BUS708: Statistics and Data Analysis Report - Trimester 2, 2019
VerifiedAdded on 2022/11/17
|11
|1691
|323
Report
AI Summary
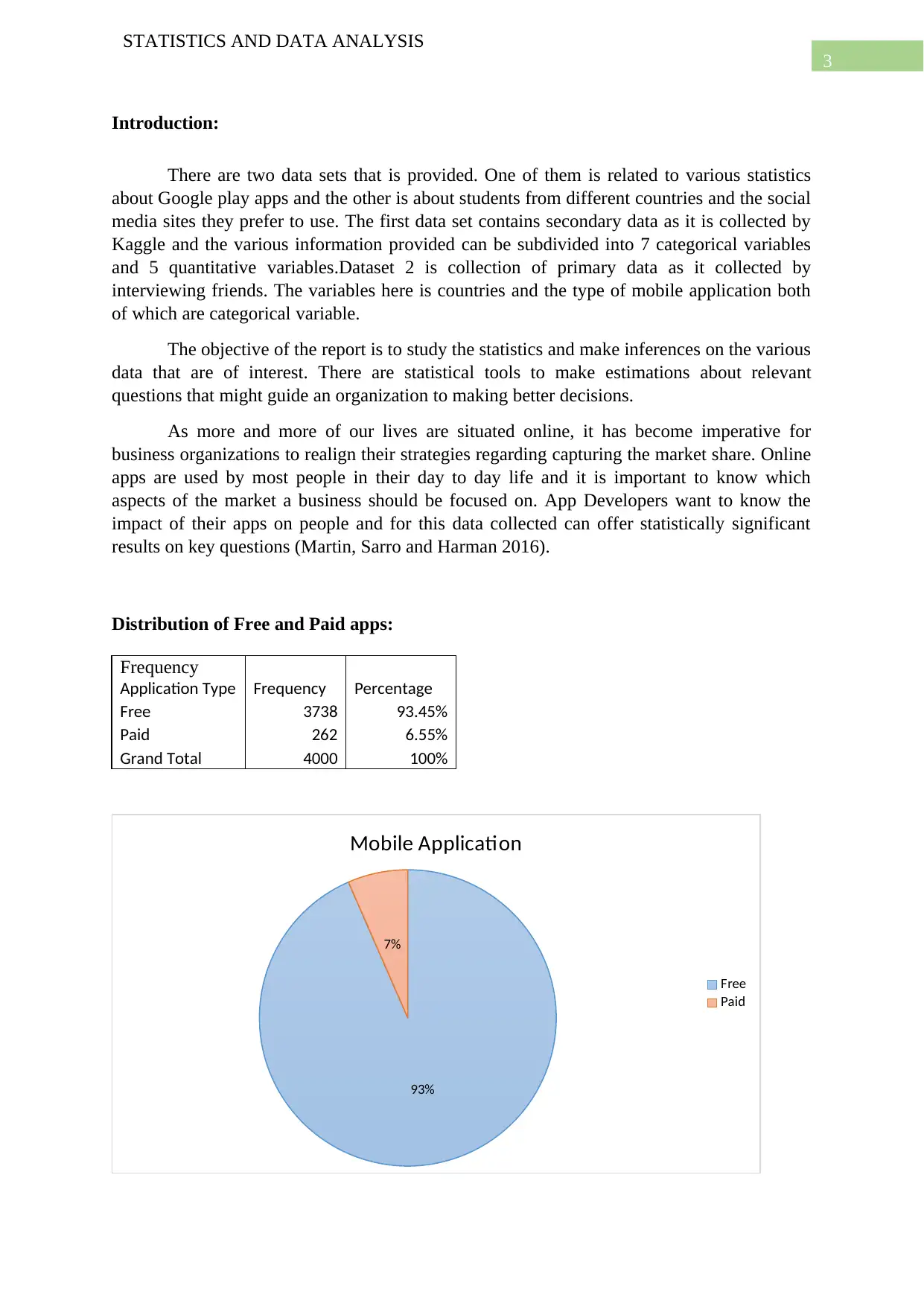
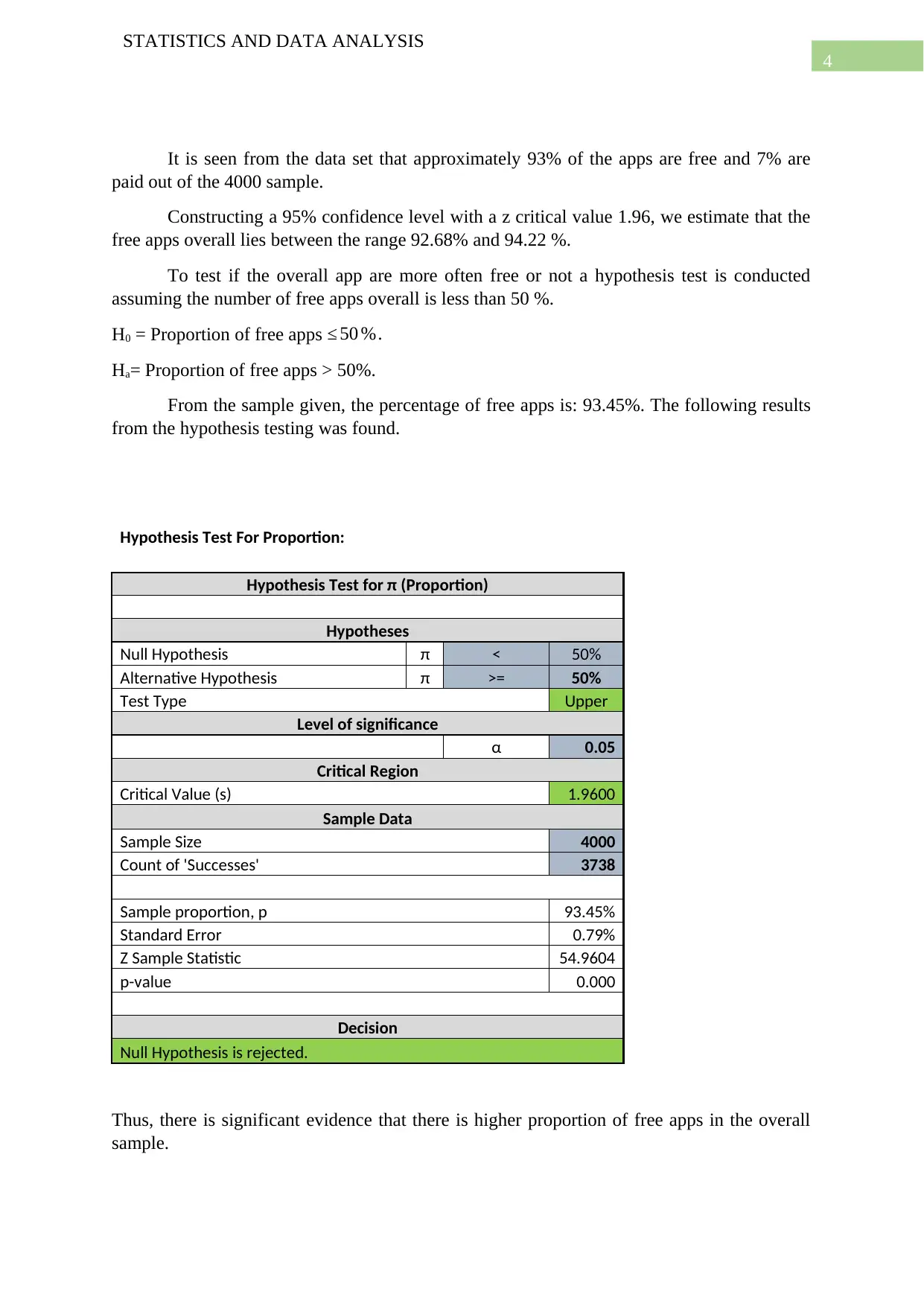
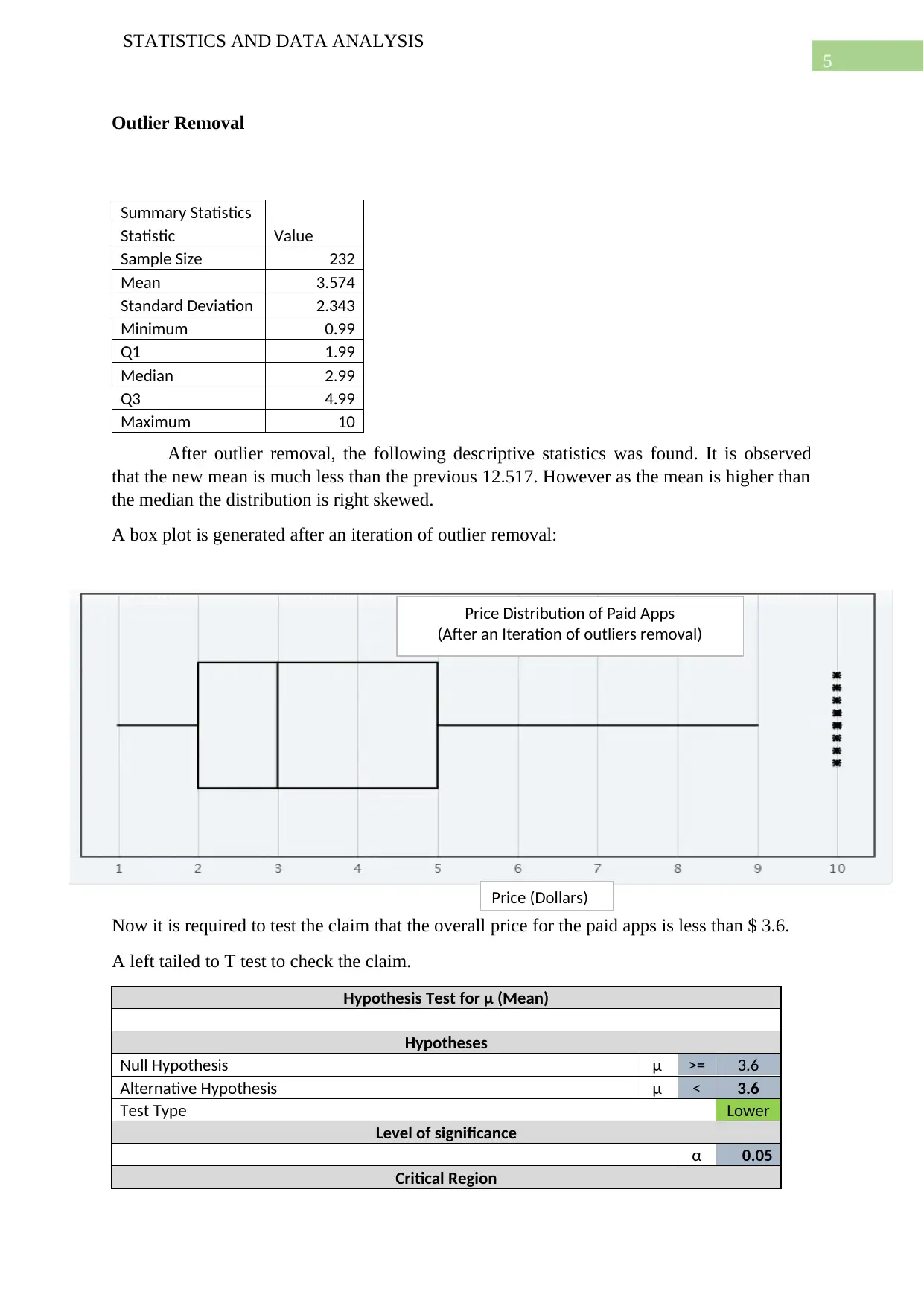
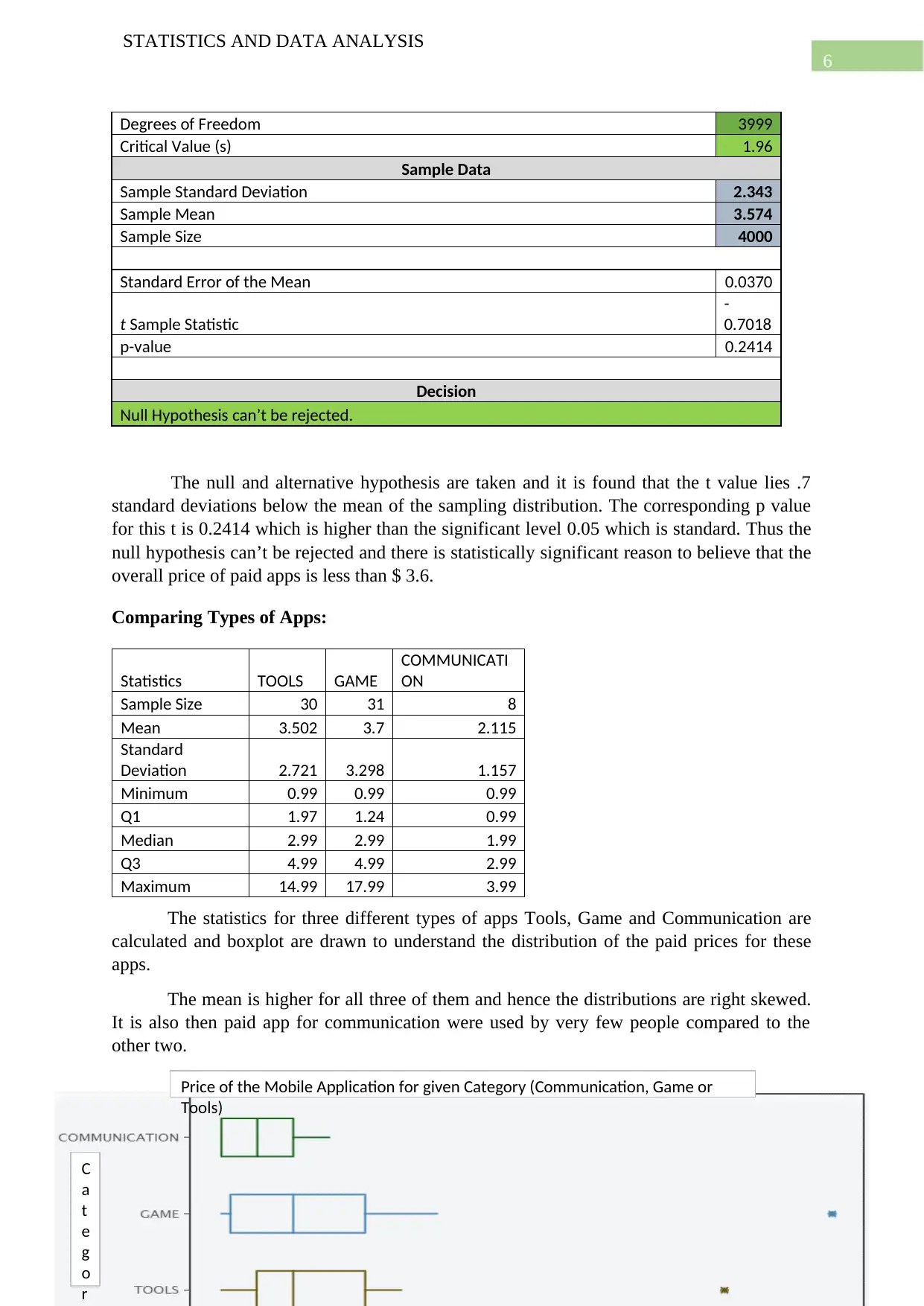
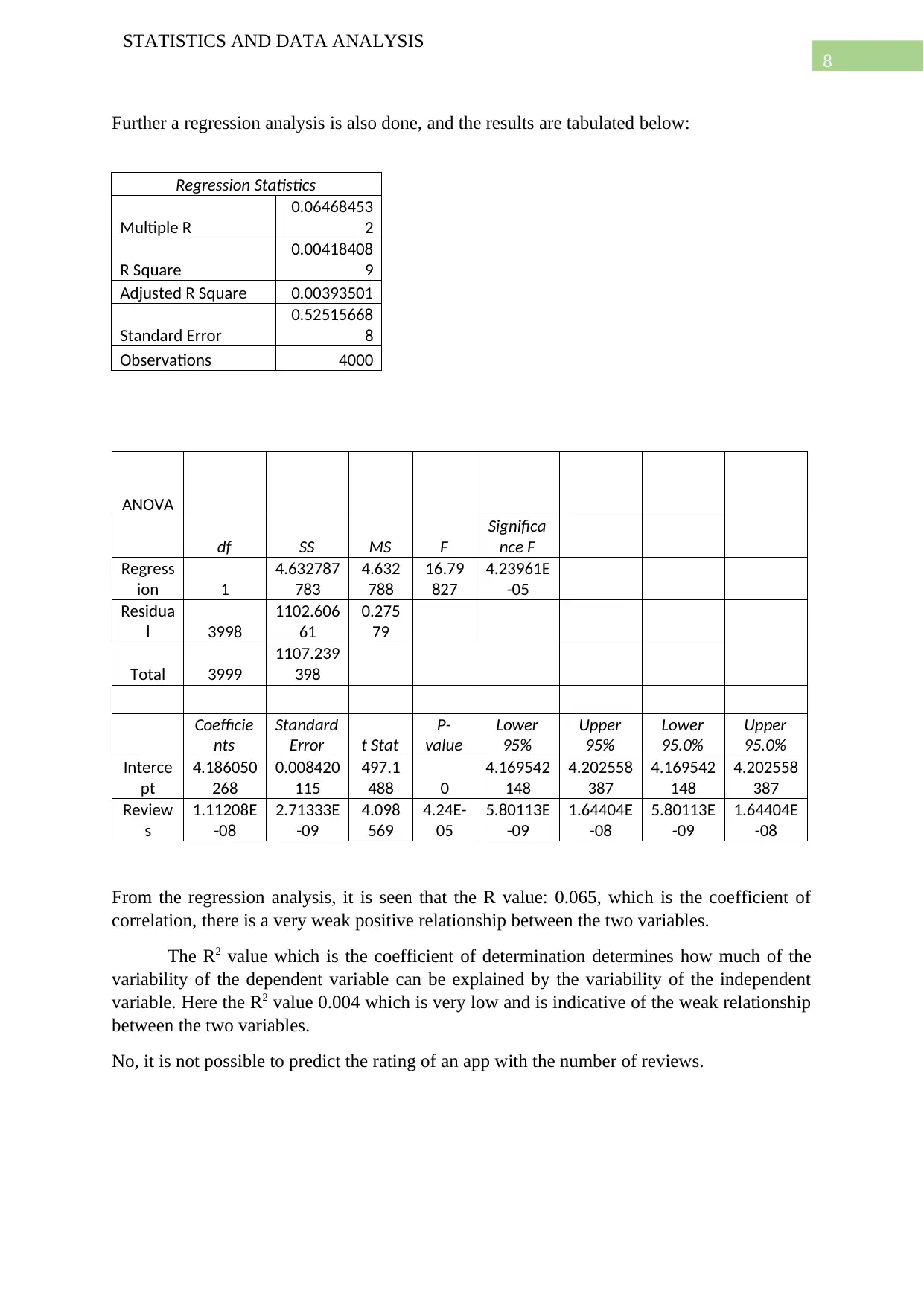
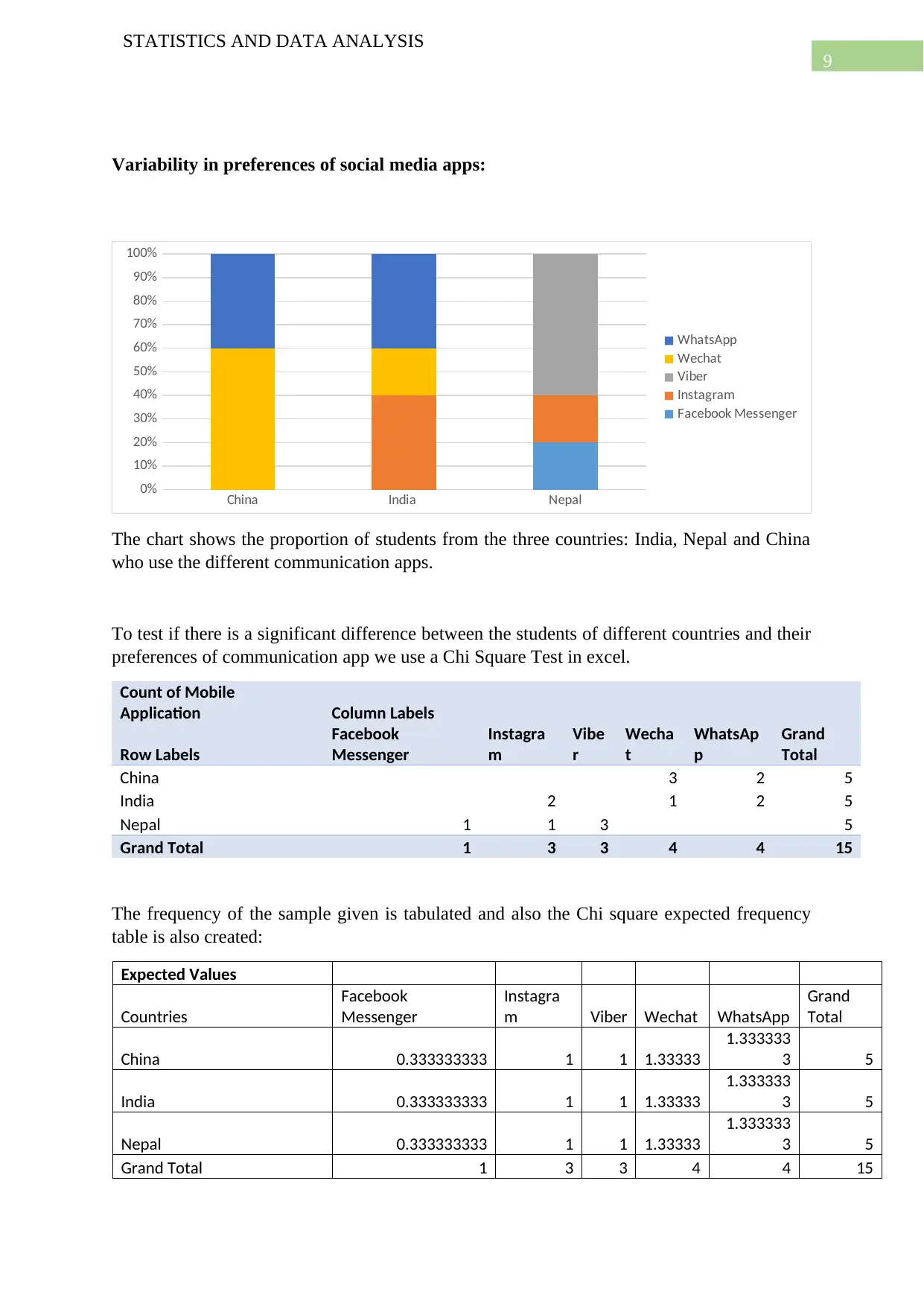
This report presents a comprehensive statistical analysis of two datasets. The first dataset, sourced from Kaggle, focuses on Google Play apps, examining the distribution of free versus paid apps, outlier removal, and comparisons between app types (Tools, Games, Communication). It includes hypothesis testing to determine the proportion of free apps and the overall price of paid apps, along with ANOVA to assess price differences between app categories. The second dataset, collected through surveys, investigates social media preferences across different countries using a Chi-Square test. The report also explores the relationship between app ratings and reviews through regression analysis. Statistical tools like t-tests, ANOVA, and Chi-Square tests are used to draw inferences and conclusions about the datasets. The analysis also includes the use of plots to visualize the data and draw insights from the data.





1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.