HI6007 Group Assignment: Statistical Data Analysis for Business
VerifiedAdded on 2023/06/11
|15
|2468
|269
Homework Assignment
AI Summary
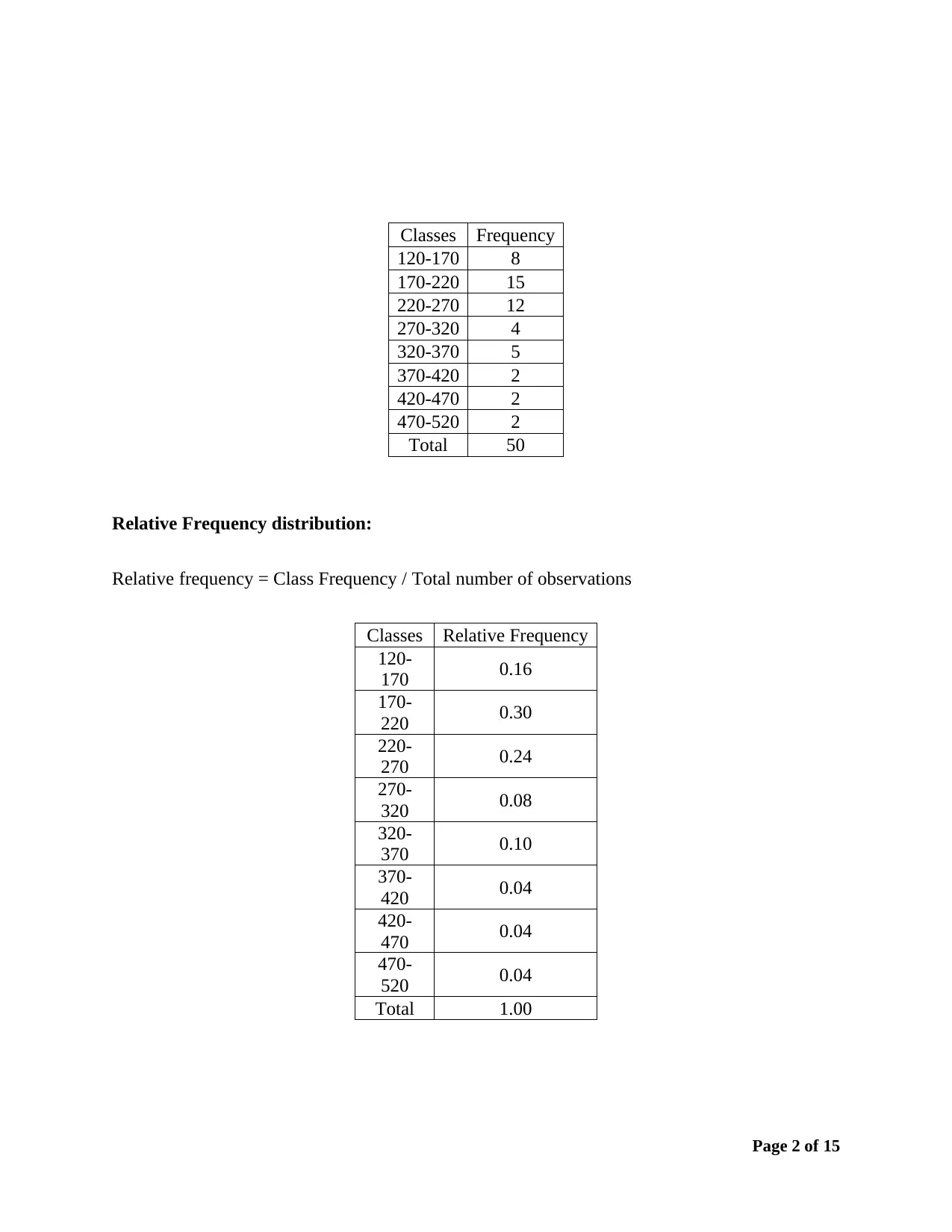
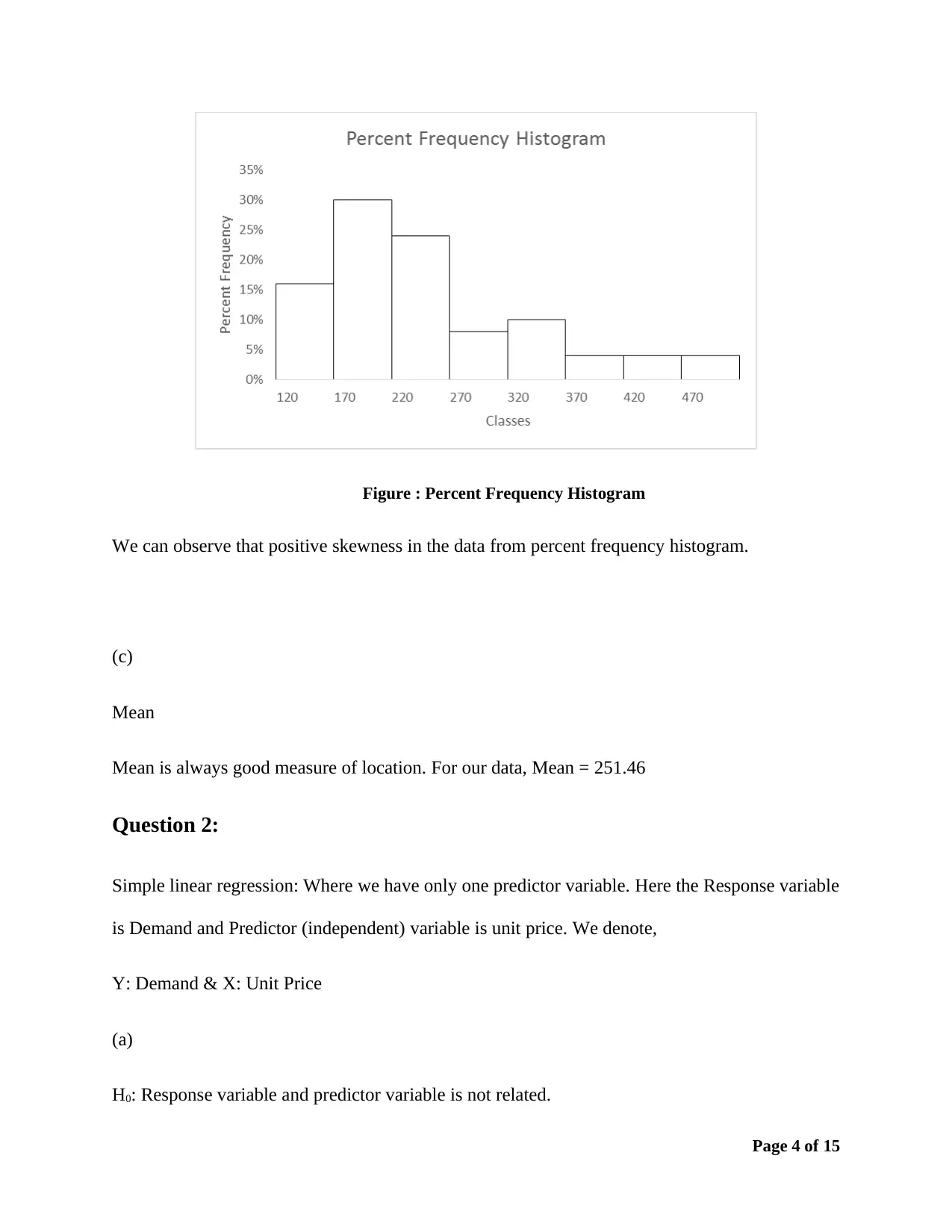
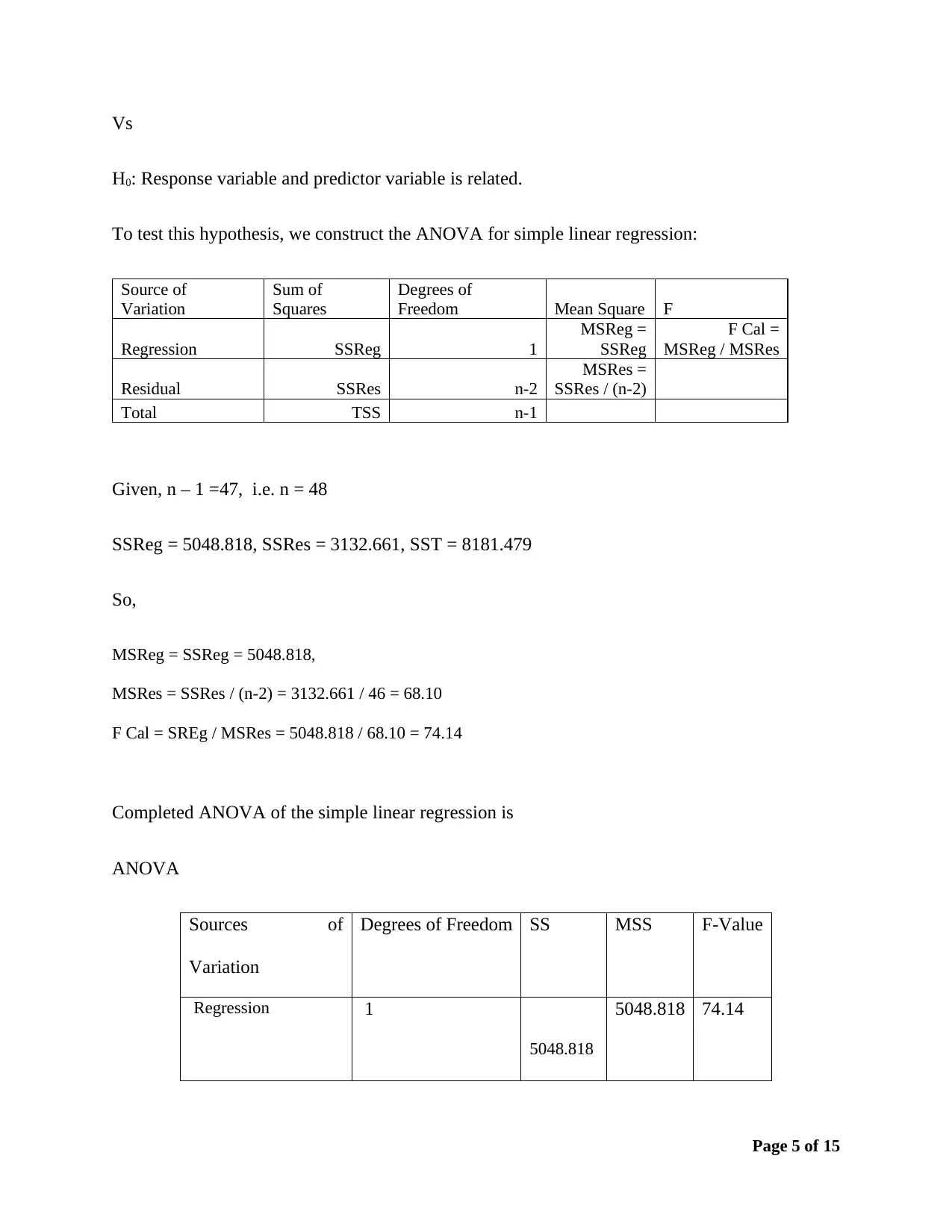
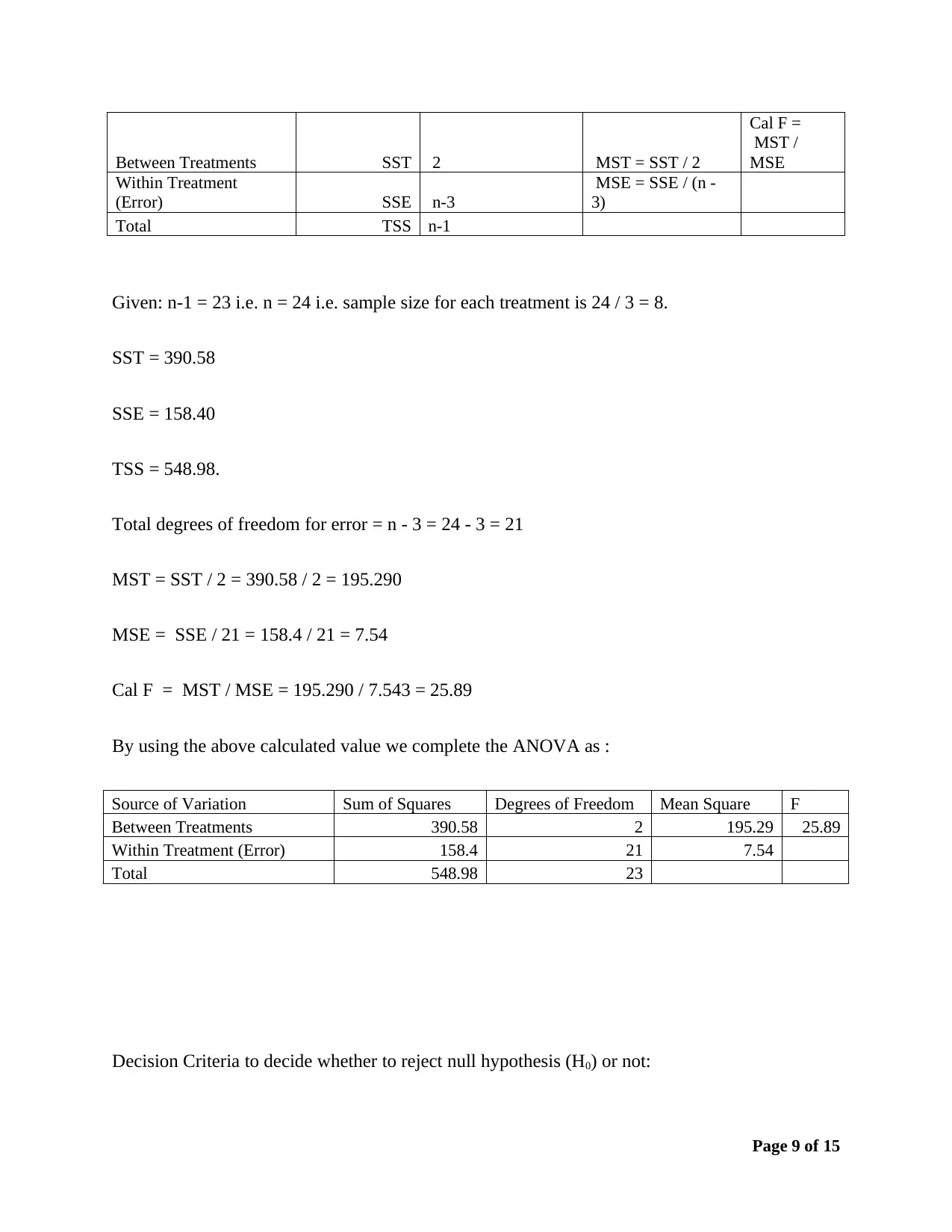
This assignment solution provides a detailed analysis of business data using statistical techniques. It includes the construction of frequency distributions (frequency, relative frequency, and percent frequency) and a histogram to analyze furniture order data. The solution also covers simple linear regression, including hypothesis testing using ANOVA, calculation of the coefficient of determination, and correlation coefficient to determine the relationship between demand and unit price. Furthermore, it addresses hypothesis testing for multiple treatments using ANOVA and multiple regression analysis to analyze the relationship between mobile phone sales and predictor variables like price and advertising spots. The solution includes interpretations of slopes, t-tests for individual coefficients, and predictions based on the regression model.








1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.