Artificial Intelligence in diabetes Care : Research Paper
VerifiedAdded on 2020/04/15
|43
|11940
|36
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Project: Development of an Artificial Intelligence Chat Bot for
Diabetes Patients
Name
Date
Diabetes Patients
Name
Date
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Abstract
This research paper proposes and develops an artificial intelligence diabetes chatbot that is a
health assistant to diabetic patients. The need for such a chatbot is informed by the tremendous
growth in technology use in health care and the challenges that face patients and physicians n the
effective management of the chronic condition of diabetes. Patients rarely have adequate
qualitative time with their doctors, with countries such as the US averaging just over one hour of
direct contact by patients with a physician. Yet counties continue sending significant amounts of
its GDP on health care, with the US using 17% of its GDP on health care for its citizens. Further,
diabetes management requires a lot of self-management by the patient to attain healthy lifestyles.
Some of the challenges faced in effective management of diabetes include not following
recommended lifestyles, high costs of insurance and payments for medicines, failure to follow
treatment regimes, and failure to monitor blood glucose levels regularly. Further, high costs and
compelling personal reasons, along with few doctor visits and doctor patient time have added to
the challenge of effective management of diabetes. Using the Internet and artificial intelligence
principles, this paper proposes the use of a chatbot that is developed with a library to become
diabetes patients’ personal assistants. A simple chatbot was built using the C++ language, using
the principles of NLP and word processing that were refined using the principles of pattern
matching, the use of suitable algorithms, and Neural networks. A survey was done on diabetic
patients and physicians to establish the kind of word and information a physician can ask a
diabetic patient and the kind of responses to match the questions. These were input into the
chatbot repository and the chatbot trained on the kind of responses that were suitable for specific
queries. Using the principles of NLP, key words were used extensively so that a patient had to
only type key words and get a response.
This research paper proposes and develops an artificial intelligence diabetes chatbot that is a
health assistant to diabetic patients. The need for such a chatbot is informed by the tremendous
growth in technology use in health care and the challenges that face patients and physicians n the
effective management of the chronic condition of diabetes. Patients rarely have adequate
qualitative time with their doctors, with countries such as the US averaging just over one hour of
direct contact by patients with a physician. Yet counties continue sending significant amounts of
its GDP on health care, with the US using 17% of its GDP on health care for its citizens. Further,
diabetes management requires a lot of self-management by the patient to attain healthy lifestyles.
Some of the challenges faced in effective management of diabetes include not following
recommended lifestyles, high costs of insurance and payments for medicines, failure to follow
treatment regimes, and failure to monitor blood glucose levels regularly. Further, high costs and
compelling personal reasons, along with few doctor visits and doctor patient time have added to
the challenge of effective management of diabetes. Using the Internet and artificial intelligence
principles, this paper proposes the use of a chatbot that is developed with a library to become
diabetes patients’ personal assistants. A simple chatbot was built using the C++ language, using
the principles of NLP and word processing that were refined using the principles of pattern
matching, the use of suitable algorithms, and Neural networks. A survey was done on diabetic
patients and physicians to establish the kind of word and information a physician can ask a
diabetic patient and the kind of responses to match the questions. These were input into the
chatbot repository and the chatbot trained on the kind of responses that were suitable for specific
queries. Using the principles of NLP, key words were used extensively so that a patient had to
only type key words and get a response.

Acknowledgements

Table of Contents
Abstract............................................................................................................................................2
Acknowledgements..........................................................................................................................3
Introduction......................................................................................................................................6
Background......................................................................................................................................8
Problem Statement...........................................................................................................................8
Aim and objectives..........................................................................................................................9
Scope of the Chatbot....................................................................................................................9
Target users................................................................................................................................10
Value profile...............................................................................................................................10
Literature Review..........................................................................................................................10
Methods and Methodology............................................................................................................13
Word Processing.........................................................................................................................15
Pattern Matching........................................................................................................................17
Tokenisation:..............................................................................................................................18
Lexicon Normalization..............................................................................................................19
Syntactic Analysis......................................................................................................................20
Semantic Analysis......................................................................................................................21
Discourse Integration.................................................................................................................21
Pragmatic analysis......................................................................................................................21
Removing Stop Words...............................................................................................................22
Stemming and Lemmatization:..................................................................................................22
Algorithms.................................................................................................................................25
Naïve Bayes Classifier...........................................................................................................25
Chatbot Design..............................................................................................................................27
Building the Server....................................................................................................................27
Training Data.............................................................................................................................31
Abstract............................................................................................................................................2
Acknowledgements..........................................................................................................................3
Introduction......................................................................................................................................6
Background......................................................................................................................................8
Problem Statement...........................................................................................................................8
Aim and objectives..........................................................................................................................9
Scope of the Chatbot....................................................................................................................9
Target users................................................................................................................................10
Value profile...............................................................................................................................10
Literature Review..........................................................................................................................10
Methods and Methodology............................................................................................................13
Word Processing.........................................................................................................................15
Pattern Matching........................................................................................................................17
Tokenisation:..............................................................................................................................18
Lexicon Normalization..............................................................................................................19
Syntactic Analysis......................................................................................................................20
Semantic Analysis......................................................................................................................21
Discourse Integration.................................................................................................................21
Pragmatic analysis......................................................................................................................21
Removing Stop Words...............................................................................................................22
Stemming and Lemmatization:..................................................................................................22
Algorithms.................................................................................................................................25
Naïve Bayes Classifier...........................................................................................................25
Chatbot Design..............................................................................................................................27
Building the Server....................................................................................................................27
Training Data.............................................................................................................................31
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Testing........................................................................................................................................35
Conclusions....................................................................................................................................36
Recommendations......................................................................................................................37
References......................................................................................................................................38
Conclusions....................................................................................................................................36
Recommendations......................................................................................................................37
References......................................................................................................................................38

Introduction
Chatter bot, popularly termed chatbot, refers to a computer program that can undertake
conversations with human beings using textual or auditory methods. These bots are designed
such that they can simulate human behavior during communication in a highly convincing
manner. A person using the chatbot from one terminal will believe they are actually interacting
with a human being at the other end and in so doing pass the Turing Test. Chatbots are employed
in dialog systems for a variety of practical applications ranging from customer service to
acquisition of information. Some chatbots employ natural systems for language processing that
are highly sophisticated, although many still utilize simpler systems in which key words are
scanned for in an input and then replies that have the most suitable word patterns or matching
words pulled form a database. The Turing Test is a test of the ability of a machine to show
intelligent behavior, developed in the 1950 by Alan Turing (1). The intelligent behavior must be
indistinguishable from, or equivalent to, that exhibited by human beings. According to the test, a
human being can evaluate natural language conversation taking place between a machine built to
generate responses akin to those of a human, and a human being. The communication between
the machine and human, however, remains limited to text only channels, for instance, a computer
screen and keyboard so that the outcomes remain independent of the capability of the machine to
render words as being speech. If it is impossible for a human evaluator to differentiate between
the machine and human, then the machine is deemed to have passed the Turing Test. The test,
however, does not check the machines ability to provide correct answers but only the closeness
with which the machine answers resemble what would be given by a human being.
Chatbots are increasingly being used, from online shopping portals to being used by websites to
provide guidance to visitors. Although chatbots are designed for specific functions and specified
knowledge areas, they use a similar where an input is by human beings is checked against the
chatbot knowledge database. A database is required since while some chatbots can remember the
past flow of conversation, it cannot remember much or all past conversation flow. Modern
healthcare is peppered by several challenges and numerous stories of patients being failed by the
‘system’ and this has become a common occurrence. There is a huge and startling disconnect
between health care providers and patients despite the efforts that have been made to offer better
healthcare using patient centered approaches that also leverage new technologies such as
Chatter bot, popularly termed chatbot, refers to a computer program that can undertake
conversations with human beings using textual or auditory methods. These bots are designed
such that they can simulate human behavior during communication in a highly convincing
manner. A person using the chatbot from one terminal will believe they are actually interacting
with a human being at the other end and in so doing pass the Turing Test. Chatbots are employed
in dialog systems for a variety of practical applications ranging from customer service to
acquisition of information. Some chatbots employ natural systems for language processing that
are highly sophisticated, although many still utilize simpler systems in which key words are
scanned for in an input and then replies that have the most suitable word patterns or matching
words pulled form a database. The Turing Test is a test of the ability of a machine to show
intelligent behavior, developed in the 1950 by Alan Turing (1). The intelligent behavior must be
indistinguishable from, or equivalent to, that exhibited by human beings. According to the test, a
human being can evaluate natural language conversation taking place between a machine built to
generate responses akin to those of a human, and a human being. The communication between
the machine and human, however, remains limited to text only channels, for instance, a computer
screen and keyboard so that the outcomes remain independent of the capability of the machine to
render words as being speech. If it is impossible for a human evaluator to differentiate between
the machine and human, then the machine is deemed to have passed the Turing Test. The test,
however, does not check the machines ability to provide correct answers but only the closeness
with which the machine answers resemble what would be given by a human being.
Chatbots are increasingly being used, from online shopping portals to being used by websites to
provide guidance to visitors. Although chatbots are designed for specific functions and specified
knowledge areas, they use a similar where an input is by human beings is checked against the
chatbot knowledge database. A database is required since while some chatbots can remember the
past flow of conversation, it cannot remember much or all past conversation flow. Modern
healthcare is peppered by several challenges and numerous stories of patients being failed by the
‘system’ and this has become a common occurrence. There is a huge and startling disconnect
between health care providers and patients despite the efforts that have been made to offer better
healthcare using patient centered approaches that also leverage new technologies such as

applications and mobile devices. The discrepancy between patients and physicians is still
incredibly huge. An example is in the American healthcare system where typically, a person
visits the doctor four times every year. The average patient in the US, however, just spends
about 16 minutes consulting with the physician resulting in just less than one hour of face time
engagement between the patient and physician every year, yet a year has 8760 hours! This
translates to just 0.01% time spent with the physician, yet on average, the patient spends between
10 and 20% of their yearly disposable income on health care (health insurance) and other
expenses related to their health. The US economy, for instance, uses over 17% of her combined
GDP on health care (1a).
The trend is not too dissimilar in other countries, although many have higher patient doctor visits
and interactions; Japan averages 13 visits per year, Germany 10 days, Canada 7 days, France 7
days, similar to Australia at 7 days, and 5 days for the UK. The few visits to the physician per
year and the little average time spent with the doctor begs the question as to what occurs in
between the infrequent visits to the physician? This is because health is not binary in nature
where one does well (medically) and then suddenly falls sick the next day (except in a few
cases). The biggest consumer of health resources and systems are person suffering from chronic
diseases and conditions that leave them teetering on the edge of an acute episode on a daily basis.
Such chronic conditions include asthma, heart conditions, and diabetes, among others. In the US
for example, research shows that only 5% of the total population account for 49% (almost half)
of the total expenses in health care. Further, 44% of the US total expenses in healthcare are
accounted for by 15% of health conditions that are the most expensive. Between the few and
infrequent patient meetings with physicians, the latter have little to no qualitative or quantitative
data on the daily condition of their patients. The physician and health care providers are not
aware of how well the patients comply with medication, whether they are experiencing side
effects, their general state of health and wellbeing (emotionally and physical wellbeing). The
physician is unaware whether their patients are following healthy lifestyles such as eating the
recommended foods, exercising, or even dieting. Time and resource constraints mean that
physicians do not know many things about their patients, and they have little or no time to do it.
At present, such concerns and questions remain unanswered because the physicians are only able
to see their patients after making arbitrary appointments for follow ups or if the patients’
condition deteriorates further and has to be rushed to the health care facility. However, such
incredibly huge. An example is in the American healthcare system where typically, a person
visits the doctor four times every year. The average patient in the US, however, just spends
about 16 minutes consulting with the physician resulting in just less than one hour of face time
engagement between the patient and physician every year, yet a year has 8760 hours! This
translates to just 0.01% time spent with the physician, yet on average, the patient spends between
10 and 20% of their yearly disposable income on health care (health insurance) and other
expenses related to their health. The US economy, for instance, uses over 17% of her combined
GDP on health care (1a).
The trend is not too dissimilar in other countries, although many have higher patient doctor visits
and interactions; Japan averages 13 visits per year, Germany 10 days, Canada 7 days, France 7
days, similar to Australia at 7 days, and 5 days for the UK. The few visits to the physician per
year and the little average time spent with the doctor begs the question as to what occurs in
between the infrequent visits to the physician? This is because health is not binary in nature
where one does well (medically) and then suddenly falls sick the next day (except in a few
cases). The biggest consumer of health resources and systems are person suffering from chronic
diseases and conditions that leave them teetering on the edge of an acute episode on a daily basis.
Such chronic conditions include asthma, heart conditions, and diabetes, among others. In the US
for example, research shows that only 5% of the total population account for 49% (almost half)
of the total expenses in health care. Further, 44% of the US total expenses in healthcare are
accounted for by 15% of health conditions that are the most expensive. Between the few and
infrequent patient meetings with physicians, the latter have little to no qualitative or quantitative
data on the daily condition of their patients. The physician and health care providers are not
aware of how well the patients comply with medication, whether they are experiencing side
effects, their general state of health and wellbeing (emotionally and physical wellbeing). The
physician is unaware whether their patients are following healthy lifestyles such as eating the
recommended foods, exercising, or even dieting. Time and resource constraints mean that
physicians do not know many things about their patients, and they have little or no time to do it.
At present, such concerns and questions remain unanswered because the physicians are only able
to see their patients after making arbitrary appointments for follow ups or if the patients’
condition deteriorates further and has to be rushed to the health care facility. However, such
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

interventions are usually almost too late and generally, only 13% of physicians are available for
telephone communication with patients. This state of affairs also mean that patients may feel
disconcerted from the care givers resulting in their disengagement from their therapy.
Background
Generally, diabetes is a disease condition that happens when the blood sugar (blood glucose)
becomes too high. The main source of energy for the human body is glucose obtained from
ingested food. In the human body, the pancreas releases insulin hormone that helps get glucose
into the body cells from the consumed food for use as energy. However, sometime the body fails
to make sufficient insulin or none at all or in some cases, fails to properly utilize insulin leading
to the glucose remaining in the persons’ blood and failing to reach their cells. With time, too
much glucose in the blood causes health problems and diabetes has no cure. Because of its
nature, daily routine and lifestyle plays a very big role in its management. The effective
management of diabetes requires awareness, by both the patient and the physician; as well as
how the daily factors of daily routines and lifestyle can be controlled. Keeping persons’ blood
sugar levels at what the physician recommends can be a huge challenge since several factors and
things lead to changes in one’s blood sugar levels in unexpected ways. The food that people eat
should be healthy since healthy eating forms one of the cornerstones of healthy living, even for
those without diabetes. Diabetics must know how food affects their blood sugar levels since it is
not just the type of food consumed that affects blood sugar but the amounts eaten as well.
Problem Statement
As discussed in the introduction, doctor patient interactions are few; doctors have no way of
knowing the daily conditions of their patients while the patients are left largely on their own.
Further, the few times that doctors interact with patients mean that qualitative advice on such
issues as diet, exercise, meals, and drink that can help the diabetic patient better manage their
condition is way too little. Diabetes poses some well-known but serious medical/ health risks to
sufferers that include orthopedic problems, peripheral circulatory problems, chronic ulceration,
stroke, high blood pressure, high triglycerides, and cholesterol. Patients must seek counsel from
their health providers to obtain essential guidance on how to look after themselves to control
their diabetic condition as well as better control related conditions to attain optima health. The
telephone communication with patients. This state of affairs also mean that patients may feel
disconcerted from the care givers resulting in their disengagement from their therapy.
Background
Generally, diabetes is a disease condition that happens when the blood sugar (blood glucose)
becomes too high. The main source of energy for the human body is glucose obtained from
ingested food. In the human body, the pancreas releases insulin hormone that helps get glucose
into the body cells from the consumed food for use as energy. However, sometime the body fails
to make sufficient insulin or none at all or in some cases, fails to properly utilize insulin leading
to the glucose remaining in the persons’ blood and failing to reach their cells. With time, too
much glucose in the blood causes health problems and diabetes has no cure. Because of its
nature, daily routine and lifestyle plays a very big role in its management. The effective
management of diabetes requires awareness, by both the patient and the physician; as well as
how the daily factors of daily routines and lifestyle can be controlled. Keeping persons’ blood
sugar levels at what the physician recommends can be a huge challenge since several factors and
things lead to changes in one’s blood sugar levels in unexpected ways. The food that people eat
should be healthy since healthy eating forms one of the cornerstones of healthy living, even for
those without diabetes. Diabetics must know how food affects their blood sugar levels since it is
not just the type of food consumed that affects blood sugar but the amounts eaten as well.
Problem Statement
As discussed in the introduction, doctor patient interactions are few; doctors have no way of
knowing the daily conditions of their patients while the patients are left largely on their own.
Further, the few times that doctors interact with patients mean that qualitative advice on such
issues as diet, exercise, meals, and drink that can help the diabetic patient better manage their
condition is way too little. Diabetes poses some well-known but serious medical/ health risks to
sufferers that include orthopedic problems, peripheral circulatory problems, chronic ulceration,
stroke, high blood pressure, high triglycerides, and cholesterol. Patients must seek counsel from
their health providers to obtain essential guidance on how to look after themselves to control
their diabetic condition as well as better control related conditions to attain optima health. The

clinical nurse or care giver, therefore, plays a highly important role in diabetic patient care. The
care givers play a highly important role in tracking and providing information and coaching to
diabetic patients, ensuring they undergo all scheduled tests and show up for appointments, and
ensuring patients are doing basic care operations like checking their blood sugar regularly, and
giving advice on exercise and diet. The cover for supplies and medications for diabetes are
costly and increasing; insurance premiums for such conditions re increasing rapidly; the patients
must also pay additional costs to meet deductibles, co-insurance, and co-pays. Adhering to the
prescribed medication is also a huge challenge in managing diabetes; increased costs, compelling
priorities, access, and lack of awareness have been reported as being major hindrances to
effective diabetes management. Treatment costs for diabetics are equally high while diabetics
get no interventions for diseases as pre-diabetics (1). Educating diabetics on present effective
interventions for better self-management of the condition is a major problem in managing
diabetes, as is ensuring patients adhere to recommended lifestyles and pharmacologic
interventions (2). All these challenges require an integrated approach to the effective
management of diabetes where the patients can get advice, be reminded of their appointments,
and enable them get basic health imparting advice and coaching
Aim and objectives
The aim of this project is to use a generative model in a closed domain to create a chatbot that
will be able to grow and learn what is good for diabetes in general and also give
recommendations based on its user.
Create a chatbot that diabetic users can access at any time and obtain health imparting
information and advice
Scope of the Chatbot
He chatbot will be able to respond to the user input (questions), based on a pre-existing database
and to continue ‘learning’ to better provide medical advice to the diabetic patients
Example of scenarios can be such that a first-time user conversation
User: Hello
care givers play a highly important role in tracking and providing information and coaching to
diabetic patients, ensuring they undergo all scheduled tests and show up for appointments, and
ensuring patients are doing basic care operations like checking their blood sugar regularly, and
giving advice on exercise and diet. The cover for supplies and medications for diabetes are
costly and increasing; insurance premiums for such conditions re increasing rapidly; the patients
must also pay additional costs to meet deductibles, co-insurance, and co-pays. Adhering to the
prescribed medication is also a huge challenge in managing diabetes; increased costs, compelling
priorities, access, and lack of awareness have been reported as being major hindrances to
effective diabetes management. Treatment costs for diabetics are equally high while diabetics
get no interventions for diseases as pre-diabetics (1). Educating diabetics on present effective
interventions for better self-management of the condition is a major problem in managing
diabetes, as is ensuring patients adhere to recommended lifestyles and pharmacologic
interventions (2). All these challenges require an integrated approach to the effective
management of diabetes where the patients can get advice, be reminded of their appointments,
and enable them get basic health imparting advice and coaching
Aim and objectives
The aim of this project is to use a generative model in a closed domain to create a chatbot that
will be able to grow and learn what is good for diabetes in general and also give
recommendations based on its user.
Create a chatbot that diabetic users can access at any time and obtain health imparting
information and advice
Scope of the Chatbot
He chatbot will be able to respond to the user input (questions), based on a pre-existing database
and to continue ‘learning’ to better provide medical advice to the diabetic patients
Example of scenarios can be such that a first-time user conversation
User: Hello

Chatbot: Hi
User: What food can you recommend?
Chatbot: How about some porridge with strawberries?
User: That’s fine thanks.
Target users
The target users what will use the Chatbot include;
• Diabetic patients
• People who need help with healthy food recommendations
• People who need exercise suggestions
Value profile
Our chatbot should be able to have some healthy food stored in its system that it can make
recommendations from. It should also have some set of exercises that it can recommend this can
be trained to suggest certain exercise from some age range based on priority. Because of the
listed problems in effective management of diabetes, this research project aims at solving the
challenges of poor personal care, high costs of care, few doctor patient interactions, and lack of
access to information on lifestyle that will help the patient improve their condition and overall
quality of life. This will be achieved by developing a chatbot based on the principles of artificial
intelligence and machine learning.
Literature Review
A chatbot is a computer program that is designed to emulate communication with human beings
as though one was communicating with a human, predominantly over the internet. The advent of
IPAs (intelligent personal assistance) and the growth of machine learning, it is becoming
increasingly possible to manage healthcare using these technologies. Chatbots already exists, for
example Siri for Apple products that can listen to voice commands and respond appropriately;
for instance, finding direction to a health center. It is projected that chatbots will be the future of
communication (3). The success of chatbots will not be limited to just messaging; chatbots will
User: What food can you recommend?
Chatbot: How about some porridge with strawberries?
User: That’s fine thanks.
Target users
The target users what will use the Chatbot include;
• Diabetic patients
• People who need help with healthy food recommendations
• People who need exercise suggestions
Value profile
Our chatbot should be able to have some healthy food stored in its system that it can make
recommendations from. It should also have some set of exercises that it can recommend this can
be trained to suggest certain exercise from some age range based on priority. Because of the
listed problems in effective management of diabetes, this research project aims at solving the
challenges of poor personal care, high costs of care, few doctor patient interactions, and lack of
access to information on lifestyle that will help the patient improve their condition and overall
quality of life. This will be achieved by developing a chatbot based on the principles of artificial
intelligence and machine learning.
Literature Review
A chatbot is a computer program that is designed to emulate communication with human beings
as though one was communicating with a human, predominantly over the internet. The advent of
IPAs (intelligent personal assistance) and the growth of machine learning, it is becoming
increasingly possible to manage healthcare using these technologies. Chatbots already exists, for
example Siri for Apple products that can listen to voice commands and respond appropriately;
for instance, finding direction to a health center. It is projected that chatbots will be the future of
communication (3). The success of chatbots will not be limited to just messaging; chatbots will
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

become very successful in the area of healthcare provision mainly because there are several
health questions and concerns that do not need the full attention of a medical practitioner/
physician. However, leaving such questions and concerns unanswered will deny the concerned
persons valuable information that could be life changing or leave people confused, nervous, and
clueless (4). Research in the UK shows that 47% of patients’ would like an application that will
enable easy booking of appointments, 43% desire a system that provides information on how to
manage prescriptions, and 38% would like a system (application) that provides advice on
exercise and diet while tracking their performance. 32% of patients would love an IT based
system that reviews symptoms and gives advice, while 29% would want a system to report
symptoms and illnesses (5).
Research has demonstrated that chatbots can be used in the healthcare industry over the internet
to influence behavior of users. In a study on drinking persons, the use of a chatbot influenced
them to change their drinking habits despite the chatbot not delving into the psychiatric nature of
the drinkers continuously. The interaction lacked emotional judgment and input. The study
concluded that continuous recognition of emotion will result in better use of chatbots on
healthcare provision (6). Another research evaluated the use of chatbots in psychological
counseling to help improve outcomes in mental health interventions. The design for the chatbot
was informed by the fact that mental health problems is one of the major burdens of disease
globally, contributing 28% of the global disease burden. This shows how serious it is, compared
to more chronic conditions such as cancer that contributes just 16%, similar to heart disease at
16% as well. Mental health problems account for a large number of sickness days, with
depression accounting for 15.8 million sick days in the UK alone. The gap between demand and
resources for mental healthcare will be so high, hence the need for more innovative ways to
handle mental health conditions. Chatbots can be incorporated into the cost effective and high
impact management of mental health conditions as shown by the research demonstration using
an interactive emoji chatbot with GIFs. A proof of concept chatbot named ‘Mandy’ has been
tested and used as a primary care chatbot. The chatbot was created to aid healthcare staff through
automation of the patient intake process. The chatbot was shown to be able to interact effectively
with patients by conducting interviews, comprehending their main complaints using natural
language, and submitting reports to physicians for further action. Further, the system has a
mobile application end that patients can use, as well as a doctor interface to access patient data
health questions and concerns that do not need the full attention of a medical practitioner/
physician. However, leaving such questions and concerns unanswered will deny the concerned
persons valuable information that could be life changing or leave people confused, nervous, and
clueless (4). Research in the UK shows that 47% of patients’ would like an application that will
enable easy booking of appointments, 43% desire a system that provides information on how to
manage prescriptions, and 38% would like a system (application) that provides advice on
exercise and diet while tracking their performance. 32% of patients would love an IT based
system that reviews symptoms and gives advice, while 29% would want a system to report
symptoms and illnesses (5).
Research has demonstrated that chatbots can be used in the healthcare industry over the internet
to influence behavior of users. In a study on drinking persons, the use of a chatbot influenced
them to change their drinking habits despite the chatbot not delving into the psychiatric nature of
the drinkers continuously. The interaction lacked emotional judgment and input. The study
concluded that continuous recognition of emotion will result in better use of chatbots on
healthcare provision (6). Another research evaluated the use of chatbots in psychological
counseling to help improve outcomes in mental health interventions. The design for the chatbot
was informed by the fact that mental health problems is one of the major burdens of disease
globally, contributing 28% of the global disease burden. This shows how serious it is, compared
to more chronic conditions such as cancer that contributes just 16%, similar to heart disease at
16% as well. Mental health problems account for a large number of sickness days, with
depression accounting for 15.8 million sick days in the UK alone. The gap between demand and
resources for mental healthcare will be so high, hence the need for more innovative ways to
handle mental health conditions. Chatbots can be incorporated into the cost effective and high
impact management of mental health conditions as shown by the research demonstration using
an interactive emoji chatbot with GIFs. A proof of concept chatbot named ‘Mandy’ has been
tested and used as a primary care chatbot. The chatbot was created to aid healthcare staff through
automation of the patient intake process. The chatbot was shown to be able to interact effectively
with patients by conducting interviews, comprehending their main complaints using natural
language, and submitting reports to physicians for further action. Further, the system has a
mobile application end that patients can use, as well as a doctor interface to access patient data

and a diagnostic component. Using data driven processing ability with natural language to
provide enhanced and efficient medical services (8). The preceding passages show that chatbots
can be effectively used in enhancing healthcare provision including diabetes management.
Further, while m-Health (mobile health) applications have grown in number and sophistication
for use in the management of chronic diseases, research shows that there is still great room for
making improvements to attain holistic healthcare provision (9).
There are two main models that are popularly used with chatbots.
Generative based models
Retrieval based models
Generative based bots are considered the future of chatbots because this design results in smarter
bots, although at present, it is mostly confined to laboratories and is not widely used by
developers of chatbots. Retrieval based Bots are simpler and much easier to build and give
results that are more predictable. However, the results from retrieval based bots are not usually
accurate 100%. They are more practical approaches to chatbot development at the moment
because there are several readily available APIs and algorithms that developers can use. For this
chatbot, a combination of both models will be used. Retrieval based model will manage
information that are unlikely to change and general to diabetic information and the generative
model will learn what the interest of the user is over time.
provide enhanced and efficient medical services (8). The preceding passages show that chatbots
can be effectively used in enhancing healthcare provision including diabetes management.
Further, while m-Health (mobile health) applications have grown in number and sophistication
for use in the management of chronic diseases, research shows that there is still great room for
making improvements to attain holistic healthcare provision (9).
There are two main models that are popularly used with chatbots.
Generative based models
Retrieval based models
Generative based bots are considered the future of chatbots because this design results in smarter
bots, although at present, it is mostly confined to laboratories and is not widely used by
developers of chatbots. Retrieval based Bots are simpler and much easier to build and give
results that are more predictable. However, the results from retrieval based bots are not usually
accurate 100%. They are more practical approaches to chatbot development at the moment
because there are several readily available APIs and algorithms that developers can use. For this
chatbot, a combination of both models will be used. Retrieval based model will manage
information that are unlikely to change and general to diabetic information and the generative
model will learn what the interest of the user is over time.

Methods
Our chatbot will need to receive input from the user in the form of text. This would need to be
passed to the chatbot. The input will be processed by the natural language processing (NLP).
Retrieval based models usually work based on the principle of pattern matching where a user’s
input is mapped to a predefined response [11]. Such system requires a large set of matching
responses for various inputs to be effective, as input can vary widely. A user can generally
choose any topic to converse with a chatbot and if the chatbot does not have predefined answer
in the topic category then the chatbot fails to communicate effectively. Generative based models
are not as popularly used as retrieval based chatbots. They do not fetch their response from a
predefined set of data, rather they generate their response in a humanly manner, processing the
input and use their experience to prepare the response. They are trained based on real dialogues
by translating user inputs [12]
Chatbots are AI (artificial intelligence) systems that users can interact with either through voice
or text interface. Such interactions can be straight forward, for instance asking a chatbot the
weather at a certain location or city. To determine the kind of information to keep in a database
and what kinds of questions are likely to be asked by diabetic patients, a systematic approach
was used [13]. First, opportunities for an AI chatbot were identified based on the criteria of
work / task complexity and data complexity. The considerations led to four main activity models
being considered namely; expert, efficiency, effectiveness, and innovation. The aim was to fully
comprehend the reasons for building the chatbot in order to be better placed on how to design the
chatbot. The next important aspect was to understand the needs and goals of the users/ customers
that would use the chatbot [14]. This research considered it of utmost importance to understand
the kind of questions that diabetics are likely to ask or need information on in order to develop
the language/ vocabulary database for the chatbot [15]. To be certain, this project used a
quantitative research approach to obtain primary information by using a questionnaire with
pretested questions posed to both experts/care givers and diabetic patients [16]. The sampling
method used was focused on health care providers specifically dealing with diabetic patients and
diabetic patients. The diabetic patients were obtained from an online support user group for
diabetic sufferers and were explained to why the survey was being undertaken. Further, the
participants were asked about whether they would be interested in using such a system to help in
Our chatbot will need to receive input from the user in the form of text. This would need to be
passed to the chatbot. The input will be processed by the natural language processing (NLP).
Retrieval based models usually work based on the principle of pattern matching where a user’s
input is mapped to a predefined response [11]. Such system requires a large set of matching
responses for various inputs to be effective, as input can vary widely. A user can generally
choose any topic to converse with a chatbot and if the chatbot does not have predefined answer
in the topic category then the chatbot fails to communicate effectively. Generative based models
are not as popularly used as retrieval based chatbots. They do not fetch their response from a
predefined set of data, rather they generate their response in a humanly manner, processing the
input and use their experience to prepare the response. They are trained based on real dialogues
by translating user inputs [12]
Chatbots are AI (artificial intelligence) systems that users can interact with either through voice
or text interface. Such interactions can be straight forward, for instance asking a chatbot the
weather at a certain location or city. To determine the kind of information to keep in a database
and what kinds of questions are likely to be asked by diabetic patients, a systematic approach
was used [13]. First, opportunities for an AI chatbot were identified based on the criteria of
work / task complexity and data complexity. The considerations led to four main activity models
being considered namely; expert, efficiency, effectiveness, and innovation. The aim was to fully
comprehend the reasons for building the chatbot in order to be better placed on how to design the
chatbot. The next important aspect was to understand the needs and goals of the users/ customers
that would use the chatbot [14]. This research considered it of utmost importance to understand
the kind of questions that diabetics are likely to ask or need information on in order to develop
the language/ vocabulary database for the chatbot [15]. To be certain, this project used a
quantitative research approach to obtain primary information by using a questionnaire with
pretested questions posed to both experts/care givers and diabetic patients [16]. The sampling
method used was focused on health care providers specifically dealing with diabetic patients and
diabetic patients. The diabetic patients were obtained from an online support user group for
diabetic sufferers and were explained to why the survey was being undertaken. Further, the
participants were asked about whether they would be interested in using such a system to help in
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

their quality of life. The survey was administered online using the Survey Monkey TM survey
tool over a period of fourteen days. The results were evaluated and the following found to be the
most common types of questions the users are likely to ask the chatbot;
What…
What should be my normal blood sugar levels when fasting?
What foods should I eat and in what quantities?
What can I do to improve on my diabetes condition?
What kinds of exercises can I engage in to improve my diabetes condition?
How
How can I improve my energy levels?
How does weight affect my diabetes condition?
How can I know if my diabetes symptoms are getting worse?
How can I lower my blood sugar levels naturally?
How often should I take measurements of my blood sugar levels?
Why….
Why are my medications not improving diabetes condition?
Why am I running out of energy?
Why must I take all these medications?
When
When can I exercise after taking diabetic medications?
When should I stop taking r using diabetes medication?
When should I visit the doctor?
tool over a period of fourteen days. The results were evaluated and the following found to be the
most common types of questions the users are likely to ask the chatbot;
What…
What should be my normal blood sugar levels when fasting?
What foods should I eat and in what quantities?
What can I do to improve on my diabetes condition?
What kinds of exercises can I engage in to improve my diabetes condition?
How
How can I improve my energy levels?
How does weight affect my diabetes condition?
How can I know if my diabetes symptoms are getting worse?
How can I lower my blood sugar levels naturally?
How often should I take measurements of my blood sugar levels?
Why….
Why are my medications not improving diabetes condition?
Why am I running out of energy?
Why must I take all these medications?
When
When can I exercise after taking diabetic medications?
When should I stop taking r using diabetes medication?
When should I visit the doctor?

From the physician’s perspective, the important aspects to ask the diabetic patients include;
How long the patient has been diabetic
What are the patients’ general dietary habits?
Does the patient do any exercises and how regularly?
What kin f medications is the patient taking?
When was the last time the patient tested their blood sugar levels?
How often does the patient take blood sugar level tests?
Has the patient taken their daily dosage of medicines?
The kind of foods the patient should take to help manage their diabetic condition
What is the weight of the patients?
Does the patient have any other existing conditions, such as cardiovascular conditions?
Does the patient eat sugar and sugary foods and how much?
Based on these responses, it was now clear what kind of information to include in the chatbot
database. In developing the chatbot database, various aspects of development were considered,
both technical and language, including word processing, pattern matching, algorithms,
tokenization, lexicon normalization, removal of stop words, stemming and lemmatization and
algorithms, further, the Naive Bayes classifier was also considered before commencing the
process of designing the chatbot.
Word Processing
Human input into chatbots needs to be converted into an understandable context for chatbots. A
sentence or an input can always be processed and classified by the software to understand the
“intent” of the sentence. The software function that does this processing is called a “classifier”.
How long the patient has been diabetic
What are the patients’ general dietary habits?
Does the patient do any exercises and how regularly?
What kin f medications is the patient taking?
When was the last time the patient tested their blood sugar levels?
How often does the patient take blood sugar level tests?
Has the patient taken their daily dosage of medicines?
The kind of foods the patient should take to help manage their diabetic condition
What is the weight of the patients?
Does the patient have any other existing conditions, such as cardiovascular conditions?
Does the patient eat sugar and sugary foods and how much?
Based on these responses, it was now clear what kind of information to include in the chatbot
database. In developing the chatbot database, various aspects of development were considered,
both technical and language, including word processing, pattern matching, algorithms,
tokenization, lexicon normalization, removal of stop words, stemming and lemmatization and
algorithms, further, the Naive Bayes classifier was also considered before commencing the
process of designing the chatbot.
Word Processing
Human input into chatbots needs to be converted into an understandable context for chatbots. A
sentence or an input can always be processed and classified by the software to understand the
“intent” of the sentence. The software function that does this processing is called a “classifier”.
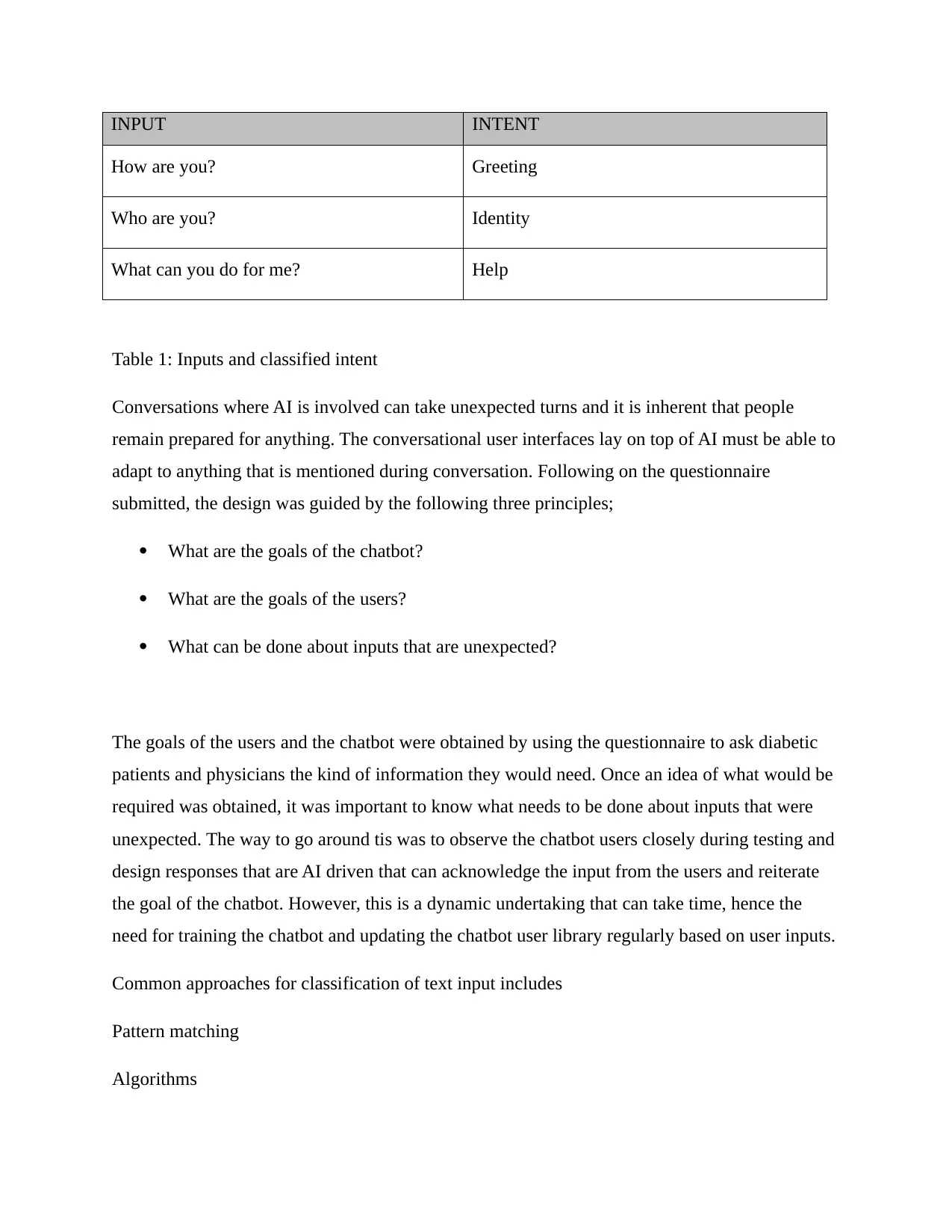
INPUT INTENT
How are you? Greeting
Who are you? Identity
What can you do for me? Help
Table 1: Inputs and classified intent
Conversations where AI is involved can take unexpected turns and it is inherent that people
remain prepared for anything. The conversational user interfaces lay on top of AI must be able to
adapt to anything that is mentioned during conversation. Following on the questionnaire
submitted, the design was guided by the following three principles;
What are the goals of the chatbot?
What are the goals of the users?
What can be done about inputs that are unexpected?
The goals of the users and the chatbot were obtained by using the questionnaire to ask diabetic
patients and physicians the kind of information they would need. Once an idea of what would be
required was obtained, it was important to know what needs to be done about inputs that were
unexpected. The way to go around tis was to observe the chatbot users closely during testing and
design responses that are AI driven that can acknowledge the input from the users and reiterate
the goal of the chatbot. However, this is a dynamic undertaking that can take time, hence the
need for training the chatbot and updating the chatbot user library regularly based on user inputs.
Common approaches for classification of text input includes
Pattern matching
Algorithms
How are you? Greeting
Who are you? Identity
What can you do for me? Help
Table 1: Inputs and classified intent
Conversations where AI is involved can take unexpected turns and it is inherent that people
remain prepared for anything. The conversational user interfaces lay on top of AI must be able to
adapt to anything that is mentioned during conversation. Following on the questionnaire
submitted, the design was guided by the following three principles;
What are the goals of the chatbot?
What are the goals of the users?
What can be done about inputs that are unexpected?
The goals of the users and the chatbot were obtained by using the questionnaire to ask diabetic
patients and physicians the kind of information they would need. Once an idea of what would be
required was obtained, it was important to know what needs to be done about inputs that were
unexpected. The way to go around tis was to observe the chatbot users closely during testing and
design responses that are AI driven that can acknowledge the input from the users and reiterate
the goal of the chatbot. However, this is a dynamic undertaking that can take time, hence the
need for training the chatbot and updating the chatbot user library regularly based on user inputs.
Common approaches for classification of text input includes
Pattern matching
Algorithms
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Neural networks
Pattern Matching
Chatbots can at first appear as normal applications with application layers, APIs for calling
external services, and a database. The user interface is replaced by a chat interface and there is
always concern the chatbot may not fully understand the user intent, further making its design
complex. Pattern matching is the traditional method of classifying texts to produce response to
the user [18]. It can be engineered to use if-else statements logic or machine learning classifiers
to generate a response to the user. The chatbot will need to get the data input and compare with
data set or structure that is already prepared by the engineers. AIML (Artificial Intelligence
Markup Language) is an XML compliant language that has been used to make it easy to
customize Alicebot which is on open source chatbot developed by Richard Wallace [19].
Chatbots use pattern matching for text classification and to generate suitable responses to inputs
from the users.
<category>
<pattern> What is your name </pattern>
<template>My name is Henry. </template>
</category>
Figure 1: Pattern Matching Template
As shown above, when anyone ask the chatbot the question “What is your name”, the response is always going to be
“My name is Henry”.
A simple AIML based pattern matching example is shown below;
<aim version = ‘1.0.1’ encoding = ‘UTF-8’?>
<category>
<pattern> WHAT CAUSES DIABETES</pattern>
<template>Diabetes is a condition caused by the body not being able to
effectively regulate blood sugar. </template>
<category>
<category>
<pattern>WHAT TYPES OF DIABETES ARE THERE</pattern>
Pattern Matching
Chatbots can at first appear as normal applications with application layers, APIs for calling
external services, and a database. The user interface is replaced by a chat interface and there is
always concern the chatbot may not fully understand the user intent, further making its design
complex. Pattern matching is the traditional method of classifying texts to produce response to
the user [18]. It can be engineered to use if-else statements logic or machine learning classifiers
to generate a response to the user. The chatbot will need to get the data input and compare with
data set or structure that is already prepared by the engineers. AIML (Artificial Intelligence
Markup Language) is an XML compliant language that has been used to make it easy to
customize Alicebot which is on open source chatbot developed by Richard Wallace [19].
Chatbots use pattern matching for text classification and to generate suitable responses to inputs
from the users.
<category>
<pattern> What is your name </pattern>
<template>My name is Henry. </template>
</category>
Figure 1: Pattern Matching Template
As shown above, when anyone ask the chatbot the question “What is your name”, the response is always going to be
“My name is Henry”.
A simple AIML based pattern matching example is shown below;
<aim version = ‘1.0.1’ encoding = ‘UTF-8’?>
<category>
<pattern> WHAT CAUSES DIABETES</pattern>
<template>Diabetes is a condition caused by the body not being able to
effectively regulate blood sugar. </template>
<category>
<category>
<pattern>WHAT TYPES OF DIABETES ARE THERE</pattern>

<template>
<srai>WHAT IS <star>/></srai>
<template>
<category>
</aiml>
An output will then be given as shown below;
Human What is Diabetes?
Bot Diabetes is a condition caused by the body not being able to
Effectively regulate blood sugar.
The chatbot is able to provide an answer only because the answer or response (what diabetes is)
is found in the associated pattern. Similarly, chatbots are able to respond to anything that relates
it to associated patterns. However, the chatbot cannot go beyond associated patterns and this
requires the use of algorithms to take the chatbot to the next level [20].
Tokenization:
In Natural language processing, before any processing is done, it is important for text to be
broken into pieces of words, punctuations, numbers, alpha-numeric etc. This process is referred
to as tokenization. In the tokenization process, spaces and punctuation are usually removed.
Other text components which are also handled are hyphens, abbreviations, number, units of
measurements, email addresses and lots more [21], for example:
Input: Ladies and gentlemen, Welcome to our show tonight.
Output: Ladies and gentlemen Welcome to our show tonight
Tokenization is the process by which sentences are broken down into words that are discrete,
removing punctuation. In the process, named entry recognition plays an important role in looking
for words in categories that are predefined for instance, addresses and place names. A library
termed ‘normalizer’ can also be utilized by the bot to detect some common errors in spelling; it
<srai>WHAT IS <star>/></srai>
<template>
<category>
</aiml>
An output will then be given as shown below;
Human What is Diabetes?
Bot Diabetes is a condition caused by the body not being able to
Effectively regulate blood sugar.
The chatbot is able to provide an answer only because the answer or response (what diabetes is)
is found in the associated pattern. Similarly, chatbots are able to respond to anything that relates
it to associated patterns. However, the chatbot cannot go beyond associated patterns and this
requires the use of algorithms to take the chatbot to the next level [20].
Tokenization:
In Natural language processing, before any processing is done, it is important for text to be
broken into pieces of words, punctuations, numbers, alpha-numeric etc. This process is referred
to as tokenization. In the tokenization process, spaces and punctuation are usually removed.
Other text components which are also handled are hyphens, abbreviations, number, units of
measurements, email addresses and lots more [21], for example:
Input: Ladies and gentlemen, Welcome to our show tonight.
Output: Ladies and gentlemen Welcome to our show tonight
Tokenization is the process by which sentences are broken down into words that are discrete,
removing punctuation. In the process, named entry recognition plays an important role in looking
for words in categories that are predefined for instance, addresses and place names. A library
termed ‘normalizer’ can also be utilized by the bot to detect some common errors in spelling; it
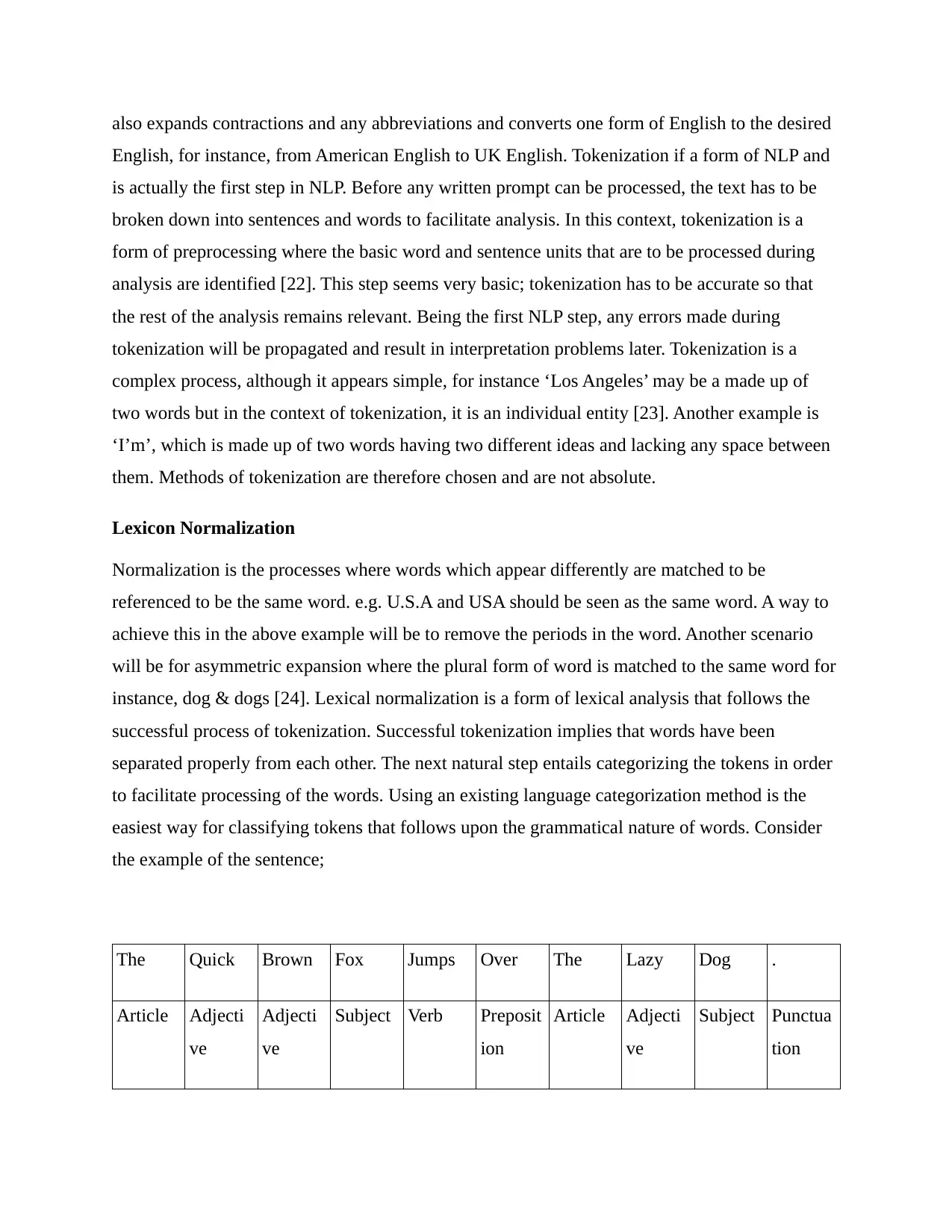
also expands contractions and any abbreviations and converts one form of English to the desired
English, for instance, from American English to UK English. Tokenization if a form of NLP and
is actually the first step in NLP. Before any written prompt can be processed, the text has to be
broken down into sentences and words to facilitate analysis. In this context, tokenization is a
form of preprocessing where the basic word and sentence units that are to be processed during
analysis are identified [22]. This step seems very basic; tokenization has to be accurate so that
the rest of the analysis remains relevant. Being the first NLP step, any errors made during
tokenization will be propagated and result in interpretation problems later. Tokenization is a
complex process, although it appears simple, for instance ‘Los Angeles’ may be a made up of
two words but in the context of tokenization, it is an individual entity [23]. Another example is
‘I’m’, which is made up of two words having two different ideas and lacking any space between
them. Methods of tokenization are therefore chosen and are not absolute.
Lexicon Normalization
Normalization is the processes where words which appear differently are matched to be
referenced to be the same word. e.g. U.S.A and USA should be seen as the same word. A way to
achieve this in the above example will be to remove the periods in the word. Another scenario
will be for asymmetric expansion where the plural form of word is matched to the same word for
instance, dog & dogs [24]. Lexical normalization is a form of lexical analysis that follows the
successful process of tokenization. Successful tokenization implies that words have been
separated properly from each other. The next natural step entails categorizing the tokens in order
to facilitate processing of the words. Using an existing language categorization method is the
easiest way for classifying tokens that follows upon the grammatical nature of words. Consider
the example of the sentence;
The Quick Brown Fox Jumps Over The Lazy Dog .
Article Adjecti
ve
Adjecti
ve
Subject Verb Preposit
ion
Article Adjecti
ve
Subject Punctua
tion
English, for instance, from American English to UK English. Tokenization if a form of NLP and
is actually the first step in NLP. Before any written prompt can be processed, the text has to be
broken down into sentences and words to facilitate analysis. In this context, tokenization is a
form of preprocessing where the basic word and sentence units that are to be processed during
analysis are identified [22]. This step seems very basic; tokenization has to be accurate so that
the rest of the analysis remains relevant. Being the first NLP step, any errors made during
tokenization will be propagated and result in interpretation problems later. Tokenization is a
complex process, although it appears simple, for instance ‘Los Angeles’ may be a made up of
two words but in the context of tokenization, it is an individual entity [23]. Another example is
‘I’m’, which is made up of two words having two different ideas and lacking any space between
them. Methods of tokenization are therefore chosen and are not absolute.
Lexicon Normalization
Normalization is the processes where words which appear differently are matched to be
referenced to be the same word. e.g. U.S.A and USA should be seen as the same word. A way to
achieve this in the above example will be to remove the periods in the word. Another scenario
will be for asymmetric expansion where the plural form of word is matched to the same word for
instance, dog & dogs [24]. Lexical normalization is a form of lexical analysis that follows the
successful process of tokenization. Successful tokenization implies that words have been
separated properly from each other. The next natural step entails categorizing the tokens in order
to facilitate processing of the words. Using an existing language categorization method is the
easiest way for classifying tokens that follows upon the grammatical nature of words. Consider
the example of the sentence;
The Quick Brown Fox Jumps Over The Lazy Dog .
Article Adjecti
ve
Adjecti
ve
Subject Verb Preposit
ion
Article Adjecti
ve
Subject Punctua
tion
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

This approach is convenient since the match between any word and it grammatical nature can be
done easily through the use of a dictionary. Further, because grammar refers to the set of rules
that govern clause and phrase composition in language, token sorting using a grammatical
criteria makes subsequent steps easy, especially syntactic analysis.
Syntactic Analysis
while lexical analysis and tokenization occur at the word level, syntactic analysis moves to the
sentence level to enable identification of the relationship between every word. Consider the
sentence below;
Predicate
Subject Verb Adjunct
The quick brown fox Jumps Over the lazy dog.
Through syntactic analysis, order is provided and each sentence structure within a text gets
ordered. For instance, identifying the subjects is especially important for discourse integration;
discourse integration evaluates the context around every sentence.
Semantic Analysis
During this step, a computer seeks for every word’s meaning; what may appear something
simple for a human that can use a dictionary, is trickier for the computer. Some words are easily
interpreted because they are straight forward, for instance monosemy words that have just a
single meaning. For polysemy words, the intended meanings are much difficult to figure out; the
word ‘set’ has up to 119 different meanings and it can also be used as an intransitive or transitive
verb, and adjective, or a noun, as well as an interjection and being found in verb phrases for
instance, ‘set back’ and in idioms such as ‘all set’. The context of the word and its use is crucial
in determining its meaning
done easily through the use of a dictionary. Further, because grammar refers to the set of rules
that govern clause and phrase composition in language, token sorting using a grammatical
criteria makes subsequent steps easy, especially syntactic analysis.
Syntactic Analysis
while lexical analysis and tokenization occur at the word level, syntactic analysis moves to the
sentence level to enable identification of the relationship between every word. Consider the
sentence below;
Predicate
Subject Verb Adjunct
The quick brown fox Jumps Over the lazy dog.
Through syntactic analysis, order is provided and each sentence structure within a text gets
ordered. For instance, identifying the subjects is especially important for discourse integration;
discourse integration evaluates the context around every sentence.
Semantic Analysis
During this step, a computer seeks for every word’s meaning; what may appear something
simple for a human that can use a dictionary, is trickier for the computer. Some words are easily
interpreted because they are straight forward, for instance monosemy words that have just a
single meaning. For polysemy words, the intended meanings are much difficult to figure out; the
word ‘set’ has up to 119 different meanings and it can also be used as an intransitive or transitive
verb, and adjective, or a noun, as well as an interjection and being found in verb phrases for
instance, ‘set back’ and in idioms such as ‘all set’. The context of the word and its use is crucial
in determining its meaning

Discourse Integration
this looks at how significant the sentences are in comparison to preceding sentences with the
assumption that following sentence texts are cohesive. To attain discourse integration, the
important factor lies in pronouns that must be recognized correctly and then linked to relevant
antecedents. In the sentence shown below, ‘it’ must be properly recognized and linked to ‘Firefox’;
Firefox is a search engine. It assists people to find information they are seeking from the web
this is a straightforward sentence, but rarely are sentences used in bots or computer normally this
straight forward.
Pragmatic analysis
pragmatics are concerned with studying how texts contribute to meaning moving from what is
said to the meaning of what is said. This is the most complex part of the NLP steps and text
recognition and classification. Computers (and bots) find it a challenge to effectively handle
ambiguity yet humans can do this very well when talking. Depending upon the situation and
language, the context becomes important in pragmatic analysis.
Removing Stop Words
Stop words in a language is a terminology that is used to describe terms that appears so often and
pervasively in documents. Manning C Et al, extremely common words add little value in helping
to understand the exclusive meaning of a vocabulary. Stop words are commonly used words such
as ‘a’, ‘the’, ‘in’, ‘an’ among others; computer search engines, for example, are programmed to
ignore these words when retrieving them from search queries and when indexing entries for
searching. In chatbot design, these words are not supposed to take up space within databases or
consume valuable processing time. For these reasons, they should be removed from databases
easily through storing words that are considered stop words.
Most Natural language processing techniques safely ignore stop words at the lexical level
https://ac.els-cdn.com/S1877050914013799/1-s2.0-S1877050914013799-main.pdf?
_tid=073687c4-bb63-11e7-8695-
this looks at how significant the sentences are in comparison to preceding sentences with the
assumption that following sentence texts are cohesive. To attain discourse integration, the
important factor lies in pronouns that must be recognized correctly and then linked to relevant
antecedents. In the sentence shown below, ‘it’ must be properly recognized and linked to ‘Firefox’;
Firefox is a search engine. It assists people to find information they are seeking from the web
this is a straightforward sentence, but rarely are sentences used in bots or computer normally this
straight forward.
Pragmatic analysis
pragmatics are concerned with studying how texts contribute to meaning moving from what is
said to the meaning of what is said. This is the most complex part of the NLP steps and text
recognition and classification. Computers (and bots) find it a challenge to effectively handle
ambiguity yet humans can do this very well when talking. Depending upon the situation and
language, the context becomes important in pragmatic analysis.
Removing Stop Words
Stop words in a language is a terminology that is used to describe terms that appears so often and
pervasively in documents. Manning C Et al, extremely common words add little value in helping
to understand the exclusive meaning of a vocabulary. Stop words are commonly used words such
as ‘a’, ‘the’, ‘in’, ‘an’ among others; computer search engines, for example, are programmed to
ignore these words when retrieving them from search queries and when indexing entries for
searching. In chatbot design, these words are not supposed to take up space within databases or
consume valuable processing time. For these reasons, they should be removed from databases
easily through storing words that are considered stop words.
Most Natural language processing techniques safely ignore stop words at the lexical level
https://ac.els-cdn.com/S1877050914013799/1-s2.0-S1877050914013799-main.pdf?
_tid=073687c4-bb63-11e7-8695-

00000aacb35d&acdnat=1509142145_4eac5136f4c0f7f80cc1af4237e3ca53. Digital libraries still
retain their textual form, while multimedia documents spread progressively. The predominance
of text in digital libraries will never be challenged or questioned and with the exception of pure
documents displays, all remaining tasks are based on some form of NLP that requires support
form suitable linguistic resources. Because the resources are language specific, they may be
unavailable for many languages and building them manually is highly costly, error prone, and
time consuming. As such, the best approach is automatic learning of linguistic resources for
natural languages beginning with texts written in that language. Having these learned resources
can make it possible for high level documents processing to be possible in that language and be
used as the basis for making advanced manual processing. Experimental results indicate that
applying it can prove highly effective in providing linguistic resources in a manner that is fully
automatic https://ac.els-cdn.com/S1877050914013799/1-s2.0-S1877050914013799-main.pdf?
_tid=073687c4-bb63-11e7-8695-
00000aacb35d&acdnat=1509142145_4eac5136f4c0f7f80cc1af4237e3ca53.
Stemming and Lemmatization:
This is the process of reducing derived words to their root form. In English language, due to
grammar and how sentences are constructed, different variations of a word can be used in
different ways such as organize, organizes and organizing without the true meaning remaining
unchanged. Stemmers do this by removing and replacing the word suffices. Documents will use
different word forms for grammatical reasons, for instance, a word such as organize can be used
as organizes, or organizing, depending on the context and tense. Further, families of words that
are derivationally related exist; these words have similar meanings, for instance, democracy,
democratization, and democratic. In several instances, it appears it would be useful to search for
one of the words so as to return documents with another word within them. The objective of
stemming and lemmatization is to reduce inflectional word forms and in some cases
derivationally related word forms to a common base form of the word. For example
are, am, is > be
cars, car, cars’, car’s > car
mapping this type of text will have a result such as
retain their textual form, while multimedia documents spread progressively. The predominance
of text in digital libraries will never be challenged or questioned and with the exception of pure
documents displays, all remaining tasks are based on some form of NLP that requires support
form suitable linguistic resources. Because the resources are language specific, they may be
unavailable for many languages and building them manually is highly costly, error prone, and
time consuming. As such, the best approach is automatic learning of linguistic resources for
natural languages beginning with texts written in that language. Having these learned resources
can make it possible for high level documents processing to be possible in that language and be
used as the basis for making advanced manual processing. Experimental results indicate that
applying it can prove highly effective in providing linguistic resources in a manner that is fully
automatic https://ac.els-cdn.com/S1877050914013799/1-s2.0-S1877050914013799-main.pdf?
_tid=073687c4-bb63-11e7-8695-
00000aacb35d&acdnat=1509142145_4eac5136f4c0f7f80cc1af4237e3ca53.
Stemming and Lemmatization:
This is the process of reducing derived words to their root form. In English language, due to
grammar and how sentences are constructed, different variations of a word can be used in
different ways such as organize, organizes and organizing without the true meaning remaining
unchanged. Stemmers do this by removing and replacing the word suffices. Documents will use
different word forms for grammatical reasons, for instance, a word such as organize can be used
as organizes, or organizing, depending on the context and tense. Further, families of words that
are derivationally related exist; these words have similar meanings, for instance, democracy,
democratization, and democratic. In several instances, it appears it would be useful to search for
one of the words so as to return documents with another word within them. The objective of
stemming and lemmatization is to reduce inflectional word forms and in some cases
derivationally related word forms to a common base form of the word. For example
are, am, is > be
cars, car, cars’, car’s > car
mapping this type of text will have a result such as
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
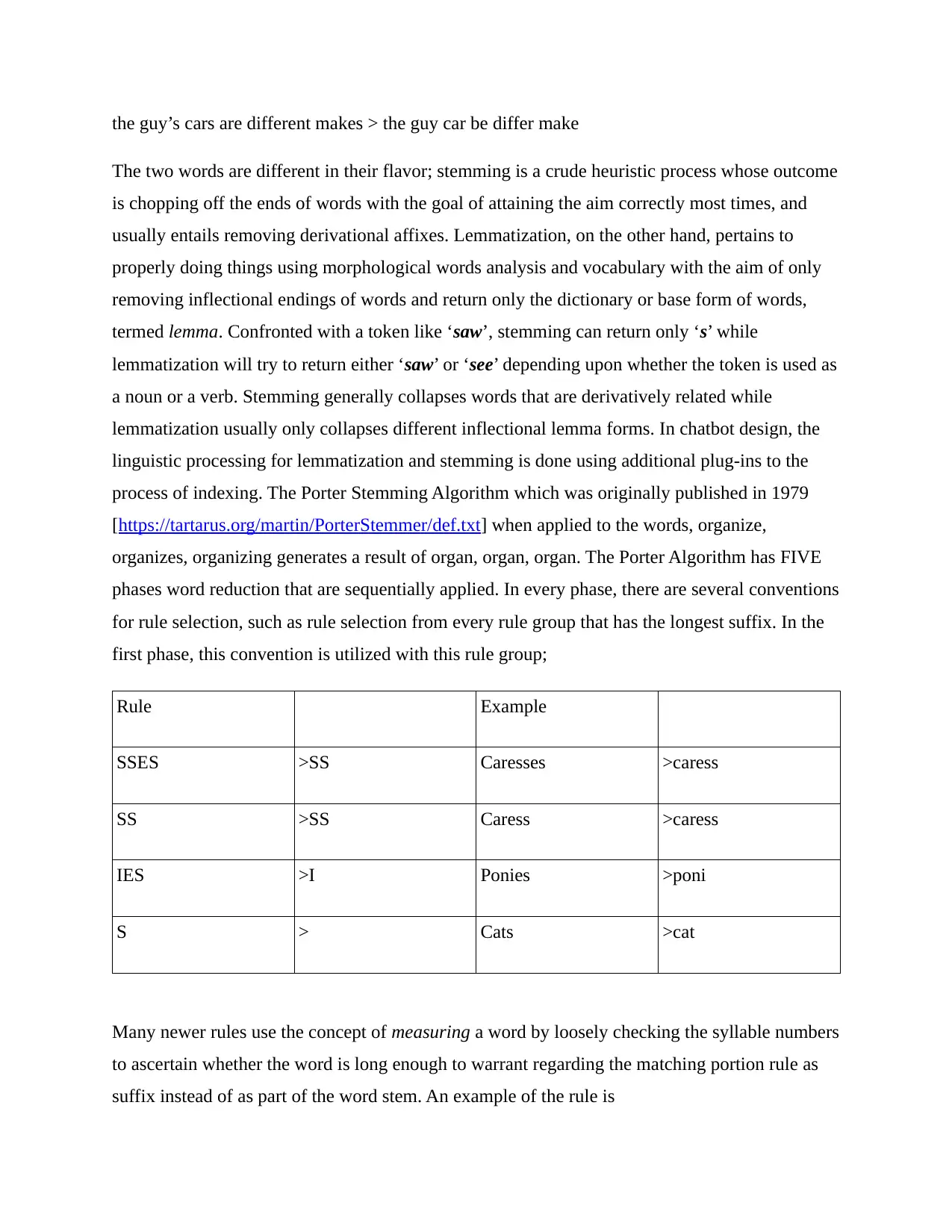
the guy’s cars are different makes > the guy car be differ make
The two words are different in their flavor; stemming is a crude heuristic process whose outcome
is chopping off the ends of words with the goal of attaining the aim correctly most times, and
usually entails removing derivational affixes. Lemmatization, on the other hand, pertains to
properly doing things using morphological words analysis and vocabulary with the aim of only
removing inflectional endings of words and return only the dictionary or base form of words,
termed lemma. Confronted with a token like ‘saw’, stemming can return only ‘s’ while
lemmatization will try to return either ‘saw’ or ‘see’ depending upon whether the token is used as
a noun or a verb. Stemming generally collapses words that are derivatively related while
lemmatization usually only collapses different inflectional lemma forms. In chatbot design, the
linguistic processing for lemmatization and stemming is done using additional plug-ins to the
process of indexing. The Porter Stemming Algorithm which was originally published in 1979
[https://tartarus.org/martin/PorterStemmer/def.txt] when applied to the words, organize,
organizes, organizing generates a result of organ, organ, organ. The Porter Algorithm has FIVE
phases word reduction that are sequentially applied. In every phase, there are several conventions
for rule selection, such as rule selection from every rule group that has the longest suffix. In the
first phase, this convention is utilized with this rule group;
Rule Example
SSES >SS Caresses >caress
SS >SS Caress >caress
IES >I Ponies >poni
S > Cats >cat
Many newer rules use the concept of measuring a word by loosely checking the syllable numbers
to ascertain whether the word is long enough to warrant regarding the matching portion rule as
suffix instead of as part of the word stem. An example of the rule is
The two words are different in their flavor; stemming is a crude heuristic process whose outcome
is chopping off the ends of words with the goal of attaining the aim correctly most times, and
usually entails removing derivational affixes. Lemmatization, on the other hand, pertains to
properly doing things using morphological words analysis and vocabulary with the aim of only
removing inflectional endings of words and return only the dictionary or base form of words,
termed lemma. Confronted with a token like ‘saw’, stemming can return only ‘s’ while
lemmatization will try to return either ‘saw’ or ‘see’ depending upon whether the token is used as
a noun or a verb. Stemming generally collapses words that are derivatively related while
lemmatization usually only collapses different inflectional lemma forms. In chatbot design, the
linguistic processing for lemmatization and stemming is done using additional plug-ins to the
process of indexing. The Porter Stemming Algorithm which was originally published in 1979
[https://tartarus.org/martin/PorterStemmer/def.txt] when applied to the words, organize,
organizes, organizing generates a result of organ, organ, organ. The Porter Algorithm has FIVE
phases word reduction that are sequentially applied. In every phase, there are several conventions
for rule selection, such as rule selection from every rule group that has the longest suffix. In the
first phase, this convention is utilized with this rule group;
Rule Example
SSES >SS Caresses >caress
SS >SS Caress >caress
IES >I Ponies >poni
S > Cats >cat
Many newer rules use the concept of measuring a word by loosely checking the syllable numbers
to ascertain whether the word is long enough to warrant regarding the matching portion rule as
suffix instead of as part of the word stem. An example of the rule is

(m >1) EMENT >
Will map the word replacement to replac, however, it will not map cement to c
However, the Lancaster Stemming Algorithm which is more aggressive than the Porter
Stemming algorithm generates a result of org, org, org. Understanding how the algorithm works
is important and should be tailored to its use case. The aim of stemming and lemmatization is to
derive the base form for a group of related words.
e.g. toy, toys, toys and toys’ can be reduced to a base value of toy.
Lemmatization considers the vocabulary and the morphology of words by removing endings that
do return the true dictionary meaning of the word. An example of this is the word done and
doing. Applying lemmatization to this would return “do” which is a verb and is the base form of
both words. Lemmatization results in actual meaningful words which is not always the case with
stemming. Stemming and Lemmatization attempts to achieve the same goal which is reducing
the inflection form of the words, however they do it in different ways and the combination of
both methods tends to yield great and better results when combined.
Algorithms
Making use of the ‘brute force’ mechanism is challenging and daunting; for every unique input, a
pattern has to be availed to specify responses. This results in a pattern of structures that is
hierarchical. To enable classifier reduction to a manageable machine, the work can be
approached algorithmically, where an equation is developed for the tasks. This is a reductionist
approach where the problem is reduced to simplify the solution. A classical algorithm for
classifying text is the ‘Multinomial Naive Bayes’ that uses the following equation;
Will map the word replacement to replac, however, it will not map cement to c
However, the Lancaster Stemming Algorithm which is more aggressive than the Porter
Stemming algorithm generates a result of org, org, org. Understanding how the algorithm works
is important and should be tailored to its use case. The aim of stemming and lemmatization is to
derive the base form for a group of related words.
e.g. toy, toys, toys and toys’ can be reduced to a base value of toy.
Lemmatization considers the vocabulary and the morphology of words by removing endings that
do return the true dictionary meaning of the word. An example of this is the word done and
doing. Applying lemmatization to this would return “do” which is a verb and is the base form of
both words. Lemmatization results in actual meaningful words which is not always the case with
stemming. Stemming and Lemmatization attempts to achieve the same goal which is reducing
the inflection form of the words, however they do it in different ways and the combination of
both methods tends to yield great and better results when combined.
Algorithms
Making use of the ‘brute force’ mechanism is challenging and daunting; for every unique input, a
pattern has to be availed to specify responses. This results in a pattern of structures that is
hierarchical. To enable classifier reduction to a manageable machine, the work can be
approached algorithmically, where an equation is developed for the tasks. This is a reductionist
approach where the problem is reduced to simplify the solution. A classical algorithm for
classifying text is the ‘Multinomial Naive Bayes’ that uses the following equation;

it is much less complicated than the equation appears; given a set of sentences with each
belonging to a given class and a new sentence input, it is possible for the occurrence of every
word in every class to be counted. Further its commonality can also be accounted for and every
class assigned a score.
Naïve Bayes Classifier
According to Huang, J. (2003) the training time with Naive Bayes is significantly smaller as
opposed to alternative methods. You can use Naive Bayes when you have limited resources in
terms of CPU and Memory. Moreover, when the training time is a crucial factor, Naive Bayes
comes handy since it can be trained very quickly. Indeed, Naive Bayes is usually outperformed
by other classifiers, but not always [1].
http://software.ucv.ro/~cmihaescu/ro/teaching/AIR/docs/Lab4-NaiveBayes.pdf
This classifier is named after Thomas Bayes who proposed the Bayes Theorem. It is primarily
used for text classification which involves high-dimensional training datasets. Bayesian
classification provides learning algorithm and knowledge about the data that will be used in the
training. Naïve Bayes classifiers remains among the very successful algorithms used to classify
natural input in natural language processing. Popular usage example of Naïve Bayes algorithm is
spam filtration. The Bayes Theorem is stated as the probability of the event B given A is equal to
the probability of the event A given B multiplied by the probability of A upon probability of B.
P (A|B) =
P (A) P (B|A)
P (B)
Factoring in commonality is essential; matching a word like ‘it’ is significantly less meaningful
than matching the word ‘cheese’. The class having the highest score is the one that is most likely
to form part of the input sentence. This over simplifies the idea since words are supposed to be
reduced to their stems. The box below shows the classification of some input sentences using the
Naive Bayes approach;
belonging to a given class and a new sentence input, it is possible for the occurrence of every
word in every class to be counted. Further its commonality can also be accounted for and every
class assigned a score.
Naïve Bayes Classifier
According to Huang, J. (2003) the training time with Naive Bayes is significantly smaller as
opposed to alternative methods. You can use Naive Bayes when you have limited resources in
terms of CPU and Memory. Moreover, when the training time is a crucial factor, Naive Bayes
comes handy since it can be trained very quickly. Indeed, Naive Bayes is usually outperformed
by other classifiers, but not always [1].
http://software.ucv.ro/~cmihaescu/ro/teaching/AIR/docs/Lab4-NaiveBayes.pdf
This classifier is named after Thomas Bayes who proposed the Bayes Theorem. It is primarily
used for text classification which involves high-dimensional training datasets. Bayesian
classification provides learning algorithm and knowledge about the data that will be used in the
training. Naïve Bayes classifiers remains among the very successful algorithms used to classify
natural input in natural language processing. Popular usage example of Naïve Bayes algorithm is
spam filtration. The Bayes Theorem is stated as the probability of the event B given A is equal to
the probability of the event A given B multiplied by the probability of A upon probability of B.
P (A|B) =
P (A) P (B|A)
P (B)
Factoring in commonality is essential; matching a word like ‘it’ is significantly less meaningful
than matching the word ‘cheese’. The class having the highest score is the one that is most likely
to form part of the input sentence. This over simplifies the idea since words are supposed to be
reduced to their stems. The box below shows the classification of some input sentences using the
Naive Bayes approach;
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

classifying the term ‘What’s it like outside’ got a term in a different class; however, similarities
of the term to the desired class resulted in a higher score. Using an equation, we seek word
matches when given sample sentences for every class, and this enables us to avoid the need to
identify every pattern.
Chatbot Design
The chatbot will be a computer program that responds meaningfully when given input in natural
language such as English. Its strength will be measured by the accuracy and quality of its output
when a user makes a query. The chatbot will be created using the C++ language, which is a
compiled language that can be directly executed by the computer hardware. The STL library will
be used frequently in developing the chatbot. The chatbot will be developed incrementally in
iterations that improve on the previous version and adding new functionalities. This method has
been chosen to ensure the chatbot does not have any problems and that bugs can be fixed early
during each iteration. The code below is for a basic chatbot named ‘diabot’, which when run,
gives responses, but not what is asked by the user;
//
of the term to the desired class resulted in a higher score. Using an equation, we seek word
matches when given sample sentences for every class, and this enables us to avoid the need to
identify every pattern.
Chatbot Design
The chatbot will be a computer program that responds meaningfully when given input in natural
language such as English. Its strength will be measured by the accuracy and quality of its output
when a user makes a query. The chatbot will be created using the C++ language, which is a
compiled language that can be directly executed by the computer hardware. The STL library will
be used frequently in developing the chatbot. The chatbot will be developed incrementally in
iterations that improve on the previous version and adding new functionalities. This method has
been chosen to ensure the chatbot does not have any problems and that bugs can be fixed early
during each iteration. The code below is for a basic chatbot named ‘diabot’, which when run,
gives responses, but not what is asked by the user;
//

// Program Name: diabot
// Description: a very basic chatbot program
//
//
#include <iostream>
#include <string>
#include <ctime>
int main()
{
std::string Response[] = {
"HELLO HOW ARE YOU TODAY?",
"SO, HAVE YOU TAKEN YOUR DIABETES MEDICATION TODAY?",
"HAVE YOU CHECKED YOUR BLOOD SUGAR LEVELS?",
"YOU MUST LOOK AFTER YOURSELF REALLY WELL.",
"SO TELL ME, HOW ARE YOU FEELING TODAY..."
};
srand((unsigned) time(NULL));
std::string sInput = "";
std::string sResponse = "";
while(1) {
std::cout << ">";
std::getline(std::cin, sInput);
int nSelection = rand() % 5;
sResponse = Response[nSelection];
std::cout << sResponse << std::endl;
}
// Description: a very basic chatbot program
//
//
#include <iostream>
#include <string>
#include <ctime>
int main()
{
std::string Response[] = {
"HELLO HOW ARE YOU TODAY?",
"SO, HAVE YOU TAKEN YOUR DIABETES MEDICATION TODAY?",
"HAVE YOU CHECKED YOUR BLOOD SUGAR LEVELS?",
"YOU MUST LOOK AFTER YOURSELF REALLY WELL.",
"SO TELL ME, HOW ARE YOU FEELING TODAY..."
};
srand((unsigned) time(NULL));
std::string sInput = "";
std::string sResponse = "";
while(1) {
std::cout << ">";
std::getline(std::cin, sInput);
int nSelection = rand() % 5;
sResponse = Response[nSelection];
std::cout << sResponse << std::endl;
}

return 0;
}
Executing this program brings a user interface where whatever input the user puts in, the
responses are the same and they do not really respond to the user inputs. Diabot repeats itself
many times because its database is very small and there is no way of controlling its behavior.
This then requires the use of keywords and creation of an inbuilt database using NLP techniques.
Tokenization and Lexicon normalization is done at this stage to improve its performance with
keywords that are associated with specific responses; this is the process of making it more
intelligent; the code is shown below;
//
// Program Name: diabot
// Description: improved , more intelligent iteration with key words
// diabot will try and understand the input from a user
//
//
#pragma warning(disable: 4786)
#include <iostream>
#include <string>
#include <vector>
#include <ctime>
const int MAX_RESP = 3;
typedef std::vector<std::string> vstring;
vstring find_match(std::string input);
}
Executing this program brings a user interface where whatever input the user puts in, the
responses are the same and they do not really respond to the user inputs. Diabot repeats itself
many times because its database is very small and there is no way of controlling its behavior.
This then requires the use of keywords and creation of an inbuilt database using NLP techniques.
Tokenization and Lexicon normalization is done at this stage to improve its performance with
keywords that are associated with specific responses; this is the process of making it more
intelligent; the code is shown below;
//
// Program Name: diabot
// Description: improved , more intelligent iteration with key words
// diabot will try and understand the input from a user
//
//
#pragma warning(disable: 4786)
#include <iostream>
#include <string>
#include <vector>
#include <ctime>
const int MAX_RESP = 3;
typedef std::vector<std::string> vstring;
vstring find_match(std::string input);
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

void copy(char *array[], vstring &v);
typedef struct {
char *input;
char *responses[MAX_RESP];
}record;
record KnowledgeBase[] = {
{"HEY, HOW ARE YOU",
{"HELLO, MY NAME IS DIABOT.",
"YOU CAN CALL ME DIABOT.",
"SO HOW CAN I HELP YOU TODAY?"}
},
{"HELLO",
{"HELLO THERE!",
"HI, HOW ARE YOU?",
"HI!"}
},
{"HI, HOW ARE YOU",
{"I'M DOING JUST FINE!",
"I'M OKAY AND YOU?",
"HOW ARE YOU FEELING TODAY, DO YOU NEED SOME HELP OR INFORMATION?"}
},
{"HOW CAN YOU HELP ME",
{"I'M YOUR DIABETES HELPER, I’M VERY KNOWLEDGEABLE IN DIABETES AND ITS
MANAGEMENT.",
"I FEEL THERE IS SOMETHING YOU WANT TO ASK OR KNOW MORE ABOUT
CONCERNING YOUR DABETES.",
typedef struct {
char *input;
char *responses[MAX_RESP];
}record;
record KnowledgeBase[] = {
{"HEY, HOW ARE YOU",
{"HELLO, MY NAME IS DIABOT.",
"YOU CAN CALL ME DIABOT.",
"SO HOW CAN I HELP YOU TODAY?"}
},
{"HELLO",
{"HELLO THERE!",
"HI, HOW ARE YOU?",
"HI!"}
},
{"HI, HOW ARE YOU",
{"I'M DOING JUST FINE!",
"I'M OKAY AND YOU?",
"HOW ARE YOU FEELING TODAY, DO YOU NEED SOME HELP OR INFORMATION?"}
},
{"HOW CAN YOU HELP ME",
{"I'M YOUR DIABETES HELPER, I’M VERY KNOWLEDGEABLE IN DIABETES AND ITS
MANAGEMENT.",
"I FEEL THERE IS SOMETHING YOU WANT TO ASK OR KNOW MORE ABOUT
CONCERNING YOUR DABETES.",

"SO, HOW ARE YOU FEELING?"}
},
{"CAN YOU REALLY HELP ME, HAVE BEEN HAVING BAD PERIODS WITH MY DIABETES",
{"YES,OF CORSE, THAT IS WHY I AM HERE.",
"ARE YOU HAVING ANY ISSUES?",
"ACTUALY,I CAN BE VERY HELPFUL, I HELP DOZENS OF OTHER PEOPLE LIKE YOU!"}
},
{"ARE YOU FOR REAL",
{"DOES THAT REALLY MATTER?",
"I AM AN INTELLIGENT DOCTOR SPECIALIZING IN DIABETES",
"I'M AS REAL AS CAN BE."}
}
};
size_t nKnowledgeBaseSize = sizeof(KnowledgeBase)/sizeof(KnowledgeBase[0]);
int main() {
srand((unsigned) time(NULL));
std::string sInput = "";
std::string sResponse = "";
while(1) {
std::cout << ">";
std::getline(std::cin, sInput);
vstring responses = find_match(sInput);
if(sInput == "OKAY, LET ME SEE WHAT I NEED, JUST A MOMENT") {
},
{"CAN YOU REALLY HELP ME, HAVE BEEN HAVING BAD PERIODS WITH MY DIABETES",
{"YES,OF CORSE, THAT IS WHY I AM HERE.",
"ARE YOU HAVING ANY ISSUES?",
"ACTUALY,I CAN BE VERY HELPFUL, I HELP DOZENS OF OTHER PEOPLE LIKE YOU!"}
},
{"ARE YOU FOR REAL",
{"DOES THAT REALLY MATTER?",
"I AM AN INTELLIGENT DOCTOR SPECIALIZING IN DIABETES",
"I'M AS REAL AS CAN BE."}
}
};
size_t nKnowledgeBaseSize = sizeof(KnowledgeBase)/sizeof(KnowledgeBase[0]);
int main() {
srand((unsigned) time(NULL));
std::string sInput = "";
std::string sResponse = "";
while(1) {
std::cout << ">";
std::getline(std::cin, sInput);
vstring responses = find_match(sInput);
if(sInput == "OKAY, LET ME SEE WHAT I NEED, JUST A MOMENT") {

std::cout << "TAKE YOUR TIME, I AM ALWAYS AVAILABLE WHEN YOU ARE READY,IT
WAS A PLEASURE TALKING TO YOU!" << std::endl;
break;
}
else if(responses.size() == 0) {
std::cout << "I DONT UNDERSTAND YOU, CAN YOU BE A LITTLE MORE CLEAR." <<
std::endl;
}
else {
int nSelection = rand() % MAX_RESP;
sResponse = responses[nSelection]; std::cout << sResponse << std::endl;
}
}
return 0;
}
// search for user input
// inside the program database
vstring find_match(std::string input) {
vstring result;
for(int i = 0; i < nKnowledgeBaseSize; ++i) {
if(std::string(KnowledgeBase[i].input) == input) {
copy(KnowledgeBase[i].responses, result);
return result;
}
}
return result;
}
void copy(char *array[], vstring &v) {
WAS A PLEASURE TALKING TO YOU!" << std::endl;
break;
}
else if(responses.size() == 0) {
std::cout << "I DONT UNDERSTAND YOU, CAN YOU BE A LITTLE MORE CLEAR." <<
std::endl;
}
else {
int nSelection = rand() % MAX_RESP;
sResponse = responses[nSelection]; std::cout << sResponse << std::endl;
}
}
return 0;
}
// search for user input
// inside the program database
vstring find_match(std::string input) {
vstring result;
for(int i = 0; i < nKnowledgeBaseSize; ++i) {
if(std::string(KnowledgeBase[i].input) == input) {
copy(KnowledgeBase[i].responses, result);
return result;
}
}
return result;
}
void copy(char *array[], vstring &v) {
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

for(int i = 0; i < MAX_RESP; ++i) {
v.push_back(array[i]);
}
}
The chatbot can now understand some input and respond specifically to specific questions, at
least better than in the first iteration. It now has some human like characteristics so that if the
chatbot cannot find a suitable response to the user input. The chatbot is still repetitive so the
repetitions must be controlled. This is done by storing the previous responses f the Diabot so he
does not repeat them using the sPrevResponse string to store them. Further, checks can be made
when the next response is being selected to evaluate if its equivalent to the previous response and
a new response from those available is selected. The chatbot is then refined by enabling input in
any letter case to be entered so that it means the same thing. Further, extra computation and
spaces are removed through lexicon normalization. After removing punctuations and letter case
sensitivity, the chatbot works a little bit better. However, the chatbot still responds only to
specific letter inputs (exact matching of sentences) t find a suitable response to the user.
Adding a single letter to the input would result in the chatbot not answering. This challenge is
overcome through the process of Stemming and Lemmatization where derived words are reduced
to the root form. This is done by making some keywords ‘loud’ within inputs to increase the
versatility and intelligence of the chatbot. Further, Fuzzy string search can also be implemented,
though this is a little more complex; it entails breaking down the present keywords into separate
words and create different vectors where one stores input words and the other vector stores the
present keyword. Using Levenshtein distance, the ‘distance’ between the two word vectors can
be measured. These were combined for this project. The chatbot did not react to a sentence
repeated over and over, so this is solved in the next iteration. Because of growing code,
encapsulation is used for subsequent iterations using classes. Entries are added to the database to
increase the range of conversation and make it more human like. Other issues, such as a user
pressing the ‘enter’ button without having input any input is also addressed. The chatbot must be
made more intelligent to know repetition even if the user slightly adjusts their previous sentence
to trick it. The chatbot is also improved by ranking keywords when there are several keyword
v.push_back(array[i]);
}
}
The chatbot can now understand some input and respond specifically to specific questions, at
least better than in the first iteration. It now has some human like characteristics so that if the
chatbot cannot find a suitable response to the user input. The chatbot is still repetitive so the
repetitions must be controlled. This is done by storing the previous responses f the Diabot so he
does not repeat them using the sPrevResponse string to store them. Further, checks can be made
when the next response is being selected to evaluate if its equivalent to the previous response and
a new response from those available is selected. The chatbot is then refined by enabling input in
any letter case to be entered so that it means the same thing. Further, extra computation and
spaces are removed through lexicon normalization. After removing punctuations and letter case
sensitivity, the chatbot works a little bit better. However, the chatbot still responds only to
specific letter inputs (exact matching of sentences) t find a suitable response to the user.
Adding a single letter to the input would result in the chatbot not answering. This challenge is
overcome through the process of Stemming and Lemmatization where derived words are reduced
to the root form. This is done by making some keywords ‘loud’ within inputs to increase the
versatility and intelligence of the chatbot. Further, Fuzzy string search can also be implemented,
though this is a little more complex; it entails breaking down the present keywords into separate
words and create different vectors where one stores input words and the other vector stores the
present keyword. Using Levenshtein distance, the ‘distance’ between the two word vectors can
be measured. These were combined for this project. The chatbot did not react to a sentence
repeated over and over, so this is solved in the next iteration. Because of growing code,
encapsulation is used for subsequent iterations using classes. Entries are added to the database to
increase the range of conversation and make it more human like. Other issues, such as a user
pressing the ‘enter’ button without having input any input is also addressed. The chatbot must be
made more intelligent to know repetition even if the user slightly adjusts their previous sentence
to trick it. The chatbot is also improved by ranking keywords when there are several keyword

choices to choose from for some input so that the best keyword among those available can be
chosen. The chatbot is implemented through addition of classes and commands as discussed
below;
select_response (): is a function selects a suitable response from a list
<code>shuffle: this is a new helper code is also added to randomly shuffle string lists
after calling seed_random_generator ()
save_prev_input () : This is a function to save present user input into a variable using the
command
(<code>m_sPrevInput) before it can fetch new inputs.
void save_prev_response () is a function added to save present response of the condition
m_sPrevResponse is fulfilled
These functions add greater functionality and versatility in the chatbot in this iteration with
encapsulation into the CBot class. Improvements are done using AI principles and even more
functionalities can be added to the chatbot to increase its intelligence and adopt human like
behavior. The ‘state’ concept is introduced where a different “state” is associated to some events
that occur during conversation. For instance, if a null input is entered by the user, the Diabot sets
itself into the “NULL INPUT**” state; if the same sentence input is repeated, the chatbot gets
into the “REPETITION T1**” state. The database has also been improved and made bigger
database. The keyword boundaries must also be addressed; for instance, if the user inputs the
term ‘Think’, the chatbot might confuse and think the keyword entered is ‘Hi’ (which is found
within ‘Think’). This is solved through the placement of a space before and after keywords in the
database or apply changes in the “find_match () function”.
The Diabot is made to start a conversation, rather than have the patient start the
conversation through ‘sign-on messages’ being added to the code; this is done by adding a new
state and suitable messages in the chatbot database (‘SIGNON**’ state). The keywords need to
be ranked to make Diabot more realistic; keyword ranking is a method that enables the chatbot to
choose the best keywords from the database if more than a single keyword can match the user
input. Equivalent keywords are then added to Diabot to make it more versatile, more so when
chosen. The chatbot is implemented through addition of classes and commands as discussed
below;
select_response (): is a function selects a suitable response from a list
<code>shuffle: this is a new helper code is also added to randomly shuffle string lists
after calling seed_random_generator ()
save_prev_input () : This is a function to save present user input into a variable using the
command
(<code>m_sPrevInput) before it can fetch new inputs.
void save_prev_response () is a function added to save present response of the condition
m_sPrevResponse is fulfilled
These functions add greater functionality and versatility in the chatbot in this iteration with
encapsulation into the CBot class. Improvements are done using AI principles and even more
functionalities can be added to the chatbot to increase its intelligence and adopt human like
behavior. The ‘state’ concept is introduced where a different “state” is associated to some events
that occur during conversation. For instance, if a null input is entered by the user, the Diabot sets
itself into the “NULL INPUT**” state; if the same sentence input is repeated, the chatbot gets
into the “REPETITION T1**” state. The database has also been improved and made bigger
database. The keyword boundaries must also be addressed; for instance, if the user inputs the
term ‘Think’, the chatbot might confuse and think the keyword entered is ‘Hi’ (which is found
within ‘Think’). This is solved through the placement of a space before and after keywords in the
database or apply changes in the “find_match () function”.
The Diabot is made to start a conversation, rather than have the patient start the
conversation through ‘sign-on messages’ being added to the code; this is done by adding a new
state and suitable messages in the chatbot database (‘SIGNON**’ state). The keywords need to
be ranked to make Diabot more realistic; keyword ranking is a method that enables the chatbot to
choose the best keywords from the database if more than a single keyword can match the user
input. Equivalent keywords are then added to Diabot to make it more versatile, more so when

keywords have a similar meaning. The chatbot is then given a list of response templates that are
liked to corresponding keywords; the templates are a blue print for building new responses for
Diabot done using wild cards in responses. Transposition is used to replace pronouns based on
syntactic analysis. A given user input can have keywords located anywhere or in specific places
for them to make sense. For instance, “how are you feeling” is a keyword that can be located
anywhere as the examples below show
How are you feeling?
And how are you feeling?
So tell me, how are you feeling?
However, keywords such as ‘what is” can be used only at the begging, for example
What is your name?
What is your blood sugar level?
The chatbot must be able to distinguish keywords based on their specific location within
sentences; this is achieved by introducing new keyword notations
Keywords that can be found only in the middle or at the beginning of a sentence are represented
by
_KEYWORD
Those only found in the middle or end of a sentence are denoted by
KEYWORD_
Those that can only be found alone in a sentence are represented by
_KEYWORD_
Keywords found anywhere in a sentence are represented by
KEYWORD
liked to corresponding keywords; the templates are a blue print for building new responses for
Diabot done using wild cards in responses. Transposition is used to replace pronouns based on
syntactic analysis. A given user input can have keywords located anywhere or in specific places
for them to make sense. For instance, “how are you feeling” is a keyword that can be located
anywhere as the examples below show
How are you feeling?
And how are you feeling?
So tell me, how are you feeling?
However, keywords such as ‘what is” can be used only at the begging, for example
What is your name?
What is your blood sugar level?
The chatbot must be able to distinguish keywords based on their specific location within
sentences; this is achieved by introducing new keyword notations
Keywords that can be found only in the middle or at the beginning of a sentence are represented
by
_KEYWORD
Those only found in the middle or end of a sentence are denoted by
KEYWORD_
Those that can only be found alone in a sentence are represented by
_KEYWORD_
Keywords found anywhere in a sentence are represented by
KEYWORD
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

The context must also be managed to the chatbot keeps track of what it said previously and
taking this into consideration when choosing the next response. A large database needs to be
stored properly and not within the program code per se; storing the database within the program
code implies any modifications to the database must be accompanies by recompiling the
program. The following lines are use to represent keywords, following the system used in the
Eliza chatbot;
Lines starting with letter; Represents
K Keywords
R Responses
S Messages
E Possible corrections
T Transpositions
N Empty responses
X Responses when chatbot fails to find matching
words
C Context of present response
W Responses for user repeating input
# Comments
This forms the database architecture and the features are implemented into the chatbot in a new
iteration.
Algorithms are required for better management of repetitions; the algorithm that has been used is
simple where it checks past responses and discards it in the present input. However, a better
algorithm is needed for long term repetition so that how long the chatbot takes to repeat a
taking this into consideration when choosing the next response. A large database needs to be
stored properly and not within the program code per se; storing the database within the program
code implies any modifications to the database must be accompanies by recompiling the
program. The following lines are use to represent keywords, following the system used in the
Eliza chatbot;
Lines starting with letter; Represents
K Keywords
R Responses
S Messages
E Possible corrections
T Transpositions
N Empty responses
X Responses when chatbot fails to find matching
words
C Context of present response
W Responses for user repeating input
# Comments
This forms the database architecture and the features are implemented into the chatbot in a new
iteration.
Algorithms are required for better management of repetitions; the algorithm that has been used is
simple where it checks past responses and discards it in the present input. However, a better
algorithm is needed for long term repetition so that how long the chatbot takes to repeat a

response can be controlled so that a response can only be repeated when all possible responses
have been used. This is done by adding the following Algorithm command
void CBot::handle_user_repetition()
{
if(same_input())
{
handle_event("REPETITION T1**");
}
else if(similar_input())
{
handle_event("REPETITION T2**");
}
}
void CBot::handle_event(std::string str)
{
save_prev_event();
set_event(str);
save_input();
set_input(str);
if(!same_event())
{
find_match();
have been used. This is done by adding the following Algorithm command
void CBot::handle_user_repetition()
{
if(same_input())
{
handle_event("REPETITION T1**");
}
else if(similar_input())
{
handle_event("REPETITION T2**");
}
}
void CBot::handle_event(std::string str)
{
save_prev_event();
set_event(str);
save_input();
set_input(str);
if(!same_event())
{
find_match();

}
restore_input();
}
By storing language (inputs) in a text database, new keywords can be added to the database ad
called upon. The conversation logs are saved so that the chatbot can be improved and learning
capability is added during chats so that its training is dynamic rather than static (done upfront
during development). This ensures that when the chatbot meets a new user input it does not have
in the database and therefore has no response or corresponding keyword, it prompts the user on
it. The user can add new keywords to the database in response to user input and hence improve
the chatbot database and range of functionality significantly. The algorithm goes as depicted
below;
1) I DID NOT GET A KEYWORD TO RESPOND TO THIS INPUT , PLEASE ENTER A
SUITABLE KEYWORD
2) THE KEYWORD IS (key)
3) (if response is no) PLEASE ENTER THE KEYWORD AGAIN (requires going back to
step 2)
4) NO RESPONSE FOUND FOR THE KEYWORD: (key), PLEASE ENTER RESPONSE
5) THE RESPONSE IS: (resp)
6) (if response is no) KINDLY ENTER THE RESPONSE (requires going back step 4)
7) THE KEYWORD AND RESPONSE HAS BEEN SUCCESSFULLY LEARNED
8) DO YOU HAVE ANOTHER KEYWORD I SHOULD LEARN?
9) (if response = yes, otherwise/ else continue chatting): KINDLY ENTER KEYWORD
(requires going back to step 2)
restore_input();
}
By storing language (inputs) in a text database, new keywords can be added to the database ad
called upon. The conversation logs are saved so that the chatbot can be improved and learning
capability is added during chats so that its training is dynamic rather than static (done upfront
during development). This ensures that when the chatbot meets a new user input it does not have
in the database and therefore has no response or corresponding keyword, it prompts the user on
it. The user can add new keywords to the database in response to user input and hence improve
the chatbot database and range of functionality significantly. The algorithm goes as depicted
below;
1) I DID NOT GET A KEYWORD TO RESPOND TO THIS INPUT , PLEASE ENTER A
SUITABLE KEYWORD
2) THE KEYWORD IS (key)
3) (if response is no) PLEASE ENTER THE KEYWORD AGAIN (requires going back to
step 2)
4) NO RESPONSE FOUND FOR THE KEYWORD: (key), PLEASE ENTER RESPONSE
5) THE RESPONSE IS: (resp)
6) (if response is no) KINDLY ENTER THE RESPONSE (requires going back step 4)
7) THE KEYWORD AND RESPONSE HAS BEEN SUCCESSFULLY LEARNED
8) DO YOU HAVE ANOTHER KEYWORD I SHOULD LEARN?
9) (if response = yes, otherwise/ else continue chatting): KINDLY ENTER KEYWORD
(requires going back to step 2)
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

The chatbot is now complete; it can be implemented in any compiler and run, taught new
words, and is versatile enough for the diabetic patients purpose
Conclusions
This research paper aimed at creating a chatbot for diabetes patients that would act as a medical
assistant. This is in response to the rising challenge of providing quality care to diabetic patients.
The challenges are due to the infrequent and little time that diabetic patients spend one on one
with their doctors (physicians) that for the US is very low at just 60 minutes per year. Patients
also visit their doctors few times in a year, with the US having an average doctor visit of just 4
times per year. Further, diabetic patients face rising costs and expenses in managing their
condition, including additional insurance and medication costs, as well as processing costs.
Further, physicians are not able to know and monitor the health indicators for their diabetic
patients hence they cannot provide adequate advice. Diabetes is a condition that requires close
management of lifestyles, diet, and medication to ensure one live a healthy normal life. Research
shows that many patients would appreciate an application that helps them make healthy choices
in their lifestyles and diets. These justified the creation of a chatbot for this project; research also
shows that chatbots can be highly effective when used in the healthcare sector/ industry as it
positively impacts healthcare outcomes. A design was made for a retrieval type chatbot because
of the simplicity in its construction. The chatbot was created in such a way that it can receive
user input, process the information, and be able to provide suitable responses based on the user
input. To determine the kind of input and key words that would be input into the chatbot, a
survey was undertaken on diabetic patients and physicians specializing in the treatment/
management of diabetes to obtain the kind of information and language that can be used for the
chatbot. The chatbot was developed based on JSON and an API created on a Google platform.
The development of the chatbot took into cognizance NLP aspects and the use of natural
language. In creating the chatbot, intents and inputs were created with as much natural language
as would allow following the principles of word processing that was managed by the principles
and concepts of Pattern matching, Algorithms, and Neural networks. From the research on
diabetes patients and physicians, the kind of words to feed into the chatbot database was created.
The chatbot was then ‘trained’, by inputting select key words and suitable word responses and
the tested to evaluate how the given answers were appropriate for the questions input. Apart from
words, and is versatile enough for the diabetic patients purpose
Conclusions
This research paper aimed at creating a chatbot for diabetes patients that would act as a medical
assistant. This is in response to the rising challenge of providing quality care to diabetic patients.
The challenges are due to the infrequent and little time that diabetic patients spend one on one
with their doctors (physicians) that for the US is very low at just 60 minutes per year. Patients
also visit their doctors few times in a year, with the US having an average doctor visit of just 4
times per year. Further, diabetic patients face rising costs and expenses in managing their
condition, including additional insurance and medication costs, as well as processing costs.
Further, physicians are not able to know and monitor the health indicators for their diabetic
patients hence they cannot provide adequate advice. Diabetes is a condition that requires close
management of lifestyles, diet, and medication to ensure one live a healthy normal life. Research
shows that many patients would appreciate an application that helps them make healthy choices
in their lifestyles and diets. These justified the creation of a chatbot for this project; research also
shows that chatbots can be highly effective when used in the healthcare sector/ industry as it
positively impacts healthcare outcomes. A design was made for a retrieval type chatbot because
of the simplicity in its construction. The chatbot was created in such a way that it can receive
user input, process the information, and be able to provide suitable responses based on the user
input. To determine the kind of input and key words that would be input into the chatbot, a
survey was undertaken on diabetic patients and physicians specializing in the treatment/
management of diabetes to obtain the kind of information and language that can be used for the
chatbot. The chatbot was developed based on JSON and an API created on a Google platform.
The development of the chatbot took into cognizance NLP aspects and the use of natural
language. In creating the chatbot, intents and inputs were created with as much natural language
as would allow following the principles of word processing that was managed by the principles
and concepts of Pattern matching, Algorithms, and Neural networks. From the research on
diabetes patients and physicians, the kind of words to feed into the chatbot database was created.
The chatbot was then ‘trained’, by inputting select key words and suitable word responses and
the tested to evaluate how the given answers were appropriate for the questions input. Apart from

the diabetic information type questions and answers, some small talk text was also added to the
word database such as a user saying
Hello
And the chatbot responding by saying
Hi there, friend
After testing, the chatbot was deployed into Facebook messenger by creating a web hook from
the developer platform and creating a unique token to run the application. In testing the chatbot,
it was noticed that it would give accurate answers sometimes, and in some cases, the responses
were not as accurate. However, the chatbot was able to fulfill the objectives and aims of this
research which was creating a diabetic chatbot to ensure better care and outcomes for diabetic
patients.
Recommendations
The chatbot creating was fairly successful in that a simple chatbot was developed that was able
to take input and provide relevant feedback. However, the chatbot can be improved further by
having a bigger word library (database) to ensure more accurate responses. Further, the chatbot
can be developed and integrated with new communications technologies such as the Internet of
Things that can be set up in wearable medical devices and enable physicians and care givers to
track the key heath indicators of the diabetic patients in real time, including the blood glucose
levels and even weight and activity. This way, the chatbot can automatically send a message to
the patient and give advice based on the readings received from wearable health monitors
connected to the chatbot through the Internet of Things (IoT)
word database such as a user saying
Hello
And the chatbot responding by saying
Hi there, friend
After testing, the chatbot was deployed into Facebook messenger by creating a web hook from
the developer platform and creating a unique token to run the application. In testing the chatbot,
it was noticed that it would give accurate answers sometimes, and in some cases, the responses
were not as accurate. However, the chatbot was able to fulfill the objectives and aims of this
research which was creating a diabetic chatbot to ensure better care and outcomes for diabetic
patients.
Recommendations
The chatbot creating was fairly successful in that a simple chatbot was developed that was able
to take input and provide relevant feedback. However, the chatbot can be improved further by
having a bigger word library (database) to ensure more accurate responses. Further, the chatbot
can be developed and integrated with new communications technologies such as the Internet of
Things that can be set up in wearable medical devices and enable physicians and care givers to
track the key heath indicators of the diabetic patients in real time, including the blood glucose
levels and even weight and activity. This way, the chatbot can automatically send a message to
the patient and give advice based on the readings received from wearable health monitors
connected to the chatbot through the Internet of Things (IoT)

References
1. Appold K. Four biggest challenges in diabetes health management [Internet]. Managed
Healthcare Executive. 2016 [cited 24 November 2017]. Available from:
http://managedhealthcareexecutive.modernmedicine.com/managed-healthcare-
executive/news/four-biggest-challenges-diabetes-health-management
2. Blonde L. Current challenges in diabetes management. Clinical Cornerstone.
2005;7(NCBI):S6-S17.
3. Newman D. Chatbots And The Future Of Conversation-Based Interfaces [Internet].
Forbes.com. 2016 [cited 23 November 2017]. Available from:
https://www.forbes.com/sites/danielnewman/2016/05/24/chatbots-and-the-future-of-
conversation-based-interfaces/#17f990ed1fc7
4. Furness D. The chatbot will see you now: AI may play doctor in the future of healthcare
[Internet]. Digital Trends. 2016 [cited 22 November 2017]. Available from:
https://www.digitaltrends.com/cool-tech/artificial-intelligence-chatbots-are-
revolutionizing-healthcare/
5. 'The Medical Futuris'. Chatbots Will Serve As Health Assistants - The Medical Futurist
[Internet]. The Medical Futurist. 2017 [cited 23 November 2017]. Available from:
http://medicalfuturist.com/chatbots-health-assistants/
6. Lee D, Oh K, Choi H. The chatbot feels you - a counseling service using emotional
response generation. IEEE Conference. 2017;1(3).
7. Cameron G, Cameron D, Megaw G, Bond R, Mulvenna M, O’Neill S et al. Towards a
chatbot for digital counselling [Internet]. Swindon: BCS Learning and Development Ltd;
2017 [cited 23 November 2017]. Available from:
http://hci2017.bcs.org/wp-content/uploads/BHCI_2017_paper_110.pdf
8. Ni L, Lu C, Liu N, Liu J. MANDY: Towards a Smart Primary Care Chatbot Application.
Knowledge and Systems Sciences. 2017;780:38-52.
9. Zaires S, Perrakis G, Bekri E, Katrakazas P, Lambrou G, Koutsouris D. Chronic Disease
Management via Mobile Apps: The Diabetes Case. In: Eskola H., Väisänen O., Viik J.,
Hyttinen J. (eds) EMBEC & NBC 2017. EMBEC 2017, NBC 2017. IFMBE Proceedings.
European Medical and Biological Engineering Confernce. 2017;65:177-180.
1. Appold K. Four biggest challenges in diabetes health management [Internet]. Managed
Healthcare Executive. 2016 [cited 24 November 2017]. Available from:
http://managedhealthcareexecutive.modernmedicine.com/managed-healthcare-
executive/news/four-biggest-challenges-diabetes-health-management
2. Blonde L. Current challenges in diabetes management. Clinical Cornerstone.
2005;7(NCBI):S6-S17.
3. Newman D. Chatbots And The Future Of Conversation-Based Interfaces [Internet].
Forbes.com. 2016 [cited 23 November 2017]. Available from:
https://www.forbes.com/sites/danielnewman/2016/05/24/chatbots-and-the-future-of-
conversation-based-interfaces/#17f990ed1fc7
4. Furness D. The chatbot will see you now: AI may play doctor in the future of healthcare
[Internet]. Digital Trends. 2016 [cited 22 November 2017]. Available from:
https://www.digitaltrends.com/cool-tech/artificial-intelligence-chatbots-are-
revolutionizing-healthcare/
5. 'The Medical Futuris'. Chatbots Will Serve As Health Assistants - The Medical Futurist
[Internet]. The Medical Futurist. 2017 [cited 23 November 2017]. Available from:
http://medicalfuturist.com/chatbots-health-assistants/
6. Lee D, Oh K, Choi H. The chatbot feels you - a counseling service using emotional
response generation. IEEE Conference. 2017;1(3).
7. Cameron G, Cameron D, Megaw G, Bond R, Mulvenna M, O’Neill S et al. Towards a
chatbot for digital counselling [Internet]. Swindon: BCS Learning and Development Ltd;
2017 [cited 23 November 2017]. Available from:
http://hci2017.bcs.org/wp-content/uploads/BHCI_2017_paper_110.pdf
8. Ni L, Lu C, Liu N, Liu J. MANDY: Towards a Smart Primary Care Chatbot Application.
Knowledge and Systems Sciences. 2017;780:38-52.
9. Zaires S, Perrakis G, Bekri E, Katrakazas P, Lambrou G, Koutsouris D. Chronic Disease
Management via Mobile Apps: The Diabetes Case. In: Eskola H., Väisänen O., Viik J.,
Hyttinen J. (eds) EMBEC & NBC 2017. EMBEC 2017, NBC 2017. IFMBE Proceedings.
European Medical and Biological Engineering Confernce. 2017;65:177-180.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

10. Surmenok P. Chatbot Architecture | [Internet]. Pavel.surmenok.com. 2016 [cited 24
November 2017]. Available from: http://pavel.surmenok.com/2016/09/11/chatbot-
architecture/
11. Boonthum-Denecke C, McCarthy P, Lamkin T. Cross-disciplinary advances in applied natural
language processing. Hershey, Pa.: IGI Global; 2012.
12. Meziane F, Métais E. Natural language processing and information systems. Berlin: Springer;
2004.
13. Blashki K, Isaias P. Emerging research and trends in interactivity and the human-computer
interface. Hershey, Pa: IGI Global; 2014.
14. Alkhafaji S. User Satisfaction on Mobile Apps: An Analytical Study on Omani Business
Environment. Archives of Business Research. 2016;4(1).
15. Shevat A. Designing bots: Creating Conversational Experiences. 1st ed. Sebastopol, CA: O'Reilly
Media;.
16. Baxter K, Courage C, Caine K. Understanding your users: A Practical Guide to User
Requirements. San Francisco: Elsevier; 2005.
17. Newell A. Design and the digital divide. [San Rafael, Calif.]: Morgan & Claypool; 2011.
18. A. S, John D. Survey on Chatbot Design Techniques in Speech Conversation Systems.
International Journal of Advanced Computer Science and Applications [Internet]. 2015;6(7).
Available from: https://thesai.org/Downloads/Volume6No7/Paper_12-
Survey_on_Chatbot_Design_Techniques_in_Speech_Conversation_Systems.pdf
19. 'A.L.I.C.E. Foundation'. AIML - The Artificial Intelligence Markup Language [Internet].
Alicebot.org. 2017 [cited 12 December 2017]. Available from: http://www.alicebot.org/aiml.html
20. Perez-Marin D, Pascual-Nieto I. Conversational agents and natural language interaction. Hershey,
PA: Information Science Reference; 2011.
21. Clark A, Fox C, Lappin S. The handbook of computational linguistics and natural language
processing. Hoboken, N.J.: Wiley-Blackwell; 2013.
November 2017]. Available from: http://pavel.surmenok.com/2016/09/11/chatbot-
architecture/
11. Boonthum-Denecke C, McCarthy P, Lamkin T. Cross-disciplinary advances in applied natural
language processing. Hershey, Pa.: IGI Global; 2012.
12. Meziane F, Métais E. Natural language processing and information systems. Berlin: Springer;
2004.
13. Blashki K, Isaias P. Emerging research and trends in interactivity and the human-computer
interface. Hershey, Pa: IGI Global; 2014.
14. Alkhafaji S. User Satisfaction on Mobile Apps: An Analytical Study on Omani Business
Environment. Archives of Business Research. 2016;4(1).
15. Shevat A. Designing bots: Creating Conversational Experiences. 1st ed. Sebastopol, CA: O'Reilly
Media;.
16. Baxter K, Courage C, Caine K. Understanding your users: A Practical Guide to User
Requirements. San Francisco: Elsevier; 2005.
17. Newell A. Design and the digital divide. [San Rafael, Calif.]: Morgan & Claypool; 2011.
18. A. S, John D. Survey on Chatbot Design Techniques in Speech Conversation Systems.
International Journal of Advanced Computer Science and Applications [Internet]. 2015;6(7).
Available from: https://thesai.org/Downloads/Volume6No7/Paper_12-
Survey_on_Chatbot_Design_Techniques_in_Speech_Conversation_Systems.pdf
19. 'A.L.I.C.E. Foundation'. AIML - The Artificial Intelligence Markup Language [Internet].
Alicebot.org. 2017 [cited 12 December 2017]. Available from: http://www.alicebot.org/aiml.html
20. Perez-Marin D, Pascual-Nieto I. Conversational agents and natural language interaction. Hershey,
PA: Information Science Reference; 2011.
21. Clark A, Fox C, Lappin S. The handbook of computational linguistics and natural language
processing. Hoboken, N.J.: Wiley-Blackwell; 2013.

22. Métais E, Meziane F, Saraee M, Sugumaran V, Vadera S. Natural Language Processing and
Information Systems. Berlin, Heidelberg: Springer Berlin Heidelberg; 2013.
23. Agerri R, Artola X, Beloki Z, Rigau G, Soroa A. Big data for Natural Language Processing: A
streaming approach. Knowledge-Based Systems. 2015;79:36-42.
24. Elvir M, Gonzalez A, Walls C, Wilder B. Remembering a Conversation – A Conversational
Memory Architecture for Embodied Conversational Agents. Journal of Intelligent Systems.
2017;26(1):1-21.
Information Systems. Berlin, Heidelberg: Springer Berlin Heidelberg; 2013.
23. Agerri R, Artola X, Beloki Z, Rigau G, Soroa A. Big data for Natural Language Processing: A
streaming approach. Knowledge-Based Systems. 2015;79:36-42.
24. Elvir M, Gonzalez A, Walls C, Wilder B. Remembering a Conversation – A Conversational
Memory Architecture for Embodied Conversational Agents. Journal of Intelligent Systems.
2017;26(1):1-21.

References
https://chatbotslife.com/chatbots-will-make-healthcare-more-patient-centric-7eaa16f617f3
https://chatbotsmagazine.com/the-complete-beginner-s-guide-to-chatbots-8280b7b906ca
https://chatbotslife.com/chatbots-will-make-healthcare-more-patient-centric-7eaa16f617f3
https://chatbotsmagazine.com/the-complete-beginner-s-guide-to-chatbots-8280b7b906ca
1 out of 43
Related Documents

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.