Business Data Analysis Assignment - Higher Diploma in Data Analytics
VerifiedAdded on 2023/06/09
|19
|3035
|215
Homework Assignment
AI Summary
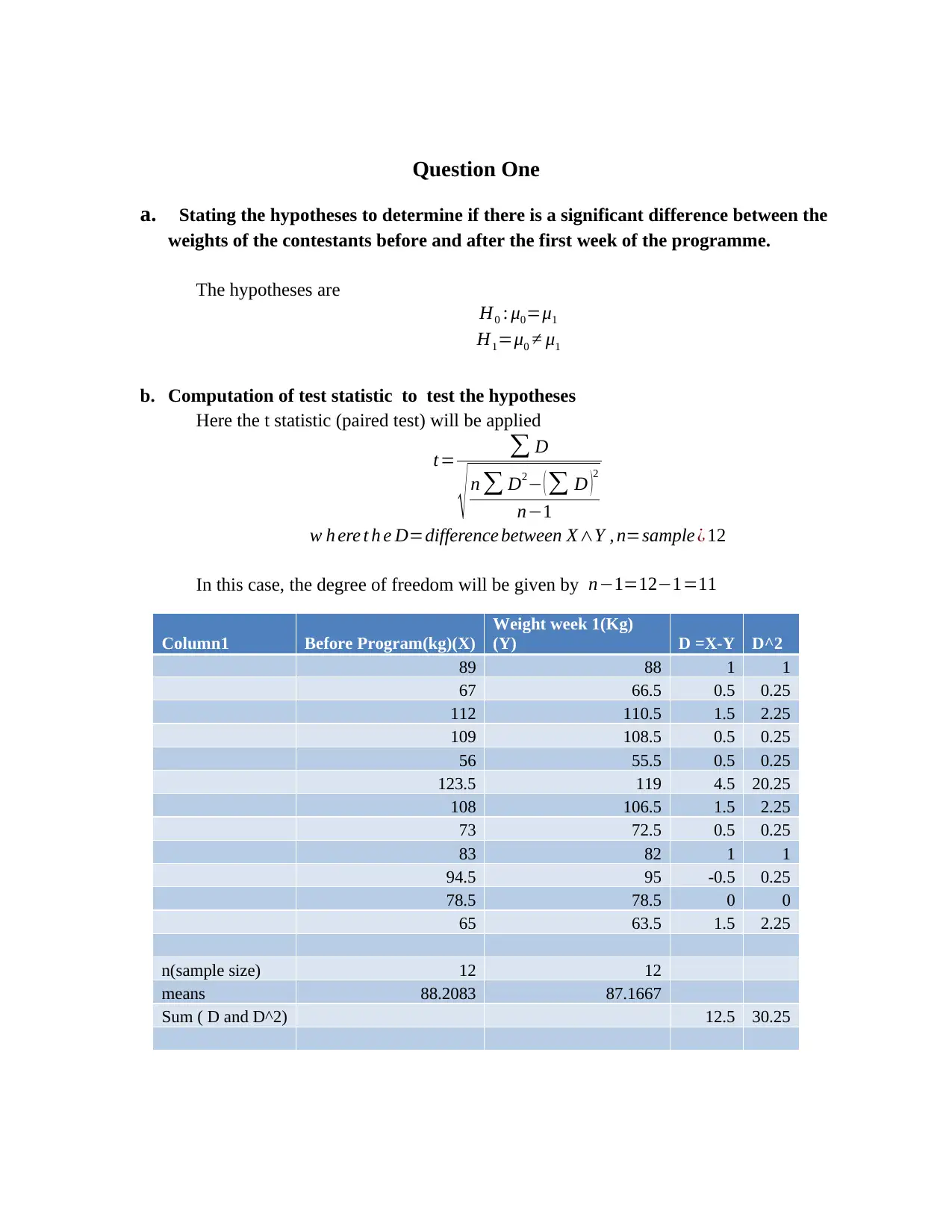
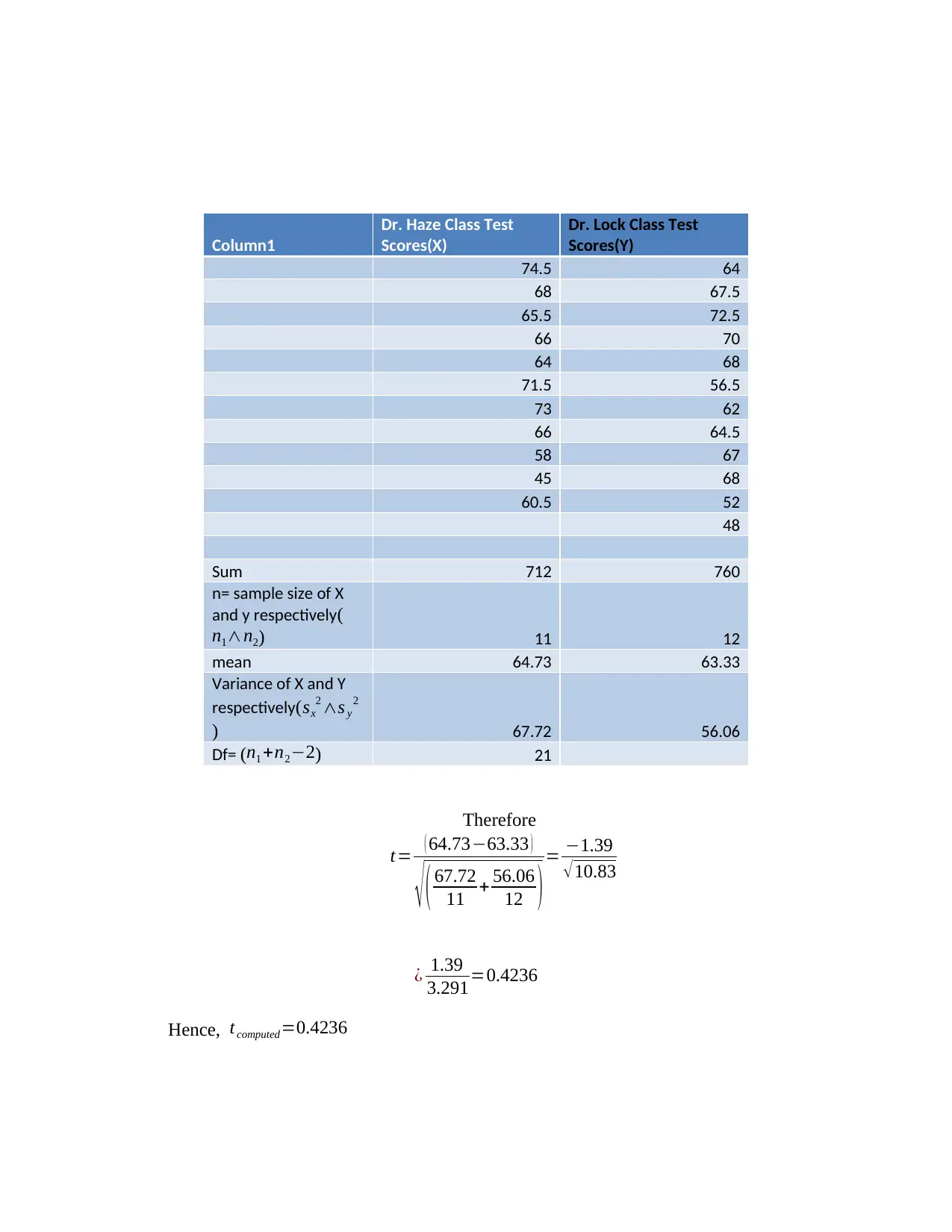
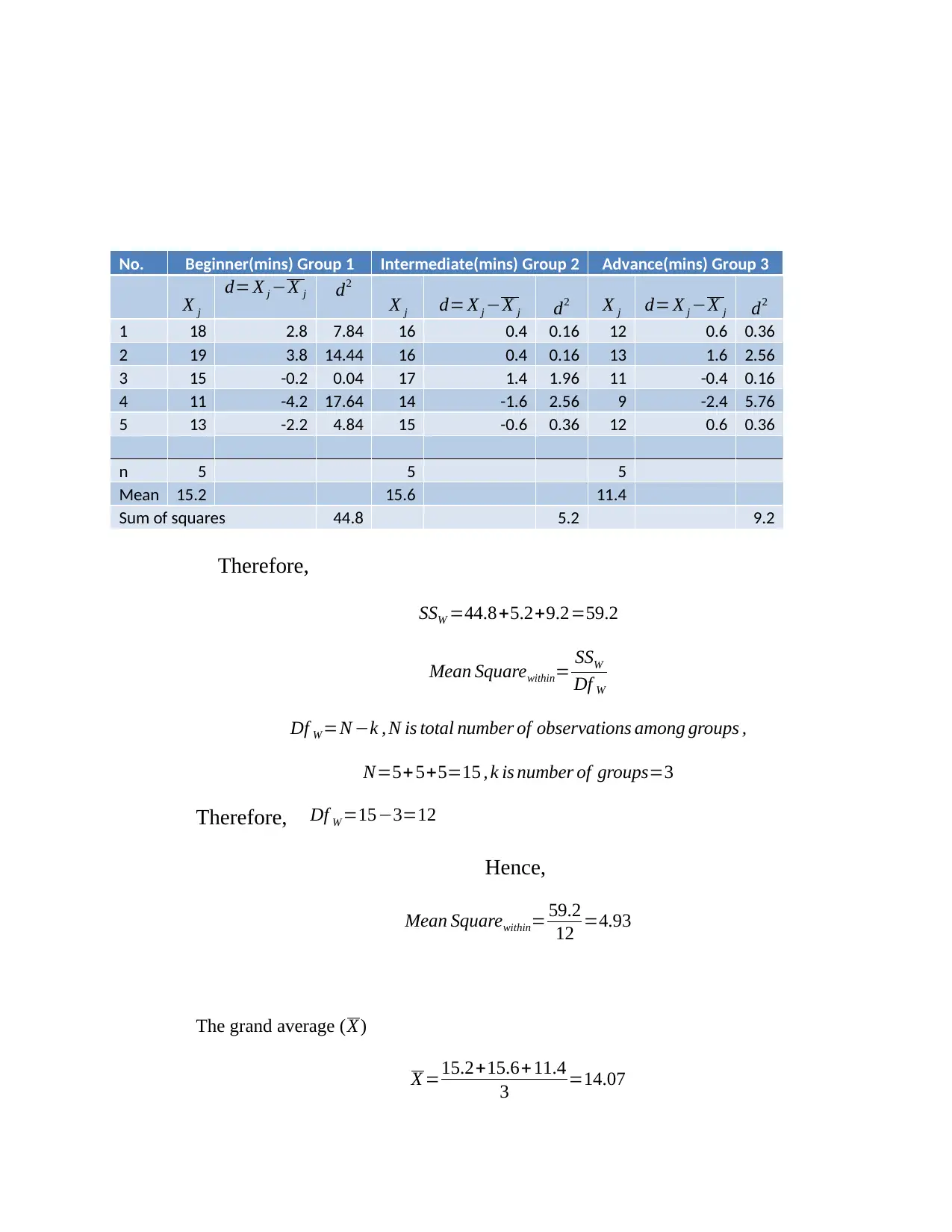
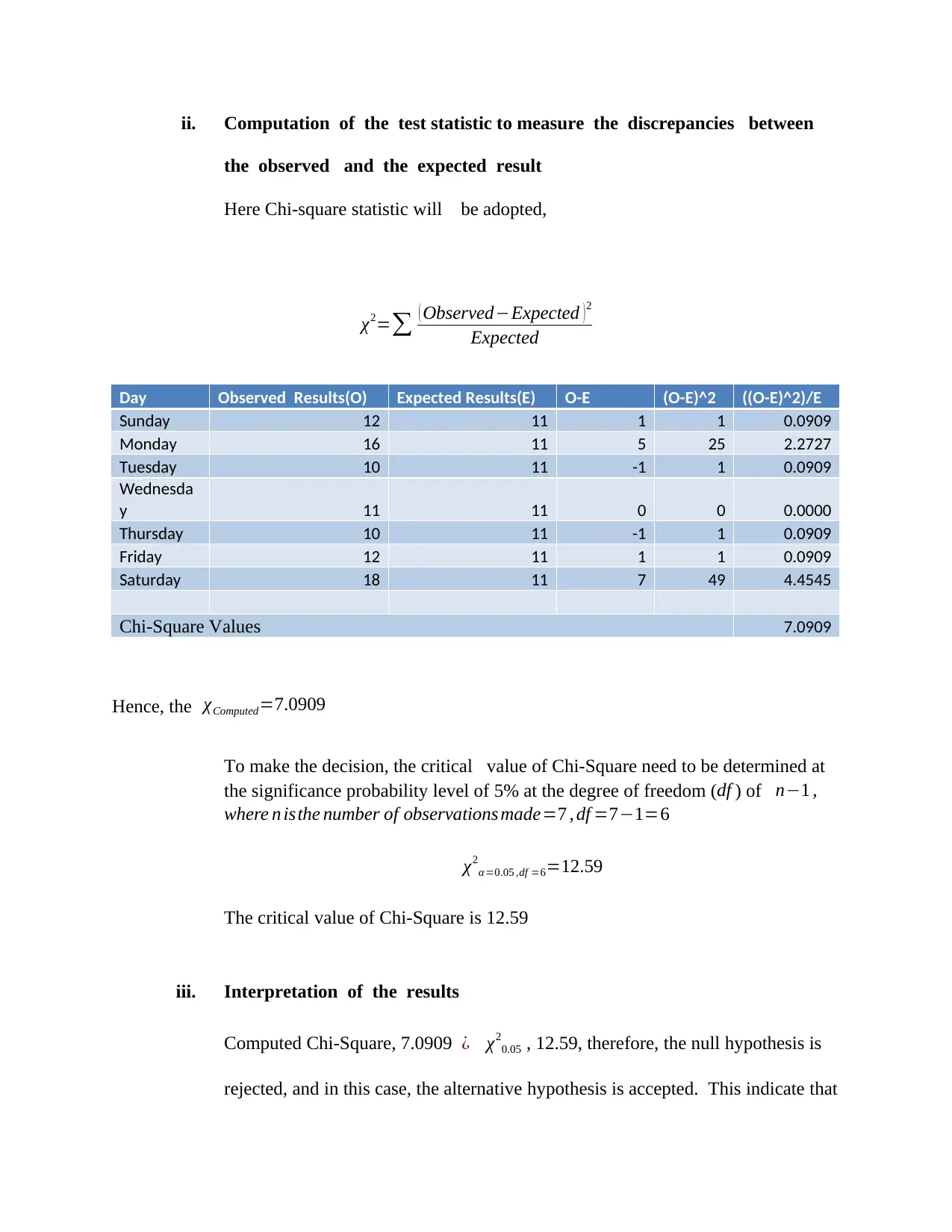
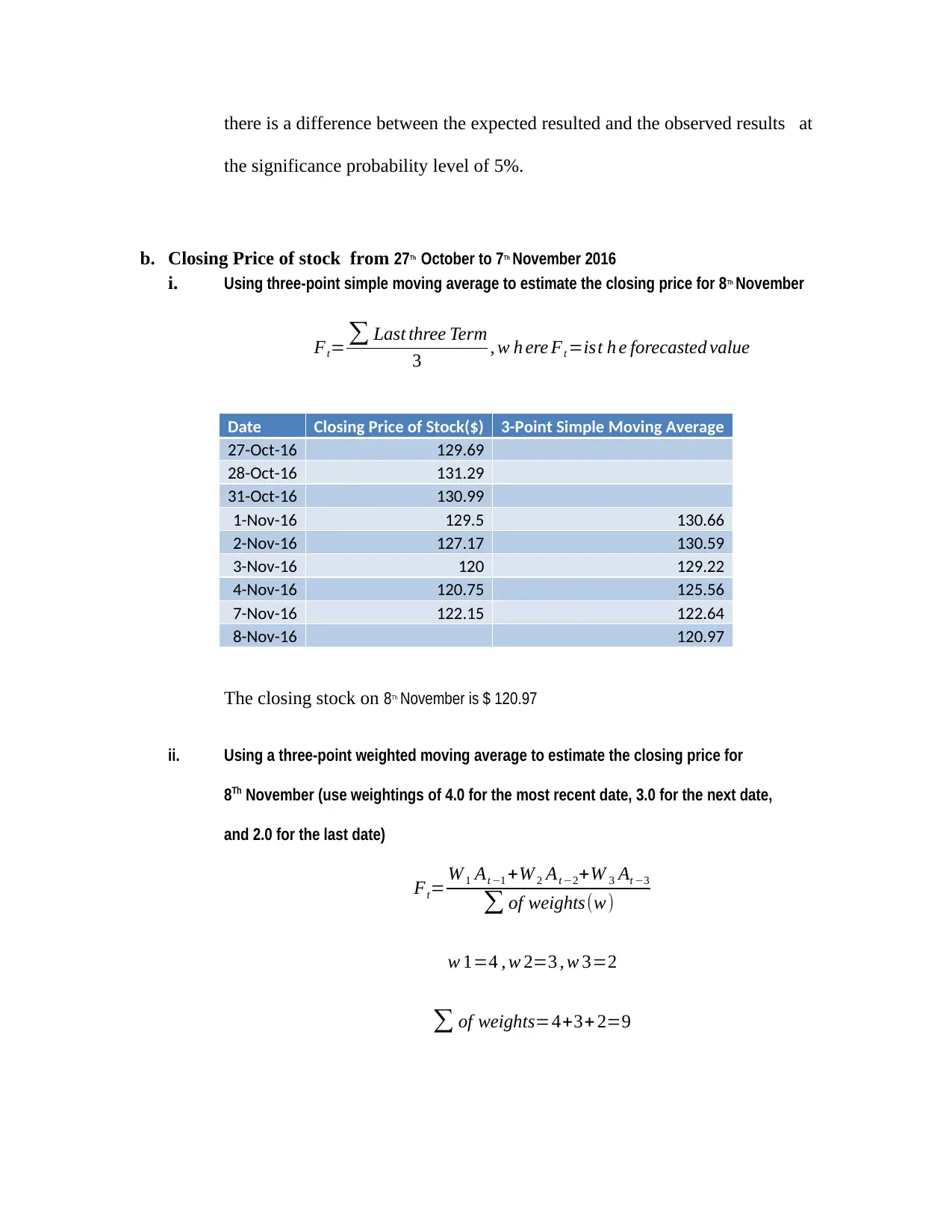
This assignment solution addresses a Business Data Analysis exam from the National College of Ireland, covering multiple statistical methods. Question one involves a paired t-test to compare contestant weights before and after a weight-loss program, including hypothesis formulation, test statistic calculation, error probability specification, and result interpretation. Question two presents an unpaired t-test to determine if there's a significant difference between the test scores of two classes, detailing hypothesis testing, test statistic calculation, error probability, and decision-making. Question three utilizes one-way ANOVA to analyze the difference between three training methods, covering hypothesis, F-statistic calculation, error probability specification, and result interpretation. Question four explores Chi-square to analyze road traffic accident data and time series analysis using moving average and exponential smoothing to forecast stock prices. The solution provides detailed calculations and interpretations for each question.







1 out of 19
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.