BUS5SBF - Statistics for Finance: Household Data Analysis Report
VerifiedAdded on 2023/06/07
|10
|1381
|56
Report
AI Summary
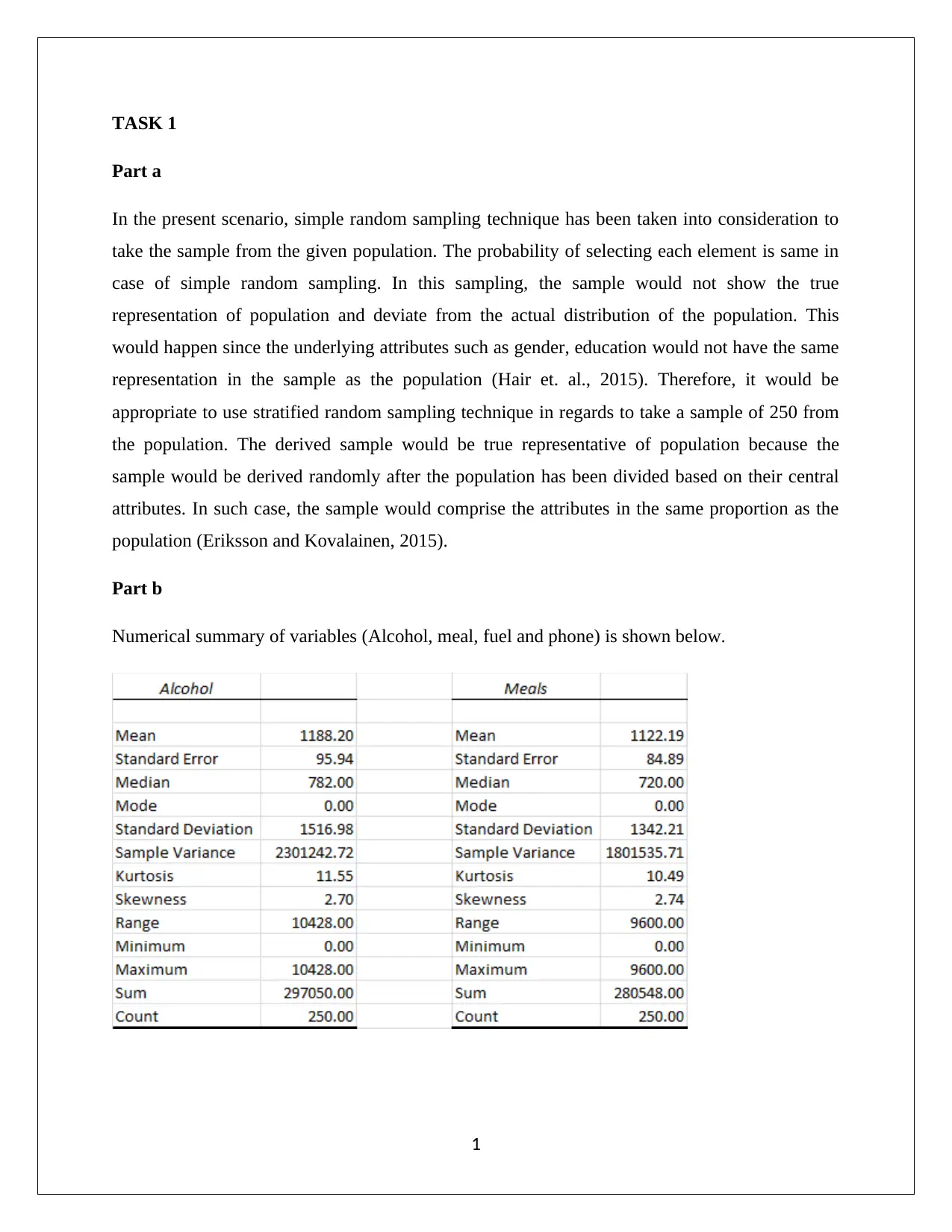
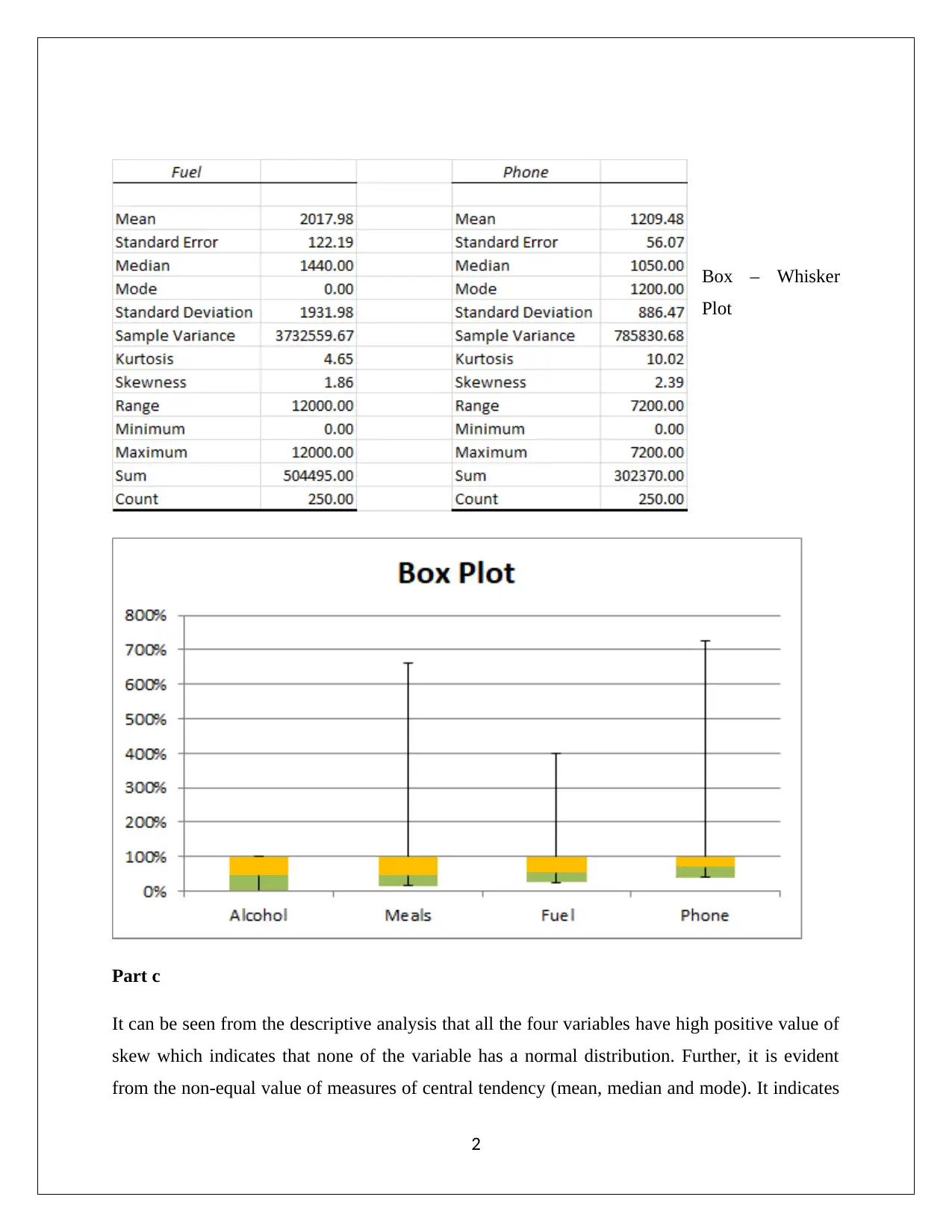
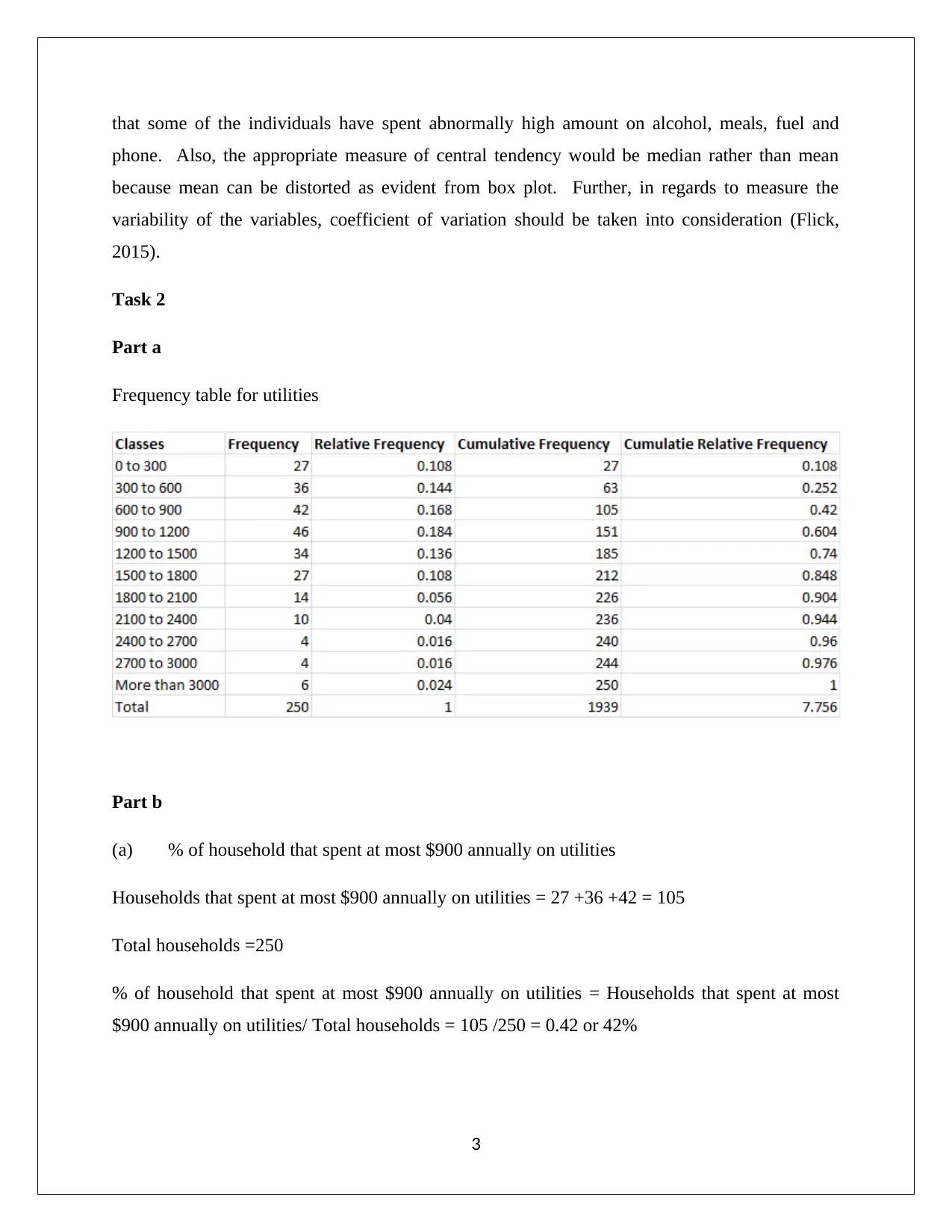
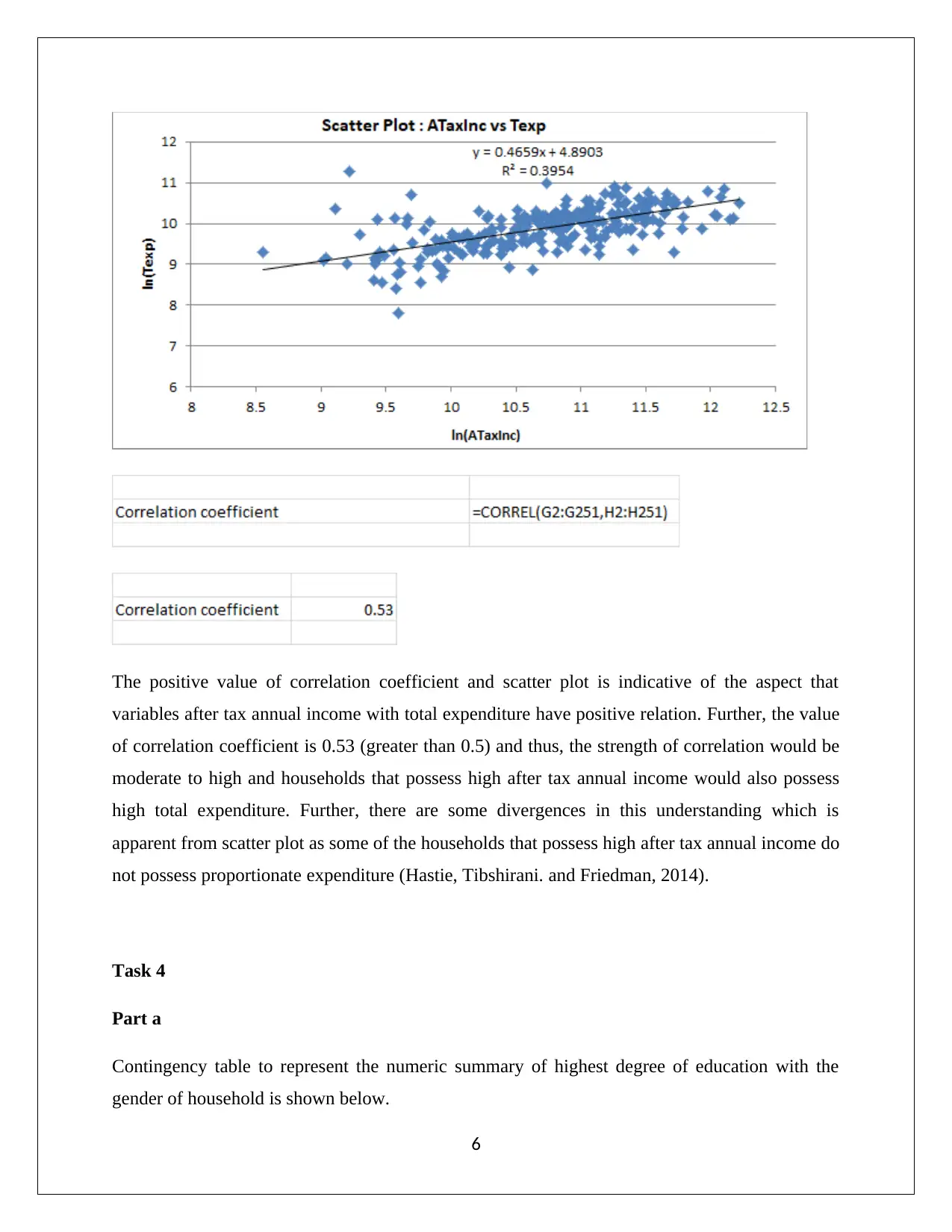
This report presents a statistical analysis of household data, employing simple random sampling and stratified random sampling techniques. It includes numerical summaries of variables like alcohol, meal, fuel, and phone expenses, revealing skewed distributions and suggesting the use of median as a central tendency measure. The analysis further examines household spending on utilities, calculates top and bottom income percentages, and classifies household ownership variables. Correlation analysis between after-tax income and total expenditure is performed, indicating a moderate to high positive relationship. Finally, the report includes a contingency table summarizing education levels and gender, calculating probabilities, and determining the independence of gender and education events. The report uses statistical methods to interpret demographic data, demonstrating the real-world applications of statistics in finance and business contexts. This document is available on Desklib, a platform offering a wide range of study resources for students.






1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.