An Overview of Distributed Data Warehouses and Discretization
VerifiedAdded on 2024/04/03
|13
|1476
|227
Report
AI Summary
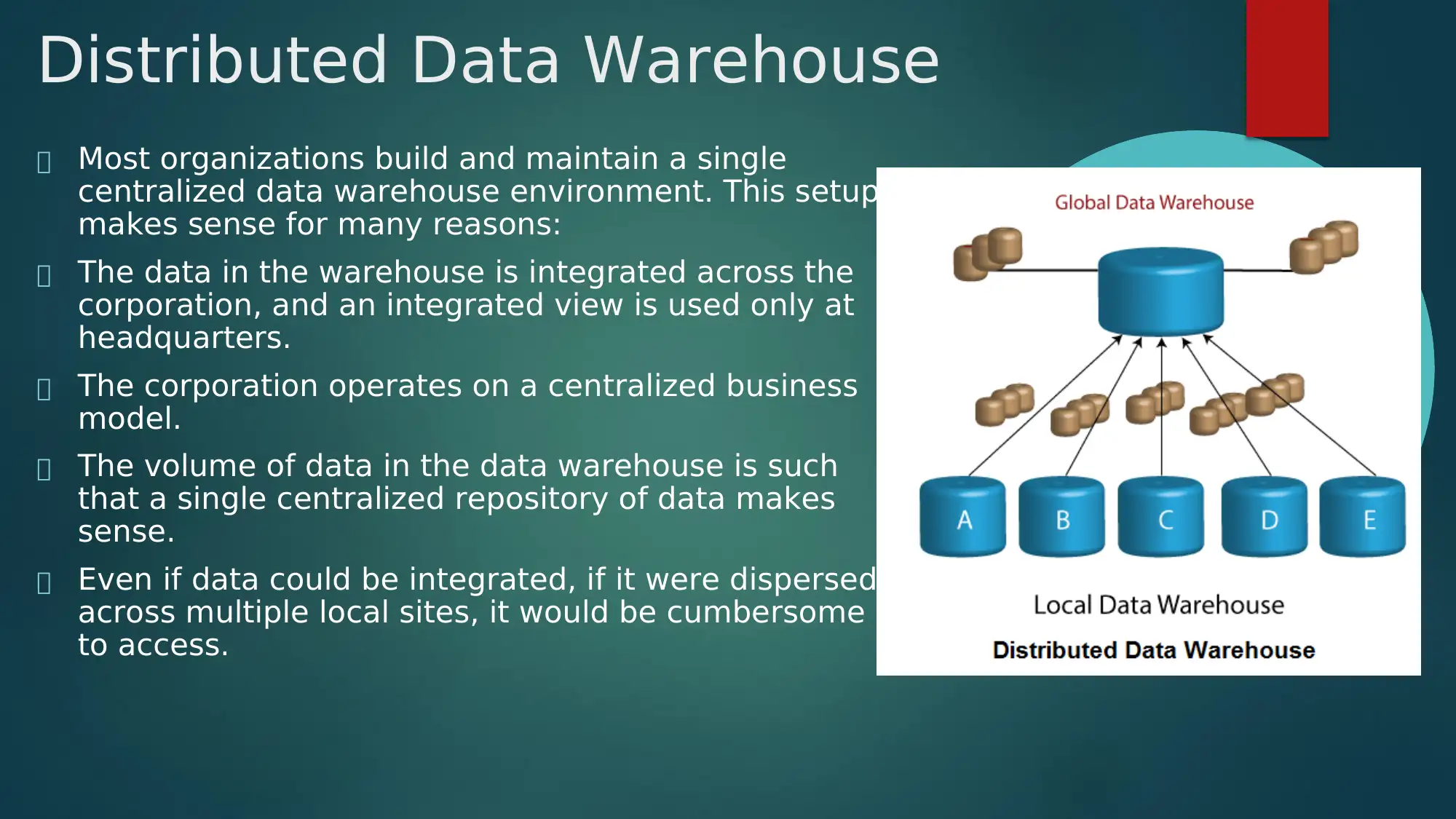
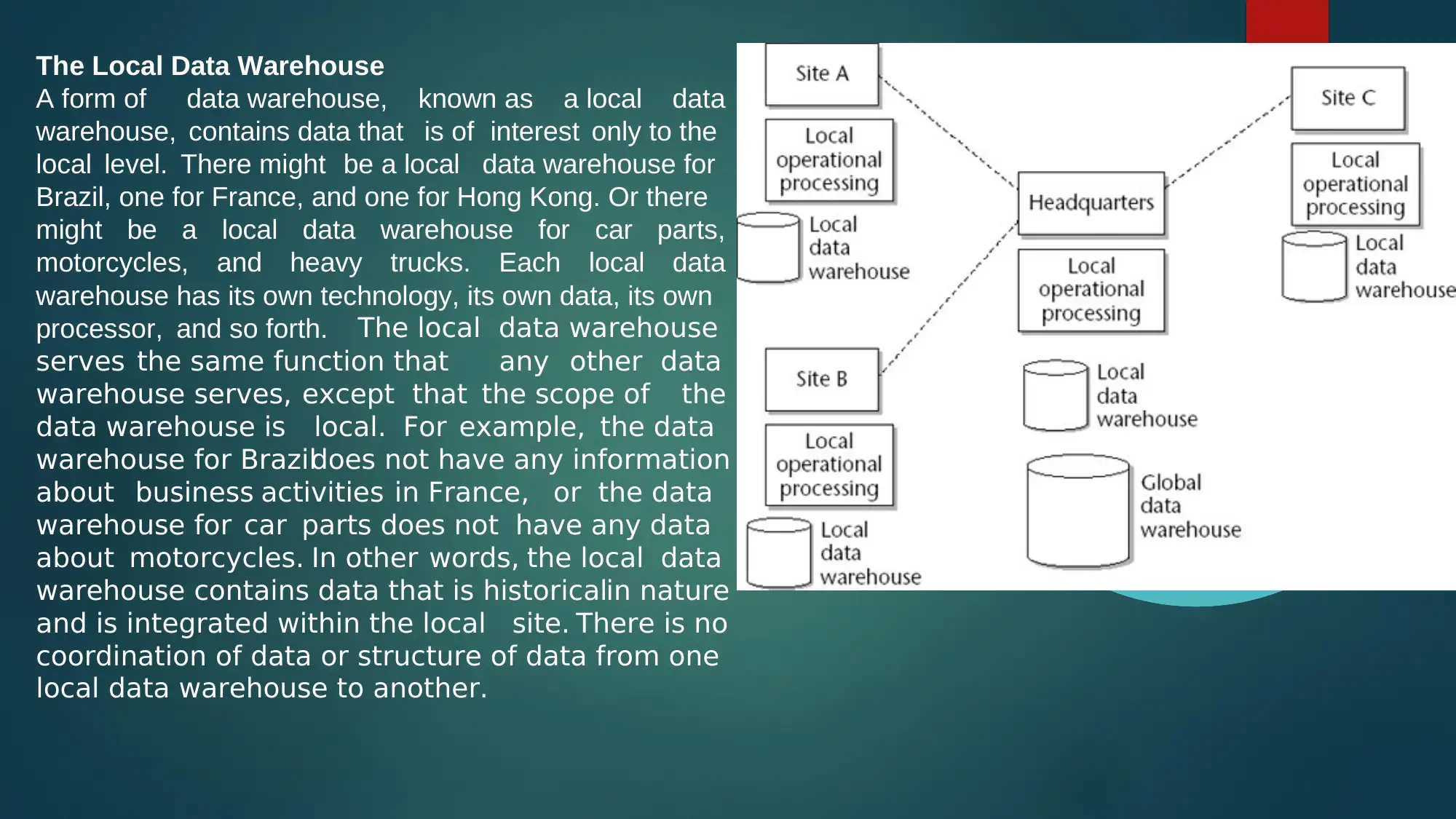
This report provides a comprehensive overview of distributed data warehouses, including local, global, and independently evolving types. It discusses the advantages and disadvantages of distributed data warehousing, focusing on the transfer of data between local and global environments. The report also delves into data discretization, explaining its purpose in converting continuous data into discrete intervals for improved data quality and reduced running time in data mining tasks. Key steps of discretization are outlined, along with an explanation of binning as a data smoothing technique, illustrated with an example of age discretization. The document is for informational purposes and Desklib provides access to similar solved assignments and past papers.










1 out of 13
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.