Data Analysis and Assumptions: A Report on Statistical Testing
VerifiedAdded on 2023/06/15

RUNNINGHEAD: Understanding and Exploring Assumptions
Question 1. Why meeting of assumptions for a statistical test is important.
According to Charles Zaiontz ”…most of the statistical tests we perform are based on a set of
assumptions. When these assumptions are violated the results of the analysis can be misleading
or completely erroneous…” Most often the tests that assumptions during statistical tests carried
out include: (Charles 2015).
i. Assumption of normality.(Data is symmetrical)
ii. Homogeneity of variances. (Variance is the same for data)
iii. Linearity.( Tested data has linear relationships)
iv. Independence. (Tested data is independent).
“Many statistical tests have assumptions that must be met in order to ensure that the data
collected is appropriate for the types of analyses you want to conduct. Common assumptions that
must be met for parametric statistics include normality, independence, linearity, and
homoscedasticity. Failure to meet these assumptions, among others, can result in inaccurate
results, which are problematic for many reasons. When testing hypotheses, running analyses on
data that has violated the assumptions of the statistical test can result in both false negatives and
false positives, depending on the particular assumption violated.” (Elite research 2012). This is
against the very aim of carrying out the statistical analysis which whose main reason is to ensure
that correct assumptions are met, analysis done, output interpreted and the results put into
importance. Failing to meet assumptions, results to misguided analysis and eventually inaccurate
interpretation.
Paraphrase This Document

Understanding and Exploring Assumptions
However in any statistical test, the assumptions may fail to be met, this calls for scrutiny and
accuracy in the whole process. This can be done, according to Lund research limited through
following the basic steps of:
i. Understand the required assumptions.
ii. Check whether the assumptions are met.
iii. Find solutions if assumptions are not met. (laerd statistics 2013).
Understanding and Exploring Assumptions
Question 2. Creating a histogram for each variable.
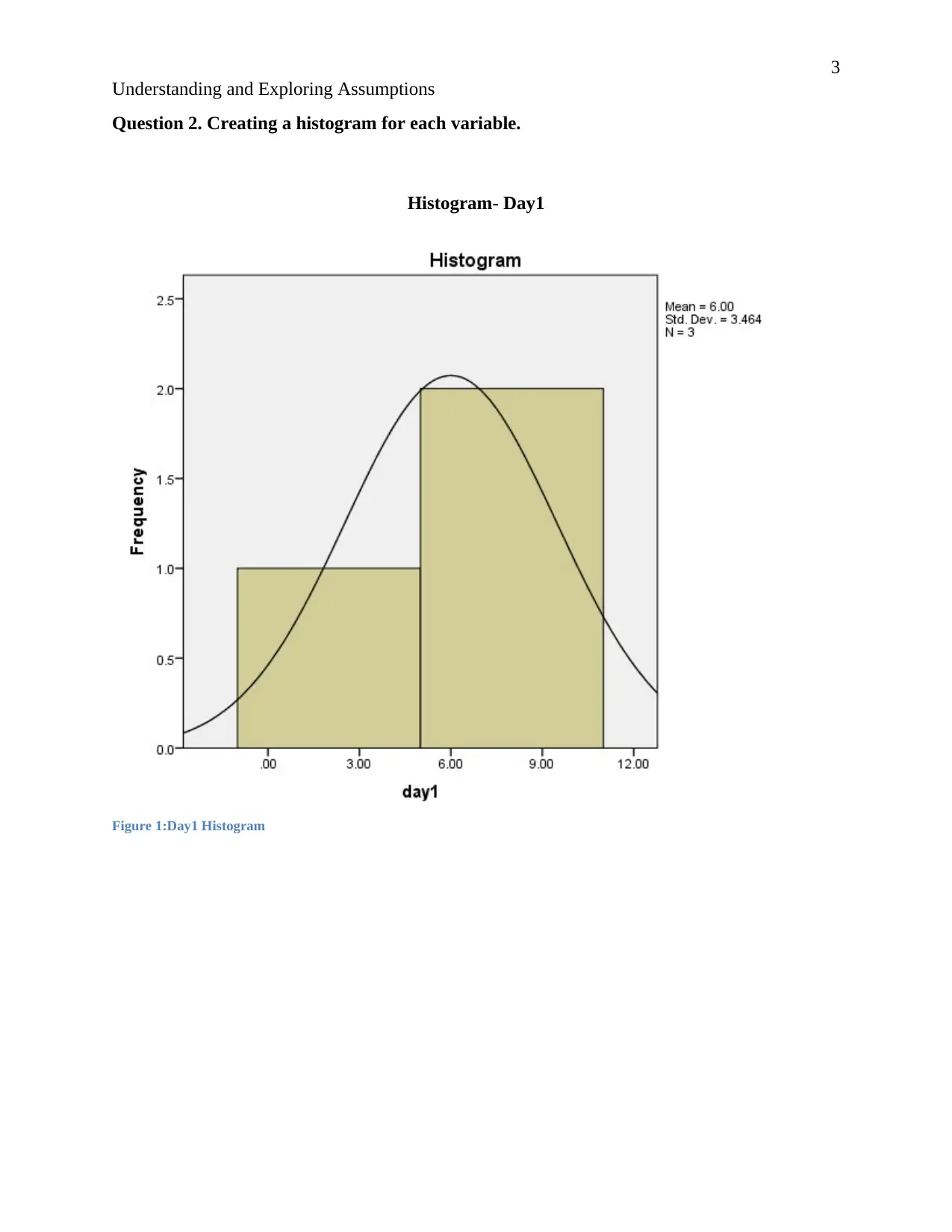
Histogram- Day1
Figure 1:Day1 Histogram
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
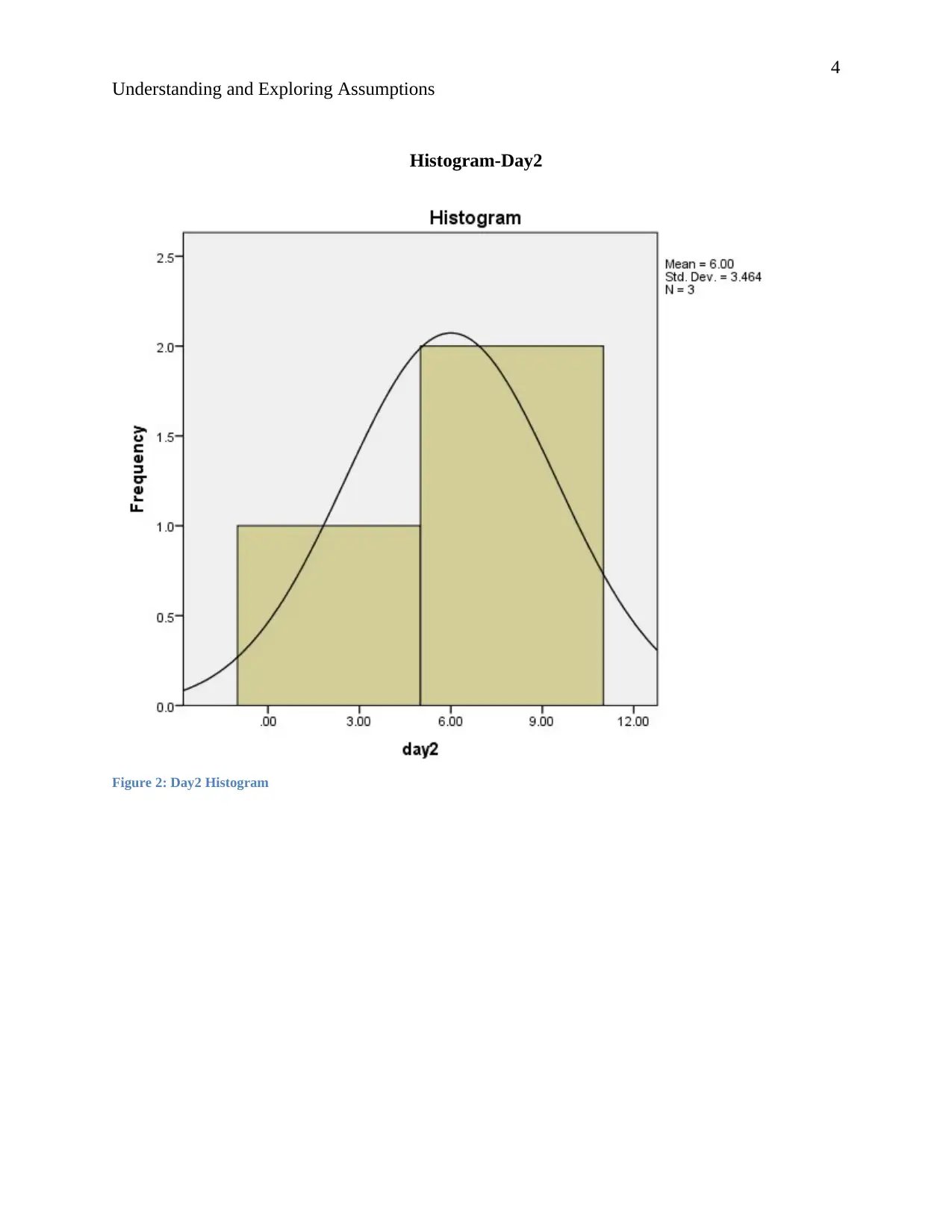
Histogram-Day2
Figure 2: Day2 Histogram
Paraphrase This Document

Understanding and Exploring Assumptions
Histogram –Day3
Figure 3:Day3 Histogram.
Understanding and Exploring Assumptions
Question 3.
Normal p-p plots for the three days.
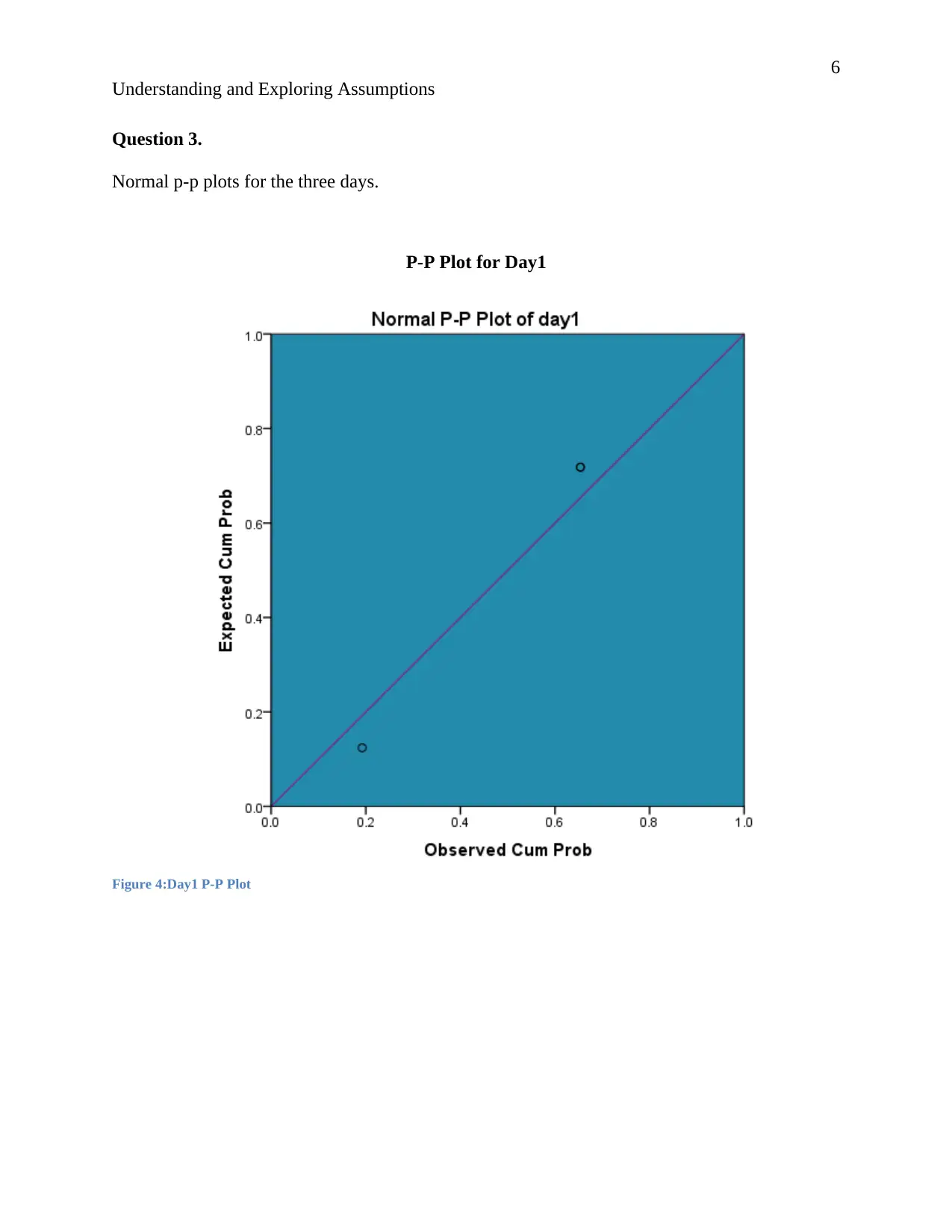
P-P Plot for Day1
Figure 4:Day1 P-P Plot
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
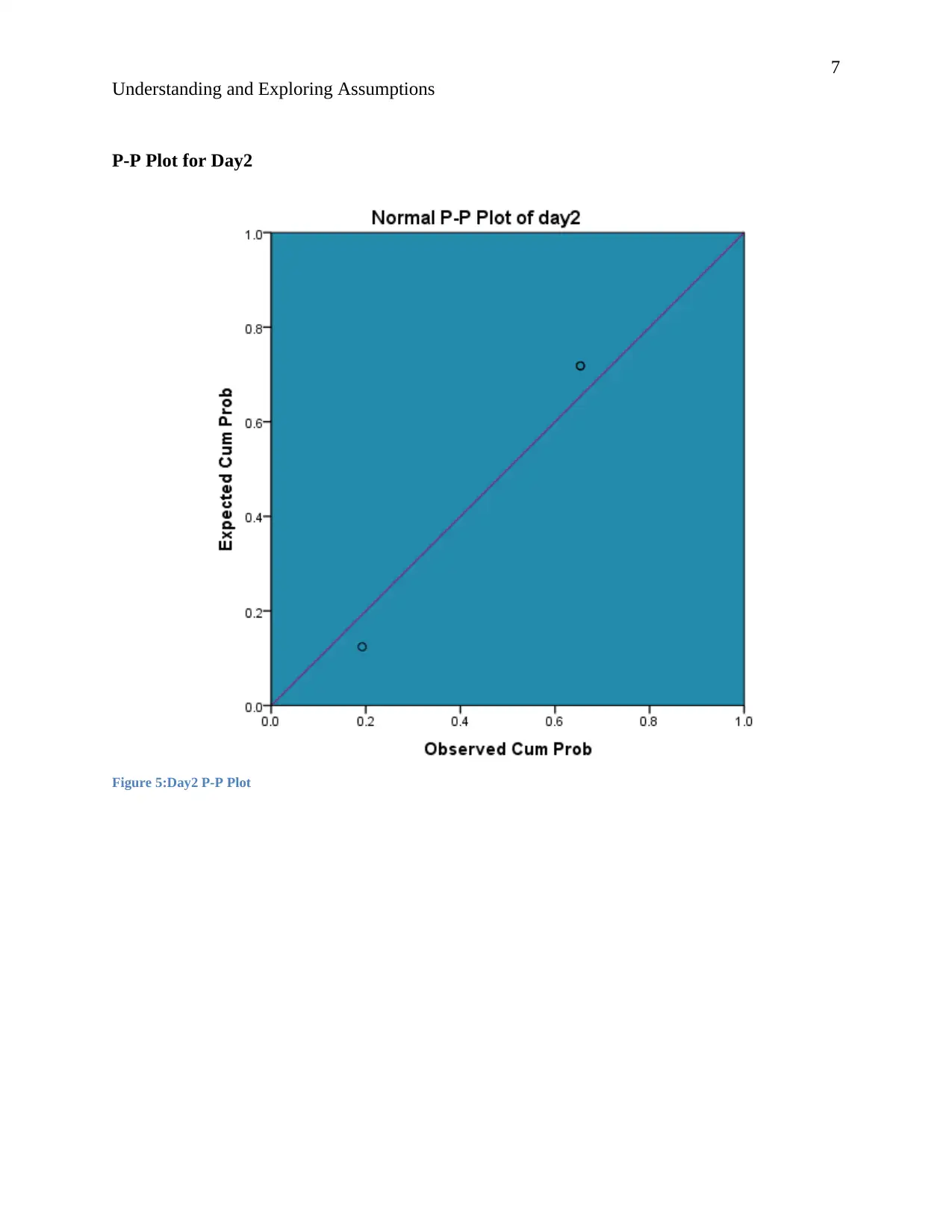
P-P Plot for Day2
Figure 5:Day2 P-P Plot
Paraphrase This Document
Understanding and Exploring Assumptions
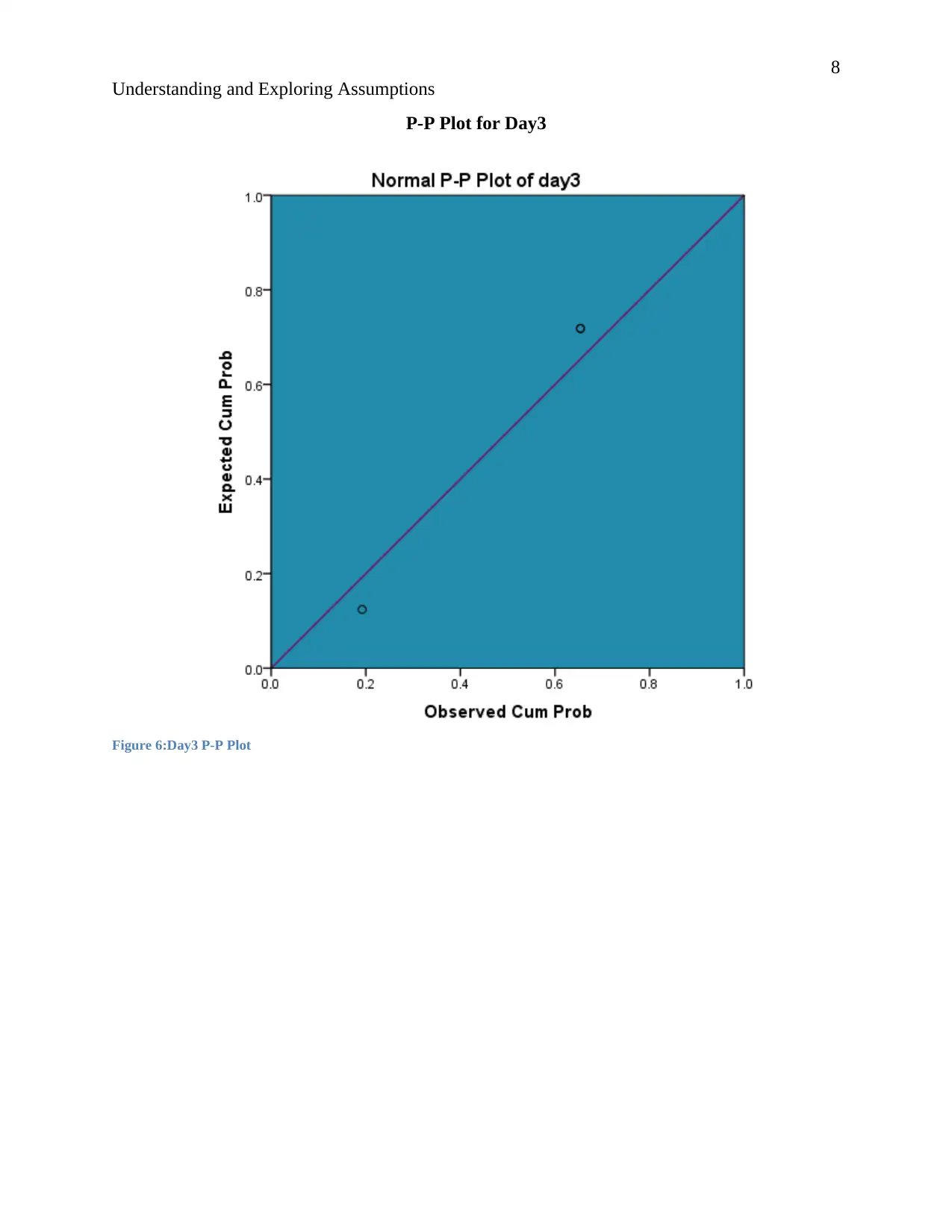
P-P Plot for Day3
Figure 6:Day3 P-P Plot

Understanding and Exploring Assumptions
Question 4. Description of the downloadfestival dataset with attention towards normality.
Day 1.
According to PQ systems “A second characteristic of the normal distribution is that it is
symmetrical. This means that if the distribution is cut in half, each side would be the mirror
of the other. It also must form a bell-shaped curve to be normal…”(PQsystems 2016). In the
day1 data the normal curve is bell shaped and the histogram is symmetric, this shows that the
data is normally distributed. Also the distribution on the p-p plot indicates that the data is
evenly distributed over the range. Hence we can say with certainty that the data for day one
follows a normal distribution.
Day2.
The normal curve of day 2 is bell shaped. This implies that the data is symmetrical as seen
from the histogram. Observing the p-p plot the data is even place along the regression line.
This indicates that the data follows a normal distribution.
Day3
In day three the p-p plot indicates that the residuals are evenly distributed over and below the
regression line. The normal curve is also bell shaped. Hence the data is symmetrical implying
that it follows a normal distribution.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
Question 5
Exploring measures of central tendencies.
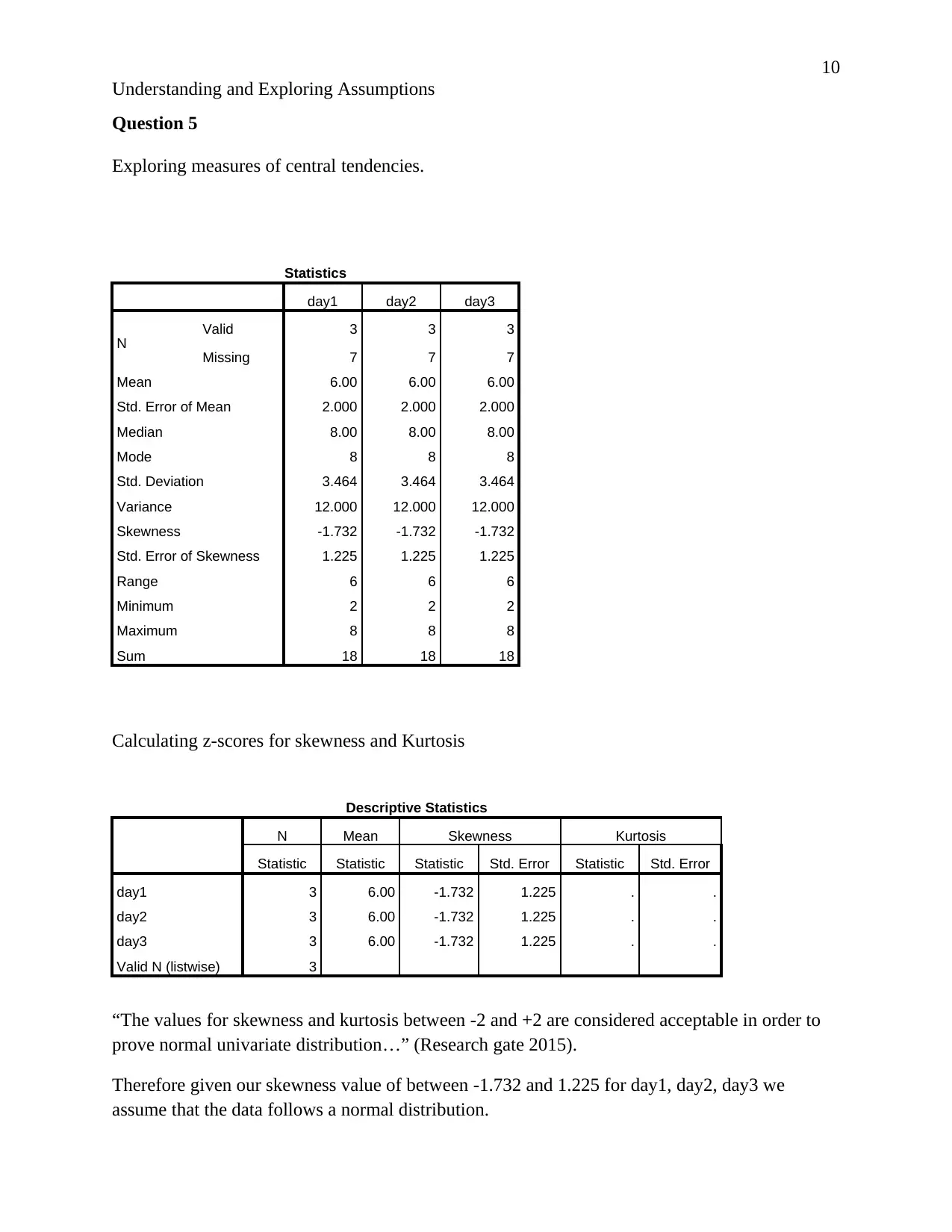
Statistics
day1 day2 day3
N Valid 3 3 3
Missing 7 7 7
Mean 6.00 6.00 6.00
Std. Error of Mean 2.000 2.000 2.000
Median 8.00 8.00 8.00
Mode 8 8 8
Std. Deviation 3.464 3.464 3.464
Variance 12.000 12.000 12.000
Skewness -1.732 -1.732 -1.732
Std. Error of Skewness 1.225 1.225 1.225
Range 6 6 6
Minimum 2 2 2
Maximum 8 8 8
Sum 18 18 18
Calculating z-scores for skewness and Kurtosis
Descriptive Statistics
N Mean Skewness Kurtosis
Statistic Statistic Statistic Std. Error Statistic Std. Error
day1 3 6.00 -1.732 1.225 . .
day2 3 6.00 -1.732 1.225 . .
day3 3 6.00 -1.732 1.225 . .
Valid N (listwise) 3
“The values for skewness and kurtosis between -2 and +2 are considered acceptable in order to
prove normal univariate distribution…” (Research gate 2015).
Therefore given our skewness value of between -1.732 and 1.225 for day1, day2, day3 we
assume that the data follows a normal distribution.
Paraphrase This Document
Understanding and Exploring Assumptions
These imply that the assumptions in question 1 are met.
Question6
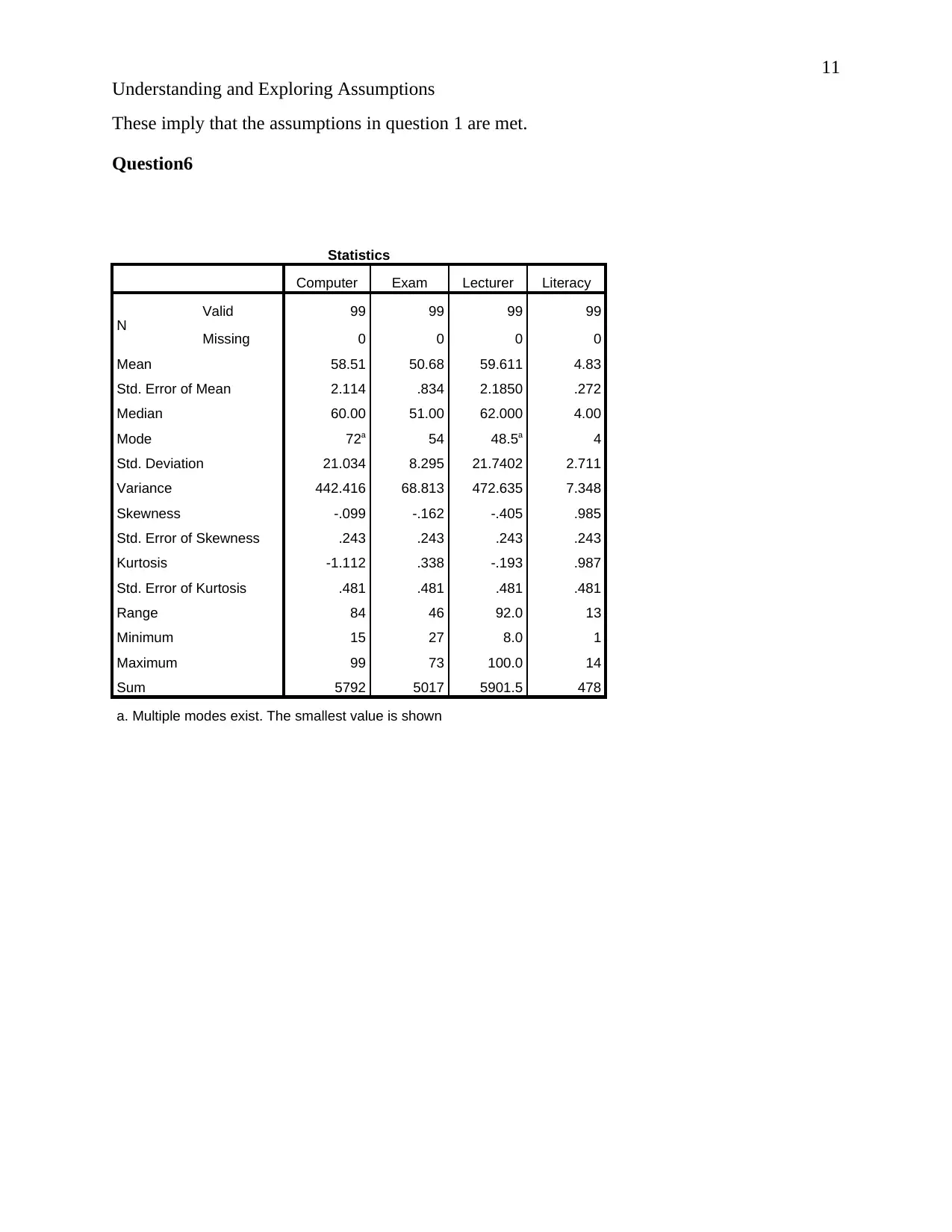
Statistics
Computer Exam Lecturer Literacy
N Valid 99 99 99 99
Missing 0 0 0 0
Mean 58.51 50.68 59.611 4.83
Std. Error of Mean 2.114 .834 2.1850 .272
Median 60.00 51.00 62.000 4.00
Mode 72a 54 48.5a 4
Std. Deviation 21.034 8.295 21.7402 2.711
Variance 442.416 68.813 472.635 7.348
Skewness -.099 -.162 -.405 .985
Std. Error of Skewness .243 .243 .243 .243
Kurtosis -1.112 .338 -.193 .987
Std. Error of Kurtosis .481 .481 .481 .481
Range 84 46 92.0 13
Minimum 15 27 8.0 1
Maximum 99 73 100.0 14
Sum 5792 5017 5901.5 478
a. Multiple modes exist. The smallest value is shown
Understanding and Exploring Assumptions
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
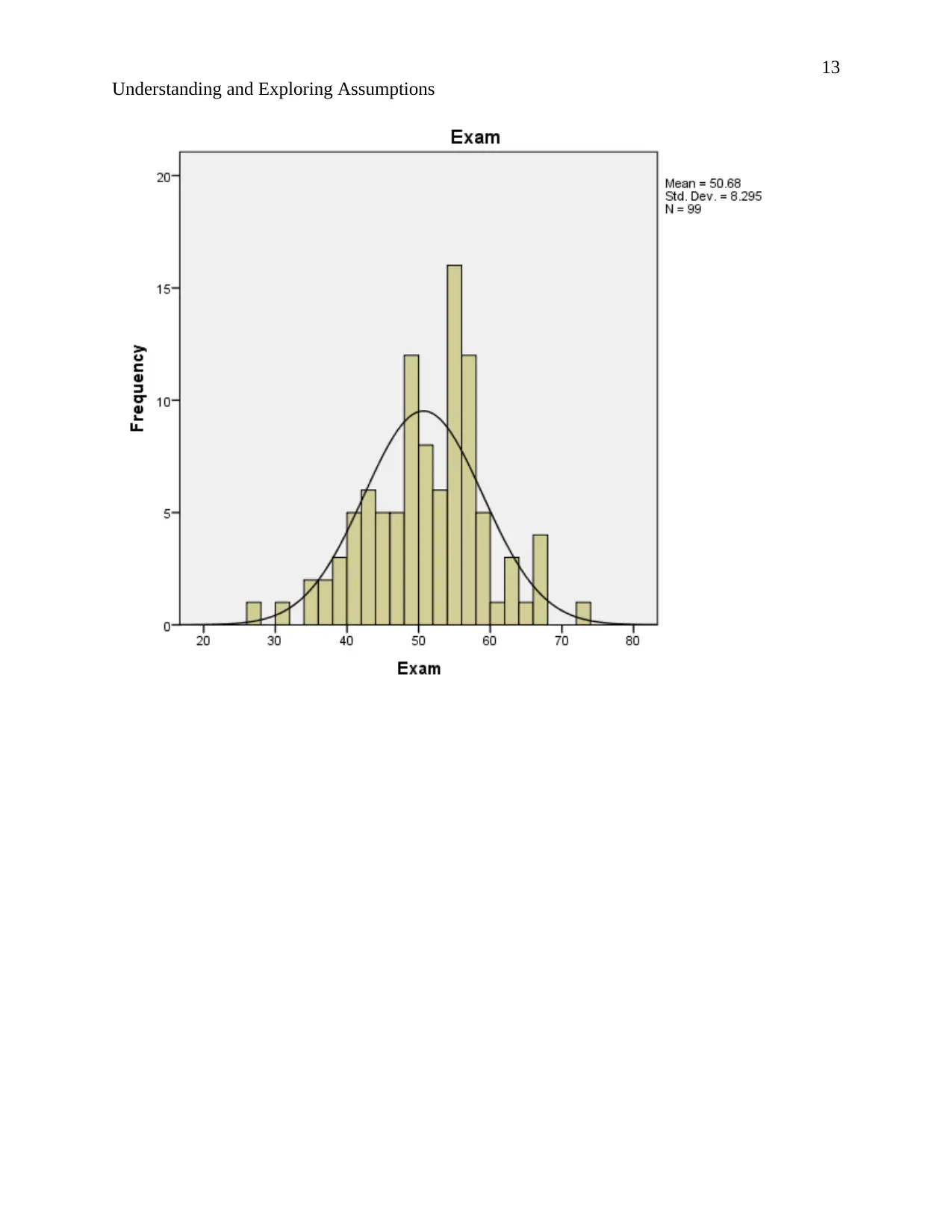
Understanding and Exploring Assumptions
Paraphrase This Document
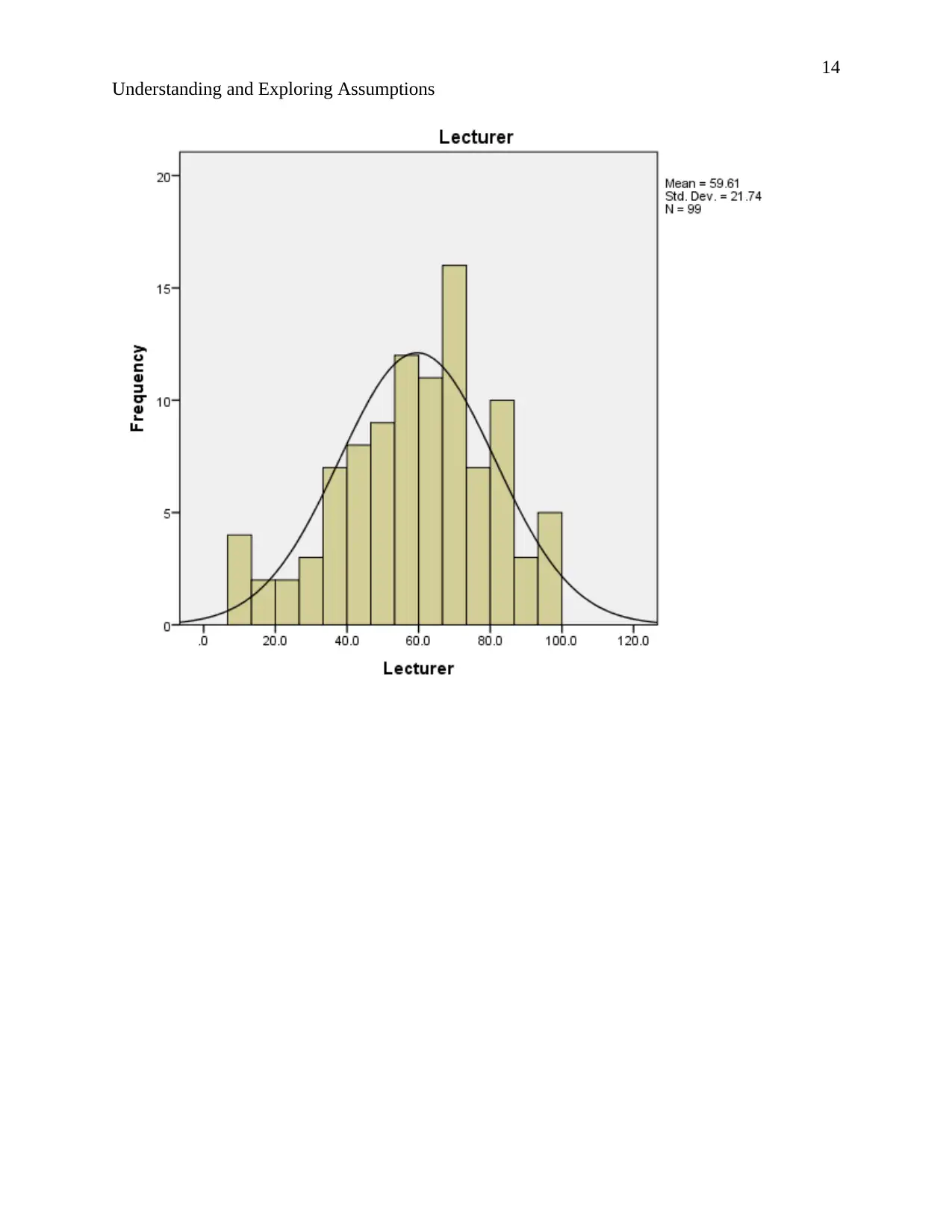
Understanding and Exploring Assumptions
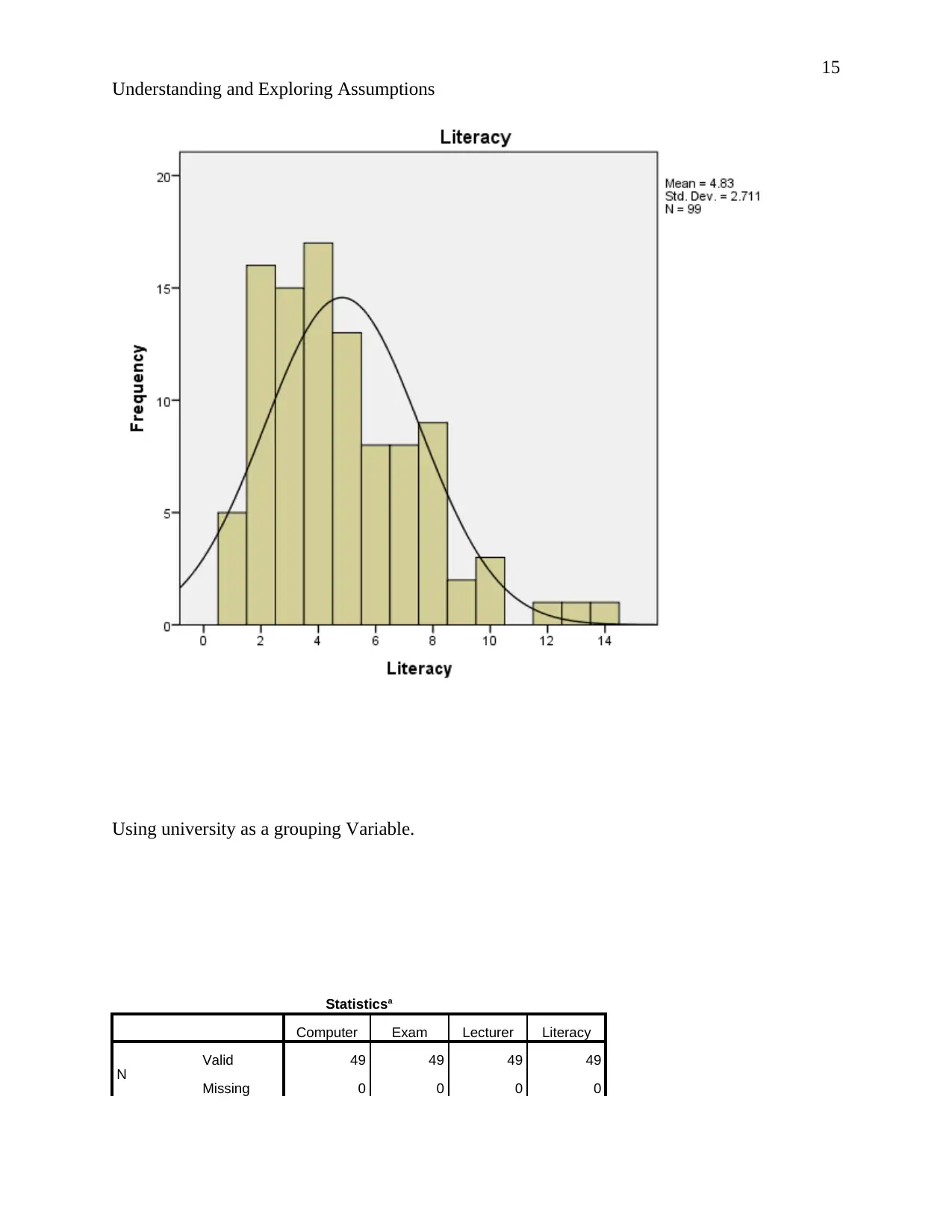
Understanding and Exploring Assumptions
Using university as a grouping Variable.
Statisticsa
Computer Exam Lecturer Literacy
N Valid 49 49 49 49
Missing 0 0 0 0
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
Mean 40.63 50.18 55.878 4.06
Std. Error of Mean 1.757 1.162 3.4090 .292
Median 38.00 49.00 60.000 4.00
Mode 34b 48b 48.5b 4
Std. Deviation 12.301 8.133 23.8630 2.045
Variance 151.321 66.153 569.443 4.184
Skewness .351 .252 -.272 .569
Std. Error of Skewness .340 .340 .340 .340
Kurtosis -.564 -.534 -.394 -.335
Std. Error of Kurtosis .668 .668 .668 .668
Range 51 32 92.0 8
Minimum 15 35 8.0 1
Maximum 66 67 100.0 9
Sum 1991 2459 2738.0 199
a. University = 0
b. Multiple modes exist. The smallest value is shown
Paraphrase This Document
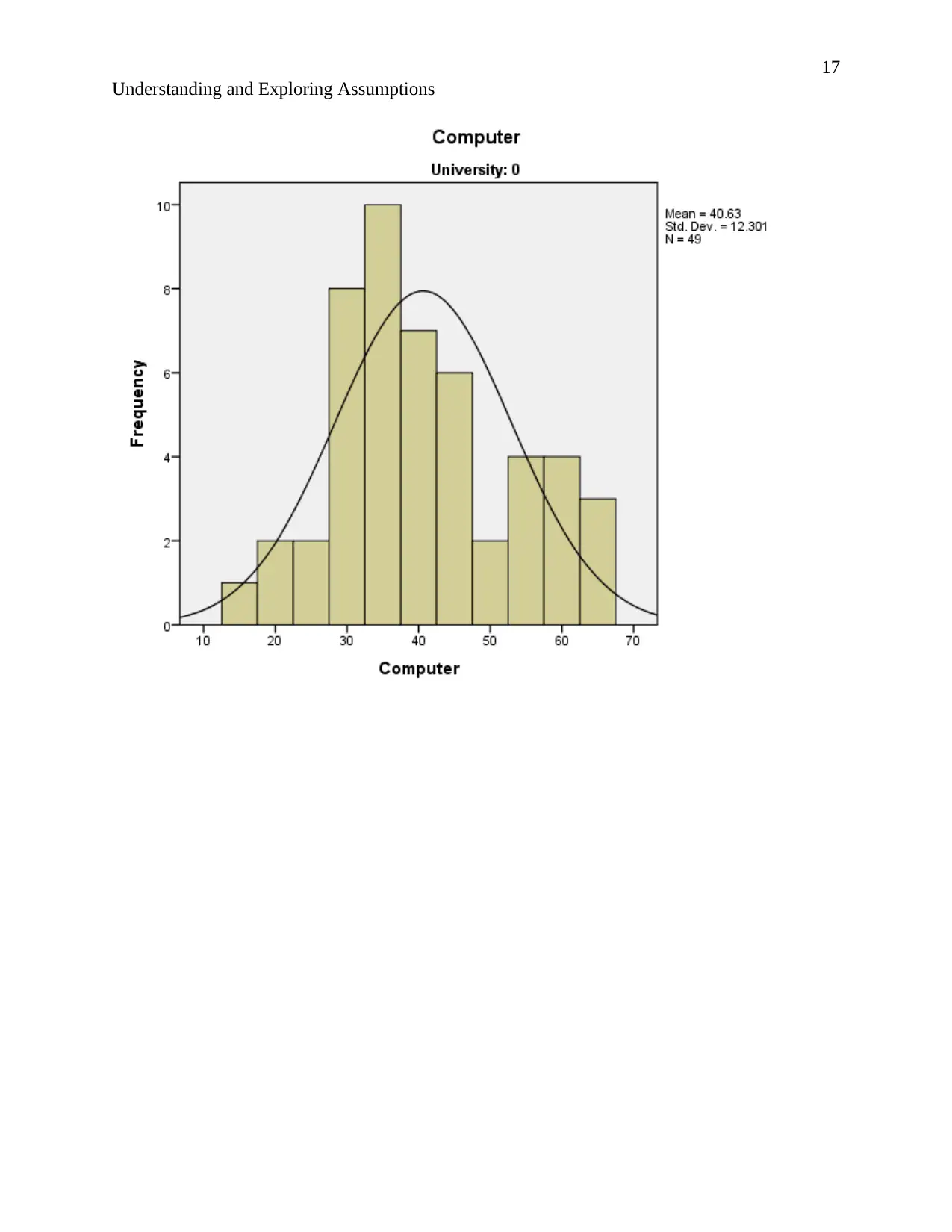
Understanding and Exploring Assumptions
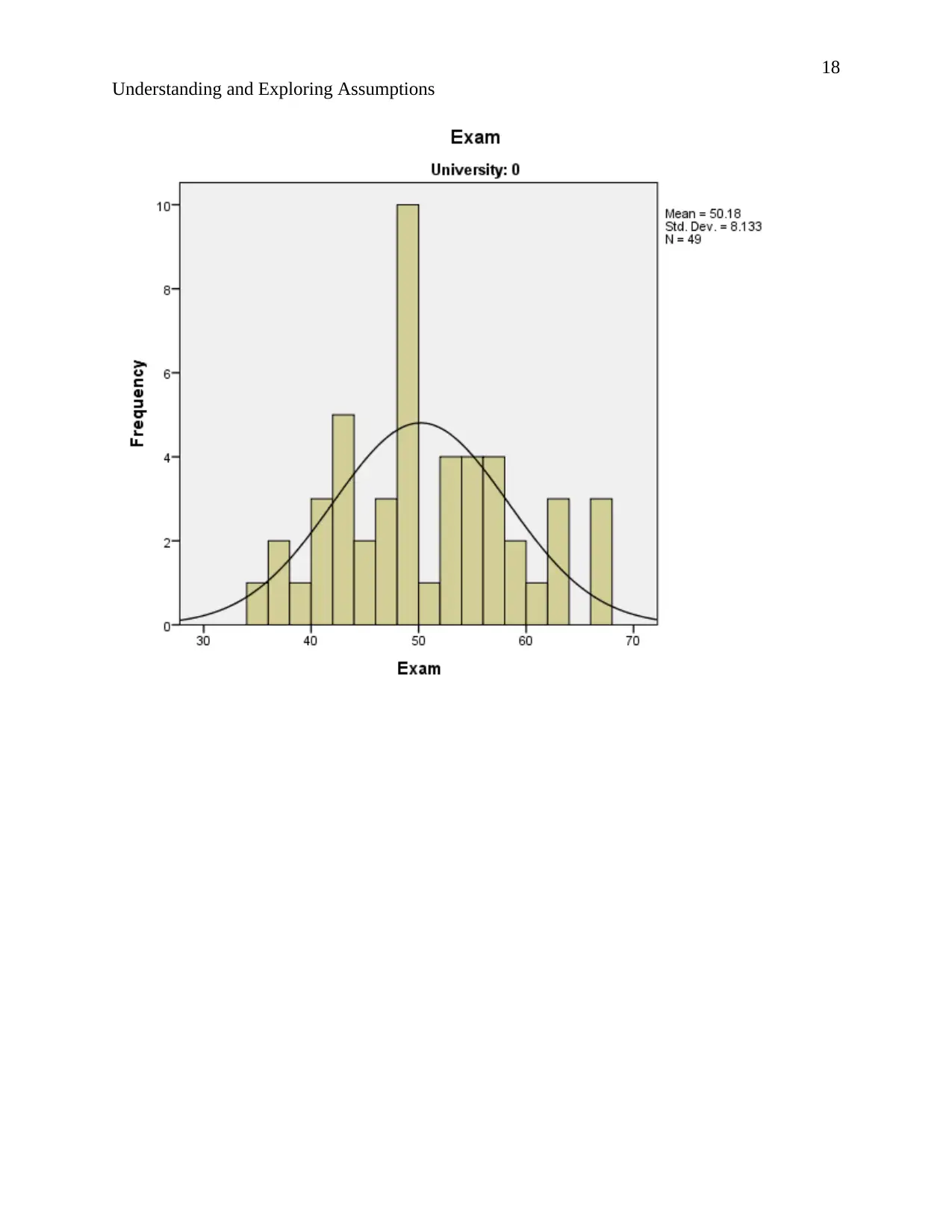
Understanding and Exploring Assumptions
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
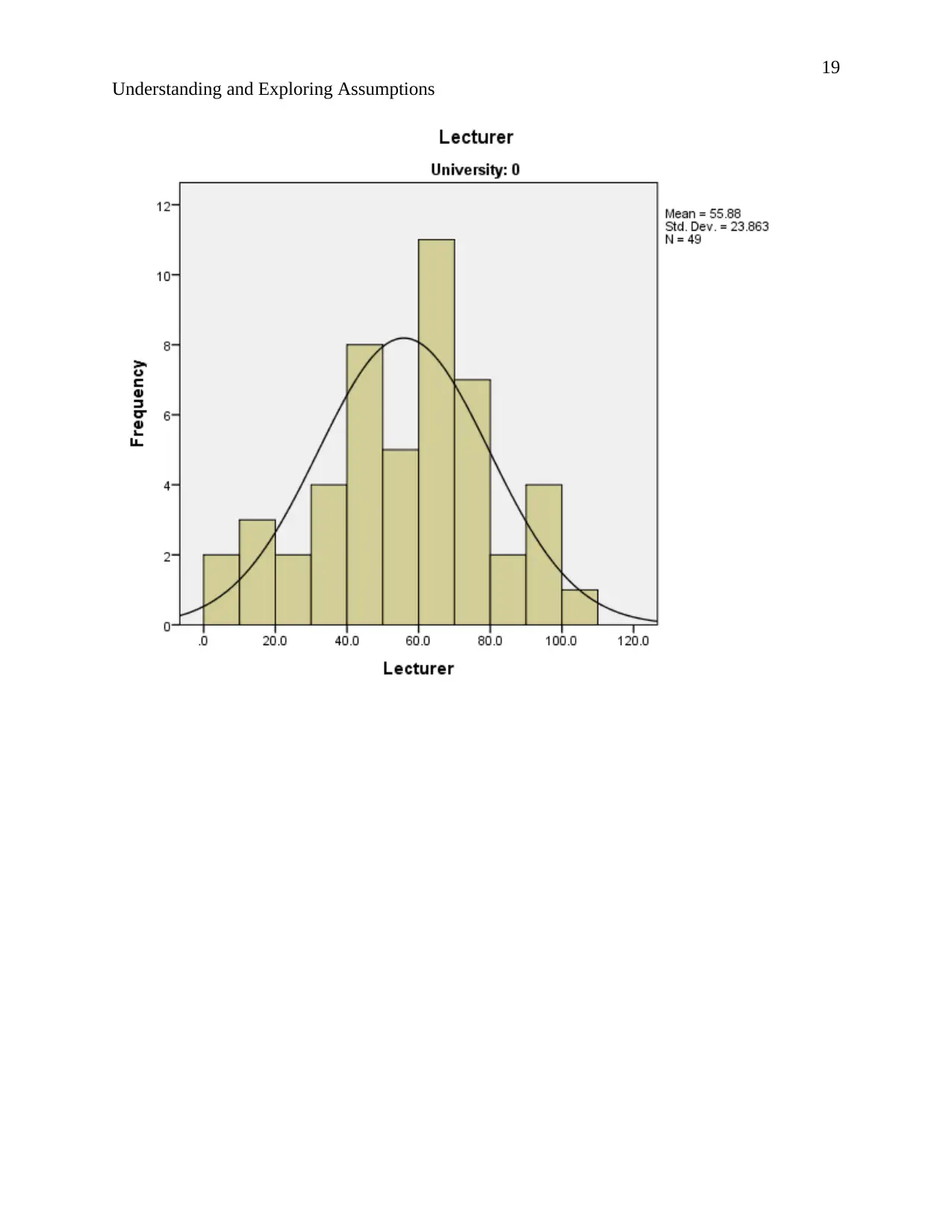
Understanding and Exploring Assumptions
Paraphrase This Document
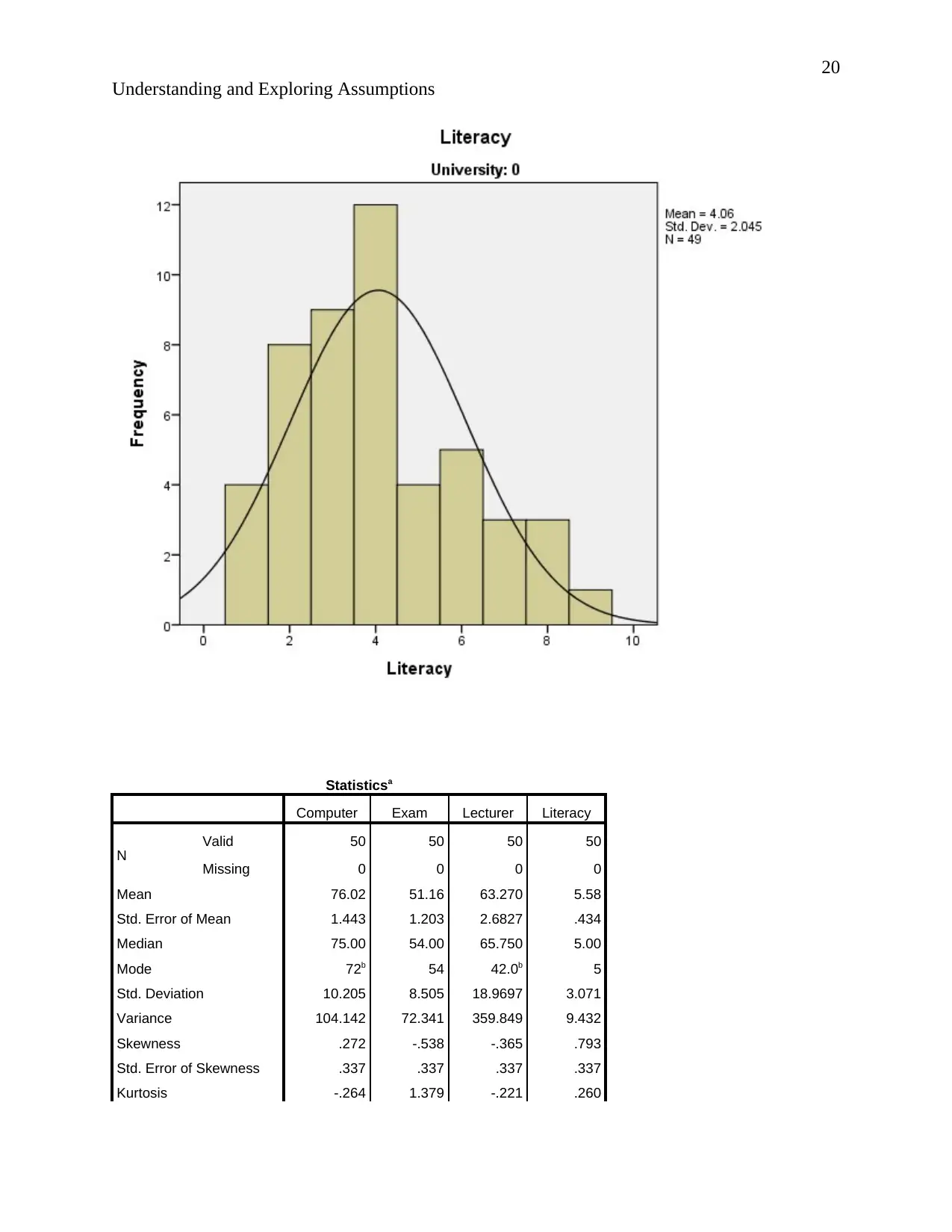
Understanding and Exploring Assumptions
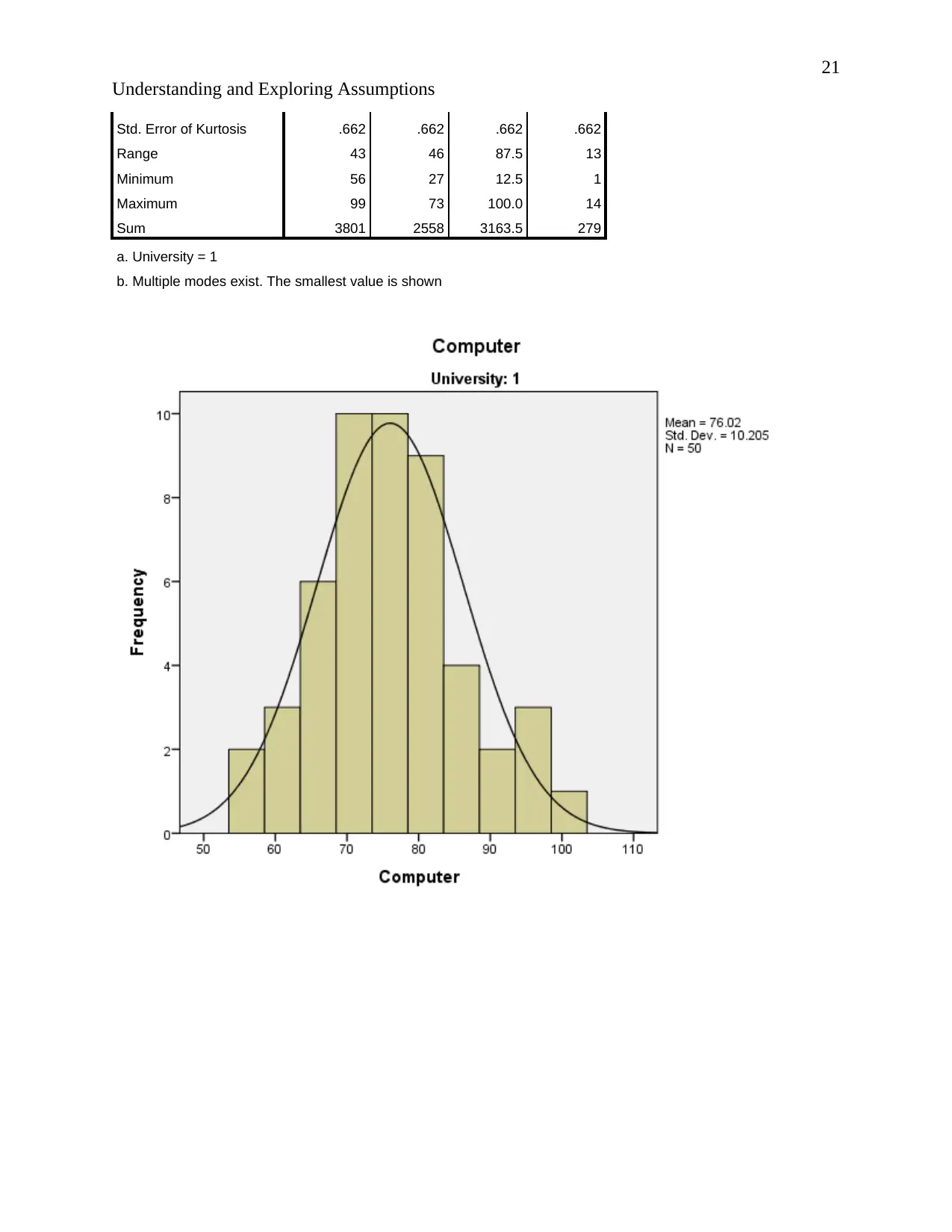
Statisticsa
Computer Exam Lecturer Literacy
N Valid 50 50 50 50
Missing 0 0 0 0
Mean 76.02 51.16 63.270 5.58
Std. Error of Mean 1.443 1.203 2.6827 .434
Median 75.00 54.00 65.750 5.00
Mode 72b 54 42.0b 5
Std. Deviation 10.205 8.505 18.9697 3.071
Variance 104.142 72.341 359.849 9.432
Skewness .272 -.538 -.365 .793
Std. Error of Skewness .337 .337 .337 .337
Kurtosis -.264 1.379 -.221 .260
Understanding and Exploring Assumptions
Std. Error of Kurtosis .662 .662 .662 .662
Range 43 46 87.5 13
Minimum 56 27 12.5 1
Maximum 99 73 100.0 14
Sum 3801 2558 3163.5 279
a. University = 1
b. Multiple modes exist. The smallest value is shown
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
Paraphrase This Document
Understanding and Exploring Assumptions
Understanding and Exploring Assumptions
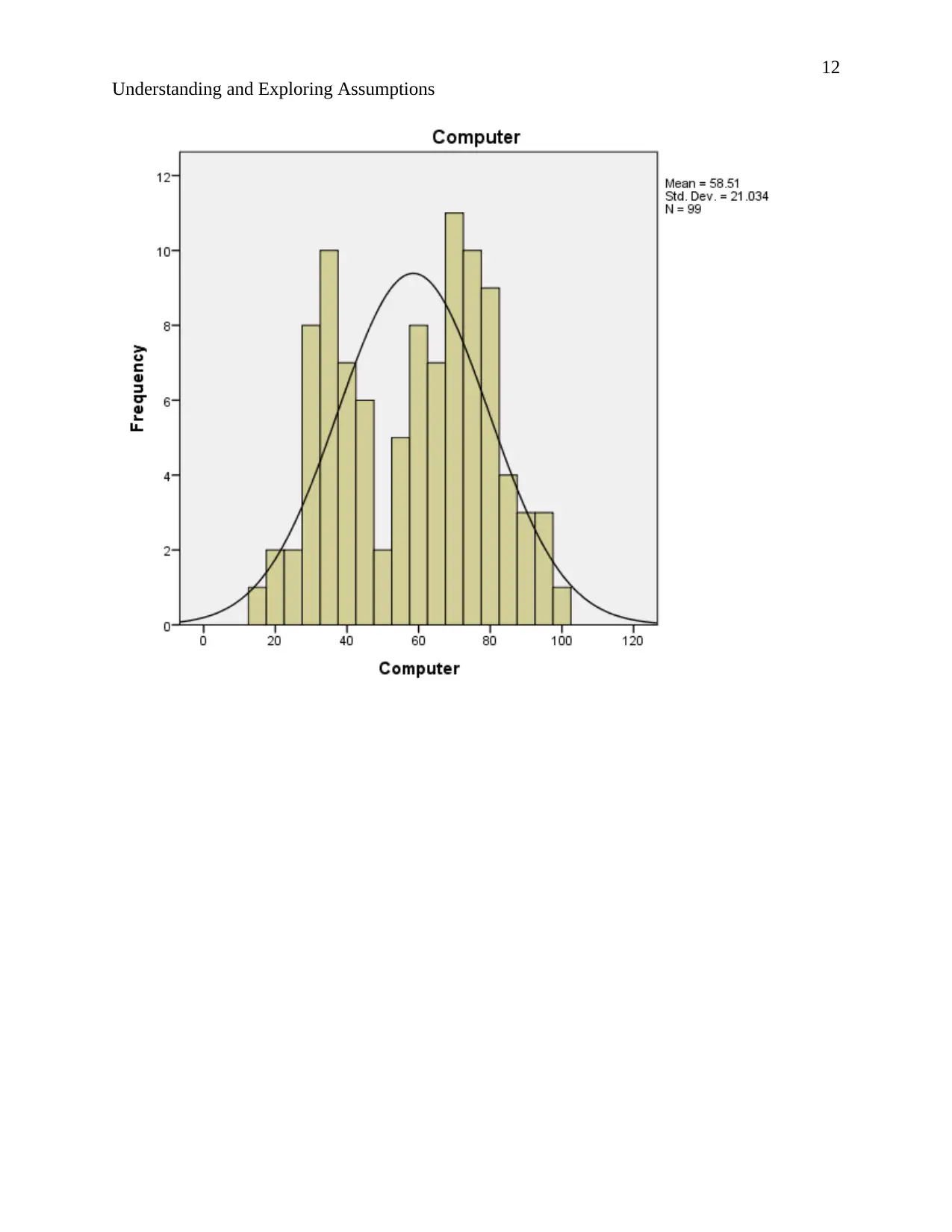
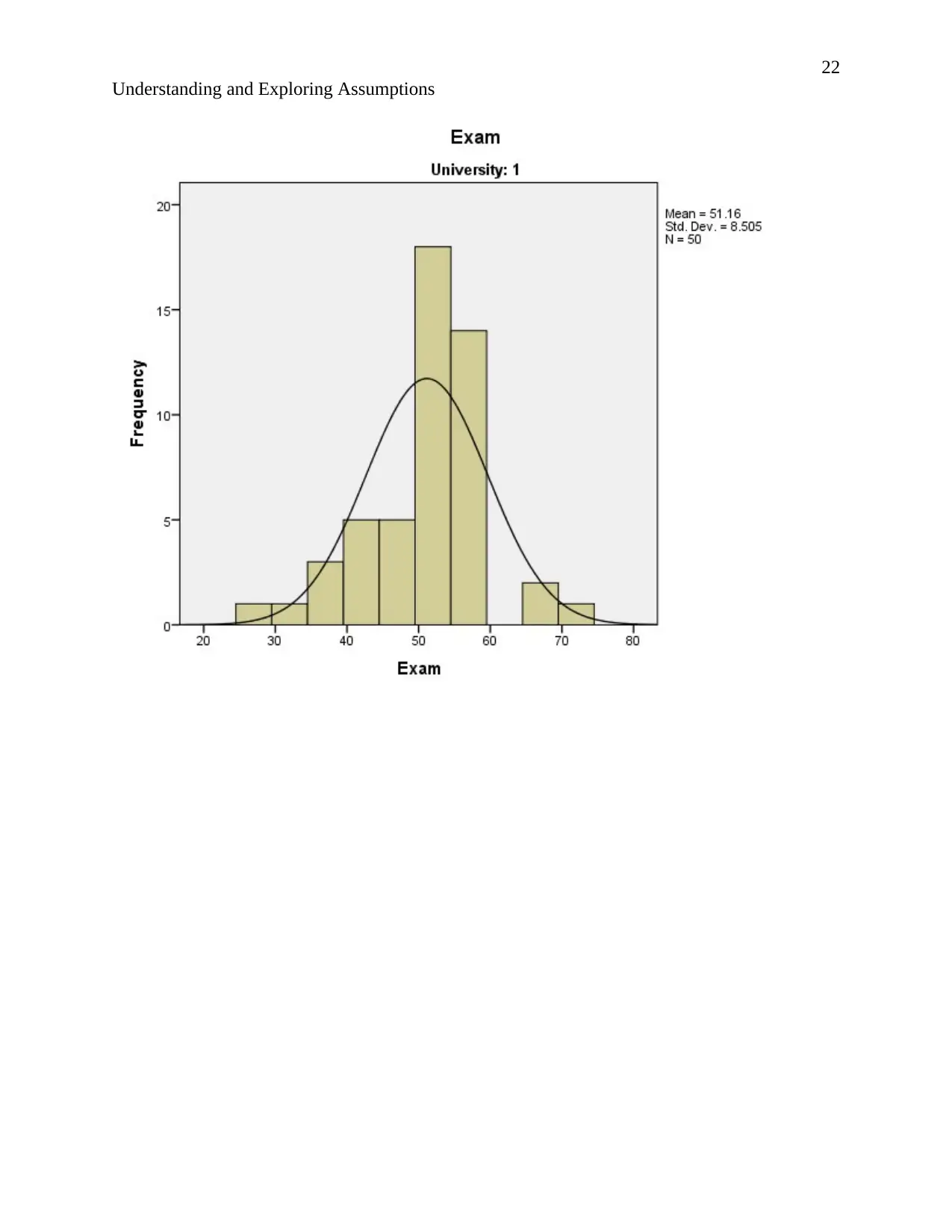
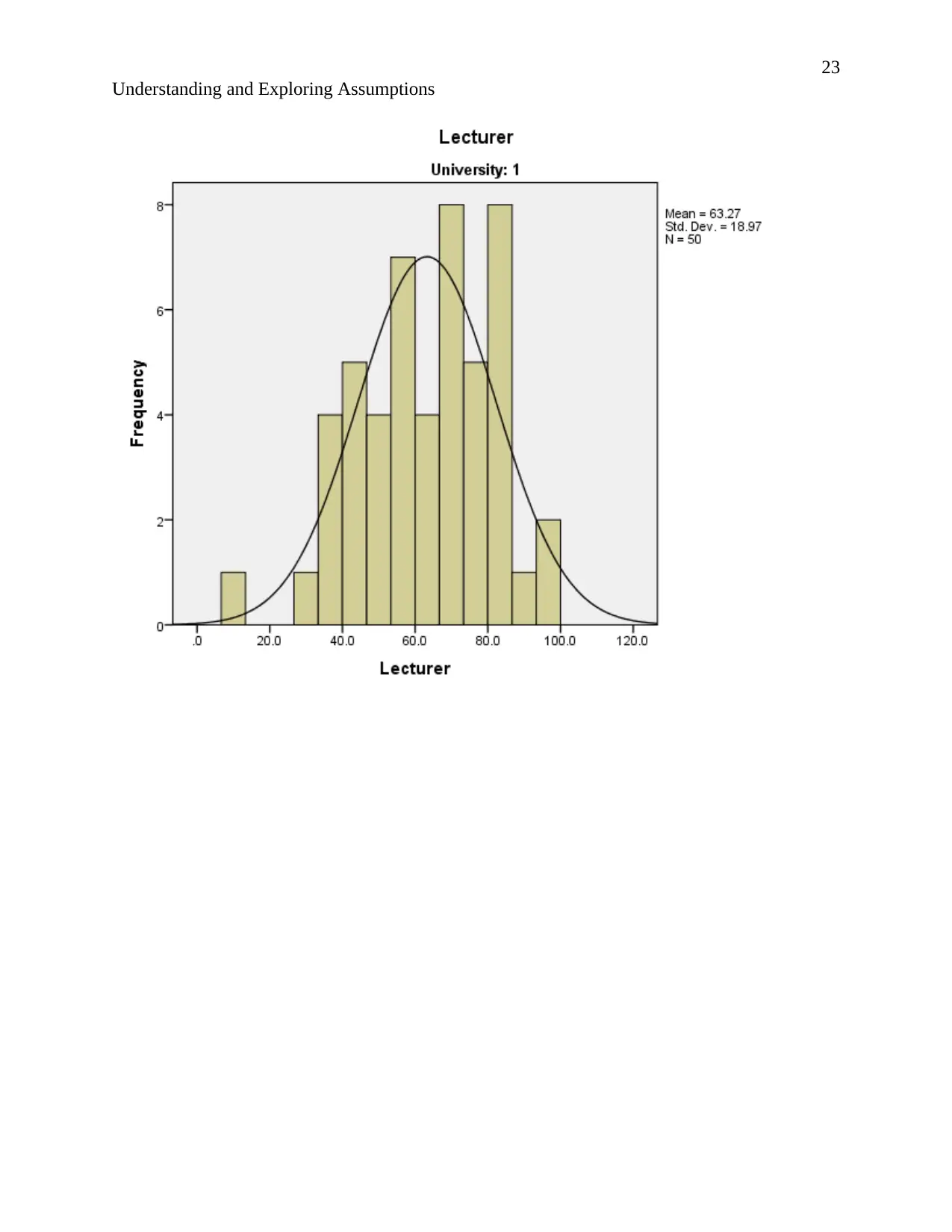
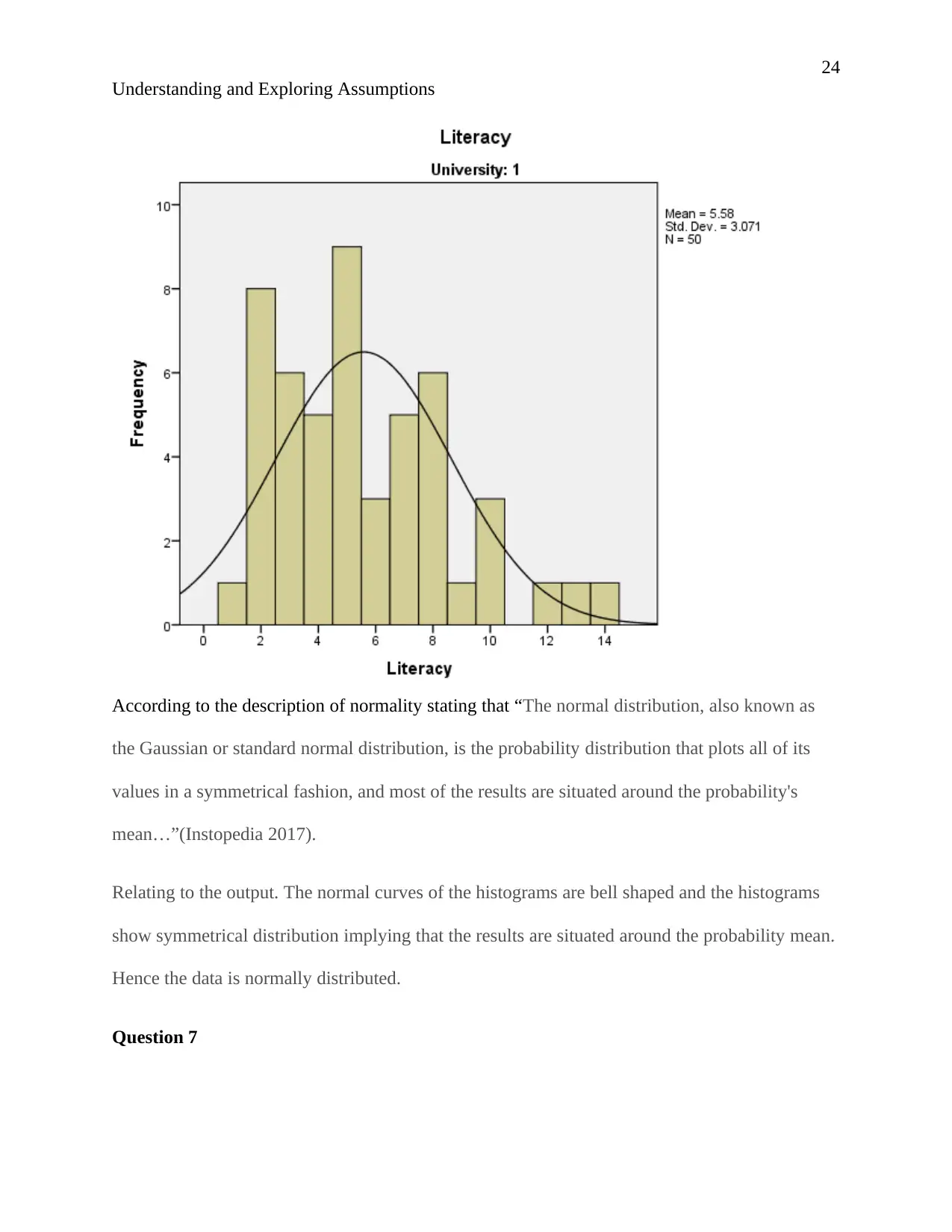
According to the description of normality stating that “The normal distribution, also known as
the Gaussian or standard normal distribution, is the probability distribution that plots all of its
values in a symmetrical fashion, and most of the results are situated around the probability's
mean…”(Instopedia 2017).
Relating to the output. The normal curves of the histograms are bell shaped and the histograms
show symmetrical distribution implying that the results are situated around the probability mean.
Hence the data is normally distributed.
Question 7
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Understanding and Exploring Assumptions
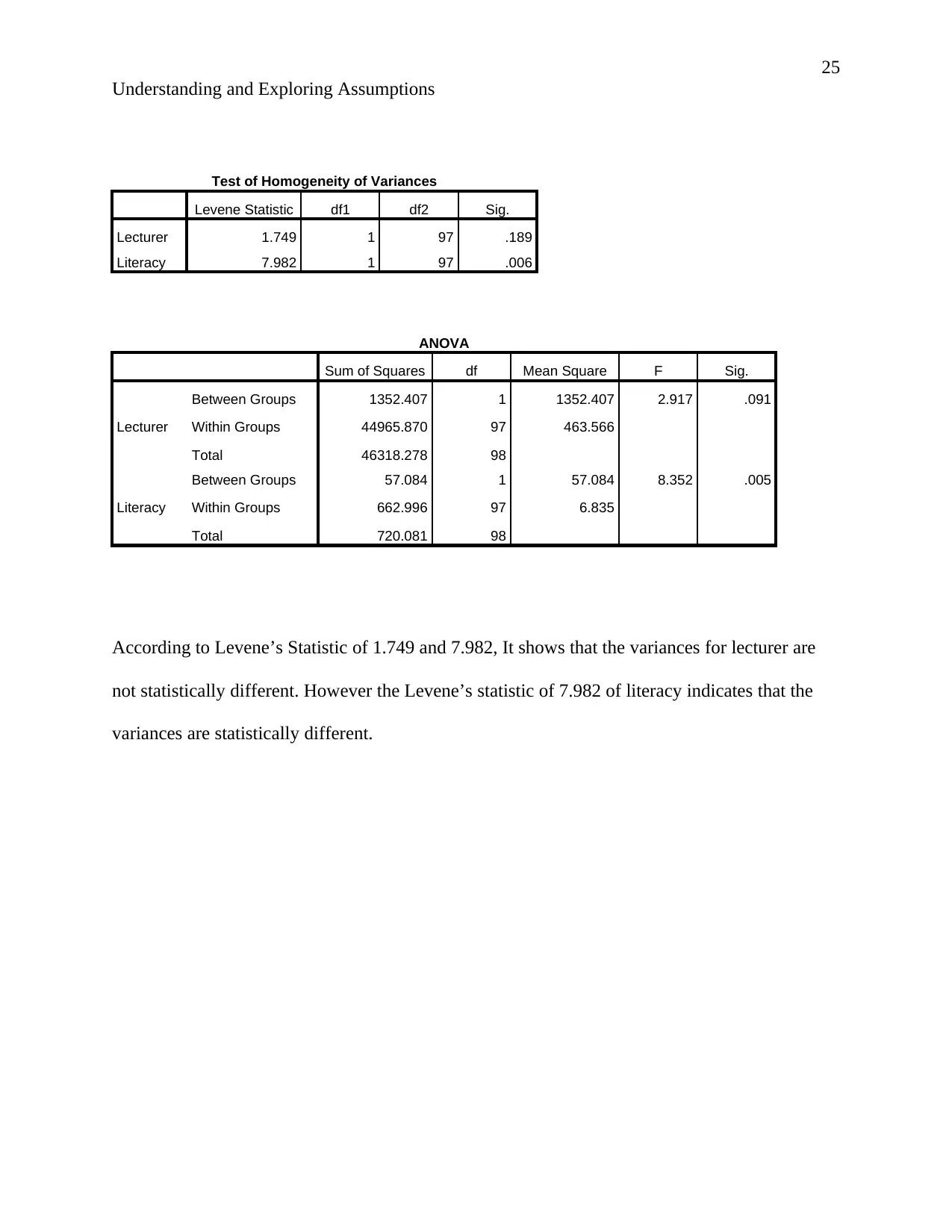
Test of Homogeneity of Variances
Levene Statistic df1 df2 Sig.
Lecturer 1.749 1 97 .189
Literacy 7.982 1 97 .006
ANOVA
Sum of Squares df Mean Square F Sig.
Lecturer
Between Groups 1352.407 1 1352.407 2.917 .091
Within Groups 44965.870 97 463.566
Total 46318.278 98
Literacy
Between Groups 57.084 1 57.084 8.352 .005
Within Groups 662.996 97 6.835
Total 720.081 98
According to Levene’s Statistic of 1.749 and 7.982, It shows that the variances for lecturer are
not statistically different. However the Levene’s statistic of 7.982 of literacy indicates that the
variances are statistically different.
Paraphrase This Document

Understanding and Exploring Assumptions
Question 8
According to Statistics solutions. “The assumption of homogeneity of variance is an assumption
of the independent samples t-test and ANOVA stating that all comparison groups have the same
variance. The independent samples t-test and ANOVA utilize the t and F statistics respectively,
which are generally robust to violations of the assumption as long as group sizes are equal.
Equal group sizes may be defined by the ratio of the largest to smallest group being less than
1.5. If group sizes are vastly unequal and homogeneity of variance is violated, then
the F statistic will be biased when large sample variances are associated with small group sizes.
When this occurs, the significance level will be underestimated, which can cause the null
hypothesis to be falsely rejected. On the other hand, the F statistic will be biased in the opposite
direction if large variances are associated with large group sizes. This would mean that the
significance level will be overestimated. This does not cause the same problems as falsely
rejecting the null hypothesis; however, it can cause a decrease in the power of the test…”
(Statisticssolutions 2018). For instance when using the Levene’s test in testing the null
hypothesis, we may end up suggesting that the variances are uniform across all the groups.
Statistical tests are educated guesses ( Survey analysis 2018). Whenever technical errors or
whichever the error is committed, the statistical tests are prone to lead to wrong assumptions.
Since statistical tests are used in assumptions, the conclusions of the statistical tests become less
reliable wherever the assumptions are not satisfied.
Therefore the failure to meet the assumptions often has an impact on the intended analysis.

Understanding and Exploring Assumptions
References
Zaintoz C. 2015. Statistical Tests. Weblog. Available from:
http://www.real-statistics.com/descriptive-statistics/assumptions-statistical-test/ accessed on 13th
Feb 2018.
Elite Research. 2013. Assumption and analysis. Weblog. Available from:
https://www.eliteresearch.com%2f/RK=0/RS=tyDRUQdU1vITmKGvidJ5Br1pxHo-/ accessed
on 13th Feb 2018.
Lund Research. 2012. Statistical Assumptions. Weblog. Available from:
http://www.researchgate.org/ accessed on 13th Feb 2018.
PQ systems .2016. Normal Distributions. Weblog. Available from:
http://www.pqsystems.com/qualityadvisor/DataAnalysisTools/interpretation/
histogram_compare_to_normal.php/ accessed on 14th Feb 2018.
Lund Research. 2015. Skewness and its use. Weblog. Available from:
https://www.researchgate.net/post/What_is_the_acceptable_range_of_skewness_and_kurtosis_fo
r_normal_distribution_of_data/ , accessed on 14th Feb 2018.
Instopedi. 2018. Normal Distribution. Weblog. Available from:
https://www.investopedia.com/terms/n/normaldistribution.asp/ accessed on 16th Feb 2018.
Statistics Solutions. 2018. Assumption of Homogeneity. Weblog. Available from:
http://www.statisticssolutions.com/the-assumption-of-homogeneity-of-variance/ , accessed on
16th Feb 2018.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Understanding and Exploring Assumptions
Survey Analysis. 2018.Test of Assumptions. Weblog. Accessed from:
http://www.surveyanalysis.org/wiki/Technical_Assumptions_of_Tests_of_Statistical_Significan
ce/ accessed on 16th Feb 2018.
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.