Statistics for Managerial Decisions Assignment Solution Week 10
VerifiedAdded on 2022/11/13
|10
|974
|397
Homework Assignment
AI Summary
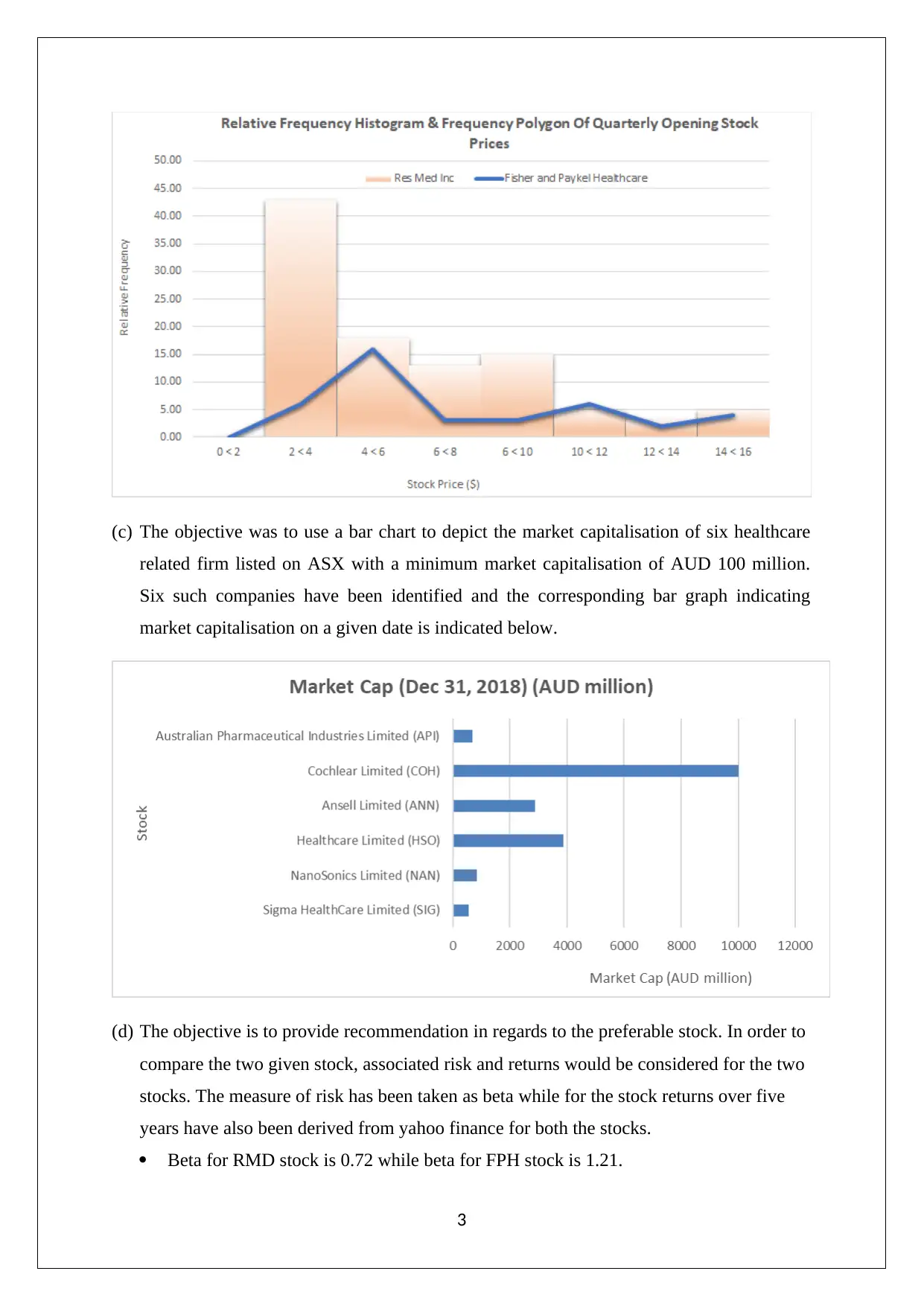
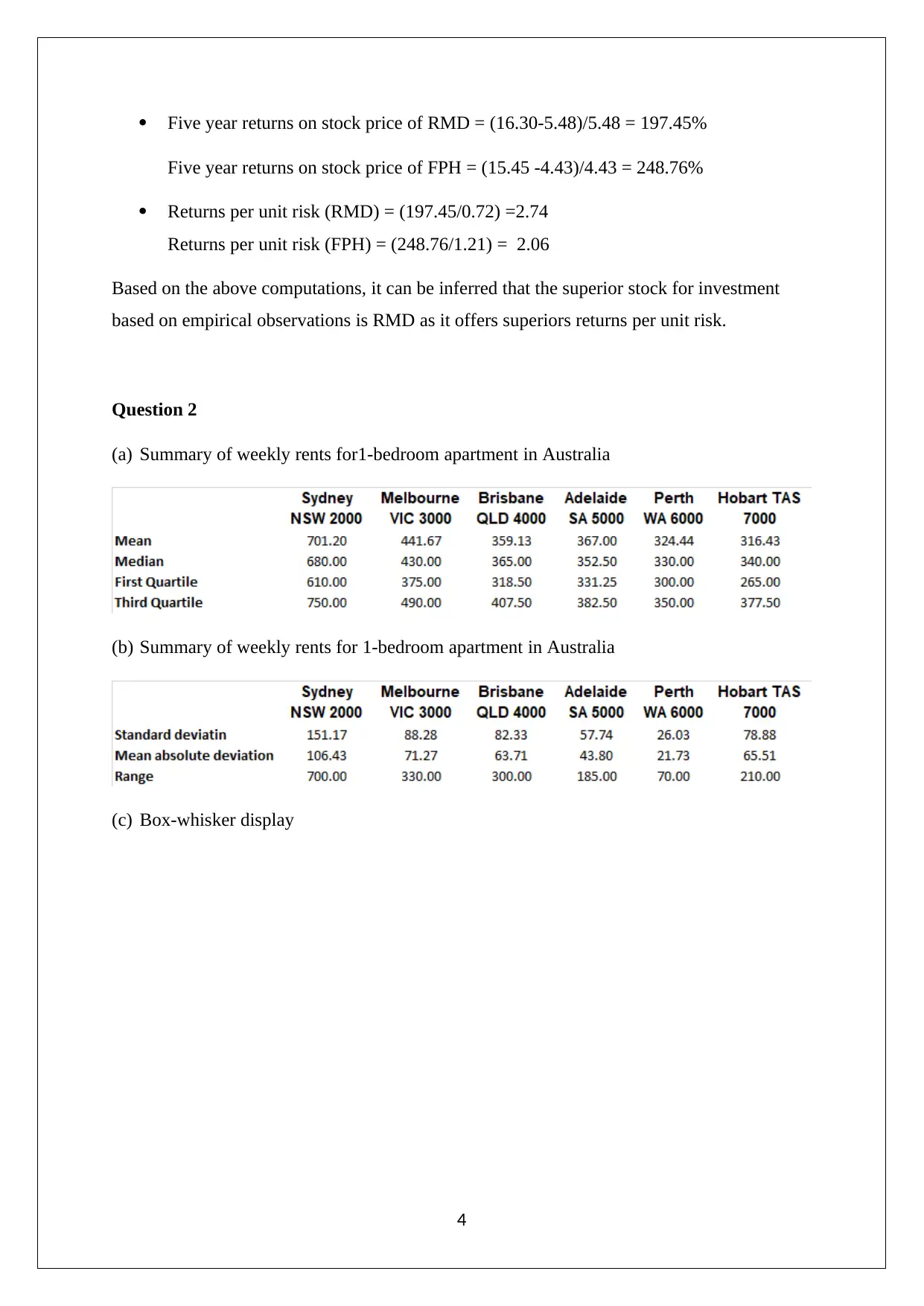
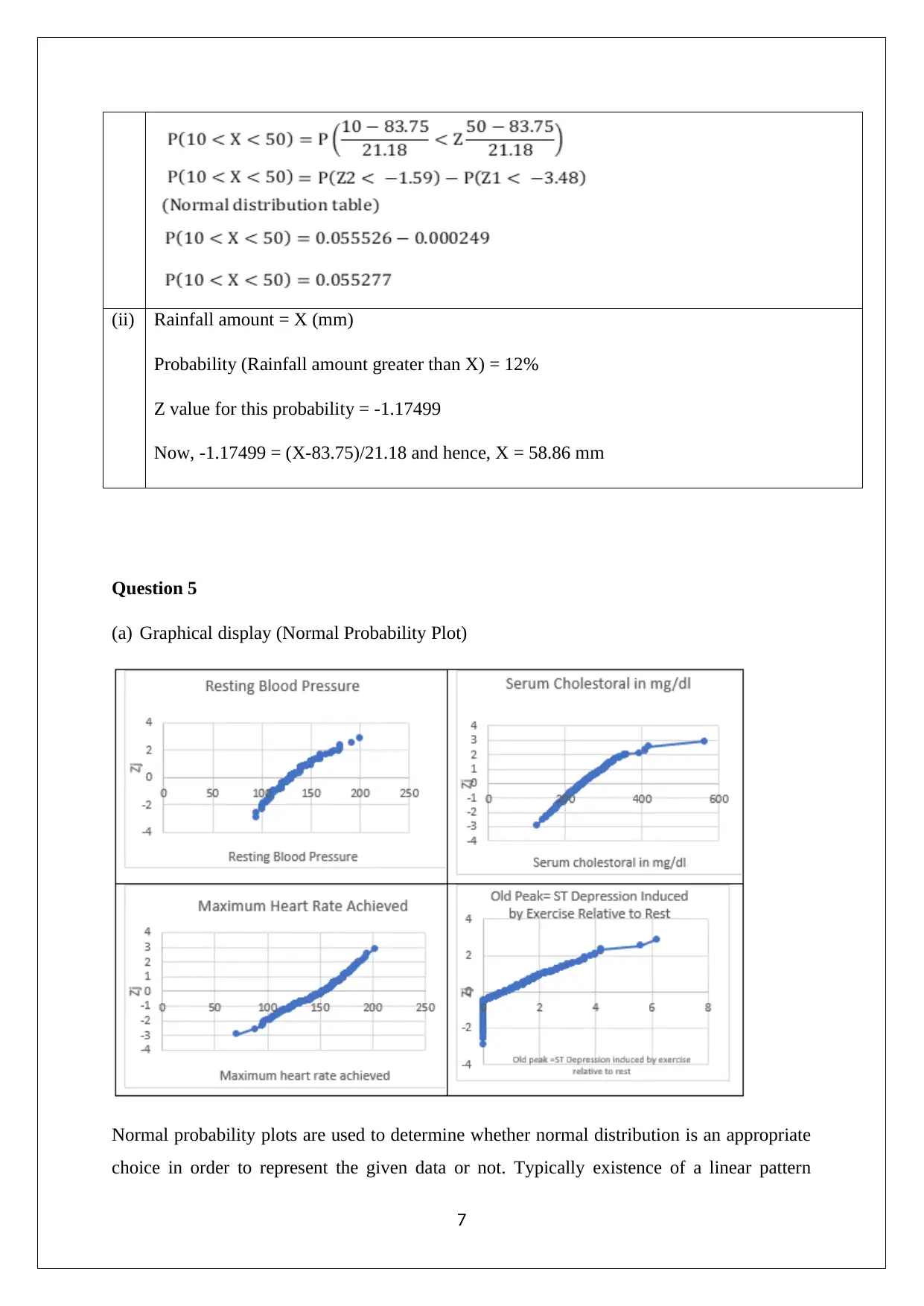
This assignment solution provides detailed answers to questions related to statistics for managerial decisions. It includes analysis of stock prices using stem and leaf plots, histograms, and frequency polygons, along with a bar chart depicting market capitalization of healthcare firms. The solution also compares stock investment options based on risk and return. Further, it summarizes weekly rents for 1-bedroom apartments in Australia and analyzes Airbnb listings. It calculates probabilities using Poisson and normal distributions and interprets normal probability plots for variables like resting blood pressure and serum cholesterol to determine the suitability of normal distribution. Confidence intervals are computed and used to assess the variables' effectiveness in segregating patients with and without heart disease. Desklib offers a wide range of solved assignments and past papers to support students in their academic journey.







1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.