Statistics Assignment: Regression, ANOVA, and Frequency Analysis
VerifiedAdded on 2023/06/07
|11
|1490
|209
Homework Assignment
AI Summary
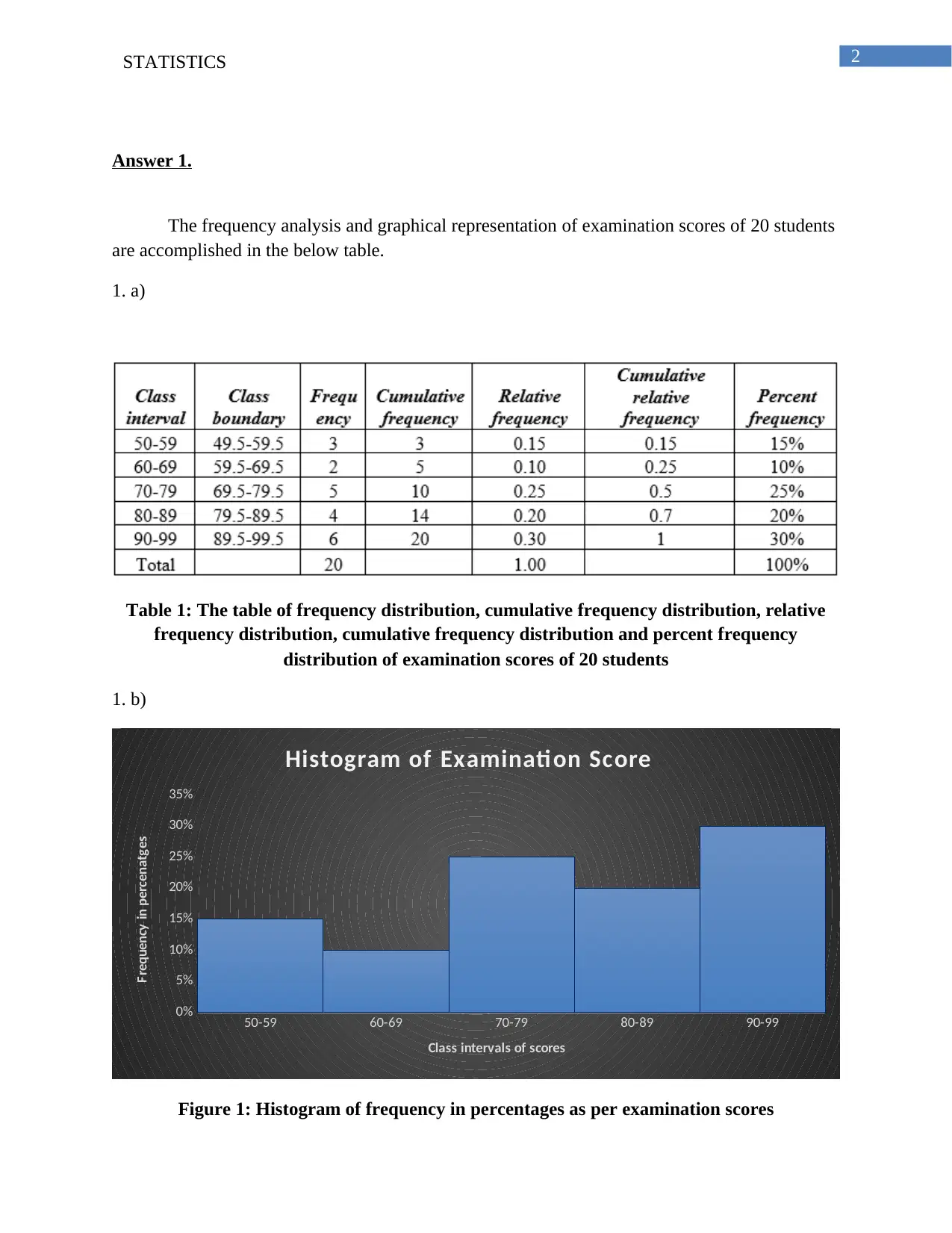
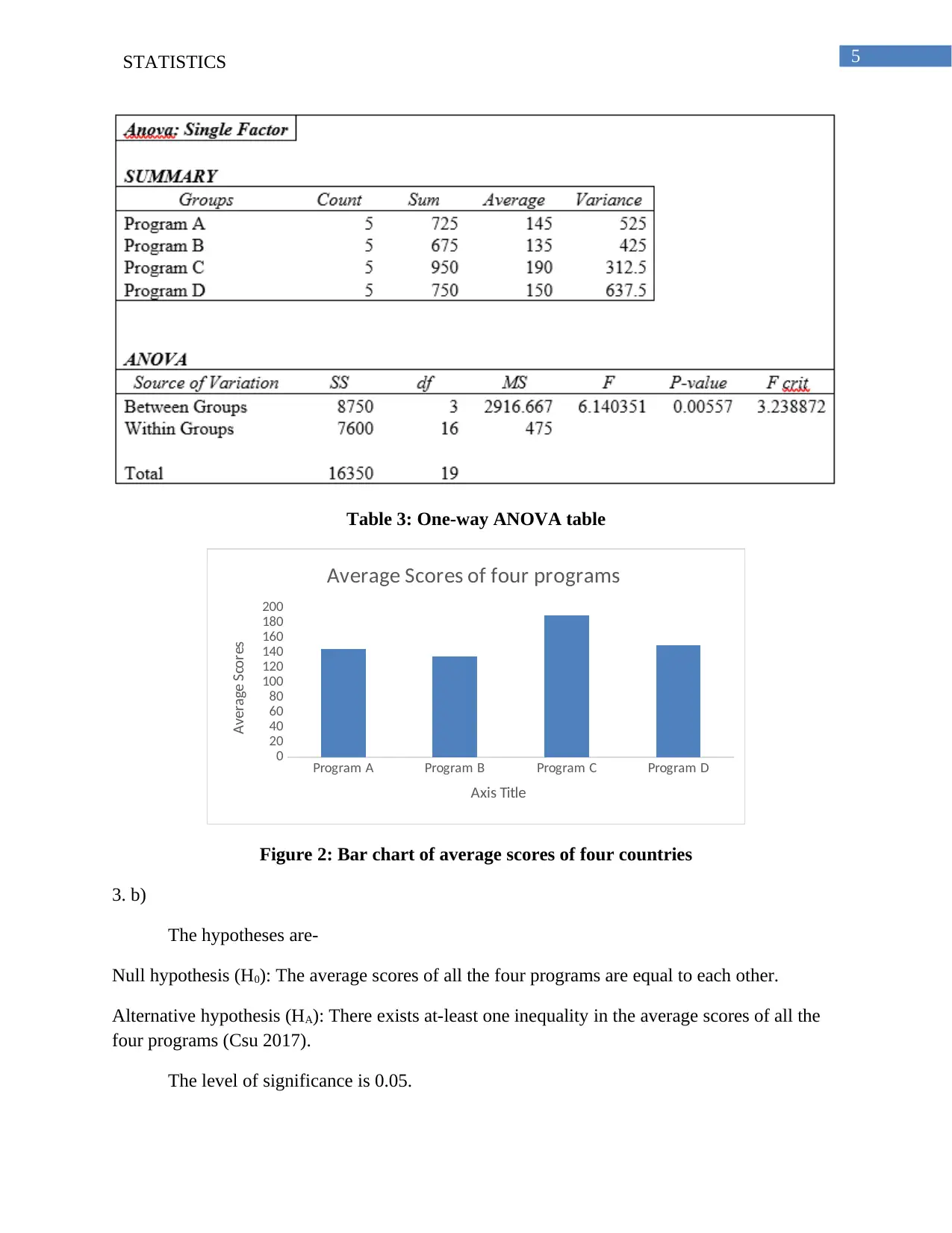
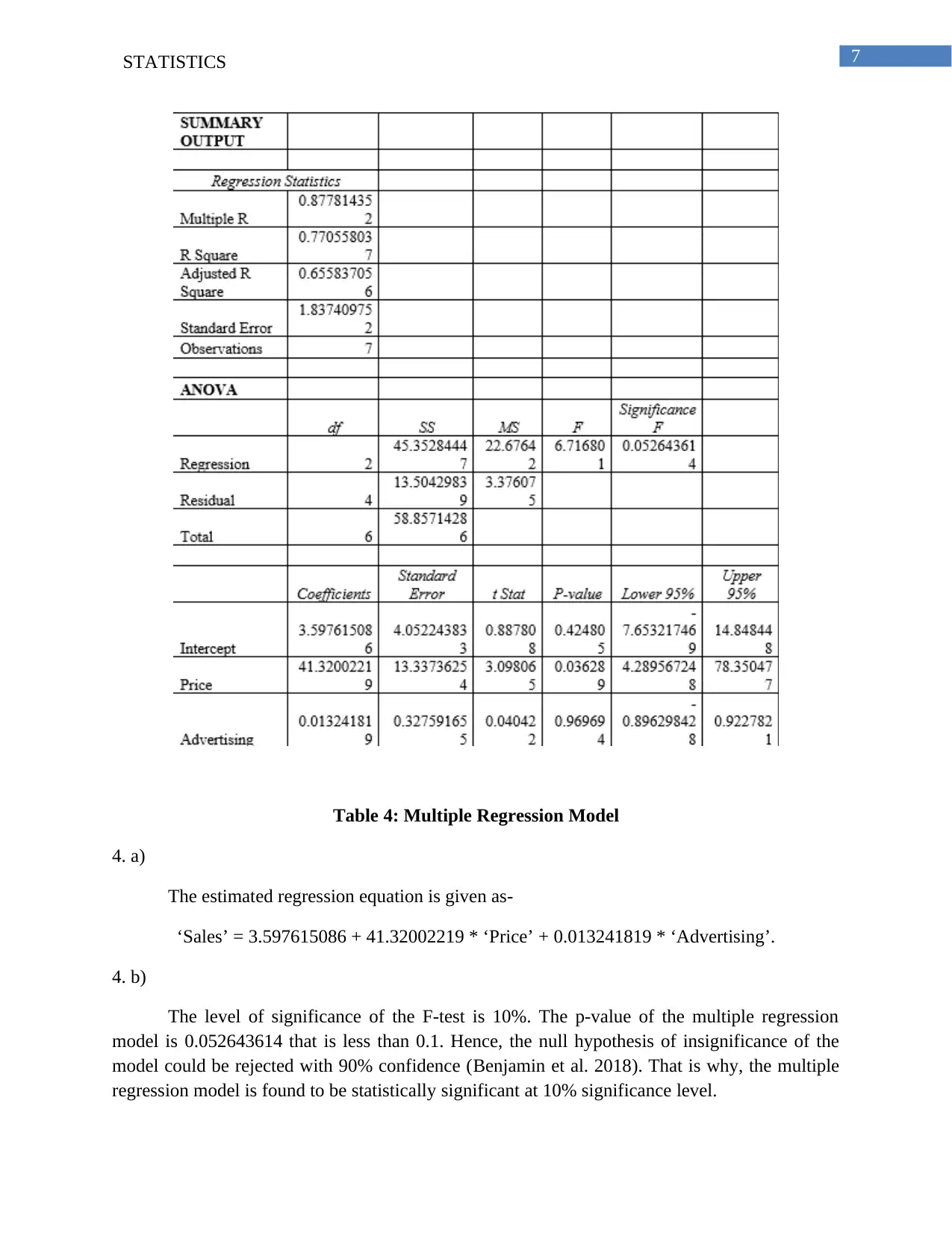
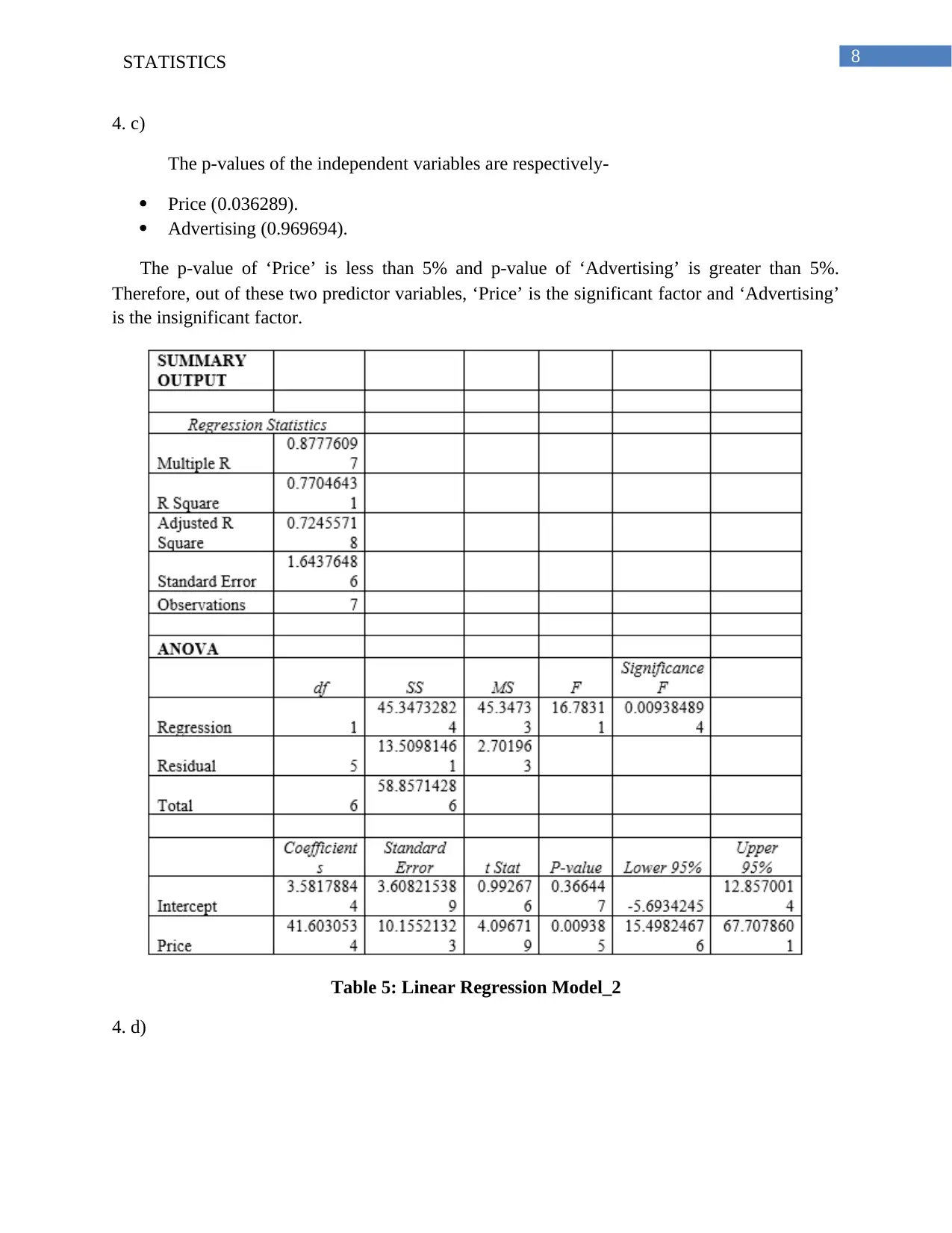
This statistics assignment solution covers various statistical concepts and techniques. The first part involves frequency analysis and graphical representation of examination scores, including the creation of a frequency distribution table and a histogram, along with an analysis of the data's skewness. The second part focuses on linear regression, calculating p-values, coefficients of determination, and correlation coefficients to analyze the relationship between 'Unit Price' and 'Supply'. The third part utilizes one-way ANOVA to test the equality of productivity averages across different program groups, including hypothesis formulation, p-value calculation, and interpretation. The final part delves into multiple regression, analyzing the relationship between 'Sales' and two independent variables: 'Price' and 'Advertising', including the estimation of a regression equation, significance testing, and interpretation of variable significance. The solution also presents tables and figures to support the analysis and includes relevant references.







1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.