Analysis of Statistics for Managerial Decisions Assignment Solution
VerifiedAdded on 2022/11/01
|10
|999
|63
Homework Assignment
AI Summary
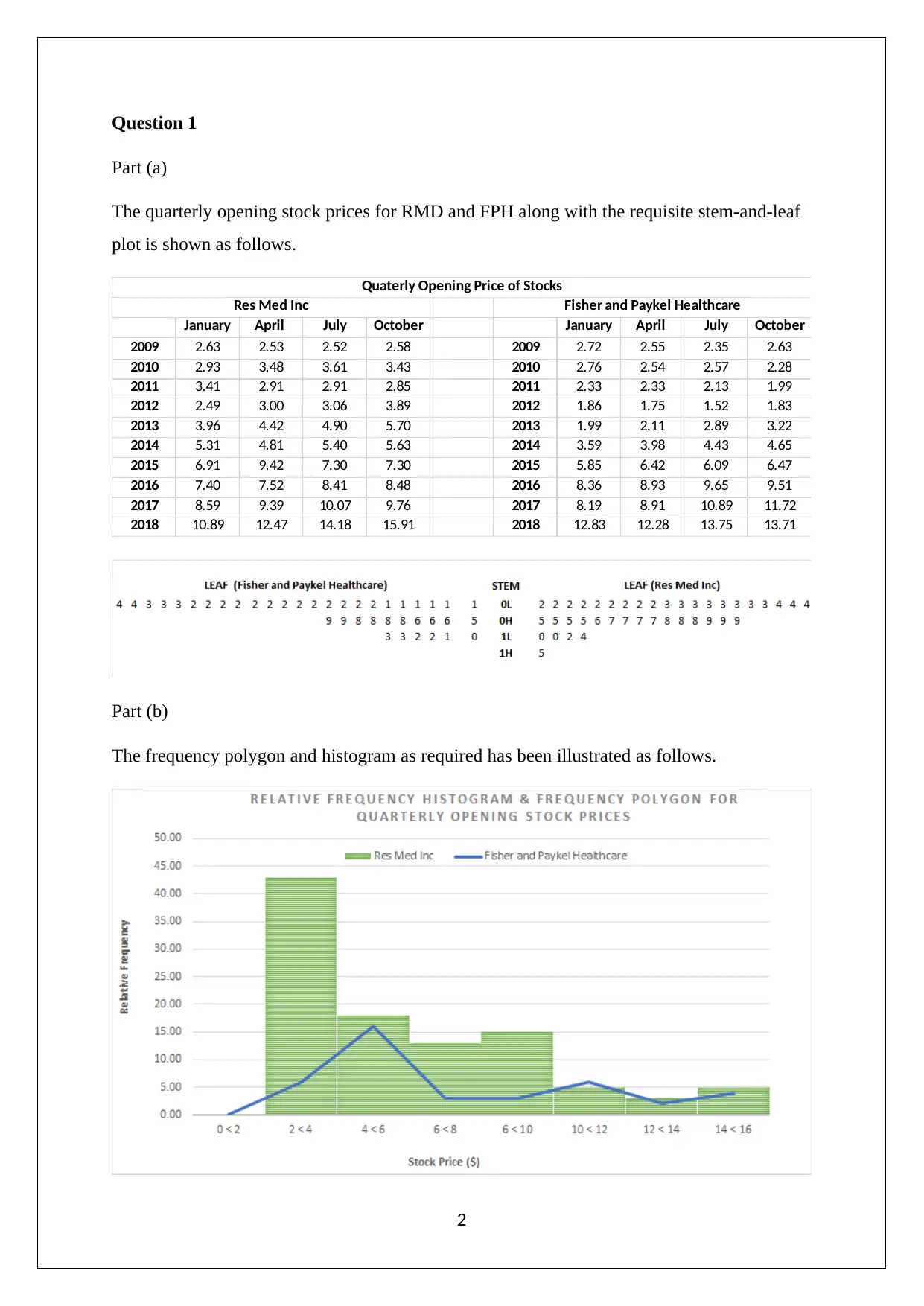
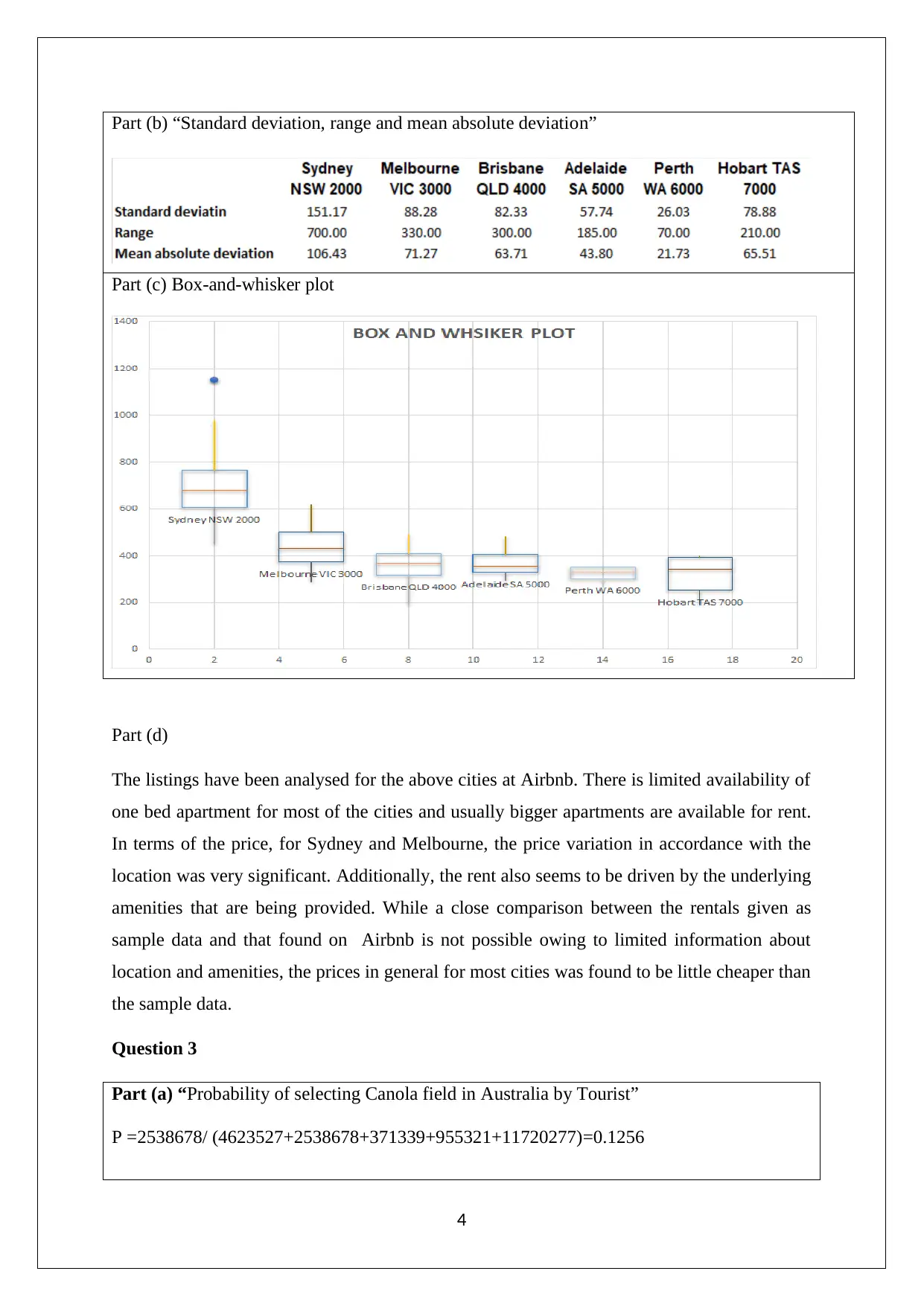
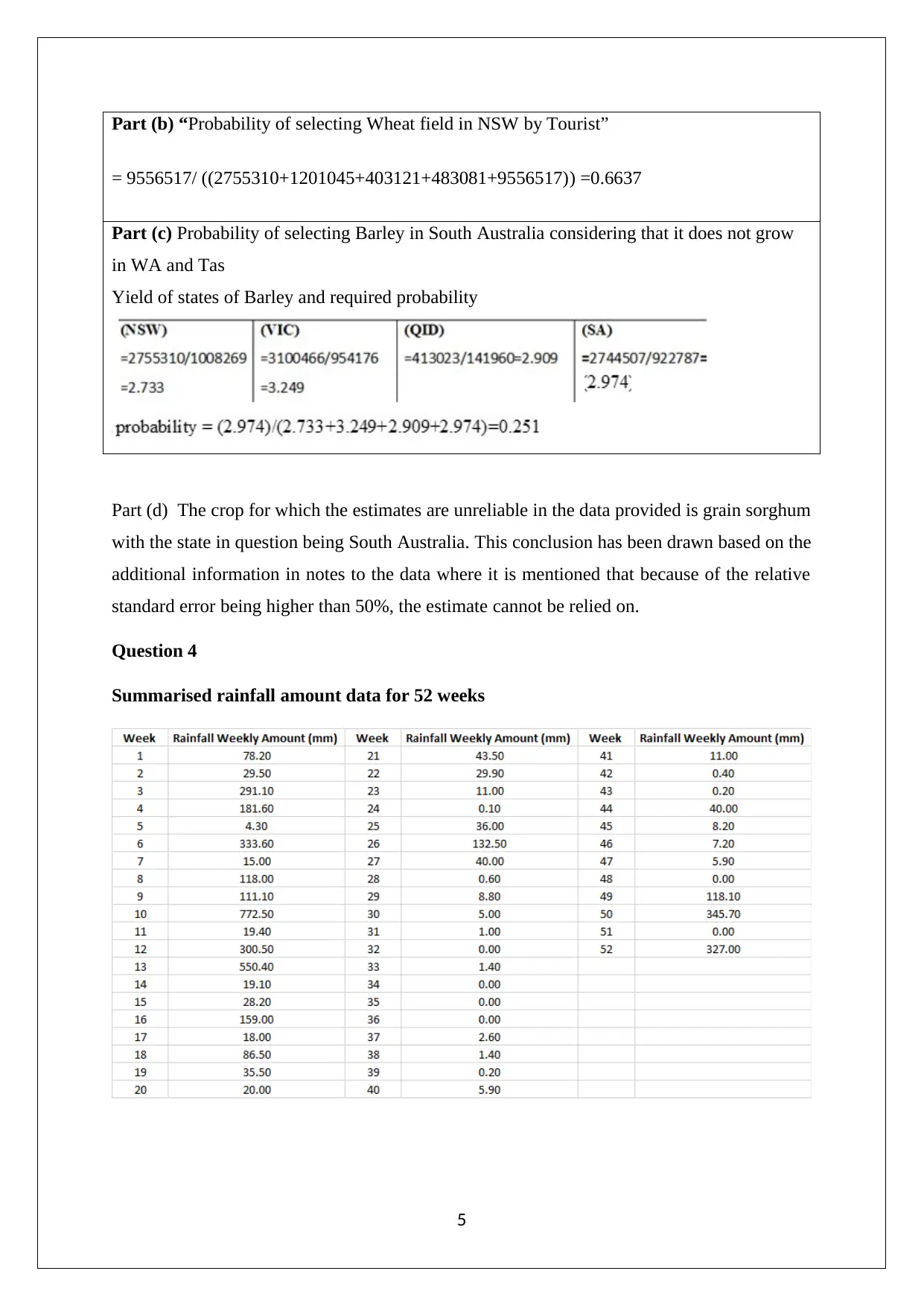
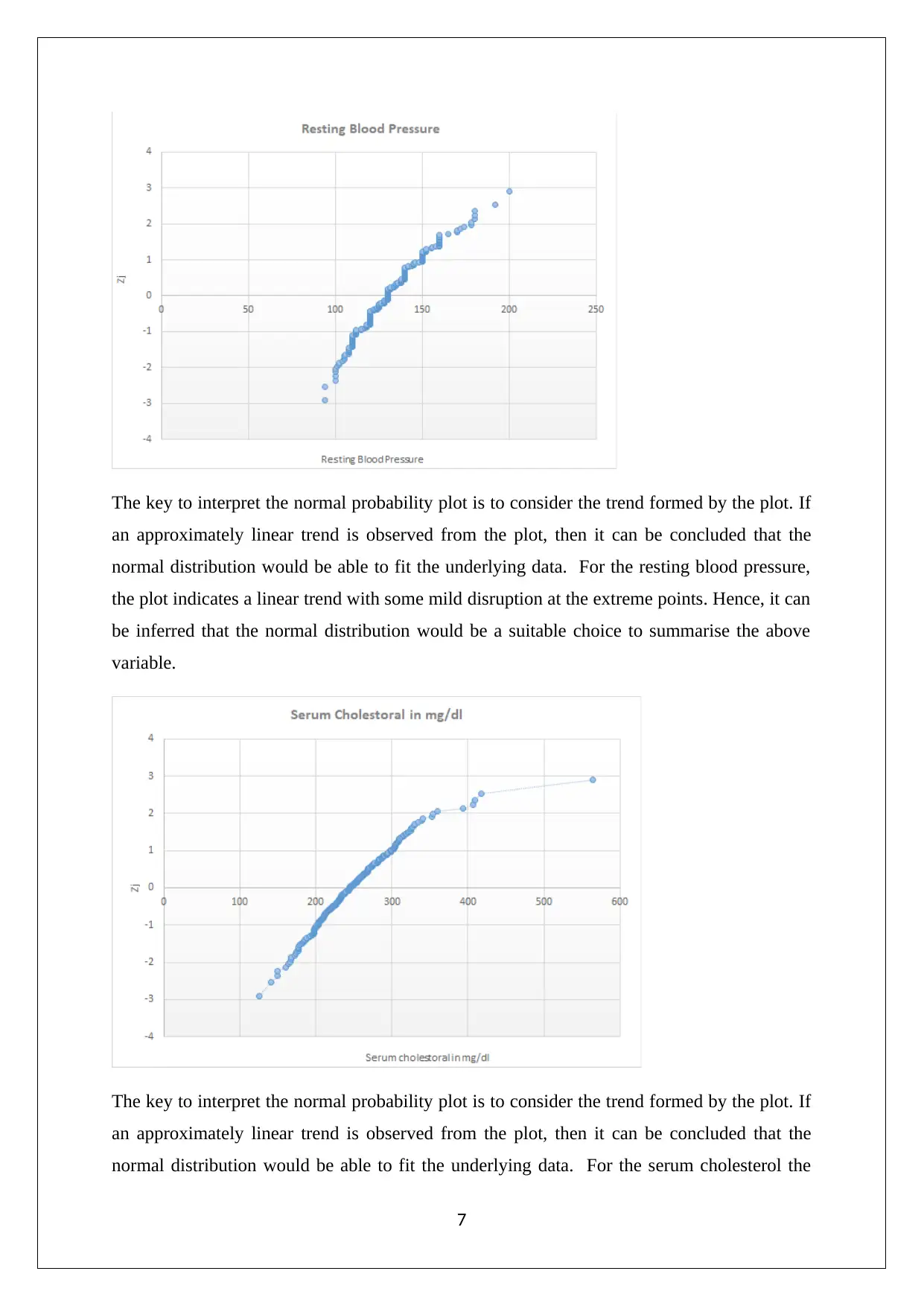
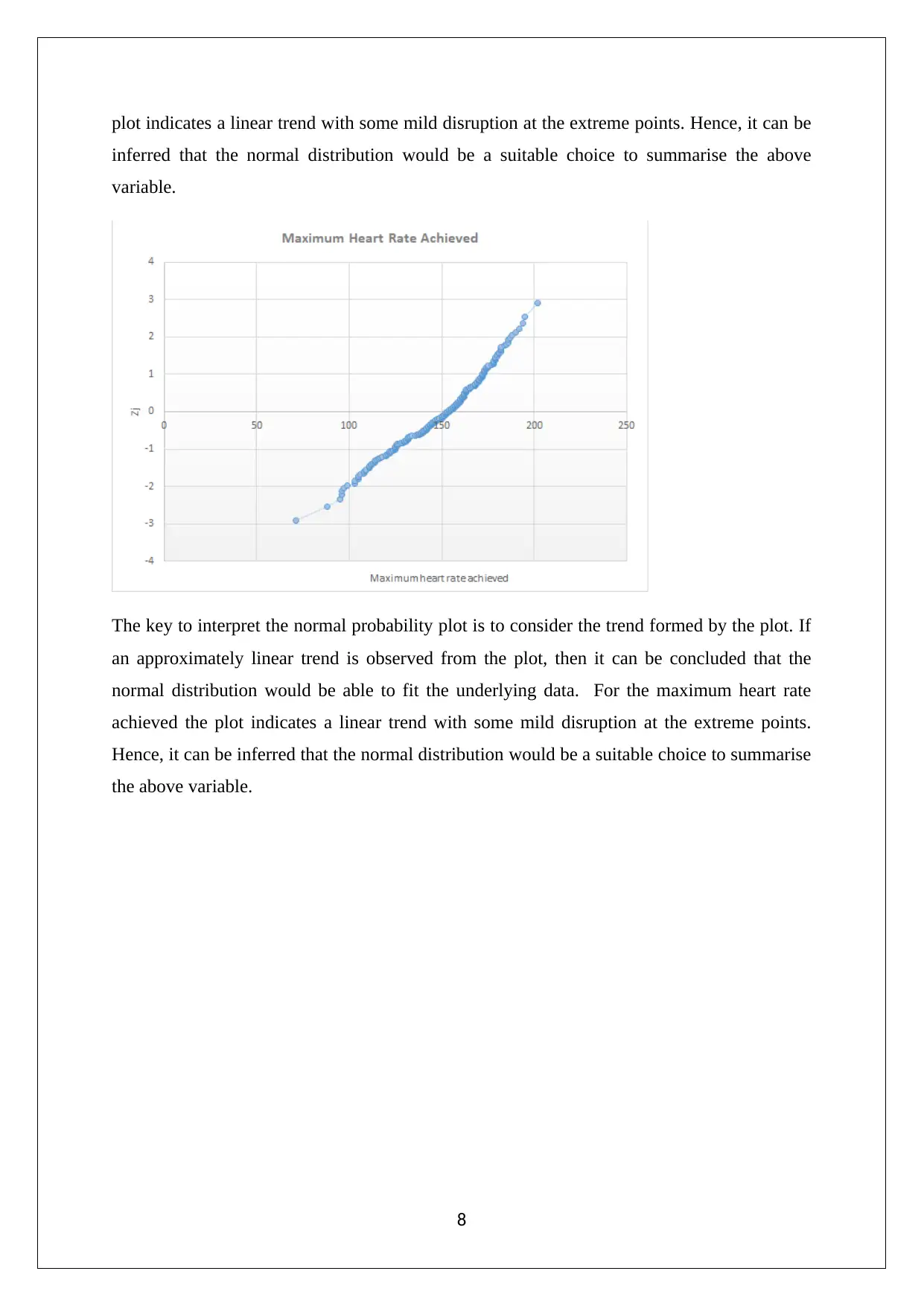
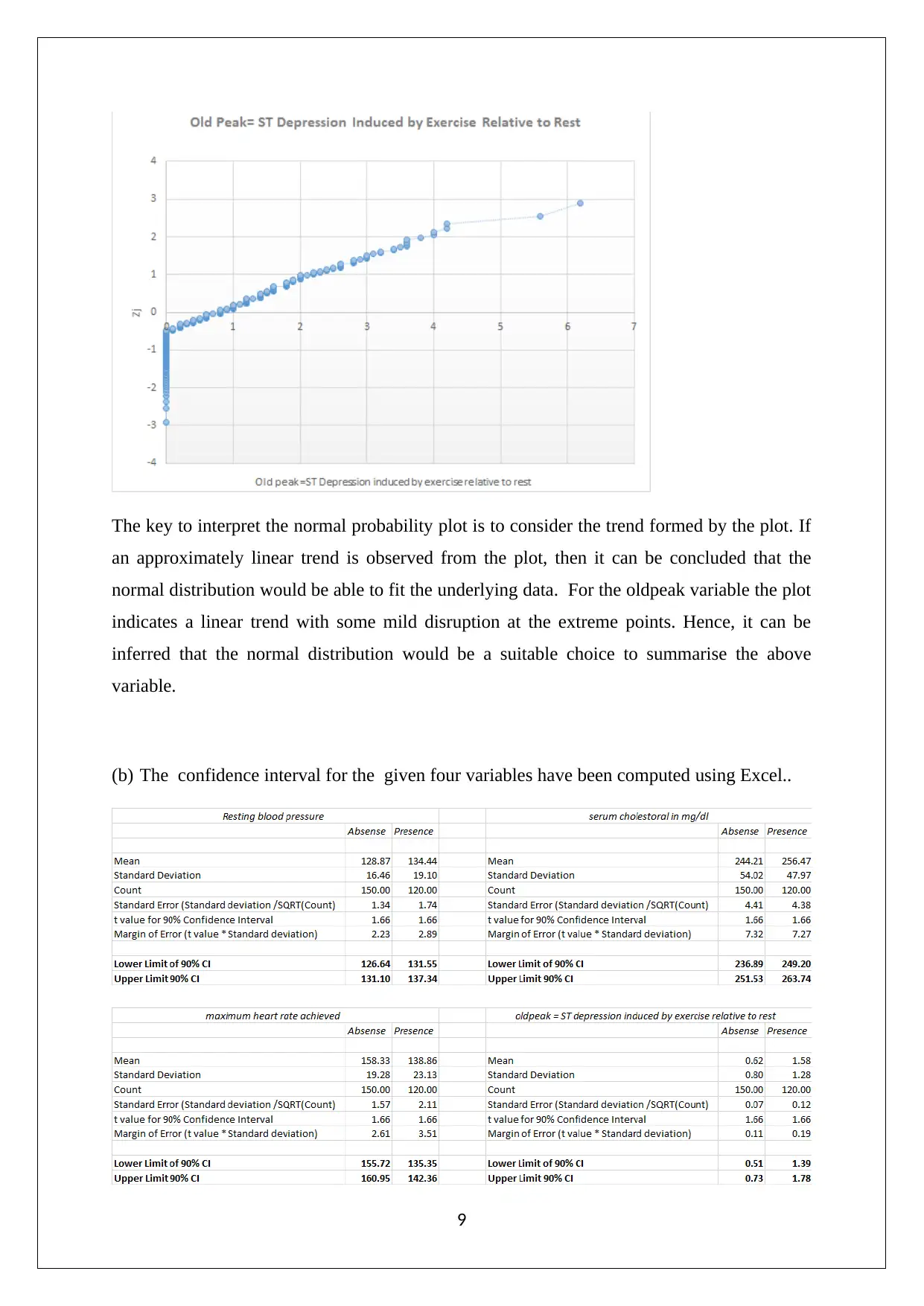
This assignment solution for Statistics for Managerial Decisions addresses several statistical concepts. It begins with data analysis, including stem-and-leaf plots, frequency polygons, and histograms to visualize stock prices. The solution then delves into investment analysis, computing risk-adjusted returns using beta to compare stock performance. Furthermore, the assignment examines real estate data, analyzing apartment rentals across different cities. The solution also explores probability, addressing crop selection based on state yields. Finally, it includes the interpretation of normal probability plots and the computation of confidence intervals to determine the variables suitable for differentiating between patient categories, specifically in identifying heart disease based on overlapping intervals.




1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.