SPARK PROGRAMMING.
Added on 2023-01-16
10 Pages1692 Words87 Views
Running head: SPARK PROGRAMMING 1
SPARK Programming:
Name:
Course:
Date:
SPARK Programming:
Name:
Course:
Date:

SPARK PROGRAMMING 2
Introduction
Spark is an application development methodology that is particularly designed for creating
high-reliability software (Aleksiyants, et al., 2015). It is made up of verification toolset,
programming language, and a method of design which when combined together realizes
deployment of error-free application in high-reliability domains, for instance where security
and safety ate primary requirements.
Structure of Resilient Distributed Datasets (RDDs)
RDD is Spark’s essential data structure. Basically, it is an unassailable object collection.
RDD datasets are subdivided into logical subsets that can be processed on various points of
the cluster. RDD can have any form of Scala, Java, or Python objects like classes that are
user-defined. Creation of RDDs can be achieved through deterministic processes on either
data on other RDDs or on stable storage. There exist two methods of creating RDDs: either
by dataset referencing in an external system of storage like HDFS, shared file system, or any
other source of data that provides Hadoop Input type or through parallelizing an accessible
assembly in the driver program. The concept of RDD is used by Spark to realize efficient and
quick MapReduce processes.
Transformation in Spark RDD
Transformation is applied in RDD to come up with new sets of data from the current one by
going through every element of dataset using a formulae and outputs a new RDD showing the
results. Generally, transformation is the process of using existing RDD to create new RDD.
Every Spark transformation depict the ‘lazy’ aspect (Sullins, 2017). This means that their
results are not processed immediately, rather they recall the transformations employed in
some base sets of data. Transformations are only processed when a process needs an output to
be sent to the driver program. The screenshot below shows transformation using the function
Introduction
Spark is an application development methodology that is particularly designed for creating
high-reliability software (Aleksiyants, et al., 2015). It is made up of verification toolset,
programming language, and a method of design which when combined together realizes
deployment of error-free application in high-reliability domains, for instance where security
and safety ate primary requirements.
Structure of Resilient Distributed Datasets (RDDs)
RDD is Spark’s essential data structure. Basically, it is an unassailable object collection.
RDD datasets are subdivided into logical subsets that can be processed on various points of
the cluster. RDD can have any form of Scala, Java, or Python objects like classes that are
user-defined. Creation of RDDs can be achieved through deterministic processes on either
data on other RDDs or on stable storage. There exist two methods of creating RDDs: either
by dataset referencing in an external system of storage like HDFS, shared file system, or any
other source of data that provides Hadoop Input type or through parallelizing an accessible
assembly in the driver program. The concept of RDD is used by Spark to realize efficient and
quick MapReduce processes.
Transformation in Spark RDD
Transformation is applied in RDD to come up with new sets of data from the current one by
going through every element of dataset using a formulae and outputs a new RDD showing the
results. Generally, transformation is the process of using existing RDD to create new RDD.
Every Spark transformation depict the ‘lazy’ aspect (Sullins, 2017). This means that their
results are not processed immediately, rather they recall the transformations employed in
some base sets of data. Transformations are only processed when a process needs an output to
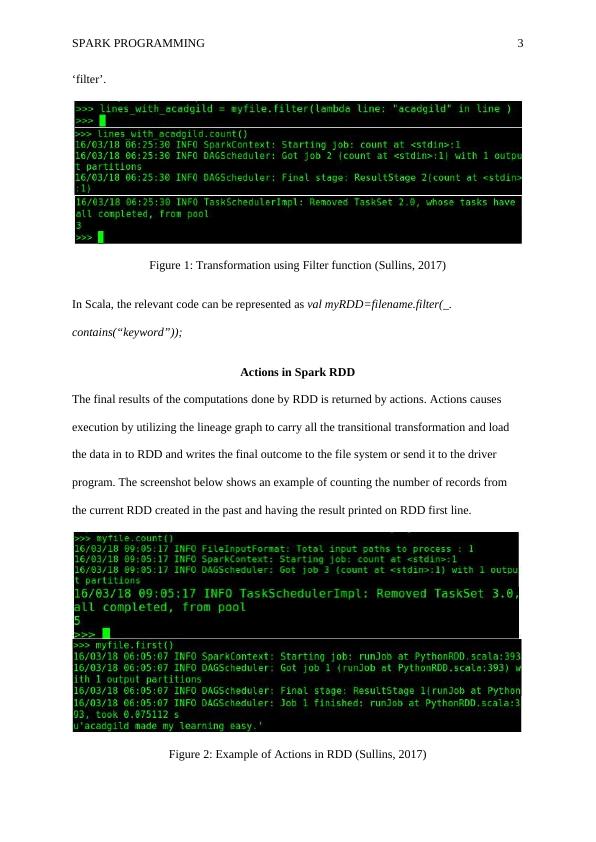
be sent to the driver program. The screenshot below shows transformation using the function

SPARK PROGRAMMING 3
‘filter’.
Figure 1: Transformation using Filter function (Sullins, 2017)
In Scala, the relevant code can be represented as val myRDD=filename.filter(_.
contains(“keyword”));
Actions in Spark RDD
The final results of the computations done by RDD is returned by actions. Actions causes
execution by utilizing the lineage graph to carry all the transitional transformation and load
the data in to RDD and writes the final outcome to the file system or send it to the driver
program. The screenshot below shows an example of counting the number of records from
the current RDD created in the past and having the result printed on RDD first line.
Figure 2: Example of Actions in RDD (Sullins, 2017)
‘filter’.
Figure 1: Transformation using Filter function (Sullins, 2017)
In Scala, the relevant code can be represented as val myRDD=filename.filter(_.
contains(“keyword”));
Actions in Spark RDD
The final results of the computations done by RDD is returned by actions. Actions causes
execution by utilizing the lineage graph to carry all the transitional transformation and load
the data in to RDD and writes the final outcome to the file system or send it to the driver
program. The screenshot below shows an example of counting the number of records from
the current RDD created in the past and having the result printed on RDD first line.
Figure 2: Example of Actions in RDD (Sullins, 2017)
End of preview
Want to access all the pages? Upload your documents or become a member.
Related Documents
Data Science Practices Using Pyspark Project 2022lg...
|13
|1910
|10
Machine Learning Research Paper 2022lg...
|12
|1485
|13