Statistical Analysis Using R: ANOVA, Kruskal-Wallis, Chi-Square
VerifiedAdded on 2023/05/30
|8
|1235
|432
Practical Assignment
AI Summary
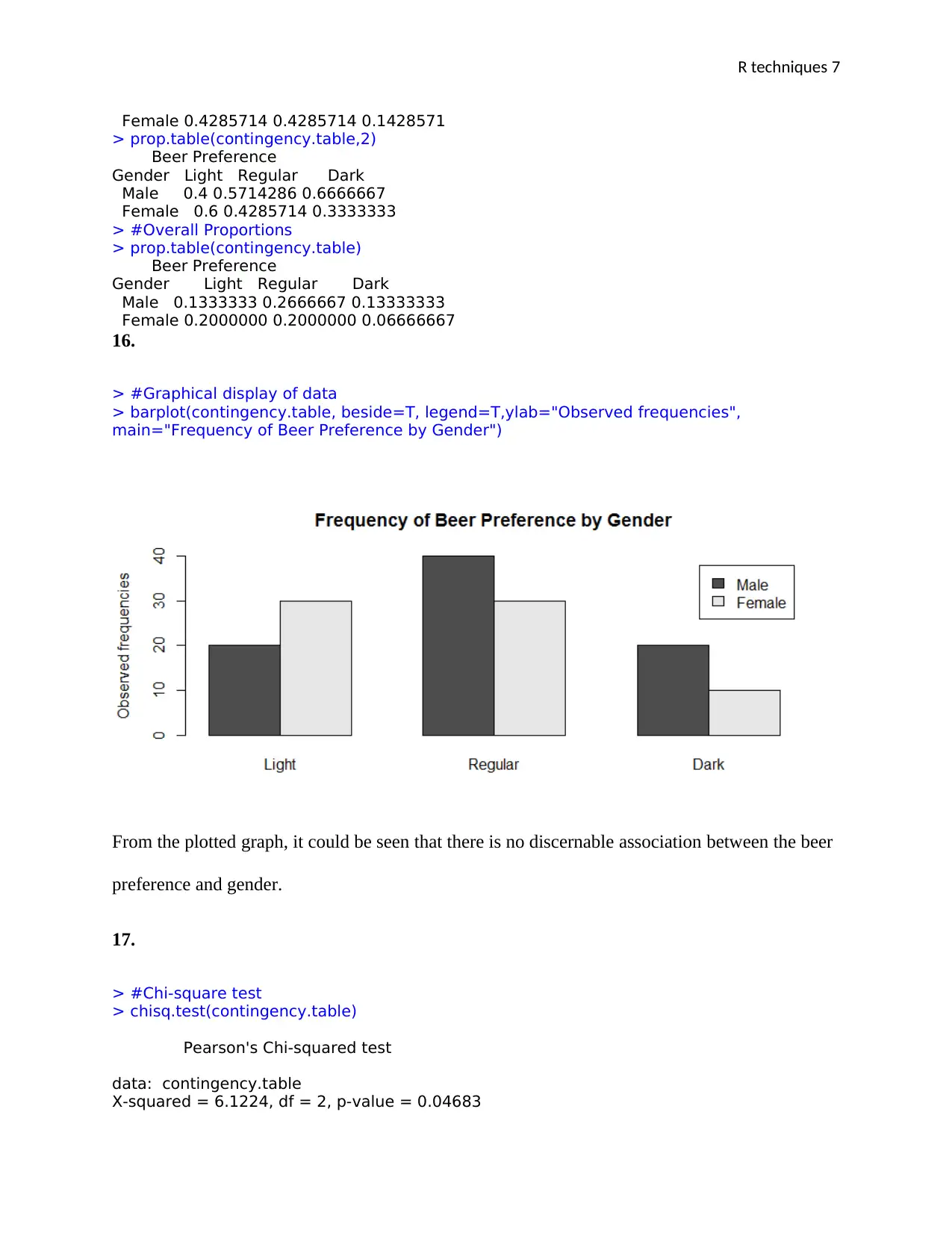
This assignment demonstrates the application of several statistical techniques using R. It includes an Analysis of Variance (ANOVA) to compare the mean scores of different professions, checking for normality and equal variance assumptions before conducting the ANOVA and post-hoc tests. Additionally, a Kruskal-Wallis test is performed to assess differences in wine prices across different types. Finally, a Chi-Square test is used to determine the dependence between gender and beer preference, including data entry, proportion calculations, graphical display, and interpretation of the test results. The assignment includes R code and interpretations of the output, providing a comprehensive guide to performing these statistical analyses in R.







1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.