Solutions to Statistical Problems: Quiz Data, Sampling Analysis
VerifiedAdded on 2023/06/12
|11
|1761
|94
Homework Assignment
AI Summary
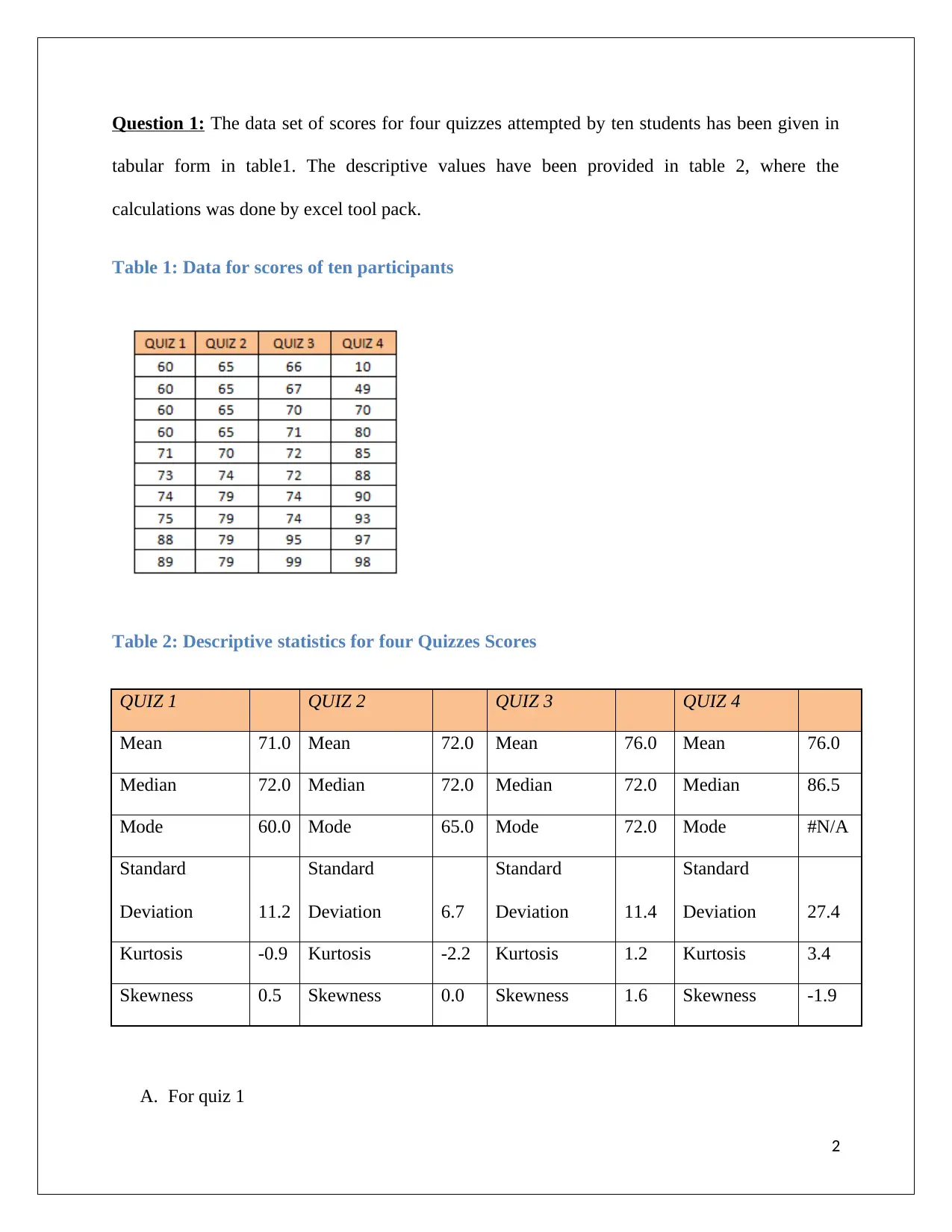
This assignment provides solutions to several statistical problems. The first problem analyzes quiz scores from ten students across four quizzes, calculating and interpreting descriptive statistics such as mean, median, mode, standard deviation, skewness, and kurtosis. It compares these measures to assess the central tendency and data distribution for each quiz. The second problem focuses on sampling, specifically calculating the confidence interval for the proportion of almonds in a sample and determining the necessary sample size for a given error. It also discusses the importance of sampling knowledge for a quality control manager. The third problem examines a regression model, interpreting the significance of the price coefficient and the R-squared value in relation to sound quality. Finally, the fourth problem deals with hypothesis testing, defining null and alternative hypotheses, identifying Type I and Type II errors, and discussing the implications of these errors from both the company's and the customer's perspectives.







1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.