MBA Quantitative Techniques Report: Central Tendency and Dispersion
VerifiedAdded on 2021/01/22
|9
|1826
|65
Report
AI Summary
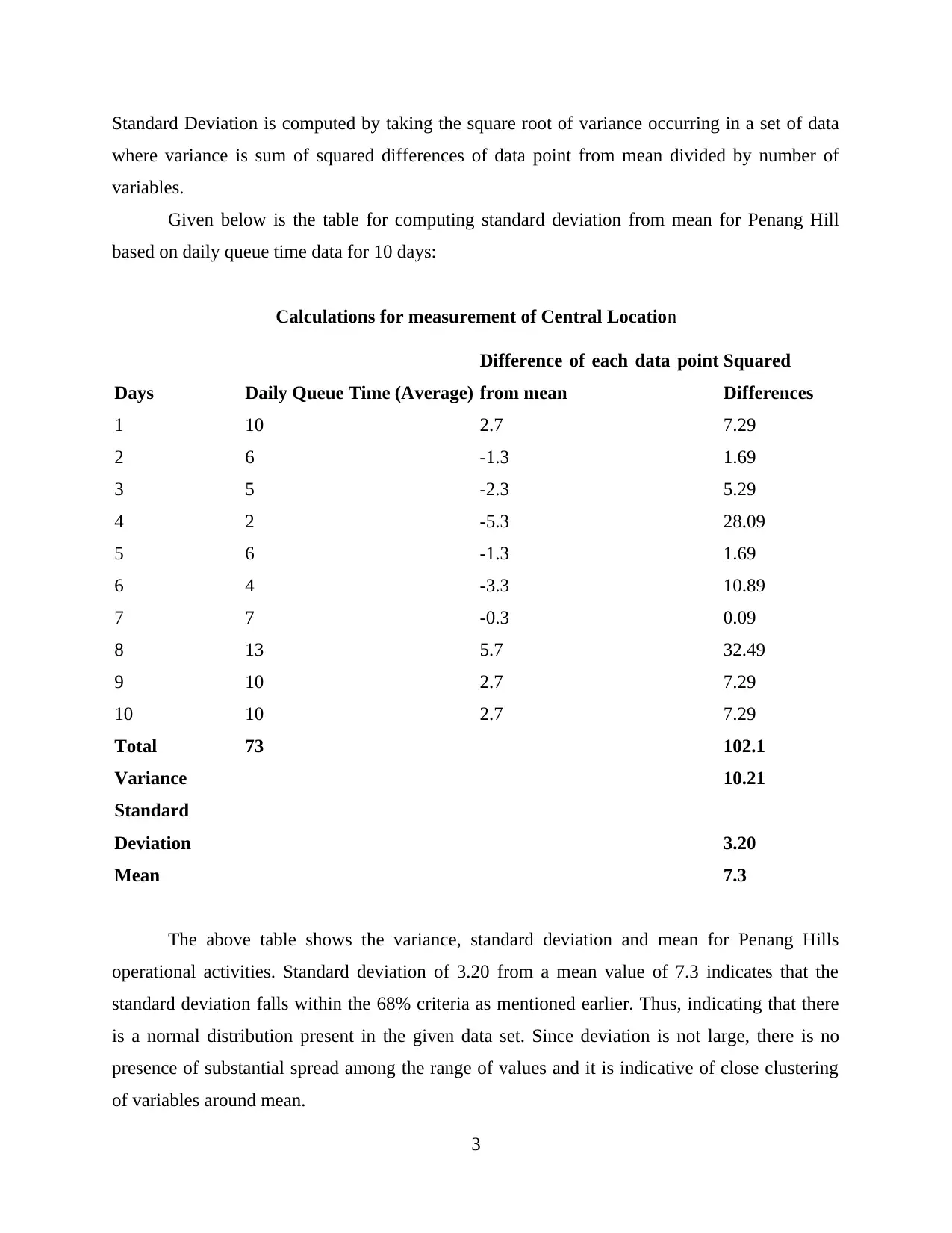
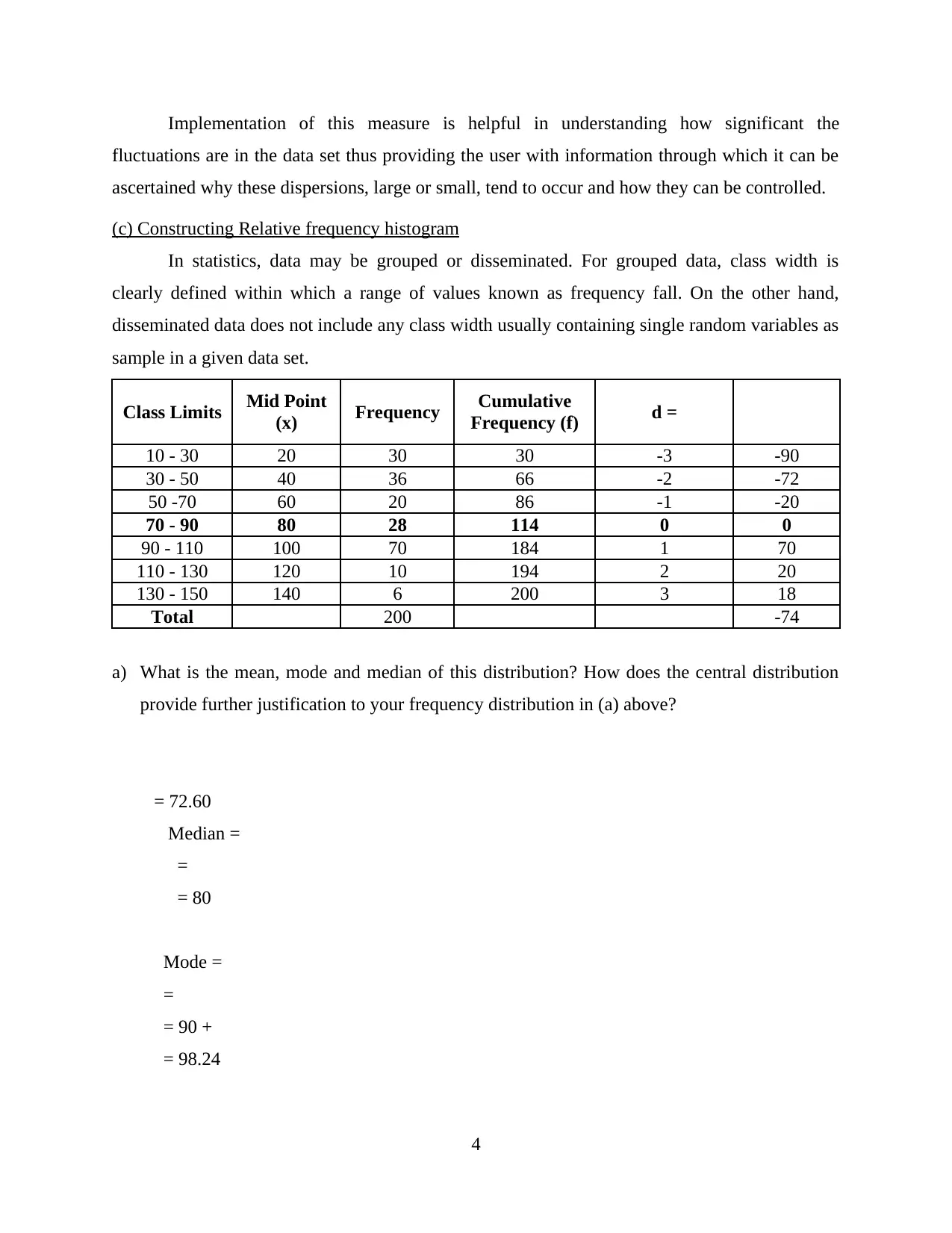
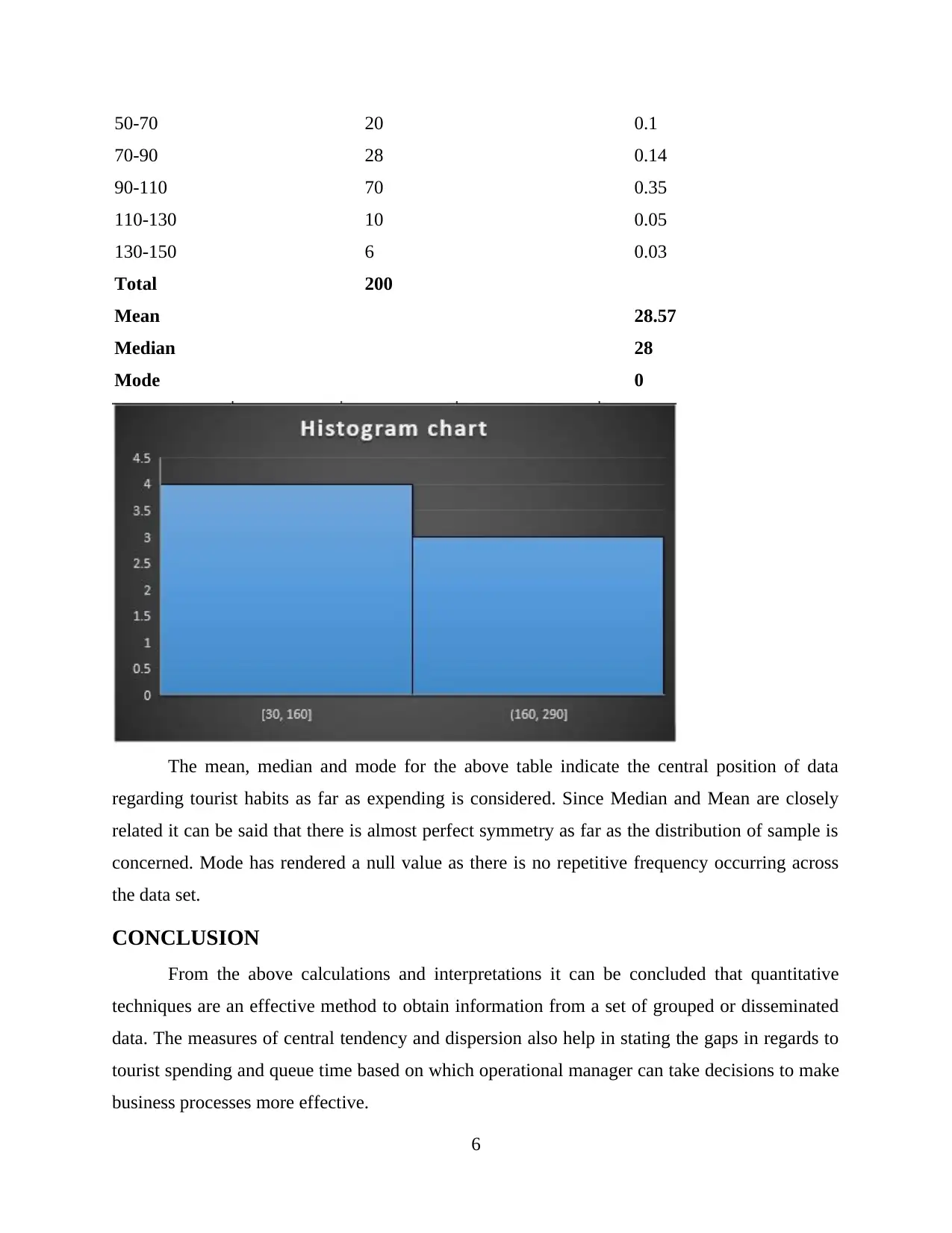
This report provides an analysis of quantitative techniques, focusing on data from Penang Hill. It begins by computing measurements of central location, including mean, median, and mode, to understand average queue times. The report then calculates and implements standard deviation to assess the dispersion of queue times, improving the precision of data recording. Furthermore, it constructs a relative frequency histogram to visualize the distribution of data and interprets the results in relation to the calculated mean, median, and mode. The analysis includes calculations for both grouped and ungrouped data, offering insights into tourist spending habits and queue times, and concludes with recommendations for operational improvements. This report showcases the application of statistical methods to derive meaningful conclusions from collected data, supporting business decision-making.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.