Comprehensive Statistical Analysis and Forecasting: Business Report
VerifiedAdded on 2020/07/23
|13
|2004
|66
Report
AI Summary
This report presents a comprehensive statistical analysis of business data, focusing on descriptive statistics, forecasting, and data interpretation. It begins with an introduction outlining the importance of data analysis in business decision-making and then proceeds with a detailed analysis of the data, including the creation of histograms and the calculation of measures of central tendency like mean and median, along with standard deviation. The report compares the performance of two companies, Cosmic Curries and Hubble Bubble Restaurant, using descriptive statistics and graphical representations like OGIVE charts. It also delves into seasonal variation models for forecasting, assesses the accuracy of forecasts, and comments on specific opinions related to sales trends. The conclusion emphasizes the significance of statistics in making informed business decisions and highlights the use of descriptive statistics as a crucial tool for evaluating company performance, with references to supporting literature and online resources.

STATISTICS
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

TABLE OF CONTENTS
INTRODUCTION...........................................................................................................................1
Question 1........................................................................................................................................1
(a).................................................................................................................................................1
(1)Histogram and shape of distribution...................................................................................1
(2)Measures of central tendency and OGIVE chart................................................................2
(b)Analysis of descriptive statistics.............................................................................................4
© Analysis of data.......................................................................................................................5
(1)Drawing of table and comparison of results.......................................................................5
(2)Difference between mean and median and their uses.........................................................5
(3) Explaination of quartiles....................................................................................................5
(4) Additional information required........................................................................................6
(5) Comparison of standard deviation.....................................................................................6
Question 2........................................................................................................................................6
(a).................................................................................................................................................6
(1)Selection of model..............................................................................................................6
(2) Brief explaination on seasonal variation model.................................................................7
(b).................................................................................................................................................7
(1)Graphical representation.....................................................................................................7
(2)Forecast values....................................................................................................................8
(C)................................................................................................................................................8
(1) Accuracy of forecasts and identification of random factors..............................................8
(2) Comment on Mr Sweaty opinion.......................................................................................8
(d) Charting of data......................................................................................................................8
CONCLUSION................................................................................................................................9
INTRODUCTION...........................................................................................................................1
Question 1........................................................................................................................................1
(a).................................................................................................................................................1
(1)Histogram and shape of distribution...................................................................................1
(2)Measures of central tendency and OGIVE chart................................................................2
(b)Analysis of descriptive statistics.............................................................................................4
© Analysis of data.......................................................................................................................5
(1)Drawing of table and comparison of results.......................................................................5
(2)Difference between mean and median and their uses.........................................................5
(3) Explaination of quartiles....................................................................................................5
(4) Additional information required........................................................................................6
(5) Comparison of standard deviation.....................................................................................6
Question 2........................................................................................................................................6
(a).................................................................................................................................................6
(1)Selection of model..............................................................................................................6
(2) Brief explaination on seasonal variation model.................................................................7
(b).................................................................................................................................................7
(1)Graphical representation.....................................................................................................7
(2)Forecast values....................................................................................................................8
(C)................................................................................................................................................8
(1) Accuracy of forecasts and identification of random factors..............................................8
(2) Comment on Mr Sweaty opinion.......................................................................................8
(d) Charting of data......................................................................................................................8
CONCLUSION................................................................................................................................9

REFERENCES..............................................................................................................................10
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
INTRODUCTION
Data generated in every business and it is very important to analyze it so that areas where
work need to be done can be identified. In current report, histogram is prepared and along with
this descriptive analaysis is also done by computing mean, median and standard deviation from
continue series data. In middle part of report companies performance is compared and conclusion
is formed about their performance. At end of the report, prediction is made by analyzing data and
comments are made on same. In this way entire research work is carried out.
Question 1
(a)
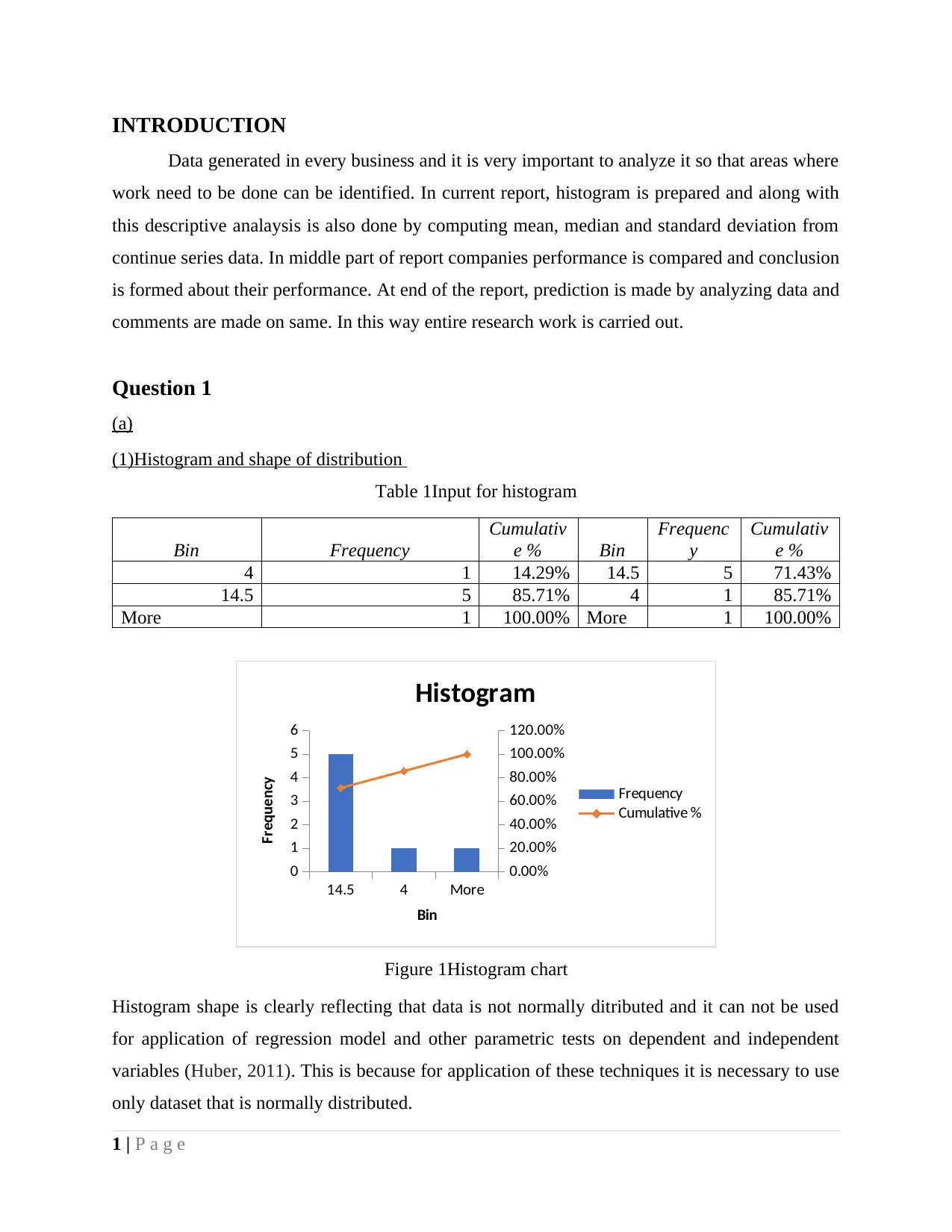
(1)Histogram and shape of distribution
Table 1Input for histogram
Bin Frequency
Cumulativ
e % Bin
Frequenc
y
Cumulativ
e %
4 1 14.29% 14.5 5 71.43%
14.5 5 85.71% 4 1 85.71%
More 1 100.00% More 1 100.00%
14.5 4 More
0
1
2
3
4
5
6
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
120.00%
Histogram
Frequency
Cumulative %
Bin
Frequency
Figure 1Histogram chart
Histogram shape is clearly reflecting that data is not normally ditributed and it can not be used
for application of regression model and other parametric tests on dependent and independent
variables (Huber, 2011). This is because for application of these techniques it is necessary to use
only dataset that is normally distributed.
1 | P a g e
Data generated in every business and it is very important to analyze it so that areas where
work need to be done can be identified. In current report, histogram is prepared and along with
this descriptive analaysis is also done by computing mean, median and standard deviation from
continue series data. In middle part of report companies performance is compared and conclusion
is formed about their performance. At end of the report, prediction is made by analyzing data and
comments are made on same. In this way entire research work is carried out.
Question 1
(a)
(1)Histogram and shape of distribution
Table 1Input for histogram
Bin Frequency
Cumulativ
e % Bin
Frequenc
y
Cumulativ
e %
4 1 14.29% 14.5 5 71.43%
14.5 5 85.71% 4 1 85.71%
More 1 100.00% More 1 100.00%
14.5 4 More
0
1
2
3
4
5
6
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
120.00%
Histogram
Frequency
Cumulative %
Bin
Frequency
Figure 1Histogram chart
Histogram shape is clearly reflecting that data is not normally ditributed and it can not be used
for application of regression model and other parametric tests on dependent and independent
variables (Huber, 2011). This is because for application of these techniques it is necessary to use
only dataset that is normally distributed.
1 | P a g e
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
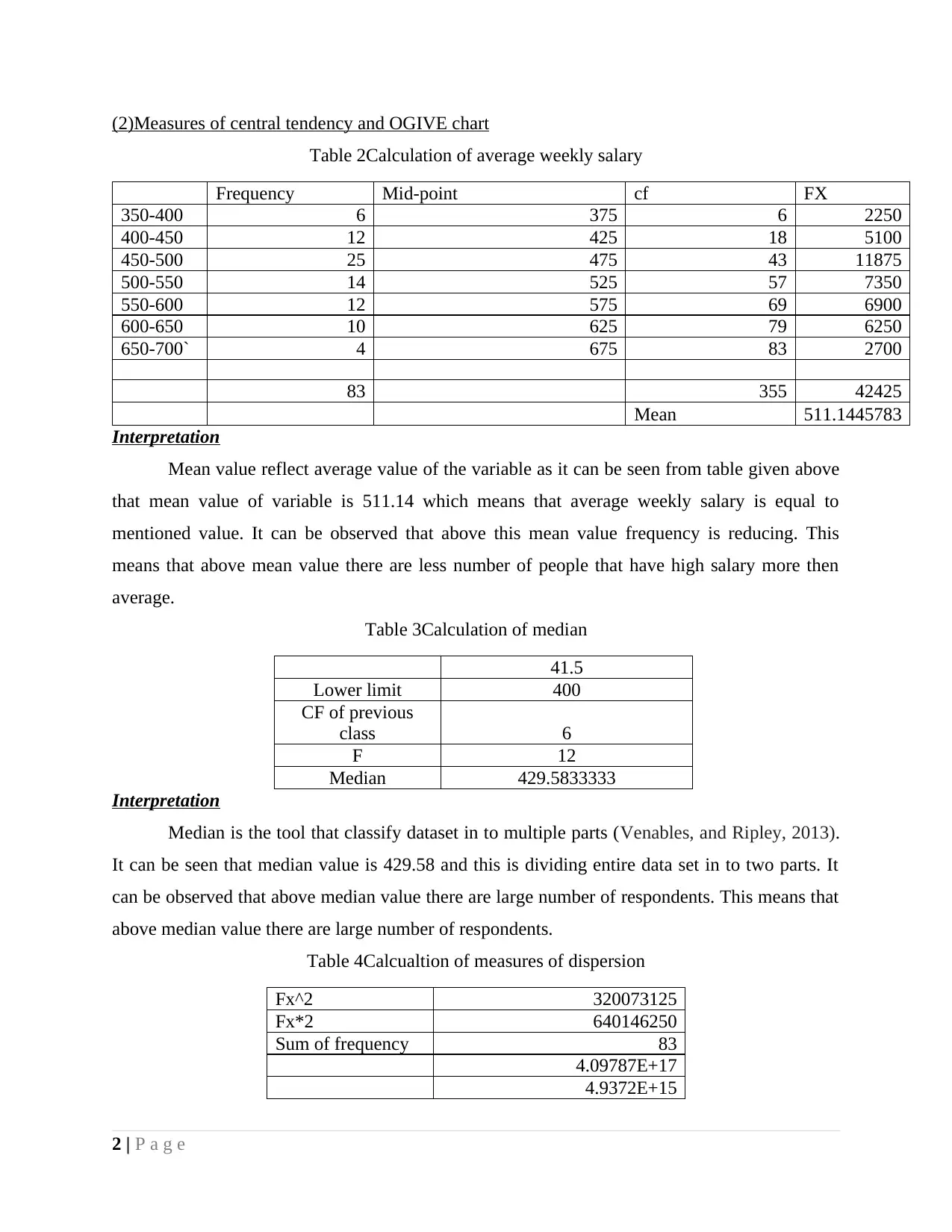
(2)Measures of central tendency and OGIVE chart
Table 2Calculation of average weekly salary
Frequency Mid-point cf FX
350-400 6 375 6 2250
400-450 12 425 18 5100
450-500 25 475 43 11875
500-550 14 525 57 7350
550-600 12 575 69 6900
600-650 10 625 79 6250
650-700` 4 675 83 2700
83 355 42425
Mean 511.1445783
Interpretation
Mean value reflect average value of the variable as it can be seen from table given above
that mean value of variable is 511.14 which means that average weekly salary is equal to
mentioned value. It can be observed that above this mean value frequency is reducing. This
means that above mean value there are less number of people that have high salary more then
average.
Table 3Calculation of median
41.5
Lower limit 400
CF of previous
class 6
F 12
Median 429.5833333
Interpretation
Median is the tool that classify dataset in to multiple parts (Venables, and Ripley, 2013).
It can be seen that median value is 429.58 and this is dividing entire data set in to two parts. It
can be observed that above median value there are large number of respondents. This means that
above median value there are large number of respondents.
Table 4Calcualtion of measures of dispersion
Fx^2 320073125
Fx*2 640146250
Sum of frequency 83
4.09787E+17
4.9372E+15
2 | P a g e
Table 2Calculation of average weekly salary
Frequency Mid-point cf FX
350-400 6 375 6 2250
400-450 12 425 18 5100
450-500 25 475 43 11875
500-550 14 525 57 7350
550-600 12 575 69 6900
600-650 10 625 79 6250
650-700` 4 675 83 2700
83 355 42425
Mean 511.1445783
Interpretation
Mean value reflect average value of the variable as it can be seen from table given above
that mean value of variable is 511.14 which means that average weekly salary is equal to
mentioned value. It can be observed that above this mean value frequency is reducing. This
means that above mean value there are less number of people that have high salary more then
average.
Table 3Calculation of median
41.5
Lower limit 400
CF of previous
class 6
F 12
Median 429.5833333
Interpretation
Median is the tool that classify dataset in to multiple parts (Venables, and Ripley, 2013).
It can be seen that median value is 429.58 and this is dividing entire data set in to two parts. It
can be observed that above median value there are large number of respondents. This means that
above median value there are large number of respondents.
Table 4Calcualtion of measures of dispersion
Fx^2 320073125
Fx*2 640146250
Sum of frequency 83
4.09787E+17
4.9372E+15
2 | P a g e
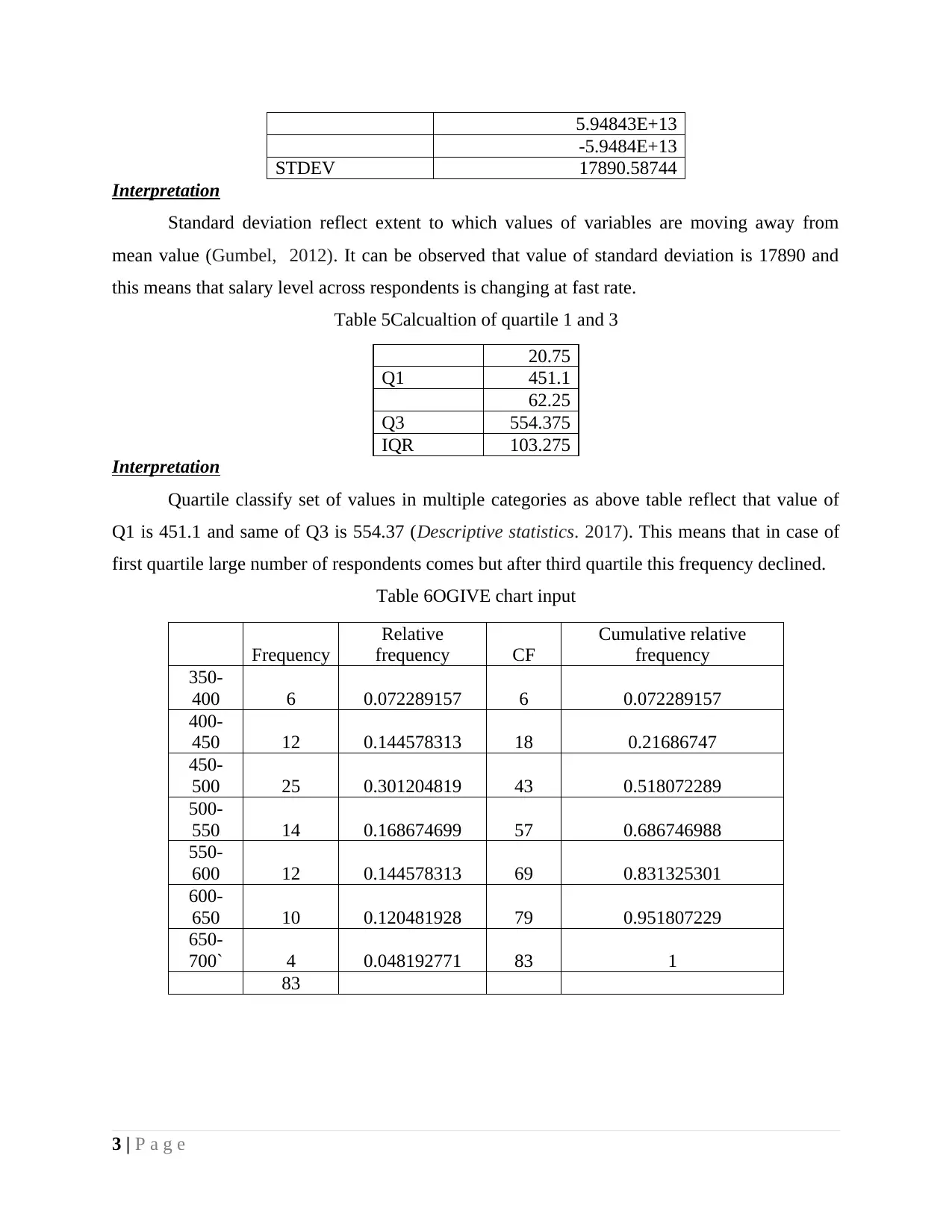
5.94843E+13
-5.9484E+13
STDEV 17890.58744
Interpretation
Standard deviation reflect extent to which values of variables are moving away from
mean value (Gumbel, 2012). It can be observed that value of standard deviation is 17890 and
this means that salary level across respondents is changing at fast rate.
Table 5Calcualtion of quartile 1 and 3
20.75
Q1 451.1
62.25
Q3 554.375
IQR 103.275
Interpretation
Quartile classify set of values in multiple categories as above table reflect that value of
Q1 is 451.1 and same of Q3 is 554.37 (Descriptive statistics. 2017). This means that in case of
first quartile large number of respondents comes but after third quartile this frequency declined.
Table 6OGIVE chart input
Frequency
Relative
frequency CF
Cumulative relative
frequency
350-
400 6 0.072289157 6 0.072289157
400-
450 12 0.144578313 18 0.21686747
450-
500 25 0.301204819 43 0.518072289
500-
550 14 0.168674699 57 0.686746988
550-
600 12 0.144578313 69 0.831325301
600-
650 10 0.120481928 79 0.951807229
650-
700` 4 0.048192771 83 1
83
3 | P a g e
-5.9484E+13
STDEV 17890.58744
Interpretation
Standard deviation reflect extent to which values of variables are moving away from
mean value (Gumbel, 2012). It can be observed that value of standard deviation is 17890 and
this means that salary level across respondents is changing at fast rate.
Table 5Calcualtion of quartile 1 and 3
20.75
Q1 451.1
62.25
Q3 554.375
IQR 103.275
Interpretation
Quartile classify set of values in multiple categories as above table reflect that value of
Q1 is 451.1 and same of Q3 is 554.37 (Descriptive statistics. 2017). This means that in case of
first quartile large number of respondents comes but after third quartile this frequency declined.
Table 6OGIVE chart input
Frequency
Relative
frequency CF
Cumulative relative
frequency
350-
400 6 0.072289157 6 0.072289157
400-
450 12 0.144578313 18 0.21686747
450-
500 25 0.301204819 43 0.518072289
500-
550 14 0.168674699 57 0.686746988
550-
600 12 0.144578313 69 0.831325301
600-
650 10 0.120481928 79 0.951807229
650-
700` 4 0.048192771 83 1
83
3 | P a g e
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
350-400 400-450 450-500 500-550 550-600 600-650 650-700`
0
0.2
0.4
0.6
0.8
1
1.2
0.07228915662650
6
0.21686746987951
8
0.51807228915662
7
0.68674698795180
7
0.83132530120481
9
0.95180722891566
3
1
Chart Title
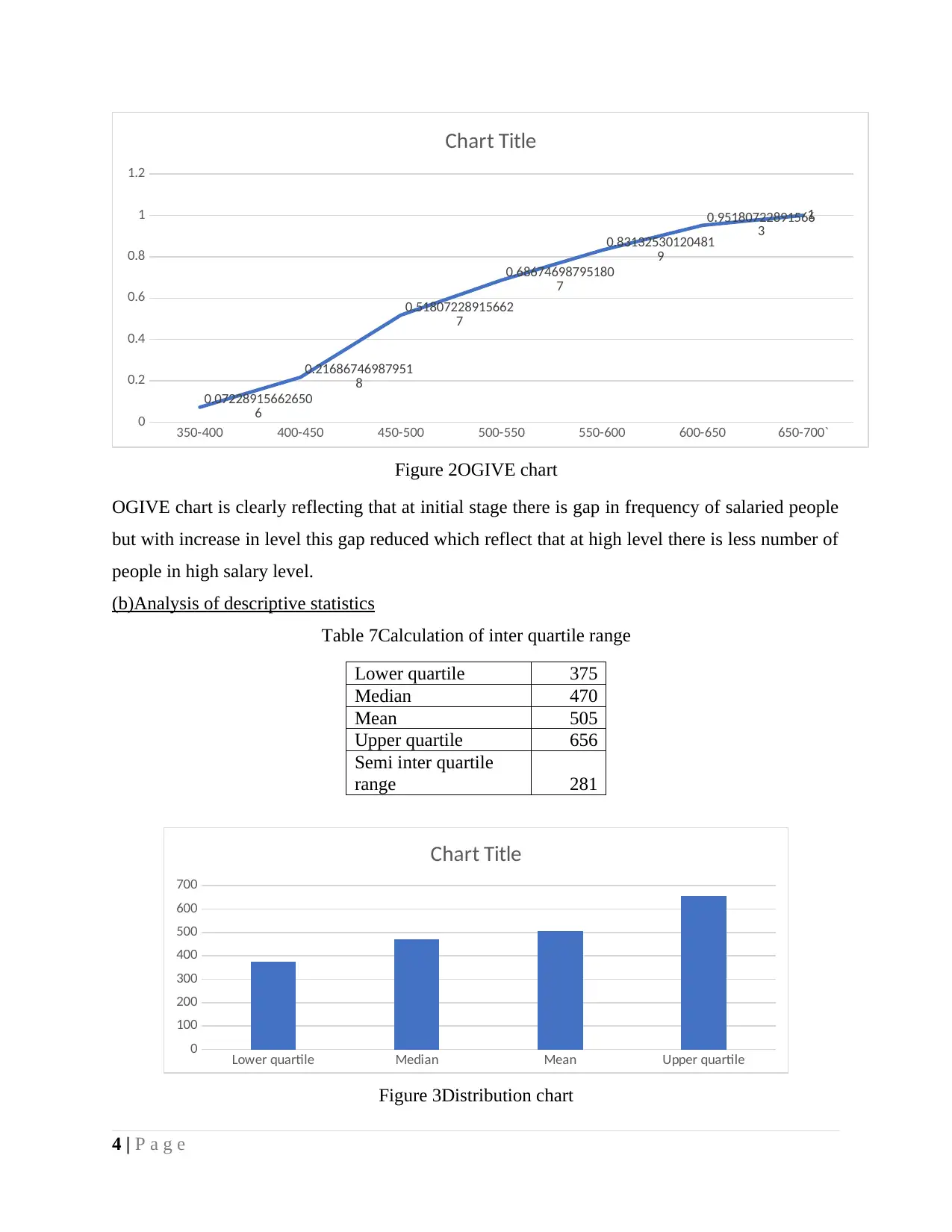
Figure 2OGIVE chart
OGIVE chart is clearly reflecting that at initial stage there is gap in frequency of salaried people
but with increase in level this gap reduced which reflect that at high level there is less number of
people in high salary level.
(b)Analysis of descriptive statistics
Table 7Calculation of inter quartile range
Lower quartile 375
Median 470
Mean 505
Upper quartile 656
Semi inter quartile
range 281
Lower quartile Median Mean Upper quartile
0
100
200
300
400
500
600
700
Chart Title
Figure 3Distribution chart
4 | P a g e
0
0.2
0.4
0.6
0.8
1
1.2
0.07228915662650
6
0.21686746987951
8
0.51807228915662
7
0.68674698795180
7
0.83132530120481
9
0.95180722891566
3
1
Chart Title
Figure 2OGIVE chart
OGIVE chart is clearly reflecting that at initial stage there is gap in frequency of salaried people
but with increase in level this gap reduced which reflect that at high level there is less number of
people in high salary level.
(b)Analysis of descriptive statistics
Table 7Calculation of inter quartile range
Lower quartile 375
Median 470
Mean 505
Upper quartile 656
Semi inter quartile
range 281
Lower quartile Median Mean Upper quartile
0
100
200
300
400
500
600
700
Chart Title
Figure 3Distribution chart
4 | P a g e
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
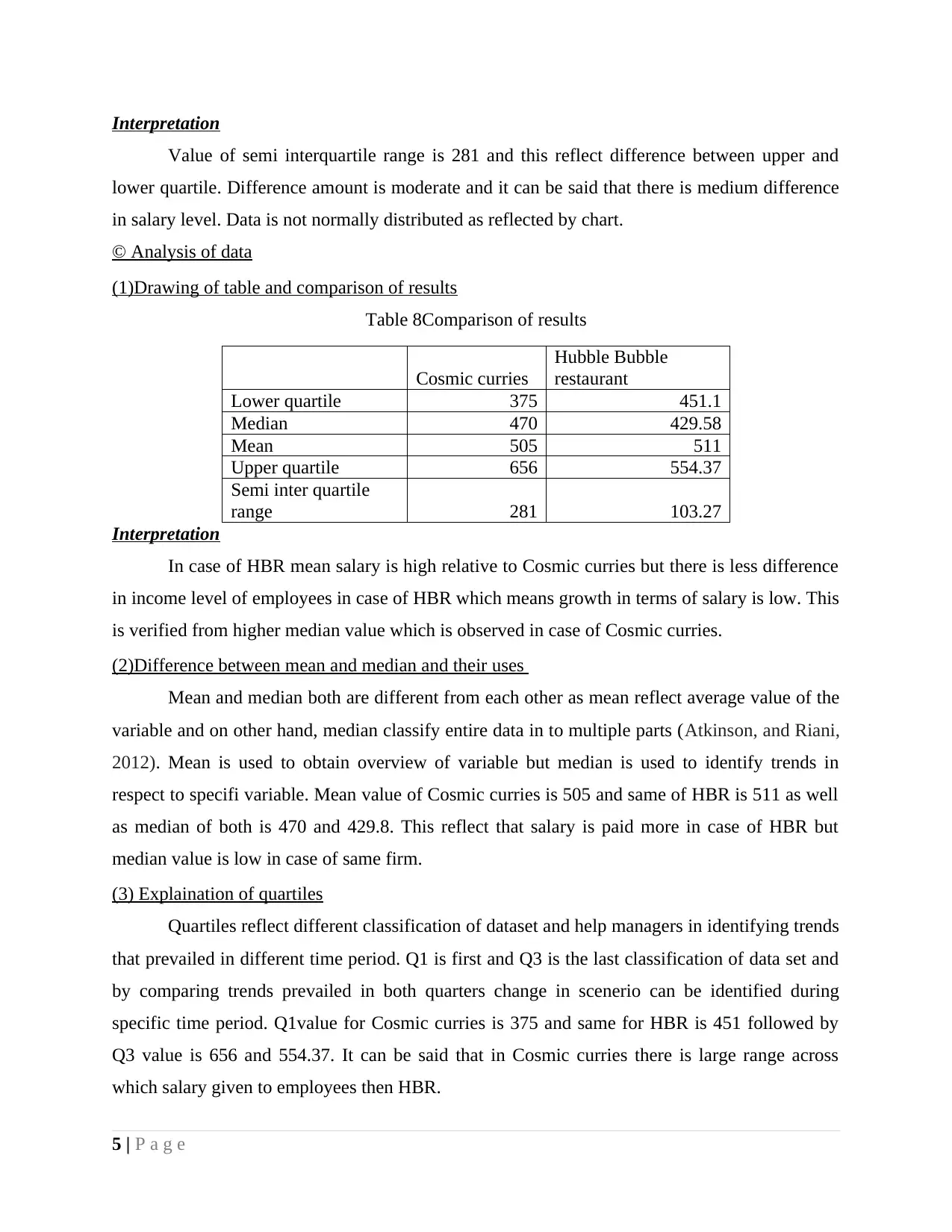
Interpretation
Value of semi interquartile range is 281 and this reflect difference between upper and
lower quartile. Difference amount is moderate and it can be said that there is medium difference
in salary level. Data is not normally distributed as reflected by chart.
© Analysis of data
(1)Drawing of table and comparison of results
Table 8Comparison of results
Cosmic curries
Hubble Bubble
restaurant
Lower quartile 375 451.1
Median 470 429.58
Mean 505 511
Upper quartile 656 554.37
Semi inter quartile
range 281 103.27
Interpretation
In case of HBR mean salary is high relative to Cosmic curries but there is less difference
in income level of employees in case of HBR which means growth in terms of salary is low. This
is verified from higher median value which is observed in case of Cosmic curries.
(2)Difference between mean and median and their uses
Mean and median both are different from each other as mean reflect average value of the
variable and on other hand, median classify entire data in to multiple parts (Atkinson, and Riani,
2012). Mean is used to obtain overview of variable but median is used to identify trends in
respect to specifi variable. Mean value of Cosmic curries is 505 and same of HBR is 511 as well
as median of both is 470 and 429.8. This reflect that salary is paid more in case of HBR but
median value is low in case of same firm.
(3) Explaination of quartiles
Quartiles reflect different classification of dataset and help managers in identifying trends
that prevailed in different time period. Q1 is first and Q3 is the last classification of data set and
by comparing trends prevailed in both quarters change in scenerio can be identified during
specific time period. Q1value for Cosmic curries is 375 and same for HBR is 451 followed by
Q3 value is 656 and 554.37. It can be said that in Cosmic curries there is large range across
which salary given to employees then HBR.
5 | P a g e
Value of semi interquartile range is 281 and this reflect difference between upper and
lower quartile. Difference amount is moderate and it can be said that there is medium difference
in salary level. Data is not normally distributed as reflected by chart.
© Analysis of data
(1)Drawing of table and comparison of results
Table 8Comparison of results
Cosmic curries
Hubble Bubble
restaurant
Lower quartile 375 451.1
Median 470 429.58
Mean 505 511
Upper quartile 656 554.37
Semi inter quartile
range 281 103.27
Interpretation
In case of HBR mean salary is high relative to Cosmic curries but there is less difference
in income level of employees in case of HBR which means growth in terms of salary is low. This
is verified from higher median value which is observed in case of Cosmic curries.
(2)Difference between mean and median and their uses
Mean and median both are different from each other as mean reflect average value of the
variable and on other hand, median classify entire data in to multiple parts (Atkinson, and Riani,
2012). Mean is used to obtain overview of variable but median is used to identify trends in
respect to specifi variable. Mean value of Cosmic curries is 505 and same of HBR is 511 as well
as median of both is 470 and 429.8. This reflect that salary is paid more in case of HBR but
median value is low in case of same firm.
(3) Explaination of quartiles
Quartiles reflect different classification of dataset and help managers in identifying trends
that prevailed in different time period. Q1 is first and Q3 is the last classification of data set and
by comparing trends prevailed in both quarters change in scenerio can be identified during
specific time period. Q1value for Cosmic curries is 375 and same for HBR is 451 followed by
Q3 value is 656 and 554.37. It can be said that in Cosmic curries there is large range across
which salary given to employees then HBR.
5 | P a g e
(4) Additional information required
Information of mode is additionally required because by using same it can be identified
that what salary amount is frequently given to employees (Bel, Fageda and Warner, 2010). It
would be useful in analysis because it will reflect salary amount that is received by multiuple
employees in both restaurants and this will lead to better comparison among both.
(5) Comparison of standard deviation
Standard deviation for Cosmic Curries restaurant is 17890 and same for HBR is 110
which reflect that in case of former restaurant deviation takes at fast place in salary level then in
case of HBR. Higher standard deviation reflect that salary is laregely disributed in case of CC
restaurant then HBR.
Question 2
(a)
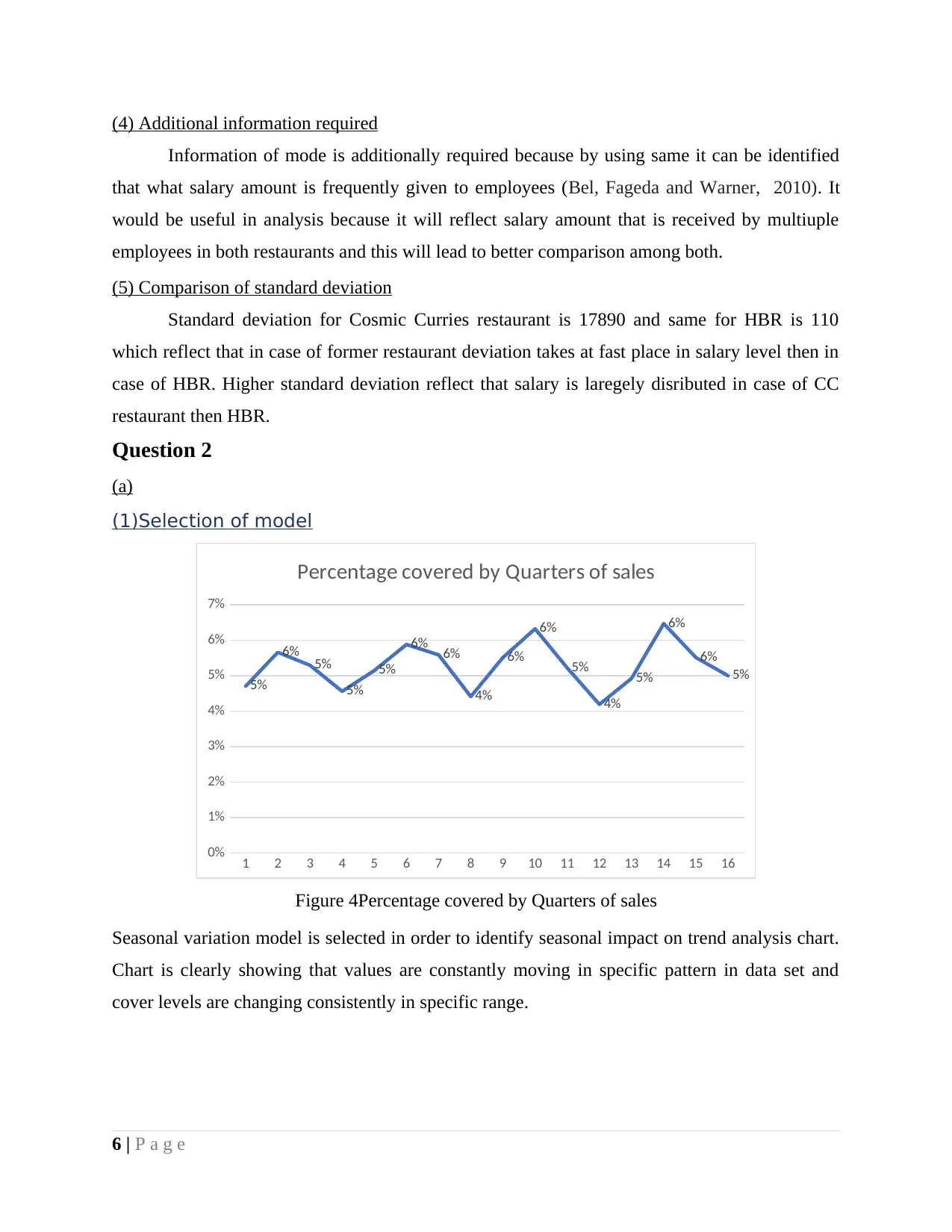
(1)Selection of model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%
Percentage covered by Quarters of sales
Figure 4Percentage covered by Quarters of sales
Seasonal variation model is selected in order to identify seasonal impact on trend analysis chart.
Chart is clearly showing that values are constantly moving in specific pattern in data set and
cover levels are changing consistently in specific range.
6 | P a g e
Information of mode is additionally required because by using same it can be identified
that what salary amount is frequently given to employees (Bel, Fageda and Warner, 2010). It
would be useful in analysis because it will reflect salary amount that is received by multiuple
employees in both restaurants and this will lead to better comparison among both.
(5) Comparison of standard deviation
Standard deviation for Cosmic Curries restaurant is 17890 and same for HBR is 110
which reflect that in case of former restaurant deviation takes at fast place in salary level then in
case of HBR. Higher standard deviation reflect that salary is laregely disributed in case of CC
restaurant then HBR.
Question 2
(a)
(1)Selection of model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%
Percentage covered by Quarters of sales
Figure 4Percentage covered by Quarters of sales
Seasonal variation model is selected in order to identify seasonal impact on trend analysis chart.
Chart is clearly showing that values are constantly moving in specific pattern in data set and
cover levels are changing consistently in specific range.
6 | P a g e
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
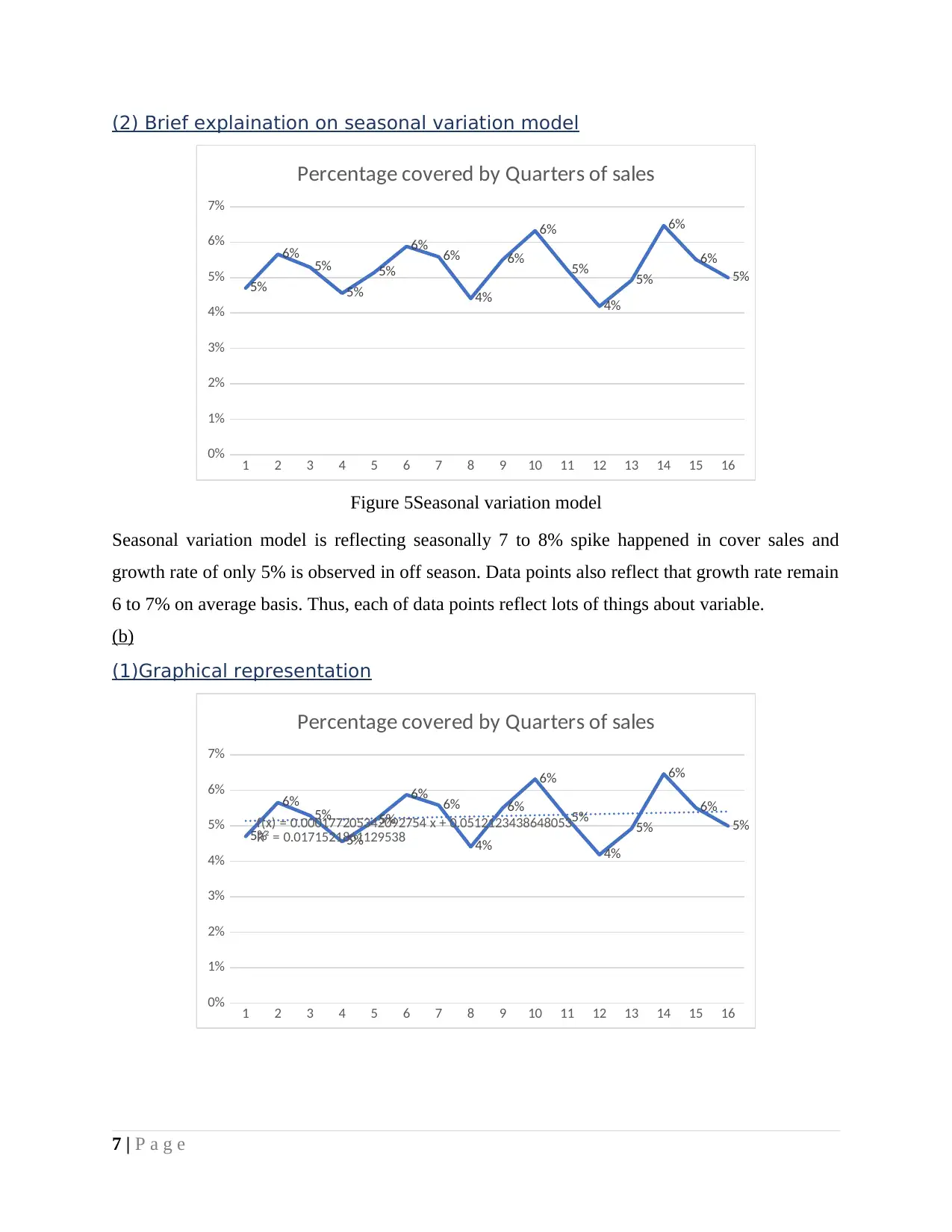
(2) Brief explaination on seasonal variation model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%
Percentage covered by Quarters of sales
Figure 5Seasonal variation model
Seasonal variation model is reflecting seasonally 7 to 8% spike happened in cover sales and
growth rate of only 5% is observed in off season. Data points also reflect that growth rate remain
6 to 7% on average basis. Thus, each of data points reflect lots of things about variable.
(b)
(1)Graphical representation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%f(x) = 0.000177205342092754 x + 0.0512123438648053
R² = 0.0171521861129538
Percentage covered by Quarters of sales
7 | P a g e
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%
Percentage covered by Quarters of sales
Figure 5Seasonal variation model
Seasonal variation model is reflecting seasonally 7 to 8% spike happened in cover sales and
growth rate of only 5% is observed in off season. Data points also reflect that growth rate remain
6 to 7% on average basis. Thus, each of data points reflect lots of things about variable.
(b)
(1)Graphical representation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0%
1%
2%
3%
4%
5%
6%
7%
5%
6% 5%
5%
5%
6% 6%
4%
6%
6%
5%
4%
5%
6%
6%
5%f(x) = 0.000177205342092754 x + 0.0512123438648053
R² = 0.0171521861129538
Percentage covered by Quarters of sales
7 | P a g e
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
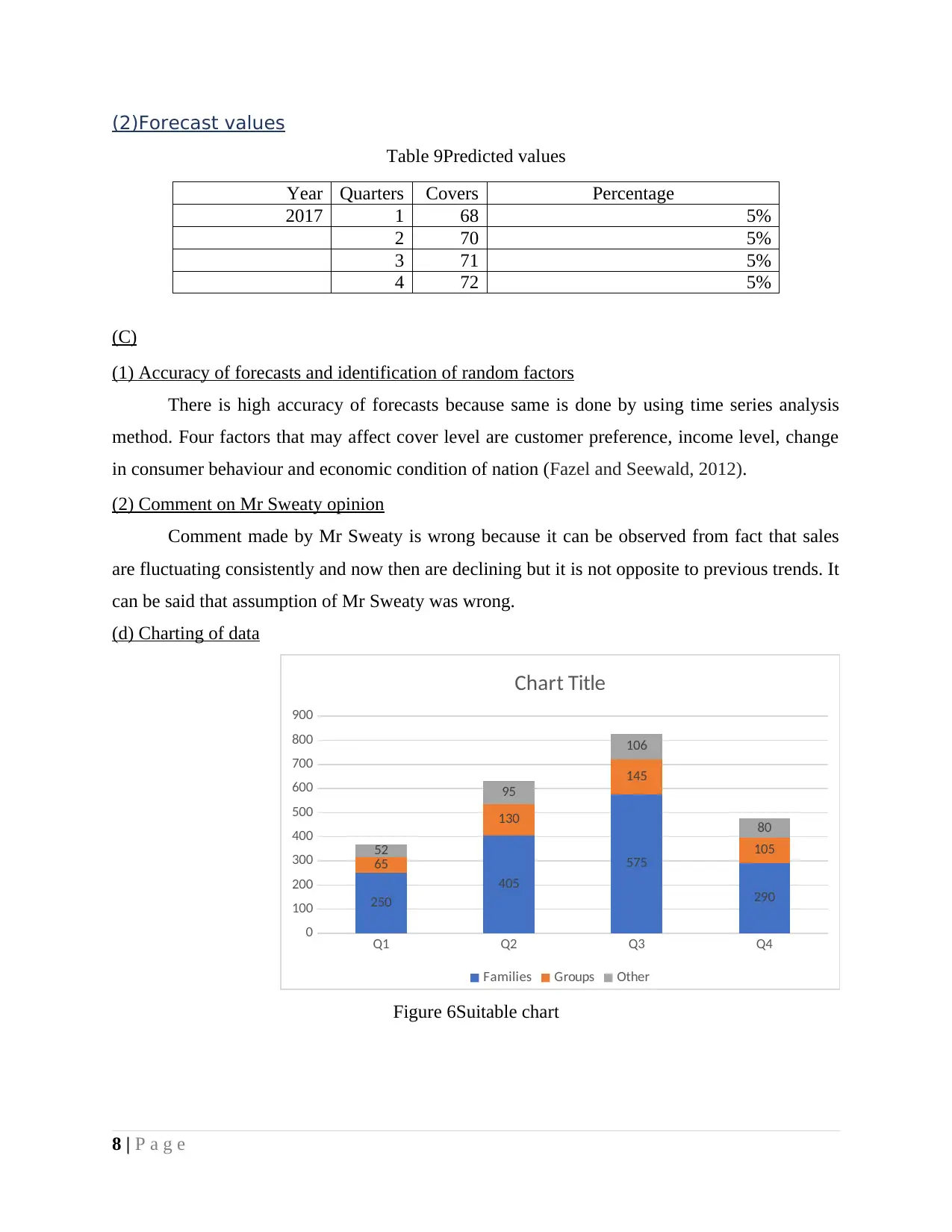
(2)Forecast values
Table 9Predicted values
Year Quarters Covers Percentage
2017 1 68 5%
2 70 5%
3 71 5%
4 72 5%
(C)
(1) Accuracy of forecasts and identification of random factors
There is high accuracy of forecasts because same is done by using time series analysis
method. Four factors that may affect cover level are customer preference, income level, change
in consumer behaviour and economic condition of nation (Fazel and Seewald, 2012).
(2) Comment on Mr Sweaty opinion
Comment made by Mr Sweaty is wrong because it can be observed from fact that sales
are fluctuating consistently and now then are declining but it is not opposite to previous trends. It
can be said that assumption of Mr Sweaty was wrong.
(d) Charting of data
Q1 Q2 Q3 Q4
0
100
200
300
400
500
600
700
800
900
250
405
575
290
65
130
145
10552
95
106
80
Chart Title
Families Groups Other
Figure 6Suitable chart
8 | P a g e
Table 9Predicted values
Year Quarters Covers Percentage
2017 1 68 5%
2 70 5%
3 71 5%
4 72 5%
(C)
(1) Accuracy of forecasts and identification of random factors
There is high accuracy of forecasts because same is done by using time series analysis
method. Four factors that may affect cover level are customer preference, income level, change
in consumer behaviour and economic condition of nation (Fazel and Seewald, 2012).
(2) Comment on Mr Sweaty opinion
Comment made by Mr Sweaty is wrong because it can be observed from fact that sales
are fluctuating consistently and now then are declining but it is not opposite to previous trends. It
can be said that assumption of Mr Sweaty was wrong.
(d) Charting of data
Q1 Q2 Q3 Q4
0
100
200
300
400
500
600
700
800
900
250
405
575
290
65
130
145
10552
95
106
80
Chart Title
Families Groups Other
Figure 6Suitable chart
8 | P a g e
Q1 Q2 Q3 Q4
0
100
200
300
400
500
600
700
250
405
575
290
65
130 145 105
52 95 106 80
Chart Title
Families Groups Other
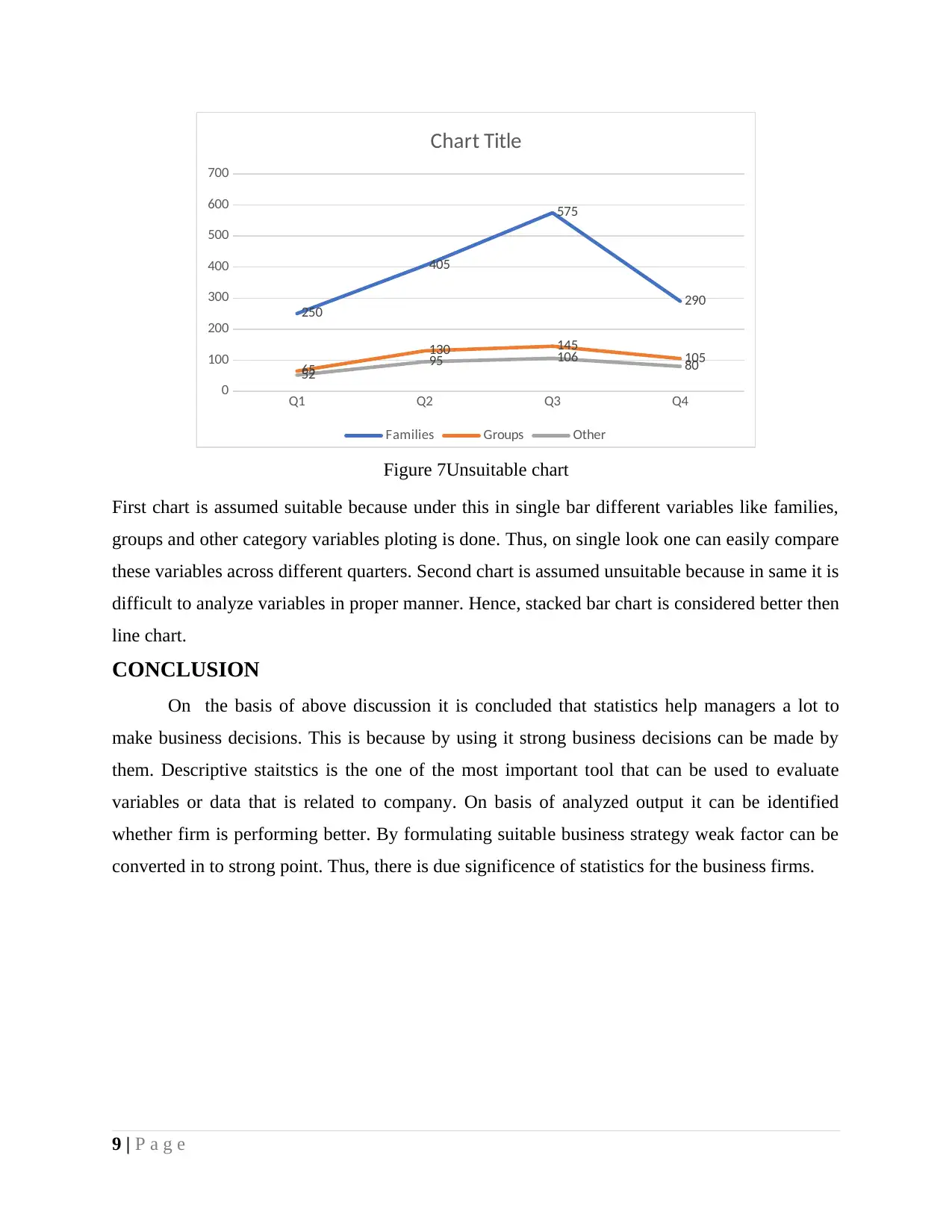
Figure 7Unsuitable chart
First chart is assumed suitable because under this in single bar different variables like families,
groups and other category variables ploting is done. Thus, on single look one can easily compare
these variables across different quarters. Second chart is assumed unsuitable because in same it is
difficult to analyze variables in proper manner. Hence, stacked bar chart is considered better then
line chart.
CONCLUSION
On the basis of above discussion it is concluded that statistics help managers a lot to
make business decisions. This is because by using it strong business decisions can be made by
them. Descriptive staitstics is the one of the most important tool that can be used to evaluate
variables or data that is related to company. On basis of analyzed output it can be identified
whether firm is performing better. By formulating suitable business strategy weak factor can be
converted in to strong point. Thus, there is due significence of statistics for the business firms.
9 | P a g e
0
100
200
300
400
500
600
700
250
405
575
290
65
130 145 105
52 95 106 80
Chart Title
Families Groups Other
Figure 7Unsuitable chart
First chart is assumed suitable because under this in single bar different variables like families,
groups and other category variables ploting is done. Thus, on single look one can easily compare
these variables across different quarters. Second chart is assumed unsuitable because in same it is
difficult to analyze variables in proper manner. Hence, stacked bar chart is considered better then
line chart.
CONCLUSION
On the basis of above discussion it is concluded that statistics help managers a lot to
make business decisions. This is because by using it strong business decisions can be made by
them. Descriptive staitstics is the one of the most important tool that can be used to evaluate
variables or data that is related to company. On basis of analyzed output it can be identified
whether firm is performing better. By formulating suitable business strategy weak factor can be
converted in to strong point. Thus, there is due significence of statistics for the business firms.
9 | P a g e
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 13
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.