University Statistics Assignment: Australian Household Data Analysis
VerifiedAdded on 2020/02/24
|13
|1682
|124
Homework Assignment
AI Summary
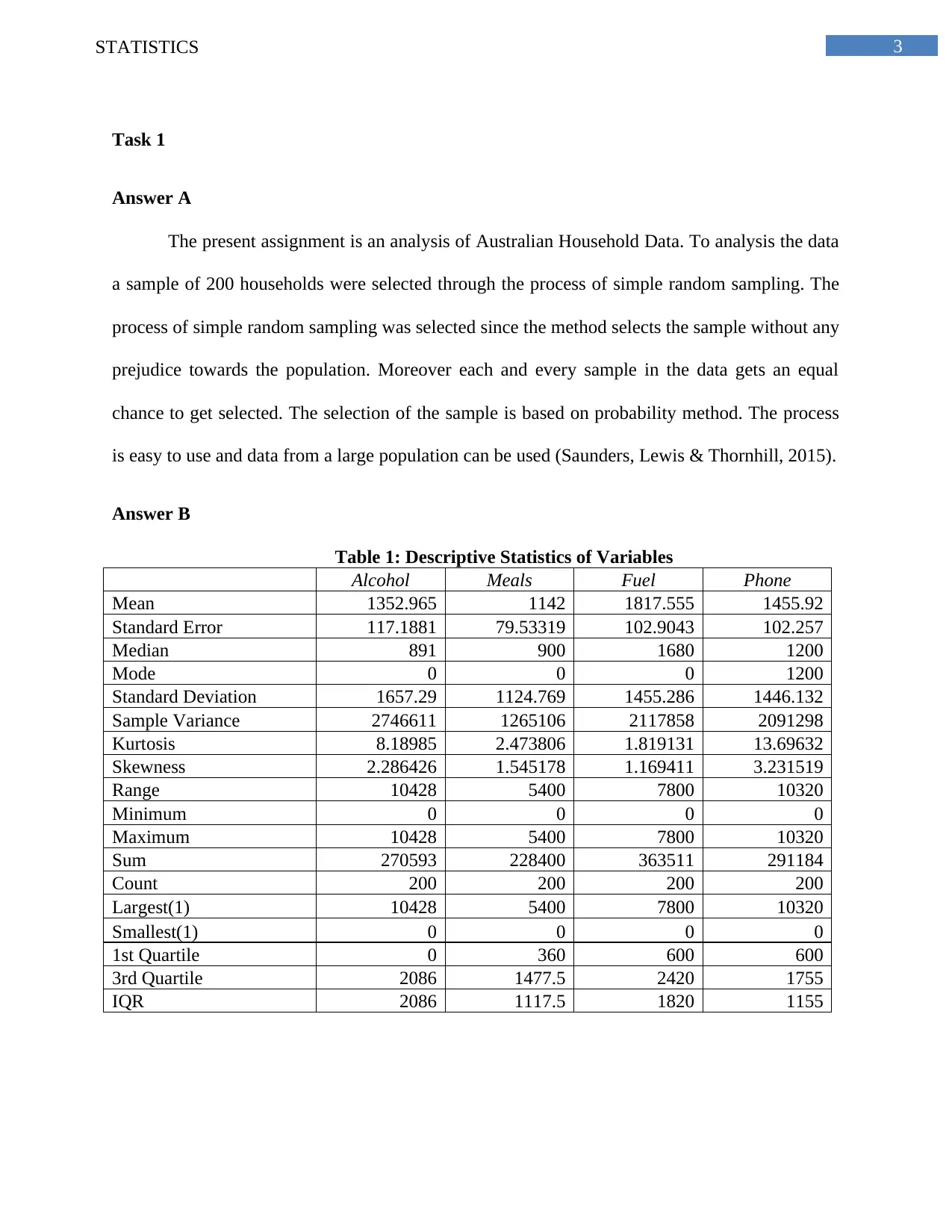
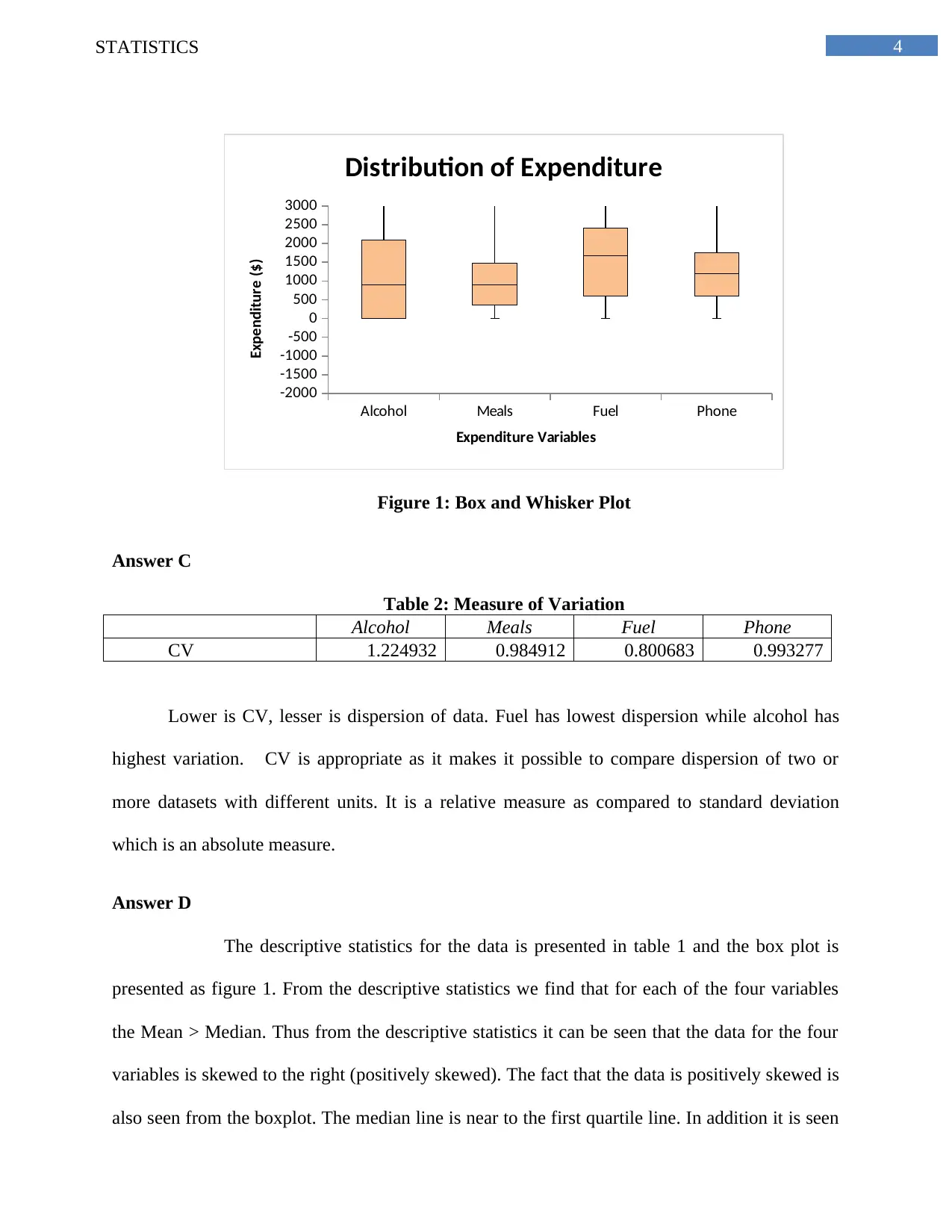
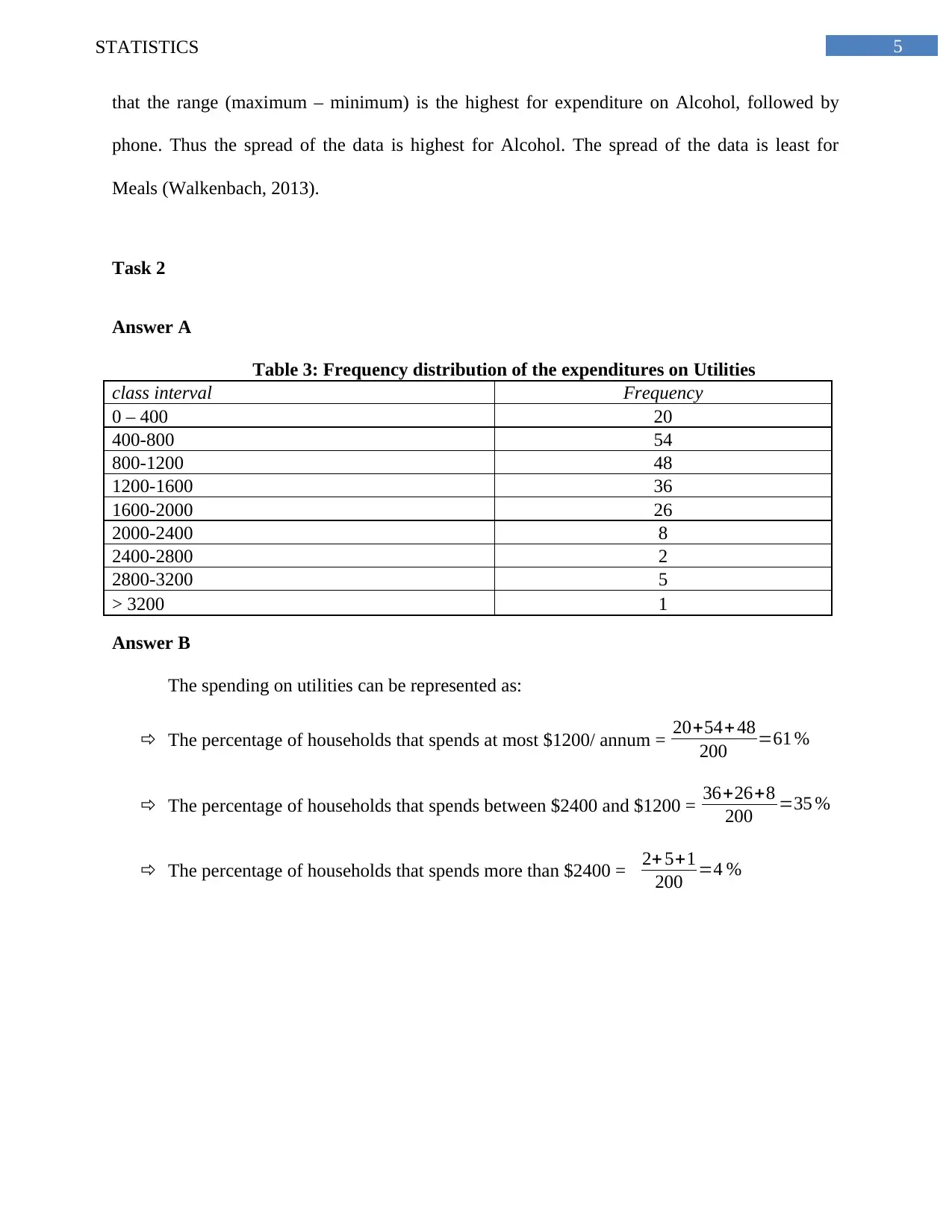
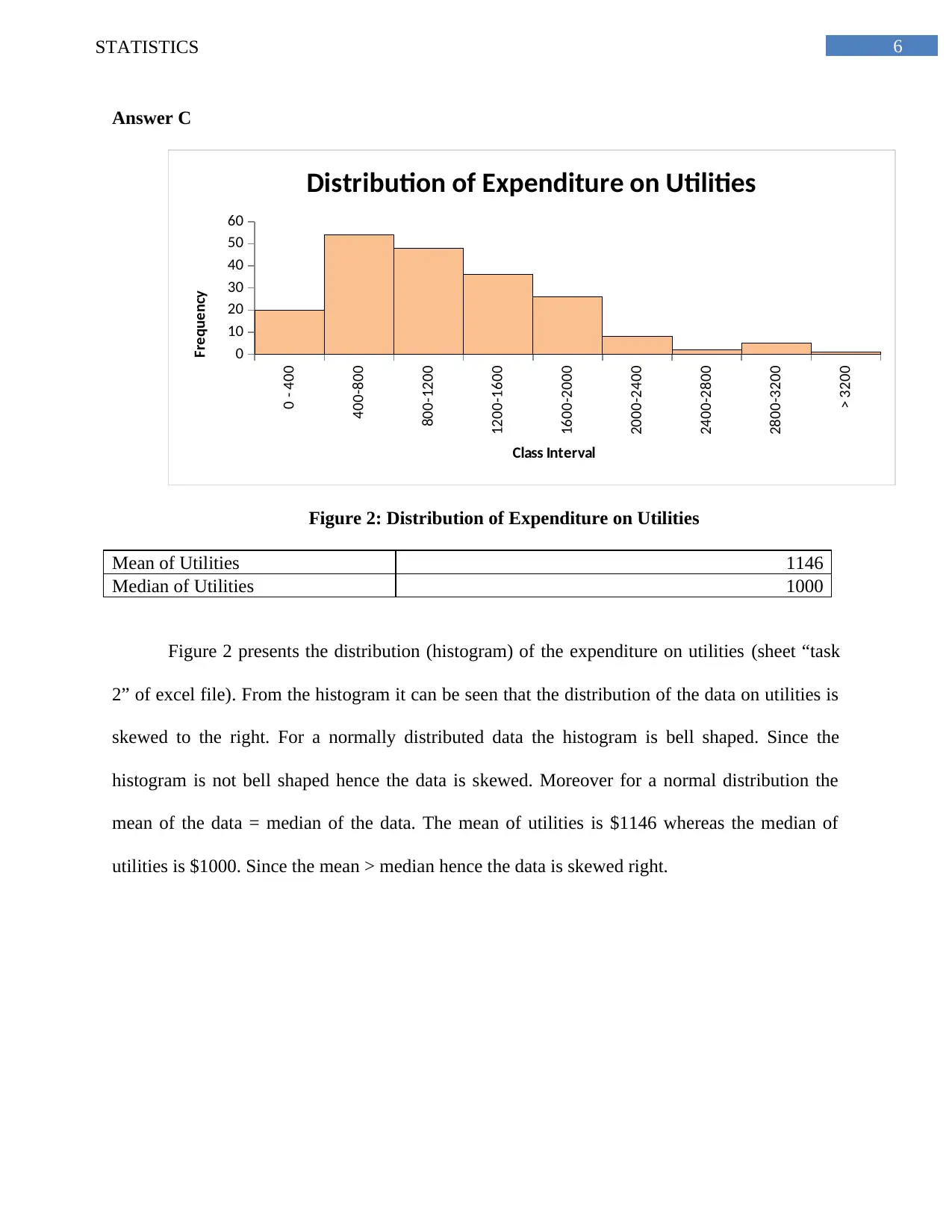
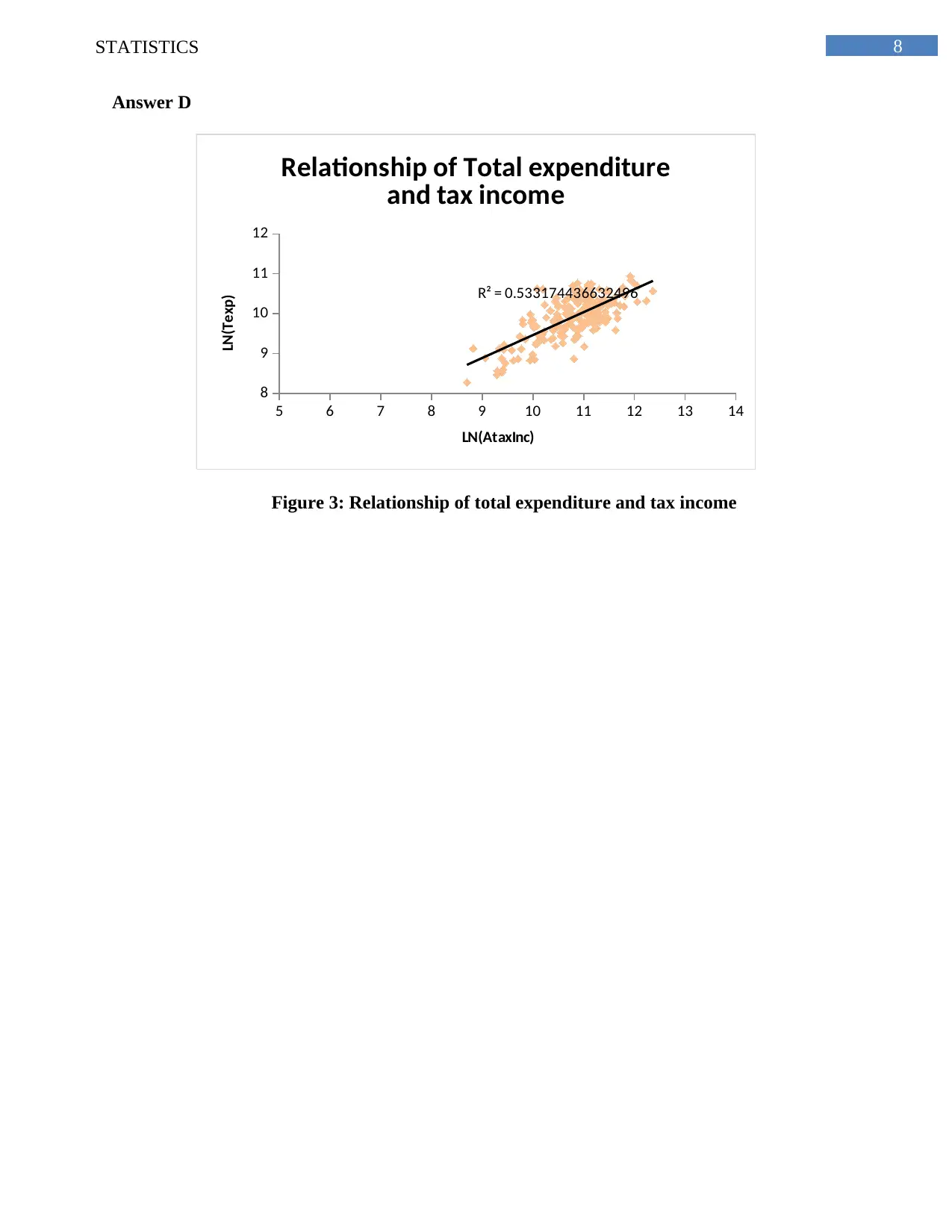
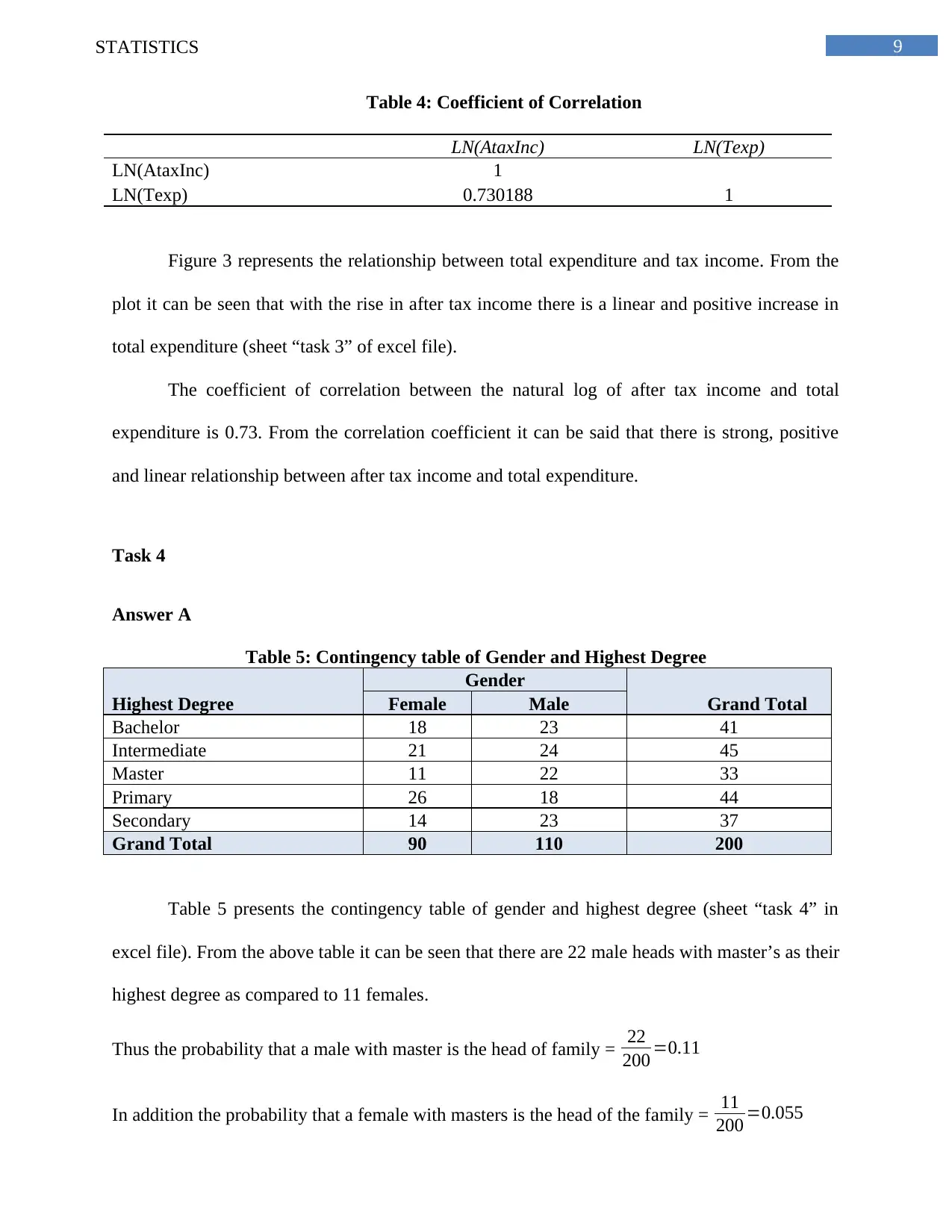
This statistics assignment analyzes Australian household data using various statistical methods. It begins with an analysis of a sample of 200 households, employing simple random sampling to ensure unbiased data selection. The assignment presents descriptive statistics, including measures of central tendency, dispersion, and skewness, for variables such as alcohol expenditure, meals, fuel, and phone expenses. The analysis includes frequency distributions of utility expenditures, calculating percentages of households within specific spending ranges and displaying the data using histograms to illustrate skewness. Further, the assignment explores household income, calculating percentiles to identify income distributions and determining the proportion of homeowners within the sample. It also examines the relationship between total expenditure and after-tax income using correlation coefficients and scatter plots. Finally, the assignment delves into contingency tables to analyze the relationship between gender and highest degree obtained by household heads, calculating probabilities and assessing the independence of events based on the provided data.






1 out of 13
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.