Data Analysis of Success Factors
VerifiedAdded on 2020/05/16
|9
|1107
|181
AI Summary
This assignment analyzes success factors using logistic regression and k-means clustering techniques. It investigates the influence of gender, age, and education on success, applying a logistic regression model to determine significant predictors. Additionally, it utilizes k-means clustering to segment cases based on these variables, providing insights into distinct groups with varying success probabilities. The analysis includes a detailed model summary, variable coefficients, and interpretations of the findings.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Running head: ASSIGNMENT
Assignment
Name of the student
Name of the university
Author’s note
Assignment
Name of the student
Name of the university
Author’s note
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

1ASSIGNMENT
Table of Contents
Introduction:....................................................................................................................................2
What is k-means clustering?........................................................................................................2
K-means clustering in healthcare industries:...............................................................................3
Discussion and Analysis:.................................................................................................................5
k-means............................................................................................................................................5
Logistic Regression.........................................................................................................................6
Table of Contents
Introduction:....................................................................................................................................2
What is k-means clustering?........................................................................................................2
K-means clustering in healthcare industries:...............................................................................3
Discussion and Analysis:.................................................................................................................5
k-means............................................................................................................................................5
Logistic Regression.........................................................................................................................6

2ASSIGNMENT
K-means Clustering
Introduction:
What is k-means clustering?
K-means clustering helps to partition a given dataset through a certain number of clusters
(assumed k clusters) for a fixed priori. Clustering is grouping of objects into different clusters.
We define a total of k-clusters, one for each cluster. The centroids must be placed in such a way
that different outcomes come from different locations. The better way of k-means clustering is to
place the clusters as much far as it could be. We have to re-calculate k new centroids as
barycentres of the clusters resulting from the previous stage. The previous two steps are repeated
until the centroids fluctuate. It generates a separate group of objects into groups from which the
metric is to be minimised. The mathematical formulation for K-means algorithm is given as-
The algorithm is significantly sensitive to the initial randomly chosen cluster centres. K-
means clustering is a simple algorithm that has been adapted to many problem domains.
K-means Clustering
Introduction:
What is k-means clustering?
K-means clustering helps to partition a given dataset through a certain number of clusters
(assumed k clusters) for a fixed priori. Clustering is grouping of objects into different clusters.
We define a total of k-clusters, one for each cluster. The centroids must be placed in such a way
that different outcomes come from different locations. The better way of k-means clustering is to
place the clusters as much far as it could be. We have to re-calculate k new centroids as
barycentres of the clusters resulting from the previous stage. The previous two steps are repeated
until the centroids fluctuate. It generates a separate group of objects into groups from which the
metric is to be minimised. The mathematical formulation for K-means algorithm is given as-
The algorithm is significantly sensitive to the initial randomly chosen cluster centres. K-
means clustering is a simple algorithm that has been adapted to many problem domains.

3ASSIGNMENT
The process of k-means clustering
K-means clustering in healthcare industries:
K-means clustering would combine the locations of maximum prone segments into
clusters and define a centre of cluster for each cluster, which would be the locations where the
emergency units would open. These clusters centres are the centroids of each cluster. Centroids
are at a minimum distance from all the points of a determined cluster. The emergency wards of
the hospital would be at minimum distance from all the accident probable areas within a cluster.
Patients could be segmented into k-means as per their satisfaction level as provided in their
response. The clustering may assist healthcare administrative leaders to determine the
characteristic required to consider the executive effective healthcare delivery. To uphold the
satisfaction of patients, maintain high quality healthcare services and minimise the cost of
healthcare delivery, k-means clustering is found to be an effective tool for the healthcare
administrative care.
With the help of cluster analysis, probable correlations are explored in relation to the
characteristics of patients, care-related factors and outcomes of patients. For instance, the study
The process of k-means clustering
K-means clustering in healthcare industries:
K-means clustering would combine the locations of maximum prone segments into
clusters and define a centre of cluster for each cluster, which would be the locations where the
emergency units would open. These clusters centres are the centroids of each cluster. Centroids
are at a minimum distance from all the points of a determined cluster. The emergency wards of
the hospital would be at minimum distance from all the accident probable areas within a cluster.
Patients could be segmented into k-means as per their satisfaction level as provided in their
response. The clustering may assist healthcare administrative leaders to determine the
characteristic required to consider the executive effective healthcare delivery. To uphold the
satisfaction of patients, maintain high quality healthcare services and minimise the cost of
healthcare delivery, k-means clustering is found to be an effective tool for the healthcare
administrative care.
With the help of cluster analysis, probable correlations are explored in relation to the
characteristics of patients, care-related factors and outcomes of patients. For instance, the study
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

4ASSIGNMENT
inspects the potential influence of time to surgery on the results of patients within the generated
clusters of patients. K-means clustering claims to serve necessary requirements for healthcare
administration to develop more patient-oriented care strategies (Elbattah and Molloy, 2018).
Clustering treatment choices within a cohort of patients takes data-driven decisions. The
discovered clusters help to utilise the prediction models. Variables like Gender, Age, Education
and success of 1000 patients help to construct classification tree.
The k-means clustering utilises a simple iterative technique to group points in a dataset
into clusters that contain equal types of characteristics. The length of stay (LOS) and time to
inspects the potential influence of time to surgery on the results of patients within the generated
clusters of patients. K-means clustering claims to serve necessary requirements for healthcare
administration to develop more patient-oriented care strategies (Elbattah and Molloy, 2018).
Clustering treatment choices within a cohort of patients takes data-driven decisions. The
discovered clusters help to utilise the prediction models. Variables like Gender, Age, Education
and success of 1000 patients help to construct classification tree.
The k-means clustering utilises a simple iterative technique to group points in a dataset
into clusters that contain equal types of characteristics. The length of stay (LOS) and time to

5ASSIGNMENT
surgery (TTS) measures the quality of medical and hospital services for the k-means extension
(Aarsland et al. 2007).
We can conclude that cluster analysis proposes a multidimensional approach for
detecting best approach that exhibit differences in clinical response to treatment algorithms
(Obenshain, 2004).
Discussion and Analysis:
For doing the calculations, the following codes are used:
1. gender is coded as male – 1, female - 2
2. age is coded as M – 1, O – 2 and Y – 3
3. Education is coded as G – 1, HS – 2 and UG – 3
4. Success is coded as Yes – 1 and No - 2
k-means
The analysis of the k-means clustering shows that there are two clusters centres.
Final Cluster Centers
Cluster
1 2
Gender 1.32 1.69
Age 1.52 2.45
Education 1.59 2.42
The number of cases in Cluster 1 is 502 and in cluster 2 is 498.
surgery (TTS) measures the quality of medical and hospital services for the k-means extension
(Aarsland et al. 2007).
We can conclude that cluster analysis proposes a multidimensional approach for
detecting best approach that exhibit differences in clinical response to treatment algorithms
(Obenshain, 2004).
Discussion and Analysis:
For doing the calculations, the following codes are used:
1. gender is coded as male – 1, female - 2
2. age is coded as M – 1, O – 2 and Y – 3
3. Education is coded as G – 1, HS – 2 and UG – 3
4. Success is coded as Yes – 1 and No - 2
k-means
The analysis of the k-means clustering shows that there are two clusters centres.
Final Cluster Centers
Cluster
1 2
Gender 1.32 1.69
Age 1.52 2.45
Education 1.59 2.42
The number of cases in Cluster 1 is 502 and in cluster 2 is 498.
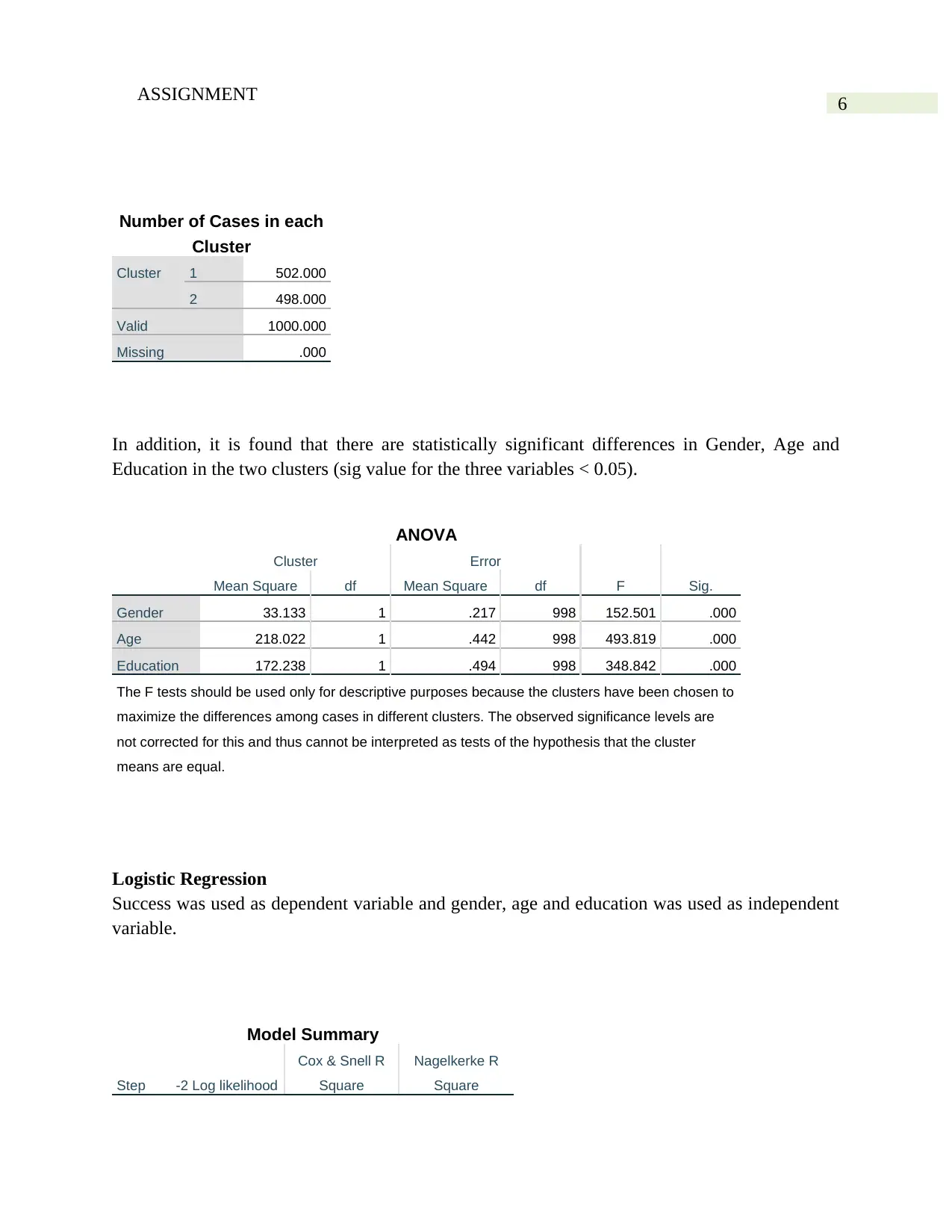
6ASSIGNMENT
Number of Cases in each
Cluster
Cluster 1 502.000
2 498.000
Valid 1000.000
Missing .000
In addition, it is found that there are statistically significant differences in Gender, Age and
Education in the two clusters (sig value for the three variables < 0.05).
ANOVA
Cluster Error
F Sig.Mean Square df Mean Square df
Gender 33.133 1 .217 998 152.501 .000
Age 218.022 1 .442 998 493.819 .000
Education 172.238 1 .494 998 348.842 .000
The F tests should be used only for descriptive purposes because the clusters have been chosen to
maximize the differences among cases in different clusters. The observed significance levels are
not corrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster
means are equal.
Logistic Regression
Success was used as dependent variable and gender, age and education was used as independent
variable.
Model Summary
Step -2 Log likelihood
Cox & Snell R
Square
Nagelkerke R
Square
Number of Cases in each
Cluster
Cluster 1 502.000
2 498.000
Valid 1000.000
Missing .000
In addition, it is found that there are statistically significant differences in Gender, Age and
Education in the two clusters (sig value for the three variables < 0.05).
ANOVA
Cluster Error
F Sig.Mean Square df Mean Square df
Gender 33.133 1 .217 998 152.501 .000
Age 218.022 1 .442 998 493.819 .000
Education 172.238 1 .494 998 348.842 .000
The F tests should be used only for descriptive purposes because the clusters have been chosen to
maximize the differences among cases in different clusters. The observed significance levels are
not corrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster
means are equal.
Logistic Regression
Success was used as dependent variable and gender, age and education was used as independent
variable.
Model Summary
Step -2 Log likelihood
Cox & Snell R
Square
Nagelkerke R
Square
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7ASSIGNMENT
1 1240.255a .122 .163
a. Estimation terminated at iteration number 4 because
parameter estimates changed by less than .001.
16.3% of the variance can be outcome(Nagelkerke pseudo-R2).
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a Gender .658 .138 22.854 1 .000 1.931
Age .036 .084 .186 1 .667 1.037
Education .867 .087 99.017 1 .000 2.379
Constant -3.096 .339 83.306 1 .000 .045
a. Variable(s) entered on step 1: Gender, Age, Education.
From the above table the probability of success is given as
log ( success
1−success )=0.658∗Gender+ 0.036∗Age+0.867∗Education−3.096
1 1240.255a .122 .163
a. Estimation terminated at iteration number 4 because
parameter estimates changed by less than .001.
16.3% of the variance can be outcome(Nagelkerke pseudo-R2).
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a Gender .658 .138 22.854 1 .000 1.931
Age .036 .084 .186 1 .667 1.037
Education .867 .087 99.017 1 .000 2.379
Constant -3.096 .339 83.306 1 .000 .045
a. Variable(s) entered on step 1: Gender, Age, Education.
From the above table the probability of success is given as
log ( success
1−success )=0.658∗Gender+ 0.036∗Age+0.867∗Education−3.096

8ASSIGNMENT
References:
Aarsland, D., Brønnick, K., Ehrt, U., De Deyn, P. P., Tekin, S., Emre, M., & Cummings, J. L.
(2007). Neuropsychiatric symptoms in patients with Parkinson’s disease and dementia:
frequency, profile and associated care giver stress. Journal of Neurology, Neurosurgery
& Psychiatry, 78(1), 36-42.
Elbattah, M., & Molloy, O. (2018). Data-driven patient segmentation using K-means clustering.
Retrieved 3 February 2018.
Obenshain, M. K. (2004). Application of data mining techniques to healthcare data. Infection
Control & Hospital Epidemiology, 25(8), 690-695.
References:
Aarsland, D., Brønnick, K., Ehrt, U., De Deyn, P. P., Tekin, S., Emre, M., & Cummings, J. L.
(2007). Neuropsychiatric symptoms in patients with Parkinson’s disease and dementia:
frequency, profile and associated care giver stress. Journal of Neurology, Neurosurgery
& Psychiatry, 78(1), 36-42.
Elbattah, M., & Molloy, O. (2018). Data-driven patient segmentation using K-means clustering.
Retrieved 3 February 2018.
Obenshain, M. K. (2004). Application of data mining techniques to healthcare data. Infection
Control & Hospital Epidemiology, 25(8), 690-695.
1 out of 9
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.