SIT718: Forest Fires Dataset Analysis and Prediction Project
VerifiedAdded on 2023/04/22
|7
|1491
|365
Project
AI Summary
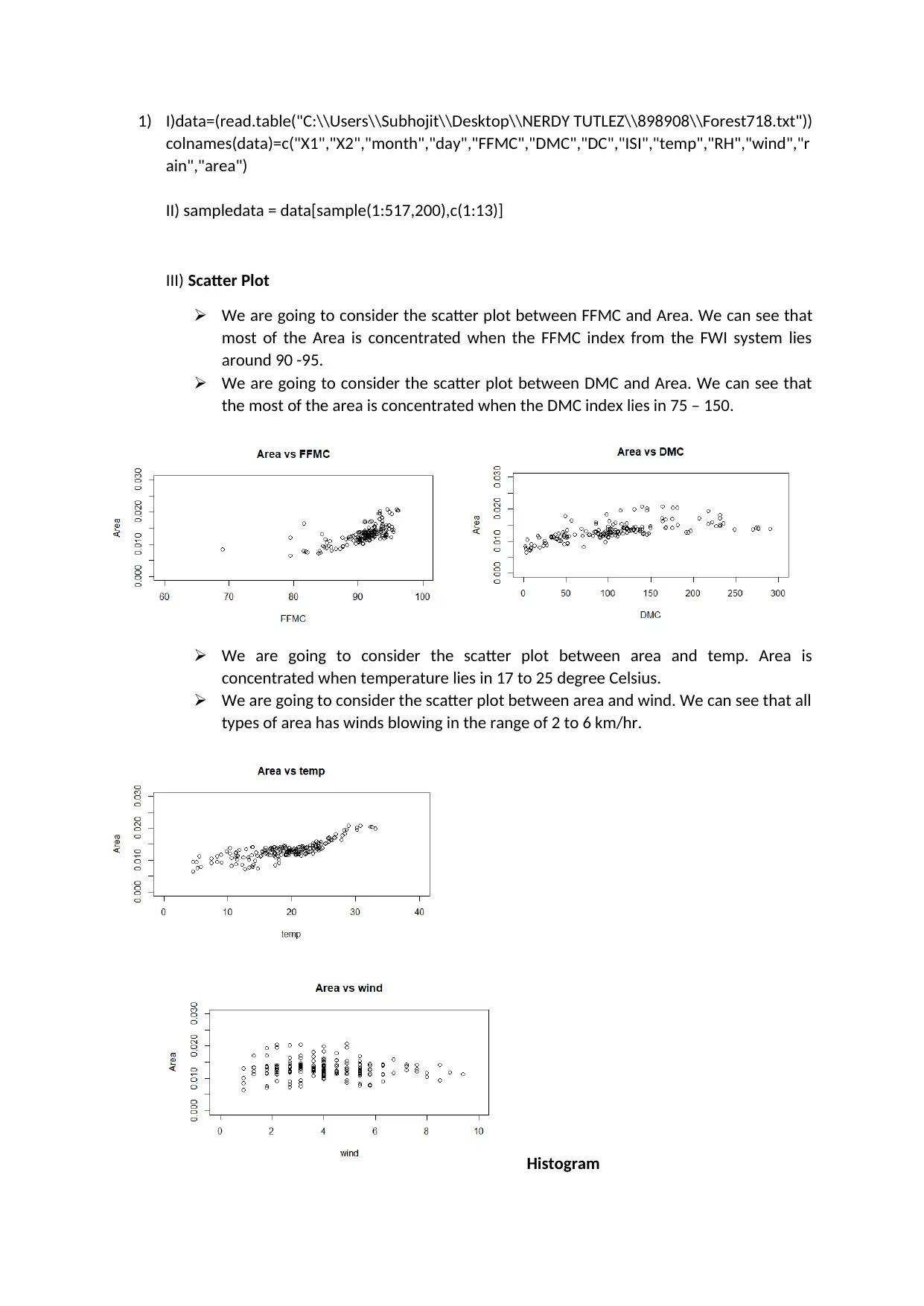
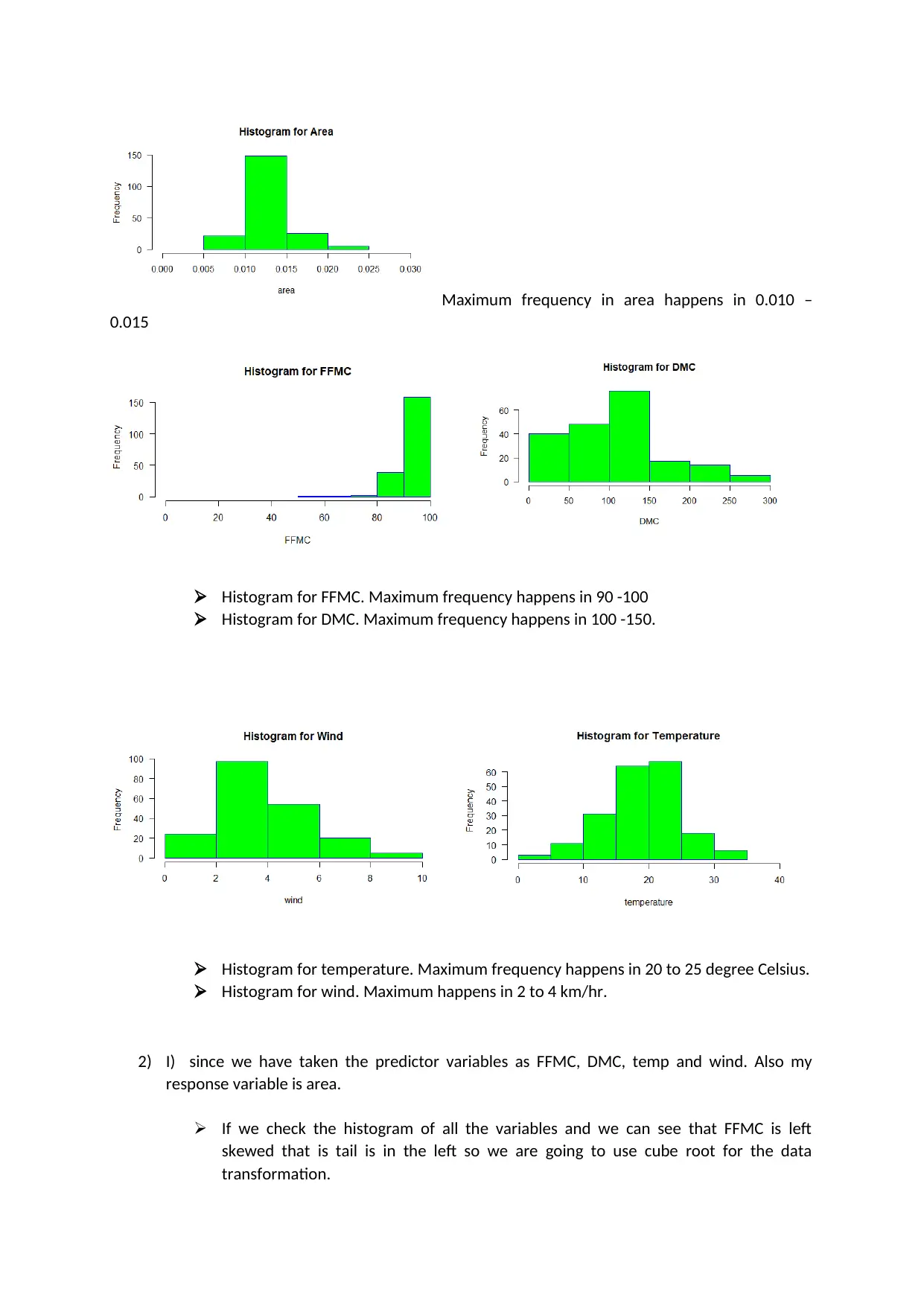
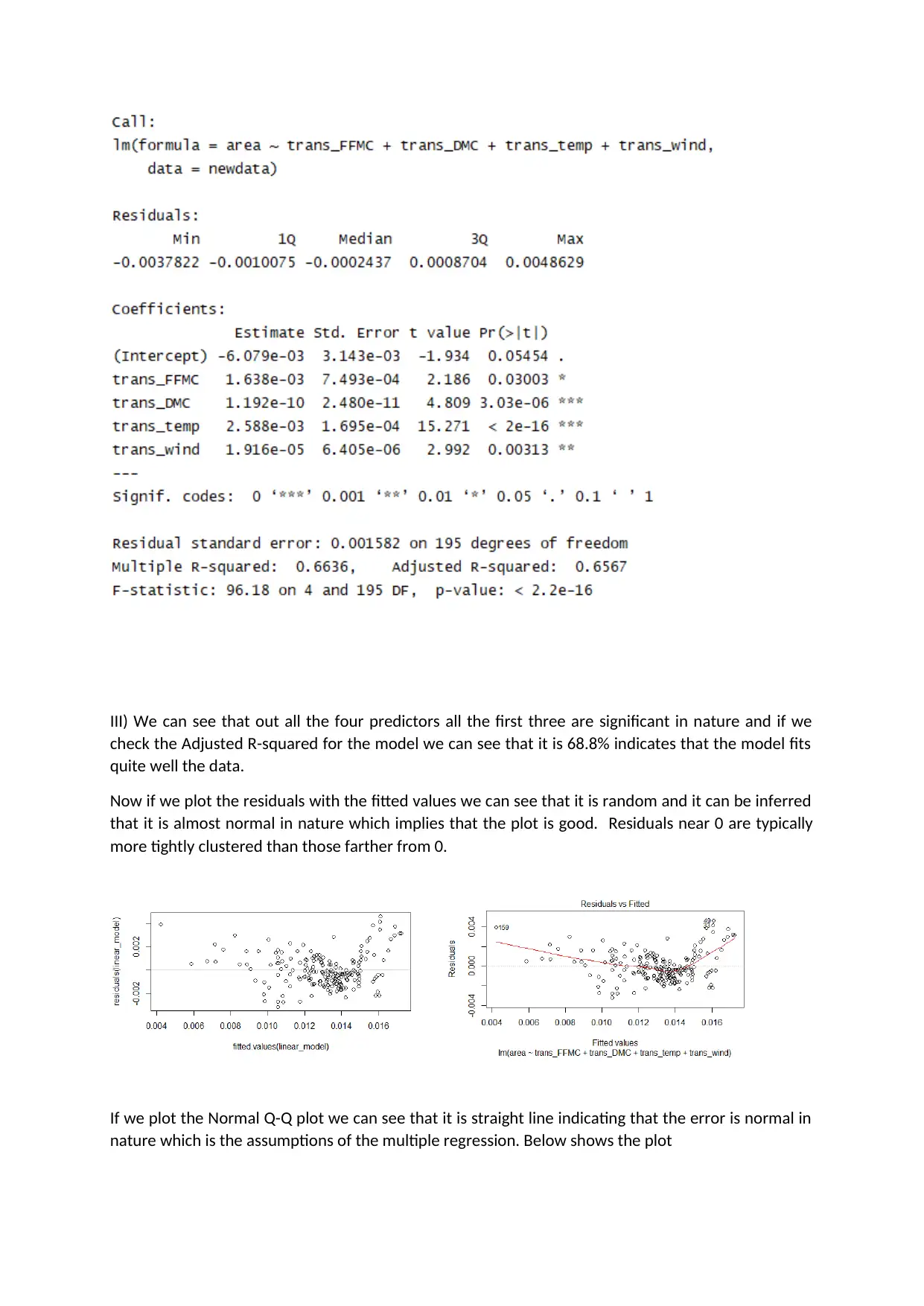
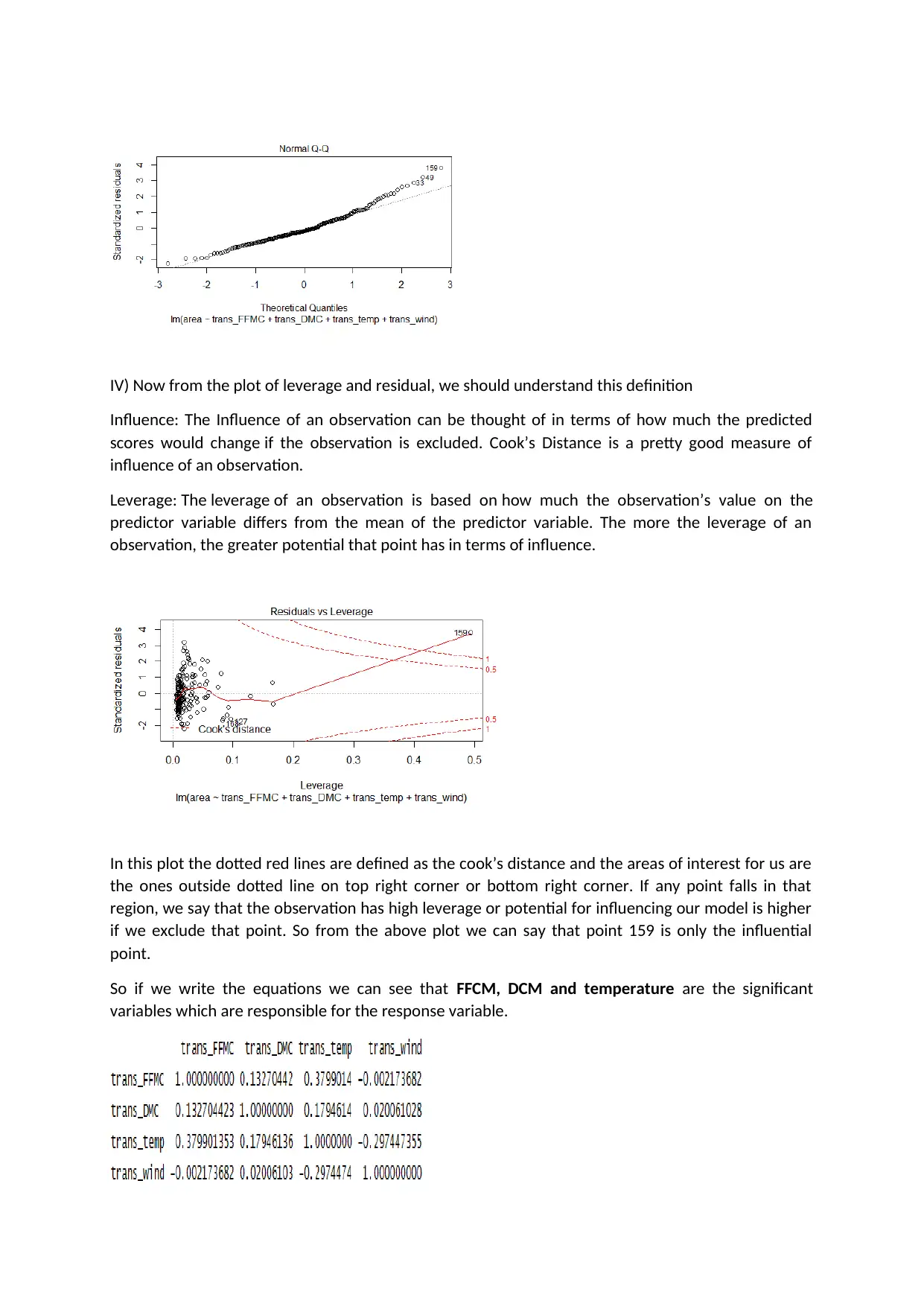
This project analyzes a forest fire dataset using R programming to predict the area burned by forest fires. The analysis includes data loading, cleaning, and exploratory data analysis (EDA) using scatter plots and histograms to understand the relationships between variables like FFMC, DMC, temperature, wind, and the area burned. Data transformation techniques, such as cube root, cube, and square root transformations, are applied to address skewness in the data. Multiple regression models are built to assess the significance of predictor variables in determining the area burned, with model diagnostics including residual plots and Q-Q plots to validate model assumptions. The project also discusses the concept of influence and leverage using Cook's Distance to identify influential data points. Finally, the project concludes with a prediction of the area burned based on given input values and provides references to the dataset and relevant publications.



1 out of 7

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.