Business Quantitative Methods Assignment - Data and Probability
VerifiedAdded on 2022/12/30
|9
|1344
|46
Homework Assignment
AI Summary
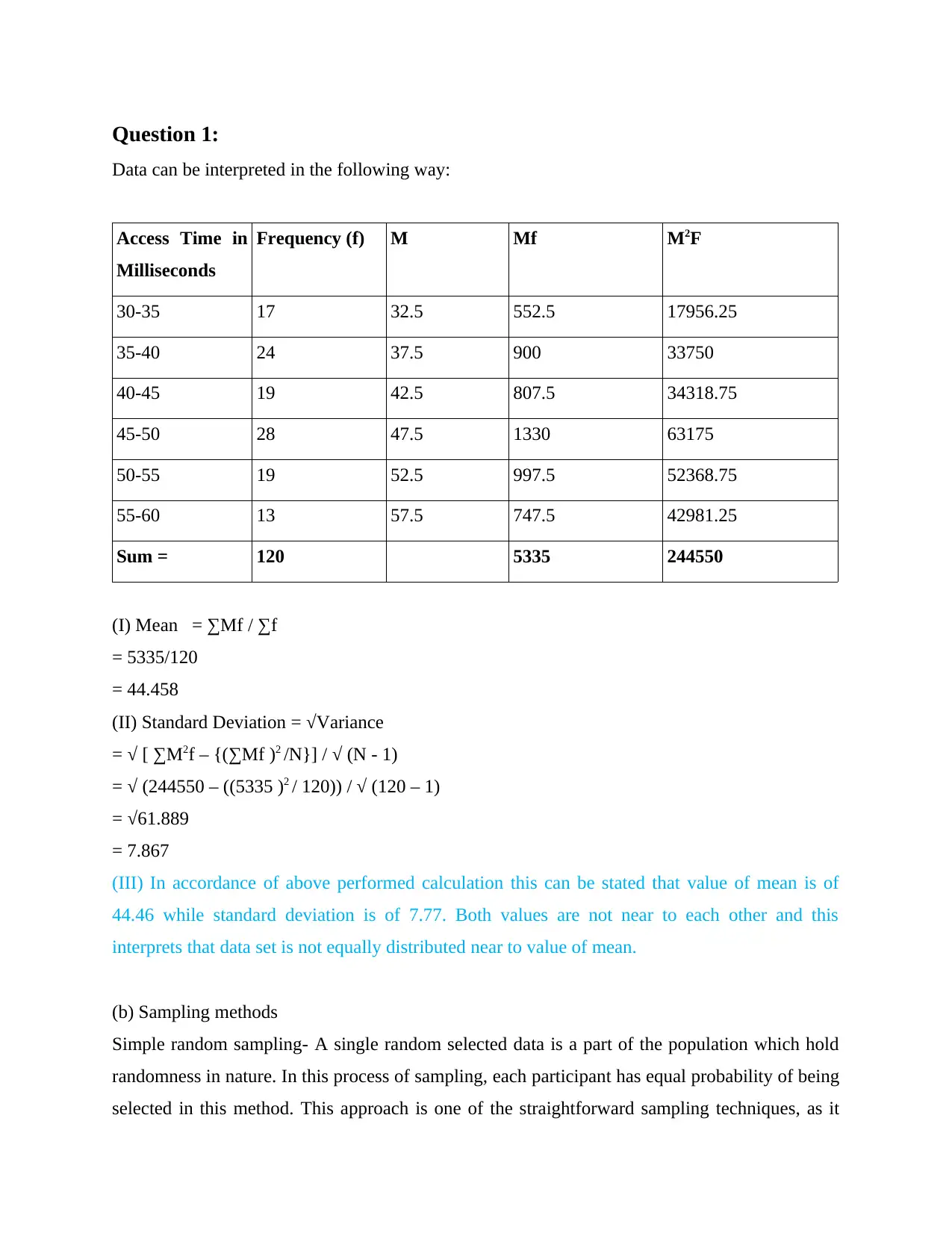
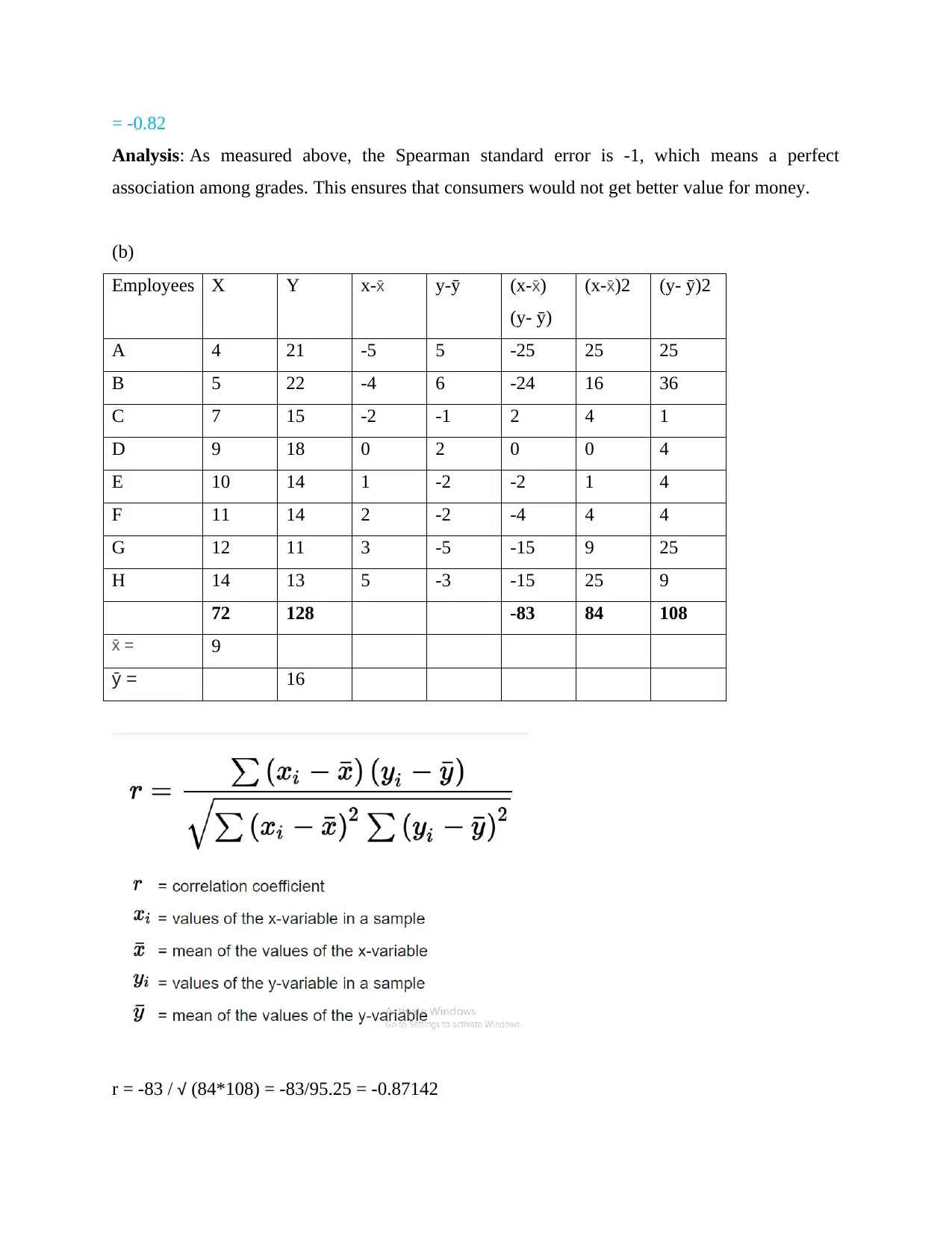
This document presents a comprehensive solution to a quantitative methods assignment, likely for a business or statistics course. The solution begins with data interpretation, calculating the mean and standard deviation from a frequency distribution table and discussing the implications of these values. It then delves into sampling methods, explaining simple random sampling, quota sampling, sample frames, cluster sampling, and systematic sampling. The assignment proceeds to probability calculations, determining the probability of events in different scenarios, including the probability of success and failure. Finally, the solution includes correlation analysis, calculating Spearman's rank correlation and analyzing the relationship between variables related to quality and price, as well as the correlation between employee preparation and refusal rates. The document provides detailed calculations and interpretations for each question.







1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.