STA101 Statistics for Business: Assessment 1 Assignment Solution
VerifiedAdded on 2023/06/04
|7
|1364
|311
Homework Assignment
AI Summary
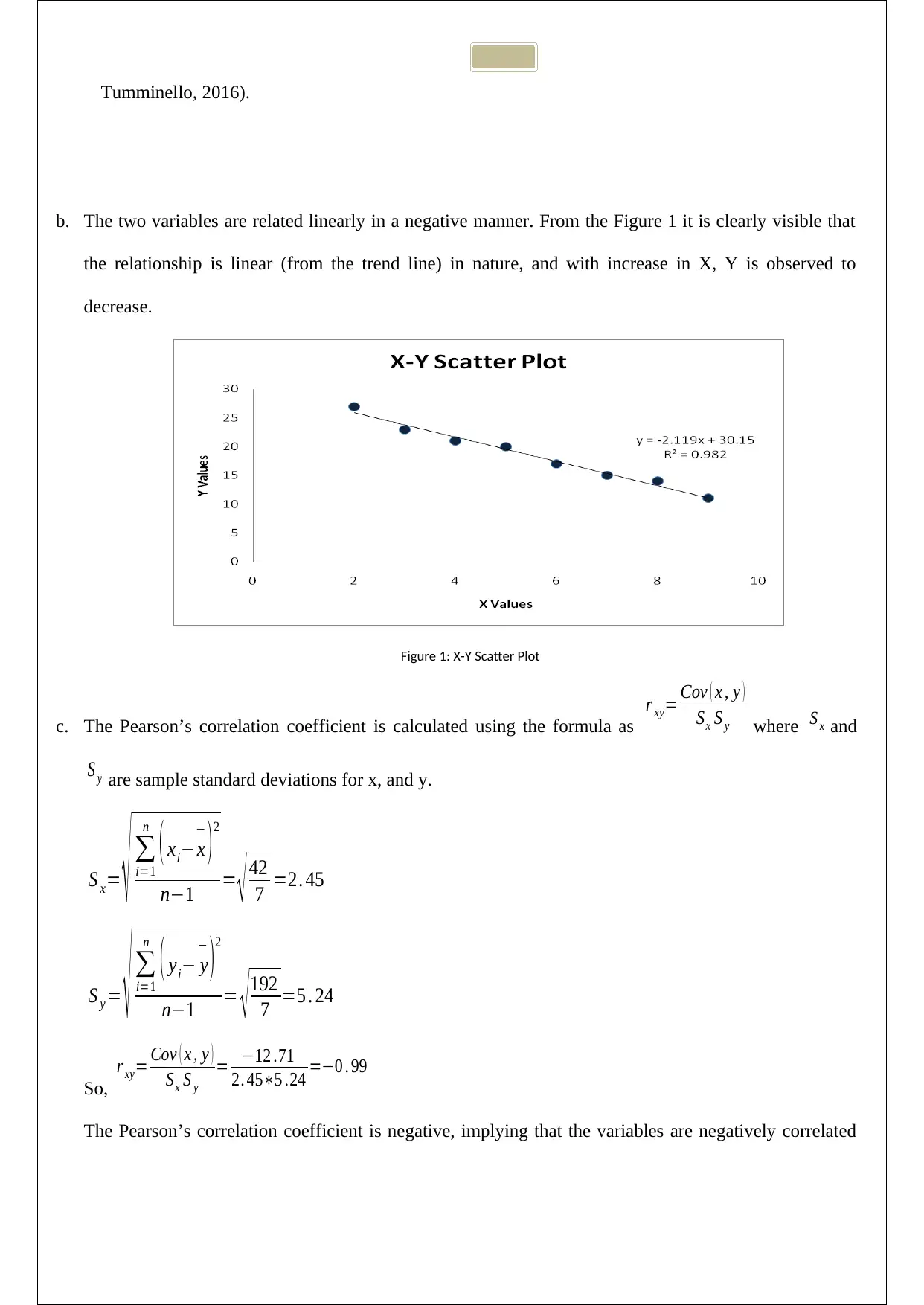
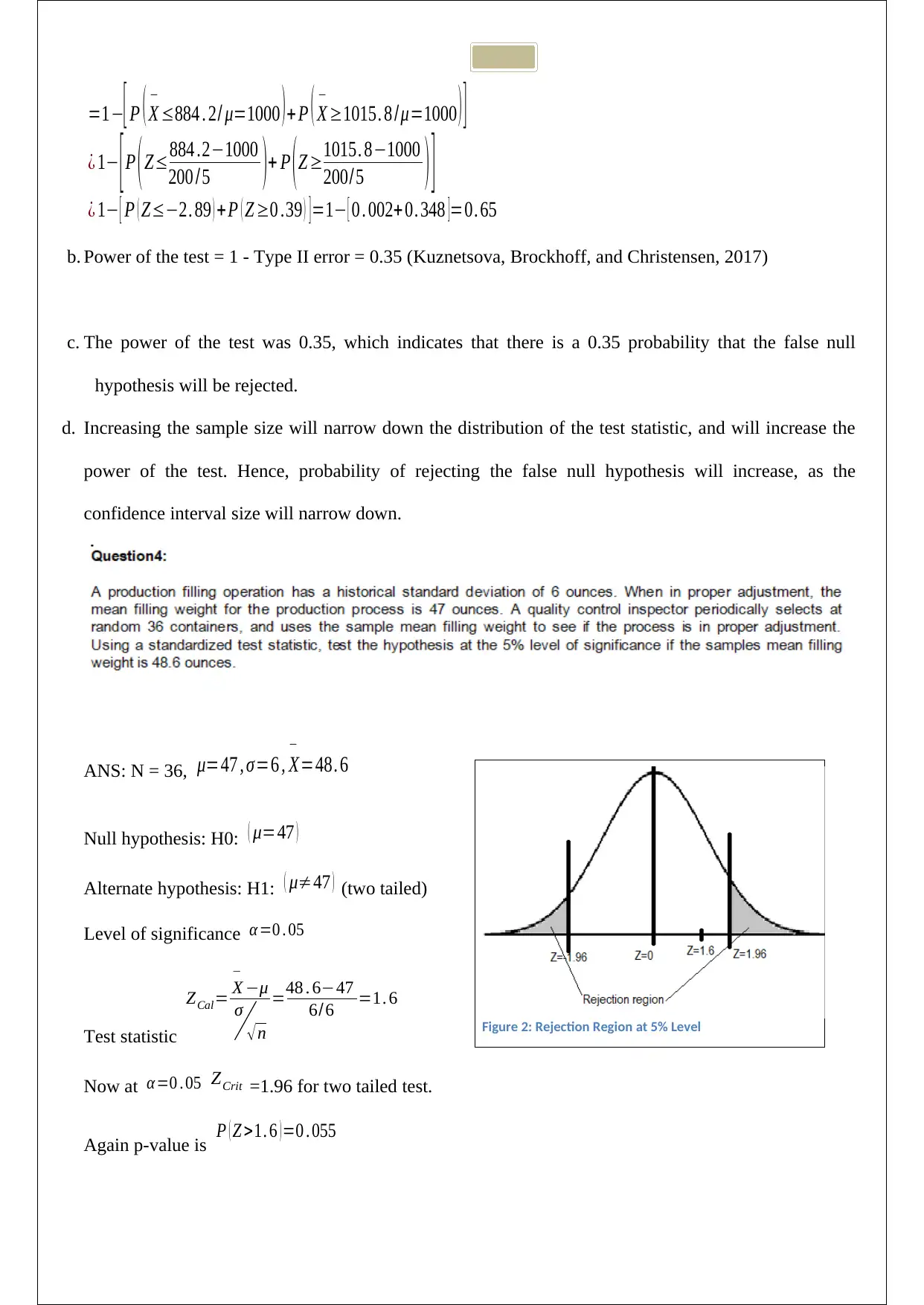
This document presents a comprehensive solution to the STA101 Statistics for Business Assignment 1. The solution addresses four key questions, beginning with the calculation and interpretation of covariance and correlation between two variables, including a scatter plot analysis. The second question delves into the exponential distribution, calculating probabilities related to waiting times. The third question focuses on hypothesis testing, including type II error and power calculations. Finally, the fourth question involves hypothesis testing and confidence intervals, providing a detailed analysis of the results and conclusions. The solution includes all necessary calculations, interpretations, and relevant references. This assignment provides a detailed guide to the concepts of statistics and probability for business applications.





1 out of 7
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.