Data Science for Business: Itineract Travel Co Report Analysis
VerifiedAdded on 2023/01/13
|21
|4318
|23
Report
AI Summary
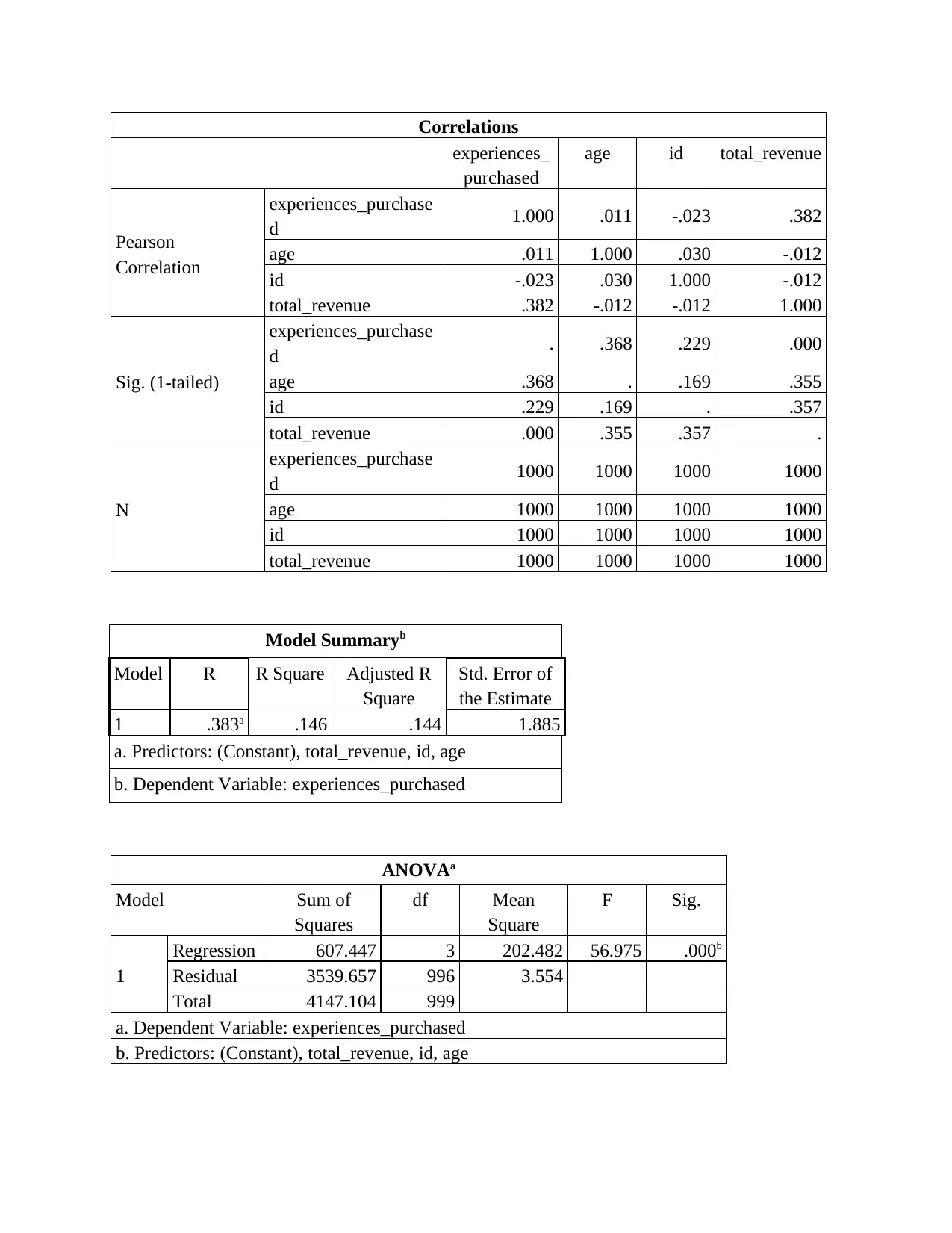
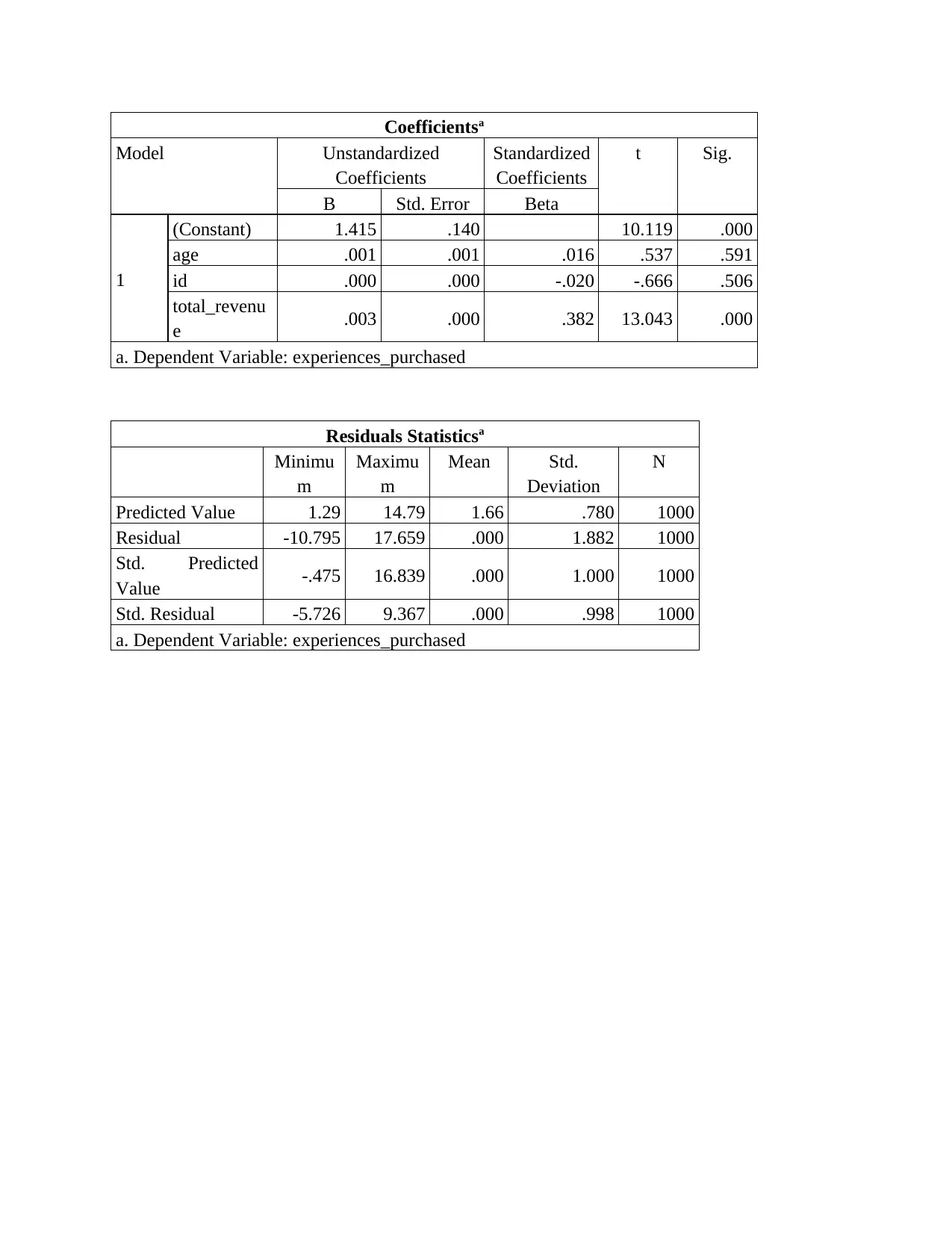
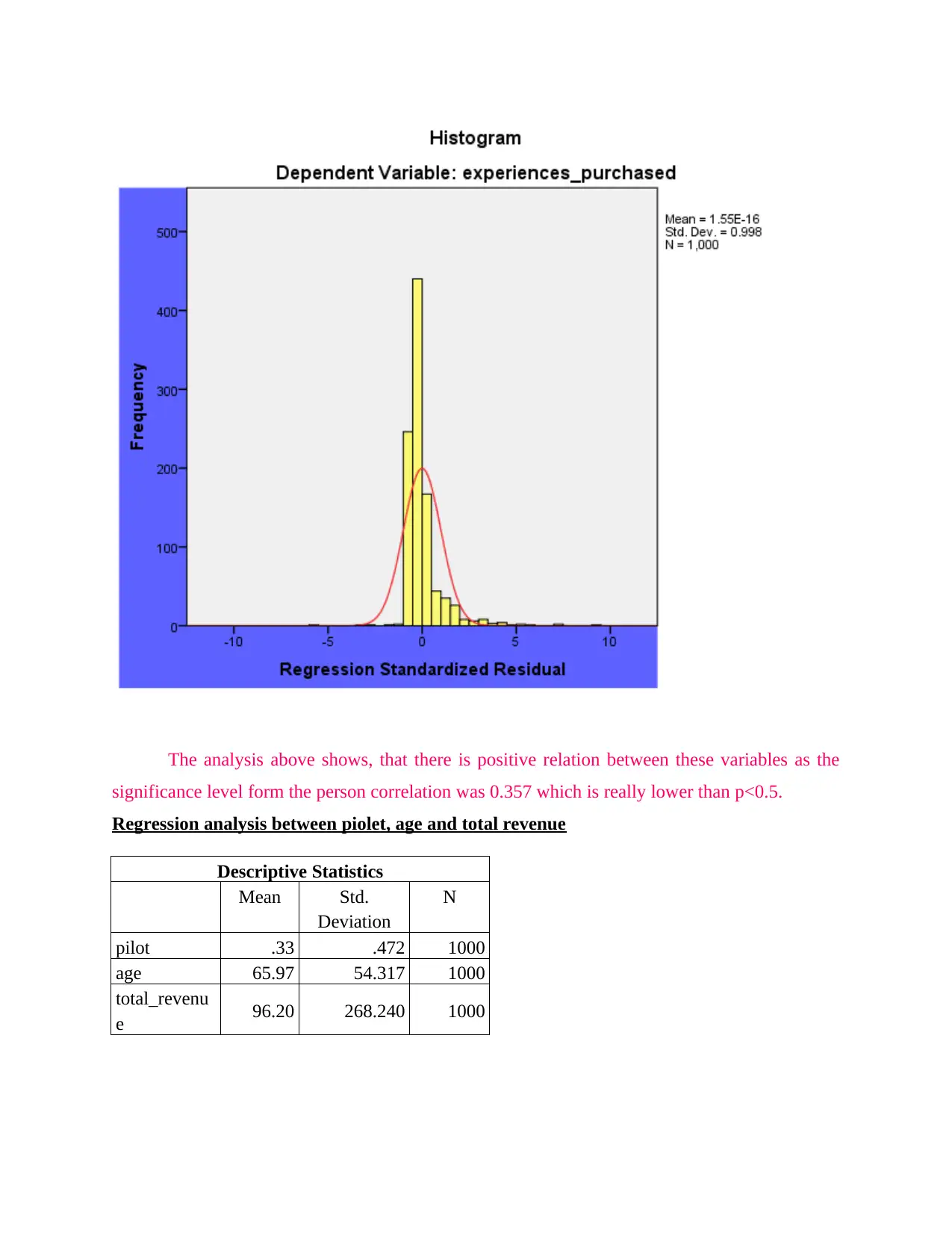
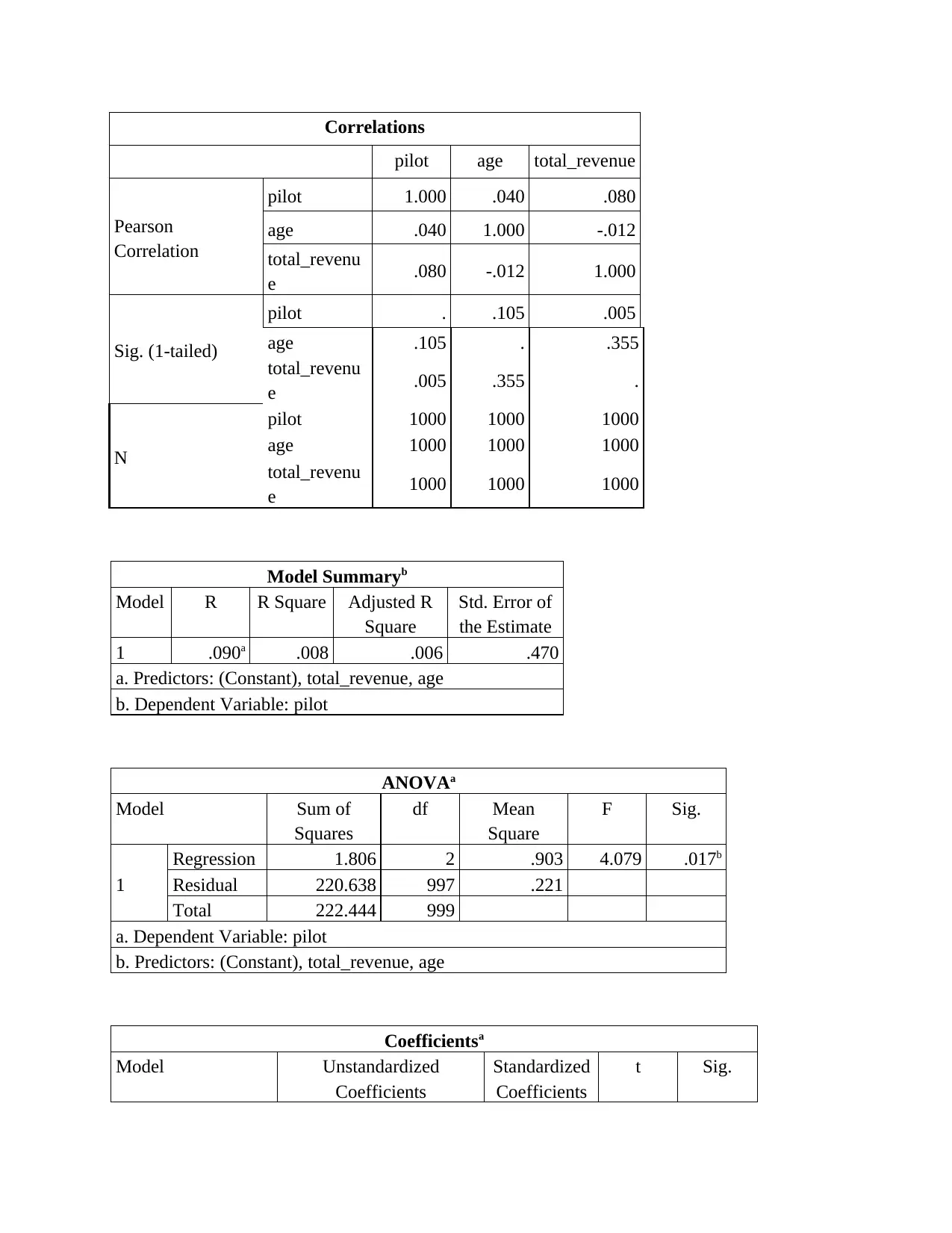
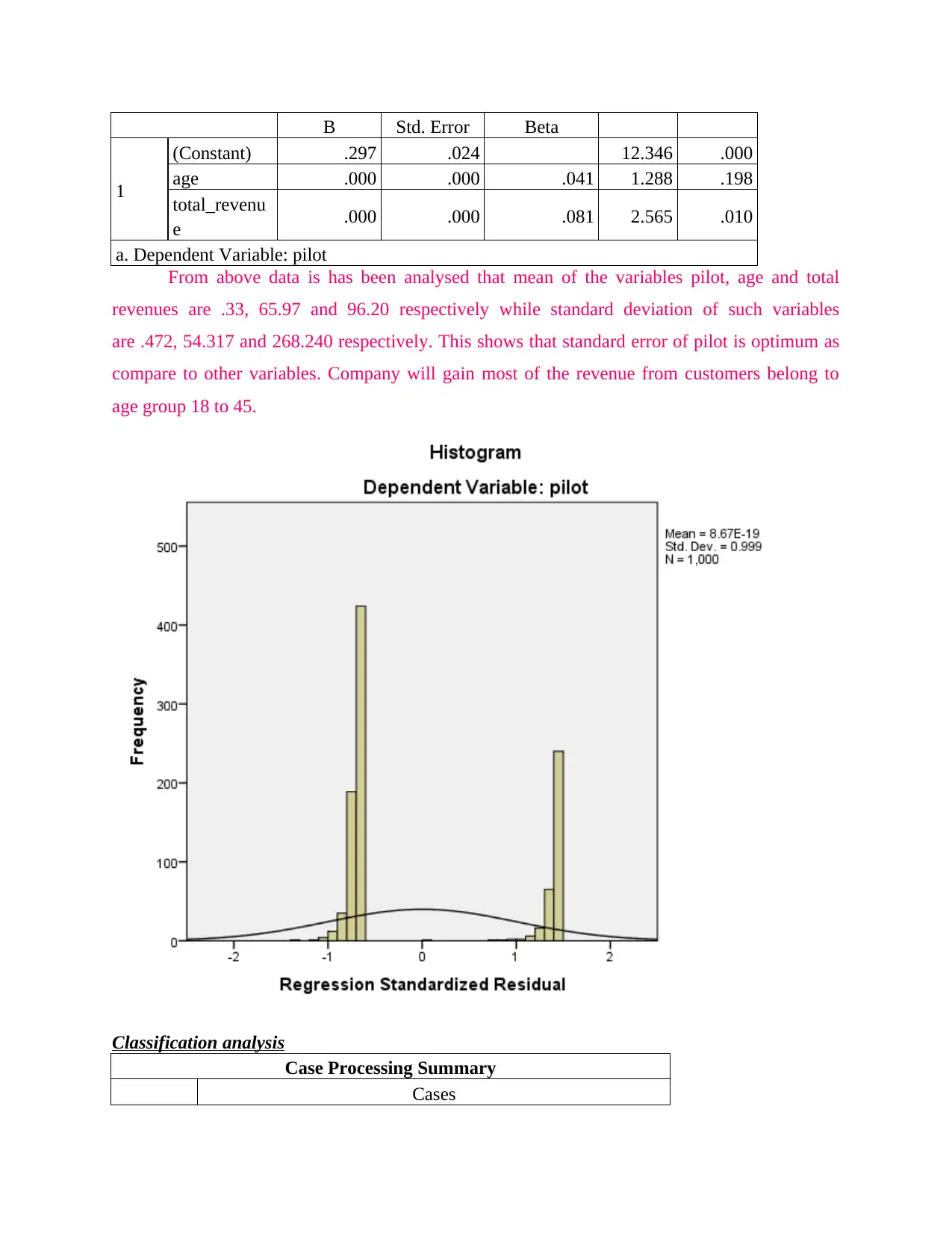
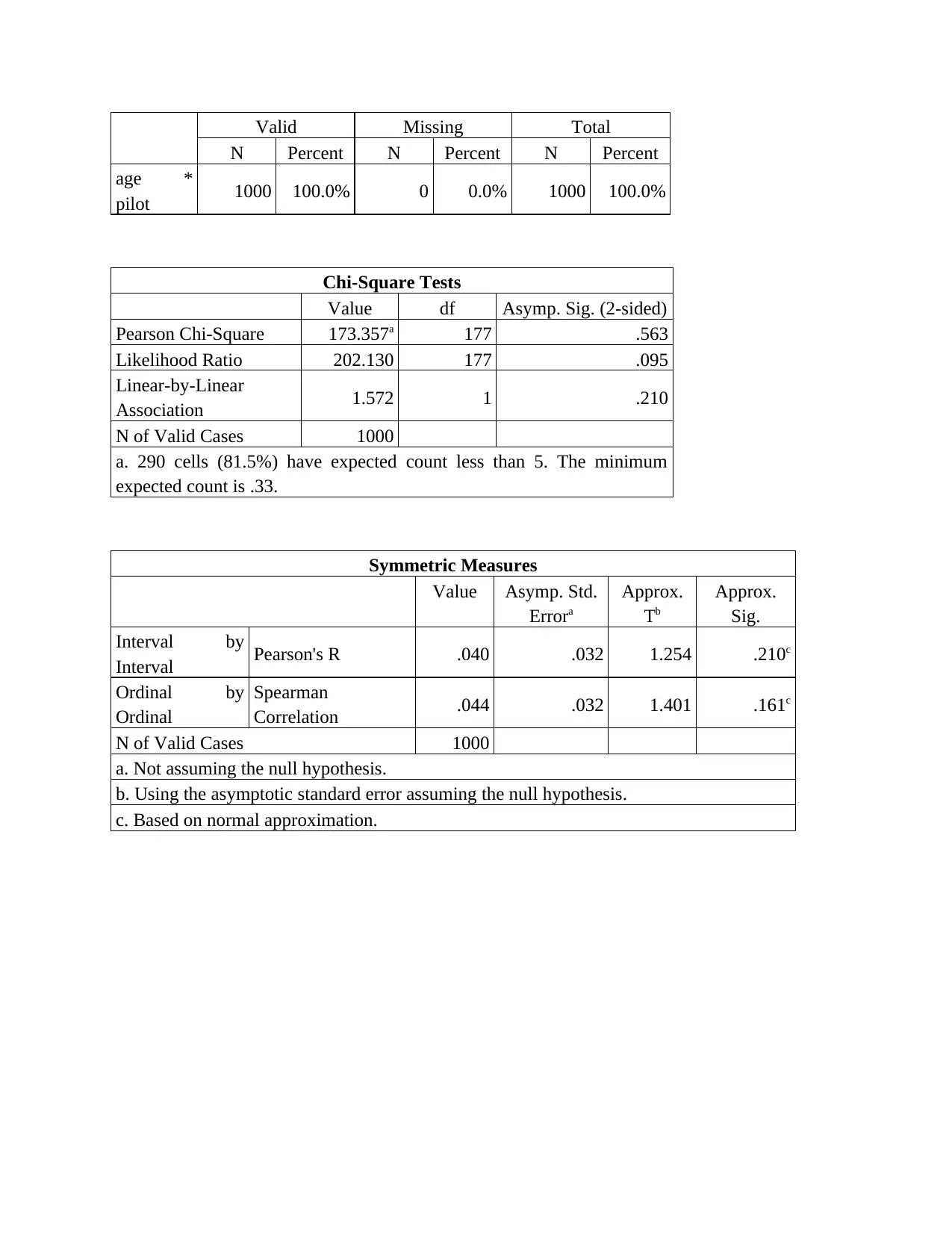
This report presents a data science analysis of customer data from Itineract Travel Co, a company offering travel experiences. The analysis begins with an assessment of the briefing note, outlining the importance of data science in making informed decisions. The investigation involves exploratory data analysis (EDA) to identify trends and patterns in customer behavior, followed by inferential statistics like bootstrap analysis to quantify confidence intervals. Regression models are used to determine the satisfaction of customers visiting specific destinations. The report includes descriptive statistics, correlation analysis, and classification analysis to derive meaningful insights. Ethical and security considerations are also addressed, ensuring responsible handling of customer data. The findings provide recommendations for improving customer experience and optimizing business strategies, including the use of data science techniques for targeted recommendations. The report concludes by presenting potential solutions for the company.






1 out of 21
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.