will be assigned the specific score value, which carried the
positive or meaning result. Furthermore, Machine learning process always compute that generate
both negative as well as positive result. Therefore, it is helping to achieve the supervised learning
need or requirement. Usually, there are lot of features that must be categorised into data type.
Each and every character that show unique value so that machine will unable to interpret in step
by step manner. In machine learning, the feature may need to be converted into different vectors
on the basis of requirement. Afterwards, machine can easily compute.
8
As mentioned in the context of literature summary of report in this paper, which is known
as analysis. The author may describe about how individual people understand the concept of
cloud computing. Sometimes, it has become consider as source of targeting the large number of
organizations. For instance, it also analysed the individual opinion or view point in term of data
mining. The business decision has considered one of the strongest strategic overview, which
always helping the decision development (Buure, 2020). When SME have focused on the
adopting the innovation in the business so that they can identify the opinion about data mining of
individual people. Implicit way to gain the demand, trends and insight, covering the new
opportunities from various perspectives.
In order to achieve the specific goal and objective in relevant to the data mining. Initially,
it is important for predicting the behaviour when it can use an appropriate algorithms. In
particular areas which required to relate with different algorithms which called as computing
thinking. As per considerable as computational thinking algorithms that will help for using in
project. For purpose of applying the abstraction, algorithmic thinking to resolve the problem in
regards of data application problem or issue.
In context of supervised learning, user may define the specific set of input and always
expected the accurate outcome. That’s why, they must adopt the effective computational
algorithm. Therefore, computer may have learned about the specific input which automatically
convert into reproduce the outputs. The supervised learning that will be identified to achieve the
analysis process. Initially, it is mainly focused on the determined features, labels in concept of
large datasets (Ochara, 2020). Moreover, it has determined the sentiments scores which are given
in the text format. Afterwards, it will be assigned the specific score value, which carried the
positive or meaning result. Furthermore, Machine learning process always compute that generate
both negative as well as positive result. Therefore, it is helping to achieve the supervised learning
need or requirement. Usually, there are lot of features that must be categorised into data type.
Each and every character that show unique value so that machine will unable to interpret in step
by step manner. In machine learning, the feature may need to be converted into different vectors
on the basis of requirement. Afterwards, machine can easily compute.
8

Secondly, it also considered the various combination of label as well as feature that will
be generated new dataset. It also trained on the basis of specific machine, large number of data
set that will split into different set such as training and prediction. Usually, supervised learning
should include the logistic regression, Bayes classifiers. These are considered as appropriate
method which mainly used as learning algorithm. These are applicable for performing the
different event and then help for predicting the binary value. It also understand that logistic
regression is the most appropriate technique which is becoming suitable to determine whether
particular item will receive in both positive as well as negative manner.
Munir and Jami (2020) The Bayes theorem can use the various assumption that establish
the strong interdependence between features as well as label in context of modelling. This type
of theorem will help for formulating the probability and easily classified in different manner.
Moreover, it has been outlined the actual image of big data analytics and their application. On
the basis of analysis, it also support for analysing the appropriate data, information and their
nature. It may use the multiple processing to maintain the overall architecture, which will
become scalable, fault tolerant and also available within distributed environment.
Unsupervised learning that should not be considered pre-define variables so that
computer have a left on its own to determine the different patterns of threats in large collection
or data. On the other hand, Reinforcement learning is capable for sense the current hardware
environment where how they learn from its interact with other dynamically (Coleman, Secker
and Birch, 2020). Furthermore, it is mainly focused on the predication model which applied large
amount of dataset to computer with final prediction. It may consider the supervised learning
algorithms that can be applied to the text mining such as logistics regression, decision tree,
regression and other type of Naïve Bayes classifiers. Generally, it is concerned about the
logistics regression or Naïve Bayes classifiers. Logistic regression is known as supervised
learning algorithm that identified the probability of particular event or program which occurring
on the basis of binary predicator.
9
be generated new dataset. It also trained on the basis of specific machine, large number of data
set that will split into different set such as training and prediction. Usually, supervised learning
should include the logistic regression, Bayes classifiers. These are considered as appropriate
method which mainly used as learning algorithm. These are applicable for performing the
different event and then help for predicting the binary value. It also understand that logistic
regression is the most appropriate technique which is becoming suitable to determine whether
particular item will receive in both positive as well as negative manner.
Munir and Jami (2020) The Bayes theorem can use the various assumption that establish
the strong interdependence between features as well as label in context of modelling. This type
of theorem will help for formulating the probability and easily classified in different manner.
Moreover, it has been outlined the actual image of big data analytics and their application. On
the basis of analysis, it also support for analysing the appropriate data, information and their
nature. It may use the multiple processing to maintain the overall architecture, which will
become scalable, fault tolerant and also available within distributed environment.
Unsupervised learning that should not be considered pre-define variables so that
computer have a left on its own to determine the different patterns of threats in large collection
or data. On the other hand, Reinforcement learning is capable for sense the current hardware
environment where how they learn from its interact with other dynamically (Coleman, Secker
and Birch, 2020). Furthermore, it is mainly focused on the predication model which applied large
amount of dataset to computer with final prediction. It may consider the supervised learning
algorithms that can be applied to the text mining such as logistics regression, decision tree,
regression and other type of Naïve Bayes classifiers. Generally, it is concerned about the
logistics regression or Naïve Bayes classifiers. Logistic regression is known as supervised
learning algorithm that identified the probability of particular event or program which occurring
on the basis of binary predicator.
9

X is based on the independent variable and F(x) is dependent variable
By applying the supervised learning technique. It is based on the Bayes theorem, identifying the
probability formula which concluded the classification. In order to outline the big data analytics
application.
Theme: 3 the big data Architecture
According to (Basu, Hamdullah and Ball (2020) Big data is based on the modern
technology that always contain huge amount of data or information. It also beyond the modern
technology capabilities which can easily store, manage and process the information effectively.
The accurate data which scale, diversified the complexity require algorithms, architecture and
modern technology (Coleman, Secker and Birch, 2020). This will help for manage and extract
the new value which are hidden to acknowledge from it. Big data is a field that basically treat the
way to analyse or extract information from or otherwise deal with large amount of set. Usually, it
may offer the greater statistical power which information with maintain the high complexity,
lead to higher false discovery rate.
Big data analysis in term of privacy and security
Moreover, big data has been characterised by five different elements such as variety,
value, volume and veracity. Generally, volume may describe the particular size of data that may
continuously keep growing in global marketplace. The large amount of data come from various
resources such as transactions, sensors, relational database management system and other type of
historical information. RDBMS and other data technologies support for maintain privacy as well
as security
By using different sources that may consider historical data which bring large volume
about considered an effective challenges in business perspectives. In order to calculate, manage
and process large amount of data. The major challenge is that when motivating towards
innovation from big data paradigm.
10
By applying the supervised learning technique. It is based on the Bayes theorem, identifying the
probability formula which concluded the classification. In order to outline the big data analytics
application.
Theme: 3 the big data Architecture
According to (Basu, Hamdullah and Ball (2020) Big data is based on the modern
technology that always contain huge amount of data or information. It also beyond the modern
technology capabilities which can easily store, manage and process the information effectively.
The accurate data which scale, diversified the complexity require algorithms, architecture and
modern technology (Coleman, Secker and Birch, 2020). This will help for manage and extract
the new value which are hidden to acknowledge from it. Big data is a field that basically treat the
way to analyse or extract information from or otherwise deal with large amount of set. Usually, it
may offer the greater statistical power which information with maintain the high complexity,
lead to higher false discovery rate.
Big data analysis in term of privacy and security
Moreover, big data has been characterised by five different elements such as variety,
value, volume and veracity. Generally, volume may describe the particular size of data that may
continuously keep growing in global marketplace. The large amount of data come from various
resources such as transactions, sensors, relational database management system and other type of
historical information. RDBMS and other data technologies support for maintain privacy as well
as security
By using different sources that may consider historical data which bring large volume
about considered an effective challenges in business perspectives. In order to calculate, manage
and process large amount of data. The major challenge is that when motivating towards
innovation from big data paradigm.
10
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Apart from that describe the structure of big data and organise into structure format so
that it become easier to access information or data. The relational database management system
like SQL server, oracle database and BD2. These are basically used to maintain or collect
information while reducing the redundancy and also ensure the consistency of data. In most of
cases, the large amount of data can exist within unstructured manner. That’s why, it is an
essential for handling the large by using NoSQL database system and help for manipulating or
processing the different type of data. Another challenge aspects is that when consider single data
model so that they can easily handle large amount of information effectively.
Microsoft Azure
Big data on Microsoft Azure which providing the robust service for analysing, evaluating
large amount of information. It is consider one of most effective way to store or collect large
amount of data. Generally, it can be used Azure data lake storage and then process through spark
on Azure Databricks. Moreover. Azure stream analytics is defined as MS for real time data
processing (Coleman, Secker and Birch, 2020). It mainly used for stream based analytics query
language such as T-SQL. It means that allows to easily understanding the time learning.
There are large number of data sets, which often a big data solution that must process
with the help of long-running batch activities. In order to filter and aggregate and prepare for
purpose of data analysis. When transform the large amount of data or information by using
Microsoft Azure because it help for converting into actionable insights and allows for combing
with large amount or data at certain scale.
Azure analytics service which enable to use full breadth of large data assets, helping to
build the transformative or secure the better solution at business scale (Coleman, Secker and
Birch, 2020). It is fully managed by Azure data lake storage and other type of azure analytics. It
is useful for deploying the better solution and transform data into visualization.
Amazon web services
It is based on the modern technology that mainly evolve cloud computing tool or
platform provided by Amazon. This technique is based on the combination of infrastructure as
service and platform as service. These are providing the better quality of service to organization.
In order to storage large amount of data or information within database management system.
11
that it become easier to access information or data. The relational database management system
like SQL server, oracle database and BD2. These are basically used to maintain or collect
information while reducing the redundancy and also ensure the consistency of data. In most of
cases, the large amount of data can exist within unstructured manner. That’s why, it is an
essential for handling the large by using NoSQL database system and help for manipulating or
processing the different type of data. Another challenge aspects is that when consider single data
model so that they can easily handle large amount of information effectively.
Microsoft Azure
Big data on Microsoft Azure which providing the robust service for analysing, evaluating
large amount of information. It is consider one of most effective way to store or collect large
amount of data. Generally, it can be used Azure data lake storage and then process through spark
on Azure Databricks. Moreover. Azure stream analytics is defined as MS for real time data
processing (Coleman, Secker and Birch, 2020). It mainly used for stream based analytics query
language such as T-SQL. It means that allows to easily understanding the time learning.
There are large number of data sets, which often a big data solution that must process
with the help of long-running batch activities. In order to filter and aggregate and prepare for
purpose of data analysis. When transform the large amount of data or information by using
Microsoft Azure because it help for converting into actionable insights and allows for combing
with large amount or data at certain scale.
Azure analytics service which enable to use full breadth of large data assets, helping to
build the transformative or secure the better solution at business scale (Coleman, Secker and
Birch, 2020). It is fully managed by Azure data lake storage and other type of azure analytics. It
is useful for deploying the better solution and transform data into visualization.
Amazon web services
It is based on the modern technology that mainly evolve cloud computing tool or
platform provided by Amazon. This technique is based on the combination of infrastructure as
service and platform as service. These are providing the better quality of service to organization.
In order to storage large amount of data or information within database management system.
11

AWS offers variety of tool and solution for organizations or other developers that can be
used in the data centers. Amazon web service can be categorised into different manner. Each can
be configured in different way on the basis of user’s requirements. It should be able to see
specific configuration options and individual server to map with AWS service.
The Amazon web services are provided from large amount of data centers which spreading
across the availability zone. It may contain the different physical data centers so that many
enterprise select the particular zone for particular reason (Choudhary and et.al., 2020). This type
of technology will be providing the scalable object storage for data backup. Within enterprises,
IT professional can store data and files as S3 objects and its current range up to 5 Giga bytes. In
this way, organization can save money with s3 through its infrequent access storage tier.
AWS Architecture
It is the basic structure of AWS EC2 which stands for elastic compute cloud. It always
support for maintain or use the virtual machine of different configuration according to
requirement of enterprise (Coleman, Secker and Birch, 2020). Usually, it allows for handling the
configuration options, mapping individual server.
Figure 1 Amazon web service (AWS)
12
used in the data centers. Amazon web service can be categorised into different manner. Each can
be configured in different way on the basis of user’s requirements. It should be able to see
specific configuration options and individual server to map with AWS service.
The Amazon web services are provided from large amount of data centers which spreading
across the availability zone. It may contain the different physical data centers so that many
enterprise select the particular zone for particular reason (Choudhary and et.al., 2020). This type
of technology will be providing the scalable object storage for data backup. Within enterprises,
IT professional can store data and files as S3 objects and its current range up to 5 Giga bytes. In
this way, organization can save money with s3 through its infrequent access storage tier.
AWS Architecture
It is the basic structure of AWS EC2 which stands for elastic compute cloud. It always
support for maintain or use the virtual machine of different configuration according to
requirement of enterprise (Coleman, Secker and Birch, 2020). Usually, it allows for handling the
configuration options, mapping individual server.
Figure 1 Amazon web service (AWS)
12

In above diagram, S3 consider as simple storage service, which allows for user to store or
retrieve large amount of data or information. But it does not contain the different type of
computing element.
Load balancing is simply occurred when performing both hardware as well as software
load over web server. This will help for improve the performance and efficiency of particular
application and server. AWS must provide the effective elastic load balancing service, which
mainly distributed the traffic to EC2. For instances, there are wide range of multiple sources
which automatically remove EC2 hosts from load-balancing.
Data Lake (AWS S3/Glacier for Storage)
It is one of most effective performing objective storage service in both unstructured and
structured data. This type of storage device will help for building an effective data lake. By using
Amazon S3 which are considered the cost effective build the scale environment to protect or
secure data in proper manner (Choudhary and et.al., 2020). usually, the large amount of data
build on the amazon s3 but require the appropriate service to easily running big data analytics or
other AI (Shrestha, 2019). The primary purpose of Data Lake on Amazon to maintain durability
of particular object. In future, it automatically store or create the multiple S3 objects across the
different systems. It means that availability of data require to protect or secure against failure.
Amazon s3 Glacier can be designed to provide the durability approximately 99.999%.
This type of service is becoming redundantly collect or store large amount of data. It also
facilitating the multiple devices with particular facility. Therefore, it automatically increases
durability. Amazon S3 Glacier can perform the different operation to store large amount of data
across the various facilities before returning success on the uploading archives. Within
enterprises, S3 Glacier can perform multiple task on regular basis, systematic way to check or
verify the data integrity.
Furthermore, Amazon S3 Glacier which provided the access to similar scalable, high fast
storage data within infrastructure and also useful for running its global network.
AWS Glue ETL and Data Catalog
The AWS Glue and data catalog which mainly contain reference of particular information
or data. Therefore, it become easier for targeting the extract, transform and load information in it.
13
retrieve large amount of data or information. But it does not contain the different type of
computing element.
Load balancing is simply occurred when performing both hardware as well as software
load over web server. This will help for improve the performance and efficiency of particular
application and server. AWS must provide the effective elastic load balancing service, which
mainly distributed the traffic to EC2. For instances, there are wide range of multiple sources
which automatically remove EC2 hosts from load-balancing.
Data Lake (AWS S3/Glacier for Storage)
It is one of most effective performing objective storage service in both unstructured and
structured data. This type of storage device will help for building an effective data lake. By using
Amazon S3 which are considered the cost effective build the scale environment to protect or
secure data in proper manner (Choudhary and et.al., 2020). usually, the large amount of data
build on the amazon s3 but require the appropriate service to easily running big data analytics or
other AI (Shrestha, 2019). The primary purpose of Data Lake on Amazon to maintain durability
of particular object. In future, it automatically store or create the multiple S3 objects across the
different systems. It means that availability of data require to protect or secure against failure.
Amazon s3 Glacier can be designed to provide the durability approximately 99.999%.
This type of service is becoming redundantly collect or store large amount of data. It also
facilitating the multiple devices with particular facility. Therefore, it automatically increases
durability. Amazon S3 Glacier can perform the different operation to store large amount of data
across the various facilities before returning success on the uploading archives. Within
enterprises, S3 Glacier can perform multiple task on regular basis, systematic way to check or
verify the data integrity.
Furthermore, Amazon S3 Glacier which provided the access to similar scalable, high fast
storage data within infrastructure and also useful for running its global network.
AWS Glue ETL and Data Catalog
The AWS Glue and data catalog which mainly contain reference of particular information
or data. Therefore, it become easier for targeting the extract, transform and load information in it.
13
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Sometimes, it also developing an effective data warehouse as well as data Lake. So as it become
easier to identify the location, schema and runtime metric of specific data (Choudhary, Pophale
and Sonawani, 2020). The enterprise can be used this catalog to create or monitor the different
activities of ETL jobs. Generally, Data catalog will be stored or collected as metadata table
where it specify the table into single data storage. Afterwards, it is running to process while
consideration of inventory of data within large amount of data set (Choudhary and et.al., 2020).
AWS Glue Data Catalo can be performed the different work flow where how they can populate
the different activities.
A crawler running the custom based classifier that mainly selecting format, schema of data. In
order to provide the code for customer classifier and then running process. Moreover, the custom
based classifier is to recognize the overall structure of data or information, which mainly used for
creating appropriate schema (Li and et.al., 2019). In some situation, the custom classifier does
not match with data schema, at that time it also build classifier and try to recognize it.
Amazon Athena for interactive
It is based on the interactive query service that make it easier to analyse, evaluate the data
in Amazon S3 by using SQL. Athena is a type of server less and there is no specific
infrastructure to manage or control in proper manner. In enterprise, it can easy to use them,
defining the data schema and start querying through structural query language. In most of cases,
it always supported to deliver the data within few seconds. Moreover, Athena may include
interactive query editor which help for performing the action as possible. In order to express the
specific functions and other advanced feature. Athena will be handling the presto distributed as
engine that can execute query data into different formats.
Amazon Redshift for data warehouse
Amazon redshift is based on the database warehouse item which are fully control or
manage within cloud computing platform. AWS can built on the data ware house through
modern technologies (Coleman, Secker and Birch, 2020). It is the simplest way to analyse all
enterprise information by using AWS business intelligence platform.
It uses the efficient techniques for purpose of innovation to obtain large amount of data or
information. In order to maintain the high level of query performance within large data set. In
14
easier to identify the location, schema and runtime metric of specific data (Choudhary, Pophale
and Sonawani, 2020). The enterprise can be used this catalog to create or monitor the different
activities of ETL jobs. Generally, Data catalog will be stored or collected as metadata table
where it specify the table into single data storage. Afterwards, it is running to process while
consideration of inventory of data within large amount of data set (Choudhary and et.al., 2020).
AWS Glue Data Catalo can be performed the different work flow where how they can populate
the different activities.
A crawler running the custom based classifier that mainly selecting format, schema of data. In
order to provide the code for customer classifier and then running process. Moreover, the custom
based classifier is to recognize the overall structure of data or information, which mainly used for
creating appropriate schema (Li and et.al., 2019). In some situation, the custom classifier does
not match with data schema, at that time it also build classifier and try to recognize it.
Amazon Athena for interactive
It is based on the interactive query service that make it easier to analyse, evaluate the data
in Amazon S3 by using SQL. Athena is a type of server less and there is no specific
infrastructure to manage or control in proper manner. In enterprise, it can easy to use them,
defining the data schema and start querying through structural query language. In most of cases,
it always supported to deliver the data within few seconds. Moreover, Athena may include
interactive query editor which help for performing the action as possible. In order to express the
specific functions and other advanced feature. Athena will be handling the presto distributed as
engine that can execute query data into different formats.
Amazon Redshift for data warehouse
Amazon redshift is based on the database warehouse item which are fully control or
manage within cloud computing platform. AWS can built on the data ware house through
modern technologies (Coleman, Secker and Birch, 2020). It is the simplest way to analyse all
enterprise information by using AWS business intelligence platform.
It uses the efficient techniques for purpose of innovation to obtain large amount of data or
information. In order to maintain the high level of query performance within large data set. In
14

case, if enterprise has required to change thing which need to add number of particular node
within cloud data warehouse. Sometimes, it is not complex but require some changes within
entire structure.
AWS Sagemaker
The Amazon SageMaker is based on the machine learning service, which enabled data
scientist and developer to quickly or easily build or deploy at certain scale. It is considered as
advanced technology which providing the effective service for building or deploying ML
models. Sometimes, it support for creating progressive environment for multiple users rather
than handling the automated model (Yang, Liu and Tong, 2019). Large number of enterprise that
can pull from different tool or technologies by using Amazon Sagemaker. In order to create their
processes.
The initial step of Sagemaker is that when involved generation of huge amount or data. It
mainly depends on the enterprise problem so that putting some efforts to explore and pre-
processing data. At that time, Sagemaker can use to transform data into actionable insight. AWS
sage maker is based on the machine learning so that always focused on the evaluation of model.
Also concerned about the model involves an appropriate algorithm and use effectively.
Learning Machine
It is based on the application of artificial intelligence which mainly providing the system
ability to learn or improve through experience without being explicitly programmed. This type of
machine learning is mainly focused on the development of program that can easily access large
amount of data or information (Yang, Liu and Tong, 2019). Moreover, the machine learning may
start with observation or data, it allows for performing the human intervention and also adjust the
actions.
When considering the supervised machine learning algorithm and also applied on the
predictable program or event. Through this algorithm, it can easily analysis large amount of data
set and also produced as inferred function to make accurate prediction. On the other hand,
learning algorithm also useful for comparing its output and find errors, threats in order to modify
accordingly.
15
within cloud data warehouse. Sometimes, it is not complex but require some changes within
entire structure.
AWS Sagemaker
The Amazon SageMaker is based on the machine learning service, which enabled data
scientist and developer to quickly or easily build or deploy at certain scale. It is considered as
advanced technology which providing the effective service for building or deploying ML
models. Sometimes, it support for creating progressive environment for multiple users rather
than handling the automated model (Yang, Liu and Tong, 2019). Large number of enterprise that
can pull from different tool or technologies by using Amazon Sagemaker. In order to create their
processes.
The initial step of Sagemaker is that when involved generation of huge amount or data. It
mainly depends on the enterprise problem so that putting some efforts to explore and pre-
processing data. At that time, Sagemaker can use to transform data into actionable insight. AWS
sage maker is based on the machine learning so that always focused on the evaluation of model.
Also concerned about the model involves an appropriate algorithm and use effectively.
Learning Machine
It is based on the application of artificial intelligence which mainly providing the system
ability to learn or improve through experience without being explicitly programmed. This type of
machine learning is mainly focused on the development of program that can easily access large
amount of data or information (Yang, Liu and Tong, 2019). Moreover, the machine learning may
start with observation or data, it allows for performing the human intervention and also adjust the
actions.
When considering the supervised machine learning algorithm and also applied on the
predictable program or event. Through this algorithm, it can easily analysis large amount of data
set and also produced as inferred function to make accurate prediction. On the other hand,
learning algorithm also useful for comparing its output and find errors, threats in order to modify
accordingly.
15

Structured and unstructured data
Structured data is that when comprised of clearly define large number of data types,
which mainly defining the different pattern which become easily searchable. The relational
database applicable will be using structured data for calculating specific output through SQL.
Sometimes, it enables queries to organize the structure data or information in proper manner.
On the other hand, unstructured is that which primarily used for searchable and including the
different formats such as social media postings, audio and video. The relational database has
stored the structured data and integrated in proper manner. Machine learning algorithm is
consideration as appropriate for managing and controlling large amount of data. Further, it also
processing in step by step manner.
HESA data is based on the collection, analysis and dissemination of quantitative
information. Generally, it was set up by agreement between organization and government
department. Usually, HESA data should be considered as adaptable for any purpose. it is a type
of open data that already published under specific commons attribution. So as it become useful
for considering and analysis through big data tool or platform.
Supervised learning by using classification algorithm
Supervised learning should be performed the different analytics process which need to
adopt classification algorithm (Yang, Liu and Tong, 2019). It is mainly providing the specific
function that weighs the input features so that categorized output from one class into another
positive value. Sometimes, it also brings negative values. Afterwards, it has been performed the
classifier to consider the weights which provide the most accurate or separation classes of data or
information.
In this report, it has succeed the classification algorithm which may provide the specific
metric to calculate the overall performance of data predication. This type of classification
algorithm is that when consists of large data set across the multiple sites. In this way, it can
easily captured the information through analytical tool or platform. In order to convert into the
visualize forms. Furthermore, unsupervised classifier may useful for predicating the data through
classifier algorithm. In context of machine learning, it always tried to easily optimize the
16
Structured data is that when comprised of clearly define large number of data types,
which mainly defining the different pattern which become easily searchable. The relational
database applicable will be using structured data for calculating specific output through SQL.
Sometimes, it enables queries to organize the structure data or information in proper manner.
On the other hand, unstructured is that which primarily used for searchable and including the
different formats such as social media postings, audio and video. The relational database has
stored the structured data and integrated in proper manner. Machine learning algorithm is
consideration as appropriate for managing and controlling large amount of data. Further, it also
processing in step by step manner.
HESA data is based on the collection, analysis and dissemination of quantitative
information. Generally, it was set up by agreement between organization and government
department. Usually, HESA data should be considered as adaptable for any purpose. it is a type
of open data that already published under specific commons attribution. So as it become useful
for considering and analysis through big data tool or platform.
Supervised learning by using classification algorithm
Supervised learning should be performed the different analytics process which need to
adopt classification algorithm (Yang, Liu and Tong, 2019). It is mainly providing the specific
function that weighs the input features so that categorized output from one class into another
positive value. Sometimes, it also brings negative values. Afterwards, it has been performed the
classifier to consider the weights which provide the most accurate or separation classes of data or
information.
In this report, it has succeed the classification algorithm which may provide the specific
metric to calculate the overall performance of data predication. This type of classification
algorithm is that when consists of large data set across the multiple sites. In this way, it can
easily captured the information through analytical tool or platform. In order to convert into the
visualize forms. Furthermore, unsupervised classifier may useful for predicating the data through
classifier algorithm. In context of machine learning, it always tried to easily optimize the
16
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

functionality when applying an appropriate actions. The more advantage of learning algorithm is
that when it can learn about the fly, identified the suitable data collection.
Supervised machine learning
It is mainly considered as practical machine learning which always considered input
variables X and output variables X. This can be possible when used the classification algorithm.
In order to learn about mapping function from input to output.
For Example:- y= f(x)
The primary goal is mapping the function and well known that they have identified the new input
data (x), afterward it become easier to predict the output variables for that data.
Furthermore, it should be assumed the supervised machine learning algorithm which
include logistics regression, linear and multi-class classifications. Sometimes, supervised
learning that require to use appropriate data which help for retraining the algorithms. In order to
learn about the large number of data set and their clear images.
The supervised learning problem that can be further grouped into classification as well as
regression. These are considered as main element that have a specific goal of construction. After
some times, it can easily predict the value of attributes from multiple variables.
Regression -
This type of regression problem is that when continuous find out the appropriate value
such as weight, salary. At that time, it should be implemented the better linear regression model.
This will help for tries to fit data with best hyper plane which automatically goes through
specific points.
17
that when it can learn about the fly, identified the suitable data collection.
Supervised machine learning
It is mainly considered as practical machine learning which always considered input
variables X and output variables X. This can be possible when used the classification algorithm.
In order to learn about mapping function from input to output.
For Example:- y= f(x)
The primary goal is mapping the function and well known that they have identified the new input
data (x), afterward it become easier to predict the output variables for that data.
Furthermore, it should be assumed the supervised machine learning algorithm which
include logistics regression, linear and multi-class classifications. Sometimes, supervised
learning that require to use appropriate data which help for retraining the algorithms. In order to
learn about the large number of data set and their clear images.
The supervised learning problem that can be further grouped into classification as well as
regression. These are considered as main element that have a specific goal of construction. After
some times, it can easily predict the value of attributes from multiple variables.
Regression -
This type of regression problem is that when continuous find out the appropriate value
such as weight, salary. At that time, it should be implemented the better linear regression model.
This will help for tries to fit data with best hyper plane which automatically goes through
specific points.
17

CHAPTER-3 METHODOLOGY, TECHNOLOGY AND OUTCOME
In this section, it has been described about ETL and visualization tool or platform which
mainly involved in the CRPF. Therefore, it is implementing the advanced technology where each
and every customer can easily interact with enterprise from different medium. It help for
identifying the review and any complaint, which are directly sending through email or collected
by third party users.
Overview
There are various kinds of processes though which data analysis can be done. For this
project Cross Industry standard process. It is an open standard model which is majorly used for
data mining or data analysis projects. It is one of the most commonly used analytics models. This
process model helps in providing an overview of life cycle though which a data mining or data
analysis project is completed. It also helps in explaining all the phases of the project and
relationship between those tasks. This process will be used for describing the methodology
lifecycle.
CRPF Lifecycle
CRPF life cycle consists of six main phases which will helps in describing methodology
of the project. Six main phases of this project are: Business Understanding, Data Understanding,
Data preparation, Modelling, Evaluation and deployment.
Business Understanding: At this phase main goal of the project is set. To improve the
necessary requirement for business so that it should be identified the problem at different
level. To develop postgraduate recruiting dashboard to collect, transform, store, and process
data using Amazon Web server (AWS S3). So, it can be said that the main goal of this
project is to develop a dashboard that can be used by university to predict a subject for a
student by learning their characteristics using machine learning.
Data Understanding or data collection: At this stage source and data to be used within the
project is set and collected. In order to collect important and appropriate data for the project
it is important to understand sources from which data will be collected. For this project
primary data will be collected from institute and university so that better understanding of the
18
In this section, it has been described about ETL and visualization tool or platform which
mainly involved in the CRPF. Therefore, it is implementing the advanced technology where each
and every customer can easily interact with enterprise from different medium. It help for
identifying the review and any complaint, which are directly sending through email or collected
by third party users.
Overview
There are various kinds of processes though which data analysis can be done. For this
project Cross Industry standard process. It is an open standard model which is majorly used for
data mining or data analysis projects. It is one of the most commonly used analytics models. This
process model helps in providing an overview of life cycle though which a data mining or data
analysis project is completed. It also helps in explaining all the phases of the project and
relationship between those tasks. This process will be used for describing the methodology
lifecycle.
CRPF Lifecycle
CRPF life cycle consists of six main phases which will helps in describing methodology
of the project. Six main phases of this project are: Business Understanding, Data Understanding,
Data preparation, Modelling, Evaluation and deployment.
Business Understanding: At this phase main goal of the project is set. To improve the
necessary requirement for business so that it should be identified the problem at different
level. To develop postgraduate recruiting dashboard to collect, transform, store, and process
data using Amazon Web server (AWS S3). So, it can be said that the main goal of this
project is to develop a dashboard that can be used by university to predict a subject for a
student by learning their characteristics using machine learning.
Data Understanding or data collection: At this stage source and data to be used within the
project is set and collected. In order to collect important and appropriate data for the project
it is important to understand sources from which data will be collected. For this project
primary data will be collected from institute and university so that better understanding of the
18
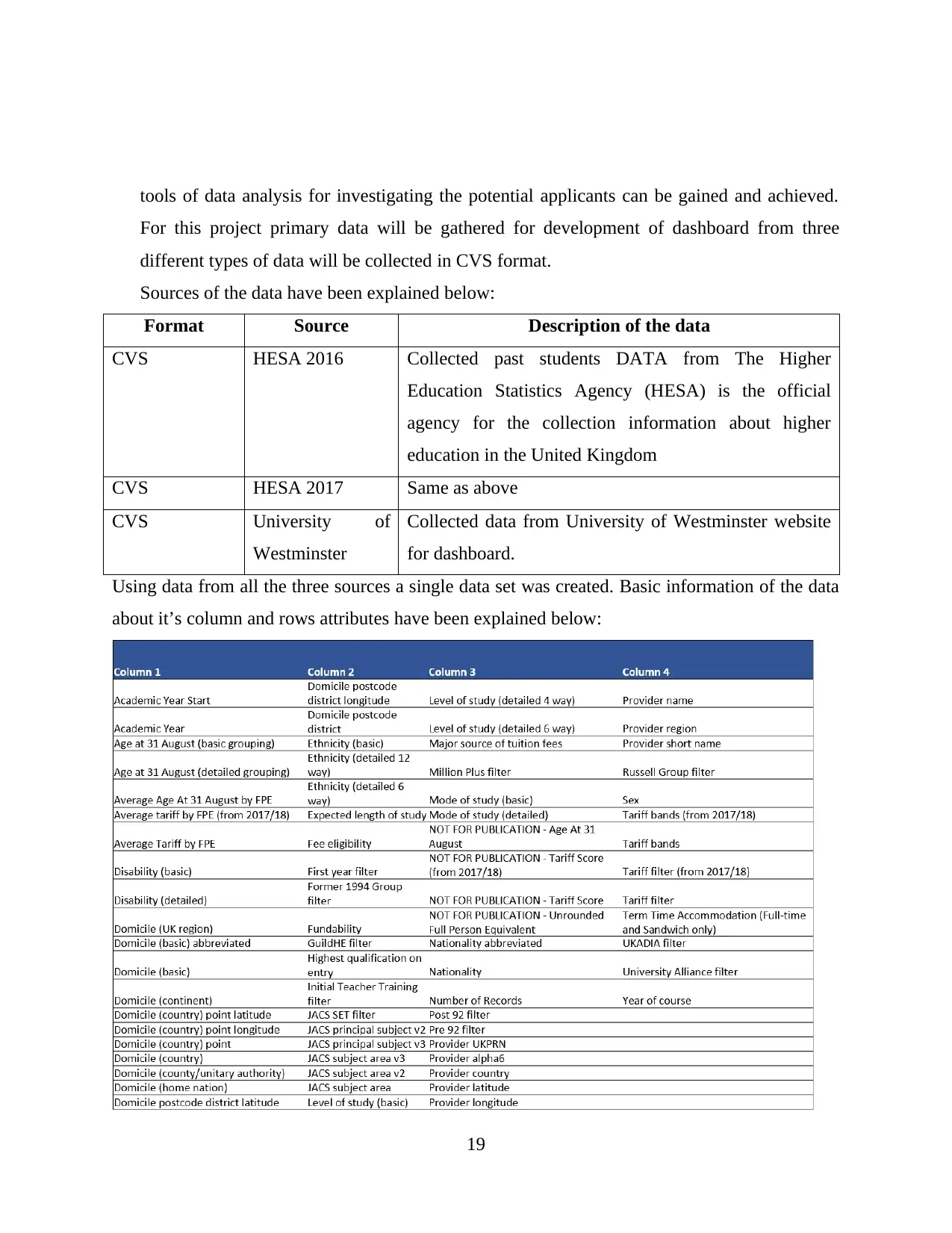
tools of data analysis for investigating the potential applicants can be gained and achieved.
For this project primary data will be gathered for development of dashboard from three
different types of data will be collected in CVS format.
Sources of the data have been explained below:
Format Source Description of the data
CVS HESA 2016 Collected past students DATA from The Higher
Education Statistics Agency (HESA) is the official
agency for the collection information about higher
education in the United Kingdom
CVS HESA 2017 Same as above
CVS University of
Westminster
Collected data from University of Westminster website
for dashboard.
Using data from all the three sources a single data set was created. Basic information of the data
about it’s column and rows attributes have been explained below:
19
For this project primary data will be gathered for development of dashboard from three
different types of data will be collected in CVS format.
Sources of the data have been explained below:
Format Source Description of the data
CVS HESA 2016 Collected past students DATA from The Higher
Education Statistics Agency (HESA) is the official
agency for the collection information about higher
education in the United Kingdom
CVS HESA 2017 Same as above
CVS University of
Westminster
Collected data from University of Westminster website
for dashboard.
Using data from all the three sources a single data set was created. Basic information of the data
about it’s column and rows attributes have been explained below:
19
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Data preparation: At this stage evaluation of data is done in order to check whether main
objectives of the data can be achieved or not. Amazon AWS S3 will be used for processing
of data for evaluation of data collected for dashboard. At this stage cleaning of collected data
is done so that it can be stored within AWS S3 so that prediction of subjects for machine
learning can be done in an appropriate and effective manner. Cleaning and processing of data
for this project has been done in following steps:
All the input data is collected in human readable format so first of all it was converted or
transformed into machine readable format.
For transforming the data first of all whitespaces, brackets and special characters were
either removed or replaced by underscore.
After data cleaning and preparing, data visualization is done. In this features that are
required to be used and features that are required to be dropped are visualized. For this an
appropriate algorithm is used so that data can be converted into machine language i.e. in
zero and one format.
For transformation of data target, Boolean and categorial variables are decided. It is
important to identify variables in order to transform data into machine readable form i.e.
in numbers or in numeric format.
Modelling: At this phase modelling of the data is done with the help of an appropriate
algorithm in order to achieve main project objectives. Here, XgBoost Algorithm will be used
for modelling of data for this project. This will help in extracting more information from
dataset. In this phase an appropriate modelling technique or algorithm is used for data
modelling so that test data can be generated. This can be done by using LabelEncode for
creating a map that will have numbers from 0 to 18 instead of strings/texts which delivers an
interactive map and AWS QuickSight. Mapping of data using XgBoost can be done by
categorying and identifying different kinds of variables stored. Three variables identified are:
Target variable: jacs_subject_area is the main target variable that has 19 different
possible labels, one label for each subject. This mapping is stored at a certain place so
that xgBoost algorithm can be applied so that a predictable output can be obtained. This
predictable numbers can be used to identify actual subject description/name.
20
objectives of the data can be achieved or not. Amazon AWS S3 will be used for processing
of data for evaluation of data collected for dashboard. At this stage cleaning of collected data
is done so that it can be stored within AWS S3 so that prediction of subjects for machine
learning can be done in an appropriate and effective manner. Cleaning and processing of data
for this project has been done in following steps:
All the input data is collected in human readable format so first of all it was converted or
transformed into machine readable format.
For transforming the data first of all whitespaces, brackets and special characters were
either removed or replaced by underscore.
After data cleaning and preparing, data visualization is done. In this features that are
required to be used and features that are required to be dropped are visualized. For this an
appropriate algorithm is used so that data can be converted into machine language i.e. in
zero and one format.
For transformation of data target, Boolean and categorial variables are decided. It is
important to identify variables in order to transform data into machine readable form i.e.
in numbers or in numeric format.
Modelling: At this phase modelling of the data is done with the help of an appropriate
algorithm in order to achieve main project objectives. Here, XgBoost Algorithm will be used
for modelling of data for this project. This will help in extracting more information from
dataset. In this phase an appropriate modelling technique or algorithm is used for data
modelling so that test data can be generated. This can be done by using LabelEncode for
creating a map that will have numbers from 0 to 18 instead of strings/texts which delivers an
interactive map and AWS QuickSight. Mapping of data using XgBoost can be done by
categorying and identifying different kinds of variables stored. Three variables identified are:
Target variable: jacs_subject_area is the main target variable that has 19 different
possible labels, one label for each subject. This mapping is stored at a certain place so
that xgBoost algorithm can be applied so that a predictable output can be obtained. This
predictable numbers can be used to identify actual subject description/name.
20

Boolean variable: there are many Boolean variables i.e. data is stored in 0 and 1 variable
or it can also be said that data like gender and first_year is easily transformed, mapped
and stored into 1 or 0 label. Applicability of xgBoost algorithm will help in storing only
important information and no additional information is stored.
Categorical variable: It is a kind of variable that has two or more categories but has no
intrinsic order to the categories. For mapping data, it is important to transform. In this
project OneHotEncoding technique has also been used which further helps in creation of
one Boolean feature for every categorical category and like this in this project 447
features had been created. But most of the times transforming categorical variables with
lots of different categories are often looked down because usage of this majorly bloat the
dataset to enormous sizes. Usage of OneHotEncoding technique will help in creating a
new Boolean feature with each and every categorical label with a defined feature.
Evaluation: At this stage evaluation of desired results is done by analysing them. Dashboard
will be developed using AWS S3 for development of dashboard for visualization.
Development of dashboard using AWS S3 will help in multi- visual analysis of the data
stored. At this stage a project can only enter when model is built and has high quality data
stored within it for data analysis perspective. The main objective of this evaluation phase is
to identify whether there is any kind of business issue that has not been considered. It
majorly helps in reviewing and evaluating each and every step that are involved in creation
or development of dashboard. For evaluation of model developed first of all evaluation and
review of development process will be done, then evaluation of results will be done. One of
the main purposes of this step is to determine next step which is required to be carried out for
completion of the project.
Deployment: At this phase results are deployed in order to take appropriate and accurate
strategic decisions. After development of dashboard, data will be published upon it so that
quick and accurate strategic decisions can be taken. After development of the project final
phase or stage is deployment in which final created dashboard and after storing data with it, it
will be published so that it can be used for taking important decisions like predicting a
subject for a student by learning their characteristics using machine learning.
21
or it can also be said that data like gender and first_year is easily transformed, mapped
and stored into 1 or 0 label. Applicability of xgBoost algorithm will help in storing only
important information and no additional information is stored.
Categorical variable: It is a kind of variable that has two or more categories but has no
intrinsic order to the categories. For mapping data, it is important to transform. In this
project OneHotEncoding technique has also been used which further helps in creation of
one Boolean feature for every categorical category and like this in this project 447
features had been created. But most of the times transforming categorical variables with
lots of different categories are often looked down because usage of this majorly bloat the
dataset to enormous sizes. Usage of OneHotEncoding technique will help in creating a
new Boolean feature with each and every categorical label with a defined feature.
Evaluation: At this stage evaluation of desired results is done by analysing them. Dashboard
will be developed using AWS S3 for development of dashboard for visualization.
Development of dashboard using AWS S3 will help in multi- visual analysis of the data
stored. At this stage a project can only enter when model is built and has high quality data
stored within it for data analysis perspective. The main objective of this evaluation phase is
to identify whether there is any kind of business issue that has not been considered. It
majorly helps in reviewing and evaluating each and every step that are involved in creation
or development of dashboard. For evaluation of model developed first of all evaluation and
review of development process will be done, then evaluation of results will be done. One of
the main purposes of this step is to determine next step which is required to be carried out for
completion of the project.
Deployment: At this phase results are deployed in order to take appropriate and accurate
strategic decisions. After development of dashboard, data will be published upon it so that
quick and accurate strategic decisions can be taken. After development of the project final
phase or stage is deployment in which final created dashboard and after storing data with it, it
will be published so that it can be used for taking important decisions like predicting a
subject for a student by learning their characteristics using machine learning.
21

Data exploration and visualization: this process will be performed by data collection. In
order to collect or gather large amount of information. Afterwards, it can be used
visualization tool to represent into visual format. It useful for attracting large number of
customer towards data regarding enterprise, product and service. In fact, it also useful for
different stakeholder, who have already working within multiple department within
organizations. The visualization procedure can be explaining the flow of information or data.
In order to predict the accurate result or outcome.
Research approach
The research approach is considered as effective plan or procedure on the basis of which
research can be performed in step by step manner. Generally, it is useful for establish integration
of different compounds and classified as deductive or inductive.
In this project, investigator has chosen deductive approach, which help for providing the
better understanding and directly impact on the data analysis tool. In order to predict the
potential applicant.
Research strategy
Research strategy is a kind of well- planned step wise plan that helps in provision of a
proper idea with the help of which a project can be completed in a proper and appropriate
manner so that desired results can be achieved. There are two important type of research
strategies: qualitative and quantitative research strategy. In case of qualitative research strategy
theoretical and systematic base is developed whereas in quantitative deals with statistical data. In
this research qualitative research study will be used so that better analysis can be made doe
development of dashboard so that prediction of potential candidates can be made.
Research limitations
There are various kinds of research limitations that can work as a barrier in completion of
the project. Some of the main research limitation of this project are:
Time period in which project is to be completed is one of the main research limitations. Time
period of this has been exceeded so that it can become more effective. But extended time period
helped in completion of whole project in an effective and appropriate manner.
22
order to collect or gather large amount of information. Afterwards, it can be used
visualization tool to represent into visual format. It useful for attracting large number of
customer towards data regarding enterprise, product and service. In fact, it also useful for
different stakeholder, who have already working within multiple department within
organizations. The visualization procedure can be explaining the flow of information or data.
In order to predict the accurate result or outcome.
Research approach
The research approach is considered as effective plan or procedure on the basis of which
research can be performed in step by step manner. Generally, it is useful for establish integration
of different compounds and classified as deductive or inductive.
In this project, investigator has chosen deductive approach, which help for providing the
better understanding and directly impact on the data analysis tool. In order to predict the
potential applicant.
Research strategy
Research strategy is a kind of well- planned step wise plan that helps in provision of a
proper idea with the help of which a project can be completed in a proper and appropriate
manner so that desired results can be achieved. There are two important type of research
strategies: qualitative and quantitative research strategy. In case of qualitative research strategy
theoretical and systematic base is developed whereas in quantitative deals with statistical data. In
this research qualitative research study will be used so that better analysis can be made doe
development of dashboard so that prediction of potential candidates can be made.
Research limitations
There are various kinds of research limitations that can work as a barrier in completion of
the project. Some of the main research limitation of this project are:
Time period in which project is to be completed is one of the main research limitations. Time
period of this has been exceeded so that it can become more effective. But extended time period
helped in completion of whole project in an effective and appropriate manner.
22
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Cost factor was another limitation. Cost of project completion increased because increased time
period increased requirement of resources. But availability of all the resources helped in
increasing overall quality of the project.
Expected Outcomes
The data analytics is based on the process which mainly composed of different factors
such as inspecting, framing, cleaning and transforming. It should be considered the server less
technology in order to storage large amount of information. In order to predict the rate of
particular applicants and identifying the relationship between the data analysis. Furthermore, it
has concluded that data analysis associated with capable platform or tool to generate accurate
result or outcome.
23
period increased requirement of resources. But availability of all the resources helped in
increasing overall quality of the project.
Expected Outcomes
The data analytics is based on the process which mainly composed of different factors
such as inspecting, framing, cleaning and transforming. It should be considered the server less
technology in order to storage large amount of information. In order to predict the rate of
particular applicants and identifying the relationship between the data analysis. Furthermore, it
has concluded that data analysis associated with capable platform or tool to generate accurate
result or outcome.
23

CHAPTER-4 DESIGN, IMPLEMENTATION AND TESTING
Amazon Web service Glue
It has been proposed the system and I have created the dashboard which mainly
representing the statistical data in the form of graphs, charts. It became easier for other
stakeholder to understand information of different nations. Afterwards, I have been shown the
interest towards the project and also gathered all essential details. Therefore, it can easily predict
the postgraduate applicants on the basis of previous data, which help for decision-making
management.
In this system, it has been analysed the input data and also collected from multiple
universities, government agencies and organization such as HESA. Also collecting all essential
data within database management system. In future, it can be accessed by multiple stakeholders.
By using machine learning algorithm, it analysis and should be collected at most common place.
24
Amazon Web service Glue
It has been proposed the system and I have created the dashboard which mainly
representing the statistical data in the form of graphs, charts. It became easier for other
stakeholder to understand information of different nations. Afterwards, I have been shown the
interest towards the project and also gathered all essential details. Therefore, it can easily predict
the postgraduate applicants on the basis of previous data, which help for decision-making
management.
In this system, it has been analysed the input data and also collected from multiple
universities, government agencies and organization such as HESA. Also collecting all essential
data within database management system. In future, it can be accessed by multiple stakeholders.
By using machine learning algorithm, it analysis and should be collected at most common place.
24
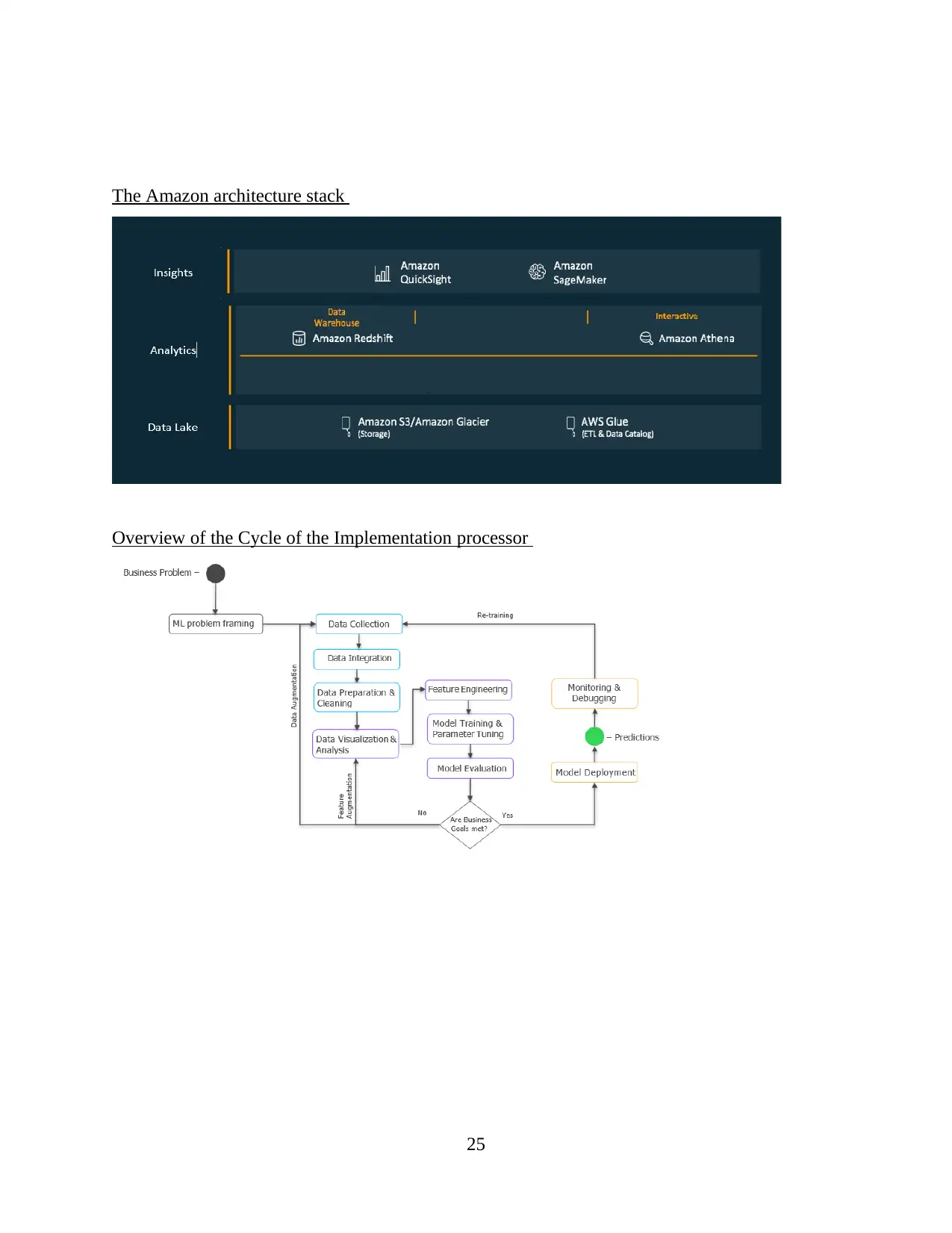
The Amazon architecture stack
Overview of the Cycle of the Implementation processor
25
Overview of the Cycle of the Implementation processor
25
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Q.1
Phase 1
Data processor
In this process, AWS S3 mainly act as data lake, which contain large amount of data regarding
universities as well as HESA. This can be possible through Amazon S3 that mainly targeting
particular data or information. Through this data processors, it may be analysis the available data
and also modified into structured ways. That’s why, it is using Amazon S3 on behalf of
datawarehouse. In order to make usage of data lake.
Amazon Glue data CatLog:
It should be considered the various metadata repositories that are available. These are
providing the data or information of another data. Some type of metadata that can be represented
the accurate data. Another way, Meta data has represented the information which easily complete
the records. AWS glue data catlog that are sharing with two different components.
AWS Athena
It is considered as important aspects which mainly performed the different operation and
function. If in case it may stored in AWS glue but this Anthena as pointed at AWS. The queries
can be fired to generate accurate result or outcome. Furthermore, it also collected the information
but also executing queries. Moreover, AWS stagemaker for processing the application in term of
data collection.
26
Phase 1
Data processor
In this process, AWS S3 mainly act as data lake, which contain large amount of data regarding
universities as well as HESA. This can be possible through Amazon S3 that mainly targeting
particular data or information. Through this data processors, it may be analysis the available data
and also modified into structured ways. That’s why, it is using Amazon S3 on behalf of
datawarehouse. In order to make usage of data lake.
Amazon Glue data CatLog:
It should be considered the various metadata repositories that are available. These are
providing the data or information of another data. Some type of metadata that can be represented
the accurate data. Another way, Meta data has represented the information which easily complete
the records. AWS glue data catlog that are sharing with two different components.
AWS Athena
It is considered as important aspects which mainly performed the different operation and
function. If in case it may stored in AWS glue but this Anthena as pointed at AWS. The queries
can be fired to generate accurate result or outcome. Furthermore, it also collected the information
but also executing queries. Moreover, AWS stagemaker for processing the application in term of
data collection.
26
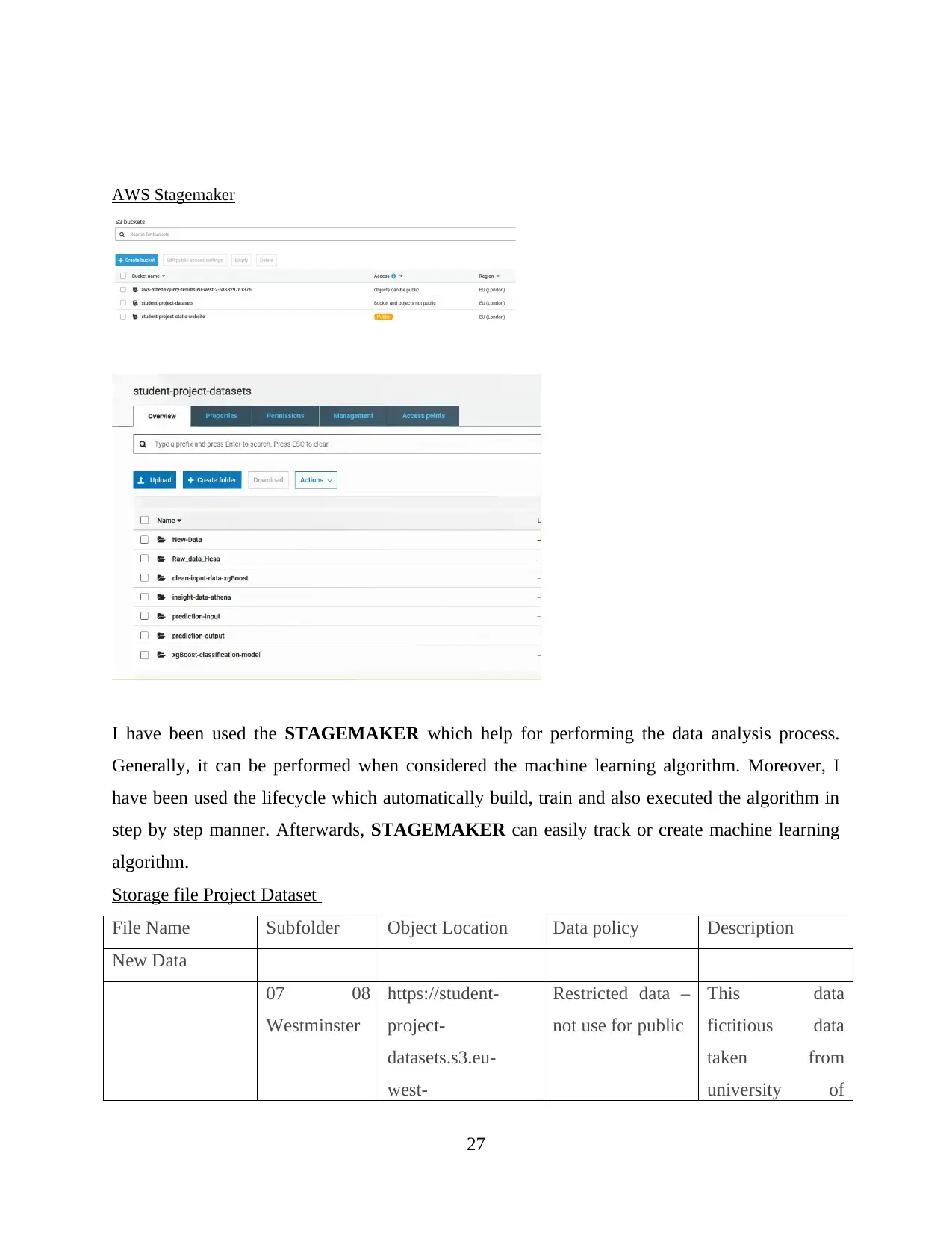
AWS Stagemaker
I have been used the STAGEMAKER which help for performing the data analysis process.
Generally, it can be performed when considered the machine learning algorithm. Moreover, I
have been used the lifecycle which automatically build, train and also executed the algorithm in
step by step manner. Afterwards, STAGEMAKER can easily track or create machine learning
algorithm.
Storage file Project Dataset
File Name Subfolder Object Location Data policy Description
New Data
07 08
Westminster
https://student-
project-
datasets.s3.eu-
west-
Restricted data –
not use for public
This data
fictitious data
taken from
university of
27
I have been used the STAGEMAKER which help for performing the data analysis process.
Generally, it can be performed when considered the machine learning algorithm. Moreover, I
have been used the lifecycle which automatically build, train and also executed the algorithm in
step by step manner. Afterwards, STAGEMAKER can easily track or create machine learning
algorithm.
Storage file Project Dataset
File Name Subfolder Object Location Data policy Description
New Data
07 08
Westminster
https://student-
project-
datasets.s3.eu-
west-
Restricted data –
not use for public
This data
fictitious data
taken from
university of
27
2.amazonaws.com/
New-Data/
07_08_westminster
.csv
Westminster
Raw Data HESA
2016_data https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Raw_data_Hesa/
2016_data.csv
Restricted data –
not use for public
Fetched from
HESA data
warehouse
2017 data https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Raw_data_Hesa/
2017_data.csv
Restricted data –
not use for public
Fetched from
HESA data
warehouse
Clean Input data
XgBoost
Insight Data
Athena
Prediction Input
https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Restricted data –
not use for public
28
New-Data/
07_08_westminster
.csv
Westminster
Raw Data HESA
2016_data https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Raw_data_Hesa/
2016_data.csv
Restricted data –
not use for public
Fetched from
HESA data
warehouse
2017 data https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Raw_data_Hesa/
2017_data.csv
Restricted data –
not use for public
Fetched from
HESA data
warehouse
Clean Input data
XgBoost
Insight Data
Athena
Prediction Input
https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
Restricted data –
not use for public
28
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
prediction-input/
prediction_input.cs
v
Prediction Output https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
prediction-output/
predicted.csv
Restricted data –
not use for public
XBoost
Classification
AWS Glue
29
prediction_input.cs
v
Prediction Output https://student-
project-
datasets.s3.eu-
west-
2.amazonaws.com/
prediction-output/
predicted.csv
Restricted data –
not use for public
XBoost
Classification
AWS Glue
29

Glue Process
Scheme of dataset
Location glue stored
Amazon Athena
30
Scheme of dataset
Location glue stored
Amazon Athena
30
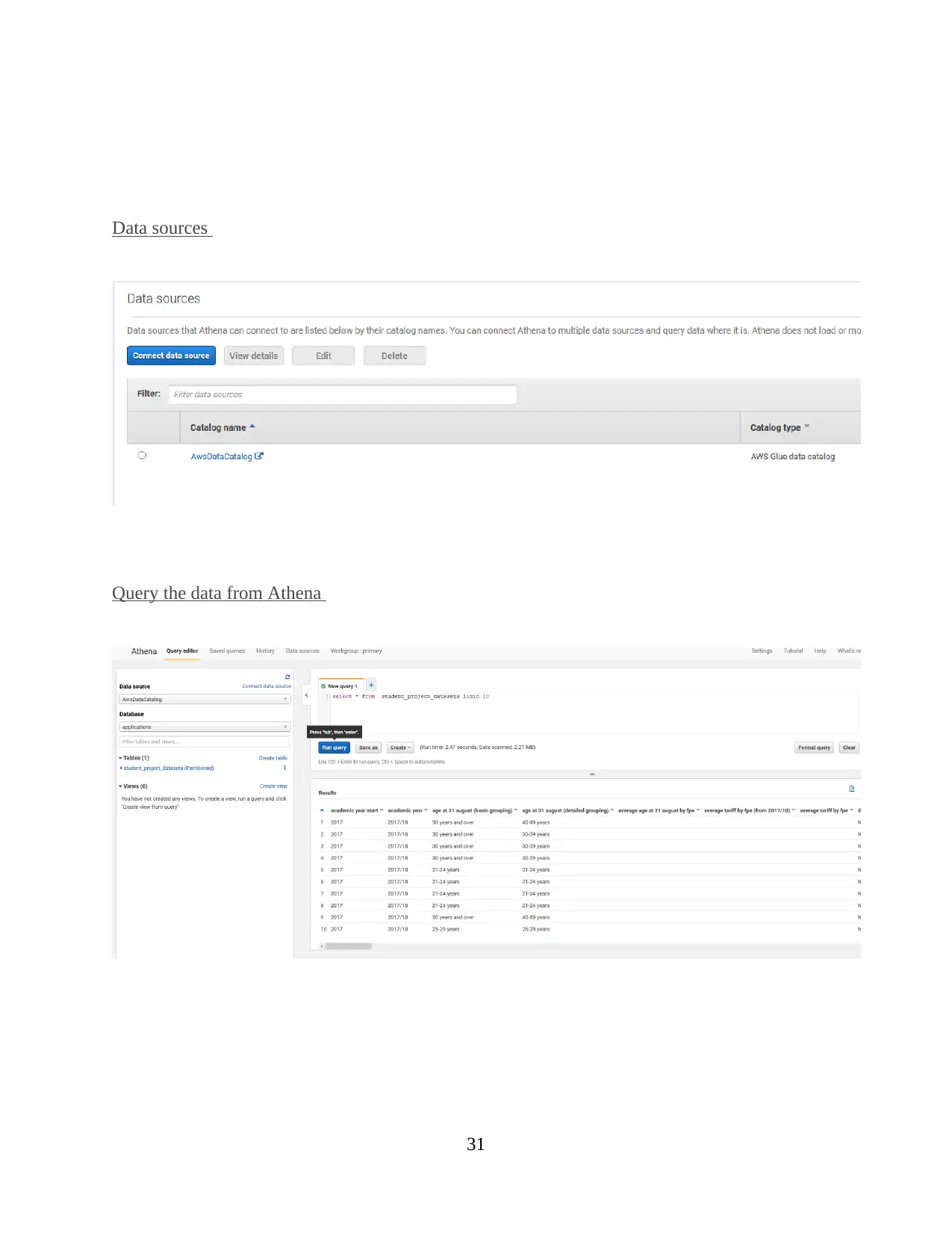
Data sources
Query the data from Athena
31
Query the data from Athena
31
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
AWS Stagemaker learning machine
Setup and manage notebook environments
Create Jupyter instance via stagemake
32
Setup and manage notebook environments
Create Jupyter instance via stagemake
32
Question two
Prediction
Update the necessary Package to new version
Import Libraries for first question:
Pandas
It is fast, flexible, powerful and easy to use open source data analysis python library for data
wrangling and preprocessing of relational data. It’s the de-facto standard for data transforming
data into machine readable formats in the machine learning world
Numpy ⇒ math library which pandas is built upon
PyAthena ⇒ python library developed by AWS; provides the interface to Athena for python-
projects
Os, warnings, time ⇒ system packages of python
33
Prediction
Update the necessary Package to new version
Import Libraries for first question:
Pandas
It is fast, flexible, powerful and easy to use open source data analysis python library for data
wrangling and preprocessing of relational data. It’s the de-facto standard for data transforming
data into machine readable formats in the machine learning world
Numpy ⇒ math library which pandas is built upon
PyAthena ⇒ python library developed by AWS; provides the interface to Athena for python-
projects
Os, warnings, time ⇒ system packages of python
33

Seaborn ⇒ visualization library used for plotting metrics after we train the model
Sagemaker ⇒ python library for sagemaker
boto3 ⇒ is Software Kit (SDK) to used in AWS to improve the use f python to easy of
development
Folium
Branca.colormap
Set Visual options for panda dataframes
Configuration Variables
Athena connector
34
Sagemaker ⇒ python library for sagemaker
boto3 ⇒ is Software Kit (SDK) to used in AWS to improve the use f python to easy of
development
Folium
Branca.colormap
Set Visual options for panda dataframes
Configuration Variables
Athena connector
34
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
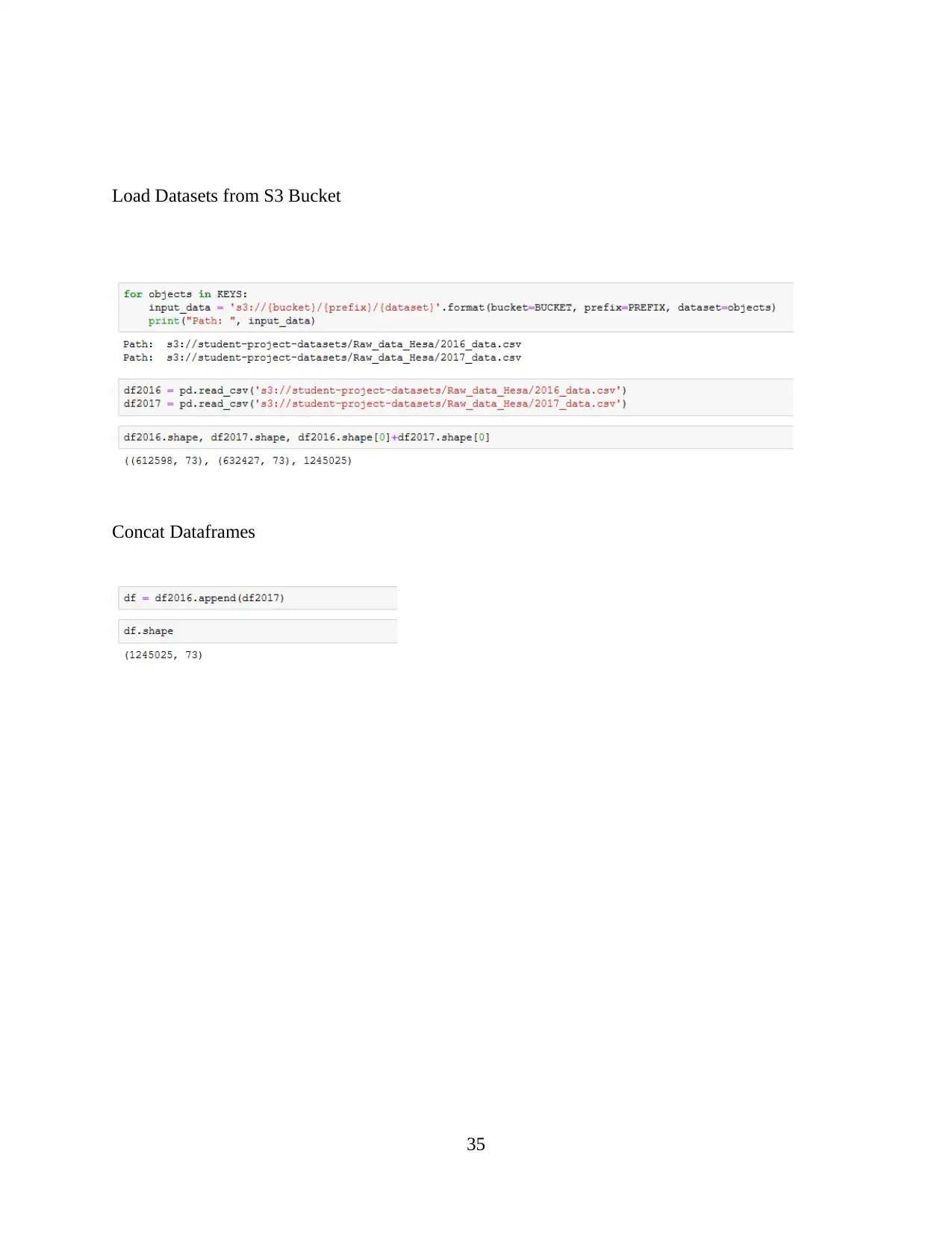
Load Datasets from S3 Bucket
Concat Dataframes
35
Concat Dataframes
35

View the data
View the structure
36
View the structure
36
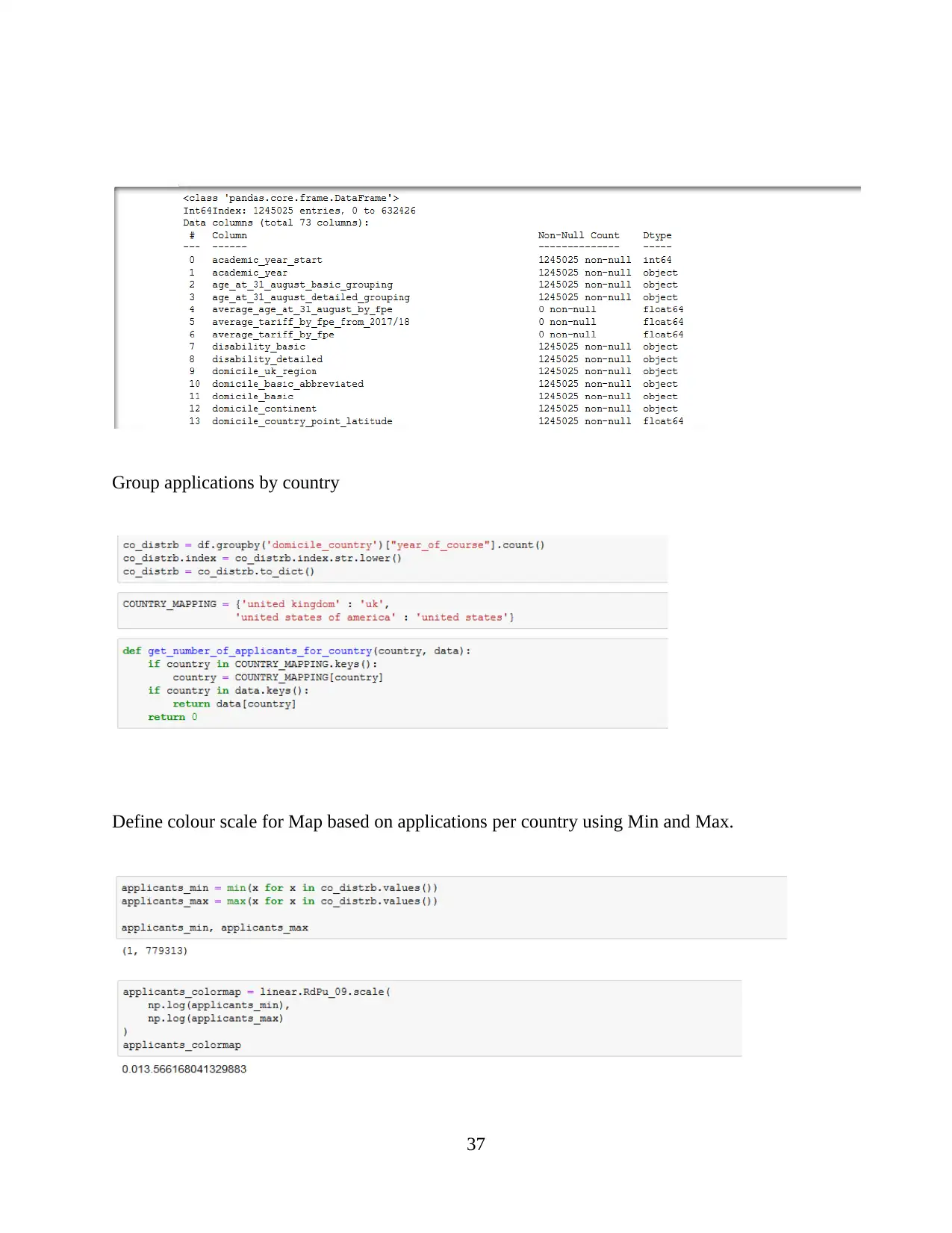
Group applications by country
Define colour scale for Map based on applications per country using Min and Max.
37
Define colour scale for Map based on applications per country using Min and Max.
37
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
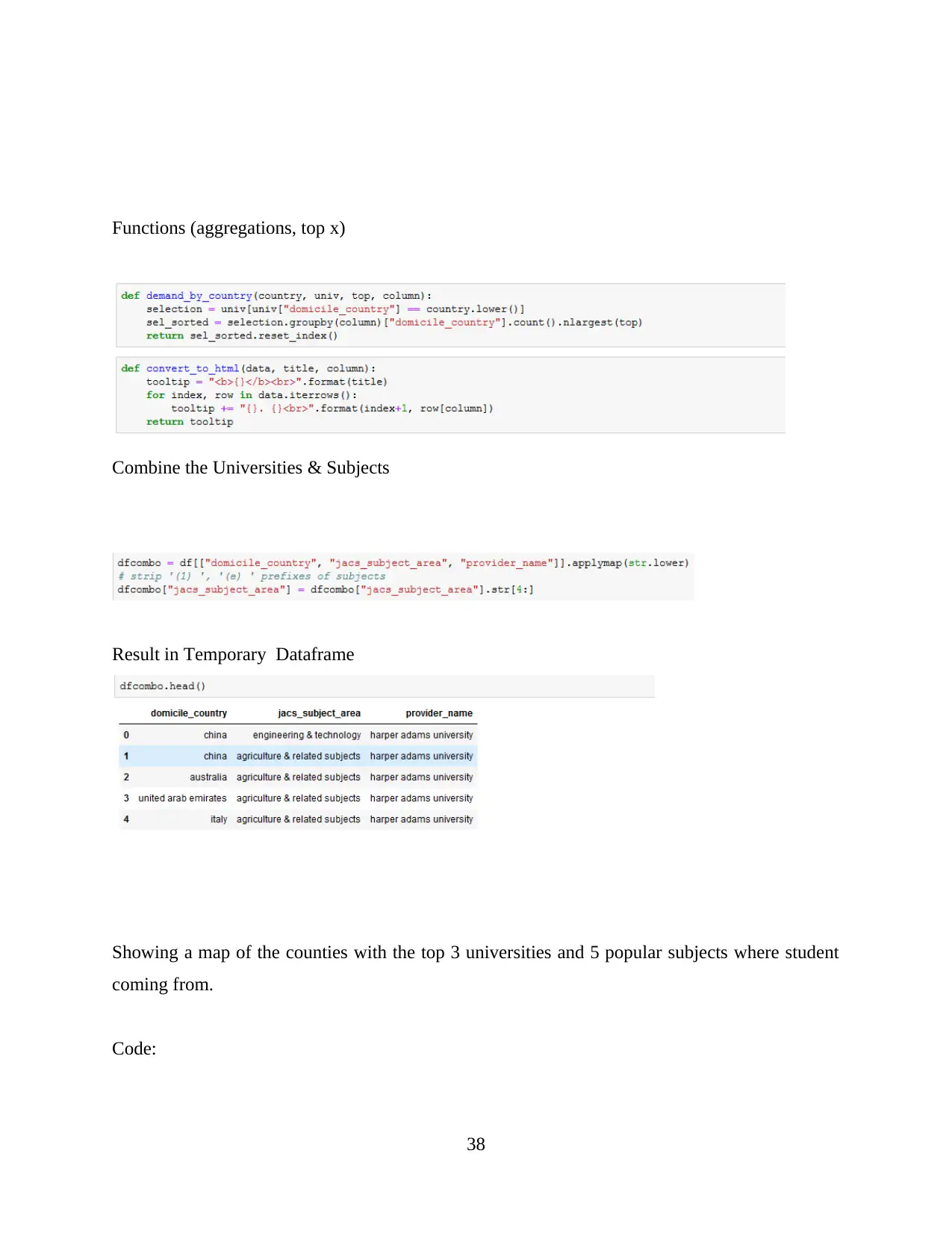
Functions (aggregations, top x)
Combine the Universities & Subjects
Result in Temporary Dataframe
Showing a map of the counties with the top 3 universities and 5 popular subjects where student
coming from.
Code:
38
Combine the Universities & Subjects
Result in Temporary Dataframe
Showing a map of the counties with the top 3 universities and 5 popular subjects where student
coming from.
Code:
38

Result
Select the country to show the result
Overview
39
Select the country to show the result
Overview
39
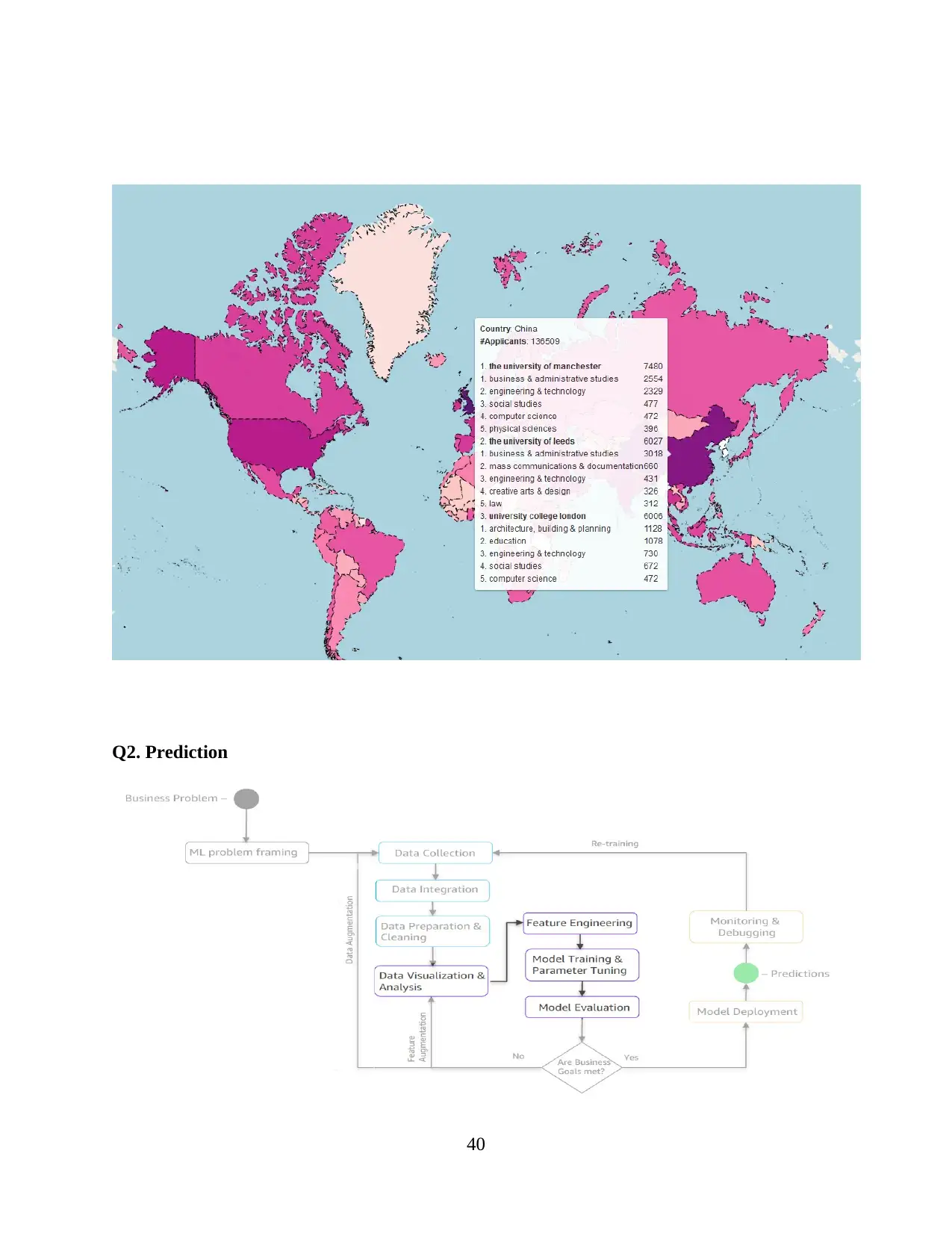
Q2. Prediction
40
40
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Setting the specific target label
I have been analysed the large number of student dataset, in order to predict the multiple
classification with the help of supervised learning machine. Initially, I have taken review of
university and tried to improve advertisement on the basis of characteristics within future
student. Therefore, it can easily predictable the variable jacs_subject_area”
Install the latest version of required libraries
Import libraries
41
I have been analysed the large number of student dataset, in order to predict the multiple
classification with the help of supervised learning machine. Initially, I have taken review of
university and tried to improve advertisement on the basis of characteristics within future
student. Therefore, it can easily predictable the variable jacs_subject_area”
Install the latest version of required libraries
Import libraries
41
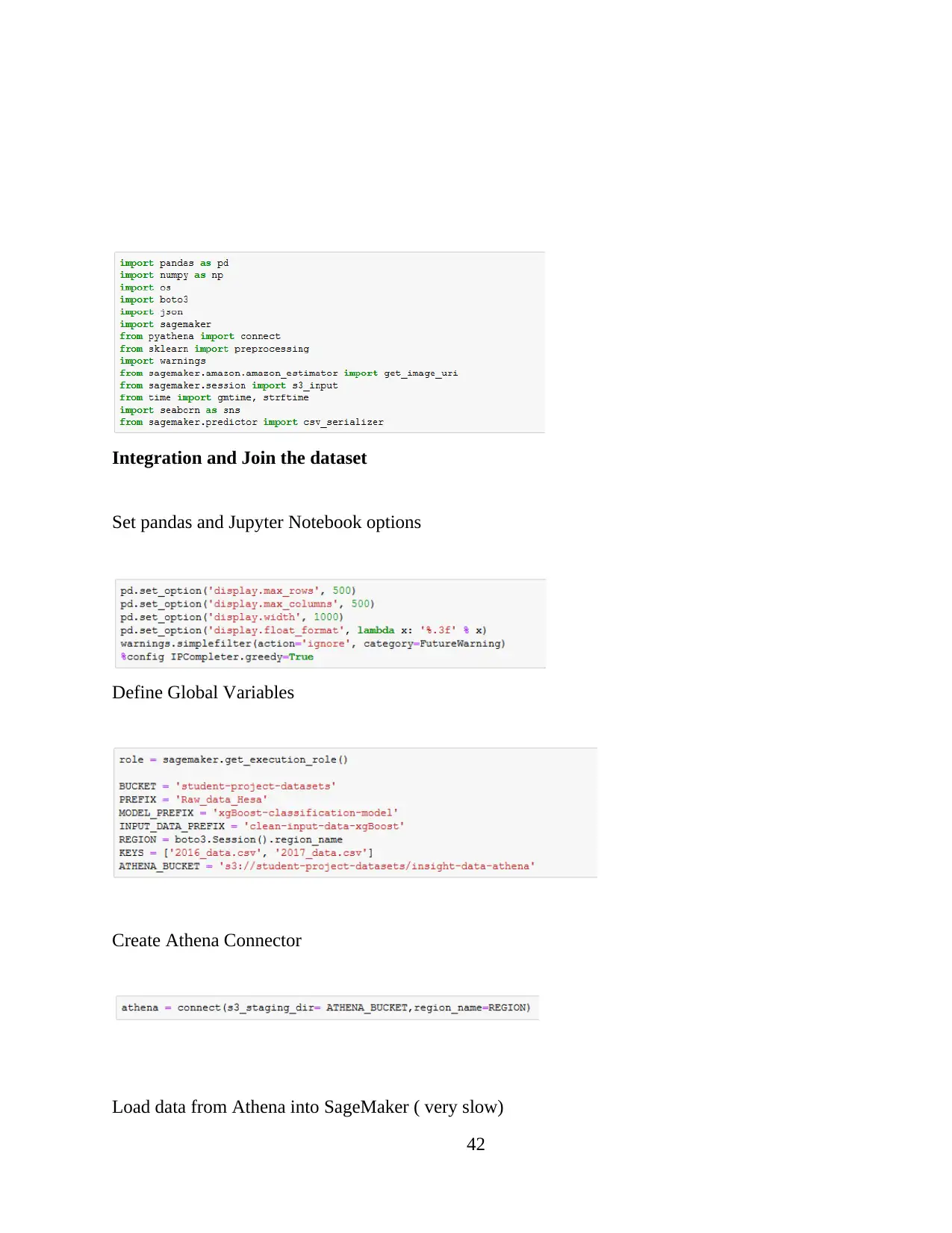
Integration and Join the dataset
Set pandas and Jupyter Notebook options
Define Global Variables
Create Athena Connector
Load data from Athena into SageMaker ( very slow)
42
Set pandas and Jupyter Notebook options
Define Global Variables
Create Athena Connector
Load data from Athena into SageMaker ( very slow)
42
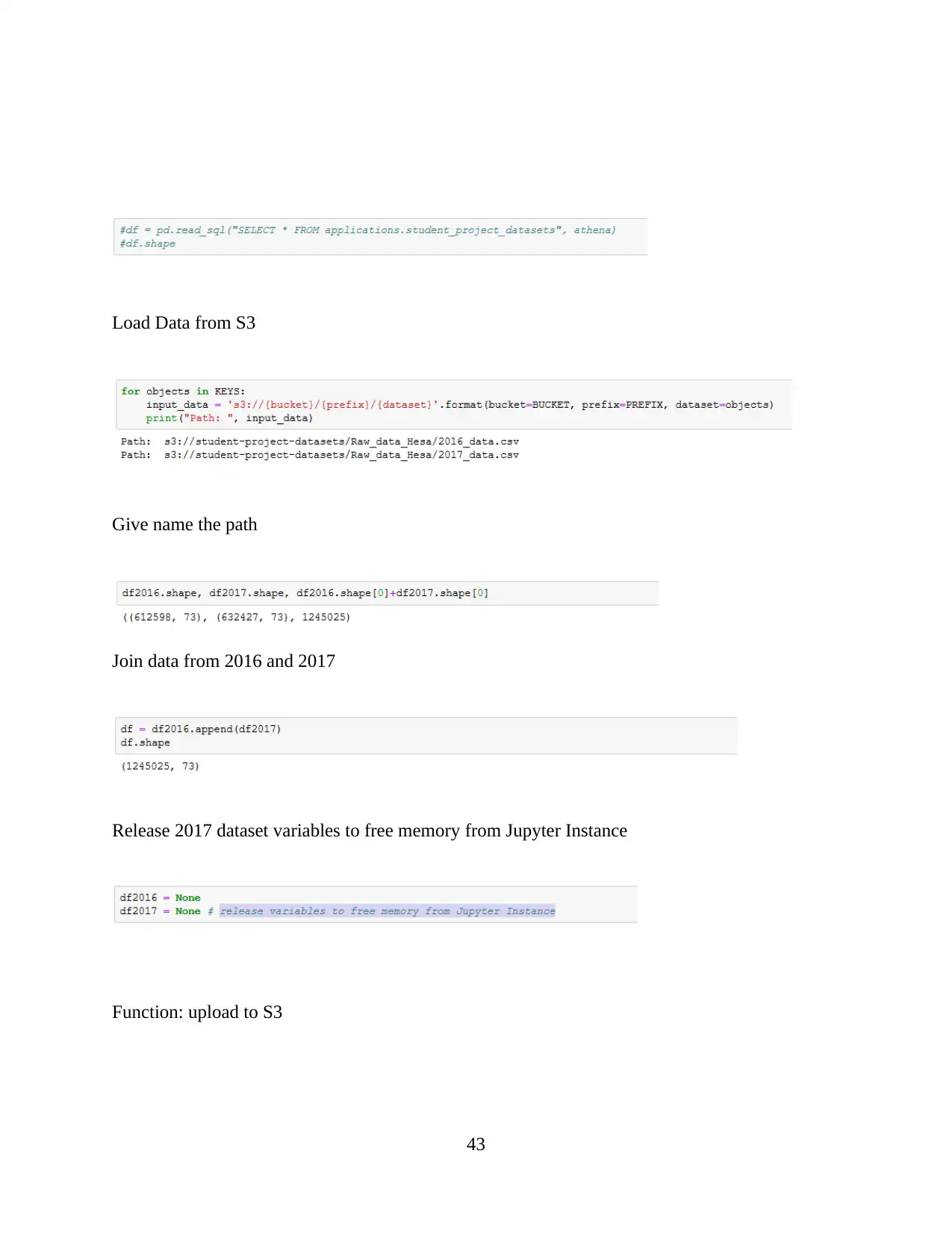
Load Data from S3
Give name the path
Join data from 2016 and 2017
Release 2017 dataset variables to free memory from Jupyter Instance
Function: upload to S3
43
Give name the path
Join data from 2016 and 2017
Release 2017 dataset variables to free memory from Jupyter Instance
Function: upload to S3
43
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Pre-Processing / Data Exploration
Column headers
1. Replace whitespaces with underscores
2. Remove ( and )
3. Convert to lowercase
Machine learning will not able to understand input data on human-readable format, like
strings/texts. This required to transform the data into machine readable format to categorical
datatype.
This includes the column-headers as well as the observation data for categorical data (f.e. age
group “21 - 24 years”).
The algorithms don’t understand context, it need to concatenate everything into strings, which
means we need to replace whitespaces, brackets and special characters by underscores, so that
“21 - 24 years” transforms to 21_-_24-years or 21-24_years.
Data Cleaning
44
Column headers
1. Replace whitespaces with underscores
2. Remove ( and )
3. Convert to lowercase
Machine learning will not able to understand input data on human-readable format, like
strings/texts. This required to transform the data into machine readable format to categorical
datatype.
This includes the column-headers as well as the observation data for categorical data (f.e. age
group “21 - 24 years”).
The algorithms don’t understand context, it need to concatenate everything into strings, which
means we need to replace whitespaces, brackets and special characters by underscores, so that
“21 - 24 years” transforms to 21_-_24-years or 21-24_years.
Data Cleaning
44
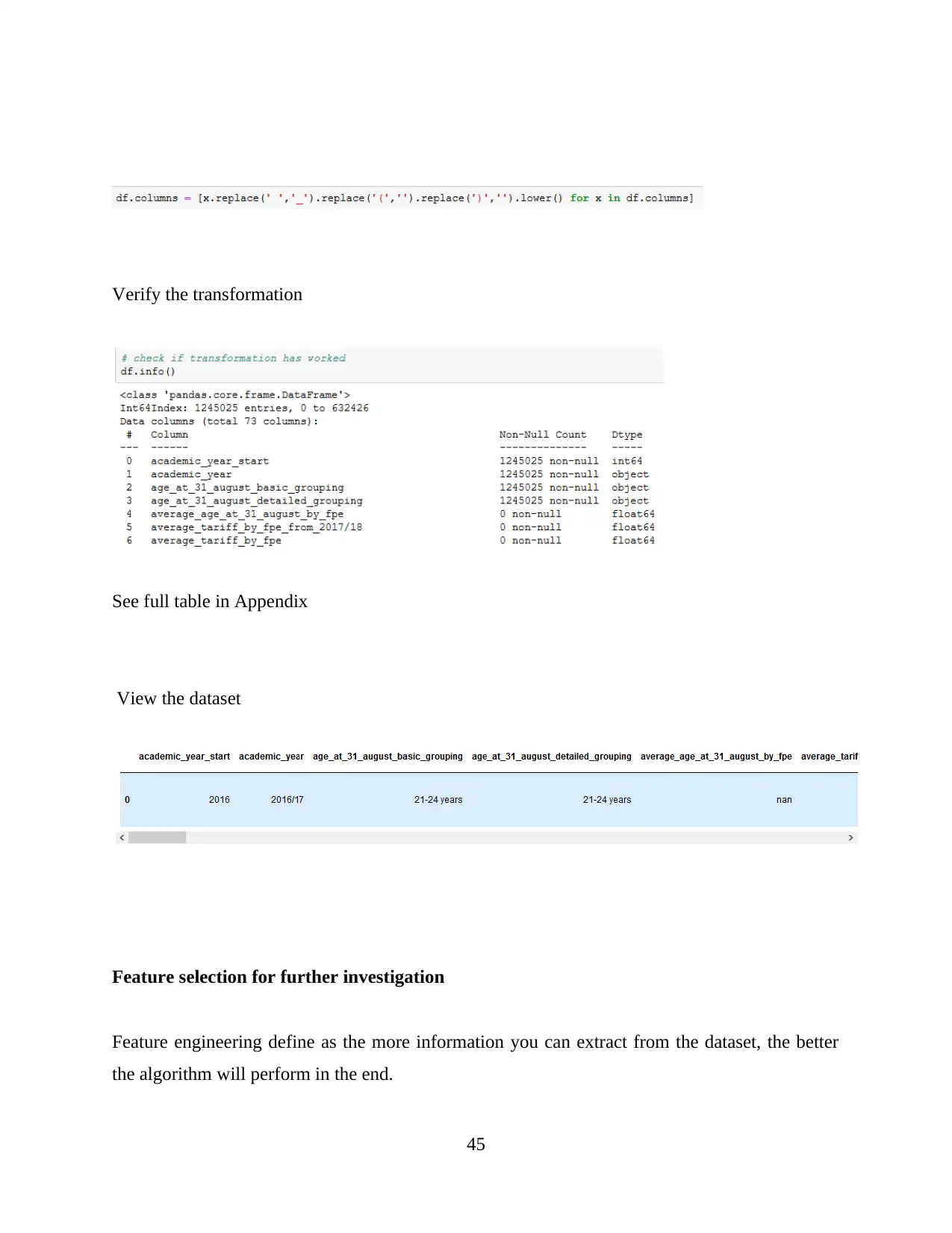
Verify the transformation
See full table in Appendix
View the dataset
Feature selection for further investigation
Feature engineering define as the more information you can extract from the dataset, the better
the algorithm will perform in the end.
45
See full table in Appendix
View the dataset
Feature selection for further investigation
Feature engineering define as the more information you can extract from the dataset, the better
the algorithm will perform in the end.
45

Target variable will be "jacs_subject_area"
The focus is around getting a better understanding of the underlying data and its
Selected the features
features = ["jacs_subject_area",
"age_at_31_august_detailed_grouping",
"age_at_31_august_basic_grouping",
"domicile_country",
"expected_length_of_study", "first_year_filter",
"highest_qualification_on_entry",
"major_source_of_tuition_fees",
"mode_of_study_detailed",
"provider_name",
"provider_short_name","sex"]
create a smaller dataset only with the necessary features
Viewing at the new and filtered dataset
46
The focus is around getting a better understanding of the underlying data and its
Selected the features
features = ["jacs_subject_area",
"age_at_31_august_detailed_grouping",
"age_at_31_august_basic_grouping",
"domicile_country",
"expected_length_of_study", "first_year_filter",
"highest_qualification_on_entry",
"major_source_of_tuition_fees",
"mode_of_study_detailed",
"provider_name",
"provider_short_name","sex"]
create a smaller dataset only with the necessary features
Viewing at the new and filtered dataset
46
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Data visualization and analysis
In stage, taking a closer look into the features that might want to use for training the
model. For example on age and provider name may to select only one of the two to included
features
Age
Compared the Age columns to see whether to use Detail or Basic age group. in this case I have
drop basic because the more information is often better for modeling.
Show all possible categories for DETAILED age grouping
47
In stage, taking a closer look into the features that might want to use for training the
model. For example on age and provider name may to select only one of the two to included
features
Age
Compared the Age columns to see whether to use Detail or Basic age group. in this case I have
drop basic because the more information is often better for modeling.
Show all possible categories for DETAILED age grouping
47

Show all possible categories for BASIC age grouping
Country
Show the first 10 countries of all available countries
Expected length of study
Show all possible labels for expected length of study
48
Country
Show the first 10 countries of all available countries
Expected length of study
Show all possible labels for expected length of study
48
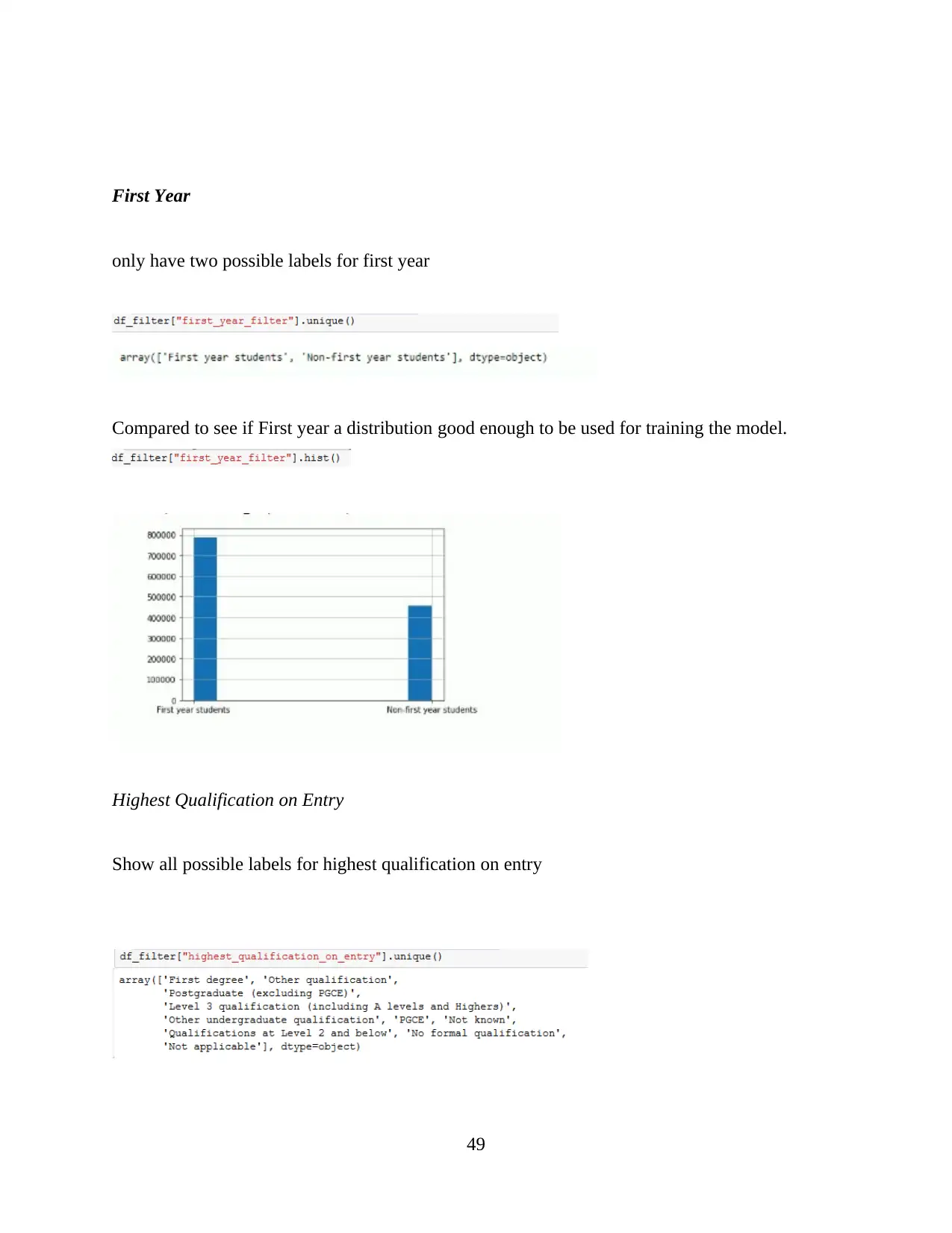
First Year
only have two possible labels for first year
Compared to see if First year a distribution good enough to be used for training the model.
Highest Qualification on Entry
Show all possible labels for highest qualification on entry
49
only have two possible labels for first year
Compared to see if First year a distribution good enough to be used for training the model.
Highest Qualification on Entry
Show all possible labels for highest qualification on entry
49
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Compared on the distribution of this feature, if this was very one-sided it would not be
recommended to use it, but in this case the distribution is fine
Major Source of Tuition fees
show all possible labels for major source of tuition fees
Furthermore, the distribution of categories looking good.
50
recommended to use it, but in this case the distribution is fine
Major Source of Tuition fees
show all possible labels for major source of tuition fees
Furthermore, the distribution of categories looking good.
50

Mode of Study
Show all possible labels for mode of study
Provider Name
The only difference with provider name is the length of the text strings and because of Using the
OneHotEncode categorical variables, decided to use the shorter strings for readability
51
Show all possible labels for mode of study
Provider Name
The only difference with provider name is the length of the text strings and because of Using the
OneHotEncode categorical variables, decided to use the shorter strings for readability
51
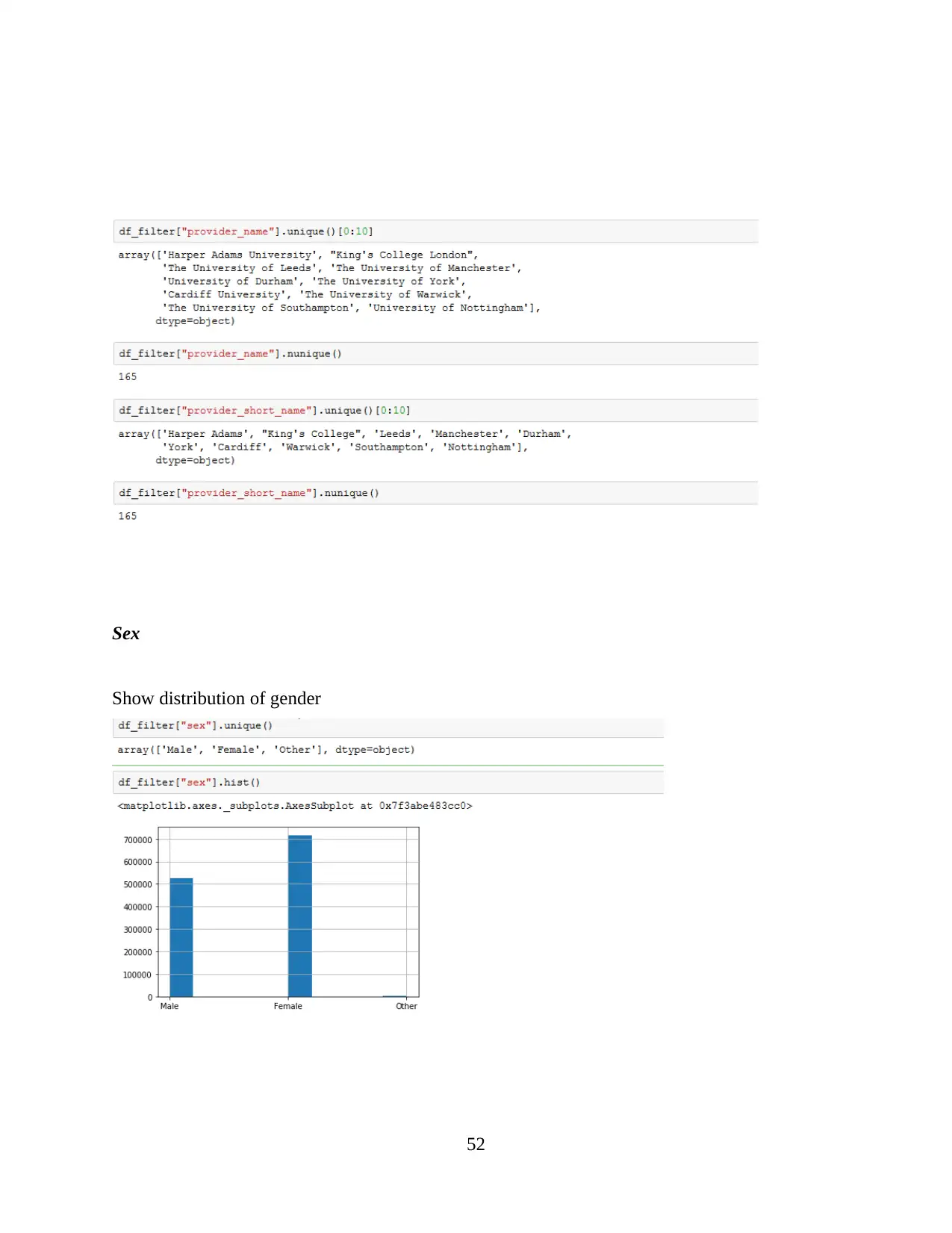
Sex
Show distribution of gender
52
Show distribution of gender
52
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

There are very few datapoints with "Other"-gender, for simplicity I am dropping the observations
with "other"-gender to have a binary/boolean variable which is easier for the algorithm to
process.
The reason I am dropping the "other" gender and not the "sandwich" mode of study even though
the distribution is similar, this because I expect sandwich to have a better predictability for the
subject compared to "other"-gender. Though, its a very miniscule difference.
Selection of features
Final selection of features and creation of "df_work" which will be our final dataset when
preparing the data for model input
features
=["jacs_subject_area","age_at_31_august_detailed_grouping","domicile_country","expected_len
gth_of_study", "first_year_filter",
"highest_qualification_on_entry","major_source_of_tuition_fees","mode_of_study_detailed",
"provider_short_name","sex"]
df_work = df_filter[features]
53
with "other"-gender to have a binary/boolean variable which is easier for the algorithm to
process.
The reason I am dropping the "other" gender and not the "sandwich" mode of study even though
the distribution is similar, this because I expect sandwich to have a better predictability for the
subject compared to "other"-gender. Though, its a very miniscule difference.
Selection of features
Final selection of features and creation of "df_work" which will be our final dataset when
preparing the data for model input
features
=["jacs_subject_area","age_at_31_august_detailed_grouping","domicile_country","expected_len
gth_of_study", "first_year_filter",
"highest_qualification_on_entry","major_source_of_tuition_fees","mode_of_study_detailed",
"provider_short_name","sex"]
df_work = df_filter[features]
53

Review detail checkpoint
selected 'jacs_subject_area' as our target variable for predictions
I have took a look at the data to pre-select features based on our domain knowledge
I have took a deeper look into data and its distribution, what are the differences between related
features, like age_basic and age_detailed and decided with which features we want to continue
with
Now I am going to clean the data and prepare it for the final modelling step
Imputation
The output below that there are no null datapoints in the dataset at this point
I don't have to impute any features and can move on to preparing the data types
Outlier Detection
Since we have only categorical or boolean variables we don't have to check for outliers because
features don’t have outliers, they will have missing data at maximum
Data Types
54
selected 'jacs_subject_area' as our target variable for predictions
I have took a look at the data to pre-select features based on our domain knowledge
I have took a deeper look into data and its distribution, what are the differences between related
features, like age_basic and age_detailed and decided with which features we want to continue
with
Now I am going to clean the data and prepare it for the final modelling step
Imputation
The output below that there are no null datapoints in the dataset at this point
I don't have to impute any features and can move on to preparing the data types
Outlier Detection
Since we have only categorical or boolean variables we don't have to check for outliers because
features don’t have outliers, they will have missing data at maximum
Data Types
54

LabelEncode: Jacs_Subject_Area
Since xgBoost works best with a single target variable we are assigning each subject a numerical
label which is then used to train the model
Replacing Underscore, & and spaces
View the result.
55
Since xgBoost works best with a single target variable we are assigning each subject a numerical
label which is then used to train the model
Replacing Underscore, & and spaces
View the result.
55
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
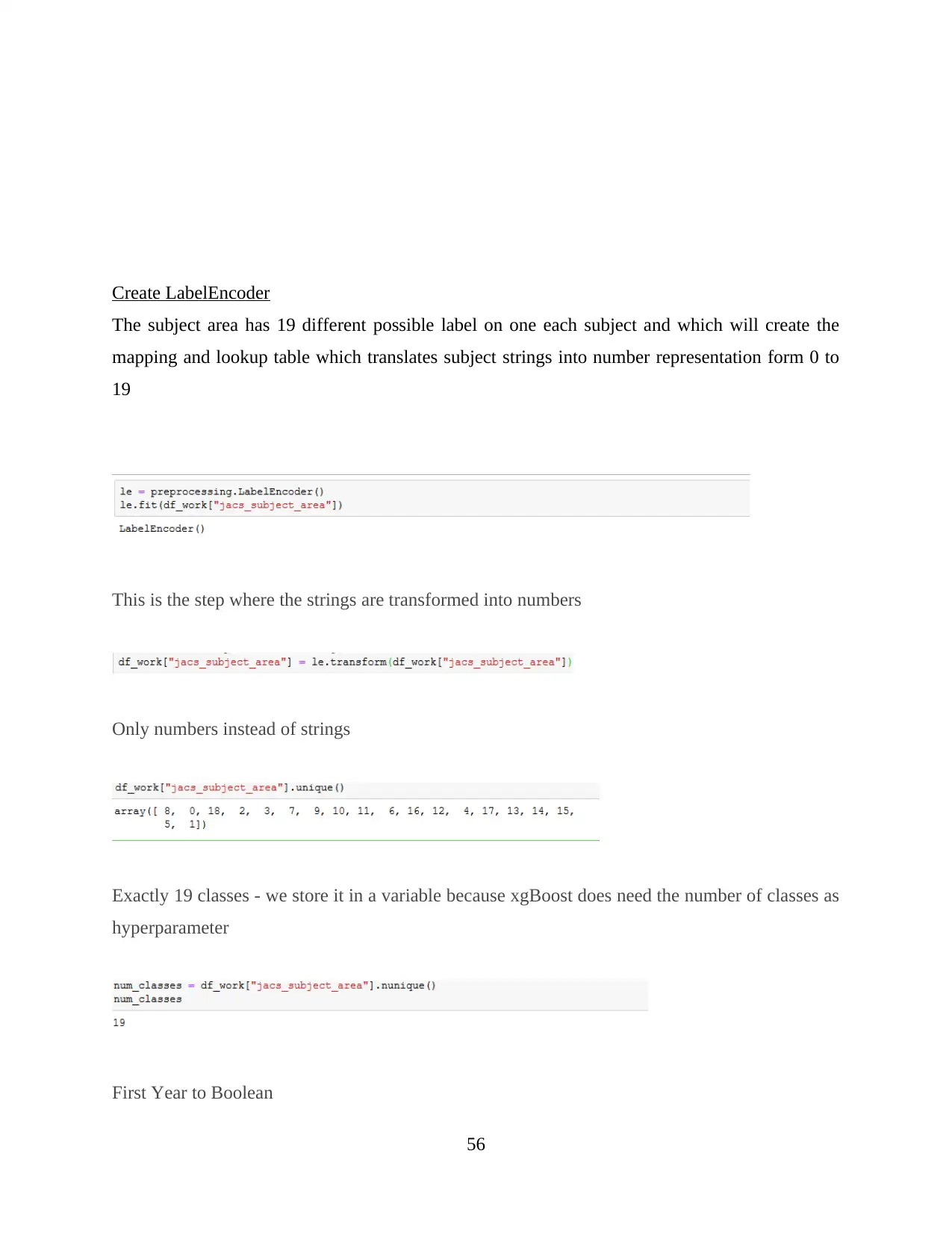
Create LabelEncoder
The subject area has 19 different possible label on one each subject and which will create the
mapping and lookup table which translates subject strings into number representation form 0 to
19
This is the step where the strings are transformed into numbers
Only numbers instead of strings
Exactly 19 classes - we store it in a variable because xgBoost does need the number of classes as
hyperparameter
First Year to Boolean
56
The subject area has 19 different possible label on one each subject and which will create the
mapping and lookup table which translates subject strings into number representation form 0 to
19
This is the step where the strings are transformed into numbers
Only numbers instead of strings
Exactly 19 classes - we store it in a variable because xgBoost does need the number of classes as
hyperparameter
First Year to Boolean
56
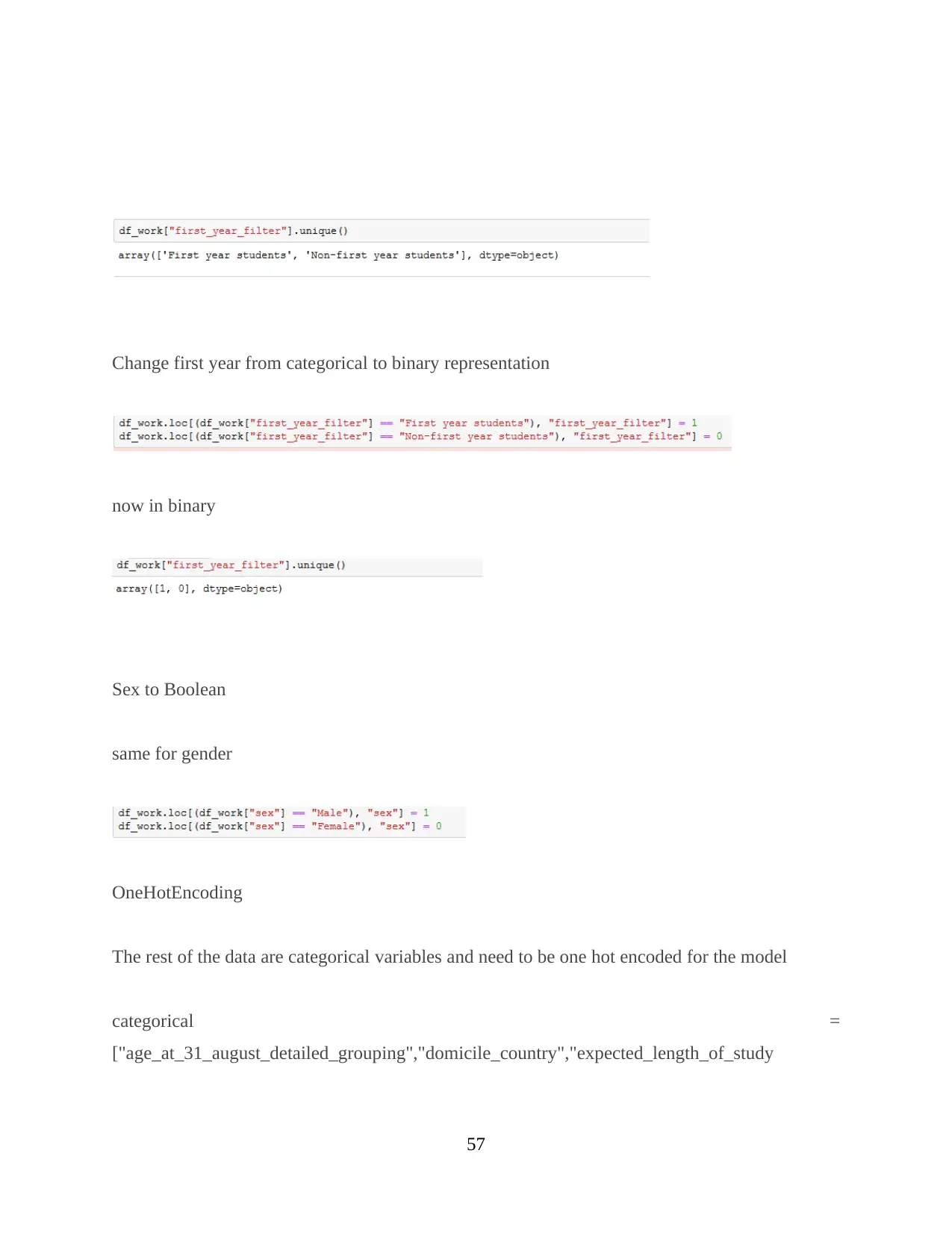
Change first year from categorical to binary representation
now in binary
Sex to Boolean
same for gender
OneHotEncoding
The rest of the data are categorical variables and need to be one hot encoded for the model
categorical =
["age_at_31_august_detailed_grouping","domicile_country","expected_length_of_study
57
now in binary
Sex to Boolean
same for gender
OneHotEncoding
The rest of the data are categorical variables and need to be one hot encoded for the model
categorical =
["age_at_31_august_detailed_grouping","domicile_country","expected_length_of_study
57

"highest_qualification_on_entry","major_source_of_tuition_fees","mode_of_study_detailed",
"provider_short_name"]
Before we encode the features we need to process the observations too. Basically, the same steps
performed as above when we were transforming our target label
View the data
Transforming categorical variables with lots of different categories is often looked down upon
since using these will bloat the dataset to enormous sizes. In our notebook we increase the
number of features to 447. this happens because of a technique that is called OneHotEncoding
OneHotEncoding will create a new boolean feature for every categorical label within a feature.
For example I will create new features for every country a student has applied from. The feature
with the domicile country of the student will then be set to 1 while all other country-features will
remain zeros
Performing OneHotEncoding process .
58
"provider_short_name"]
Before we encode the features we need to process the observations too. Basically, the same steps
performed as above when we were transforming our target label
View the data
Transforming categorical variables with lots of different categories is often looked down upon
since using these will bloat the dataset to enormous sizes. In our notebook we increase the
number of features to 447. this happens because of a technique that is called OneHotEncoding
OneHotEncoding will create a new boolean feature for every categorical label within a feature.
For example I will create new features for every country a student has applied from. The feature
with the domicile country of the student will then be set to 1 while all other country-features will
remain zeros
Performing OneHotEncoding process .
58
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
The step above bloats our features from 9 to 447
Model Training, parameter tuning and Model evaluation
When training a model we have to have some sort of metric to evaluate how good or bad is the
algorithm.
In stage, I am going to split the model into two parts, one training dataset and one test/validation
set using a ratio of 80/20 for this case study.
Shuffle
In this data-split, I want to make sure that datapoints are distributed randomly over both datasets.
This is too avoid having clustered data in either of the datasets
Spilt
splitting the dataset in 80/20 ratio
59
Model Training, parameter tuning and Model evaluation
When training a model we have to have some sort of metric to evaluate how good or bad is the
algorithm.
In stage, I am going to split the model into two parts, one training dataset and one test/validation
set using a ratio of 80/20 for this case study.
Shuffle
In this data-split, I want to make sure that datapoints are distributed randomly over both datasets.
This is too avoid having clustered data in either of the datasets
Spilt
splitting the dataset in 80/20 ratio
59
The actual split
shape of both datasets
Save to instance disk
Store Datasets in S3
Store our train- and test-dataset on S3 after shuffle and splitting
60
shape of both datasets
Save to instance disk
Store Datasets in S3
Store our train- and test-dataset on S3 after shuffle and splitting
60
Preparing xgBoost
xgBoost is very picky with its input format. it only takes libsvm or comma-separated-values
(csv). Dataset input is in csv format, setting the content-type to “csv” and initializing training and
test-dataset streams from S3
Get AWS optimized docker image of xgBoost algorithm and using version 1.0-1
Create a unique training name
xgBoost uses libsvm or csv format, our data is in csv format
Create s3-inputs for train and validation dataset
Set and output path where the trained model will be stored as model.tar.gz file
61
xgBoost is very picky with its input format. it only takes libsvm or comma-separated-values
(csv). Dataset input is in csv format, setting the content-type to “csv” and initializing training and
test-dataset streams from S3
Get AWS optimized docker image of xgBoost algorithm and using version 1.0-1
Create a unique training name
xgBoost uses libsvm or csv format, our data is in csv format
Create s3-inputs for train and validation dataset
Set and output path where the trained model will be stored as model.tar.gz file
61
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

xgBoost hyperparameters:
Creating an estimator instance within sagemaker using a memory optimised instance
(“ml.m5.12xlarge”) and train the model using the .Method while providing the test and
validation streams and after the model has completed training it is compressed and stored in
tar.gz format in a S3 bucket for further use
initialize hyperparameters
initialize sagemaker-estimator instance with
Execute the XGBoost training job
62
Creating an estimator instance within sagemaker using a memory optimised instance
(“ml.m5.12xlarge”) and train the model using the .Method while providing the test and
validation streams and after the model has completed training it is compressed and stored in
tar.gz format in a S3 bucket for further use
initialize hyperparameters
initialize sagemaker-estimator instance with
Execute the XGBoost training job
62
Model evaluation and visualisation of the metrics train/Validation
Get training analytics data from the estimator
After the model has finished, we can use information from the training analytics to visualize the
evolution of our train and validation errors
Plot analytics
63
Get training analytics data from the estimator
After the model has finished, we can use information from the training analytics to visualize the
evolution of our train and validation errors
Plot analytics
63
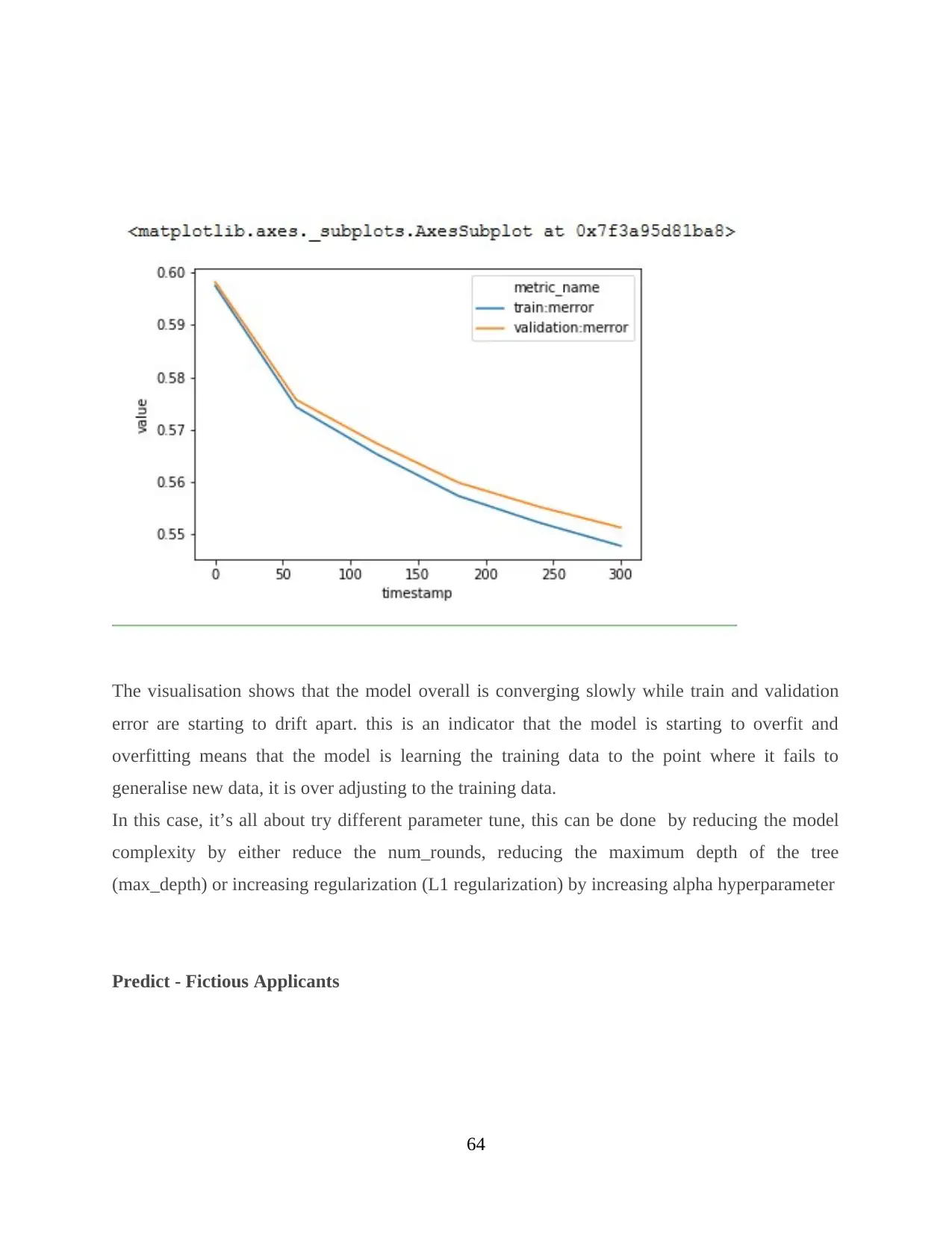
The visualisation shows that the model overall is converging slowly while train and validation
error are starting to drift apart. this is an indicator that the model is starting to overfit and
overfitting means that the model is learning the training data to the point where it fails to
generalise new data, it is over adjusting to the training data.
In this case, it’s all about try different parameter tune, this can be done by reducing the model
complexity by either reduce the num_rounds, reducing the maximum depth of the tree
(max_depth) or increasing regularization (L1 regularization) by increasing alpha hyperparameter
Predict - Fictious Applicants
64
error are starting to drift apart. this is an indicator that the model is starting to overfit and
overfitting means that the model is learning the training data to the point where it fails to
generalise new data, it is over adjusting to the training data.
In this case, it’s all about try different parameter tune, this can be done by reducing the model
complexity by either reduce the num_rounds, reducing the maximum depth of the tree
(max_depth) or increasing regularization (L1 regularization) by increasing alpha hyperparameter
Predict - Fictious Applicants
64
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

This where try the dataset to predict but first copy the stored model file (tar.gz) back to our
notebook instance and extract the model and then use the python pickle library to load the trained
model and at this point the model is ready to predict data.
Prediction input the model expects the same data format as the data it has trained on, in our case
study it expects a row with 446 comma separated values
Storage URI of last trained model – change screenshot
Get location storage of last trained model
65
notebook instance and extract the model and then use the python pickle library to load the trained
model and at this point the model is ready to predict data.
Prediction input the model expects the same data format as the data it has trained on, in our case
study it expects a row with 446 comma separated values
Storage URI of last trained model – change screenshot
Get location storage of last trained model
65
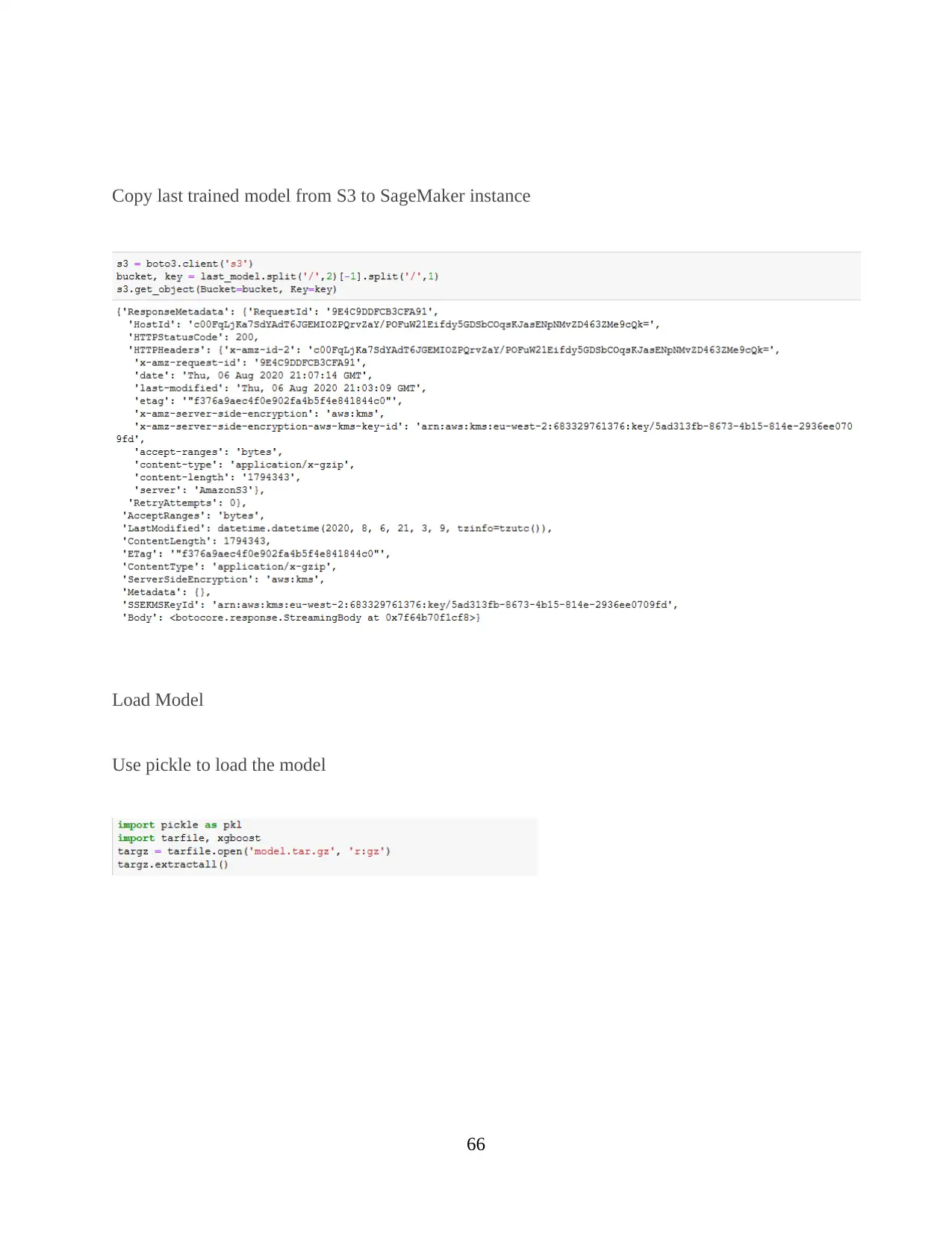
Copy last trained model from S3 to SageMaker instance
Load Model
Use pickle to load the model
66
Load Model
Use pickle to load the model
66
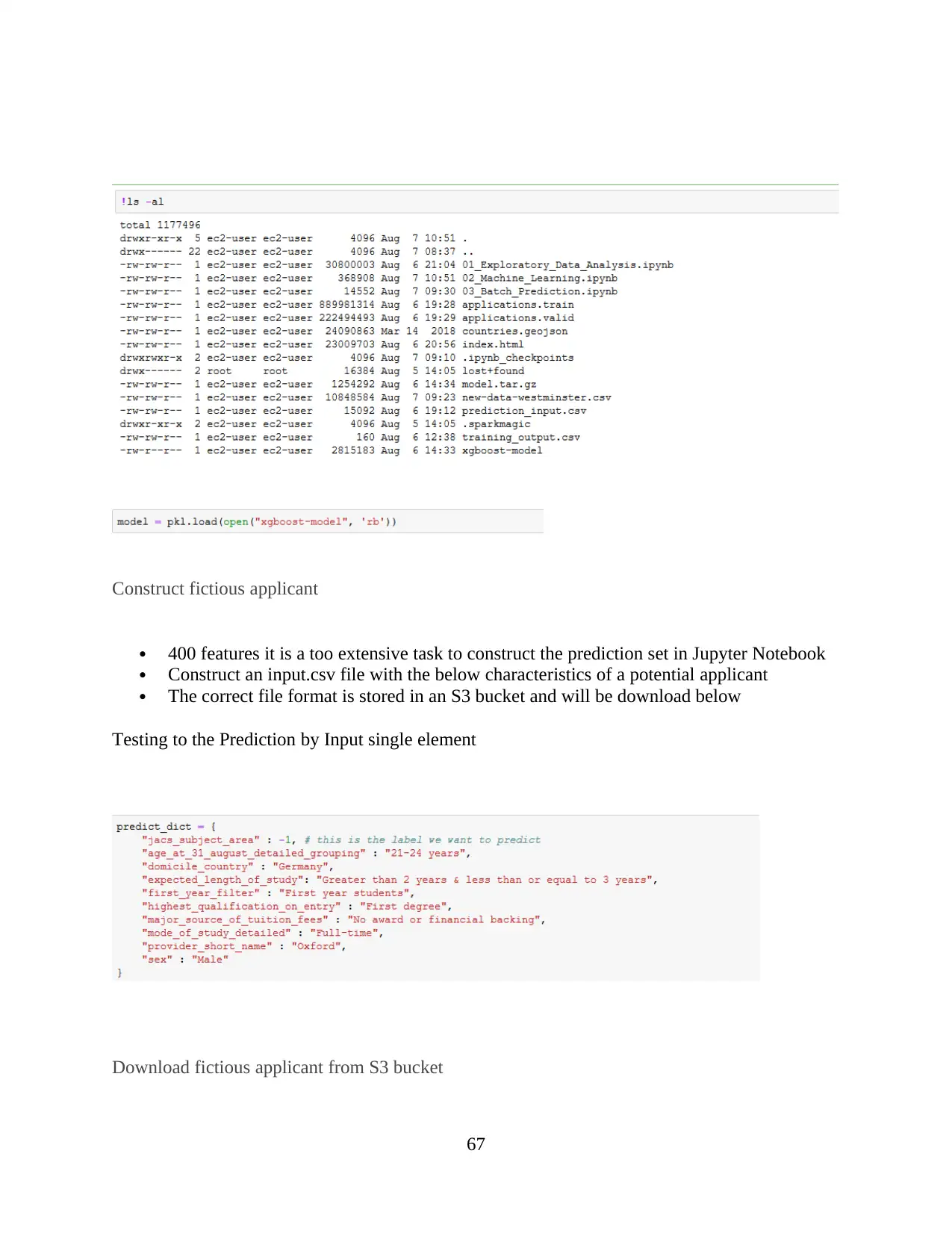
Construct fictious applicant
400 features it is a too extensive task to construct the prediction set in Jupyter Notebook
Construct an input.csv file with the below characteristics of a potential applicant
The correct file format is stored in an S3 bucket and will be download below
Testing to the Prediction by Input single element
Download fictious applicant from S3 bucket
67
400 features it is a too extensive task to construct the prediction set in Jupyter Notebook
Construct an input.csv file with the below characteristics of a potential applicant
The correct file format is stored in an S3 bucket and will be download below
Testing to the Prediction by Input single element
Download fictious applicant from S3 bucket
67
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Reshaping prediction format in xgBoost DMatrix format for prediction
Every machine learning algorithm has its own structures which it can work with it.
AWS optimized xgBoost uses a (1, len(features)) DMatrix representation
Do some data wrangling to reshape our data into the input format
Reshaping the last time to have an xgBoost-valid format
Prediction
68
Every machine learning algorithm has its own structures which it can work with it.
AWS optimized xgBoost uses a (1, len(features)) DMatrix representation
Do some data wrangling to reshape our data into the input format
Reshaping the last time to have an xgBoost-valid format
Prediction
68
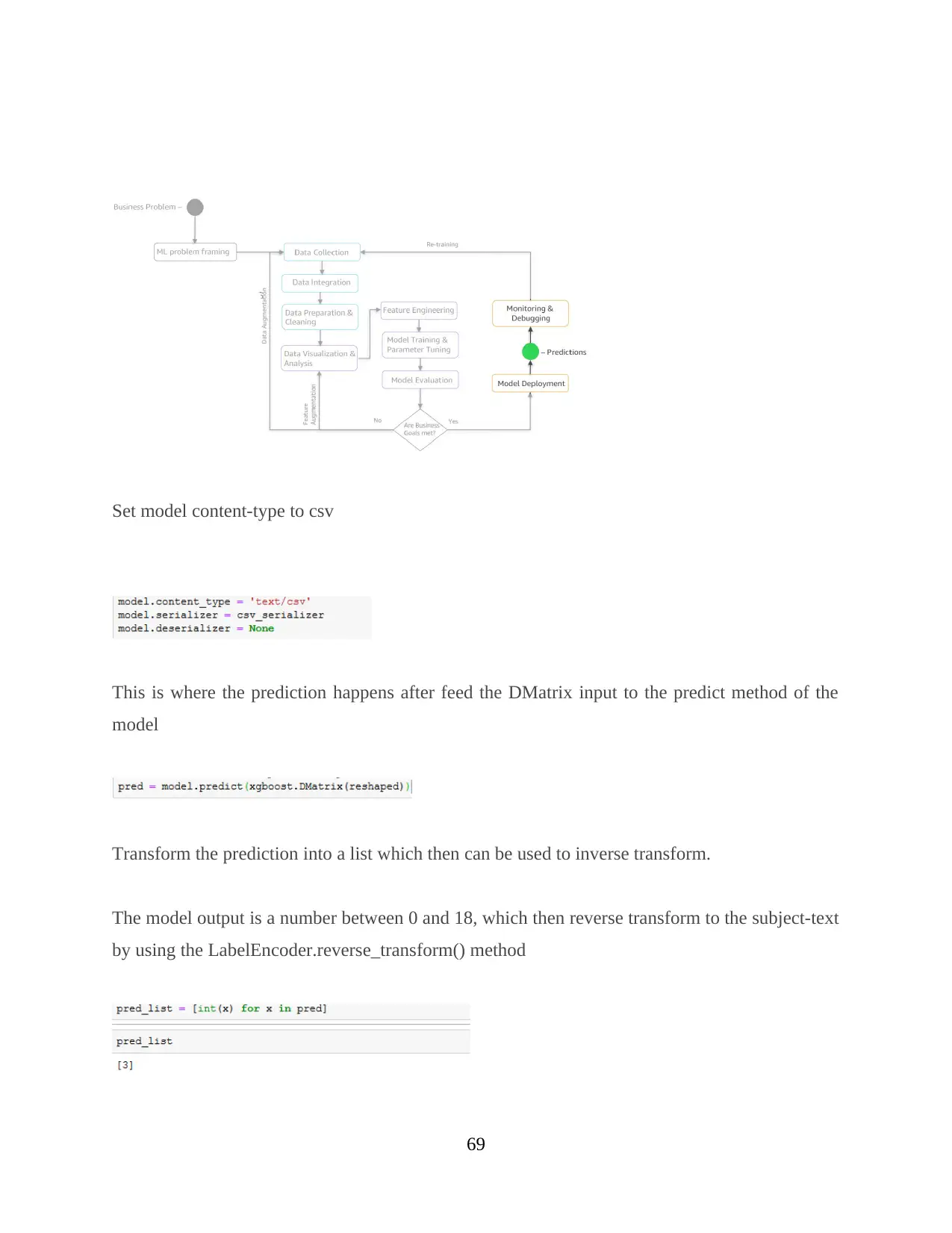
Set model content-type to csv
This is where the prediction happens after feed the DMatrix input to the predict method of the
model
Transform the prediction into a list which then can be used to inverse transform.
The model output is a number between 0 and 18, which then reverse transform to the subject-text
by using the LabelEncoder.reverse_transform() method
69
This is where the prediction happens after feed the DMatrix input to the predict method of the
model
Transform the prediction into a list which then can be used to inverse transform.
The model output is a number between 0 and 18, which then reverse transform to the subject-text
by using the LabelEncoder.reverse_transform() method
69

The system predict number (3) then inverse Transform label encoding to actual subject
Transforming the number back to the subject text
Prediction Input single element : Prediction : Business Administrative studies
New data set for batch prediction of Westminster University Dataset
Read data to be predicted from S3 Bucket
View the first row of the Westminster data
70
Transforming the number back to the subject text
Prediction Input single element : Prediction : Business Administrative studies
New data set for batch prediction of Westminster University Dataset
Read data to be predicted from S3 Bucket
View the first row of the Westminster data
70
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
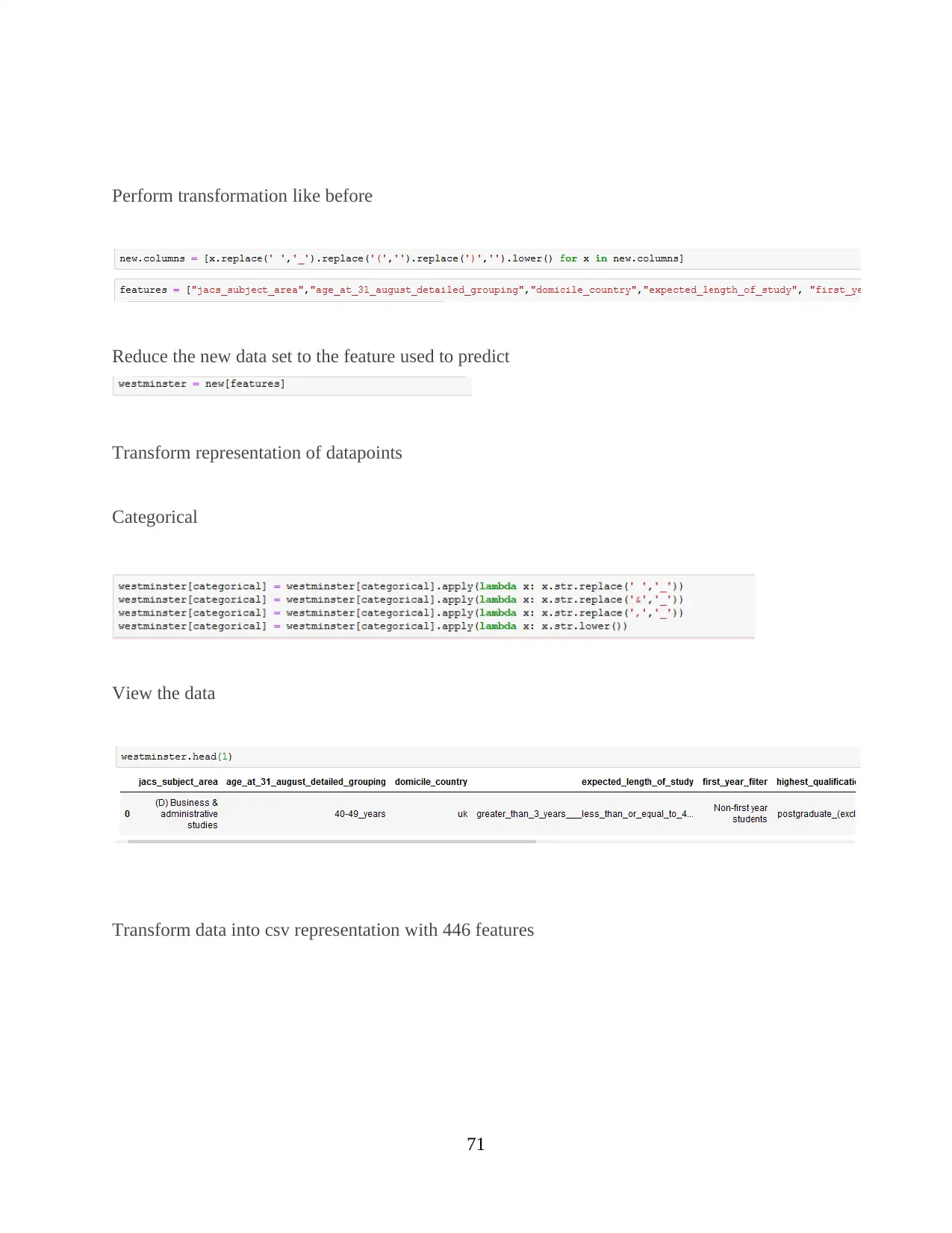
Perform transformation like before
Reduce the new data set to the feature used to predict
Transform representation of datapoints
Categorical
View the data
Transform data into csv representation with 446 features
71
Reduce the new data set to the feature used to predict
Transform representation of datapoints
Categorical
View the data
Transform data into csv representation with 446 features
71
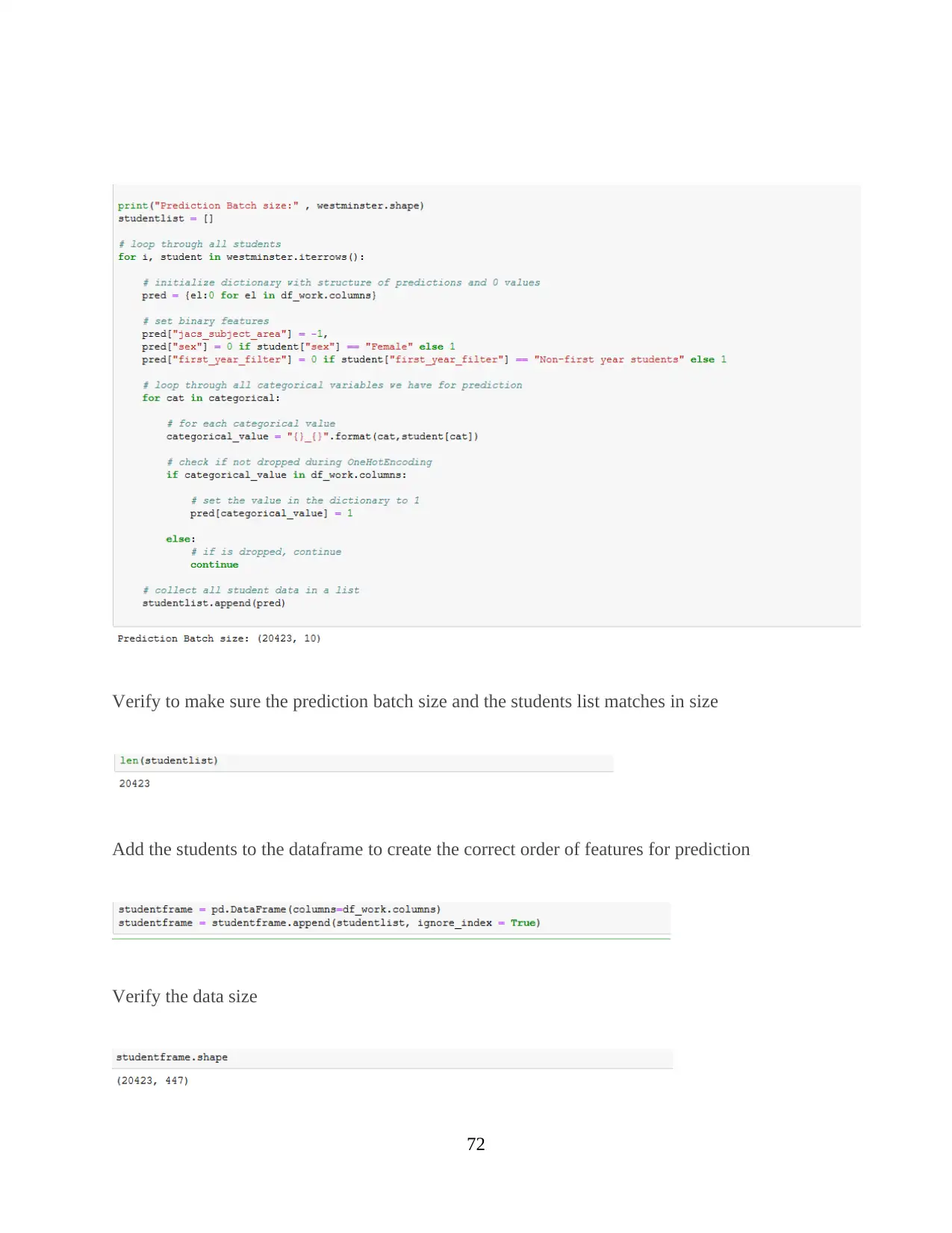
Verify to make sure the prediction batch size and the students list matches in size
Add the students to the dataframe to create the correct order of features for prediction
Verify the data size
72
Add the students to the dataframe to create the correct order of features for prediction
Verify the data size
72
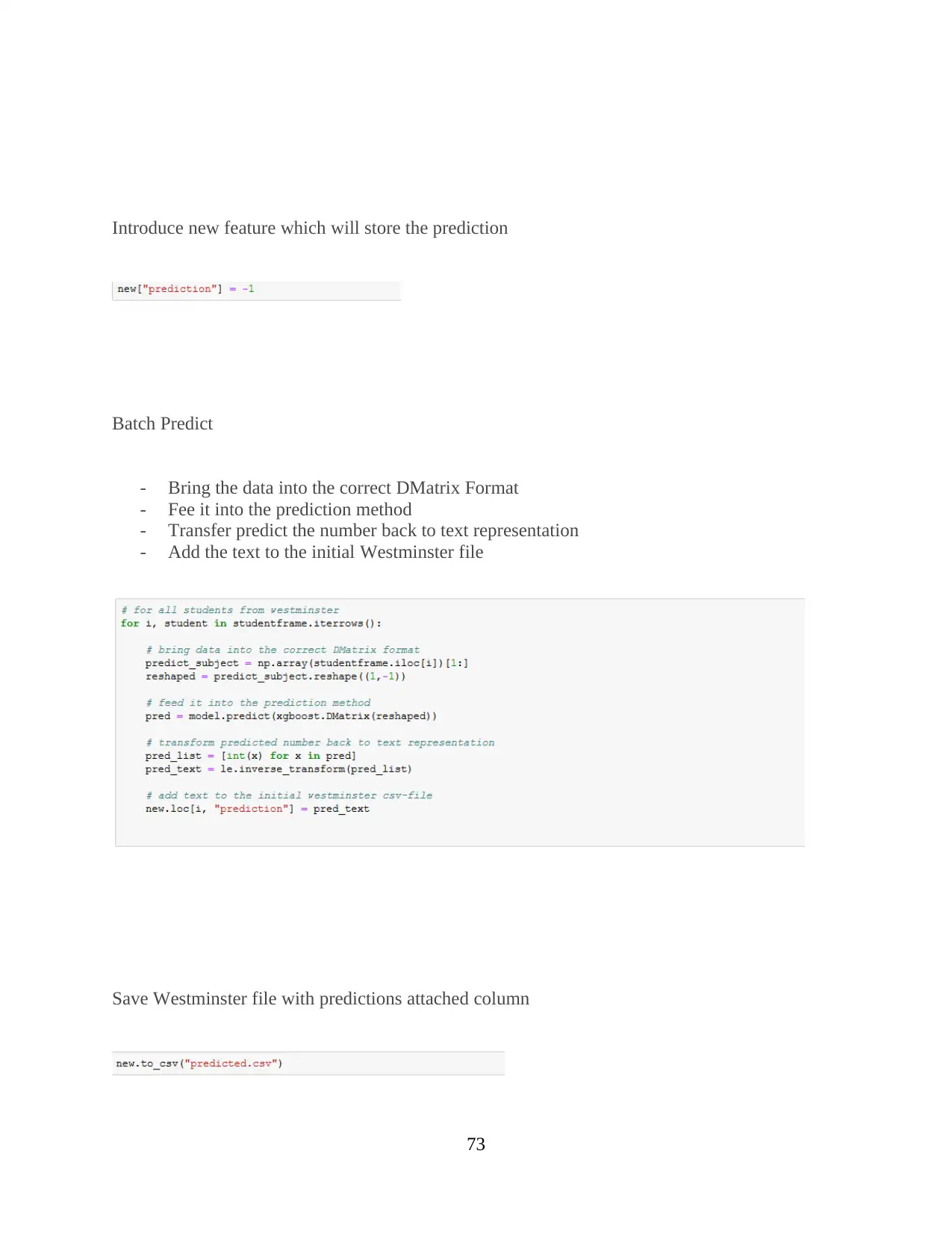
Introduce new feature which will store the prediction
Batch Predict
- Bring the data into the correct DMatrix Format
- Fee it into the prediction method
- Transfer predict the number back to text representation
- Add the text to the initial Westminster file
Save Westminster file with predictions attached column
73
Batch Predict
- Bring the data into the correct DMatrix Format
- Fee it into the prediction method
- Transfer predict the number back to text representation
- Add the text to the initial Westminster file
Save Westminster file with predictions attached column
73
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Upload CSV File back to S3 Bucket
At this point I have completed the whole data science/machine learning lifestyle from start to end
and the data is available for usage in business intelligence tools like AWS QuickSight or Tableau
AWS Quick sight
All data will get uploaded to Amazon S3 Storage then connect to Quicksight for visualisation.
QuickSight, has easily connect to other applications in AWS, including Redshift, Athena, and S3
bucket data sources. AWS S3 buckets store objects consisting of data, and its descriptive
metadata, and cloud storage resources similar to file folders.
Integrating S3 Storage with QuickSight using manifest Jason to identify files that you want to
use for analyze the data.
74
At this point I have completed the whole data science/machine learning lifestyle from start to end
and the data is available for usage in business intelligence tools like AWS QuickSight or Tableau
AWS Quick sight
All data will get uploaded to Amazon S3 Storage then connect to Quicksight for visualisation.
QuickSight, has easily connect to other applications in AWS, including Redshift, Athena, and S3
bucket data sources. AWS S3 buckets store objects consisting of data, and its descriptive
metadata, and cloud storage resources similar to file folders.
Integrating S3 Storage with QuickSight using manifest Jason to identify files that you want to
use for analyze the data.
74
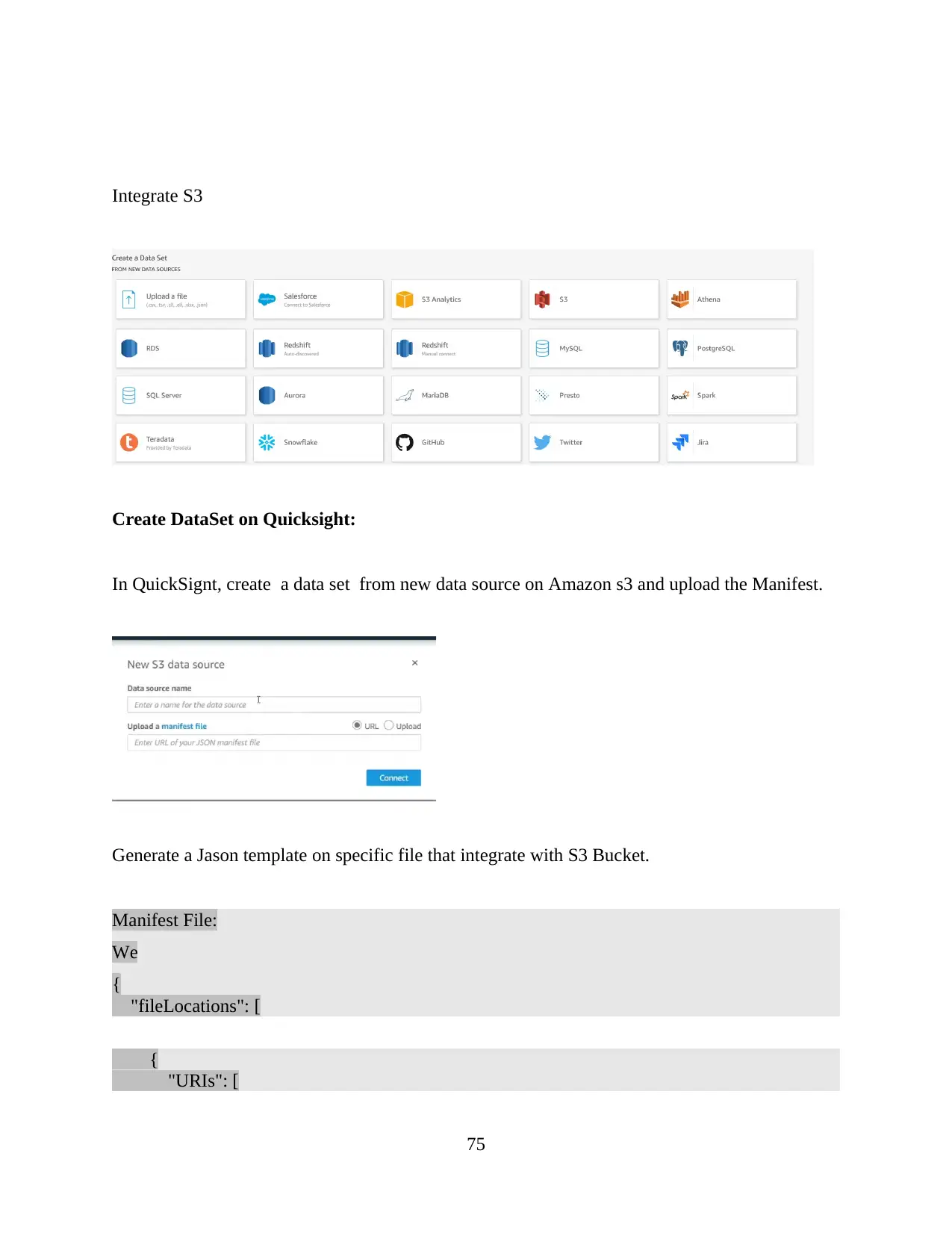
Integrate S3
Create DataSet on Quicksight:
In QuickSignt, create a data set from new data source on Amazon s3 and upload the Manifest.
Generate a Jason template on specific file that integrate with S3 Bucket.
Manifest File:
We
{
"fileLocations": [
{
"URIs": [
75
Create DataSet on Quicksight:
In QuickSignt, create a data set from new data source on Amazon s3 and upload the Manifest.
Generate a Jason template on specific file that integrate with S3 Bucket.
Manifest File:
We
{
"fileLocations": [
{
"URIs": [
75

"s3://student-project-datasets/prediction-output/predicted.csv" [ location of the data
storage]
]
}
],
"globalUploadSettings": {
"format": "CSV",
"textqualifier": "\""
}
}
Overview of workflow data to display on dashboard
Analyse and Vsiualation with Quicksight
Result Prediction:
Compare
76
storage]
]
}
],
"globalUploadSettings": {
"format": "CSV",
"textqualifier": "\""
}
}
Overview of workflow data to display on dashboard
Analyse and Vsiualation with Quicksight
Result Prediction:
Compare
76
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
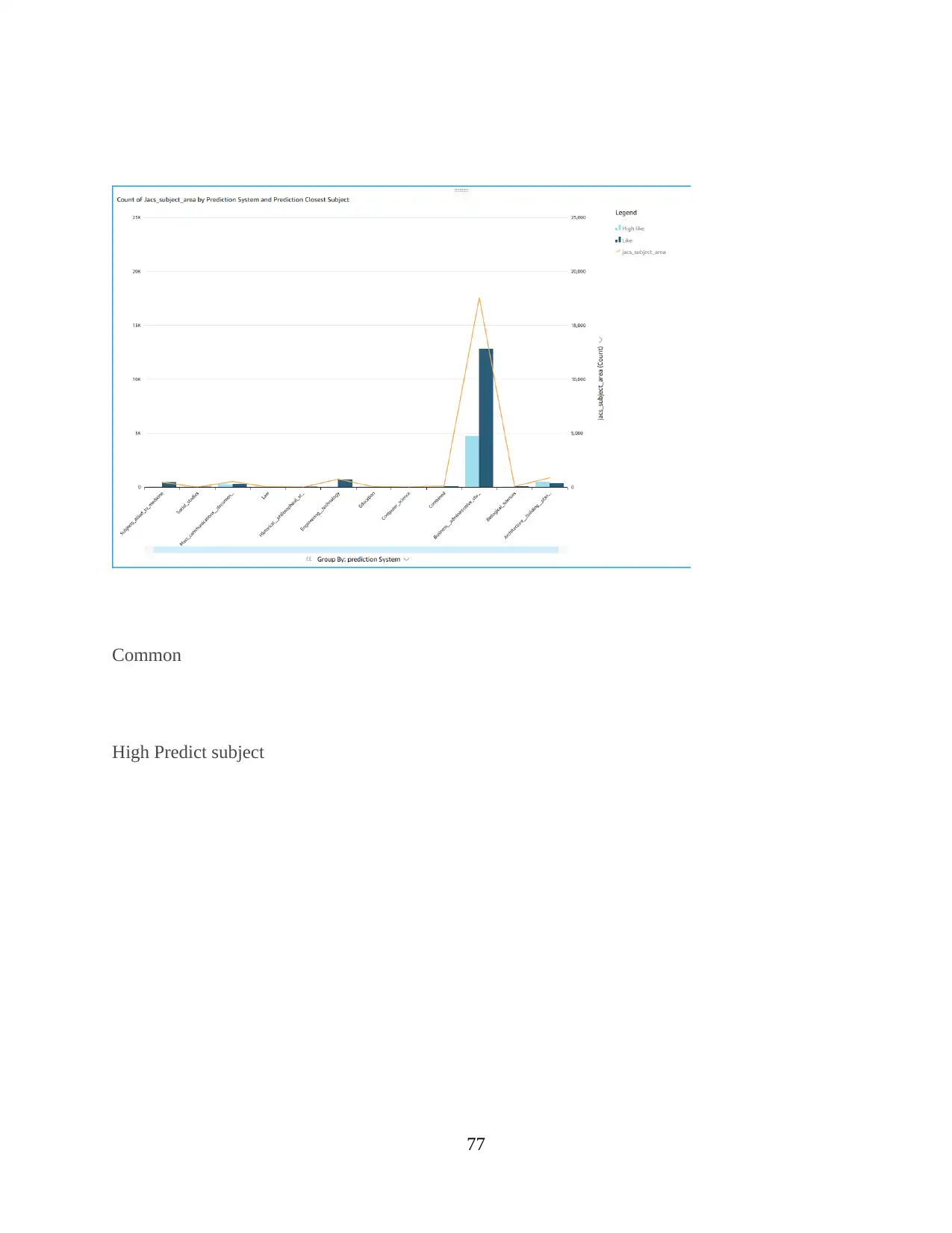
Common
High Predict subject
77
High Predict subject
77
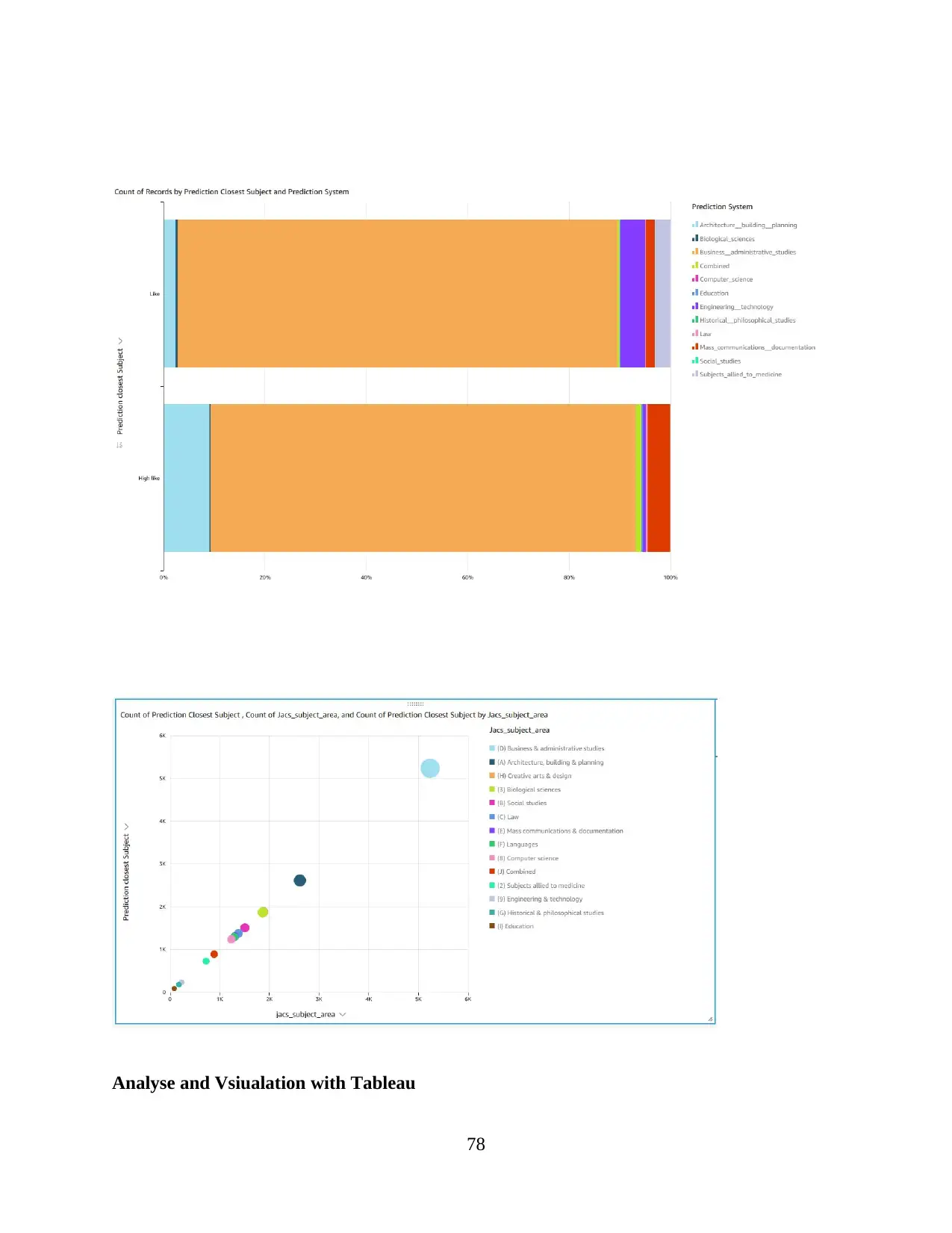
Analyse and Vsiualation with Tableau
78
78
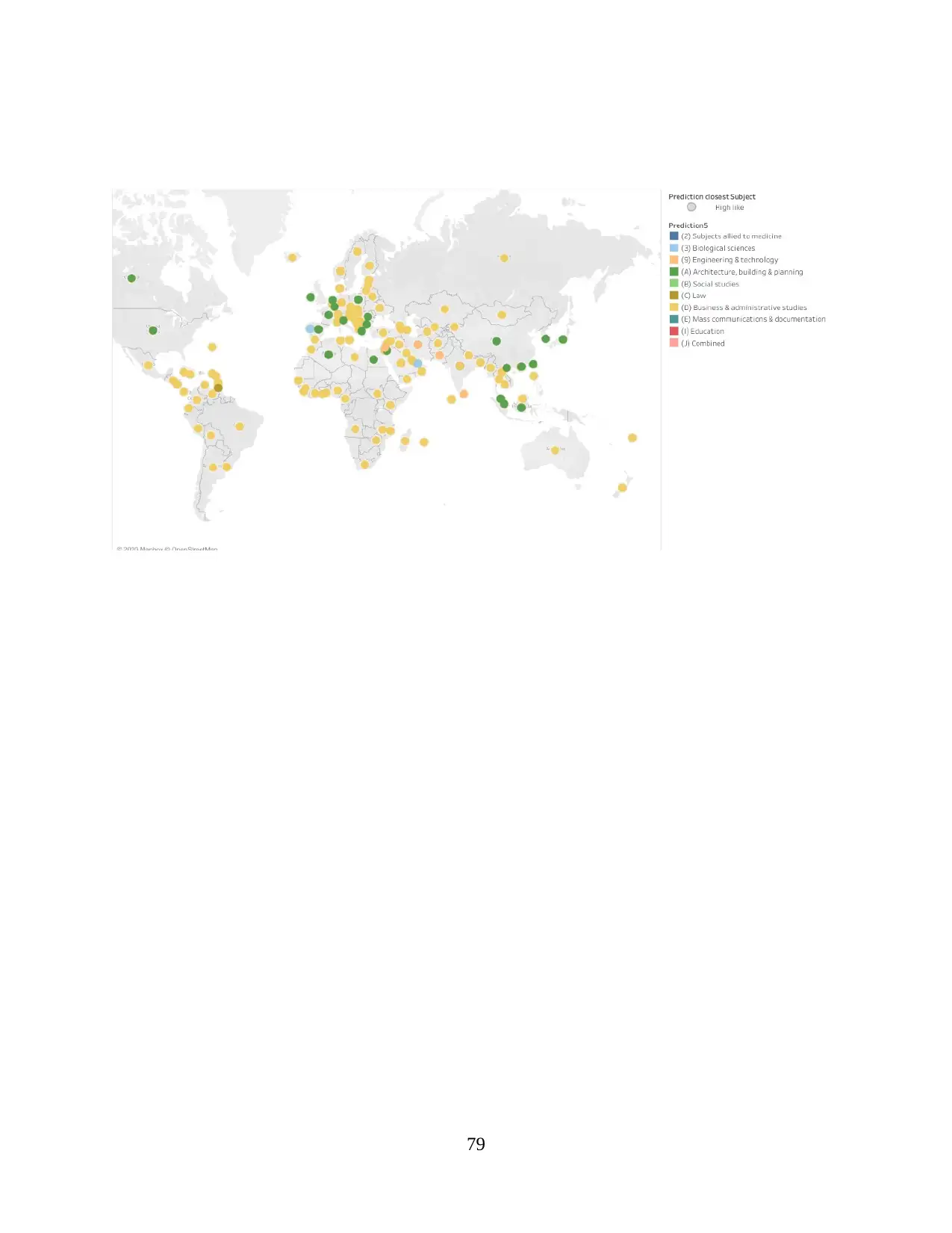
79
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

CHAPTER-5 CONCLUSION AND RECOMMENDATION
From above discussion, it has been concluded that big data analytics tool such Amazon web
server less technology which always supporting for storage large amount or data or information.
Generally, it may consists of different factors such as volume, velocity and variety. In order to
process the data which bring about the unprecedented challenges the enterprise and need to face
or overcome problem. The big data analytical platform which can easily gain competitive
advantage.
As per analysis, it can be determined that big data is consider as integral part of enterprise
operations. It help for gain unmeasurable value and unexplored. Large Corporation have
implemented the new paradigm due to advancement of technologies, which can easily help for
reducing challenges, threat and risk.
In this report, it has been attempted to clarify the specific challenges but can be reduced
through big data server less technology such as Amazon web service. This can provide the
scalable or better solution. Although AWS has considered as main framework in this case study.
Furthermore, it also designed to do work as isolation and also demonstrated with AWS where
how it can easily resolve complex problem or issue through big data analytics or processing.
Through study, it has concluded that large amount of data growing or moving rapidly in both
inside as well as outside of enterprise. so as considered the data integration strategy through
hybrid big data solution for analytical purpose. Therefore, it is becoming crucial part of
organization to embrace software as a service model through buying the different customised big
data package. It is the most effective way to minimise the complexity and setup suitable
price/cost for managing the big data infrastructure.
Recommendation
In future, it has recommended the big data analytics and processing application, which can
easily improve the automated architecture. At some point, the prototype is predominately which
mainly configured or managed in proper manner. The overall system could be considered as
dynamic, automated and scalable to manage the effective connectivity between multiple sources.
Furthermore, it has suggested to use Kaftka for publishing-subscribed messaging system this
will provide the better service where giving unlimited number of data sources and could be
80
From above discussion, it has been concluded that big data analytics tool such Amazon web
server less technology which always supporting for storage large amount or data or information.
Generally, it may consists of different factors such as volume, velocity and variety. In order to
process the data which bring about the unprecedented challenges the enterprise and need to face
or overcome problem. The big data analytical platform which can easily gain competitive
advantage.
As per analysis, it can be determined that big data is consider as integral part of enterprise
operations. It help for gain unmeasurable value and unexplored. Large Corporation have
implemented the new paradigm due to advancement of technologies, which can easily help for
reducing challenges, threat and risk.
In this report, it has been attempted to clarify the specific challenges but can be reduced
through big data server less technology such as Amazon web service. This can provide the
scalable or better solution. Although AWS has considered as main framework in this case study.
Furthermore, it also designed to do work as isolation and also demonstrated with AWS where
how it can easily resolve complex problem or issue through big data analytics or processing.
Through study, it has concluded that large amount of data growing or moving rapidly in both
inside as well as outside of enterprise. so as considered the data integration strategy through
hybrid big data solution for analytical purpose. Therefore, it is becoming crucial part of
organization to embrace software as a service model through buying the different customised big
data package. It is the most effective way to minimise the complexity and setup suitable
price/cost for managing the big data infrastructure.
Recommendation
In future, it has recommended the big data analytics and processing application, which can
easily improve the automated architecture. At some point, the prototype is predominately which
mainly configured or managed in proper manner. The overall system could be considered as
dynamic, automated and scalable to manage the effective connectivity between multiple sources.
Furthermore, it has suggested to use Kaftka for publishing-subscribed messaging system this
will provide the better service where giving unlimited number of data sources and could be
80

configured or connected. It is useful in future when multiple application can process or use data
through kafka interface. Sometimes, it will be integrated with AWS architecture to manage or
collect large amount of information effectively.
81
through kafka interface. Sometimes, it will be integrated with AWS architecture to manage or
collect large amount of information effectively.
81

REFERENCES
Book and Journals
Backes, J. and et.al., 2019, July. Reachability analysis for AWS-based networks. In International
Conference on Computer Aided Verification (pp. 231-241). Springer, Cham.
Bai, J., Jhaney, I. and Wells, J., 2019. Developing a Reproducible Microbiome Data Analysis
Pipeline Using the Amazon Web Services Cloud for a Cancer Research Group: Proof-of-
Concept Study. JMIR medical informatics. 7(4). p.e14667.
Basu, K., Hamdullah, A. and Ball, F., 2020, June. Architecture of a Cloud-based Fault-Tolerant
Control Platform for improving the QoS of Social Multimedia Applications on SD-WAN.
In 2020 13th International Conference on Communications (COMM) (pp. 495-500).
IEEE.
Buure, O., 2020. Challenges in moving to cloud computing environment: case Finnish
teleoperator.
Choudhary, B. and et.al., 2020, January. Case Study: Use of AWS Lambda for Building a
Serverless Chat. In Proceeding of International Conference on Computational Science
and Applications: ICCSA 2019 (p. 237). Springer Nature.
Choudhary, B., Pophale, C. and Sonawani, S.S., 2020, January. Case Study: Use of AWS
Lambda for Building a Serverless Chat. In Proceeding of International Conference on
Computational Science and Applications: ICCSA 2019 (p. 237). Springer Nature.
Church, K.S., Schmidt, P.J. and Ajayi, K., 2020. Forecast Cloudy-Fair or Stormy Weather:
Cloud Computing Insights and Issues. Journal of Information Systems. pp.0000-0000.
Coleman, S., Secker, A. and Birch, A., 2020, May. Architecture of a Scalable, Secure and
Resilient Translation Platform for Multilingual News Media. In Proceedings of the 1st
International Workshop on Language Technology Platforms (pp. 16-21).
Li, L. and et.al., 2019. Machine-learning reprogrammable metasurface imager. Nature
communications. 10(1). pp.1-8.
Moghaddam, D.C., 2020. Developing Cloud Computing Infrastructures in Developing Countries
in Asia (Doctoral dissertation, Walden University).
Munir, S. and Jami, S.I., 2020. Current trends in cloud computing. Indian Journal of Science and
Technology. 13(24). pp.2418-2435.
Ochara, N.M., 2020. Assimilation of Cloud Computing in Business Continuity Management for
Container Terminal Operations in South Africa. Available at SSRN 3560745.
Shrestha, S., 2019. Comparing Programming Languages used in AWS Lambda for Serverless
Architecture.
Trudgian, D.C. and Mirzaei, H., 2012. Cloud CPFP: a shotgun proteomics data analysis pipeline
using cloud and high performance computing. Journal of proteome research. 11(12).
pp.6282-6290.
Yang, Q., Liu, Y. and Tong, Y., 2019. Federated machine learning: Concept and
applications. ACM Transactions on Intelligent Systems and Technology (TIST). 10(2).
pp.1-19.
82
Book and Journals
Backes, J. and et.al., 2019, July. Reachability analysis for AWS-based networks. In International
Conference on Computer Aided Verification (pp. 231-241). Springer, Cham.
Bai, J., Jhaney, I. and Wells, J., 2019. Developing a Reproducible Microbiome Data Analysis
Pipeline Using the Amazon Web Services Cloud for a Cancer Research Group: Proof-of-
Concept Study. JMIR medical informatics. 7(4). p.e14667.
Basu, K., Hamdullah, A. and Ball, F., 2020, June. Architecture of a Cloud-based Fault-Tolerant
Control Platform for improving the QoS of Social Multimedia Applications on SD-WAN.
In 2020 13th International Conference on Communications (COMM) (pp. 495-500).
IEEE.
Buure, O., 2020. Challenges in moving to cloud computing environment: case Finnish
teleoperator.
Choudhary, B. and et.al., 2020, January. Case Study: Use of AWS Lambda for Building a
Serverless Chat. In Proceeding of International Conference on Computational Science
and Applications: ICCSA 2019 (p. 237). Springer Nature.
Choudhary, B., Pophale, C. and Sonawani, S.S., 2020, January. Case Study: Use of AWS
Lambda for Building a Serverless Chat. In Proceeding of International Conference on
Computational Science and Applications: ICCSA 2019 (p. 237). Springer Nature.
Church, K.S., Schmidt, P.J. and Ajayi, K., 2020. Forecast Cloudy-Fair or Stormy Weather:
Cloud Computing Insights and Issues. Journal of Information Systems. pp.0000-0000.
Coleman, S., Secker, A. and Birch, A., 2020, May. Architecture of a Scalable, Secure and
Resilient Translation Platform for Multilingual News Media. In Proceedings of the 1st
International Workshop on Language Technology Platforms (pp. 16-21).
Li, L. and et.al., 2019. Machine-learning reprogrammable metasurface imager. Nature
communications. 10(1). pp.1-8.
Moghaddam, D.C., 2020. Developing Cloud Computing Infrastructures in Developing Countries
in Asia (Doctoral dissertation, Walden University).
Munir, S. and Jami, S.I., 2020. Current trends in cloud computing. Indian Journal of Science and
Technology. 13(24). pp.2418-2435.
Ochara, N.M., 2020. Assimilation of Cloud Computing in Business Continuity Management for
Container Terminal Operations in South Africa. Available at SSRN 3560745.
Shrestha, S., 2019. Comparing Programming Languages used in AWS Lambda for Serverless
Architecture.
Trudgian, D.C. and Mirzaei, H., 2012. Cloud CPFP: a shotgun proteomics data analysis pipeline
using cloud and high performance computing. Journal of proteome research. 11(12).
pp.6282-6290.
Yang, Q., Liu, Y. and Tong, Y., 2019. Federated machine learning: Concept and
applications. ACM Transactions on Intelligent Systems and Technology (TIST). 10(2).
pp.1-19.
82
1 out of 82
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.