Statistics for Management Decision Assessment - II Analysis Report
VerifiedAdded on 2020/04/01
|20
|1332
|42
Homework Assignment
AI Summary
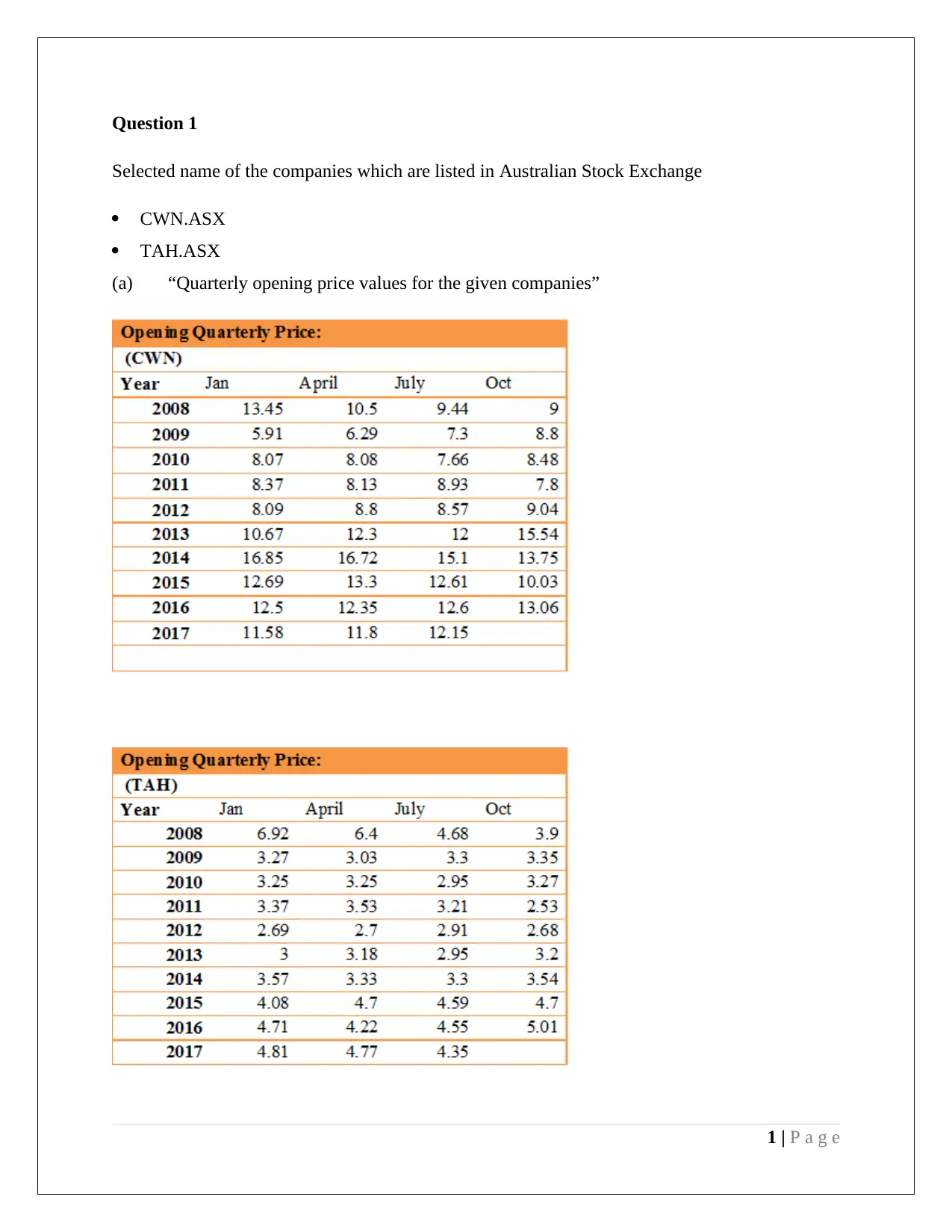
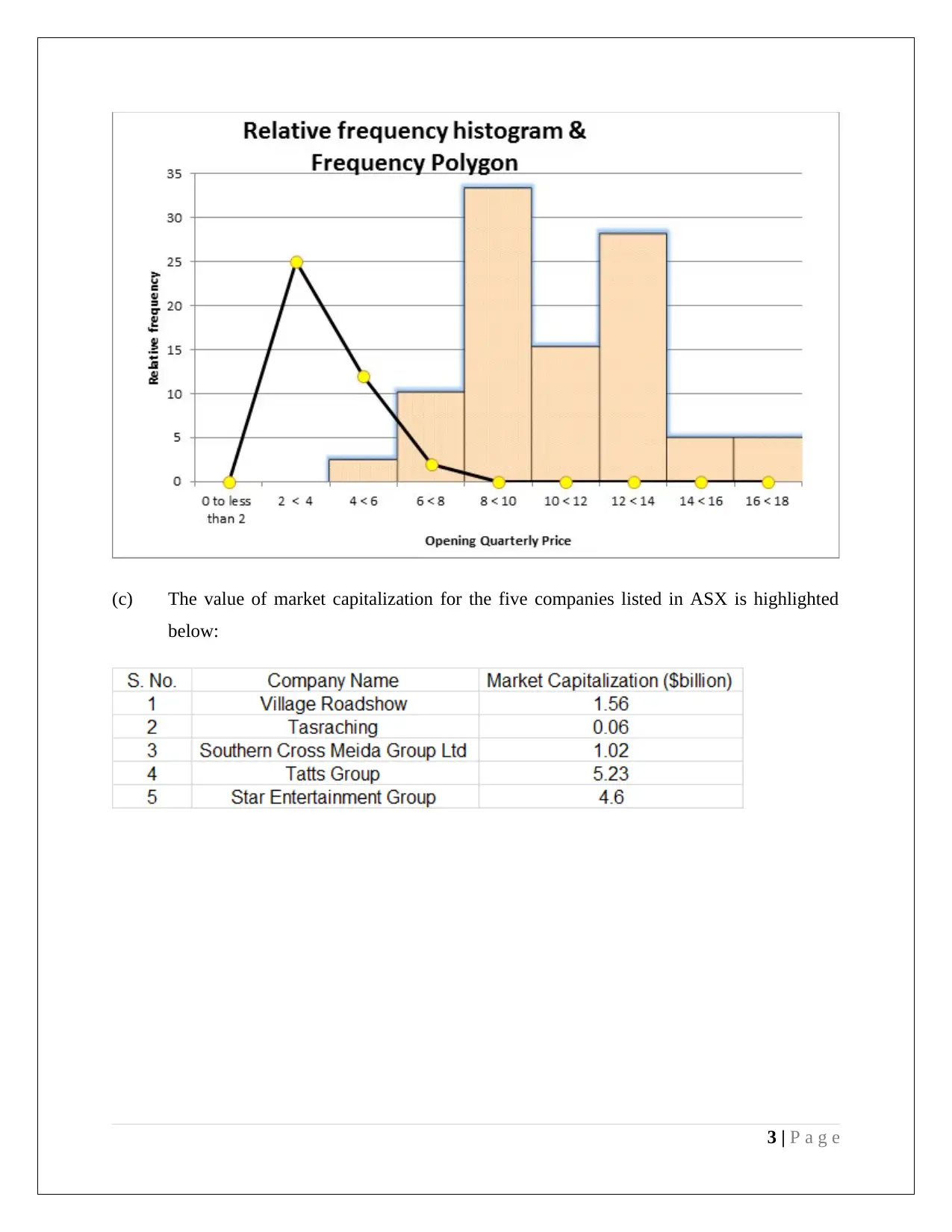
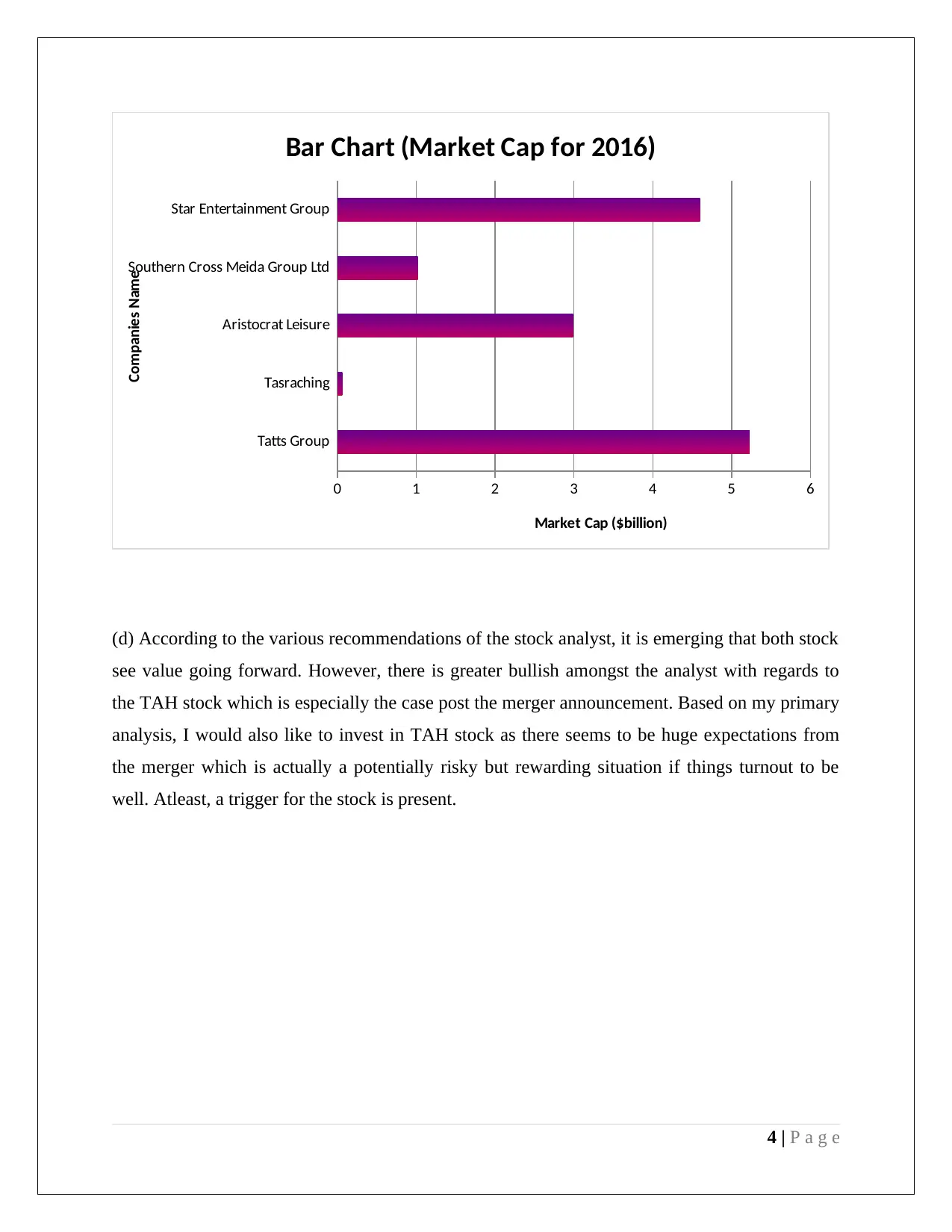
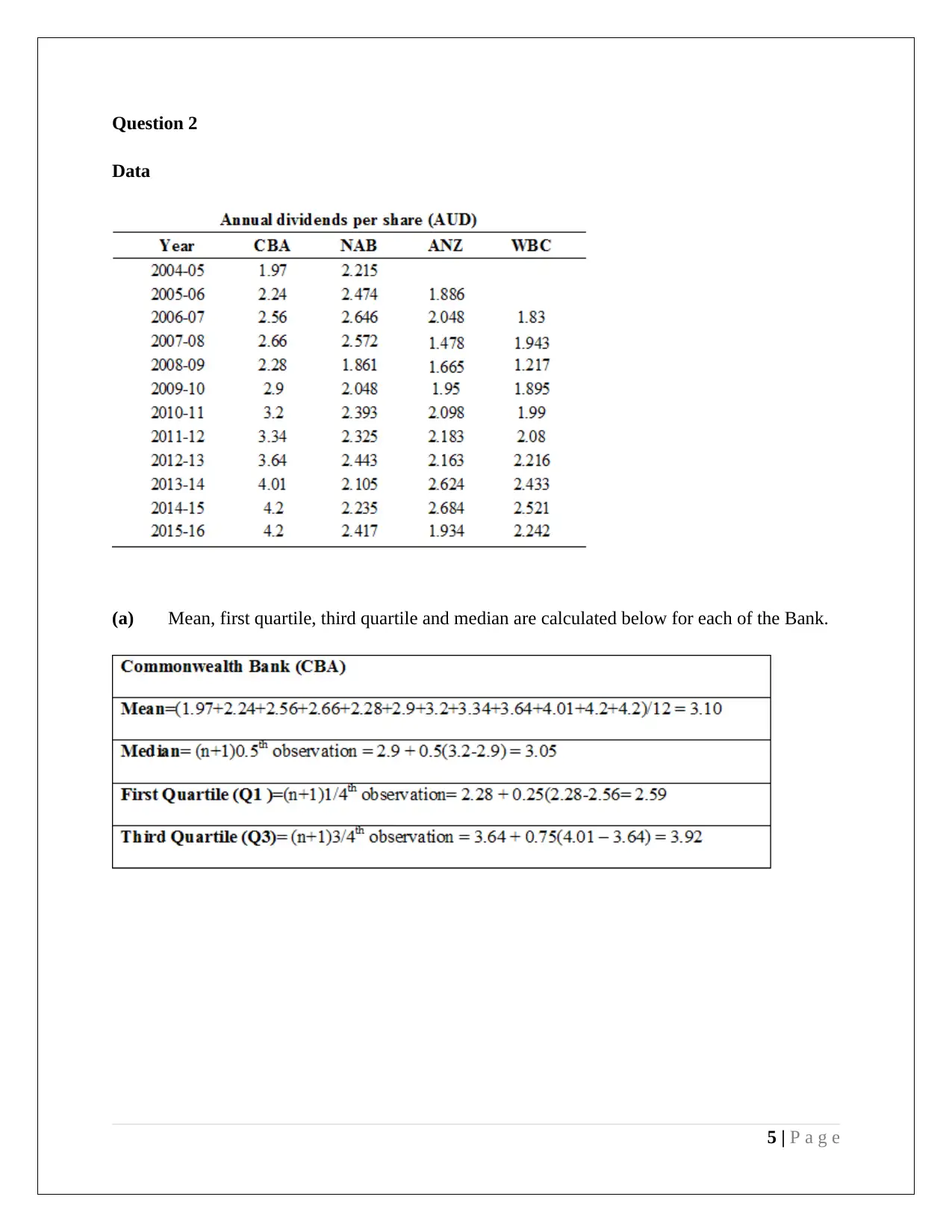
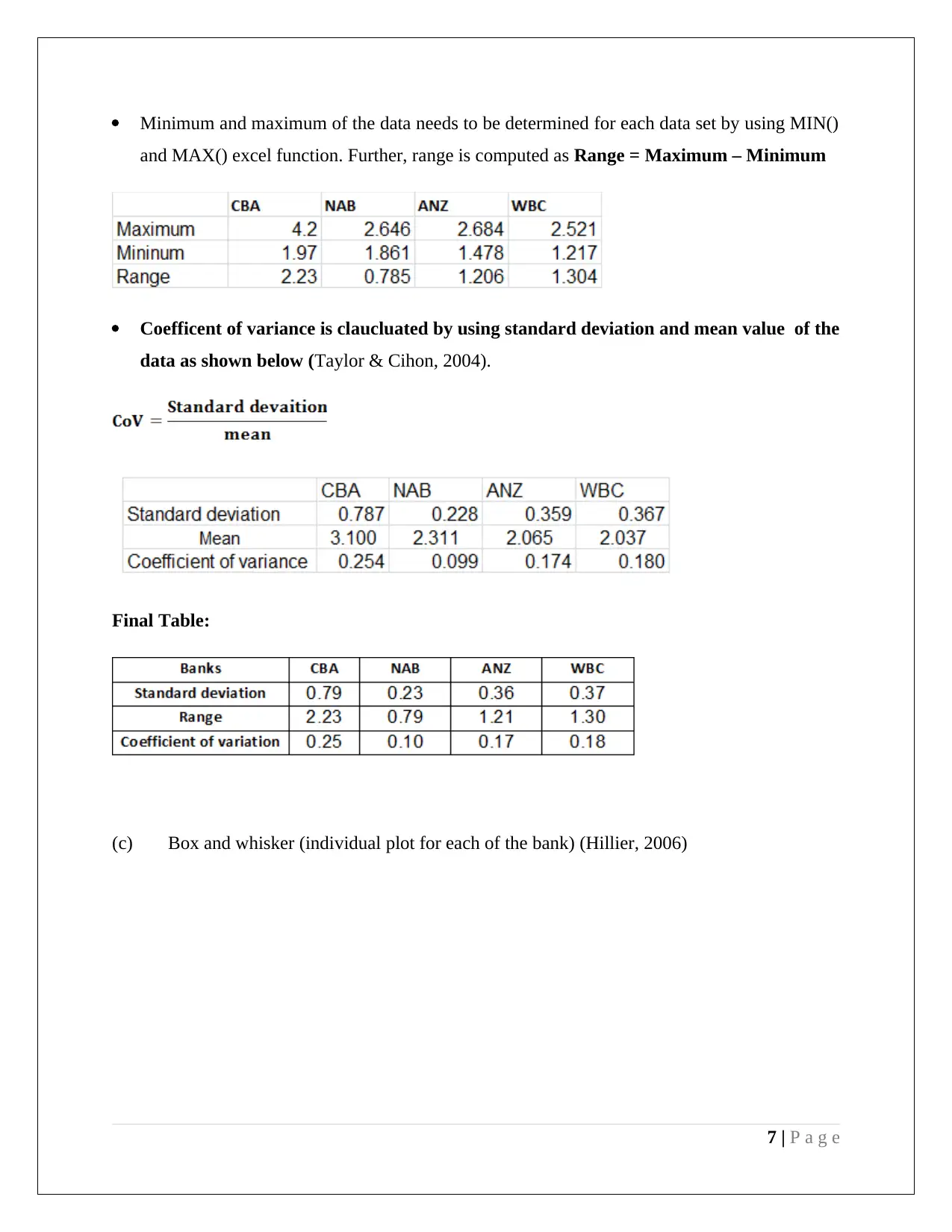
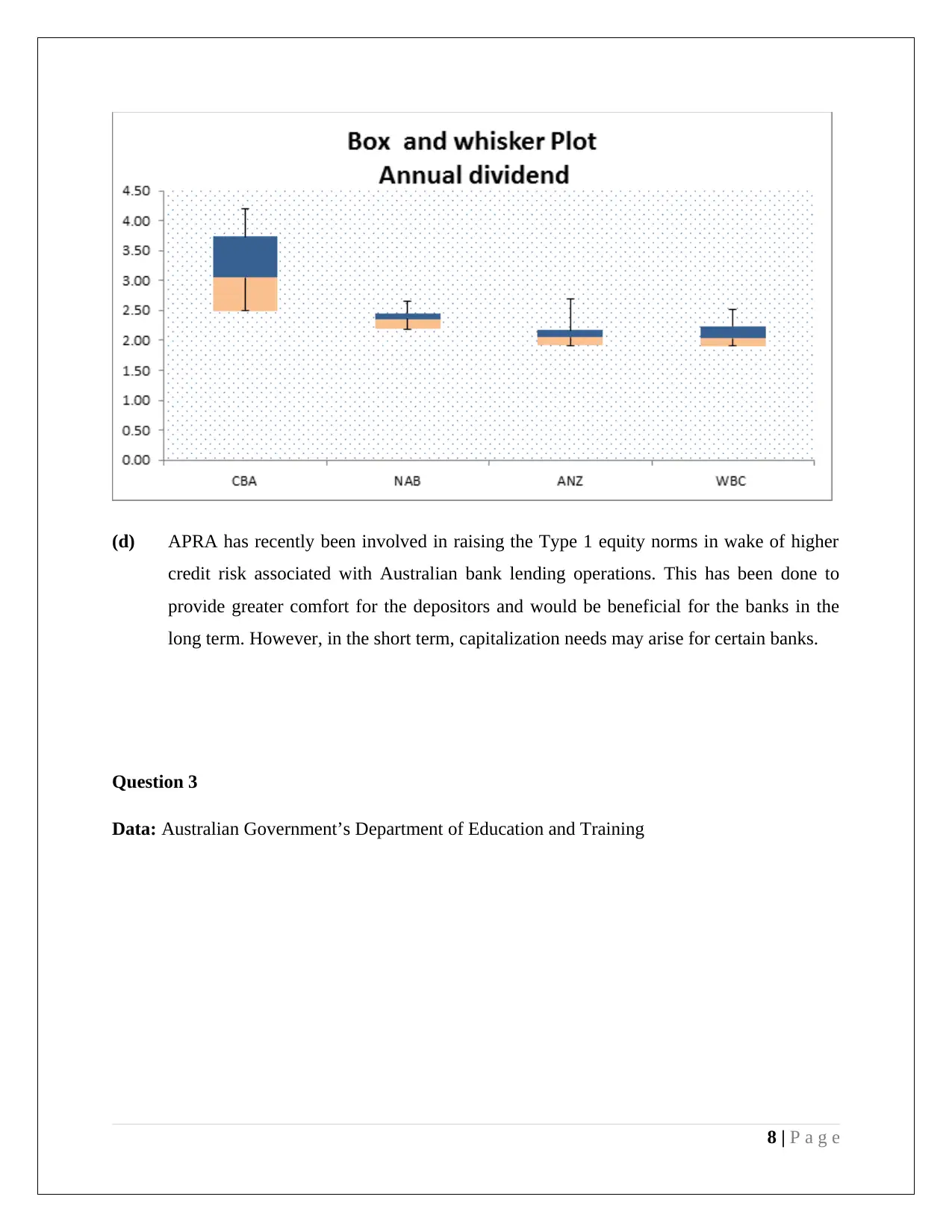
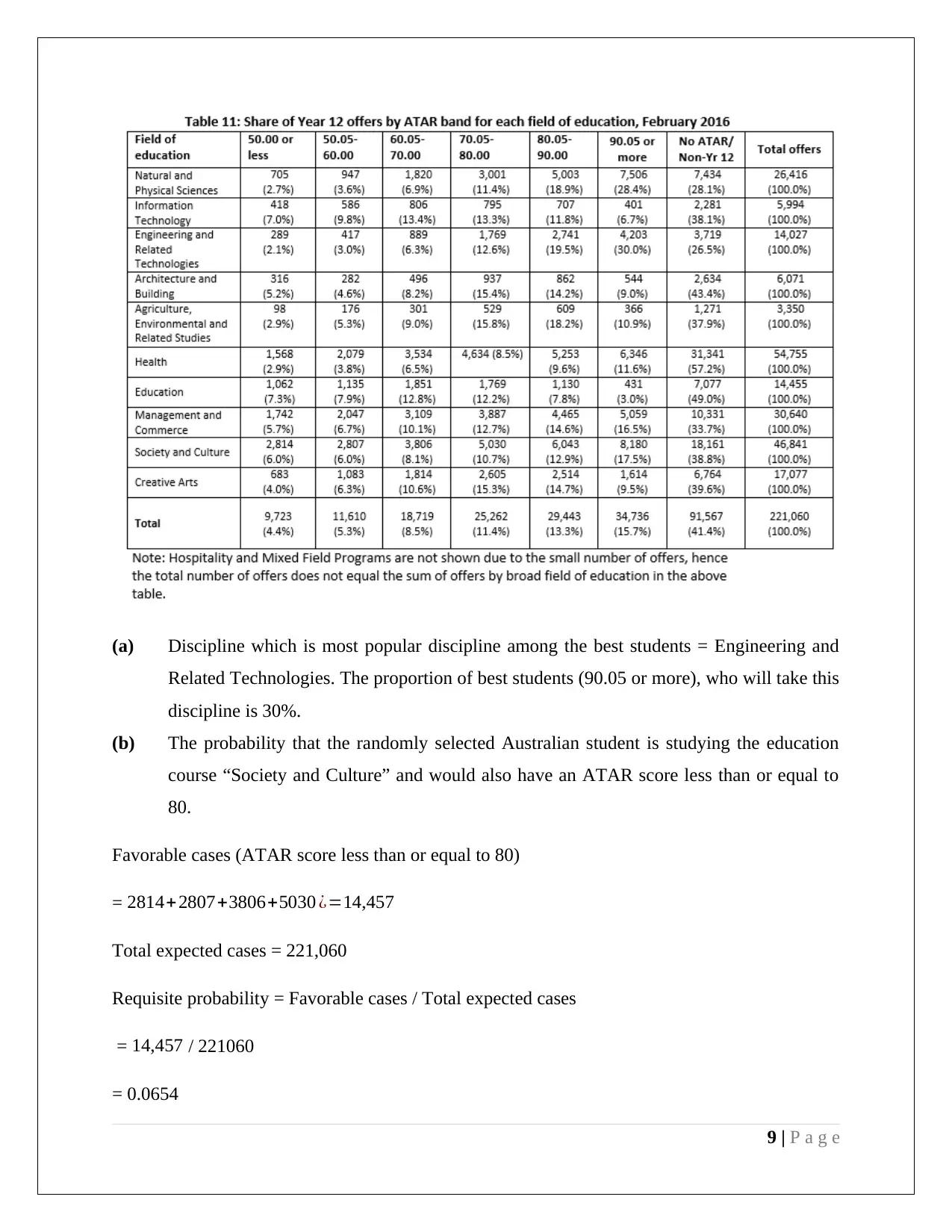
This assignment provides a comprehensive analysis of statistical methods applied to management decision-making. It includes an examination of stock market data from the Australian Stock Exchange, utilizing stem and leaf plots, relative frequency histograms, and frequency polygons to visualize and interpret quarterly opening price values for selected companies (CWN and TAH). The assignment delves into calculating descriptive statistics such as mean, median, quartiles, standard deviation, and coefficient of variation for financial data, accompanied by box and whisker plots for comparative analysis. Further, the assignment explores probability distributions, including Poisson and Normal distributions, to model rainfall patterns and analyze student ATAR scores and discipline preferences. The document incorporates hypothesis testing, confidence intervals, and normal probability plots to assess the significance of data and draw conclusions. The assignment also uses Excel functions for calculations and refers to relevant academic literature for methodological support.





1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.