Logistic Regression Analysis for Survey Data Variables
VerifiedAdded on 2022/11/01
|8
|1152
|205
AI Summary
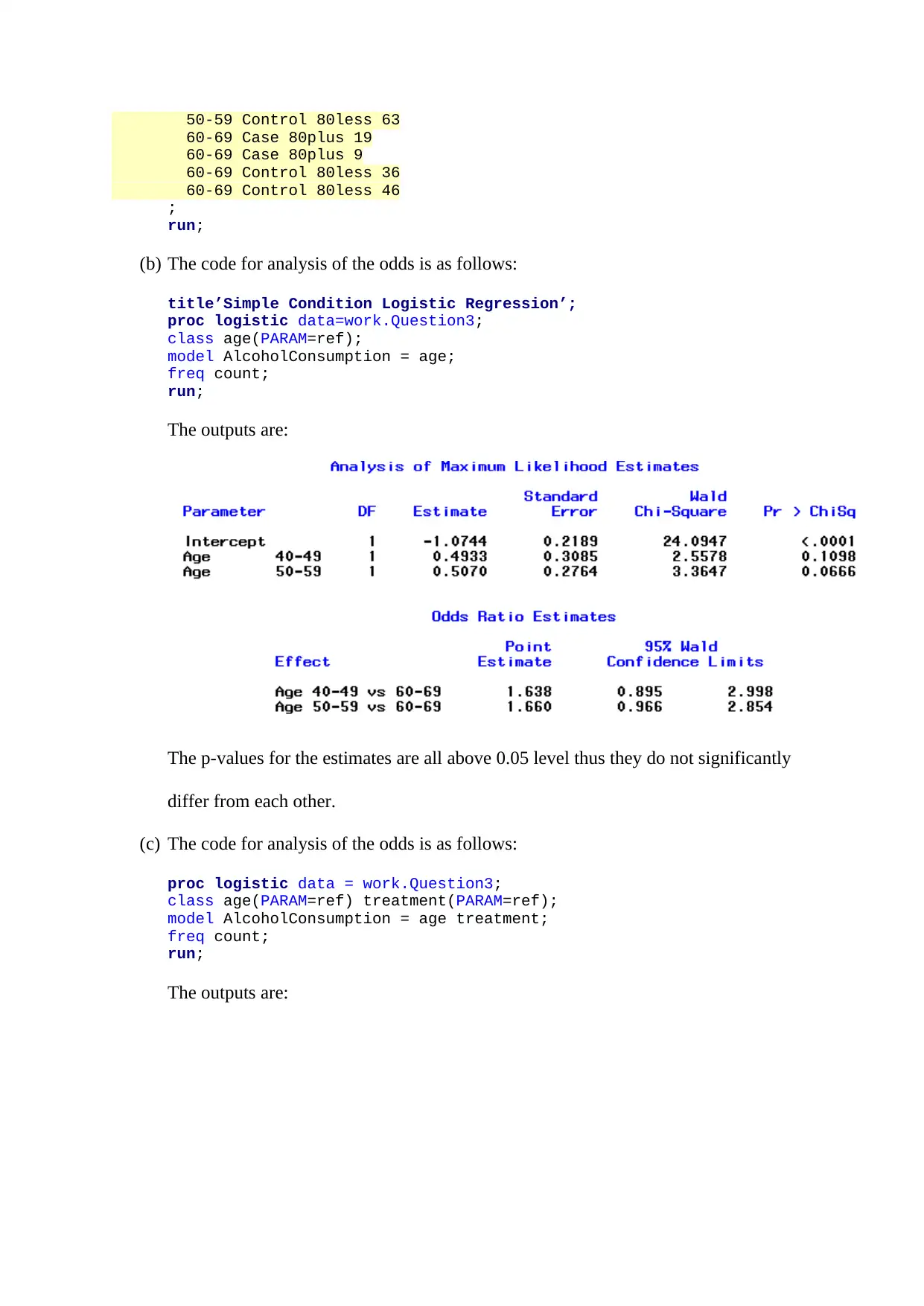
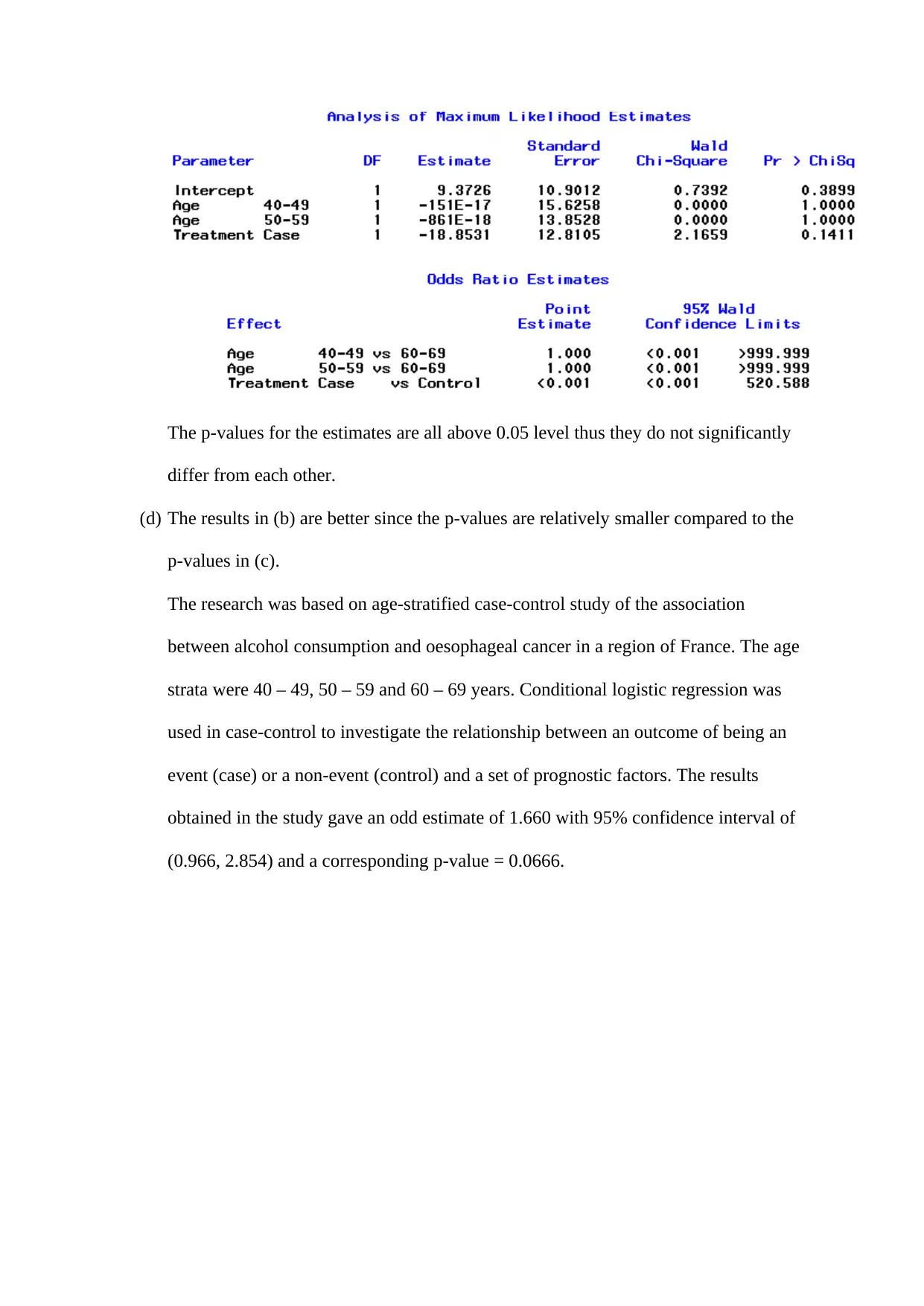
Learn how to perform logistic regression analysis on survey data variables using SAS syntax. Obtain descriptive statistics and coefficient estimates for the model. Find out the odds ratio and predicted probabilities for significant variables. Also, calculate the area under the ROC curve and proportion of correct predictions. Get insights into the analysis of odds for age-stratified case-control study of the association between alcohol consumption and oesophageal cancer in a region of France.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.


1 out of 8

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.