Data Analysis Report: Carbon Disclosure, Board Decisions, and Factors
VerifiedAdded on 2021/06/15
|11
|1734
|19
Report
AI Summary
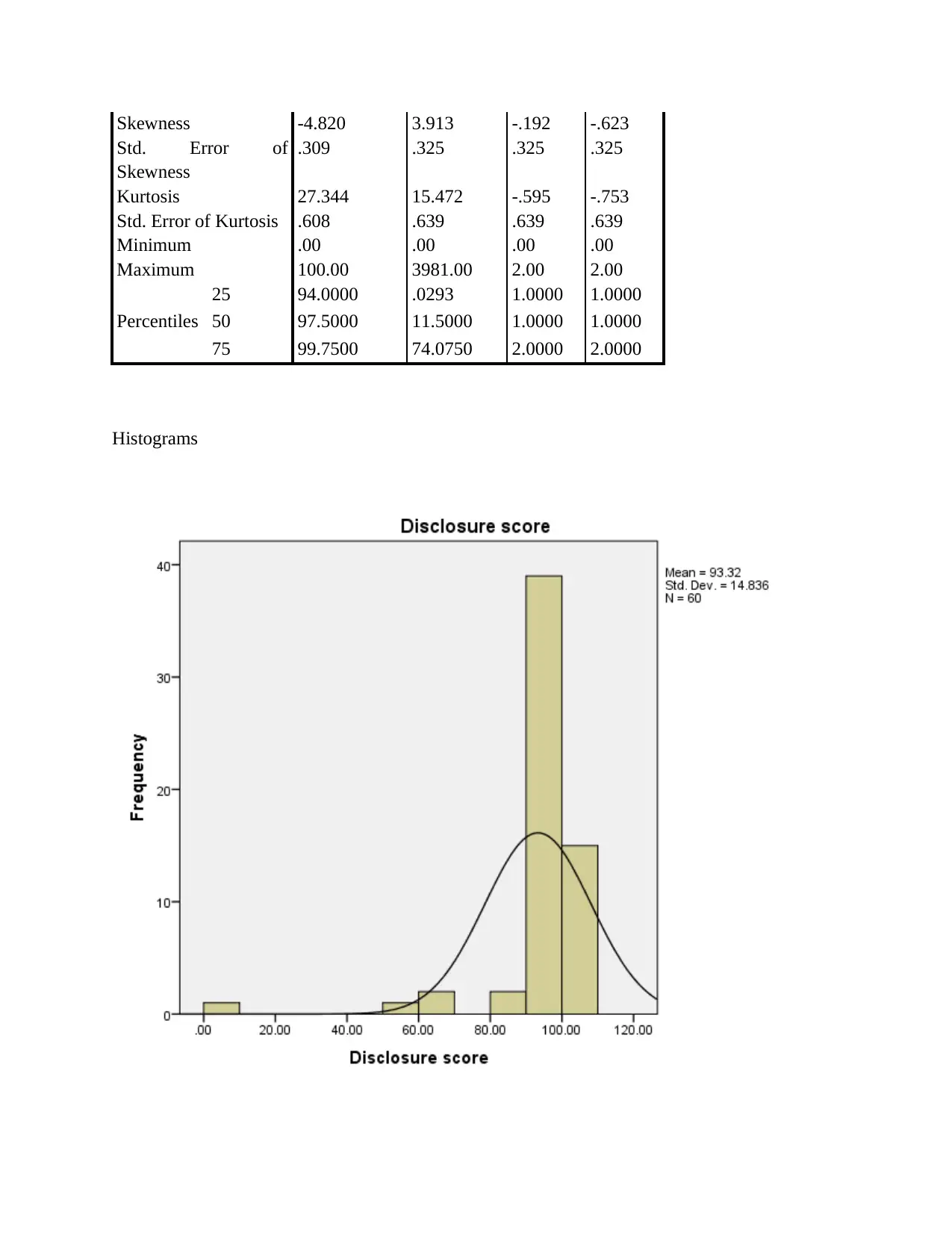
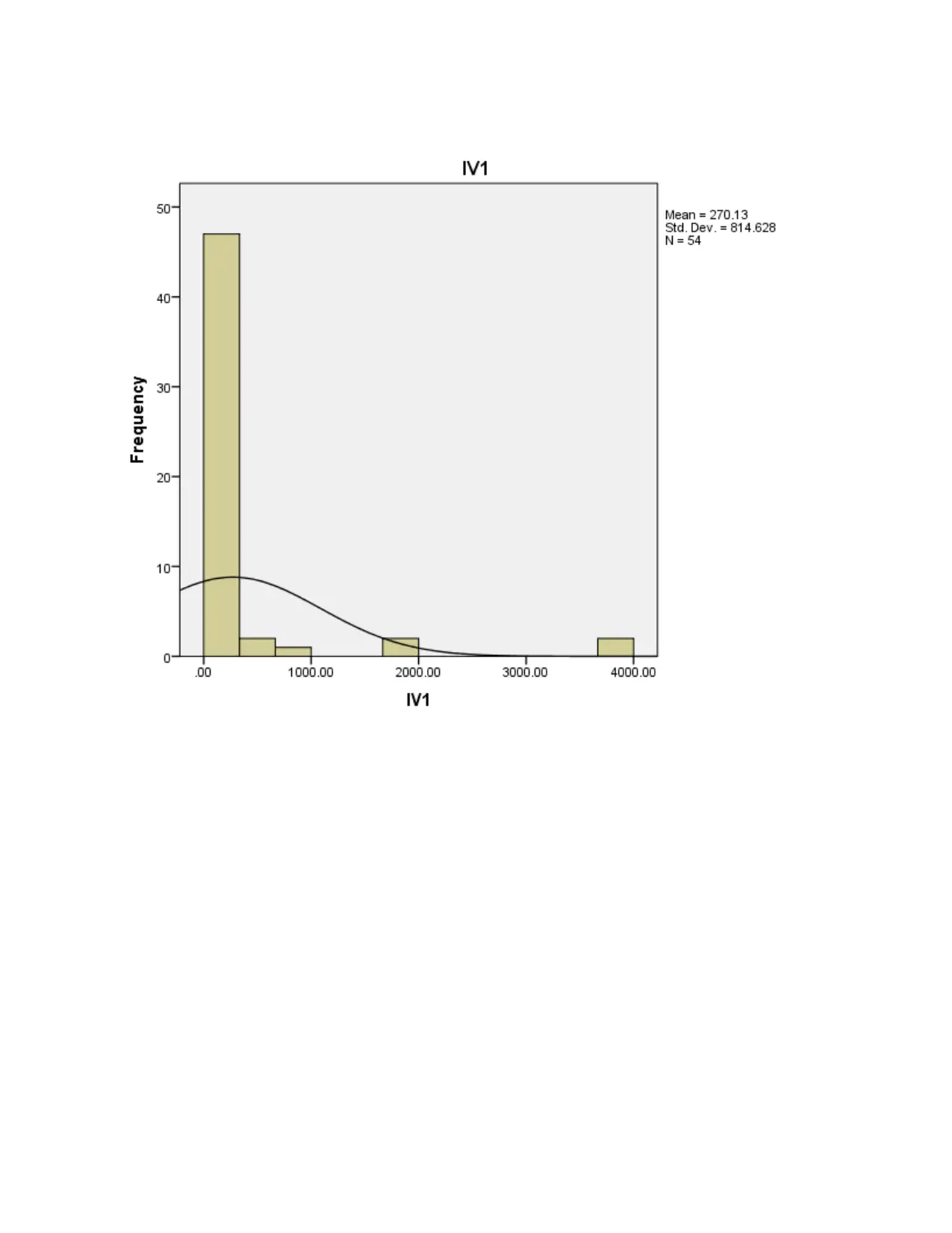
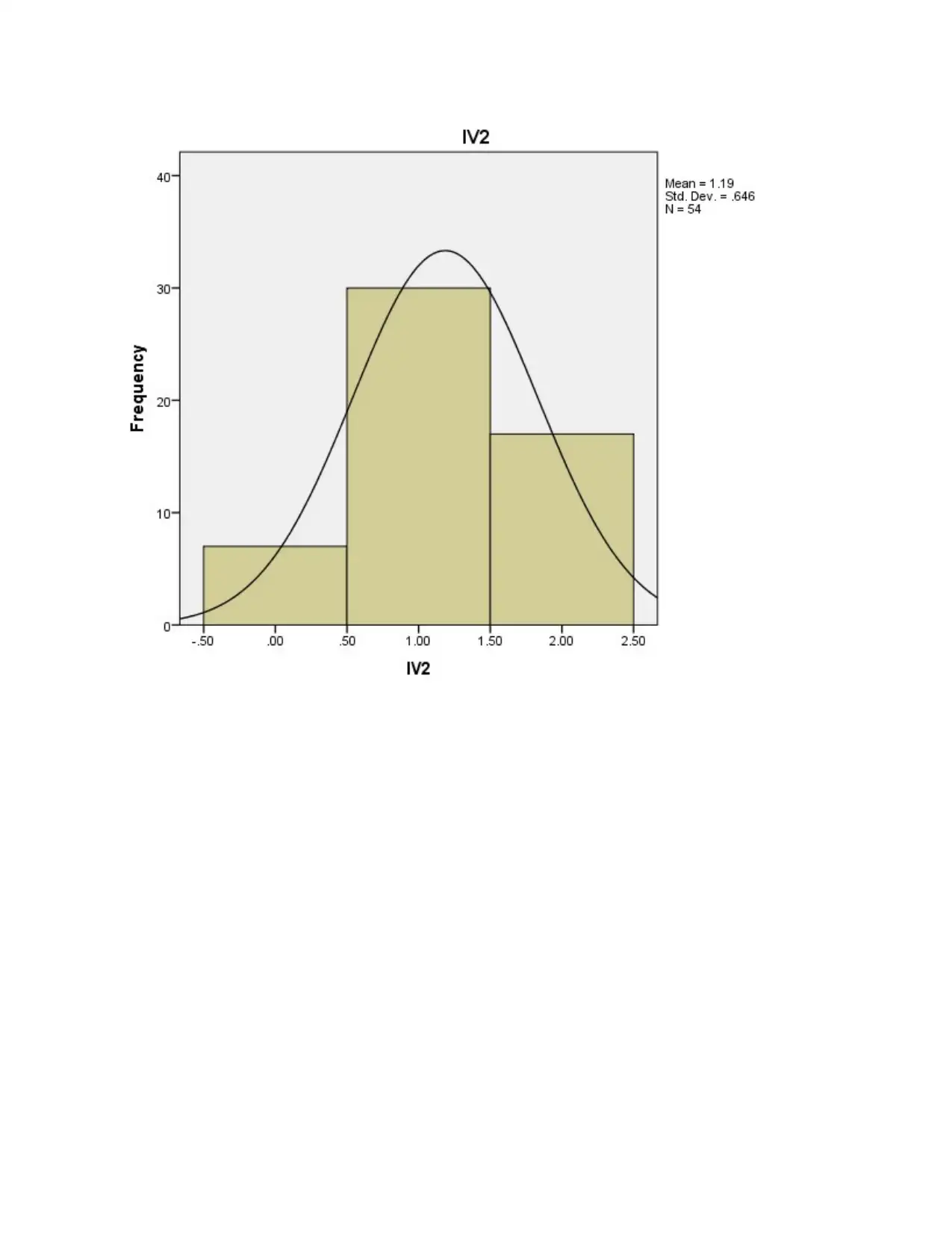
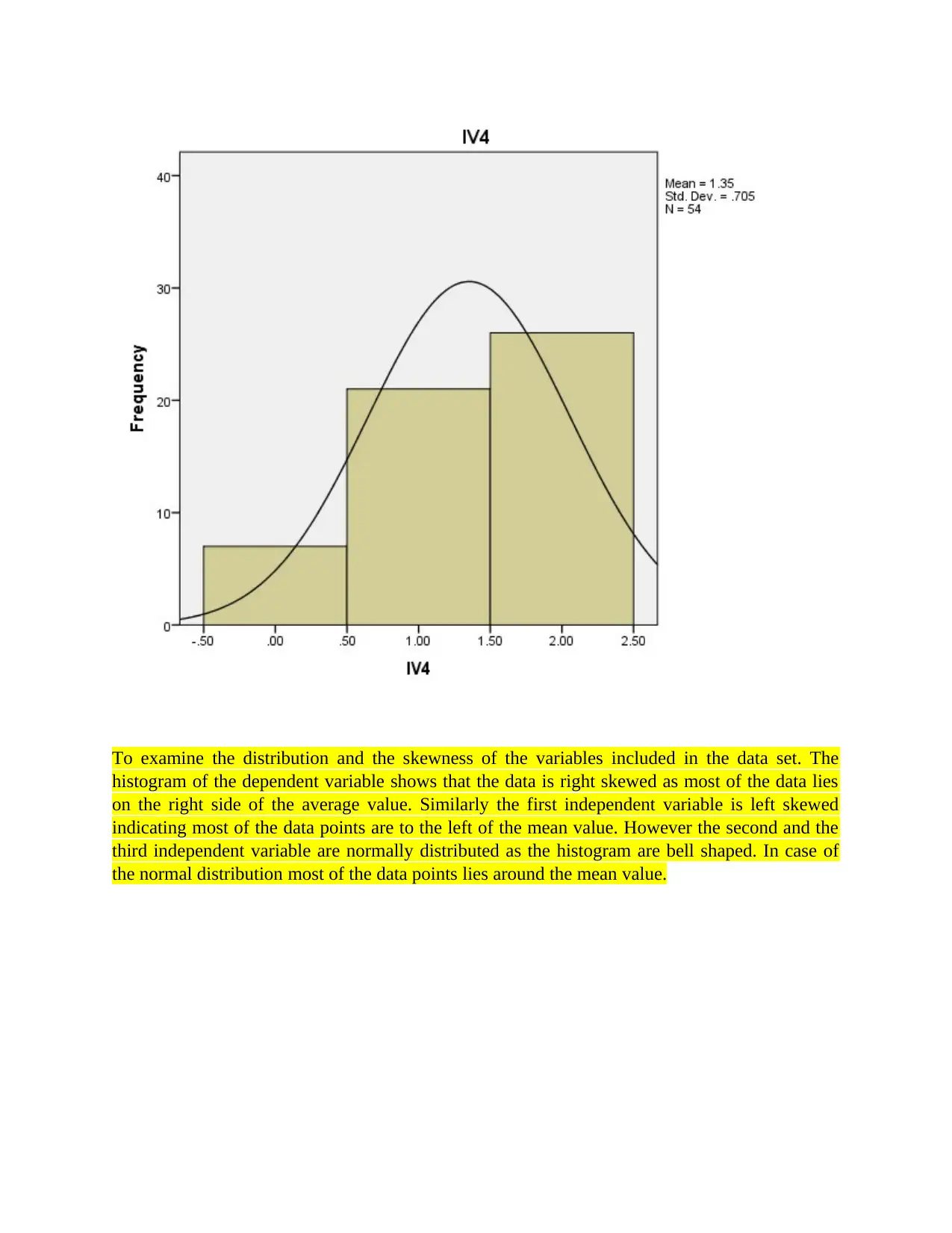
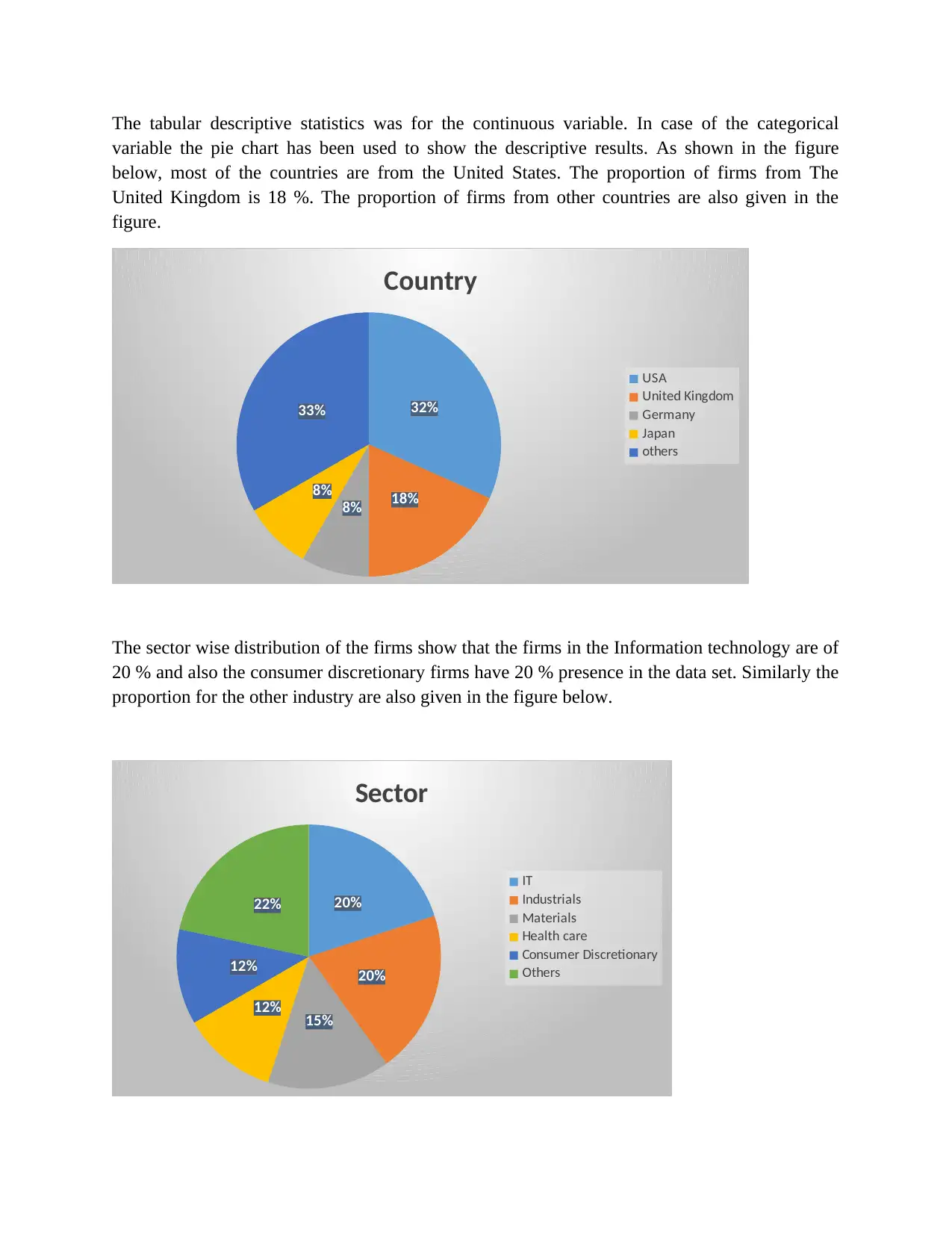
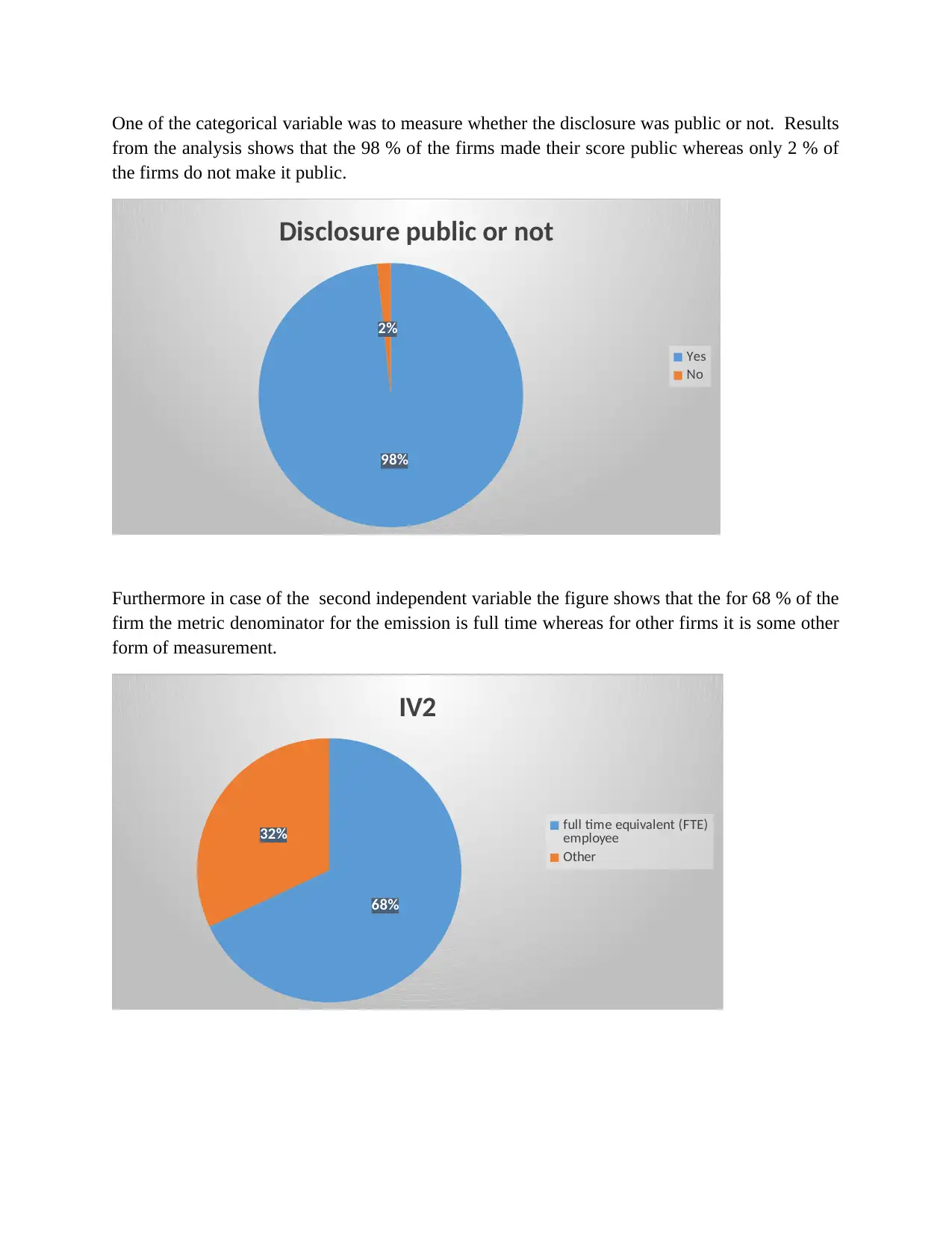
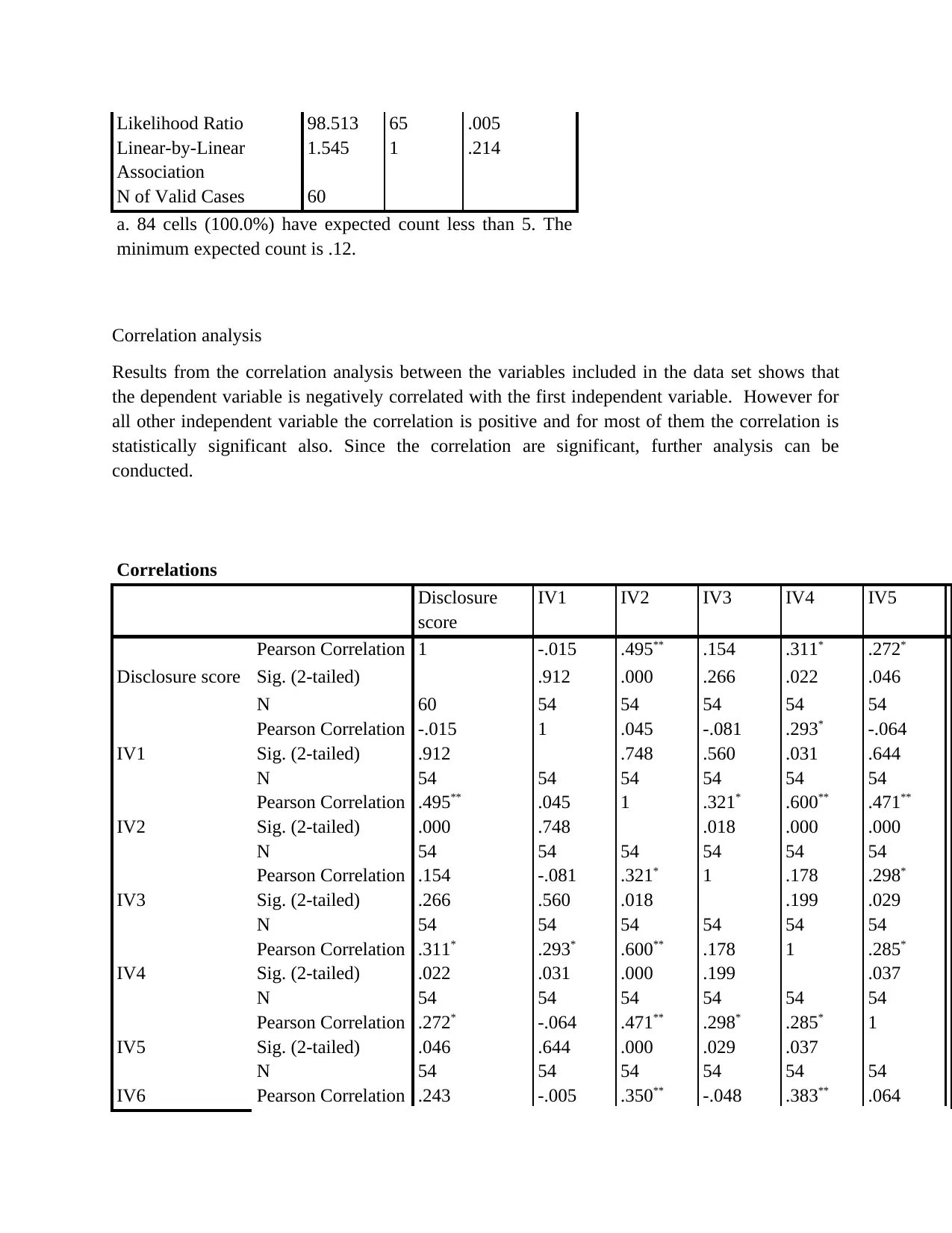
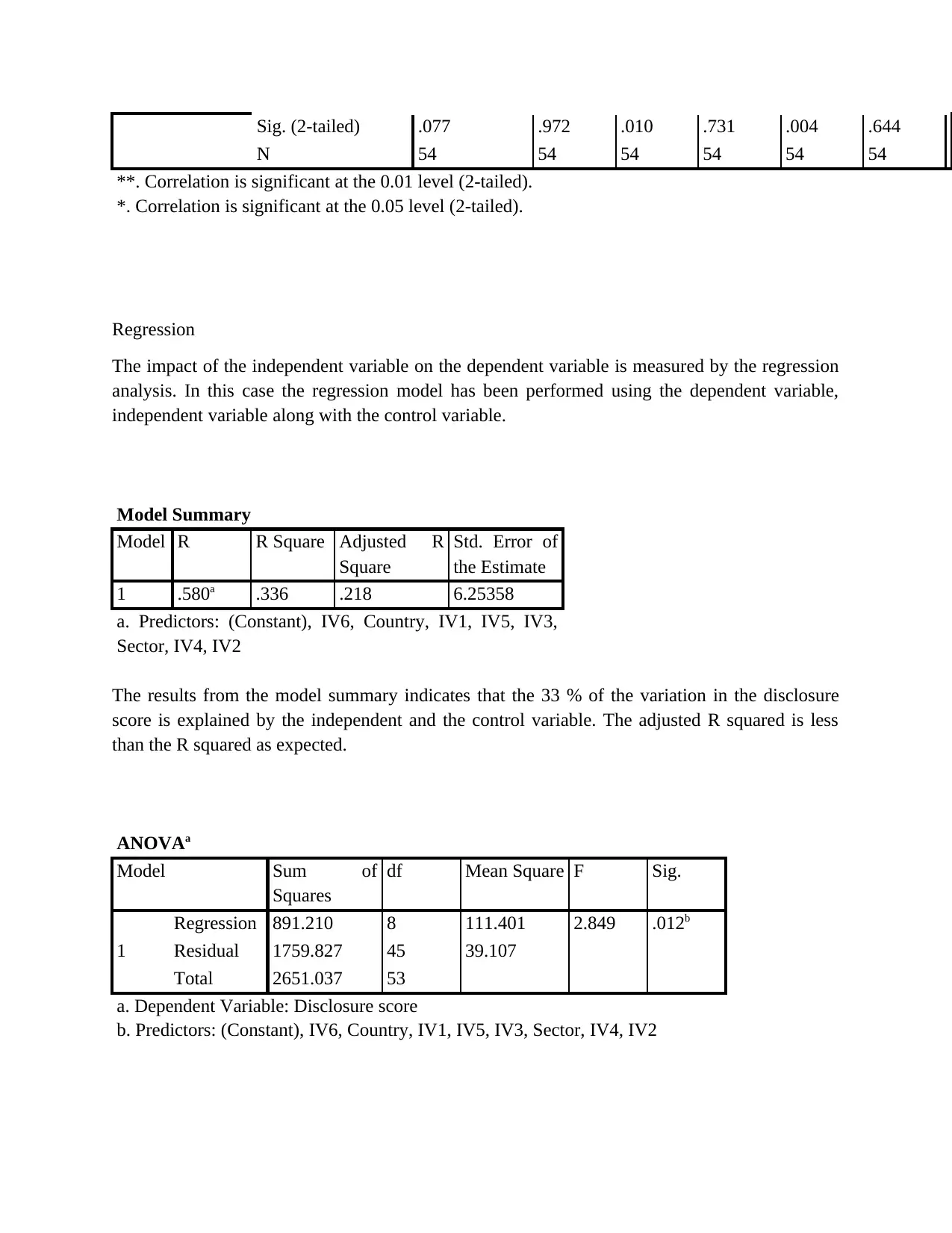
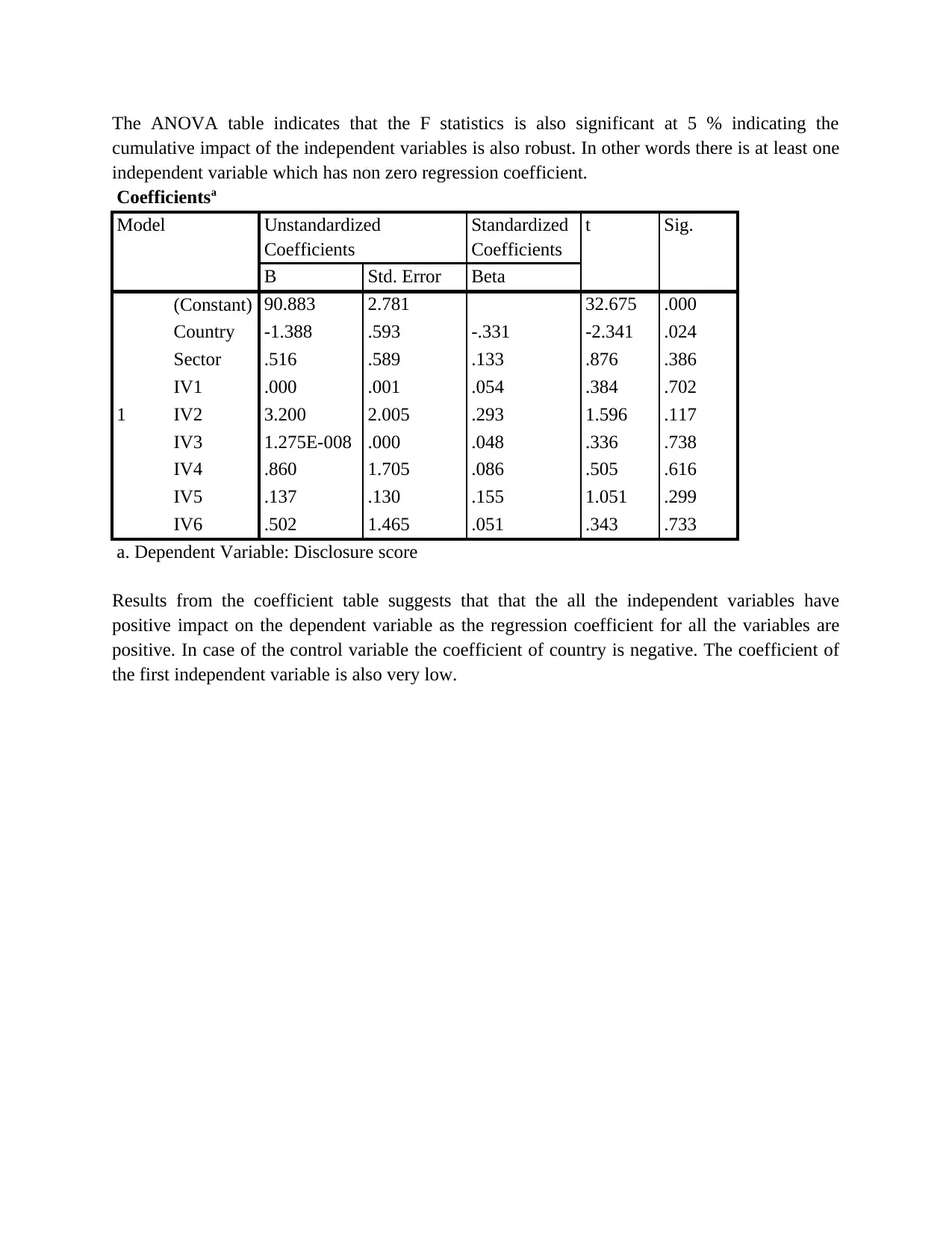
This report presents a comprehensive data analysis of carbon disclosure practices among 60 firms globally. The analysis begins with data collection methods, including random sampling, and data cleaning procedures. Descriptive statistics, such as mean, median, mode, standard deviation, skewness, and kurtosis, are used to characterize the data, including the disclosure score and various independent variables related to board decisions. Histograms and pie charts are used to visualize data distributions and categorical variable proportions. Inferential statistics, including chi-square tests, correlation analysis, and regression analysis, are employed to test hypotheses and determine relationships between variables. The chi-square tests assess differences in disclosure scores across countries and sectors. Correlation analysis explores relationships between the dependent and independent variables. Regression analysis is used to measure the impact of independent variables on the disclosure score, with model summaries, ANOVA tables, and coefficient tables providing detailed insights. The report concludes with an interpretation of the findings, highlighting the significant factors influencing carbon disclosure.


1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.