UGB108 Quantitative Methods for Business Alternative Assessment
VerifiedAdded on 2023/01/11
|7
|1091
|93
Report
AI Summary
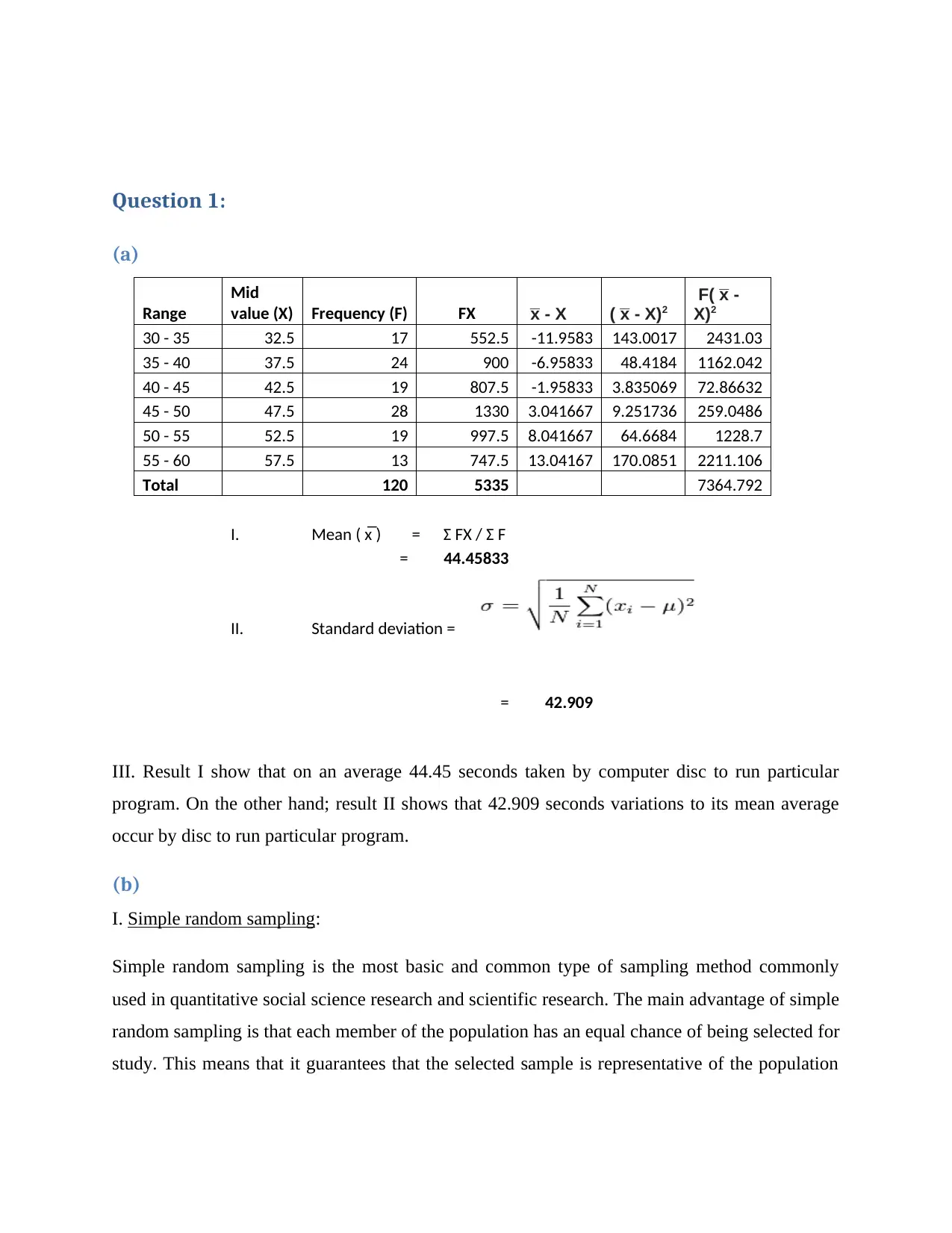
This report presents a comprehensive solution to a Quantitative Methods for Business assignment, addressing key concepts and techniques. The report begins with a detailed analysis of statistical measures, including calculating the mean and standard deviation from grouped data, and interprets the results. It then explores different sampling methods, such as simple random sampling, quota sampling, sample frames, and cluster sampling, providing definitions and applications for each. The report further delves into regression analysis, explaining the meaning of regression coefficients and applying them to predict costs and make informed decisions. Finally, it tackles probability problems, calculating the probability of events using probability rules. The solutions are presented with clear explanations and calculations, demonstrating the application of quantitative methods in business contexts. The assignment covers topics like descriptive statistics, sampling techniques, regression analysis, and probability.






1 out of 7
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.