Statistics Homework: Confidence Intervals, ANOVA, and Regression
VerifiedAdded on 2023/01/10
|10
|1445
|24
Homework Assignment
AI Summary
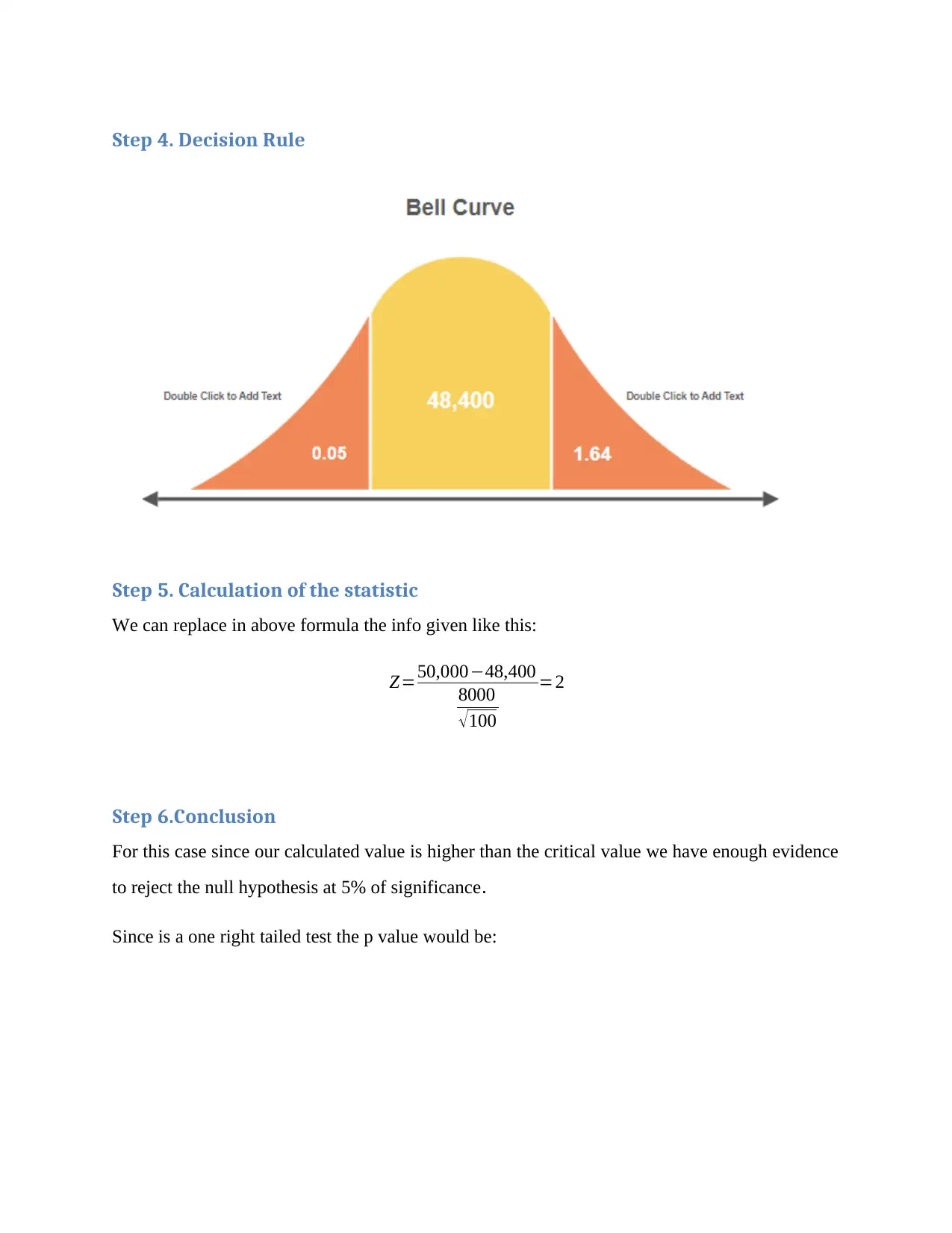
This statistics assignment provides comprehensive solutions to various statistical problems. The first question addresses confidence intervals and sample size calculations for hospital referrals. Question 2 delves into hypothesis testing, including setting up hypotheses, calculating test statistics, and making conclusions. Question 3 focuses on ANOVA, detailing the null and alternative hypotheses, decision rules, test statistic calculation, and interpretation. The assignment then moves on to regression analysis in Question 4, covering the estimated regression line, interpretation of the slope coefficient, and tests for significant relationships. Finally, Question 5 explores multiple linear regression models, including the estimated regression equation, coefficient of determination, and tests for significant relationships between variables. The solutions provide detailed step-by-step procedures and interpretations of the results.









1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.