Report on Itineract Travel Co: Data Analysis and Recommendations
VerifiedAdded on 2023/01/06
|18
|4121
|34
Report
AI Summary
This report focuses on the data analysis conducted for Itineract Travel Co, addressing the company's searchability challenge. The analysis utilizes customer data, including age, experiences purchased, and total revenue, to understand customer behavior and preferences. The report employs various statistical methods, such as descriptive statistics, correlation analysis, and regression models, to identify key relationships and patterns within the data. It examines the impact of different variables on customer satisfaction and revenue generation. Furthermore, the report delves into the ethical and security considerations associated with handling customer data, emphasizing the importance of protecting personal information. The findings are presented with recommendations aimed at improving the company's searchability, enhancing customer experience, and ensuring ethical data handling practices. The report includes an appendix with detailed statistical methodologies and references to support the analysis.

Principles of Data Science
for Business
for Business
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Contents
Section 1......................................................................................................................................3
Section 2......................................................................................................................................4
Section 3......................................................................................................................................5
Section 4:...................................................................................................................................13
Section 5....................................................................................................................................14
Report Appendix: Statistics and Methodology:.........................................................................15
REFERENCES............................................................................................................................18
Section 1......................................................................................................................................3
Section 2......................................................................................................................................4
Section 3......................................................................................................................................5
Section 4:...................................................................................................................................13
Section 5....................................................................................................................................14
Report Appendix: Statistics and Methodology:.........................................................................15
REFERENCES............................................................................................................................18

ITINERACT TRAVEL CO – SEARCHABILITY CHALLENGE:
REPORT & RECOMMENDATIONS
Section 1
Data studies grow to be one of the important aspect that aid in making different important
outcomes which are useful for successful decision making. Successful programming specialists
now understand they need to master the traditional skills in vast volumes of data processing, data
storage and coding (Green, 2020). Data scientists need to track the full extent of the data science
growth cycle and also have a degree of freedom and awareness to maximise returns for those
organisations in every phase of finding useful knowledge. Data scientists need to be informed
and concentrated on performance, with outstanding industry-specific experience and
communications abilities that allow for confirmation of the scientific findings of their multi-
professional colleagues. We have a strong scientific track record in data analysis, processing and
machine modelling focus on statistics and linear mechanics and computing skills. Customer
information from the business report for the last 6 months was retrieved and exchanged in the
associated excel package. Every day enterprises deal with gigabytes and yottabytes of structured
and binary files in a world that increasingly becomes a distributed space. Emerging technologies
offers cost savings and a greater computing space to store sensitive information. For each user,
the extract includes details about their age, ethnicity, preferred reason, amount of bought
encounters, overall consumer sales, and whether they were chosen for the pilot or not. The
business provides people the ability to embark on important travel journeys that will transform
the world as a safer environment. This company was founded only five years ago. Itineract travel
co offering more than 200 visitor experience for a huge group of customers. Therefore, the
Itineract site has a fine line to ensure a pleasant user service.
Hopefully, it is necessary to show client's most suitable experience and then the least viable must
be to make visitors almost pleasant. This increases the difficulty of selecting products perfect for
wants and wishes. Itineract Travel organization needs to create and maintain a state-of-the-art
advisory system and create an internal data analysis team if a specific collection of details is
verified. Considering the above-mentioned business susceptibility to various political reasons,
such a set of guidelines must be planned and regulated with caution. The alternative methods to
making decisions provide a number of criteria for decisions to be made. Strategic decision-
making is also important for business success. As a data analyst in the company of digital
REPORT & RECOMMENDATIONS
Section 1
Data studies grow to be one of the important aspect that aid in making different important
outcomes which are useful for successful decision making. Successful programming specialists
now understand they need to master the traditional skills in vast volumes of data processing, data
storage and coding (Green, 2020). Data scientists need to track the full extent of the data science
growth cycle and also have a degree of freedom and awareness to maximise returns for those
organisations in every phase of finding useful knowledge. Data scientists need to be informed
and concentrated on performance, with outstanding industry-specific experience and
communications abilities that allow for confirmation of the scientific findings of their multi-
professional colleagues. We have a strong scientific track record in data analysis, processing and
machine modelling focus on statistics and linear mechanics and computing skills. Customer
information from the business report for the last 6 months was retrieved and exchanged in the
associated excel package. Every day enterprises deal with gigabytes and yottabytes of structured
and binary files in a world that increasingly becomes a distributed space. Emerging technologies
offers cost savings and a greater computing space to store sensitive information. For each user,
the extract includes details about their age, ethnicity, preferred reason, amount of bought
encounters, overall consumer sales, and whether they were chosen for the pilot or not. The
business provides people the ability to embark on important travel journeys that will transform
the world as a safer environment. This company was founded only five years ago. Itineract travel
co offering more than 200 visitor experience for a huge group of customers. Therefore, the
Itineract site has a fine line to ensure a pleasant user service.
Hopefully, it is necessary to show client's most suitable experience and then the least viable must
be to make visitors almost pleasant. This increases the difficulty of selecting products perfect for
wants and wishes. Itineract Travel organization needs to create and maintain a state-of-the-art
advisory system and create an internal data analysis team if a specific collection of details is
verified. Considering the above-mentioned business susceptibility to various political reasons,
such a set of guidelines must be planned and regulated with caution. The alternative methods to
making decisions provide a number of criteria for decisions to be made. Strategic decision-
making is also important for business success. As a data analyst in the company of digital
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

advertising and analytics, diverse decision decisions must be implemented according to the
values, risk patterns and aspirations of the decision-makers' potential results. It was found that
the core practical property of the customers’ willingness to travel particular location, to have
similar characteristics. Three main features are a range of choices or expectations, choice
criterion and selection techniques set. The work includes preparation of data set, detailed
analysis of experimental information and numerical assessment. As well as different kinds of
SPSS tests has been applied and interpreted in order to find out possible outcome.
Section 2
The research began by introducing the details in a way that makes for the study of explorative
data (EDA). It involved the reorganisation of data and any data analysis we felt could also cause
partiality. As the Itineract Travel Company's market expansion plans rely on raising the size of
visitors to the website and the service offered to thousands of customers, it would become
increasingly complicated to coordinate right experiences with each potential client, while
simultaneously finding time to achieving the organisation 's success objectives. EDA is the
"method for standardising the description of all variables by means of data visualisation”. As a
consulting firm, managers have described patterns across EDA showing how the consumer's
demand for travel has changed and potential reasons that these customers would like to pursue.
The result was a large amount of outstanding visualisations, showing how overtime emerged as a
traffic epidemic (Grus, 2019). The research then focused as to whether the collected counts
suited an existing statistical trend in which to base further analytics. It is also assessed that the
values were not evenly distributed, and the results were similar to the Poisson test. This helped
consulting firm to consider what kind of observational numbers, manager will be doing to make
the right decision. Afterwards, inferential figures were rendered as a bootstrap. It presented
managers with the opportunity to measure trust intervals and determine if statistically meaningful
differences are identified, whether or not these differences were the outcome of a transition, or
may have existed between consumer expectations and the target.
Ultimately, they used these results to explore alternatives to the challenges and suggested data
analysis techniques that can be tailored to their implementation and efficiency. The common set
of data associated with consumer service like age, the gender inside 1000 measurements, the
favourite explanation for the service ranking. In addition, the data set also contains the ID code
values, risk patterns and aspirations of the decision-makers' potential results. It was found that
the core practical property of the customers’ willingness to travel particular location, to have
similar characteristics. Three main features are a range of choices or expectations, choice
criterion and selection techniques set. The work includes preparation of data set, detailed
analysis of experimental information and numerical assessment. As well as different kinds of
SPSS tests has been applied and interpreted in order to find out possible outcome.
Section 2
The research began by introducing the details in a way that makes for the study of explorative
data (EDA). It involved the reorganisation of data and any data analysis we felt could also cause
partiality. As the Itineract Travel Company's market expansion plans rely on raising the size of
visitors to the website and the service offered to thousands of customers, it would become
increasingly complicated to coordinate right experiences with each potential client, while
simultaneously finding time to achieving the organisation 's success objectives. EDA is the
"method for standardising the description of all variables by means of data visualisation”. As a
consulting firm, managers have described patterns across EDA showing how the consumer's
demand for travel has changed and potential reasons that these customers would like to pursue.
The result was a large amount of outstanding visualisations, showing how overtime emerged as a
traffic epidemic (Grus, 2019). The research then focused as to whether the collected counts
suited an existing statistical trend in which to base further analytics. It is also assessed that the
values were not evenly distributed, and the results were similar to the Poisson test. This helped
consulting firm to consider what kind of observational numbers, manager will be doing to make
the right decision. Afterwards, inferential figures were rendered as a bootstrap. It presented
managers with the opportunity to measure trust intervals and determine if statistically meaningful
differences are identified, whether or not these differences were the outcome of a transition, or
may have existed between consumer expectations and the target.
Ultimately, they used these results to explore alternatives to the challenges and suggested data
analysis techniques that can be tailored to their implementation and efficiency. The common set
of data associated with consumer service like age, the gender inside 1000 measurements, the
favourite explanation for the service ranking. In addition, the data set also contains the ID code
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
that was allocated to each person and group of customers visiting a particular location in that
time span according to their desires and specifications. Furthermore, the whole evaluation also
involves the overall revenue produced from a single location whether each consumer was chosen
for the pilot or not. The information pertaining to Itineract was first divided into dependent
variable and independent variable in addition to make clearer outcomes from all the research so
that findings would be beneficial. In addition, descriptive test and association is calculated
between, experiences acquired, age, Id, overall income. Furthermore, correlation study is
conducted between pilot, age and overall sales.
Section 3
Distinct types of regression models are being used to conduct precise and effective research and
to evaluate the effective information that help to decide whether the consumer visiting a specific
place is happy or not (Daniel, 2019). Analysis of the liner regression is helpful in evaluating the
required values to endorse the correct advice that is performed below in such manner:
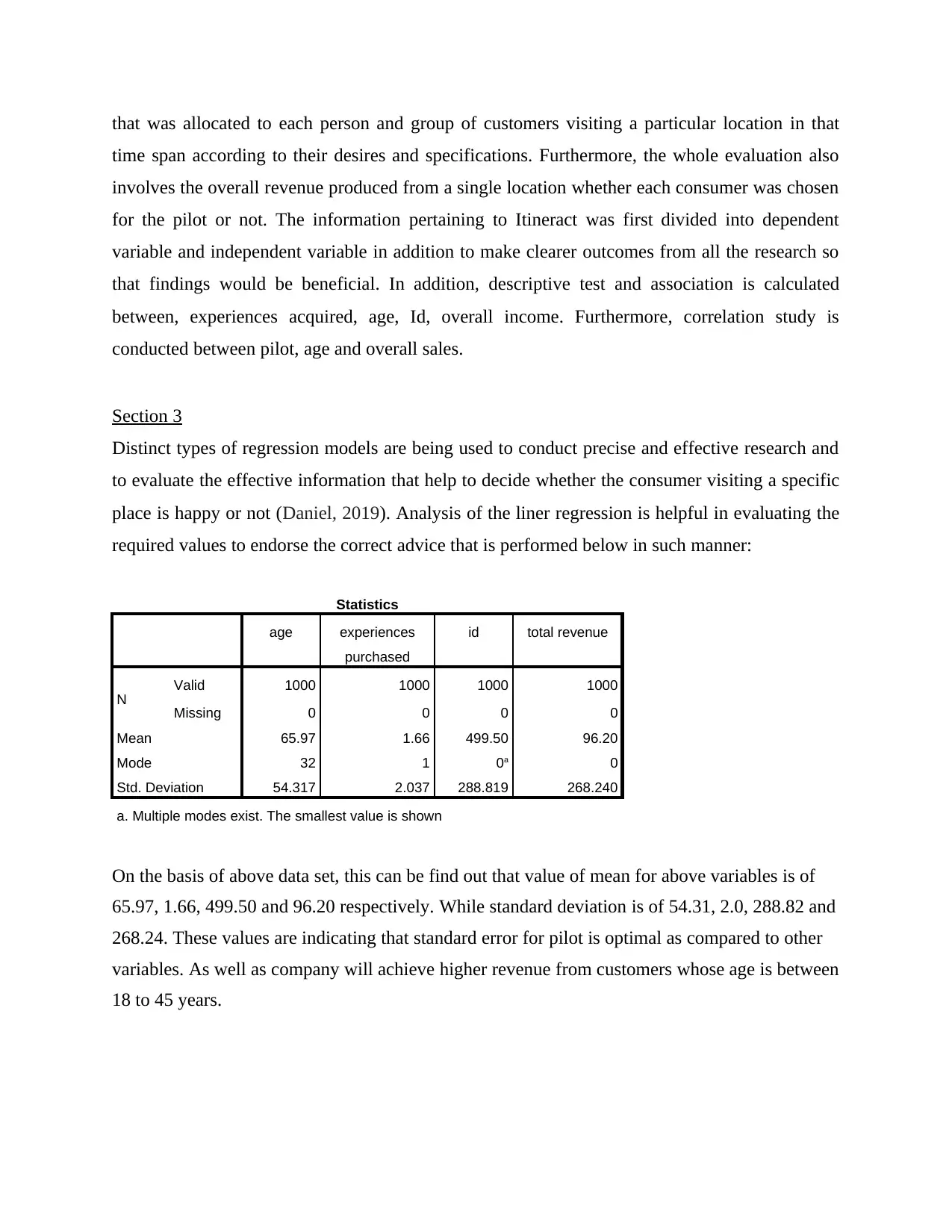
Statistics
age experiences
purchased
id total revenue
N Valid 1000 1000 1000 1000
Missing 0 0 0 0
Mean 65.97 1.66 499.50 96.20
Mode 32 1 0a 0
Std. Deviation 54.317 2.037 288.819 268.240
a. Multiple modes exist. The smallest value is shown
On the basis of above data set, this can be find out that value of mean for above variables is of
65.97, 1.66, 499.50 and 96.20 respectively. While standard deviation is of 54.31, 2.0, 288.82 and
268.24. These values are indicating that standard error for pilot is optimal as compared to other
variables. As well as company will achieve higher revenue from customers whose age is between
18 to 45 years.
time span according to their desires and specifications. Furthermore, the whole evaluation also
involves the overall revenue produced from a single location whether each consumer was chosen
for the pilot or not. The information pertaining to Itineract was first divided into dependent
variable and independent variable in addition to make clearer outcomes from all the research so
that findings would be beneficial. In addition, descriptive test and association is calculated
between, experiences acquired, age, Id, overall income. Furthermore, correlation study is
conducted between pilot, age and overall sales.
Section 3
Distinct types of regression models are being used to conduct precise and effective research and
to evaluate the effective information that help to decide whether the consumer visiting a specific
place is happy or not (Daniel, 2019). Analysis of the liner regression is helpful in evaluating the
required values to endorse the correct advice that is performed below in such manner:
Statistics
age experiences
purchased
id total revenue
N Valid 1000 1000 1000 1000
Missing 0 0 0 0
Mean 65.97 1.66 499.50 96.20
Mode 32 1 0a 0
Std. Deviation 54.317 2.037 288.819 268.240
a. Multiple modes exist. The smallest value is shown
On the basis of above data set, this can be find out that value of mean for above variables is of
65.97, 1.66, 499.50 and 96.20 respectively. While standard deviation is of 54.31, 2.0, 288.82 and
268.24. These values are indicating that standard error for pilot is optimal as compared to other
variables. As well as company will achieve higher revenue from customers whose age is between
18 to 45 years.
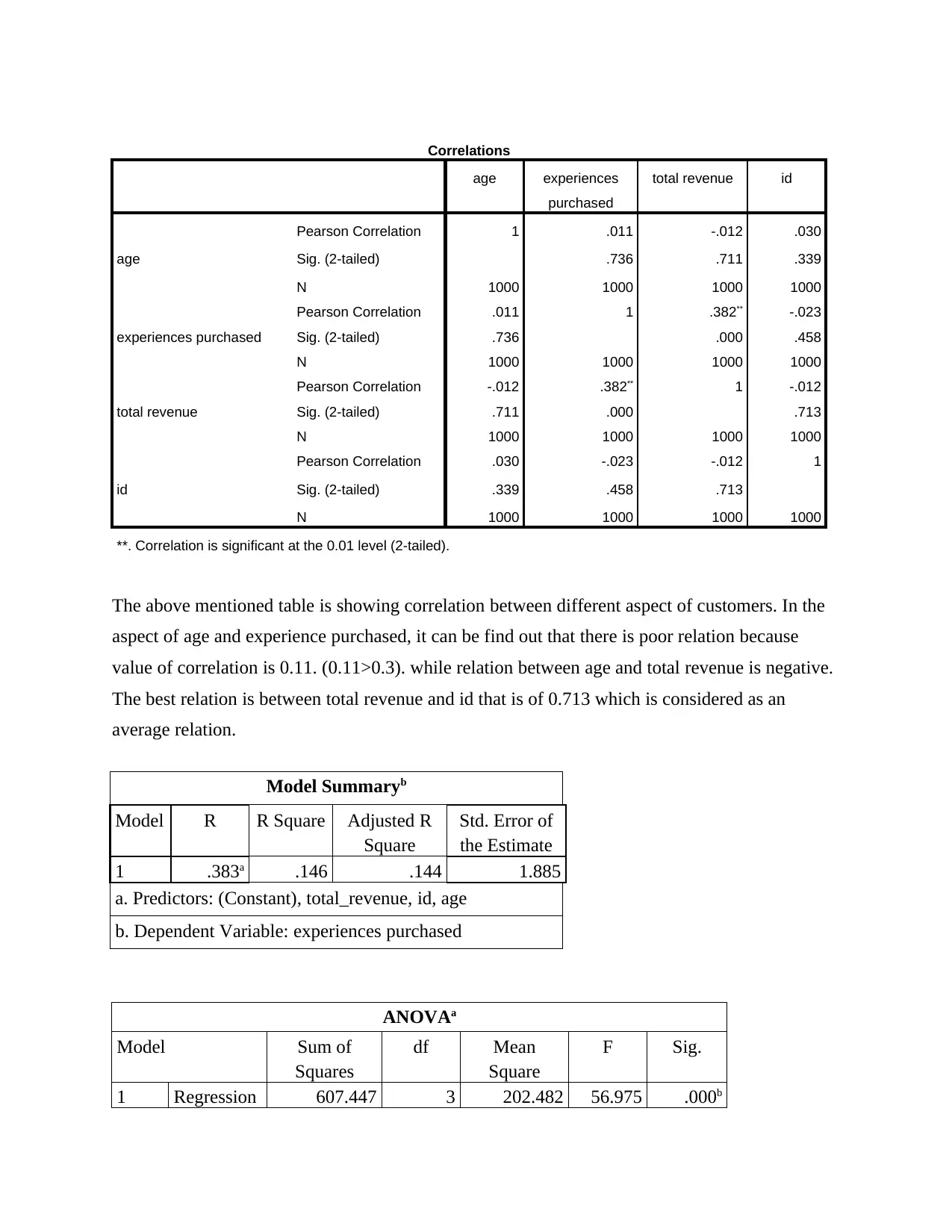
Correlations
age experiences
purchased
total revenue id
age
Pearson Correlation 1 .011 -.012 .030
Sig. (2-tailed) .736 .711 .339
N 1000 1000 1000 1000
experiences purchased
Pearson Correlation .011 1 .382** -.023
Sig. (2-tailed) .736 .000 .458
N 1000 1000 1000 1000
total revenue
Pearson Correlation -.012 .382** 1 -.012
Sig. (2-tailed) .711 .000 .713
N 1000 1000 1000 1000
id
Pearson Correlation .030 -.023 -.012 1
Sig. (2-tailed) .339 .458 .713
N 1000 1000 1000 1000
**. Correlation is significant at the 0.01 level (2-tailed).
The above mentioned table is showing correlation between different aspect of customers. In the
aspect of age and experience purchased, it can be find out that there is poor relation because
value of correlation is 0.11. (0.11>0.3). while relation between age and total revenue is negative.
The best relation is between total revenue and id that is of 0.713 which is considered as an
average relation.
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of
the Estimate
1 .383a .146 .144 1.885
a. Predictors: (Constant), total_revenue, id, age
b. Dependent Variable: experiences purchased
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1 Regression 607.447 3 202.482 56.975 .000b
age experiences
purchased
total revenue id
age
Pearson Correlation 1 .011 -.012 .030
Sig. (2-tailed) .736 .711 .339
N 1000 1000 1000 1000
experiences purchased
Pearson Correlation .011 1 .382** -.023
Sig. (2-tailed) .736 .000 .458
N 1000 1000 1000 1000
total revenue
Pearson Correlation -.012 .382** 1 -.012
Sig. (2-tailed) .711 .000 .713
N 1000 1000 1000 1000
id
Pearson Correlation .030 -.023 -.012 1
Sig. (2-tailed) .339 .458 .713
N 1000 1000 1000 1000
**. Correlation is significant at the 0.01 level (2-tailed).
The above mentioned table is showing correlation between different aspect of customers. In the
aspect of age and experience purchased, it can be find out that there is poor relation because
value of correlation is 0.11. (0.11>0.3). while relation between age and total revenue is negative.
The best relation is between total revenue and id that is of 0.713 which is considered as an
average relation.
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of
the Estimate
1 .383a .146 .144 1.885
a. Predictors: (Constant), total_revenue, id, age
b. Dependent Variable: experiences purchased
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1 Regression 607.447 3 202.482 56.975 .000b
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
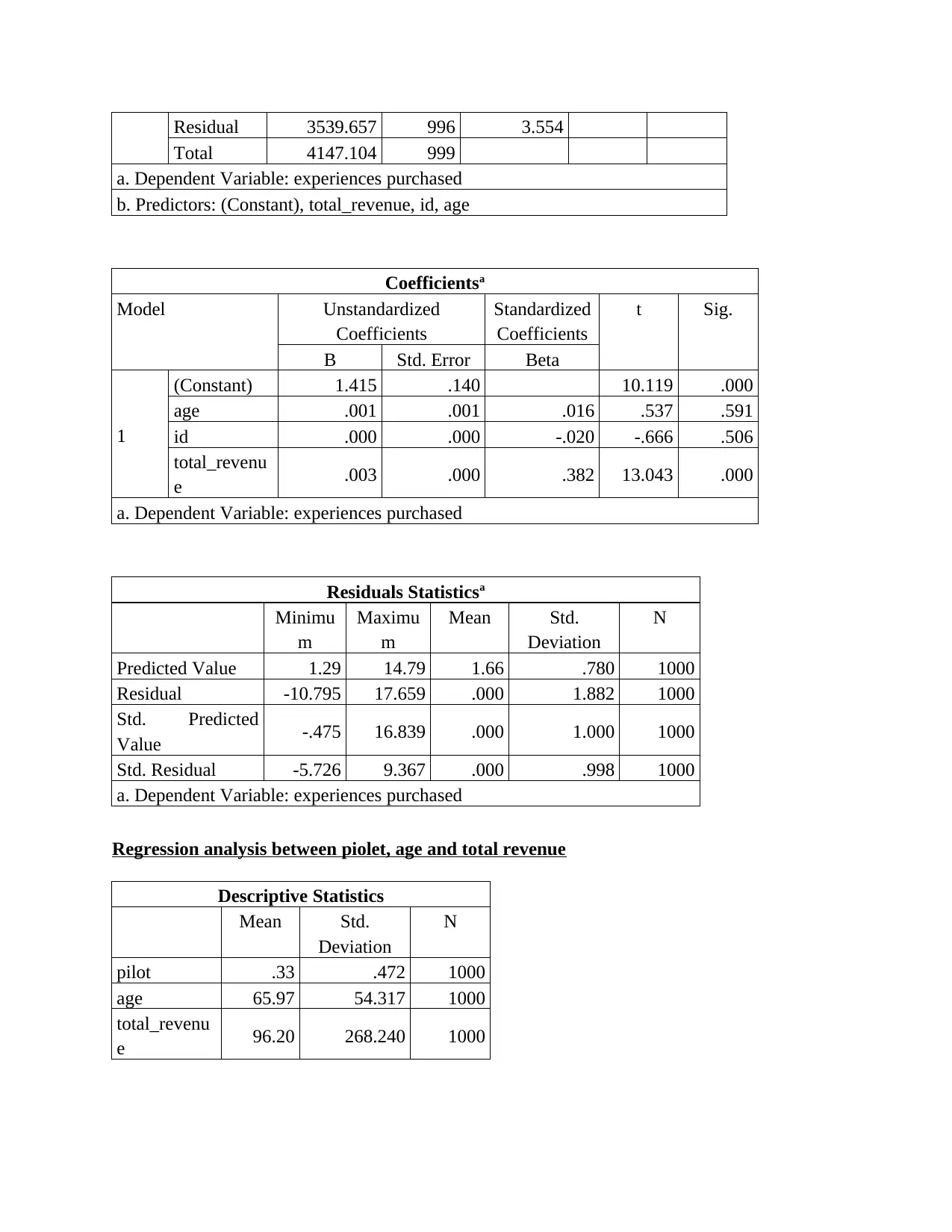
Residual 3539.657 996 3.554
Total 4147.104 999
a. Dependent Variable: experiences purchased
b. Predictors: (Constant), total_revenue, id, age
Coefficientsa
Model Unstandardized
Coefficients
Standardized
Coefficients
t Sig.
B Std. Error Beta
1
(Constant) 1.415 .140 10.119 .000
age .001 .001 .016 .537 .591
id .000 .000 -.020 -.666 .506
total_revenu
e .003 .000 .382 13.043 .000
a. Dependent Variable: experiences purchased
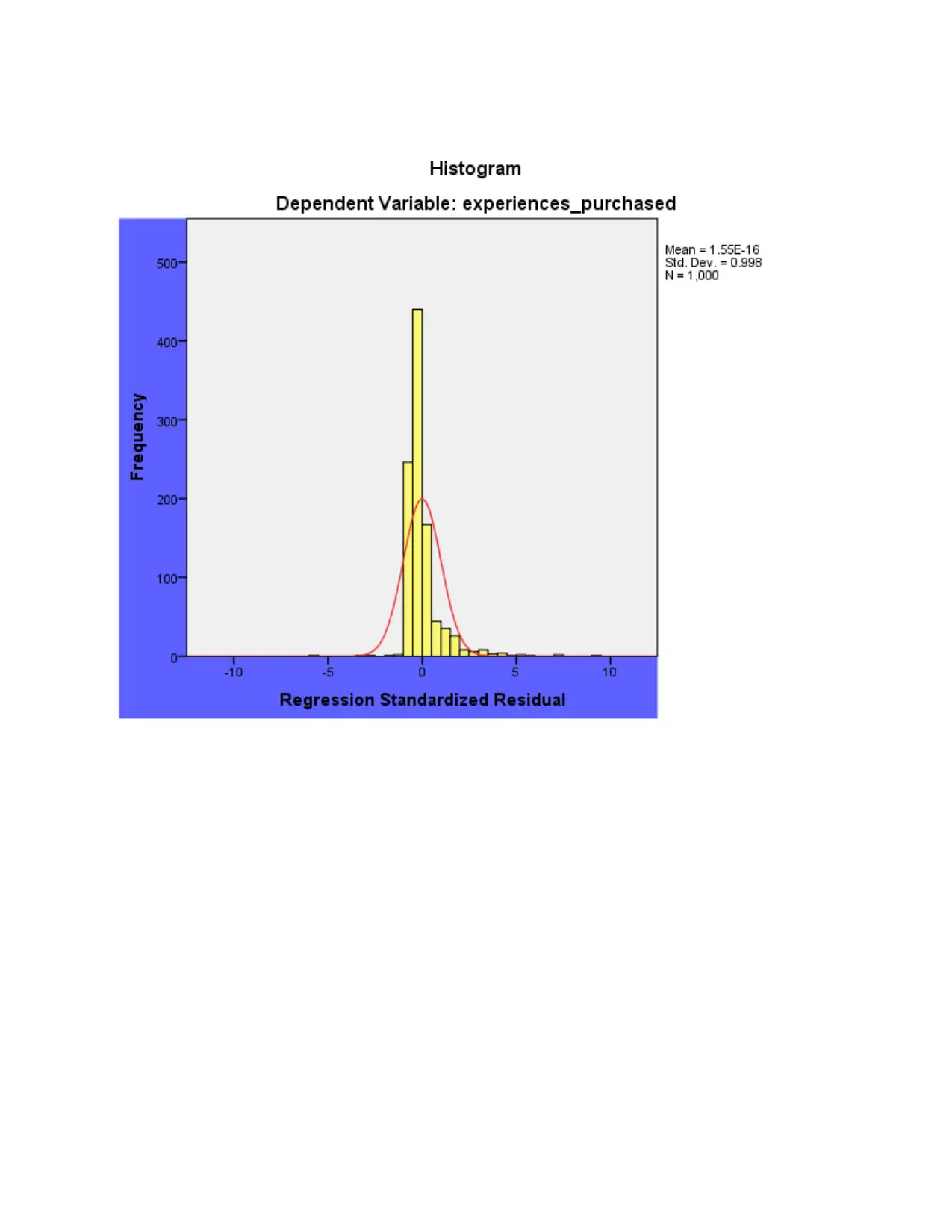
Residuals Statisticsa
Minimu
m
Maximu
m
Mean Std.
Deviation
N
Predicted Value 1.29 14.79 1.66 .780 1000
Residual -10.795 17.659 .000 1.882 1000
Std. Predicted
Value -.475 16.839 .000 1.000 1000
Std. Residual -5.726 9.367 .000 .998 1000
a. Dependent Variable: experiences purchased
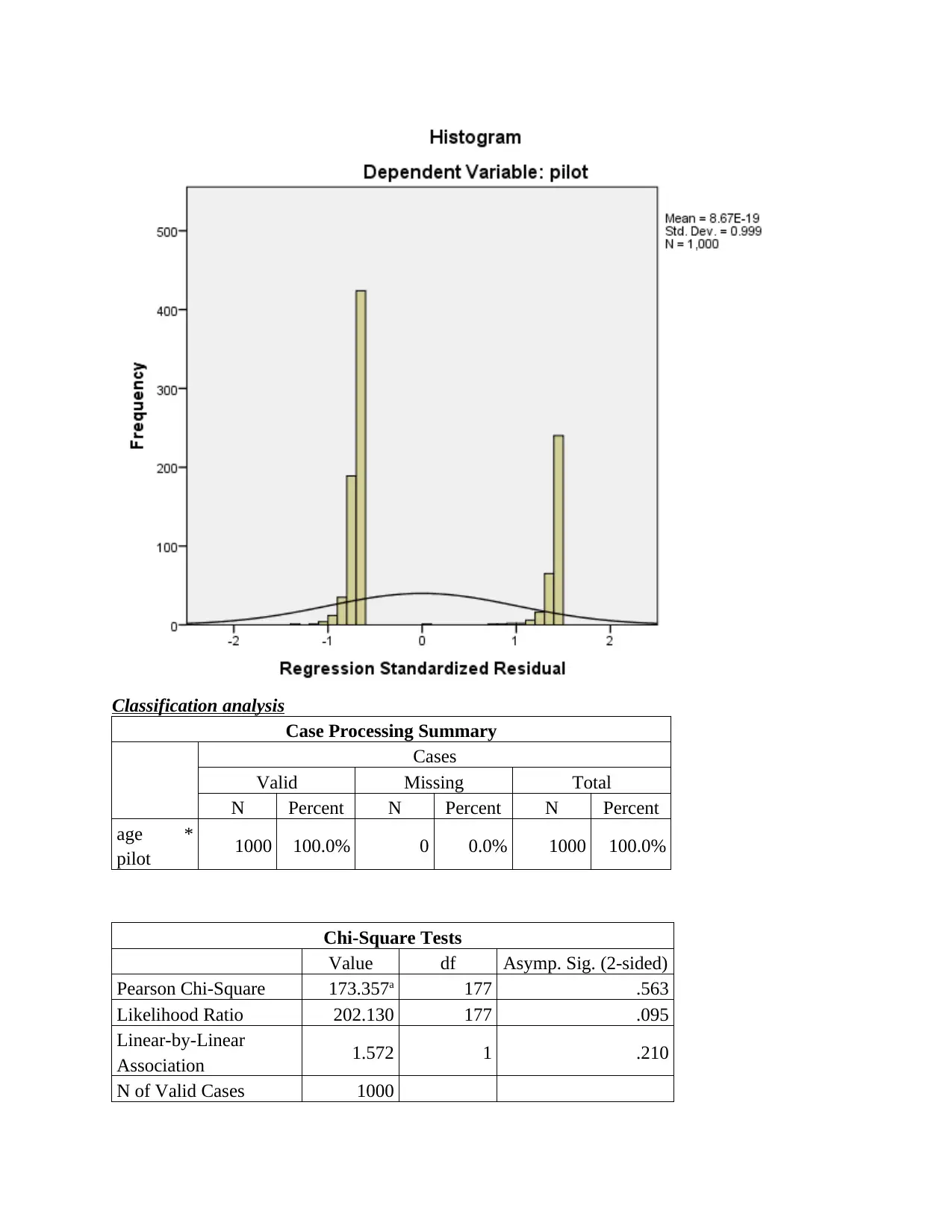
Regression analysis between piolet, age and total revenue
Descriptive Statistics
Mean Std.
Deviation
N
pilot .33 .472 1000
age 65.97 54.317 1000
total_revenu
e 96.20 268.240 1000
Total 4147.104 999
a. Dependent Variable: experiences purchased
b. Predictors: (Constant), total_revenue, id, age
Coefficientsa
Model Unstandardized
Coefficients
Standardized
Coefficients
t Sig.
B Std. Error Beta
1
(Constant) 1.415 .140 10.119 .000
age .001 .001 .016 .537 .591
id .000 .000 -.020 -.666 .506
total_revenu
e .003 .000 .382 13.043 .000
a. Dependent Variable: experiences purchased
Residuals Statisticsa
Minimu
m
Maximu
m
Mean Std.
Deviation
N
Predicted Value 1.29 14.79 1.66 .780 1000
Residual -10.795 17.659 .000 1.882 1000
Std. Predicted
Value -.475 16.839 .000 1.000 1000
Std. Residual -5.726 9.367 .000 .998 1000
a. Dependent Variable: experiences purchased
Regression analysis between piolet, age and total revenue
Descriptive Statistics
Mean Std.
Deviation
N
pilot .33 .472 1000
age 65.97 54.317 1000
total_revenu
e 96.20 268.240 1000
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
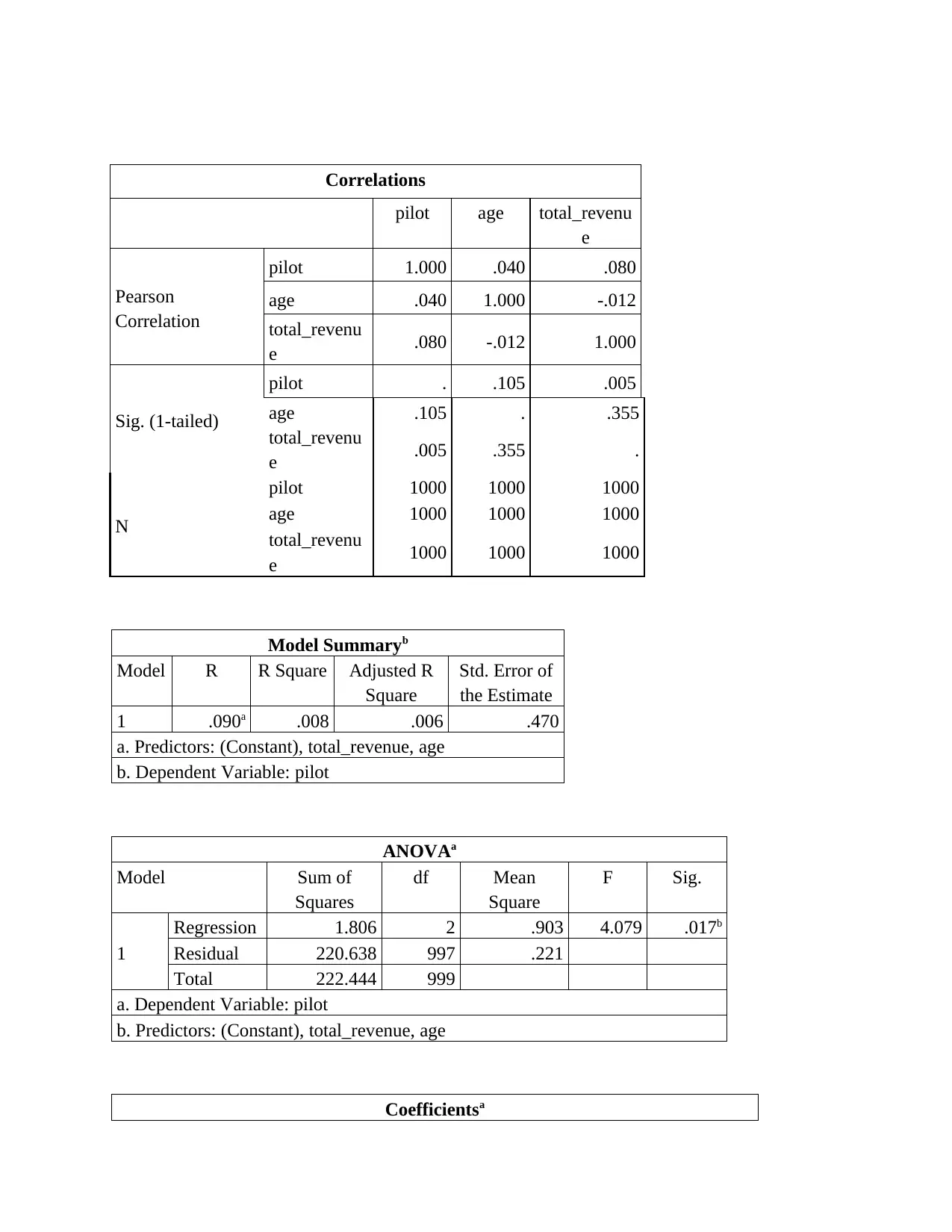
Correlations
pilot age total_revenu
e
Pearson
Correlation
pilot 1.000 .040 .080
age .040 1.000 -.012
total_revenu
e .080 -.012 1.000
Sig. (1-tailed)
pilot . .105 .005
age .105 . .355
total_revenu
e .005 .355 .
N
pilot 1000 1000 1000
age 1000 1000 1000
total_revenu
e 1000 1000 1000
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of
the Estimate
1 .090a .008 .006 .470
a. Predictors: (Constant), total_revenue, age
b. Dependent Variable: pilot
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1
Regression 1.806 2 .903 4.079 .017b
Residual 220.638 997 .221
Total 222.444 999
a. Dependent Variable: pilot
b. Predictors: (Constant), total_revenue, age
Coefficientsa
pilot age total_revenu
e
Pearson
Correlation
pilot 1.000 .040 .080
age .040 1.000 -.012
total_revenu
e .080 -.012 1.000
Sig. (1-tailed)
pilot . .105 .005
age .105 . .355
total_revenu
e .005 .355 .
N
pilot 1000 1000 1000
age 1000 1000 1000
total_revenu
e 1000 1000 1000
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of
the Estimate
1 .090a .008 .006 .470
a. Predictors: (Constant), total_revenue, age
b. Dependent Variable: pilot
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1
Regression 1.806 2 .903 4.079 .017b
Residual 220.638 997 .221
Total 222.444 999
a. Dependent Variable: pilot
b. Predictors: (Constant), total_revenue, age
Coefficientsa
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Classification analysis
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
age *
pilot 1000 100.0% 0 0.0% 1000 100.0%
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 173.357a 177 .563
Likelihood Ratio 202.130 177 .095
Linear-by-Linear
Association 1.572 1 .210
N of Valid Cases 1000
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
age *
pilot 1000 100.0% 0 0.0% 1000 100.0%
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 173.357a 177 .563
Likelihood Ratio 202.130 177 .095
Linear-by-Linear
Association 1.572 1 .210
N of Valid Cases 1000
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
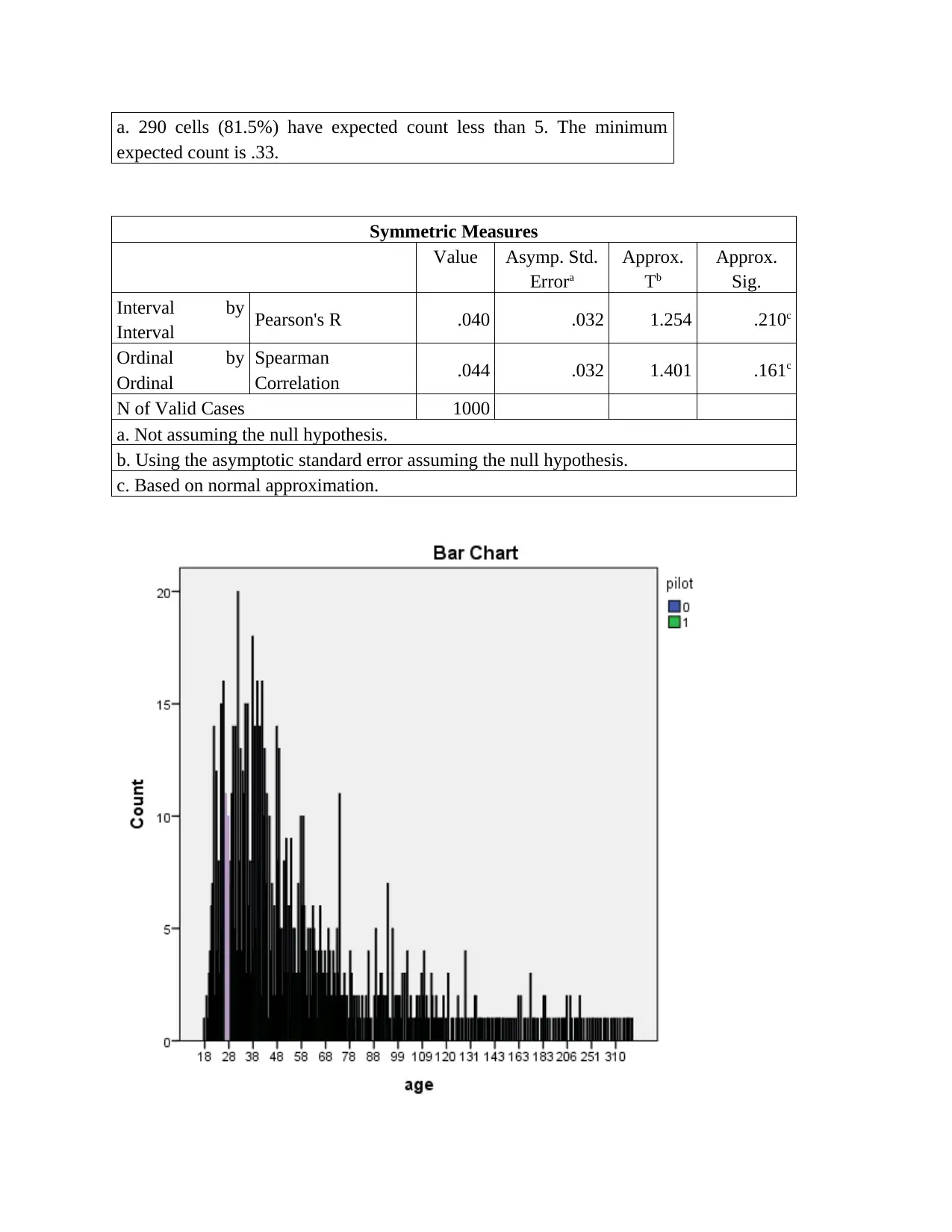
a. 290 cells (81.5%) have expected count less than 5. The minimum
expected count is .33.
Symmetric Measures
Value Asymp. Std.
Errora
Approx.
Tb
Approx.
Sig.
Interval by
Interval Pearson's R .040 .032 1.254 .210c
Ordinal by
Ordinal
Spearman
Correlation .044 .032 1.401 .161c
N of Valid Cases 1000
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
expected count is .33.
Symmetric Measures
Value Asymp. Std.
Errora
Approx.
Tb
Approx.
Sig.
Interval by
Interval Pearson's R .040 .032 1.254 .210c
Ordinal by
Ordinal
Spearman
Correlation .044 .032 1.401 .161c
N of Valid Cases 1000
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
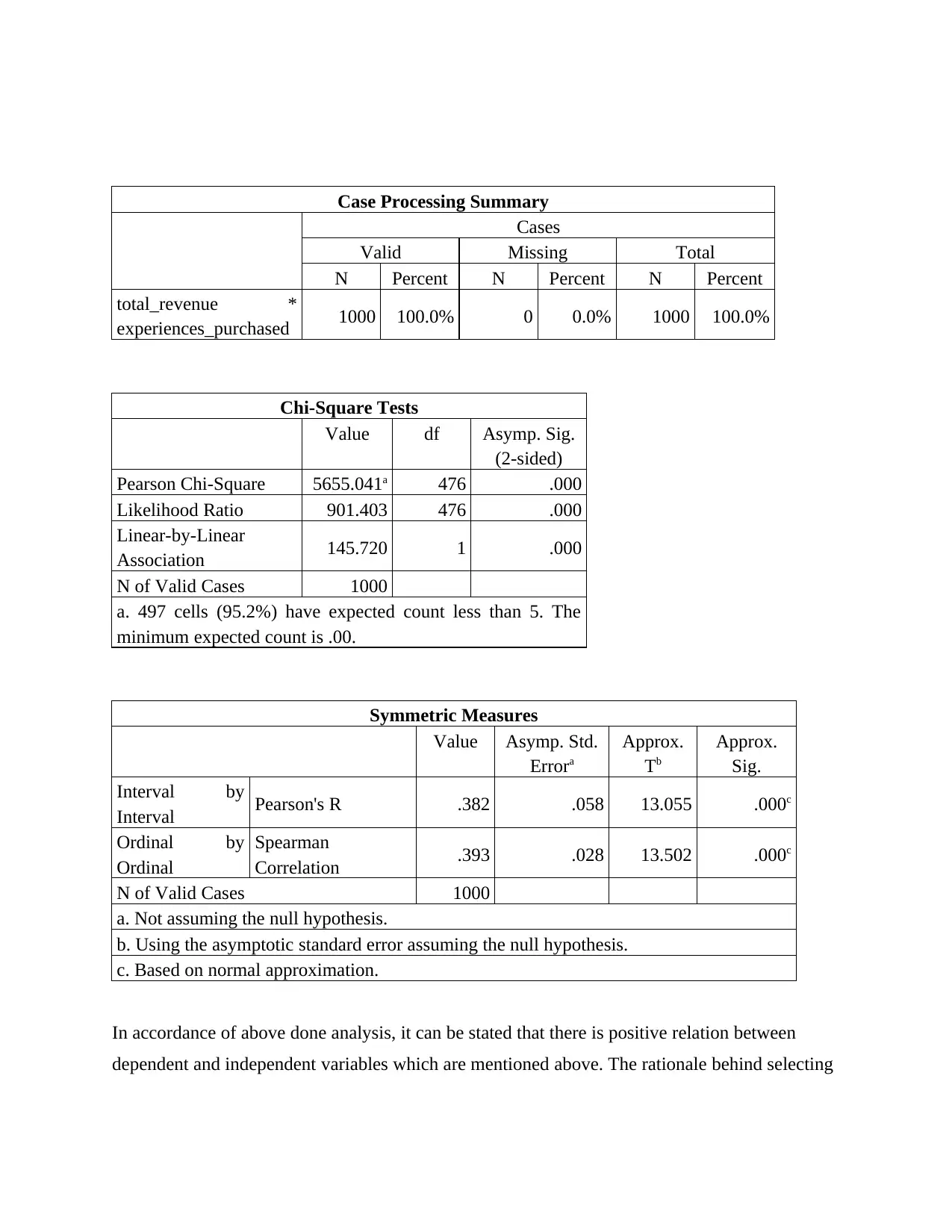
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
total_revenue *
experiences_purchased 1000 100.0% 0 0.0% 1000 100.0%
Chi-Square Tests
Value df Asymp. Sig.
(2-sided)
Pearson Chi-Square 5655.041a 476 .000
Likelihood Ratio 901.403 476 .000
Linear-by-Linear
Association 145.720 1 .000
N of Valid Cases 1000
a. 497 cells (95.2%) have expected count less than 5. The
minimum expected count is .00.
Symmetric Measures
Value Asymp. Std.
Errora
Approx.
Tb
Approx.
Sig.
Interval by
Interval Pearson's R .382 .058 13.055 .000c
Ordinal by
Ordinal
Spearman
Correlation .393 .028 13.502 .000c
N of Valid Cases 1000
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
In accordance of above done analysis, it can be stated that there is positive relation between
dependent and independent variables which are mentioned above. The rationale behind selecting
Cases
Valid Missing Total
N Percent N Percent N Percent
total_revenue *
experiences_purchased 1000 100.0% 0 0.0% 1000 100.0%
Chi-Square Tests
Value df Asymp. Sig.
(2-sided)
Pearson Chi-Square 5655.041a 476 .000
Likelihood Ratio 901.403 476 .000
Linear-by-Linear
Association 145.720 1 .000
N of Valid Cases 1000
a. 497 cells (95.2%) have expected count less than 5. The
minimum expected count is .00.
Symmetric Measures
Value Asymp. Std.
Errora
Approx.
Tb
Approx.
Sig.
Interval by
Interval Pearson's R .382 .058 13.055 .000c
Ordinal by
Ordinal
Spearman
Correlation .393 .028 13.502 .000c
N of Valid Cases 1000
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Based on normal approximation.
In accordance of above done analysis, it can be stated that there is positive relation between
dependent and independent variables which are mentioned above. The rationale behind selecting
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 18
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.