Business Intelligence Project on Australian Weather Data using Rapid Miner and Data Warehouse Architecture Design
VerifiedAdded on 2022/11/13
|26
|4567
|302
AI Summary
This project analyzes Australian weather data using Rapid Miner and implements business intelligence in organization's systems and processes. It also researches relevant literature on data warehouse architecture design. The project consists of two tasks: Task 1 involves predicting rainfall using Rapid Miner and Task 2 involves researching data warehouse architecture design. Subject: Business Intelligence, Course Code: Not mentioned, Course Name: Not mentioned, College/University: Not mentioned.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

University
Semester
Business Intelligence
Student ID
Student Name
Submission Date
Semester
Business Intelligence
Student ID
Student Name
Submission Date
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Table of Contents
1. Project Description........................................................................................................................1
2. Task 1 - Rapid Miner.....................................................................................................................1
2.1 Exploratory Data Analysis on Weather AUS Data................................................................1
2.2 Decision Tree Model.............................................................................................................8
2.3 Logistic Regression Model..................................................................................................10
2.4 Final Decision Tree and Final Logistics Regression Models’ Validation............................11
3. Task 2 - Research the Relevant Literature...................................................................................12
3.1 Architecture Design of a High Level Data Warehouse........................................................12
3.2 Proposed High Level Data Warehouse Architecture Design’s Main Components...............15
3.3 Security Privacy and the Ethical Concerns..........................................................................19
References...........................................................................................................................................24
1. Project Description........................................................................................................................1
2. Task 1 - Rapid Miner.....................................................................................................................1
2.1 Exploratory Data Analysis on Weather AUS Data................................................................1
2.2 Decision Tree Model.............................................................................................................8
2.3 Logistic Regression Model..................................................................................................10
2.4 Final Decision Tree and Final Logistics Regression Models’ Validation............................11
3. Task 2 - Research the Relevant Literature...................................................................................12
3.1 Architecture Design of a High Level Data Warehouse........................................................12
3.2 Proposed High Level Data Warehouse Architecture Design’s Main Components...............15
3.3 Security Privacy and the Ethical Concerns..........................................................................19
References...........................................................................................................................................24

1. Project Description
This project's primary objective includes analyzing the provided data set by using the
Rapid Miner. The provided data set is based on Australian Weather data. This project applies
the business intelligence's implementation in organization's systems and in the business
processes. It identifies and solves the complex organizational problems practically and
creatively through the use of business intelligences. It also effectively addresses the real
world problems. This project is consists of three main tasks. In Task one, the likelihood of
rainfall for the next day's weather depending on today's weather conditions is predicted by
using the data mining tool like Rapid Miner which is used for analyzing and reporting to the
Australian weather data set. Here, the business understanding, data understanding, data
preparation, the CRISP DM data mining process’s modelling phase and evaluation phase will
be applied. In Task Two, the related literature on how the capabilities of big data analytics
can be implemented into a data warehouse architecture will be researched.
2. Task 1 - Rapid Miner
In task 1, the likelihood of rainfall for the next day depending on today’s weather
condition will be predicted by applying data preparation, data understanding, data modelling
and CRISP DM data mining process’s evaluation phases. Thus, the following steps are
followed for the prediction of weather:
First, we are exploratory data analysis on Australian Weather data.
Build a Decision Tree Model.
Build a Logistic Regression Model.
Validation on Final Decision Tree Model.
Validation on Logistic Regression Model.
2.1 Exploratory Data Analysis on Weather AUS Data
To exploratory data analysis on Australian weather data by using the Rapid Miner
which is used for understanding the characteristics of every single variable and their
relationships. It also addresses and describes the main characteristics of each variables in the
weather dataset like missing values, minimum values, maximum values, average, most
frequent values, invalid values, standard deviation and more. These are presented as below.
To exploratory provided Australian Weather data on Rapid Miner by using the below steps,
1
This project's primary objective includes analyzing the provided data set by using the
Rapid Miner. The provided data set is based on Australian Weather data. This project applies
the business intelligence's implementation in organization's systems and in the business
processes. It identifies and solves the complex organizational problems practically and
creatively through the use of business intelligences. It also effectively addresses the real
world problems. This project is consists of three main tasks. In Task one, the likelihood of
rainfall for the next day's weather depending on today's weather conditions is predicted by
using the data mining tool like Rapid Miner which is used for analyzing and reporting to the
Australian weather data set. Here, the business understanding, data understanding, data
preparation, the CRISP DM data mining process’s modelling phase and evaluation phase will
be applied. In Task Two, the related literature on how the capabilities of big data analytics
can be implemented into a data warehouse architecture will be researched.
2. Task 1 - Rapid Miner
In task 1, the likelihood of rainfall for the next day depending on today’s weather
condition will be predicted by applying data preparation, data understanding, data modelling
and CRISP DM data mining process’s evaluation phases. Thus, the following steps are
followed for the prediction of weather:
First, we are exploratory data analysis on Australian Weather data.
Build a Decision Tree Model.
Build a Logistic Regression Model.
Validation on Final Decision Tree Model.
Validation on Logistic Regression Model.
2.1 Exploratory Data Analysis on Weather AUS Data
To exploratory data analysis on Australian weather data by using the Rapid Miner
which is used for understanding the characteristics of every single variable and their
relationships. It also addresses and describes the main characteristics of each variables in the
weather dataset like missing values, minimum values, maximum values, average, most
frequent values, invalid values, standard deviation and more. These are presented as below.
To exploratory provided Australian Weather data on Rapid Miner by using the below steps,
1
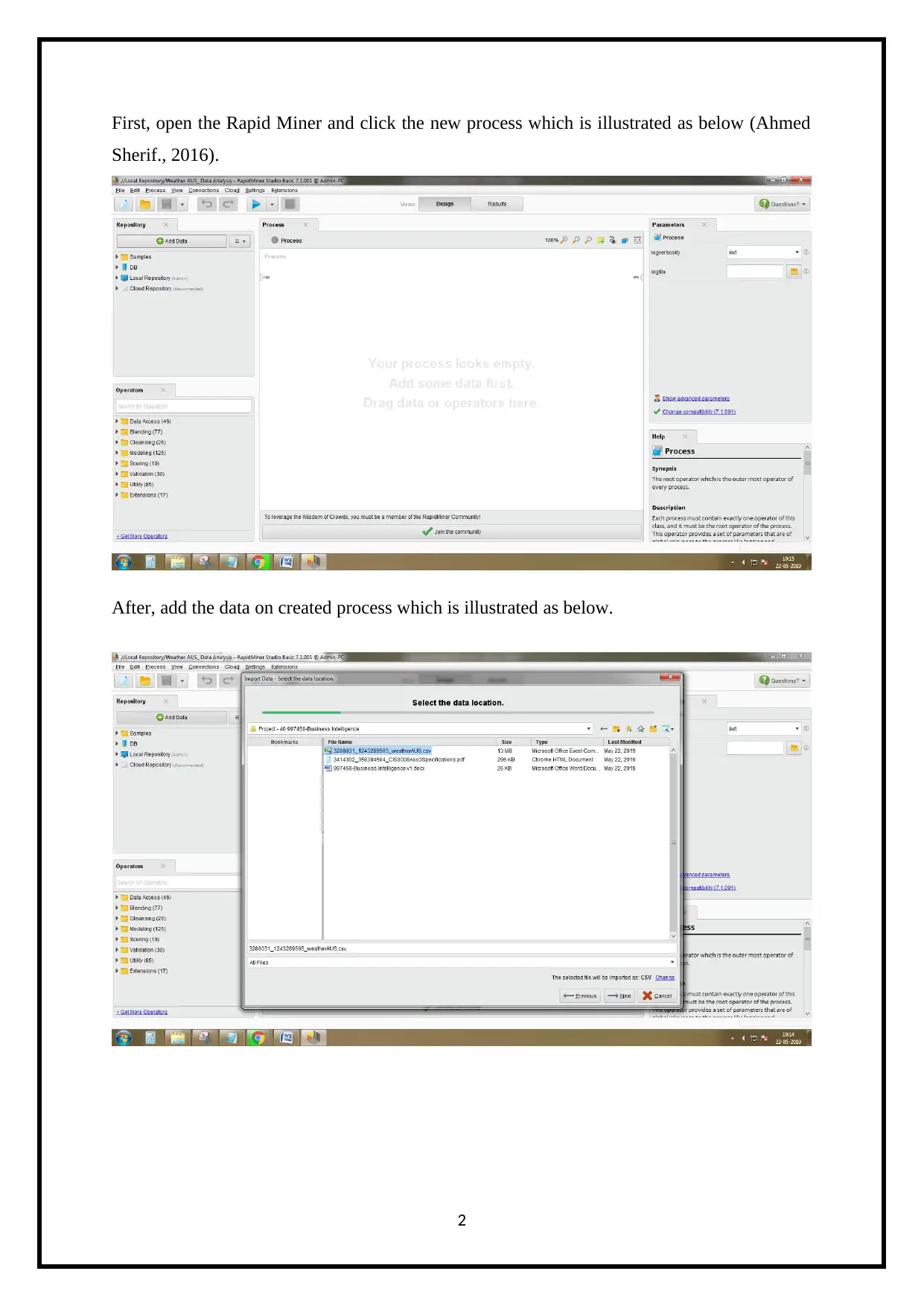
First, open the Rapid Miner and click the new process which is illustrated as below (Ahmed
Sherif., 2016).
After, add the data on created process which is illustrated as below.
2
Sherif., 2016).
After, add the data on created process which is illustrated as below.
2
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
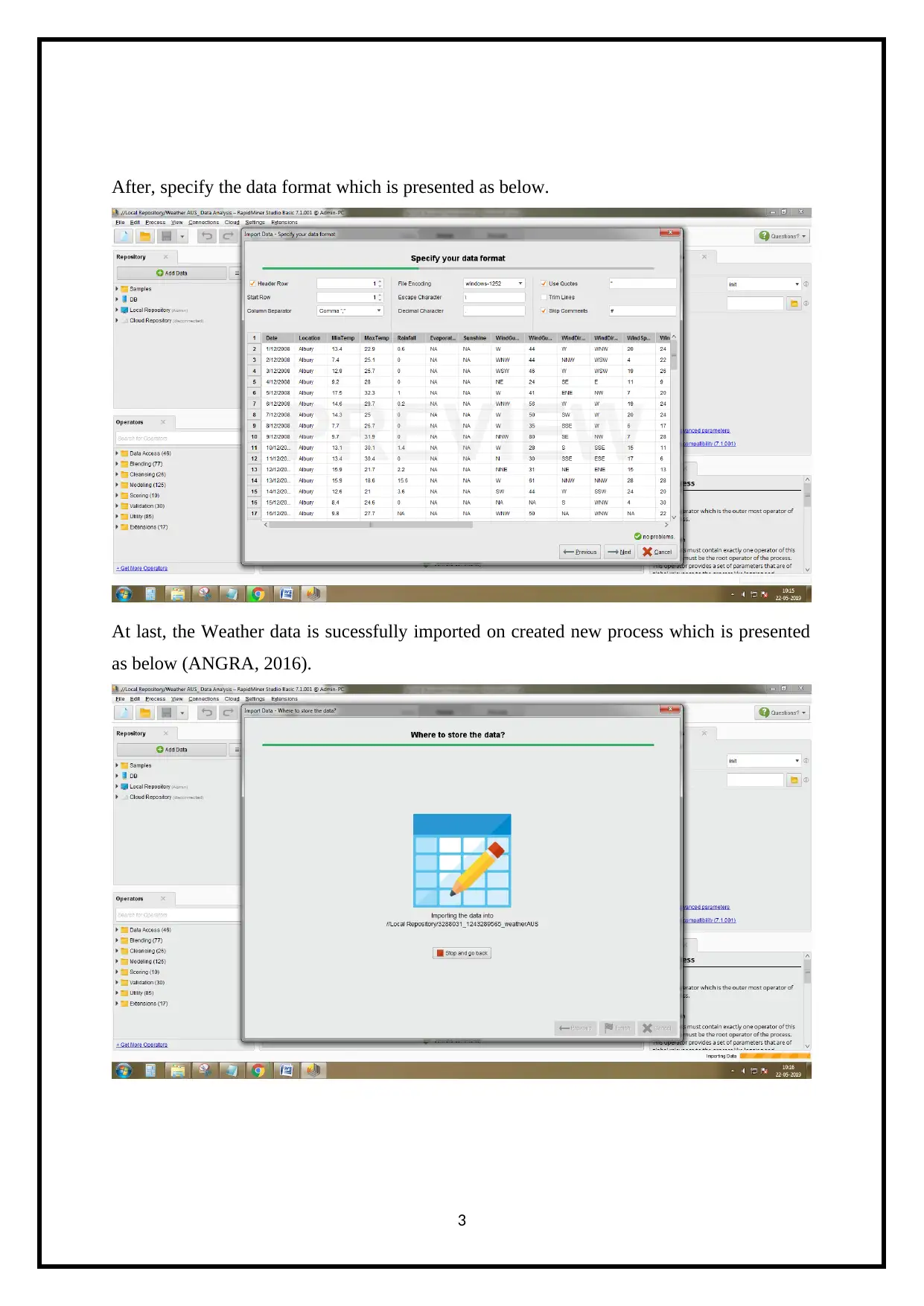
After, specify the data format which is presented as below.
At last, the Weather data is sucessfully imported on created new process which is presented
as below (ANGRA, 2016).
3
At last, the Weather data is sucessfully imported on created new process which is presented
as below (ANGRA, 2016).
3
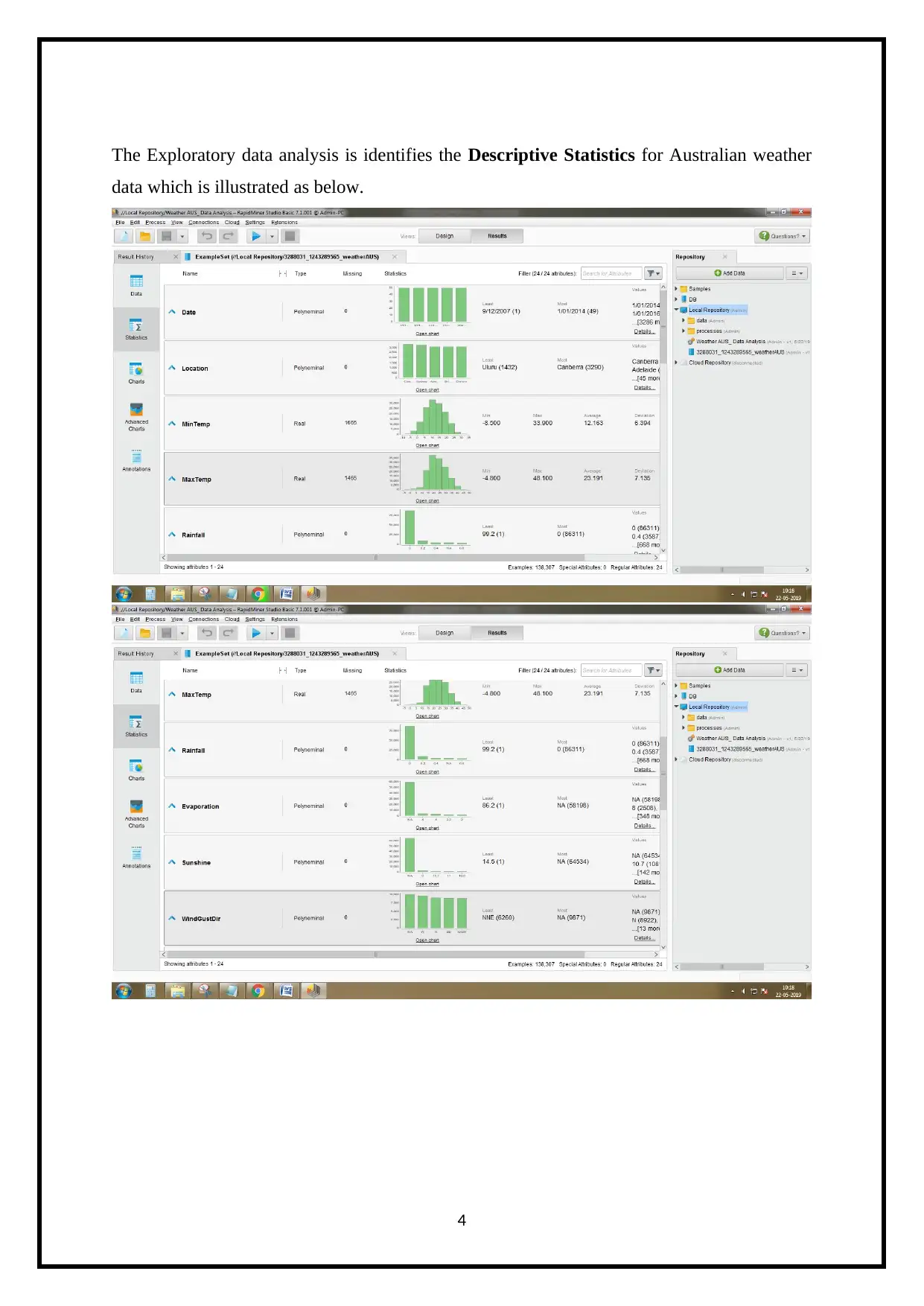
The Exploratory data analysis is identifies the Descriptive Statistics for Australian weather
data which is illustrated as below.
4
data which is illustrated as below.
4
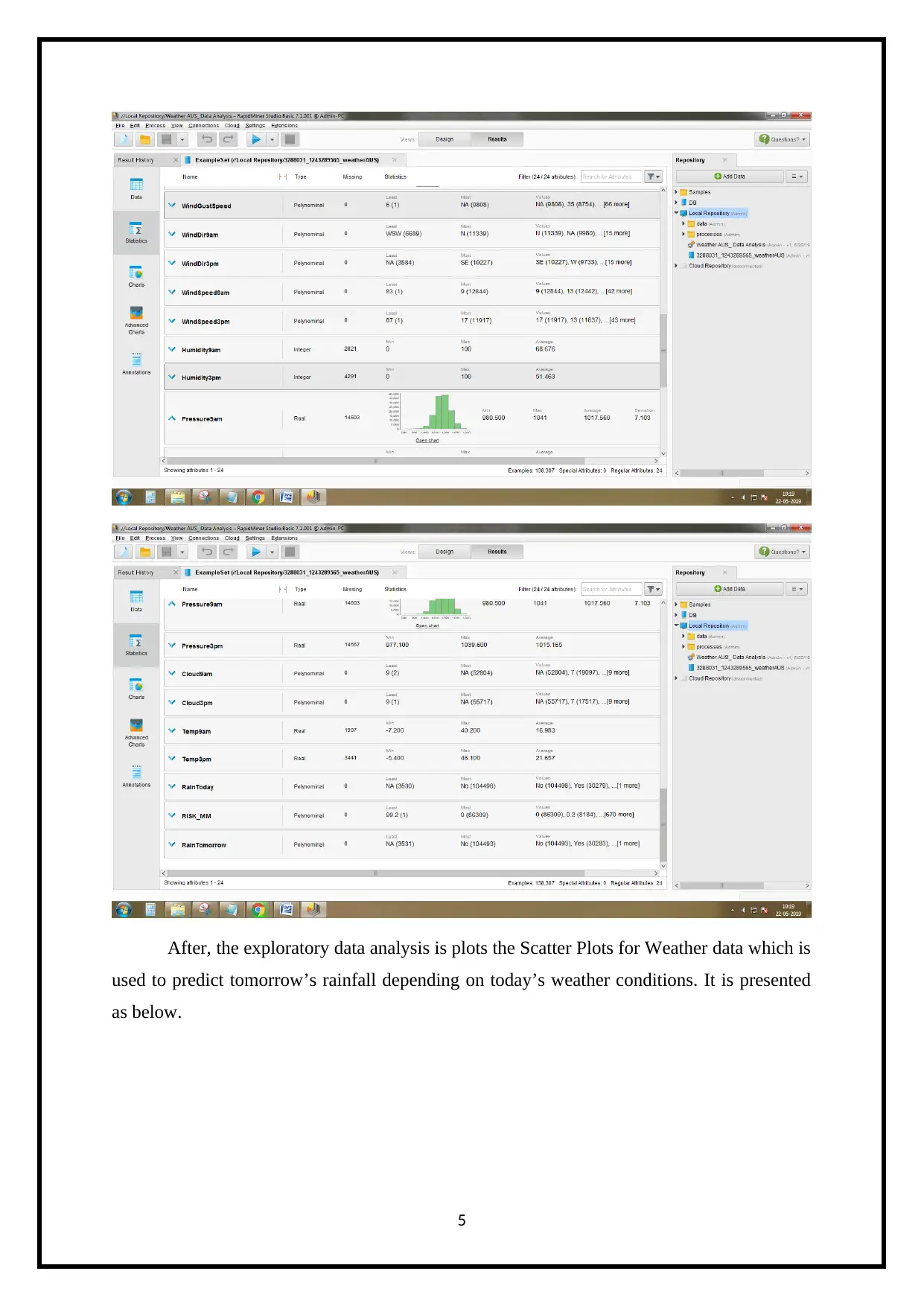
After, the exploratory data analysis is plots the Scatter Plots for Weather data which is
used to predict tomorrow’s rainfall depending on today’s weather conditions. It is presented
as below.
5
used to predict tomorrow’s rainfall depending on today’s weather conditions. It is presented
as below.
5
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
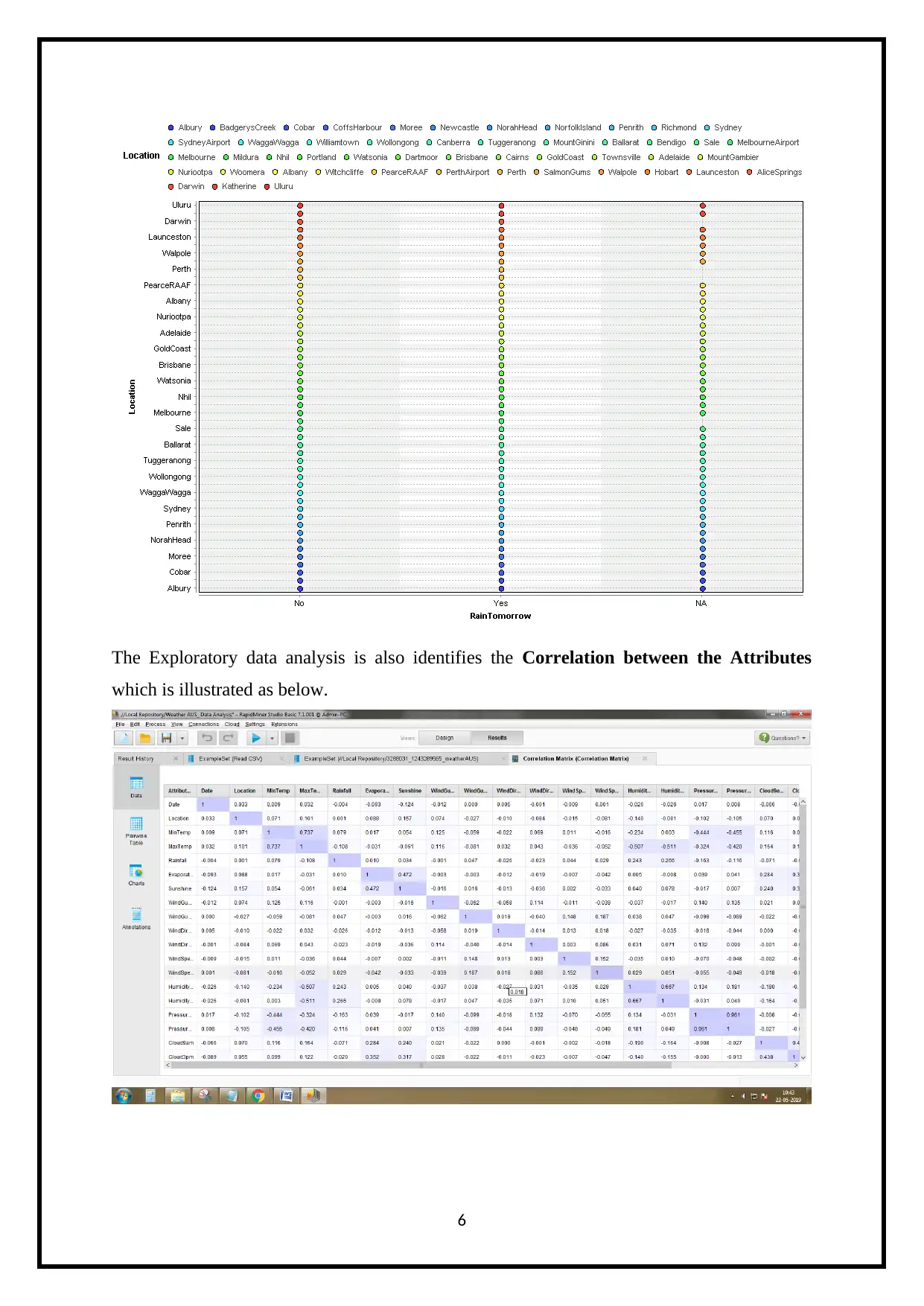
The Exploratory data analysis is also identifies the Correlation between the Attributes
which is illustrated as below.
6
which is illustrated as below.
6
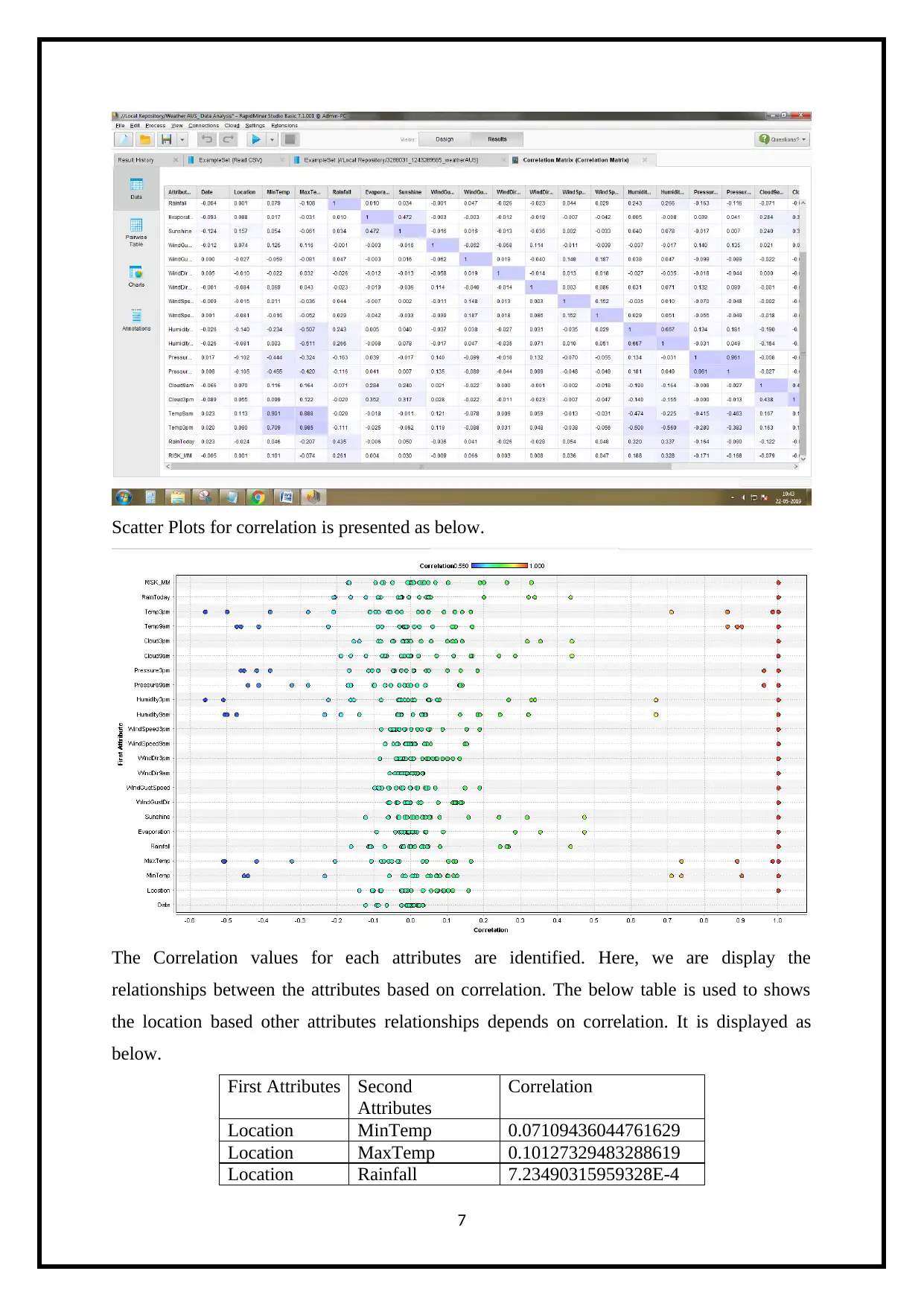
Scatter Plots for correlation is presented as below.
The Correlation values for each attributes are identified. Here, we are display the
relationships between the attributes based on correlation. The below table is used to shows
the location based other attributes relationships depends on correlation. It is displayed as
below.
First Attributes Second
Attributes
Correlation
Location MinTemp 0.07109436044761629
Location MaxTemp 0.10127329483288619
Location Rainfall 7.23490315959328E-4
7
The Correlation values for each attributes are identified. Here, we are display the
relationships between the attributes based on correlation. The below table is used to shows
the location based other attributes relationships depends on correlation. It is displayed as
below.
First Attributes Second
Attributes
Correlation
Location MinTemp 0.07109436044761629
Location MaxTemp 0.10127329483288619
Location Rainfall 7.23490315959328E-4
7

Location Evaporation 0.0876406859296809
Location Sunshine 0.15691079549795772
Location WindGustDir 0.07380526915044719
Location WindGustSpeed -0.02653352547548375
Location WindDir9am -0.010094286545031785
Location WindDir3pm -0.08433911227543703
Location WindSpeed9am -0.015476076396479027
Location WindSpeed3pm -0.08075139464359571
Location Humidity9am -0.1404196925852295
Location Humidity3pm -0.08130458868280568
Location Pressure9am -0.1017916765337633
Location Pressure3pm -0.1054963294188902
Location Cloud9am 0.06978253871787489
Location Cloud3pm 0.05492245824912861
Location Temp9am 0.11312842634840445
Location Temp3pm 0.0896676400881381
Location RainToday -0.024010912962328032
Location RISK_MM 8.320005124659872E-4
2.2 Decision Tree Model
In this section, a decision tree model is built by using Rapid Miner. A decision tree model is
utilized to predict tomorrow’s rainfall depending on today’s weather condition and the appropriate
dataset of data mining operators (Bramer, 2017). The decision tree model utilized for a provided
dataset is represented below.
8
Location Sunshine 0.15691079549795772
Location WindGustDir 0.07380526915044719
Location WindGustSpeed -0.02653352547548375
Location WindDir9am -0.010094286545031785
Location WindDir3pm -0.08433911227543703
Location WindSpeed9am -0.015476076396479027
Location WindSpeed3pm -0.08075139464359571
Location Humidity9am -0.1404196925852295
Location Humidity3pm -0.08130458868280568
Location Pressure9am -0.1017916765337633
Location Pressure3pm -0.1054963294188902
Location Cloud9am 0.06978253871787489
Location Cloud3pm 0.05492245824912861
Location Temp9am 0.11312842634840445
Location Temp3pm 0.0896676400881381
Location RainToday -0.024010912962328032
Location RISK_MM 8.320005124659872E-4
2.2 Decision Tree Model
In this section, a decision tree model is built by using Rapid Miner. A decision tree model is
utilized to predict tomorrow’s rainfall depending on today’s weather condition and the appropriate
dataset of data mining operators (Bramer, 2017). The decision tree model utilized for a provided
dataset is represented below.
8
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
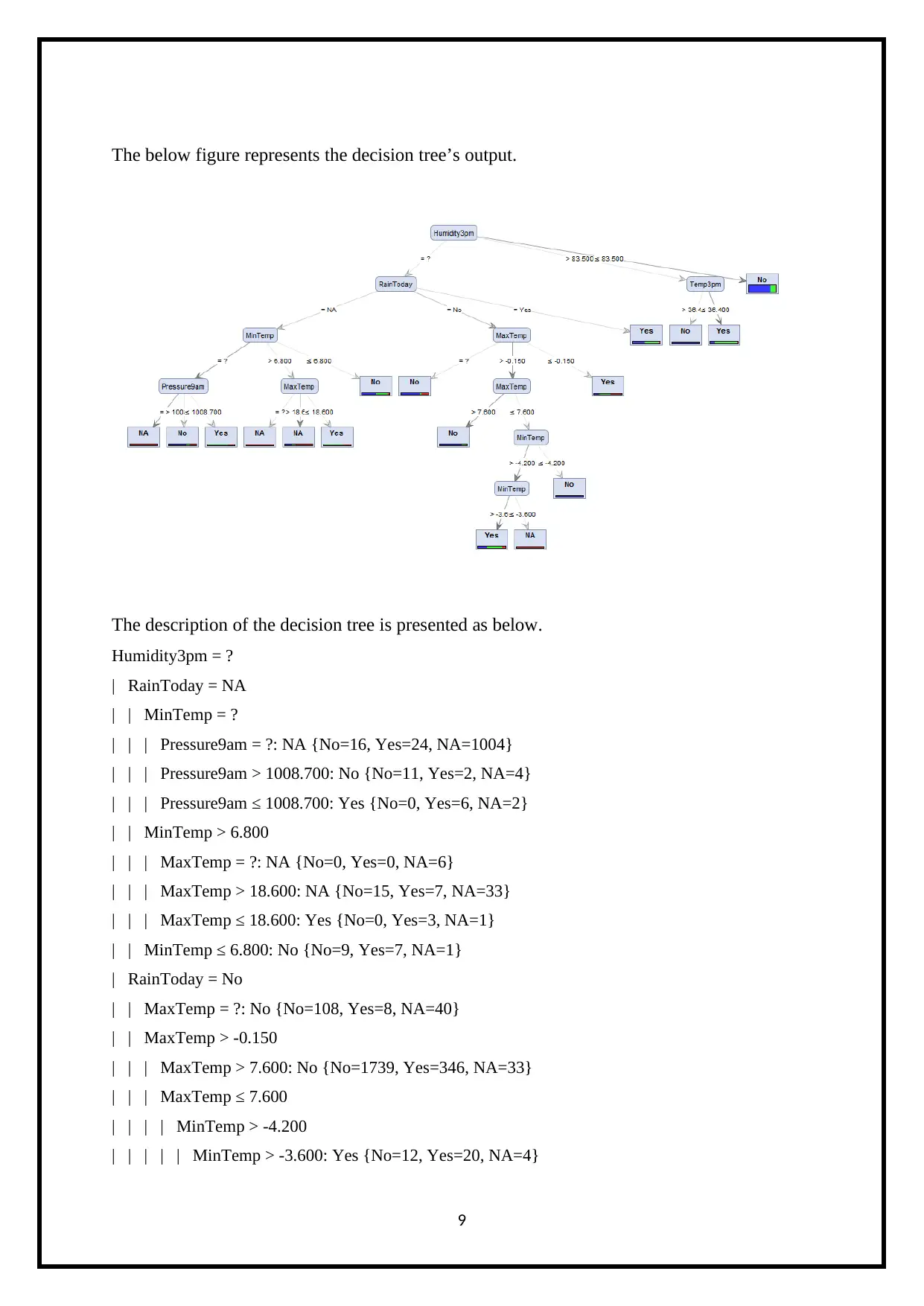
The below figure represents the decision tree’s output.
The description of the decision tree is presented as below.
Humidity3pm = ?
| RainToday = NA
| | MinTemp = ?
| | | Pressure9am = ?: NA {No=16, Yes=24, NA=1004}
| | | Pressure9am > 1008.700: No {No=11, Yes=2, NA=4}
| | | Pressure9am ≤ 1008.700: Yes {No=0, Yes=6, NA=2}
| | MinTemp > 6.800
| | | MaxTemp = ?: NA {No=0, Yes=0, NA=6}
| | | MaxTemp > 18.600: NA {No=15, Yes=7, NA=33}
| | | MaxTemp ≤ 18.600: Yes {No=0, Yes=3, NA=1}
| | MinTemp ≤ 6.800: No {No=9, Yes=7, NA=1}
| RainToday = No
| | MaxTemp = ?: No {No=108, Yes=8, NA=40}
| | MaxTemp > -0.150
| | | MaxTemp > 7.600: No {No=1739, Yes=346, NA=33}
| | | MaxTemp ≤ 7.600
| | | | MinTemp > -4.200
| | | | | MinTemp > -3.600: Yes {No=12, Yes=20, NA=4}
9
The description of the decision tree is presented as below.
Humidity3pm = ?
| RainToday = NA
| | MinTemp = ?
| | | Pressure9am = ?: NA {No=16, Yes=24, NA=1004}
| | | Pressure9am > 1008.700: No {No=11, Yes=2, NA=4}
| | | Pressure9am ≤ 1008.700: Yes {No=0, Yes=6, NA=2}
| | MinTemp > 6.800
| | | MaxTemp = ?: NA {No=0, Yes=0, NA=6}
| | | MaxTemp > 18.600: NA {No=15, Yes=7, NA=33}
| | | MaxTemp ≤ 18.600: Yes {No=0, Yes=3, NA=1}
| | MinTemp ≤ 6.800: No {No=9, Yes=7, NA=1}
| RainToday = No
| | MaxTemp = ?: No {No=108, Yes=8, NA=40}
| | MaxTemp > -0.150
| | | MaxTemp > 7.600: No {No=1739, Yes=346, NA=33}
| | | MaxTemp ≤ 7.600
| | | | MinTemp > -4.200
| | | | | MinTemp > -3.600: Yes {No=12, Yes=20, NA=4}
9
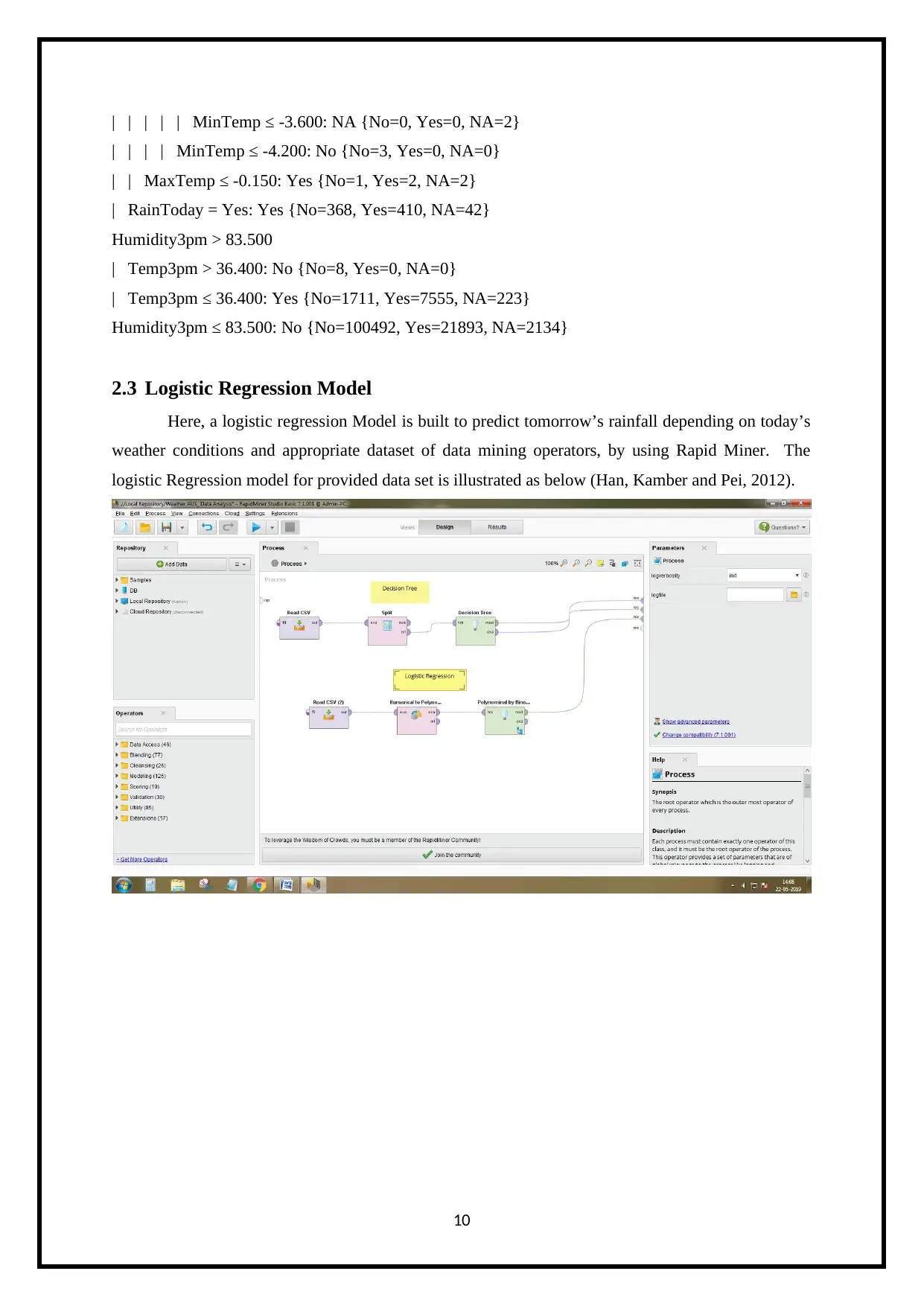
| | | | | MinTemp ≤ -3.600: NA {No=0, Yes=0, NA=2}
| | | | MinTemp ≤ -4.200: No {No=3, Yes=0, NA=0}
| | MaxTemp ≤ -0.150: Yes {No=1, Yes=2, NA=2}
| RainToday = Yes: Yes {No=368, Yes=410, NA=42}
Humidity3pm > 83.500
| Temp3pm > 36.400: No {No=8, Yes=0, NA=0}
| Temp3pm ≤ 36.400: Yes {No=1711, Yes=7555, NA=223}
Humidity3pm ≤ 83.500: No {No=100492, Yes=21893, NA=2134}
2.3 Logistic Regression Model
Here, a logistic regression Model is built to predict tomorrow’s rainfall depending on today’s
weather conditions and appropriate dataset of data mining operators, by using Rapid Miner. The
logistic Regression model for provided data set is illustrated as below (Han, Kamber and Pei, 2012).
10
| | | | MinTemp ≤ -4.200: No {No=3, Yes=0, NA=0}
| | MaxTemp ≤ -0.150: Yes {No=1, Yes=2, NA=2}
| RainToday = Yes: Yes {No=368, Yes=410, NA=42}
Humidity3pm > 83.500
| Temp3pm > 36.400: No {No=8, Yes=0, NA=0}
| Temp3pm ≤ 36.400: Yes {No=1711, Yes=7555, NA=223}
Humidity3pm ≤ 83.500: No {No=100492, Yes=21893, NA=2134}
2.3 Logistic Regression Model
Here, a logistic regression Model is built to predict tomorrow’s rainfall depending on today’s
weather conditions and appropriate dataset of data mining operators, by using Rapid Miner. The
logistic Regression model for provided data set is illustrated as below (Han, Kamber and Pei, 2012).
10
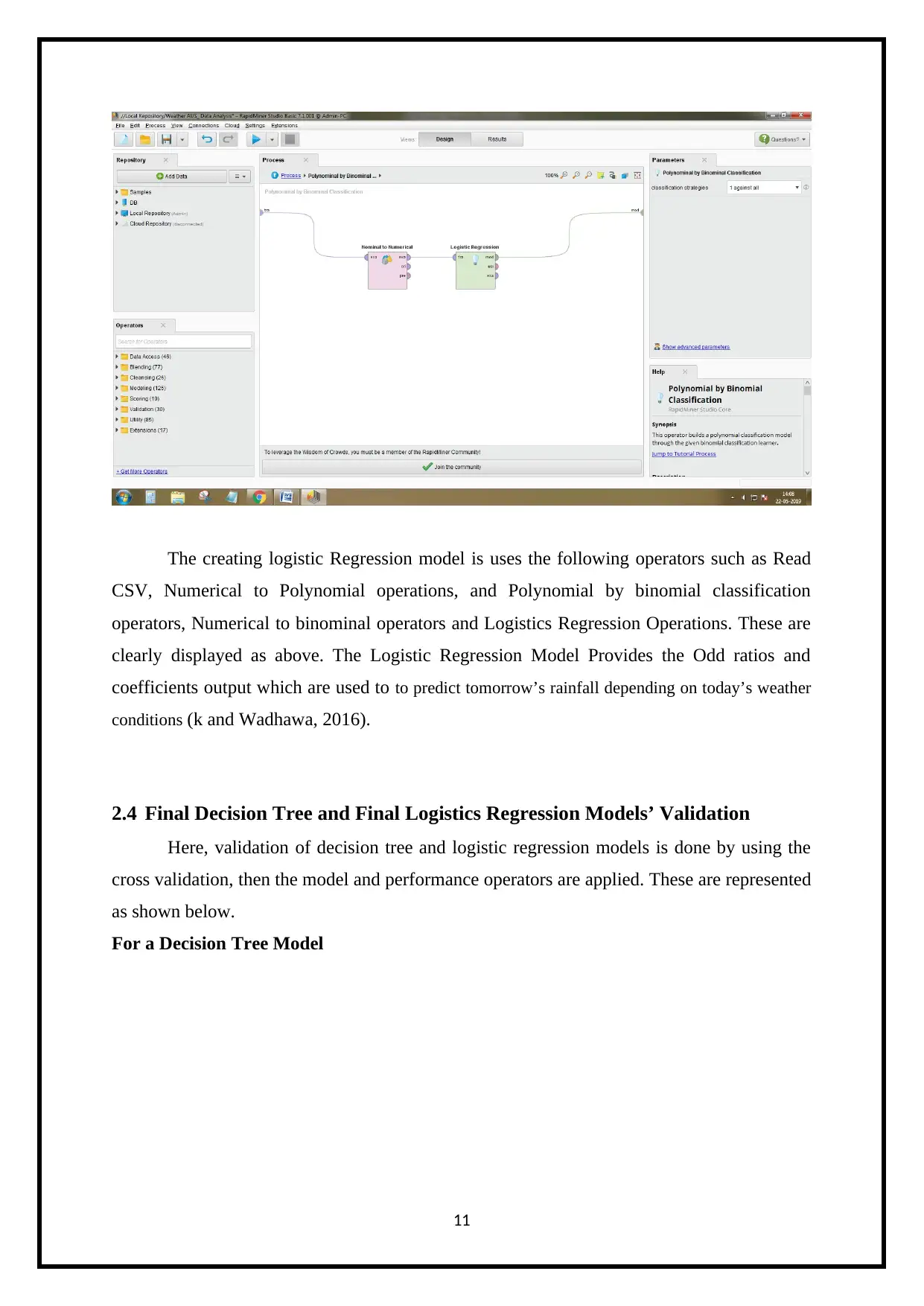
The creating logistic Regression model is uses the following operators such as Read
CSV, Numerical to Polynomial operations, and Polynomial by binomial classification
operators, Numerical to binominal operators and Logistics Regression Operations. These are
clearly displayed as above. The Logistic Regression Model Provides the Odd ratios and
coefficients output which are used to to predict tomorrow’s rainfall depending on today’s weather
conditions (k and Wadhawa, 2016).
2.4 Final Decision Tree and Final Logistics Regression Models’ Validation
Here, validation of decision tree and logistic regression models is done by using the
cross validation, then the model and performance operators are applied. These are represented
as shown below.
For a Decision Tree Model
11
CSV, Numerical to Polynomial operations, and Polynomial by binomial classification
operators, Numerical to binominal operators and Logistics Regression Operations. These are
clearly displayed as above. The Logistic Regression Model Provides the Odd ratios and
coefficients output which are used to to predict tomorrow’s rainfall depending on today’s weather
conditions (k and Wadhawa, 2016).
2.4 Final Decision Tree and Final Logistics Regression Models’ Validation
Here, validation of decision tree and logistic regression models is done by using the
cross validation, then the model and performance operators are applied. These are represented
as shown below.
For a Decision Tree Model
11
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
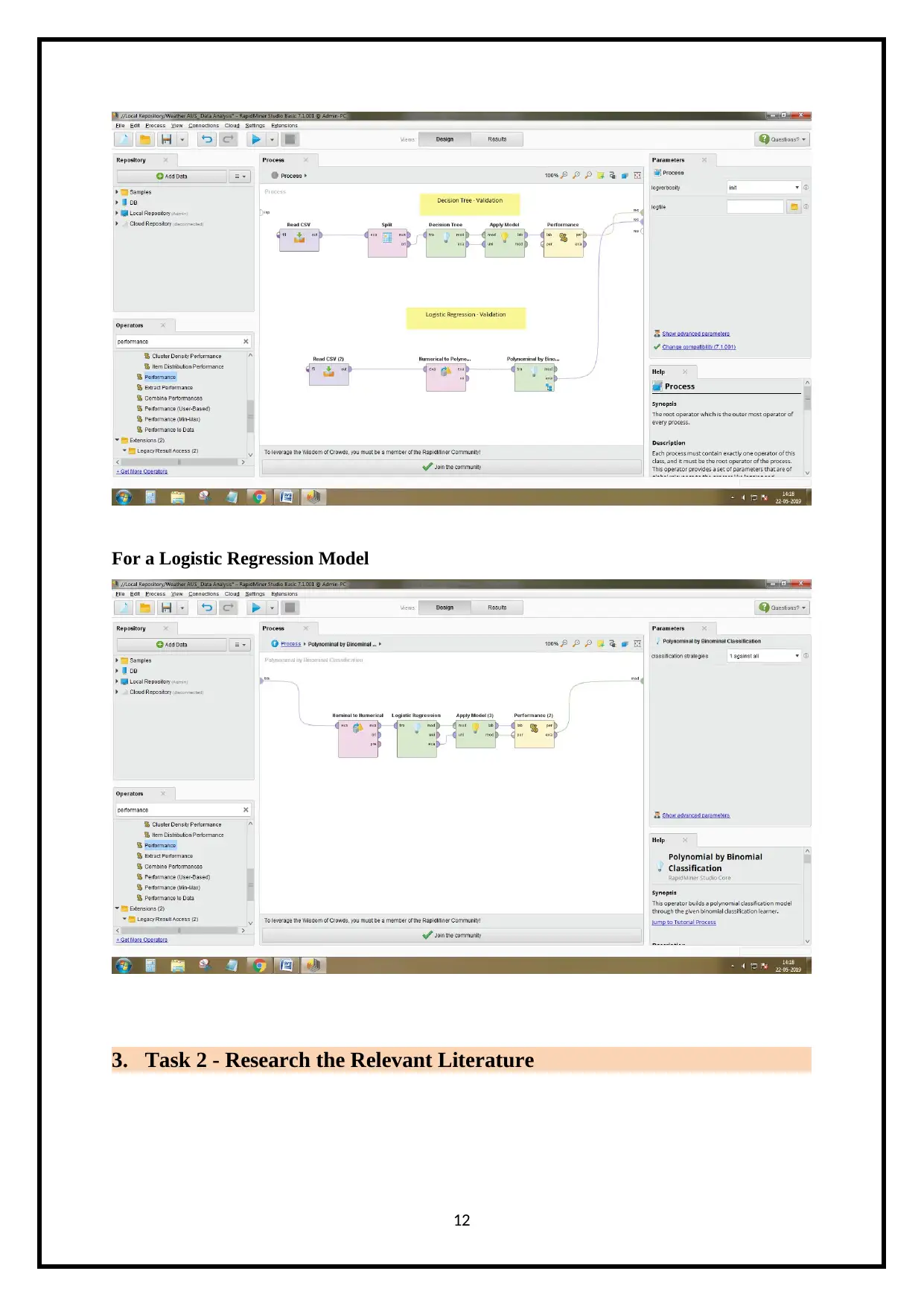
For a Logistic Regression Model
3. Task 2 - Research the Relevant Literature
12
3. Task 2 - Research the Relevant Literature
12

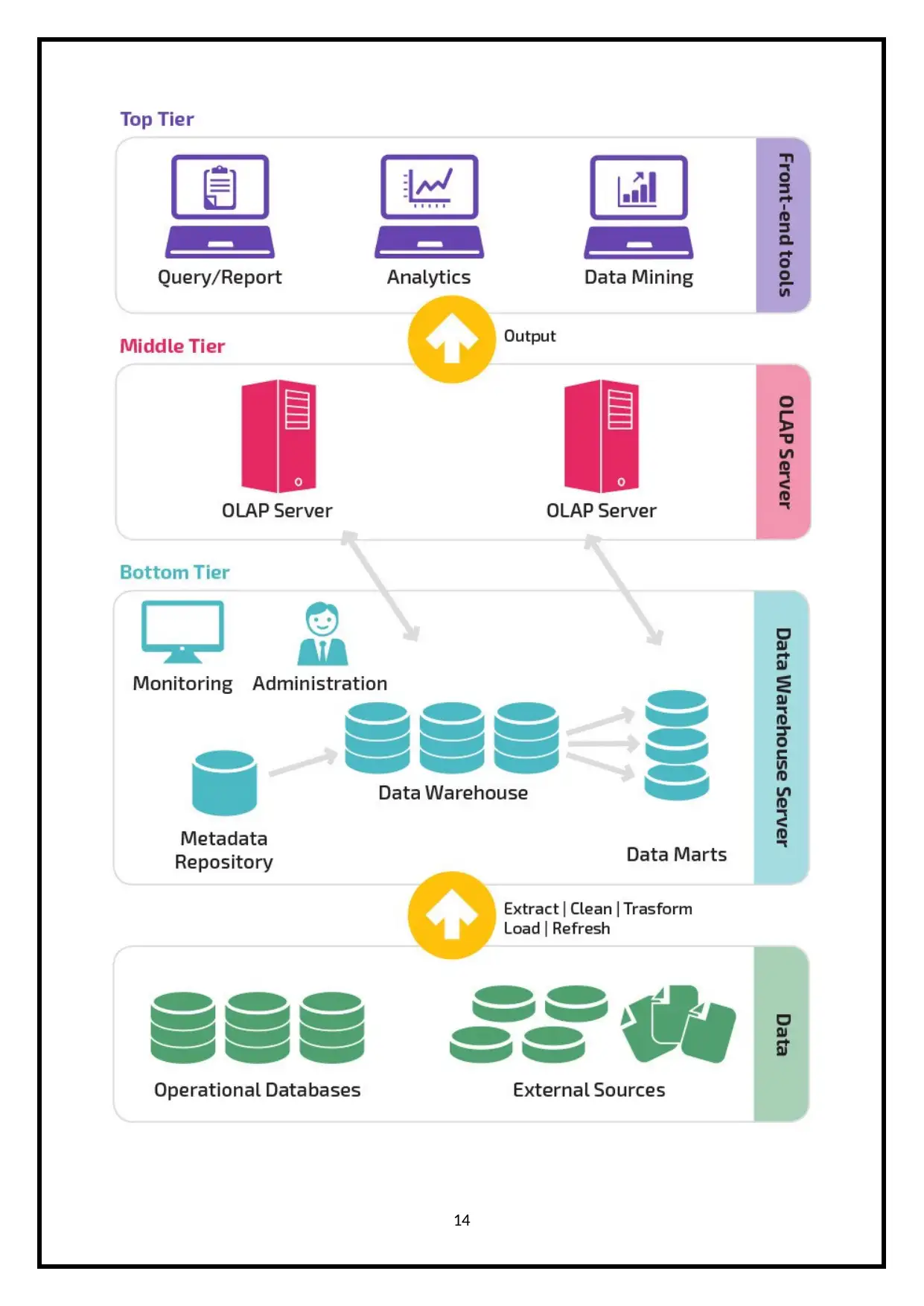
3.1 Architecture Design of a High Level Data Warehouse
Containing communicative and historical data from multi locations and sources and even
single location, this Information service is called as “Data Warehouse”. For the organization
this will make the process of reporting and evaluation simpler. Used for forecasting analysis
and also for decision making factors, “Data Warehouse” refers to a single version of truth.
Data warehouse Architectures are of three types (Mohanty, Jagadeesh and Srivatsa, 2013): -
Single-tier architecture
The data size stored is reduced by the use of this architecture and that is the objective of using
the single layer. This will also isolate and remove the data redundancy. In practice there is
less usage of this Single-tier architecture.
Two-tier architecture
The physically present sources and data warehouses are separated by using the Two-layer
architecture. The limitations of this architecture is that is contains connectivity issues, due to
limitations of network, has limited support of end users and, it is not expandable.
Three-tier architecture
The well-known and broadly utilized architecture, it contains three tiers, they are:
1. Bottom Tier: It contains database of the Data warehouse servers.
With the use of back-end tools, the data is cleaned, transformed and loaded into the
layers of the usually relational database system analyses it.
2. Middle Tier: By implementing either ROLAP or the MOLAP model, which is an
OLAP server and a middle tier of data warehouse. Among the end-user and database,
the middle tier layer is the mediator and also gives database’s abstract view.
3. Top-Tier: API uses a tool for connecting and getting data from a data warehouse, the
tool is the top-tier that is also the front end client layer. The tools can be like Analysis
Tool, Data mining Tool, Reporting Tool, Managed Query Tool & Query tools.
The below image shows the architecture design of a high level data warehouse.
13
Containing communicative and historical data from multi locations and sources and even
single location, this Information service is called as “Data Warehouse”. For the organization
this will make the process of reporting and evaluation simpler. Used for forecasting analysis
and also for decision making factors, “Data Warehouse” refers to a single version of truth.
Data warehouse Architectures are of three types (Mohanty, Jagadeesh and Srivatsa, 2013): -
Single-tier architecture
The data size stored is reduced by the use of this architecture and that is the objective of using
the single layer. This will also isolate and remove the data redundancy. In practice there is
less usage of this Single-tier architecture.
Two-tier architecture
The physically present sources and data warehouses are separated by using the Two-layer
architecture. The limitations of this architecture is that is contains connectivity issues, due to
limitations of network, has limited support of end users and, it is not expandable.
Three-tier architecture
The well-known and broadly utilized architecture, it contains three tiers, they are:
1. Bottom Tier: It contains database of the Data warehouse servers.
With the use of back-end tools, the data is cleaned, transformed and loaded into the
layers of the usually relational database system analyses it.
2. Middle Tier: By implementing either ROLAP or the MOLAP model, which is an
OLAP server and a middle tier of data warehouse. Among the end-user and database,
the middle tier layer is the mediator and also gives database’s abstract view.
3. Top-Tier: API uses a tool for connecting and getting data from a data warehouse, the
tool is the top-tier that is also the front end client layer. The tools can be like Analysis
Tool, Data mining Tool, Reporting Tool, Managed Query Tool & Query tools.
The below image shows the architecture design of a high level data warehouse.
13
14
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

3.2 Proposed High Level Data Warehouse Architecture Design’s Main
Components
The following data is included in the purposed architecture design for a high level data
warehouse (Stahlbock, Abou-Nasr and Weiss, 2018),
Data warehouse, from single or multiple sources, is an information system which
comprises of historical data and the commutative data.
Giving information related to the subject rather than the organization's ongoing
operations, the Data warehouse is subject oriented.
For all Common and same type of data from different databases, integration in Data
Warehouse refers to the establishment of a common unit of measure.
When fresh data is entered, the old and previous data isn’t removed, this makes the
Data warehouse non-volatile.
In a Data warehouse, the data has a high shelf life making it Time-variant.
The five key components of the Data warehouse are:
Database
Data Marts
ETL Tools
Query Tools
Meta Data
The 4 major divisions of the query tools are:
Application Development tools
Query and reporting, tools
OLAP tools
Data mining tools
For performing all conversions and summarizations, it uses data sourcing, migration
tools and transformation.
By specifying the data warehouse data’s usage, source, values, and features, the meta-
data plays a vital role in the Data Warehouse Architecture.
Components of Data warehouse
15
Components
The following data is included in the purposed architecture design for a high level data
warehouse (Stahlbock, Abou-Nasr and Weiss, 2018),
Data warehouse, from single or multiple sources, is an information system which
comprises of historical data and the commutative data.
Giving information related to the subject rather than the organization's ongoing
operations, the Data warehouse is subject oriented.
For all Common and same type of data from different databases, integration in Data
Warehouse refers to the establishment of a common unit of measure.
When fresh data is entered, the old and previous data isn’t removed, this makes the
Data warehouse non-volatile.
In a Data warehouse, the data has a high shelf life making it Time-variant.
The five key components of the Data warehouse are:
Database
Data Marts
ETL Tools
Query Tools
Meta Data
The 4 major divisions of the query tools are:
Application Development tools
Query and reporting, tools
OLAP tools
Data mining tools
For performing all conversions and summarizations, it uses data sourcing, migration
tools and transformation.
By specifying the data warehouse data’s usage, source, values, and features, the meta-
data plays a vital role in the Data Warehouse Architecture.
Components of Data warehouse
15

For creating a complete environment manageable, functional, and accessible, the Data
Warehouse that depends on RDBMS server will have a central information repository and
will be surrounded by few important elements.
Data Warehouse consists of these 5 components.
Database of the Data Warehouse
Implemented on the RDBMS technology, central database refers to a data warehousing
environment’s foundation. Optimized for transactional database processing, traditional
RDBMS system is constrained when utilized for the data warehousing. We can see for
example, aggregates, multi-table joins, ad-hoc query, are resource intensive, which decreases
the performance (Tahyudin, 2015).
Below, thus are the options that can be used for the Database,
In a data warehouse, for allowing scalability, the relational databases are actually
deployed in parallel. The shared memory/shared nothing model on several
multiprocessor configurations or massively parallel processors is possible when the
data warehouses are used as Parallel relational databases.
To increase the speed and for bypassing the relational table scan, the new index
structures are utilized.
The limitations that are placed due to relational data model are overcome by using the
multidimensional database (MDDBs). For instance: Oracle’s Essbase
16
Warehouse that depends on RDBMS server will have a central information repository and
will be surrounded by few important elements.
Data Warehouse consists of these 5 components.
Database of the Data Warehouse
Implemented on the RDBMS technology, central database refers to a data warehousing
environment’s foundation. Optimized for transactional database processing, traditional
RDBMS system is constrained when utilized for the data warehousing. We can see for
example, aggregates, multi-table joins, ad-hoc query, are resource intensive, which decreases
the performance (Tahyudin, 2015).
Below, thus are the options that can be used for the Database,
In a data warehouse, for allowing scalability, the relational databases are actually
deployed in parallel. The shared memory/shared nothing model on several
multiprocessor configurations or massively parallel processors is possible when the
data warehouses are used as Parallel relational databases.
To increase the speed and for bypassing the relational table scan, the new index
structures are utilized.
The limitations that are placed due to relational data model are overcome by using the
multidimensional database (MDDBs). For instance: Oracle’s Essbase
16

Sourcing, Acquisition, Clean-up and Transformation Tools (ETL)
In a data warehouse, to transform the data into a unified format by conversions,
summarizations, including all the required modifications, data sourcing, migration tools and
transformation shall be employed. These special tools are even known as ETL (Extract,
Transform and Load) Tools.
The following are some of its functionalities:
According to the regulatory stipulations, anonymize the data.
While loading of data in the operational databases into Data warehouse, removal of all
data that is unwanted in the operational databases.
For data arriving from different sources, will be searched and replaced by common
names and definitions.
Estimating the summaries and the retrieved data.
Populating the missing data with defaults.
De-duplicated the recurred data that is retrieved from multiple data sources.
For the regular updates of data in data warehouse, there are tools like Extract, Transform, and
Load which will generate the corn jobs, Cobol programs, background jobs, shell scripts, and
so on. These will also frequently update, help in maintaining of these data in the data
warehouse and.
With challenges of Database & Data heterogeneity, ETL Tools are vital for data warehouse
system.
Metadata
In data warehouse, defining data and the data which deals with data is called as the
“Metadata”, which although sounds like a heavy concept word is rather simple. In the data
warehouse, it helps in building, maintaining and managing. By specifying the source, usage,
values, and the data warehouse’s features for the data within the Data Warehouse
Architecture, the meta-data plays a vital and important role. Closely related and connected to
the data warehouse, it also establishes the way in which data can be changed and processed.
For instance, a line in the sales database might include,
4030 KJ732 299.90
It is a data which has no meaning until the Meta is consulted which states that it is a:
17
In a data warehouse, to transform the data into a unified format by conversions,
summarizations, including all the required modifications, data sourcing, migration tools and
transformation shall be employed. These special tools are even known as ETL (Extract,
Transform and Load) Tools.
The following are some of its functionalities:
According to the regulatory stipulations, anonymize the data.
While loading of data in the operational databases into Data warehouse, removal of all
data that is unwanted in the operational databases.
For data arriving from different sources, will be searched and replaced by common
names and definitions.
Estimating the summaries and the retrieved data.
Populating the missing data with defaults.
De-duplicated the recurred data that is retrieved from multiple data sources.
For the regular updates of data in data warehouse, there are tools like Extract, Transform, and
Load which will generate the corn jobs, Cobol programs, background jobs, shell scripts, and
so on. These will also frequently update, help in maintaining of these data in the data
warehouse and.
With challenges of Database & Data heterogeneity, ETL Tools are vital for data warehouse
system.
Metadata
In data warehouse, defining data and the data which deals with data is called as the
“Metadata”, which although sounds like a heavy concept word is rather simple. In the data
warehouse, it helps in building, maintaining and managing. By specifying the source, usage,
values, and the data warehouse’s features for the data within the Data Warehouse
Architecture, the meta-data plays a vital and important role. Closely related and connected to
the data warehouse, it also establishes the way in which data can be changed and processed.
For instance, a line in the sales database might include,
4030 KJ732 299.90
It is a data which has no meaning until the Meta is consulted which states that it is a:
17
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Model number- 4030
Sales Agent ID- KJ732
The total cost of the sales i.e., $299.90.
Transformation of data information into meaningful knowledge thus is the important feature
of Meta Data.
The following questions are answered by Metadata,
What are the Data Warehouse’s tables, keys and attributes?
From where does the data come?
What is the number of times the data gets reloaded?
With cleaning, what transformations were applied?
The following are the categorization of Metadata:
1. Technical Meta Data: Utilized by the designers and administrators of the Data
warehouse, this type of Metadata includes the information about the warehouses.
2. Business Meta Data: A method to simply understand all the stored information in a
data warehouse, the full details of which are stored in this type of Metadata.
Query Tools
For making the vital and the all-important strategic decisions, this becomes the main objects
of the data warehousing. For this interaction of the users and administrators with a data
warehouse, the Query tools are used.
The four different categories of this tool are,
1. Application Development tools
2. Query and reporting tools
3. OLAP tools
4. Data mining tools
1. Query and reporting tools:
They are further categorized as follows:
Managed query tools
Reporting tools
18
Sales Agent ID- KJ732
The total cost of the sales i.e., $299.90.
Transformation of data information into meaningful knowledge thus is the important feature
of Meta Data.
The following questions are answered by Metadata,
What are the Data Warehouse’s tables, keys and attributes?
From where does the data come?
What is the number of times the data gets reloaded?
With cleaning, what transformations were applied?
The following are the categorization of Metadata:
1. Technical Meta Data: Utilized by the designers and administrators of the Data
warehouse, this type of Metadata includes the information about the warehouses.
2. Business Meta Data: A method to simply understand all the stored information in a
data warehouse, the full details of which are stored in this type of Metadata.
Query Tools
For making the vital and the all-important strategic decisions, this becomes the main objects
of the data warehousing. For this interaction of the users and administrators with a data
warehouse, the Query tools are used.
The four different categories of this tool are,
1. Application Development tools
2. Query and reporting tools
3. OLAP tools
4. Data mining tools
1. Query and reporting tools:
They are further categorized as follows:
Managed query tools
Reporting tools
18

Managed query tools:
1) By adding the meta-layer amidst the database and users, these access tools helps the
end-users to solve the snags in SQL, database and in the database structure.
2) Application development tools:
When the analytical needs of an organization are not satisfied by the built-in graphical
and analytical tools, than by using the Application development tools custom reports
are generated.
3) Data mining tools:
By mining large amount of data for searching and finding out meaningful new
correlation, patterns, and trends, we use the process called as Data mining. These are
all done by the tool automatically using the data mining method.
4) OLAP tools:
Using elaborate and complex multidimensional views, users can analyze the data with
the tools which depend on the multidimensional database concept.
Reporting tools: Production reporting tools and desktop report writer are the further sub-
division of the Reporting tools.
1. Report writers: for the purpose of analyzing, this tool is designed, which helps the
end-users.
2. Production reporting: Used for generating regular operational reports by the use of
this tool, this also helps in high volume batch job such as calculating and printing.
Brio, Business Objects, SAS Institute, Power Soft, Oracle, are few commonly used
reporting tools.
3.3 Security Privacy and the Ethical Concerns
Large and vast data require good security which can be a challenging task.
For the complex applications, the big data security model won’t be recommended as this will
get disabled by default. But without this, all the data and information will be in the risk of
getting compromised and unsafe. For this privacy and safety related issues will be discussed
in this topic.
How the personal information is gathered and utilized in a system or a data base and to have a
controlling privilege over the same, we have Privacy Information.
19
1) By adding the meta-layer amidst the database and users, these access tools helps the
end-users to solve the snags in SQL, database and in the database structure.
2) Application development tools:
When the analytical needs of an organization are not satisfied by the built-in graphical
and analytical tools, than by using the Application development tools custom reports
are generated.
3) Data mining tools:
By mining large amount of data for searching and finding out meaningful new
correlation, patterns, and trends, we use the process called as Data mining. These are
all done by the tool automatically using the data mining method.
4) OLAP tools:
Using elaborate and complex multidimensional views, users can analyze the data with
the tools which depend on the multidimensional database concept.
Reporting tools: Production reporting tools and desktop report writer are the further sub-
division of the Reporting tools.
1. Report writers: for the purpose of analyzing, this tool is designed, which helps the
end-users.
2. Production reporting: Used for generating regular operational reports by the use of
this tool, this also helps in high volume batch job such as calculating and printing.
Brio, Business Objects, SAS Institute, Power Soft, Oracle, are few commonly used
reporting tools.
3.3 Security Privacy and the Ethical Concerns
Large and vast data require good security which can be a challenging task.
For the complex applications, the big data security model won’t be recommended as this will
get disabled by default. But without this, all the data and information will be in the risk of
getting compromised and unsafe. For this privacy and safety related issues will be discussed
in this topic.
How the personal information is gathered and utilized in a system or a data base and to have a
controlling privilege over the same, we have Privacy Information.
19

How much information should be shared and how much should not be shared in a given
group or in a data base is known as the Information privacy, which also gives capacity to an
individual or group for stopping this type of information.
During information and data transmission over the Internet, one serious problem is the user’s
privacy issues, which includes detection of personal information.
Through a proper use of processes, technology, and the training from the following:-
Disclosure, Unauthorized access, Modification, Disruption, Destruction, Recording, and
Inspection, the security will be carried out for the defending information and information
assets.
Privacy vs. security
For instance setting the policies for ensuring that the user’s personal information is being
gathered, misused and shared inappropriately shall be the priority for the Data privacy policy
and it will focus on the use and governance of individual data. Various Malicious attacks and
the misuse of the stolen data to benefit from it are the main concerns for the security on
protecting this type of data.
Big data privacy in data generation phase
Active data generation and Passive data generation refers to a couple of Data
generation types. The main point of difference between these two types of data, where the
data is collected and stored. In Passive data generation, the circumstances will be such that
the data are produced by data owner’s online actions, for instance, browsing, and the owner
of the data might not be aware that the data is collected from a third party while in active data
generation, this data is voluntarily given by a user to a third party.
Big data privacy in data storage phase
Advancement in data storage and collection methodologies like cloud computing, have
helped in storing high volume data. It can be exceptionally dangerous and alarming as the
users private and vital information can be disclosed in case there is a compromise in the data
storage system. The challenge and securing of privacy protection in a distributed environment
where an application might require various datasets from many data centers it can be
compromised and challenged.
These are divided into four categories that is the conventional security methods for protecting
the data. They include, database level data security schemes, file level data security schemes,
application level encryption schemes, and the media level security schemes.
20
group or in a data base is known as the Information privacy, which also gives capacity to an
individual or group for stopping this type of information.
During information and data transmission over the Internet, one serious problem is the user’s
privacy issues, which includes detection of personal information.
Through a proper use of processes, technology, and the training from the following:-
Disclosure, Unauthorized access, Modification, Disruption, Destruction, Recording, and
Inspection, the security will be carried out for the defending information and information
assets.
Privacy vs. security
For instance setting the policies for ensuring that the user’s personal information is being
gathered, misused and shared inappropriately shall be the priority for the Data privacy policy
and it will focus on the use and governance of individual data. Various Malicious attacks and
the misuse of the stolen data to benefit from it are the main concerns for the security on
protecting this type of data.
Big data privacy in data generation phase
Active data generation and Passive data generation refers to a couple of Data
generation types. The main point of difference between these two types of data, where the
data is collected and stored. In Passive data generation, the circumstances will be such that
the data are produced by data owner’s online actions, for instance, browsing, and the owner
of the data might not be aware that the data is collected from a third party while in active data
generation, this data is voluntarily given by a user to a third party.
Big data privacy in data storage phase
Advancement in data storage and collection methodologies like cloud computing, have
helped in storing high volume data. It can be exceptionally dangerous and alarming as the
users private and vital information can be disclosed in case there is a compromise in the data
storage system. The challenge and securing of privacy protection in a distributed environment
where an application might require various datasets from many data centers it can be
compromised and challenged.
These are divided into four categories that is the conventional security methods for protecting
the data. They include, database level data security schemes, file level data security schemes,
application level encryption schemes, and the media level security schemes.
20
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Big data privacy preserving in data processing
The batch, graph, stream, and machine learning processing are the categorized systems of the
Big data processing paradigm. Division could be carried into a couple of phases, for the
privacy protection in data processing parts. The gathered data may involve information of a
data owner and thus, in the first phase the goal of safeguarding information from unsolicited
disclosures is very vital and important. Without violating the privacy, extracting meaningful
information from the data is the main goal in the second phase. We have discussed in brief
some traditional methods to preserve privacy in big data.
Now, new methods and new technologies will have to be utilised as the above approaches are
used traditionally providing privacy to an extent for the sectors.
De-identification
Using the methods of suppression (won’t release certain values) and data must be initially
sanitized with the generalization. In order to protect user’s privacy and before the release for
data mining. De-identification is the traditional technique used for privacy-preserving data
mining. The concepts of t-closeness, l-diversity and k-anonymity is introduced into the
system for improving the traditional privacy-preserving of the data mining and to mitigate the
threats from re-identification. A very vital and crucial tool in privacy protection is the De-
identification which is used to migrate the privacy preserving big data analytics.
One must be careful about the big data which could even maximize the re-identification risks
because as an attacker, in the big data it helps to gather additional external information
assistance for de-identification. Thus for the overall protection of the big data privacy, de-
identification isn’t sufficient.
Because of either the flexibility problems including the effectiveness or the risks of
de-identification, the big data analytics’ Privacy-preserving is the currently faced big
challenge.
If the effective privacy-preserving algorithms are developed for helping in mitigation
of re-identification risk, then the de-identification could be highly feasible for privacy-
preserving big data analytics.
De-identification classified into 3 privacy-preserving approaches such as L-diversity, T-
closeness, and K-anonymity. There exists few common terms that are utilized in the field of
privacy of these approaches:
Identifier attributes contains driver license, full name, number of the social security
etc., that are unique and directly differentiate users.
21
The batch, graph, stream, and machine learning processing are the categorized systems of the
Big data processing paradigm. Division could be carried into a couple of phases, for the
privacy protection in data processing parts. The gathered data may involve information of a
data owner and thus, in the first phase the goal of safeguarding information from unsolicited
disclosures is very vital and important. Without violating the privacy, extracting meaningful
information from the data is the main goal in the second phase. We have discussed in brief
some traditional methods to preserve privacy in big data.
Now, new methods and new technologies will have to be utilised as the above approaches are
used traditionally providing privacy to an extent for the sectors.
De-identification
Using the methods of suppression (won’t release certain values) and data must be initially
sanitized with the generalization. In order to protect user’s privacy and before the release for
data mining. De-identification is the traditional technique used for privacy-preserving data
mining. The concepts of t-closeness, l-diversity and k-anonymity is introduced into the
system for improving the traditional privacy-preserving of the data mining and to mitigate the
threats from re-identification. A very vital and crucial tool in privacy protection is the De-
identification which is used to migrate the privacy preserving big data analytics.
One must be careful about the big data which could even maximize the re-identification risks
because as an attacker, in the big data it helps to gather additional external information
assistance for de-identification. Thus for the overall protection of the big data privacy, de-
identification isn’t sufficient.
Because of either the flexibility problems including the effectiveness or the risks of
de-identification, the big data analytics’ Privacy-preserving is the currently faced big
challenge.
If the effective privacy-preserving algorithms are developed for helping in mitigation
of re-identification risk, then the de-identification could be highly feasible for privacy-
preserving big data analytics.
De-identification classified into 3 privacy-preserving approaches such as L-diversity, T-
closeness, and K-anonymity. There exists few common terms that are utilized in the field of
privacy of these approaches:
Identifier attributes contains driver license, full name, number of the social security
etc., that are unique and directly differentiate users.
21

Quasi-identifier attributes refers to a set of information, for instance, age, gender, zip
code, date of birth etc. To re-identify individuals, the above information could be
mixed with the rest of the external data.
Sensitive attributes refer to a private and personal information, for instance, salary,
sickness, and so on.
Insensitive attributes refer to the information that is general and innocuous.
Equivalence classes refer to a set of records which involves the same values on the
quasi-identifiers.
K-anonymity
For every single individual in the release couldn’t be perceived from at least k-1 individuals
whose details are displayed during the release, than the release of data is said to have the k-
anonymity property. A database refers to a table that comprises of n rows and m columns in
the context of k-anonymization problems and, here every single row of a table denotes a
record that relates with a specific individual from a public and the different rows’ entries are
not required to be distinctive. The attributes’ values connected with the public are the values
in the different columns.
L-diversity
By reducing the granularity of a data representation, L-diversity refers to a form of group
based anonymization which is used for securing the data sets’ privacy. For gaining some
privacy, there is a reduction in the trade-off and this will result in loss of viability of data
management or the data mining algorithms.
Any provided record maps on at least k distinct records in a data,
Diminishing the data granularity’s representation using methods like, l-diversity model
(Distinct, Recursive and Entropy) refers to k-anonymity model execution, which also
includes generalization and suppression in a way that any provided record maps on at least k
distinct records in a data.
Protecting relative sensitive values which were generalized or suppressed is not equal to
protected identities to the level of k-individuals, where L-diversity model manages some of
the k-anonymity model’s weaknesses, especially when in a group the sensitive values exhibits
22
code, date of birth etc. To re-identify individuals, the above information could be
mixed with the rest of the external data.
Sensitive attributes refer to a private and personal information, for instance, salary,
sickness, and so on.
Insensitive attributes refer to the information that is general and innocuous.
Equivalence classes refer to a set of records which involves the same values on the
quasi-identifiers.
K-anonymity
For every single individual in the release couldn’t be perceived from at least k-1 individuals
whose details are displayed during the release, than the release of data is said to have the k-
anonymity property. A database refers to a table that comprises of n rows and m columns in
the context of k-anonymization problems and, here every single row of a table denotes a
record that relates with a specific individual from a public and the different rows’ entries are
not required to be distinctive. The attributes’ values connected with the public are the values
in the different columns.
L-diversity
By reducing the granularity of a data representation, L-diversity refers to a form of group
based anonymization which is used for securing the data sets’ privacy. For gaining some
privacy, there is a reduction in the trade-off and this will result in loss of viability of data
management or the data mining algorithms.
Any provided record maps on at least k distinct records in a data,
Diminishing the data granularity’s representation using methods like, l-diversity model
(Distinct, Recursive and Entropy) refers to k-anonymity model execution, which also
includes generalization and suppression in a way that any provided record maps on at least k
distinct records in a data.
Protecting relative sensitive values which were generalized or suppressed is not equal to
protected identities to the level of k-individuals, where L-diversity model manages some of
the k-anonymity model’s weaknesses, especially when in a group the sensitive values exhibits
22

homogeneity. In the anonymization mechanism, promotion of intra-group diversity for the
sensitive values is included in l-diversity model and this also is dependent on a range of
sensitive attributes. Fictitious data has to be inserted if we wish to make data L-diverse via
sensitive attribute which contains not that much distinct values. There might be problematic
factors in the analysis by using this but the overall security will be better. This also can’t
prevent attribute disclosure as L-diversity method is subjected to the skewness and similarity
attacks.
23
sensitive values is included in l-diversity model and this also is dependent on a range of
sensitive attributes. Fictitious data has to be inserted if we wish to make data L-diverse via
sensitive attribute which contains not that much distinct values. There might be problematic
factors in the analysis by using this but the overall security will be better. This also can’t
prevent attribute disclosure as L-diversity method is subjected to the skewness and similarity
attacks.
23
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

References
Ahmed Sherif. (2016). Practical Business Intelligence. Packt Publishing.
ANGRA, S. (2016). Analysis of student’s data using rapid miner. Journal on Today's Ideas -
Tomorrow's Technologies, 4(1), pp.49-58.
Bramer, M. (2017). Principles of data mining. London: Springer.
Han, J., Kamber, M. and Pei, J. (2012). Data mining. Amsterdam: Elsevier/Morgan
Kaufmann.
k, T. and Wadhawa, M. (2016). Analysis and Comparison Study of Data Mining Algorithms
Using Rapid Miner. International Journal of Computer Science, Engineering and
Applications, 6(1), pp.9-21.
Mohanty, S., Jagadeesh, M. and Srivatsa, H. (2013). Big data imperatives. New York:
Apress.
Stahlbock, R., Abou-Nasr, M. and Weiss, G. (2018). Data Mining. Bloomfield: C.S.R.E.A.
Tahyudin, I. (2015). Data Mining (Comparison Between Manual and Rapid Miner Process).
Saarbrücken: LAP LAMBERT Academic Publishing.
24
Ahmed Sherif. (2016). Practical Business Intelligence. Packt Publishing.
ANGRA, S. (2016). Analysis of student’s data using rapid miner. Journal on Today's Ideas -
Tomorrow's Technologies, 4(1), pp.49-58.
Bramer, M. (2017). Principles of data mining. London: Springer.
Han, J., Kamber, M. and Pei, J. (2012). Data mining. Amsterdam: Elsevier/Morgan
Kaufmann.
k, T. and Wadhawa, M. (2016). Analysis and Comparison Study of Data Mining Algorithms
Using Rapid Miner. International Journal of Computer Science, Engineering and
Applications, 6(1), pp.9-21.
Mohanty, S., Jagadeesh, M. and Srivatsa, H. (2013). Big data imperatives. New York:
Apress.
Stahlbock, R., Abou-Nasr, M. and Weiss, G. (2018). Data Mining. Bloomfield: C.S.R.E.A.
Tahyudin, I. (2015). Data Mining (Comparison Between Manual and Rapid Miner Process).
Saarbrücken: LAP LAMBERT Academic Publishing.
24
1 out of 26


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.