STAT603 Forecasting: Time Series Analysis, ARIMA & ETS Comparison
VerifiedAdded on 2023/06/11
|14
|2151
|398
Homework Assignment
AI Summary
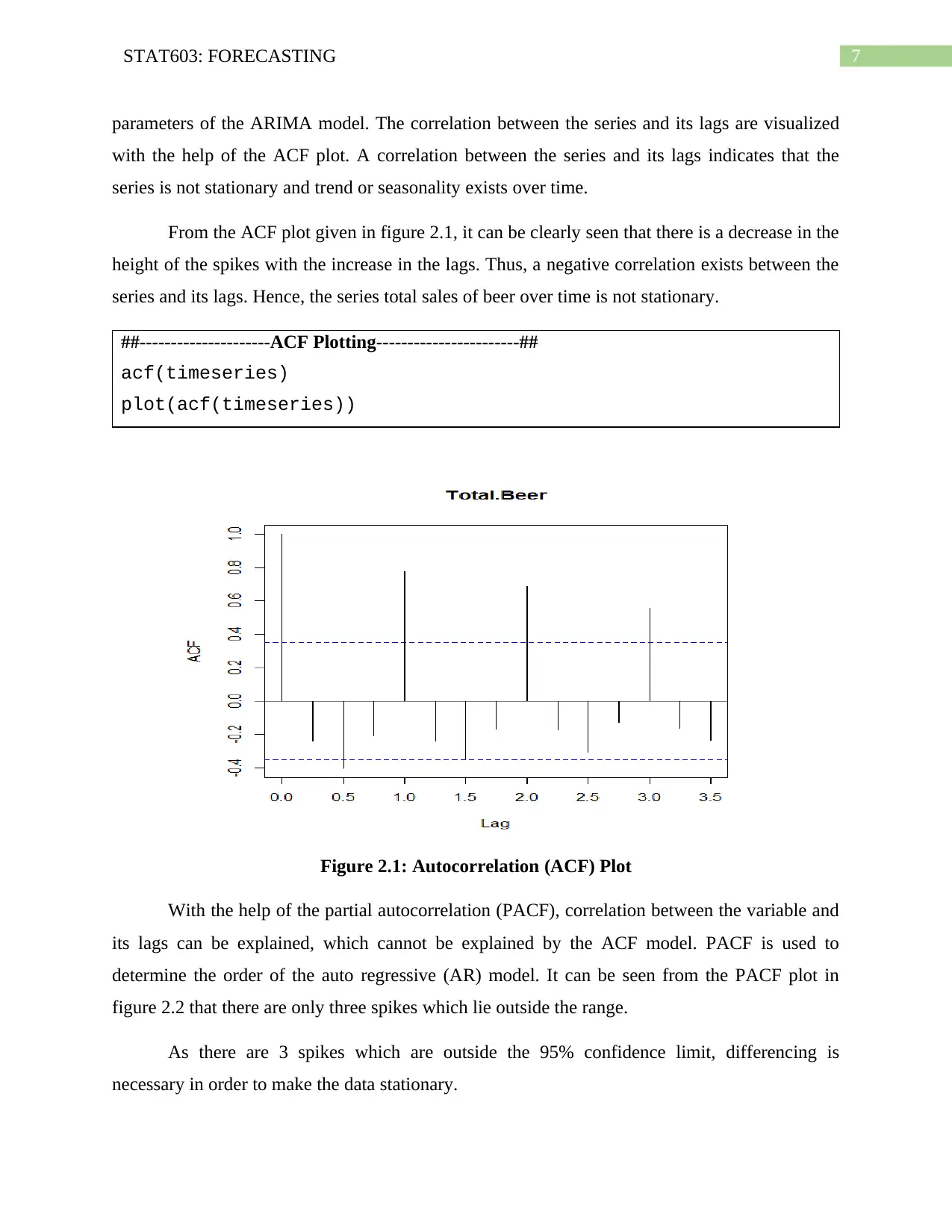
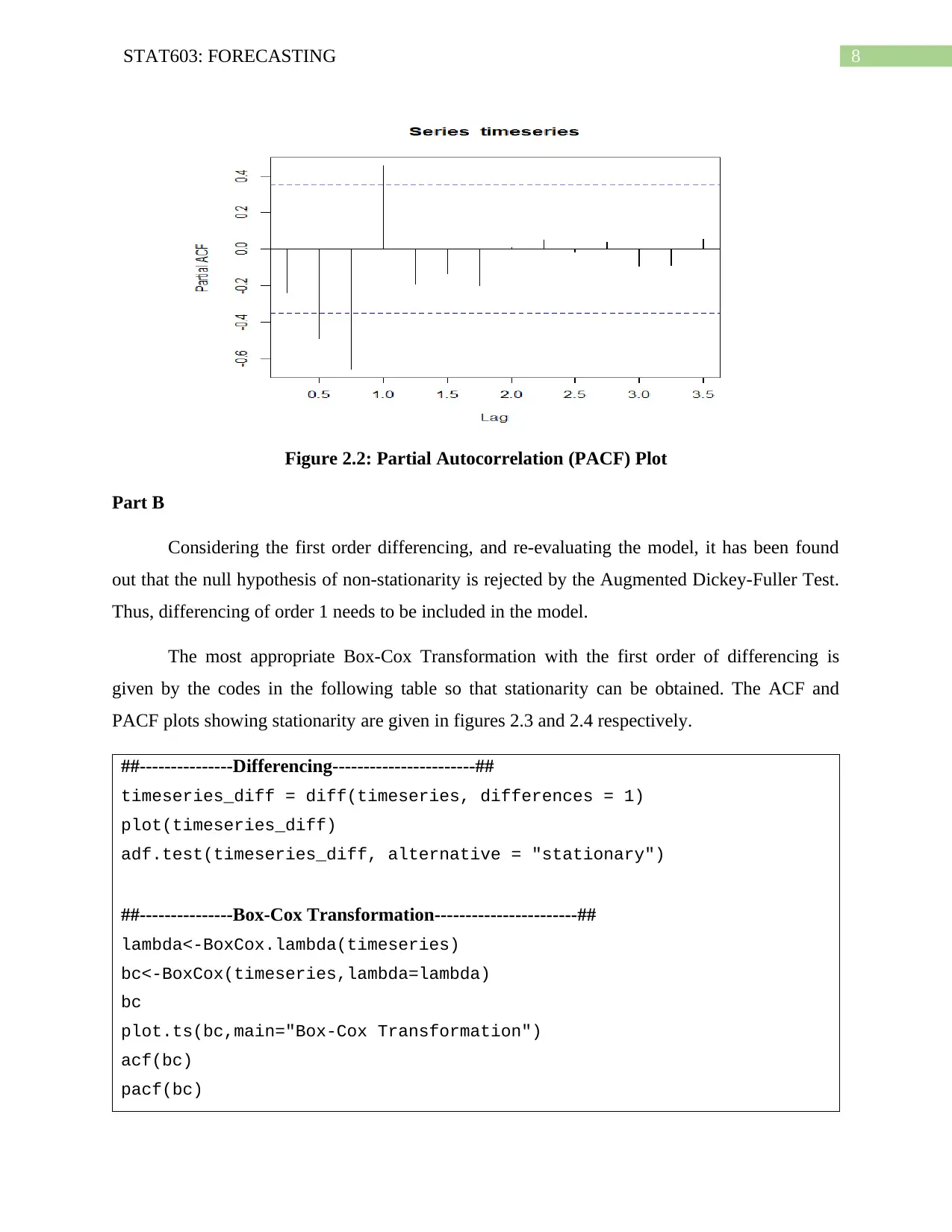
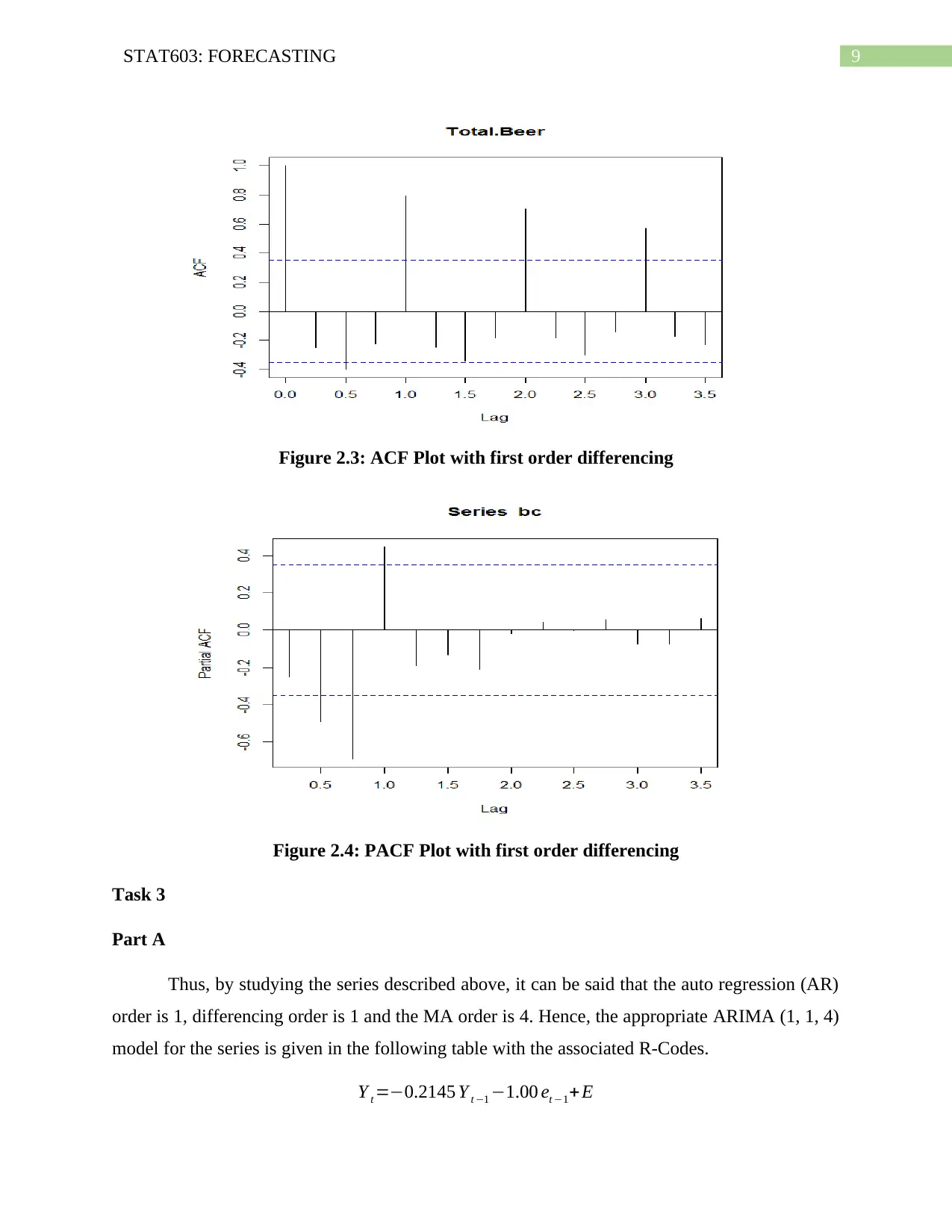
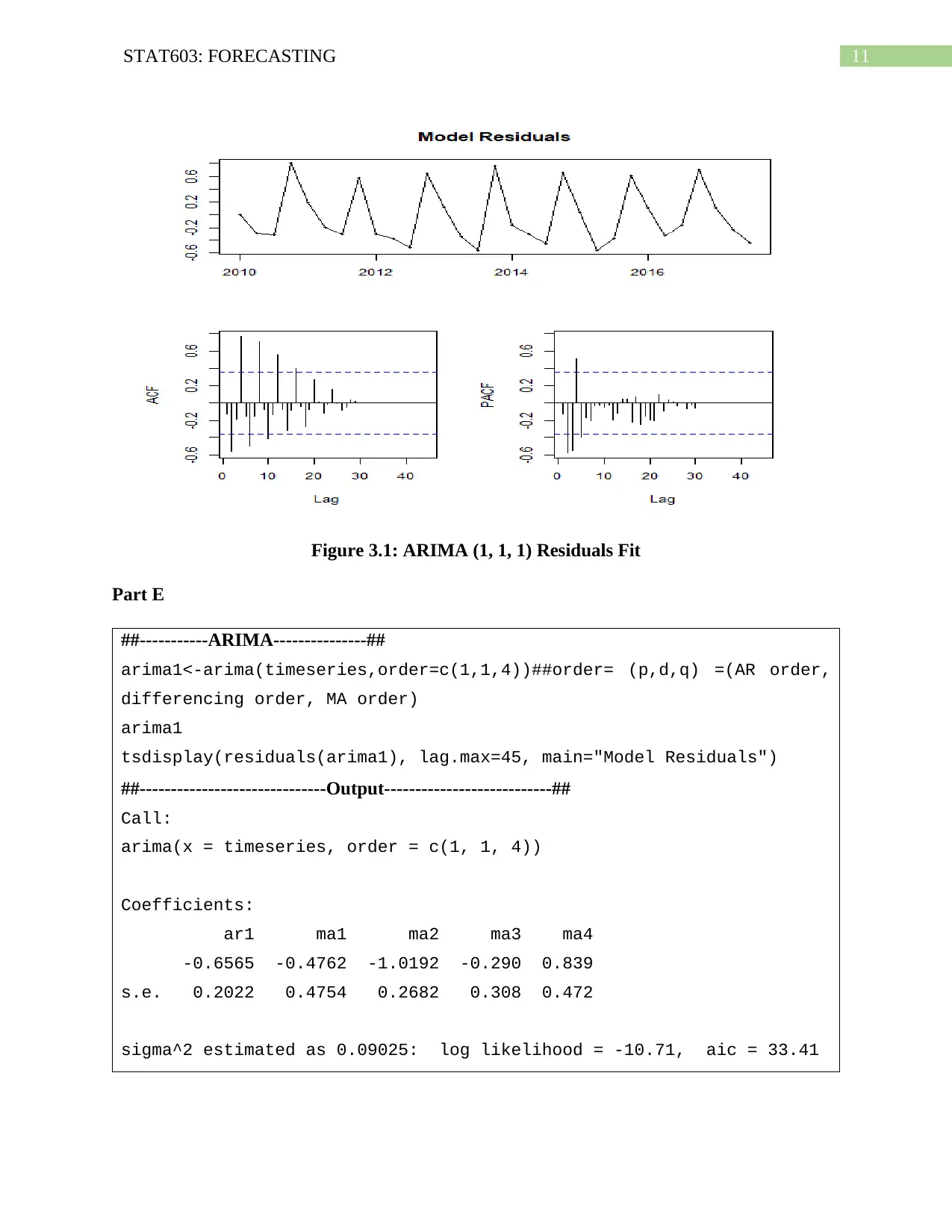
This assignment solution focuses on forecasting techniques using time series data. It includes an analysis of beer sales data in New Zealand from 2010 to 2017, employing methods such as exponential smoothing, Holt's Linear Trend, and Damped Trend to forecast future sales. The solution also covers Autocorrelation (ACF) and Partial Autocorrelation (PACF) plots to assess stationarity and determine the order of ARIMA models. Box-Cox transformation is used to stabilize the variance. The assignment further explores ARIMA models, including parameter selection, residual analysis, and comparison with the auto.arima() and ETS methods, ultimately concluding that the ARIMA model provides better predictions than the ETS model for the given dataset.




1 out of 14
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.