University Project: Recommended System Evaluations - Offline vs Online
VerifiedAdded on 2020/05/28
|13
|5636
|190
Project
AI Summary
This project delves into the evaluation of recommender systems, contrasting offline and online methodologies. It begins by outlining the problem and providing background on the evolution of recommender systems, including a historical perspective and a comparison of evaluation techniques. The project explores offline evaluations in detail, discussing methodologies, research design, and data collection methods. It also examines various evaluation metrics such as precision, recall, and CTR. The project's methodology section provides an overview of the different levels of investigation that can be used to compare recommenders. The project highlights the importance of choosing appropriate evaluation methods and the potential discrepancies between offline and online results. The project aims to provide a comprehensive understanding of the challenges and considerations in evaluating recommender systems and offers a practical guide to their implementation and assessment.

Running head: RECOMMENDED SYSTEM EVALUATIONS - OFFLINE VS ONLINE
Project Title - Recommended System evaluations: Offline vs Online
Name of the Student:
Name of the University:
Project Title - Recommended System evaluations: Offline vs Online
Name of the Student:
Name of the University:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
Table of Contents
Problem description.........................................................................................................................2
Background......................................................................................................................................2
Evolution of recommender systems.............................................................................................2
History of previous studies on recommender systems................................................................3
Comparison of Online and Offline evaluations...........................................................................3
Analysis of Offline Evaluations...................................................................................................4
Methodology....................................................................................................................................5
Overview......................................................................................................................................5
Research Design..........................................................................................................................5
Research Method.........................................................................................................................6
Data collection.............................................................................................................................7
Project deliverable...........................................................................................................................8
References......................................................................................................................................11
Table of Contents
Problem description.........................................................................................................................2
Background......................................................................................................................................2
Evolution of recommender systems.............................................................................................2
History of previous studies on recommender systems................................................................3
Comparison of Online and Offline evaluations...........................................................................3
Analysis of Offline Evaluations...................................................................................................4
Methodology....................................................................................................................................5
Overview......................................................................................................................................5
Research Design..........................................................................................................................5
Research Method.........................................................................................................................6
Data collection.............................................................................................................................7
Project deliverable...........................................................................................................................8
References......................................................................................................................................11

2RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
Problem description
The emergence and expansion of e-commerce along with online media over the past
years have given rise to Recommender systems. Recommender systems would now be able to be
found in numerous modern applications that open the client to an enormous accumulations of
things. Such frameworks commonly give the client a rundown of suggested things they may lean
toward, or anticipate the amount they may favor everything. These frameworks help clients to
settle on proper things, and facilitate the task of finding favored things in the accumulation
(Adomavicius and Tuzhilin 2015). Recommender frameworks are presently well known both
economically and in the examination group, where numerous methodologies have been proposed
for giving proposals. As a rule a framework creator that desires to utilize a proposal framework
must pick between an arrangements of applicant approaches. An initial move towards choosing a
suitable calculation is to choose which properties of the application to center upon when settling
on this decision. In fact, suggestion frameworks have an assortment of properties that may
influence client encounter, for example, precision, power, adaptability, etc (Wang, Wang and
Yeung 2015). Offline assessments are the most well-known assessment strategy for investigate
paper recommender frameworks. However, no intensive discourse on the propriety of offline
assessments has occurred, notwithstanding some voiced feedback. Numerous examinations have
been led in which assessment of different suggestion approaches with both offline and online
assessments are represented. The aftereffects of offline and online assessments regularly
repudiate each other. It has been presumed that offline assessments might be wrong to evaluate
investigate paper recommender frameworks, in numerous settings.
Background
Evolution of recommender systems
Although the principal recommender frameworks were initially intended for news
discussions, the writing depicting real executions and assessments feeding at live news sites is
not regular contrasted with the general writing on recommender frameworks. Adomavicius and
Kwon (2015), break down the organization of a cross breed recommender framework on Google
News which is a news aggregator. They think about their strategy against the current collective
sifting framework actualized by Amatriain and Pujol (2015), and consider just signed in clients
for the assessment. They demonstrate a 30% change over the current community oriented
separating framework. Beel et al. (2016), directed an online assessment with signed in clients of
a few recommender frameworks for news articles on Forbes.com. They report that a cross breed
framework plays out the best, with a 37% change over prominence based techniques. Schaffer,
Hollerer and O'Donovan (2015), think about the week after week and hourly impressions and
navigate rates in news recommender system of the Plista, which conveys proposals to numerous
news sites. They watch out for live assessment and check whether it is touchy to outer variables
not really identified with proposals. They likewise recognize inclines in suggestions identified
with the kind of news sites (conventional or theme centered news sources). Users of point
centered sites are less inclined to take suggestions than users of conventional news sites. Sadly, it
is not clear which recommender calculation is utilized as a part of the Plista structure and their
examination. The assessment by Rubens et al. (2015), is like the one of Adomavicius and Kwon
(2015), yet varies in two essential focuses. To start with, they considered unknown clients who
are difficult to track over various visits. For the second point, it can be said that the nature of
Problem description
The emergence and expansion of e-commerce along with online media over the past
years have given rise to Recommender systems. Recommender systems would now be able to be
found in numerous modern applications that open the client to an enormous accumulations of
things. Such frameworks commonly give the client a rundown of suggested things they may lean
toward, or anticipate the amount they may favor everything. These frameworks help clients to
settle on proper things, and facilitate the task of finding favored things in the accumulation
(Adomavicius and Tuzhilin 2015). Recommender frameworks are presently well known both
economically and in the examination group, where numerous methodologies have been proposed
for giving proposals. As a rule a framework creator that desires to utilize a proposal framework
must pick between an arrangements of applicant approaches. An initial move towards choosing a
suitable calculation is to choose which properties of the application to center upon when settling
on this decision. In fact, suggestion frameworks have an assortment of properties that may
influence client encounter, for example, precision, power, adaptability, etc (Wang, Wang and
Yeung 2015). Offline assessments are the most well-known assessment strategy for investigate
paper recommender frameworks. However, no intensive discourse on the propriety of offline
assessments has occurred, notwithstanding some voiced feedback. Numerous examinations have
been led in which assessment of different suggestion approaches with both offline and online
assessments are represented. The aftereffects of offline and online assessments regularly
repudiate each other. It has been presumed that offline assessments might be wrong to evaluate
investigate paper recommender frameworks, in numerous settings.
Background
Evolution of recommender systems
Although the principal recommender frameworks were initially intended for news
discussions, the writing depicting real executions and assessments feeding at live news sites is
not regular contrasted with the general writing on recommender frameworks. Adomavicius and
Kwon (2015), break down the organization of a cross breed recommender framework on Google
News which is a news aggregator. They think about their strategy against the current collective
sifting framework actualized by Amatriain and Pujol (2015), and consider just signed in clients
for the assessment. They demonstrate a 30% change over the current community oriented
separating framework. Beel et al. (2016), directed an online assessment with signed in clients of
a few recommender frameworks for news articles on Forbes.com. They report that a cross breed
framework plays out the best, with a 37% change over prominence based techniques. Schaffer,
Hollerer and O'Donovan (2015), think about the week after week and hourly impressions and
navigate rates in news recommender system of the Plista, which conveys proposals to numerous
news sites. They watch out for live assessment and check whether it is touchy to outer variables
not really identified with proposals. They likewise recognize inclines in suggestions identified
with the kind of news sites (conventional or theme centered news sources). Users of point
centered sites are less inclined to take suggestions than users of conventional news sites. Sadly, it
is not clear which recommender calculation is utilized as a part of the Plista structure and their
examination. The assessment by Rubens et al. (2015), is like the one of Adomavicius and Kwon
(2015), yet varies in two essential focuses. To start with, they considered unknown clients who
are difficult to track over various visits. For the second point, it can be said that the nature of
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
websites like swissinfo.cha and Forbes.com are different based on the unique practices of the
users.
History of previous studies on recommender systems
In the previous 14 years, over 170 research articles had been distributed about the
recommender frameworks of research paper, and in 2013 alone, an expected 30 new articles are
relied upon to show up in this field. The more suggestion approaches are proposed, the more
vital their assessment progresses toward becoming to decide the best performing approaches and
their individual qualities and shortcomings (Gavalas et al. 2014). Deciding the 'best'
recommender framework is not insignificant and there are three primary assessment techniques,
specifically client thinks about, online assessments, and offline assessments to quantify
recommender frameworks quality. In client contemplates, clients expressly rate proposals created
by various calculations and the calculation with the most astounding normal rating is viewed as
the best calculation. Client ponders ordinarily request that their members evaluate their general
fulfillment with the proposals. A client study may likewise request that of member’s rate
reasonable they are for non-specialists (Guy 2015). Then again, a client study can gather
subjective input, but since this approach is once in a while utilized for recommender framework
assessments, it will not be tended to further. Note that client examines measure client fulfillment
at the season of proposal. They do not quantify the precision of a recommender framework since
clients do not have the unclear idea, at the season of the rating, regardless of whether a given
suggestion truly was the most significant.
Comparison of Online and Offline evaluations
In online assessments, suggestions are appeared to genuine clients of the framework amid
their session. Clients do not rate proposals however the recommender framework watches how
regularly a client acknowledges a suggestion. Acknowledgment is most generally estimated by
active visitor clicking percentage (CTR), i.e. the proportion of clicked suggestions. For example,
if a framework shows 10,000 suggestions and 120 are clicked, the CTR is 1.2%. To look at two
calculations, suggestions are made utilizing every calculation and the CTR of the calculations is
analyzed (A/B test) (Zhang et al. 2016). Beside client considers, online assessments certainly
measure client fulfillment, and can straightforwardly be utilized to gauge income if
recommender frameworks apply a compensation for every snap plot. Offline assessments utilize
pre-accumulated offline datasets from which some data has been evacuated. Hence, the
recommender calculations are broke down on their capacity to prescribe the missing data. There
are three sorts of offline datasets are characterized as (1) genuine offline datasets, (2) client
offline dataset, and (3) master offline datasets.
'Genuine offline informational indexes' started in the field of cooperative sifting where
clients expressly rate things (e.g. films). Genuine offline datasets contain a rundown of clients
and their appraisals of things. To assess a recommender framework, a few appraisals are
expelled, and the recommender framework makes proposals in view of the data remaining (Yang
et al. 2014). The greater amount of the evacuated appraisals the recommender predicts
accurately, the better the calculation. The suspicion behind this strategy is that if a recommender
can precisely anticipated some known appraisals, it ought to likewise dependably foresee other,
obscure, evaluations. The clients regularly do not rate inquire about articles within the topic of
research paper recommender frameworks. Thusly, there are no evident offline datasets. To defeat
this issue, verifiable appraisals normally are deduced from client activities.
websites like swissinfo.cha and Forbes.com are different based on the unique practices of the
users.
History of previous studies on recommender systems
In the previous 14 years, over 170 research articles had been distributed about the
recommender frameworks of research paper, and in 2013 alone, an expected 30 new articles are
relied upon to show up in this field. The more suggestion approaches are proposed, the more
vital their assessment progresses toward becoming to decide the best performing approaches and
their individual qualities and shortcomings (Gavalas et al. 2014). Deciding the 'best'
recommender framework is not insignificant and there are three primary assessment techniques,
specifically client thinks about, online assessments, and offline assessments to quantify
recommender frameworks quality. In client contemplates, clients expressly rate proposals created
by various calculations and the calculation with the most astounding normal rating is viewed as
the best calculation. Client ponders ordinarily request that their members evaluate their general
fulfillment with the proposals. A client study may likewise request that of member’s rate
reasonable they are for non-specialists (Guy 2015). Then again, a client study can gather
subjective input, but since this approach is once in a while utilized for recommender framework
assessments, it will not be tended to further. Note that client examines measure client fulfillment
at the season of proposal. They do not quantify the precision of a recommender framework since
clients do not have the unclear idea, at the season of the rating, regardless of whether a given
suggestion truly was the most significant.
Comparison of Online and Offline evaluations
In online assessments, suggestions are appeared to genuine clients of the framework amid
their session. Clients do not rate proposals however the recommender framework watches how
regularly a client acknowledges a suggestion. Acknowledgment is most generally estimated by
active visitor clicking percentage (CTR), i.e. the proportion of clicked suggestions. For example,
if a framework shows 10,000 suggestions and 120 are clicked, the CTR is 1.2%. To look at two
calculations, suggestions are made utilizing every calculation and the CTR of the calculations is
analyzed (A/B test) (Zhang et al. 2016). Beside client considers, online assessments certainly
measure client fulfillment, and can straightforwardly be utilized to gauge income if
recommender frameworks apply a compensation for every snap plot. Offline assessments utilize
pre-accumulated offline datasets from which some data has been evacuated. Hence, the
recommender calculations are broke down on their capacity to prescribe the missing data. There
are three sorts of offline datasets are characterized as (1) genuine offline datasets, (2) client
offline dataset, and (3) master offline datasets.
'Genuine offline informational indexes' started in the field of cooperative sifting where
clients expressly rate things (e.g. films). Genuine offline datasets contain a rundown of clients
and their appraisals of things. To assess a recommender framework, a few appraisals are
expelled, and the recommender framework makes proposals in view of the data remaining (Yang
et al. 2014). The greater amount of the evacuated appraisals the recommender predicts
accurately, the better the calculation. The suspicion behind this strategy is that if a recommender
can precisely anticipated some known appraisals, it ought to likewise dependably foresee other,
obscure, evaluations. The clients regularly do not rate inquire about articles within the topic of
research paper recommender frameworks. Thusly, there are no evident offline datasets. To defeat
this issue, verifiable appraisals normally are deduced from client activities.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

4RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
For example, if a client composes an exploration paper and refers to different articles, the
references are translated as positive votes of the referred to articles. To assess a recommender
framework, the articles a client has referred to are expelled from his wrote paper. At that point,
proposals are created (e.g. in light of the content in the composed paper) and the greater amount
of the missing references are suggested the more precise the recommender is. Rather than papers
and references, some other report accumulations might be used (Lika, Kolomvatsos and
Hadjiefthymiades 2014). For example, if clients oversee explore articles utilizing a reference
administration programming, for example, JabRef or Zotero, a few (or all) of the clients' articles
could be expelled and proposals could be made utilizing the rest of the data. This kind of dataset
is called 'client offline dataset' on the grounds that it is construed from the clients' choice whether
to refer to, tag, store, and so forth an article.
The third sort of datasets, which is called 'master offline datasets', are those made by
specialists. Cases of such datasets incorporate TREC or the MeSH grouping. In these datasets,
papers are ordinarily arranged by human specialists as per data needs. In MeSH, for example,
terms from a controlled vocabulary (illustrative of the data needs) are appointed to papers (Zeng
et al. 2015). Papers with a similar MeSH terms are considered profoundly comparable. For an
assessment, the data need of the client must be resolved and the greater amount of the papers
fulfilling the data require are suggested, the better. As opposed to client considers and online
assessments, offline assessments measure the exactness of a recommender framework. Offline
datasets are viewed as a ground-truth that speaks to the perfect arrangement of papers to be
prescribed.
For example, in the past case, it has been accepted that the articles a writer refers to are
those articles to be best suggested. Subsequently, the less of the writer referred to articles are
anticipated by the recommender framework, the less precise it is. To quantify exactness,
accuracy at position n (P@n) is normally used to express what number of the significant articles
were prescribed inside the best n consequences of the recommender (Ricci, Rokach and Shapira
2015). Other regular assessment measurements incorporate review, F-measure, mean
corresponding rank (MRR) and standardized reduced aggregate pick up (NDCG). Just MRR and
NDCG consider the position of proposals in the produced suggestion list. For a thorough
diagram of offline assessments including assessment measurements and potential issues refer to.
Analysis of Offline Evaluations
Ordinarily, offline assessments are intended to distinguish the most encouraging
suggestion approaches. These most encouraging methodologies should then be assessed in more
detail with a client examine or an online assessment to distinguish the best methodologies. In any
case, it has been discovered that most methodologies are just assessed with offline assessments,
rendering the outcomes uneven (Zhang and Min 2016). Moreover, a few contentions have been
voiced that offline assessments are not satisfactory to assess recommender frameworks. Research
demonstrates that offline assessments and client examines some of the time repudiate each other.
This implies, calculations that performed well in offline assessments did not generally perform
well in client examines. This is a difficult issue. In the event that offline assessments could not
dependably foresee a calculation's execution and subsequently cannot satisfy their motivation in
a client consider or an online assessment, the inquiry emerges for what they are great.
Regularly it is simplest to carry out offline investigations utilizing accessible
informational collections and a convention which models client conduct to evaluate
For example, if a client composes an exploration paper and refers to different articles, the
references are translated as positive votes of the referred to articles. To assess a recommender
framework, the articles a client has referred to are expelled from his wrote paper. At that point,
proposals are created (e.g. in light of the content in the composed paper) and the greater amount
of the missing references are suggested the more precise the recommender is. Rather than papers
and references, some other report accumulations might be used (Lika, Kolomvatsos and
Hadjiefthymiades 2014). For example, if clients oversee explore articles utilizing a reference
administration programming, for example, JabRef or Zotero, a few (or all) of the clients' articles
could be expelled and proposals could be made utilizing the rest of the data. This kind of dataset
is called 'client offline dataset' on the grounds that it is construed from the clients' choice whether
to refer to, tag, store, and so forth an article.
The third sort of datasets, which is called 'master offline datasets', are those made by
specialists. Cases of such datasets incorporate TREC or the MeSH grouping. In these datasets,
papers are ordinarily arranged by human specialists as per data needs. In MeSH, for example,
terms from a controlled vocabulary (illustrative of the data needs) are appointed to papers (Zeng
et al. 2015). Papers with a similar MeSH terms are considered profoundly comparable. For an
assessment, the data need of the client must be resolved and the greater amount of the papers
fulfilling the data require are suggested, the better. As opposed to client considers and online
assessments, offline assessments measure the exactness of a recommender framework. Offline
datasets are viewed as a ground-truth that speaks to the perfect arrangement of papers to be
prescribed.
For example, in the past case, it has been accepted that the articles a writer refers to are
those articles to be best suggested. Subsequently, the less of the writer referred to articles are
anticipated by the recommender framework, the less precise it is. To quantify exactness,
accuracy at position n (P@n) is normally used to express what number of the significant articles
were prescribed inside the best n consequences of the recommender (Ricci, Rokach and Shapira
2015). Other regular assessment measurements incorporate review, F-measure, mean
corresponding rank (MRR) and standardized reduced aggregate pick up (NDCG). Just MRR and
NDCG consider the position of proposals in the produced suggestion list. For a thorough
diagram of offline assessments including assessment measurements and potential issues refer to.
Analysis of Offline Evaluations
Ordinarily, offline assessments are intended to distinguish the most encouraging
suggestion approaches. These most encouraging methodologies should then be assessed in more
detail with a client examine or an online assessment to distinguish the best methodologies. In any
case, it has been discovered that most methodologies are just assessed with offline assessments,
rendering the outcomes uneven (Zhang and Min 2016). Moreover, a few contentions have been
voiced that offline assessments are not satisfactory to assess recommender frameworks. Research
demonstrates that offline assessments and client examines some of the time repudiate each other.
This implies, calculations that performed well in offline assessments did not generally perform
well in client examines. This is a difficult issue. In the event that offline assessments could not
dependably foresee a calculation's execution and subsequently cannot satisfy their motivation in
a client consider or an online assessment, the inquiry emerges for what they are great.
Regularly it is simplest to carry out offline investigations utilizing accessible
informational collections and a convention which models client conduct to evaluate

5RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
recommender execution procedures, for example, expectation exactness (Borras, Moreno and
Valls 2014). A more costly choice is a client contemplate, where a little arrangement of clients is
solicited to play out a set from assignments utilizing the framework, commonly noting questions
a short time later about their experience. At last, extensive scale tests can be keep running on a
sent framework, which is called online examinations. Such trials assess the execution of the
recommenders on genuine clients which are careless in regards to the conducted exploration.
Methodology
Overview
In this segment three levels of investigations are depicted that can be utilized as a part of
request to look at a few recommenders. The dialog underneath is inspired by assessment
conventions in related regions, for example, machine learning and data recovery, featuring hones
significant to assessing proposal frameworks. The reader is contacted for productions in these
fields and for more detailed exchanges (Campos, Díez and Cantador 2014). Offline examinations
can be begun, which are ordinarily the most effortless to direct, as they require no cooperation
with genuine clients. At that point client studies will be portrayed, where a little gathering of
subjects will be requested to utilize the framework in a controlled situation, and after that write
about their experience. In such analyses both quantitative and subjective data can be gathered
about the frameworks, yet mind must be taken to think about different inclinations in the
exploratory plan. At long last, maybe the most reliable analysis is the point at which the
framework is utilized by a pool of genuine clients, ordinarily ignorant of the investigation. While
in such an investigation just certain kinds of information can be gathered, this trial configuration
is nearest to reality.
Research Design
In every test situation, it is imperative to take after a couple of essential rules when all is
said in done test contemplates.
Hypothesis: Before running the investigation there is have to frame a speculation. It is
essential for being succinct and prohibitive about the following speculation, and plans a test that
examines and evaluates the theory. For instance, a theory can be that calculation A superior
predicts client evaluations than calculation B (Son 2016). All things considered, the analysis
should test the forecast exactness, and no different components.
Controlling factors: When looking at a couple of applicant calculations on a specific
theory, it is critical that all factors that are not tried will remain settled. For instance, assume that
correlation will be led for the expectation exactness of motion picture evaluations of calculation
A and calculation B, that both utilize diverse communication separating models (Wu et al. 2016).
Besides that A is centered around the MovieLens informational index, and B on the Netflix
informational index, and calculation A presents unrivaled execution, it is not conceivable to
advise whether the execution was because of the predominant CF display, or because of the
better information, or both. Along these lines center must be around the calculations on similar
informational collection (or over fair examples from similar informational index), or prepare
similar calculations over the two unique informational collections, with a specific end goal to
comprehend the reason for the predominant execution.
Generalization: When making inferences from tests, it might be wanted that conclusions
sum up past the quick setting of the analyses. While picking a calculation for a genuine
recommender execution procedures, for example, expectation exactness (Borras, Moreno and
Valls 2014). A more costly choice is a client contemplate, where a little arrangement of clients is
solicited to play out a set from assignments utilizing the framework, commonly noting questions
a short time later about their experience. At last, extensive scale tests can be keep running on a
sent framework, which is called online examinations. Such trials assess the execution of the
recommenders on genuine clients which are careless in regards to the conducted exploration.
Methodology
Overview
In this segment three levels of investigations are depicted that can be utilized as a part of
request to look at a few recommenders. The dialog underneath is inspired by assessment
conventions in related regions, for example, machine learning and data recovery, featuring hones
significant to assessing proposal frameworks. The reader is contacted for productions in these
fields and for more detailed exchanges (Campos, Díez and Cantador 2014). Offline examinations
can be begun, which are ordinarily the most effortless to direct, as they require no cooperation
with genuine clients. At that point client studies will be portrayed, where a little gathering of
subjects will be requested to utilize the framework in a controlled situation, and after that write
about their experience. In such analyses both quantitative and subjective data can be gathered
about the frameworks, yet mind must be taken to think about different inclinations in the
exploratory plan. At long last, maybe the most reliable analysis is the point at which the
framework is utilized by a pool of genuine clients, ordinarily ignorant of the investigation. While
in such an investigation just certain kinds of information can be gathered, this trial configuration
is nearest to reality.
Research Design
In every test situation, it is imperative to take after a couple of essential rules when all is
said in done test contemplates.
Hypothesis: Before running the investigation there is have to frame a speculation. It is
essential for being succinct and prohibitive about the following speculation, and plans a test that
examines and evaluates the theory. For instance, a theory can be that calculation A superior
predicts client evaluations than calculation B (Son 2016). All things considered, the analysis
should test the forecast exactness, and no different components.
Controlling factors: When looking at a couple of applicant calculations on a specific
theory, it is critical that all factors that are not tried will remain settled. For instance, assume that
correlation will be led for the expectation exactness of motion picture evaluations of calculation
A and calculation B, that both utilize diverse communication separating models (Wu et al. 2016).
Besides that A is centered around the MovieLens informational index, and B on the Netflix
informational index, and calculation A presents unrivaled execution, it is not conceivable to
advise whether the execution was because of the predominant CF display, or because of the
better information, or both. Along these lines center must be around the calculations on similar
informational collection (or over fair examples from similar informational index), or prepare
similar calculations over the two unique informational collections, with a specific end goal to
comprehend the reason for the predominant execution.
Generalization: When making inferences from tests, it might be wanted that conclusions
sum up past the quick setting of the analyses. While picking a calculation for a genuine
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

6RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
application, it might be wanted that conclusions hang on the sent framework, and sum up past the
test informational index (Aggarwal 2016). Correspondingly, when growing new calculations, it
is needed that conclusions hold past the extent of the particular application or informational
index that is tested. To expand the likelihood of speculation of the outcomes try must be
normally done with a few informational collections or applications (Aggarwal 2016). It is vital to
comprehend the properties of the different informational collections that are utilized. As a rule,
the more assorted the information utilized, the more speculation of results will be accomplished.
Research Method
Offline evaluations
An offline investigation is carried out by utilizing a pre-gathered informational index of
clients picking or rating things. Utilizing this informational index the conduct of clients can be
reproduced that connect with a suggestion framework. In doing as such, it will be expected that
the client conduct when the information was gathered will be sufficiently comparative to the
client conduct when the recommender framework is conveyed, so solid choices can be made in
view of the recreation (Beel and Langer 2015). Offline analyses are appealing on the grounds
that they require no cooperation with genuine clients, and in this way permits to look at an
extensive variety of hopeful calculations easily. The drawback of offline tests is that they can
answer an extremely limit set of inquiries, ordinarily inquiries concerning the expectation energy
of a calculation. Specifically, it must be accepted that clients' conduct while collaborating with a
framework including the recommender framework picked will be demonstrated well by the
clients' conduct before that framework's arrangement. Along these lines the recommender's effect
on client conduct cannot be specifically estimated in this setting (Garcin et al. 2014). Along
these lines, the objective of the offline investigations is to sift through wrong methodologies,
leaving a moderately little arrangement of hopeful calculations to be tried by the all the more
expensive client thinks about or online analyses. An ordinary case of this procedure is the point
at which the constraints of the calculations are converted to an offline trial, and after that the
calculation providing the best constraints would proceed to the following stage.
Online evaluations
A number of critical proposal applications, the planner would wish to form the impact on
the client in the framework. Along these lines, in this investigation of the premium for adjusting
the conductance of the client had been formed along with formation of the connection within
various mediums (Maksai, Garcin and Faltings 2015). The clients of one system would take the
regular proposals of client’s framework and also form the framework for surpassing the
accumulated framework from the assembled utility. The regular proposals from the client might
overtake the functionality of the clients of other system framework and it can be presumed that
one system functionalities are better than that of the other. The authentic impact on the system
framework would allow the formation of the assortments of the effective variables and formation
of the operations. The specific conditions of the clients would result in forming the proposals of
the interface development (Rossetti, Stella and Zanker 2016). The dependable deployment of the
effective management methods had resulted in listing the proficiency of the testing of the
application based on the testing methods. The frameworks would allow the development of the
improve development methods.
application, it might be wanted that conclusions hang on the sent framework, and sum up past the
test informational index (Aggarwal 2016). Correspondingly, when growing new calculations, it
is needed that conclusions hold past the extent of the particular application or informational
index that is tested. To expand the likelihood of speculation of the outcomes try must be
normally done with a few informational collections or applications (Aggarwal 2016). It is vital to
comprehend the properties of the different informational collections that are utilized. As a rule,
the more assorted the information utilized, the more speculation of results will be accomplished.
Research Method
Offline evaluations
An offline investigation is carried out by utilizing a pre-gathered informational index of
clients picking or rating things. Utilizing this informational index the conduct of clients can be
reproduced that connect with a suggestion framework. In doing as such, it will be expected that
the client conduct when the information was gathered will be sufficiently comparative to the
client conduct when the recommender framework is conveyed, so solid choices can be made in
view of the recreation (Beel and Langer 2015). Offline analyses are appealing on the grounds
that they require no cooperation with genuine clients, and in this way permits to look at an
extensive variety of hopeful calculations easily. The drawback of offline tests is that they can
answer an extremely limit set of inquiries, ordinarily inquiries concerning the expectation energy
of a calculation. Specifically, it must be accepted that clients' conduct while collaborating with a
framework including the recommender framework picked will be demonstrated well by the
clients' conduct before that framework's arrangement. Along these lines the recommender's effect
on client conduct cannot be specifically estimated in this setting (Garcin et al. 2014). Along
these lines, the objective of the offline investigations is to sift through wrong methodologies,
leaving a moderately little arrangement of hopeful calculations to be tried by the all the more
expensive client thinks about or online analyses. An ordinary case of this procedure is the point
at which the constraints of the calculations are converted to an offline trial, and after that the
calculation providing the best constraints would proceed to the following stage.
Online evaluations
A number of critical proposal applications, the planner would wish to form the impact on
the client in the framework. Along these lines, in this investigation of the premium for adjusting
the conductance of the client had been formed along with formation of the connection within
various mediums (Maksai, Garcin and Faltings 2015). The clients of one system would take the
regular proposals of client’s framework and also form the framework for surpassing the
accumulated framework from the assembled utility. The regular proposals from the client might
overtake the functionality of the clients of other system framework and it can be presumed that
one system functionalities are better than that of the other. The authentic impact on the system
framework would allow the formation of the assortments of the effective variables and formation
of the operations. The specific conditions of the clients would result in forming the proposals of
the interface development (Rossetti, Stella and Zanker 2016). The dependable deployment of the
effective management methods had resulted in listing the proficiency of the testing of the
application based on the testing methods. The frameworks would allow the development of the
improve development methods.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
Data collection
Sampling method
As the objective of the offline assessment was for forming the channel calculations, the
information utilized for the offline assessment should coordinate as nearly as conceivable the
information the originator anticipates that the recommender framework will confront when sent
on the web. Care must be practiced to guarantee that there is no inclination in the circulations of
clients, things and evaluations chosen (Gebremeskel and de Vries 2016). Taking consideration of
the scenario where the deployment of the improved functions would allow the integration of the
activities and formation of the pre-channel development model. The integration of the activities
would allow the formation of the operations. The allowance of the activities would result in
forming the lower and exclusive experimenter development model.
In the event that vital, randomly sampling users and things might be a best technique for
diminishing information, in spite of the fact that this can likewise bring different inclinations into
the investigation. In some cases, known inclinations in the information can be redressed for by
methods, for example, reweighing information, yet rectifying predispositions in the information
is frequently troublesome (Kille et al. 2015). Another wellspring of inclination might be simply
the information accumulation. For instance, clients might probably rate things that they have
solid feelings on, and a few clients may give numerous a bigger number of appraisals than
others. Consequently, the arrangement of things on which express evaluations are accessible
might be one-sided by the appraisals themselves. By and by, strategies, for example, resampling
or reweighting the test information might be utilized to endeavor to right such inclinations.
Observation
Numerous proposal approaches depend on the cooperation of clients with the framework.
It is extremely hard to make a dependable reenactment of client's connections with the
framework, and in this manner, offline testing are hard to lead. So as to legitimately assess such
frameworks, genuine client cooperation’s with the framework must be gathered (van Egmond,
Intelligentie and Kanoulas 2015). Notwithstanding when offline testing is conceivable,
cooperation’s with genuine clients can at present give extra data about the framework execution.
In these cases we commonly direct client considers. A client consider is led by enlisting an
arrangement of guinea pig, and requesting that they play out a few undertakings requiring a
cooperation with the proposal framework. While the subjects play out the assignments, their
conduct will be watched and recorded, gathering any number of quantitative estimations, for
example, what segment of the undertaking was finished, the precision of the task comes about, or
the time taken to play out the undertaking. By and large we can make subjective inquiries,
previously, amid, and after the undertaking is finished (Massimo et al. 2017). Such inquiries can
gather information that is not specifically discernible, for example, regardless of whether the
subject delighted in the UI, or whether the client saw the undertaking as simple to finish.
Questionnaire
Client contemplates permits to utilize the effective survey apparatus. Earlier, amid, and
following subjects play out their errands we can get some information regarding their experience.
These inquiries can give data related to properties that were hard to gauge, for example, the
subject's perspective, or whether the subject delighted in the framework (Beel et al. 2016). While
these inquiries can give profitable data, they can likewise give deluding data. It is essential to
Data collection
Sampling method
As the objective of the offline assessment was for forming the channel calculations, the
information utilized for the offline assessment should coordinate as nearly as conceivable the
information the originator anticipates that the recommender framework will confront when sent
on the web. Care must be practiced to guarantee that there is no inclination in the circulations of
clients, things and evaluations chosen (Gebremeskel and de Vries 2016). Taking consideration of
the scenario where the deployment of the improved functions would allow the integration of the
activities and formation of the pre-channel development model. The integration of the activities
would allow the formation of the operations. The allowance of the activities would result in
forming the lower and exclusive experimenter development model.
In the event that vital, randomly sampling users and things might be a best technique for
diminishing information, in spite of the fact that this can likewise bring different inclinations into
the investigation. In some cases, known inclinations in the information can be redressed for by
methods, for example, reweighing information, yet rectifying predispositions in the information
is frequently troublesome (Kille et al. 2015). Another wellspring of inclination might be simply
the information accumulation. For instance, clients might probably rate things that they have
solid feelings on, and a few clients may give numerous a bigger number of appraisals than
others. Consequently, the arrangement of things on which express evaluations are accessible
might be one-sided by the appraisals themselves. By and by, strategies, for example, resampling
or reweighting the test information might be utilized to endeavor to right such inclinations.
Observation
Numerous proposal approaches depend on the cooperation of clients with the framework.
It is extremely hard to make a dependable reenactment of client's connections with the
framework, and in this manner, offline testing are hard to lead. So as to legitimately assess such
frameworks, genuine client cooperation’s with the framework must be gathered (van Egmond,
Intelligentie and Kanoulas 2015). Notwithstanding when offline testing is conceivable,
cooperation’s with genuine clients can at present give extra data about the framework execution.
In these cases we commonly direct client considers. A client consider is led by enlisting an
arrangement of guinea pig, and requesting that they play out a few undertakings requiring a
cooperation with the proposal framework. While the subjects play out the assignments, their
conduct will be watched and recorded, gathering any number of quantitative estimations, for
example, what segment of the undertaking was finished, the precision of the task comes about, or
the time taken to play out the undertaking. By and large we can make subjective inquiries,
previously, amid, and after the undertaking is finished (Massimo et al. 2017). Such inquiries can
gather information that is not specifically discernible, for example, regardless of whether the
subject delighted in the UI, or whether the client saw the undertaking as simple to finish.
Questionnaire
Client contemplates permits to utilize the effective survey apparatus. Earlier, amid, and
following subjects play out their errands we can get some information regarding their experience.
These inquiries can give data related to properties that were hard to gauge, for example, the
subject's perspective, or whether the subject delighted in the framework (Beel et al. 2016). While
these inquiries can give profitable data, they can likewise give deluding data. It is essential to
8RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
make impartial inquiries had not propose a "right" answer. Individuals might likewise answer
dishonestly, for instance when they saw the appropriate response as personal, or in the event that
they figure the genuine answer might place them in a critical position. Undoubtedly, tremendous
measure of research was led in different regions about the craft of survey composing, and the
readers will be referred to that writing for more points of interest.
Project deliverable
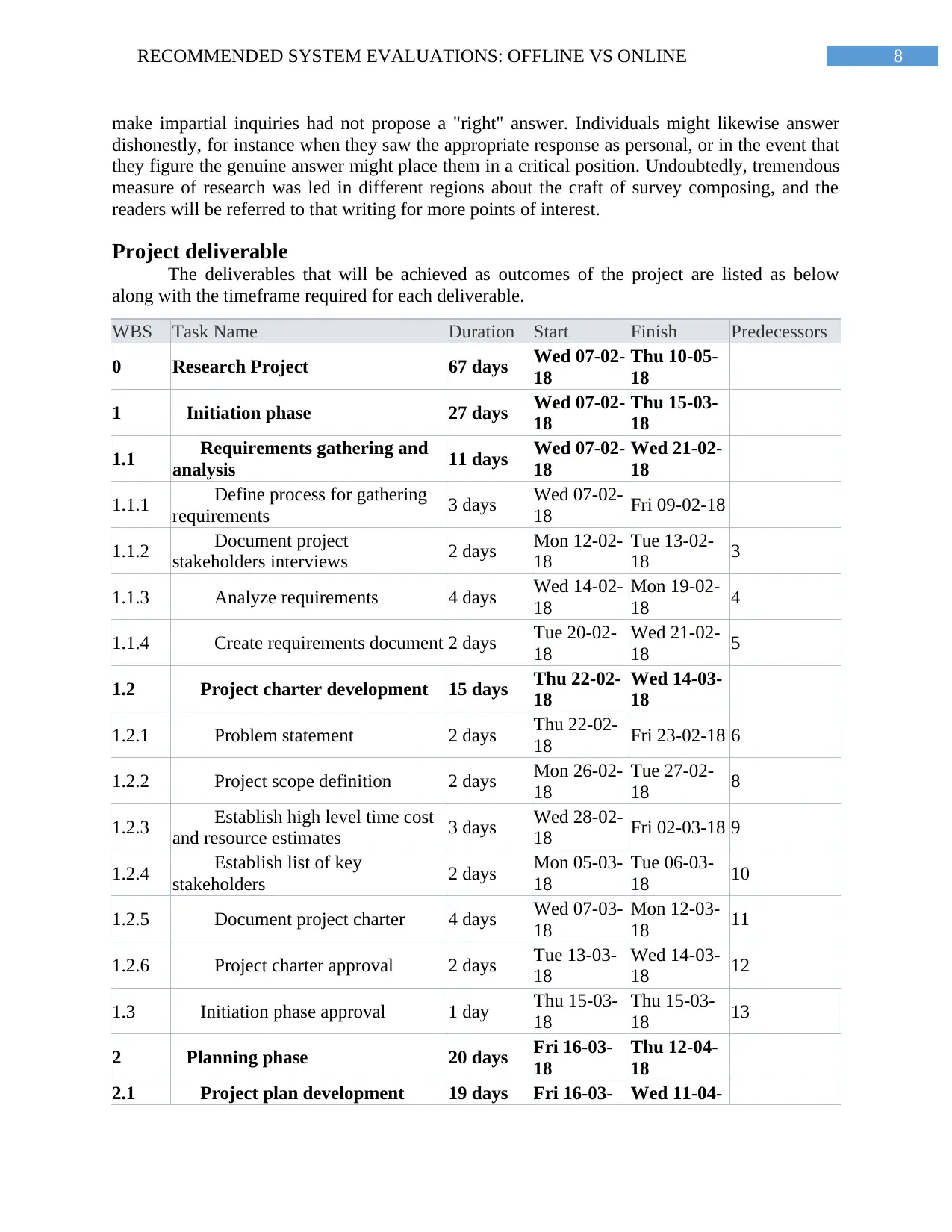
The deliverables that will be achieved as outcomes of the project are listed as below
along with the timeframe required for each deliverable.
WBS Task Name Duration Start Finish Predecessors
0 Research Project 67 days Wed 07-02-
18
Thu 10-05-
18
1 Initiation phase 27 days Wed 07-02-
18
Thu 15-03-
18
1.1 Requirements gathering and
analysis 11 days Wed 07-02-
18
Wed 21-02-
18
1.1.1 Define process for gathering
requirements 3 days Wed 07-02-
18 Fri 09-02-18
1.1.2 Document project
stakeholders interviews 2 days Mon 12-02-
18
Tue 13-02-
18 3
1.1.3 Analyze requirements 4 days Wed 14-02-
18
Mon 19-02-
18 4
1.1.4 Create requirements document 2 days Tue 20-02-
18
Wed 21-02-
18 5
1.2 Project charter development 15 days Thu 22-02-
18
Wed 14-03-
18
1.2.1 Problem statement 2 days Thu 22-02-
18 Fri 23-02-18 6
1.2.2 Project scope definition 2 days Mon 26-02-
18
Tue 27-02-
18 8
1.2.3 Establish high level time cost
and resource estimates 3 days Wed 28-02-
18 Fri 02-03-18 9
1.2.4 Establish list of key
stakeholders 2 days Mon 05-03-
18
Tue 06-03-
18 10
1.2.5 Document project charter 4 days Wed 07-03-
18
Mon 12-03-
18 11
1.2.6 Project charter approval 2 days Tue 13-03-
18
Wed 14-03-
18 12
1.3 Initiation phase approval 1 day Thu 15-03-
18
Thu 15-03-
18 13
2 Planning phase 20 days Fri 16-03-
18
Thu 12-04-
18
2.1 Project plan development 19 days Fri 16-03- Wed 11-04-
make impartial inquiries had not propose a "right" answer. Individuals might likewise answer
dishonestly, for instance when they saw the appropriate response as personal, or in the event that
they figure the genuine answer might place them in a critical position. Undoubtedly, tremendous
measure of research was led in different regions about the craft of survey composing, and the
readers will be referred to that writing for more points of interest.
Project deliverable
The deliverables that will be achieved as outcomes of the project are listed as below
along with the timeframe required for each deliverable.
WBS Task Name Duration Start Finish Predecessors
0 Research Project 67 days Wed 07-02-
18
Thu 10-05-
18
1 Initiation phase 27 days Wed 07-02-
18
Thu 15-03-
18
1.1 Requirements gathering and
analysis 11 days Wed 07-02-
18
Wed 21-02-
18
1.1.1 Define process for gathering
requirements 3 days Wed 07-02-
18 Fri 09-02-18
1.1.2 Document project
stakeholders interviews 2 days Mon 12-02-
18
Tue 13-02-
18 3
1.1.3 Analyze requirements 4 days Wed 14-02-
18
Mon 19-02-
18 4
1.1.4 Create requirements document 2 days Tue 20-02-
18
Wed 21-02-
18 5
1.2 Project charter development 15 days Thu 22-02-
18
Wed 14-03-
18
1.2.1 Problem statement 2 days Thu 22-02-
18 Fri 23-02-18 6
1.2.2 Project scope definition 2 days Mon 26-02-
18
Tue 27-02-
18 8
1.2.3 Establish high level time cost
and resource estimates 3 days Wed 28-02-
18 Fri 02-03-18 9
1.2.4 Establish list of key
stakeholders 2 days Mon 05-03-
18
Tue 06-03-
18 10
1.2.5 Document project charter 4 days Wed 07-03-
18
Mon 12-03-
18 11
1.2.6 Project charter approval 2 days Tue 13-03-
18
Wed 14-03-
18 12
1.3 Initiation phase approval 1 day Thu 15-03-
18
Thu 15-03-
18 13
2 Planning phase 20 days Fri 16-03-
18
Thu 12-04-
18
2.1 Project plan development 19 days Fri 16-03- Wed 11-04-
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

9RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
18 18
2.1.1 Scope statement 2 days Fri 16-03-
18
Mon 19-03-
18 14
2.1.2 Work Breakdown Structure 3 days Tue 20-03-
18
Thu 22-03-
18 17
2.1.3 Performance baseline
measurement 2 days Fri 23-03-
18
Mon 26-03-
18 18
2.1.4 Procurement planning 4 days Tue 27-03-
18 Fri 30-03-18 19
2.1.5 Project schedule plan 2 days Mon 02-04-
18
Tue 03-04-
18 20
2.1.6 Resource management 2 days Wed 04-04-
18
Thu 05-04-
18 21
2.1.7 Supporting PM process plans 3 days Fri 06-04-
18
Tue 10-04-
18 22
2.1.8 Project plan approval 1 day Wed 11-04-
18
Wed 11-04-
18 23
2.2 Planning phase approval 1 day Thu 12-04-
18
Thu 12-04-
18 24
3 Execution phase 13 days Fri 13-04-
18
Tue 01-05-
18
3.1 Brainstorming session 12 days Fri 13-04-
18
Mon 30-04-
18
3.1.1 Preparation work 4 days Fri 13-04-
18
Wed 18-04-
18 25
3.1.2 Related work study 3 days Thu 19-04-
18
Mon 23-04-
18 28
3.1.3 Source selection 2 days Tue 24-04-
18
Wed 25-04-
18 29
3.1.4 Secondary research 3 days Thu 26-04-
18
Mon 30-04-
18 30
3.2 Execution phase approval 1 day Tue 01-05-
18
Tue 01-05-
18 31
4 Closeout phase 7 days Wed 02-05-
18
Thu 10-05-
18
4.1 Research closeout 2 days Wed 02-05-
18
Thu 03-05-
18 32
4.2 Launch project "Lessons
Learned" review 1 day Fri 04-05-
18 Fri 04-05-18 34
4.3 Establish process for
archiving project data 2 days Mon 07-05-
18
Tue 08-05-
18
4.3.1 Archive documents 2 days Mon 07-05-
18
Tue 08-05-
18 35
18 18
2.1.1 Scope statement 2 days Fri 16-03-
18
Mon 19-03-
18 14
2.1.2 Work Breakdown Structure 3 days Tue 20-03-
18
Thu 22-03-
18 17
2.1.3 Performance baseline
measurement 2 days Fri 23-03-
18
Mon 26-03-
18 18
2.1.4 Procurement planning 4 days Tue 27-03-
18 Fri 30-03-18 19
2.1.5 Project schedule plan 2 days Mon 02-04-
18
Tue 03-04-
18 20
2.1.6 Resource management 2 days Wed 04-04-
18
Thu 05-04-
18 21
2.1.7 Supporting PM process plans 3 days Fri 06-04-
18
Tue 10-04-
18 22
2.1.8 Project plan approval 1 day Wed 11-04-
18
Wed 11-04-
18 23
2.2 Planning phase approval 1 day Thu 12-04-
18
Thu 12-04-
18 24
3 Execution phase 13 days Fri 13-04-
18
Tue 01-05-
18
3.1 Brainstorming session 12 days Fri 13-04-
18
Mon 30-04-
18
3.1.1 Preparation work 4 days Fri 13-04-
18
Wed 18-04-
18 25
3.1.2 Related work study 3 days Thu 19-04-
18
Mon 23-04-
18 28
3.1.3 Source selection 2 days Tue 24-04-
18
Wed 25-04-
18 29
3.1.4 Secondary research 3 days Thu 26-04-
18
Mon 30-04-
18 30
3.2 Execution phase approval 1 day Tue 01-05-
18
Tue 01-05-
18 31
4 Closeout phase 7 days Wed 02-05-
18
Thu 10-05-
18
4.1 Research closeout 2 days Wed 02-05-
18
Thu 03-05-
18 32
4.2 Launch project "Lessons
Learned" review 1 day Fri 04-05-
18 Fri 04-05-18 34
4.3 Establish process for
archiving project data 2 days Mon 07-05-
18
Tue 08-05-
18
4.3.1 Archive documents 2 days Mon 07-05-
18
Tue 08-05-
18 35
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
10RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
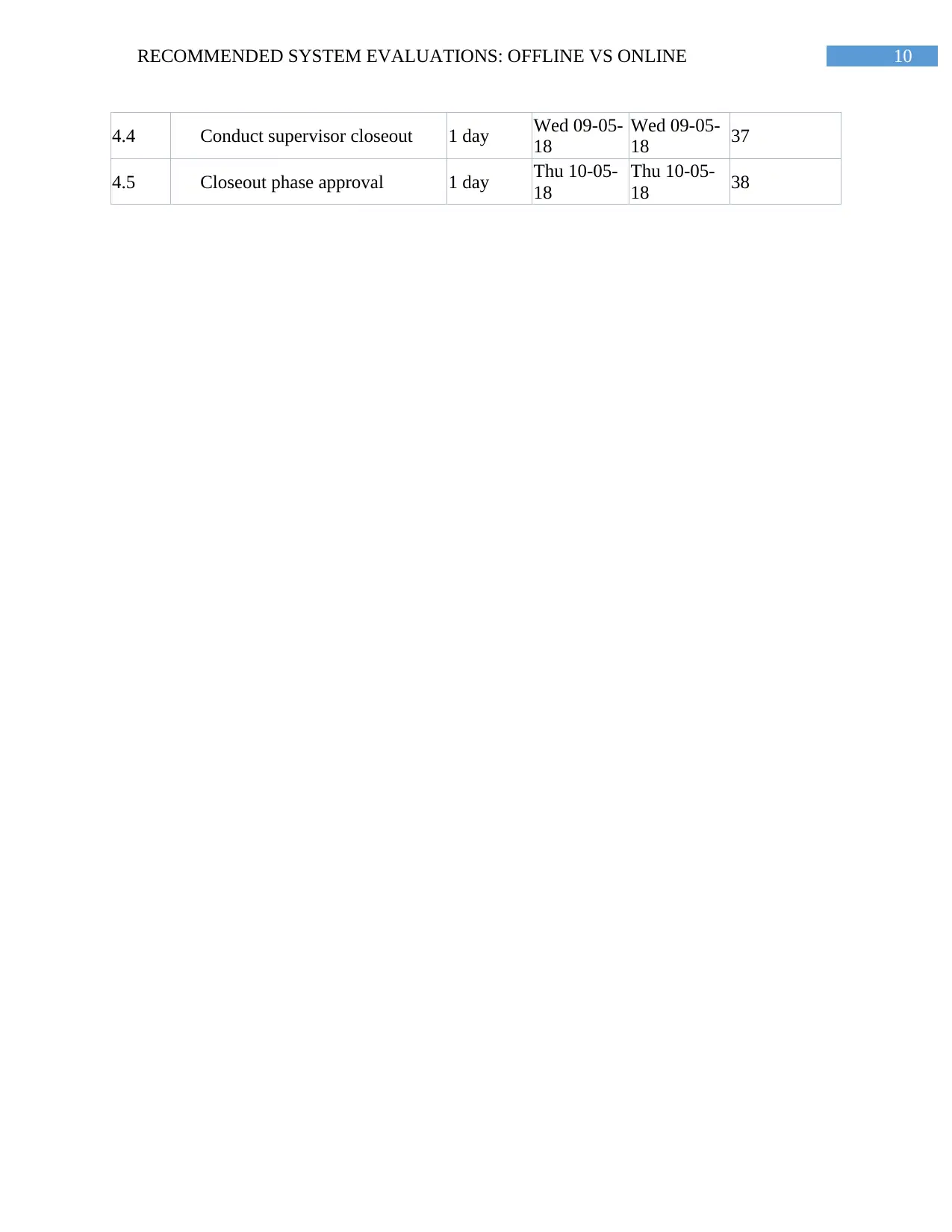
4.4 Conduct supervisor closeout 1 day Wed 09-05-
18
Wed 09-05-
18 37
4.5 Closeout phase approval 1 day Thu 10-05-
18
Thu 10-05-
18 38
4.4 Conduct supervisor closeout 1 day Wed 09-05-
18
Wed 09-05-
18 37
4.5 Closeout phase approval 1 day Thu 10-05-
18
Thu 10-05-
18 38

11RECOMMENDED SYSTEM EVALUATIONS: OFFLINE VS ONLINE
References
Adomavicius, G. and Tuzhilin, A., 2015. Context-aware recommender systems. In Recommender
systems handbook(pp. 191-226). Springer, Boston, MA.
Adomavicius, G. and Kwon, Y., 2015. Multi-criteria recommender systems. In Recommender
systems handbook(pp. 847-880). Springer, Boston, MA.
Amatriain, X. and Pujol, J.M., 2015. Data mining methods for recommender systems.
In Recommender systems handbook(pp. 227-262). Springer, Boston, MA.
Beel, J., Gipp, B., Langer, S. and Breitinger, C., 2016. paper recommender systems: a literature
survey. International Journal on Digital Libraries, 17(4), pp.305-338.
Rubens, N., Elahi, M., Sugiyama, M. and Kaplan, D., 2015. Active learning in recommender
systems. In Recommender systems handbook (pp. 809-846). Springer, Boston, MA.
Gavalas, D., Konstantopoulos, C., Mastakas, K. and Pantziou, G., 2014. Mobile recommender
systems in tourism. Journal of network and computer applications, 39, pp.319-333.
Guy, I., 2015. Social recommender systems. In Recommender Systems Handbook (pp. 511-543).
Springer, Boston, MA.
Zhang, F., Yuan, N.J., Lian, D., Xie, X. and Ma, W.Y., 2016, August. Collaborative knowledge
base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD
international conference on knowledge discovery and data mining (pp. 353-362). ACM.
Yang, X., Guo, Y., Liu, Y. and Steck, H., 2014. A survey of collaborative filtering based social
recommender systems. Computer Communications, 41, pp.1-10.
Lika, B., Kolomvatsos, K. and Hadjiefthymiades, S., 2014. Facing the cold start problem in
recommender systems. Expert Systems with Applications, 41(4), pp.2065-2073.
Zeng, A., Yeung, C.H., Medo, M. and Zhang, Y.C., 2015. Modeling mutual feedback between
users and recommender systems. Journal of Statistical Mechanics: Theory and
Experiment, 2015(7), p.P07020.
Ricci, F., Rokach, L. and Shapira, B., 2015. Recommender systems: introduction and challenges.
In Recommender systems handbook (pp. 1-34). Springer, Boston, MA.
Zhang, H.R. and Min, F., 2016. Three-way recommender systems based on random
forests. Knowledge-Based Systems, 91, pp.275-286.
Borràs, J., Moreno, A. and Valls, A., 2014. Intelligent tourism recommender systems: A
survey. Expert Systems with Applications, 41(16), pp.7370-7389.
Campos, P.G., Díez, F. and Cantador, I., 2014. Time-aware recommender systems: a
comprehensive survey and analysis of existing evaluation protocols. User Modeling and User-
Adapted Interaction, 24(1-2), pp.67-119.
Son, L.H., 2016. Dealing with the new user cold-start problem in recommender systems A
comparative review.
References
Adomavicius, G. and Tuzhilin, A., 2015. Context-aware recommender systems. In Recommender
systems handbook(pp. 191-226). Springer, Boston, MA.
Adomavicius, G. and Kwon, Y., 2015. Multi-criteria recommender systems. In Recommender
systems handbook(pp. 847-880). Springer, Boston, MA.
Amatriain, X. and Pujol, J.M., 2015. Data mining methods for recommender systems.
In Recommender systems handbook(pp. 227-262). Springer, Boston, MA.
Beel, J., Gipp, B., Langer, S. and Breitinger, C., 2016. paper recommender systems: a literature
survey. International Journal on Digital Libraries, 17(4), pp.305-338.
Rubens, N., Elahi, M., Sugiyama, M. and Kaplan, D., 2015. Active learning in recommender
systems. In Recommender systems handbook (pp. 809-846). Springer, Boston, MA.
Gavalas, D., Konstantopoulos, C., Mastakas, K. and Pantziou, G., 2014. Mobile recommender
systems in tourism. Journal of network and computer applications, 39, pp.319-333.
Guy, I., 2015. Social recommender systems. In Recommender Systems Handbook (pp. 511-543).
Springer, Boston, MA.
Zhang, F., Yuan, N.J., Lian, D., Xie, X. and Ma, W.Y., 2016, August. Collaborative knowledge
base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD
international conference on knowledge discovery and data mining (pp. 353-362). ACM.
Yang, X., Guo, Y., Liu, Y. and Steck, H., 2014. A survey of collaborative filtering based social
recommender systems. Computer Communications, 41, pp.1-10.
Lika, B., Kolomvatsos, K. and Hadjiefthymiades, S., 2014. Facing the cold start problem in
recommender systems. Expert Systems with Applications, 41(4), pp.2065-2073.
Zeng, A., Yeung, C.H., Medo, M. and Zhang, Y.C., 2015. Modeling mutual feedback between
users and recommender systems. Journal of Statistical Mechanics: Theory and
Experiment, 2015(7), p.P07020.
Ricci, F., Rokach, L. and Shapira, B., 2015. Recommender systems: introduction and challenges.
In Recommender systems handbook (pp. 1-34). Springer, Boston, MA.
Zhang, H.R. and Min, F., 2016. Three-way recommender systems based on random
forests. Knowledge-Based Systems, 91, pp.275-286.
Borràs, J., Moreno, A. and Valls, A., 2014. Intelligent tourism recommender systems: A
survey. Expert Systems with Applications, 41(16), pp.7370-7389.
Campos, P.G., Díez, F. and Cantador, I., 2014. Time-aware recommender systems: a
comprehensive survey and analysis of existing evaluation protocols. User Modeling and User-
Adapted Interaction, 24(1-2), pp.67-119.
Son, L.H., 2016. Dealing with the new user cold-start problem in recommender systems A
comparative review.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 13
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.