Statistics for Management: Income and Economic Analysis Report
VerifiedAdded on 2021/02/19
|22
|2951
|69
Report
AI Summary
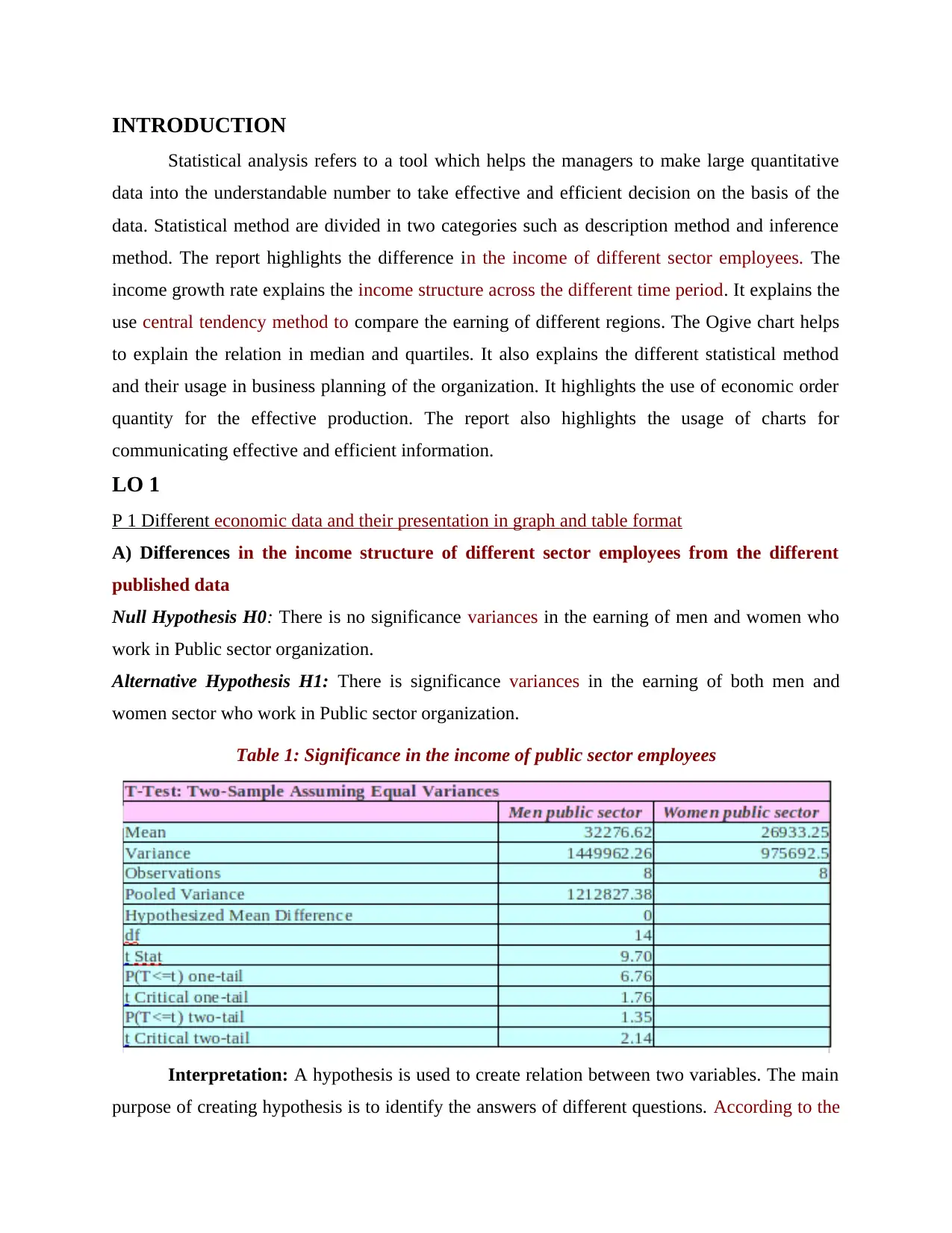
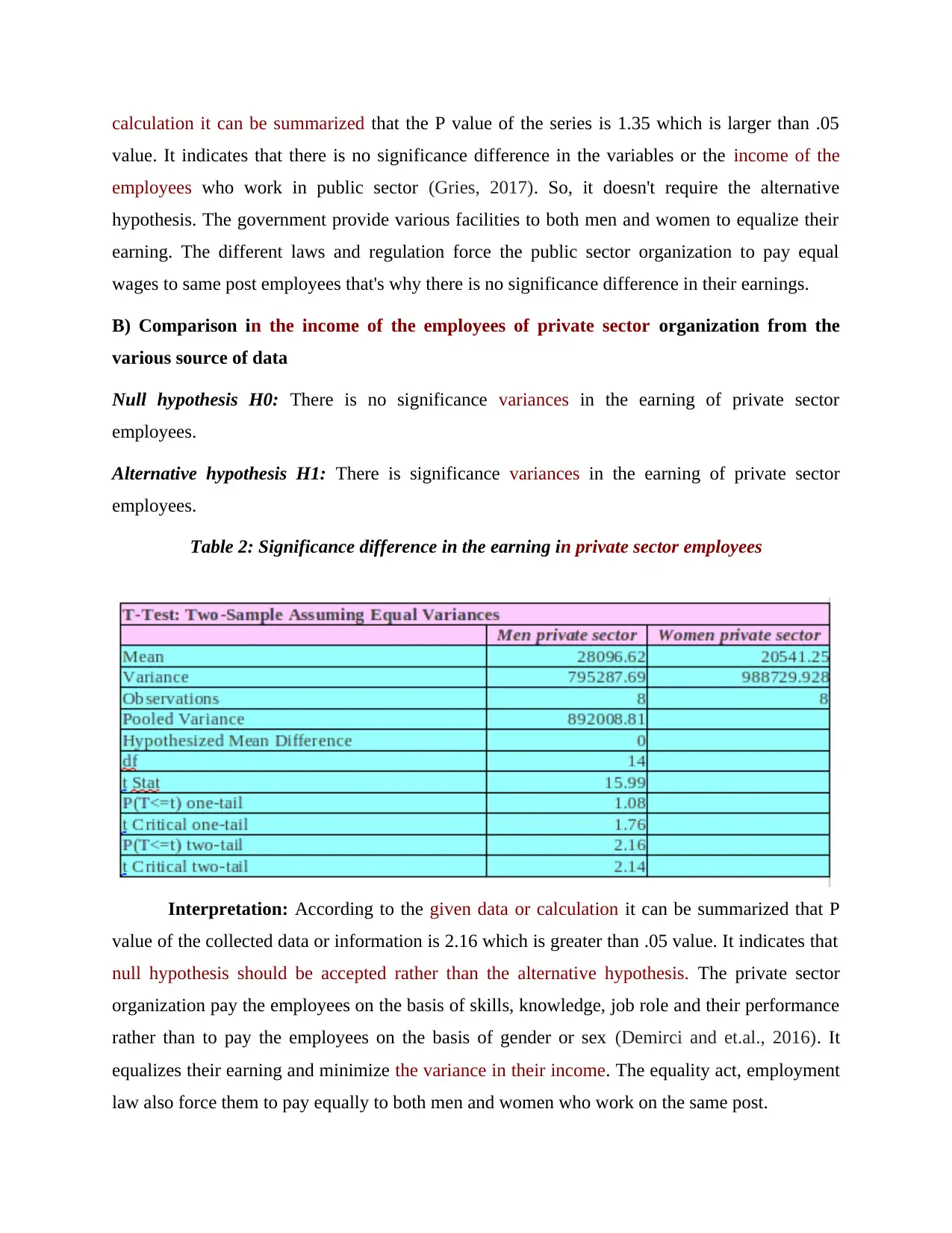
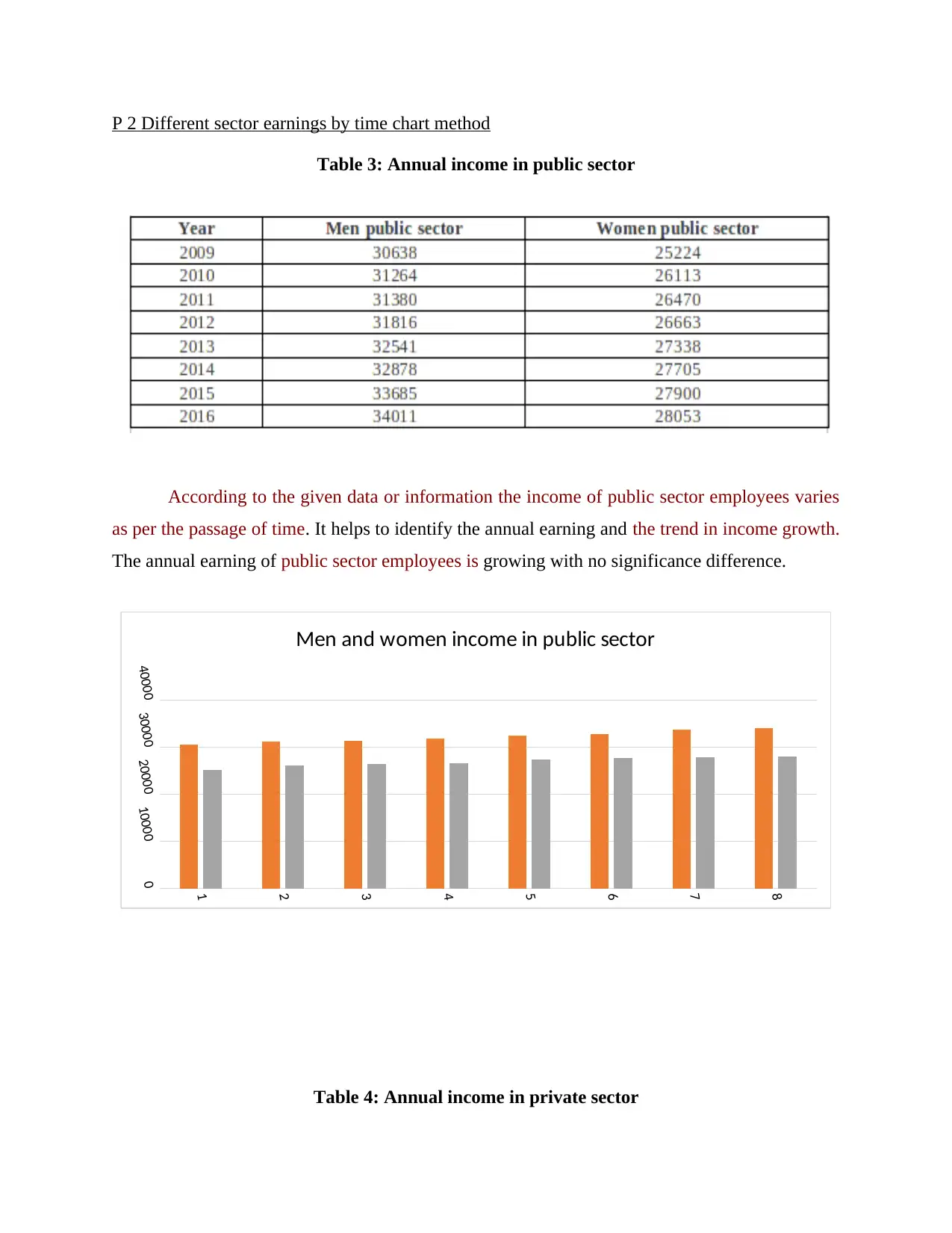
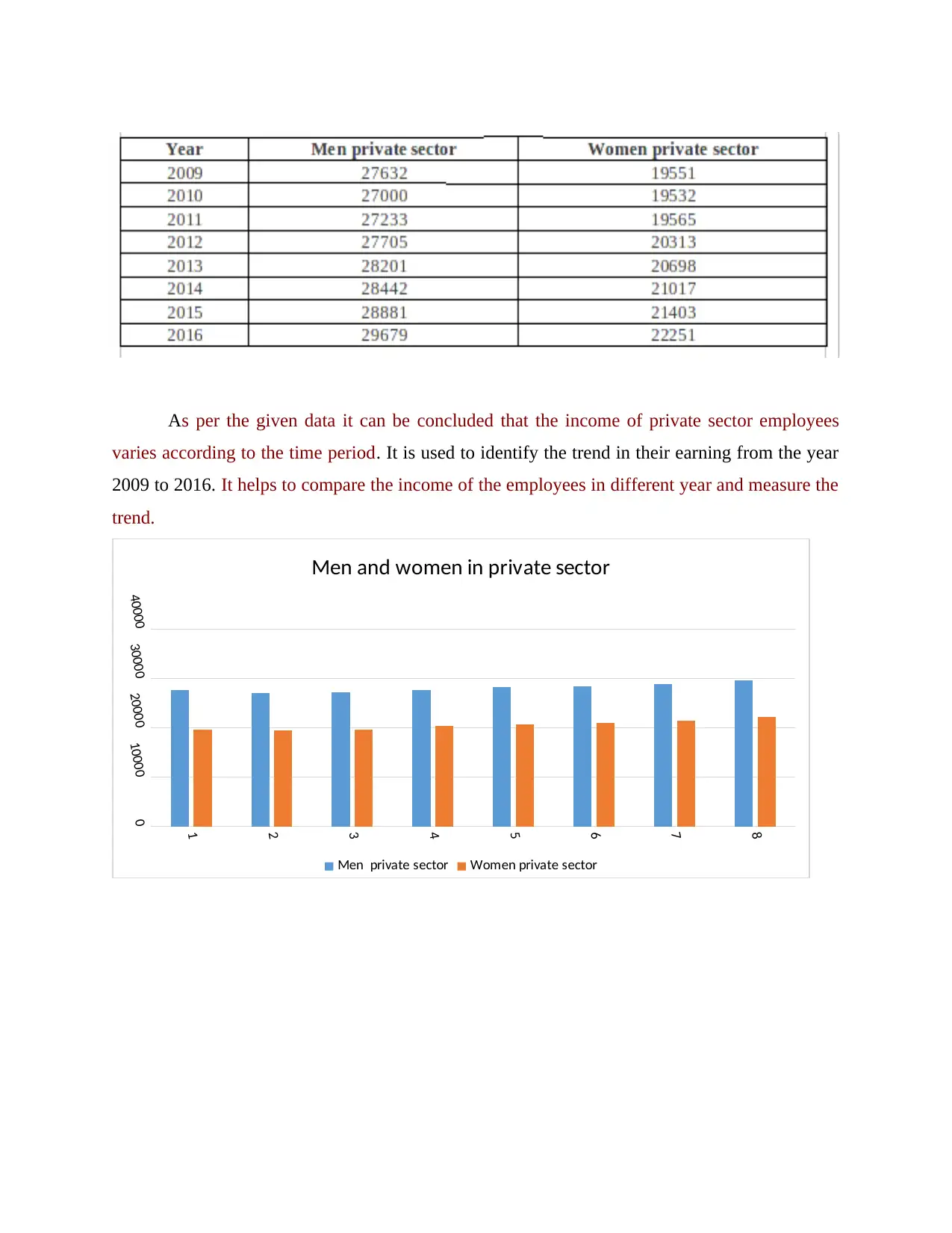
This report provides a comprehensive statistical analysis of income data, focusing on comparisons between public and private sector employees, income growth trends, and regional differences. It utilizes various statistical methods, including hypothesis testing, median, quartile, mean, and standard deviation calculations, to interpret the data. The report also explores the application of statistical techniques in business planning, such as the calculation of Economic Order Quantity (EOQ) for inventory management and Z-value calculation for quality control. Furthermore, the report incorporates the use of charts and tables for effective data presentation and communication of findings. Overall, the analysis aims to provide insights into income structures, economic trends, and the practical application of statistical tools in management decision-making.




1 out of 22
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.