Creating and Testing Inverted Index with Boolean and Vector Models
VerifiedAdded on 2023/04/23
|11
|1836
|72
Report
AI Summary
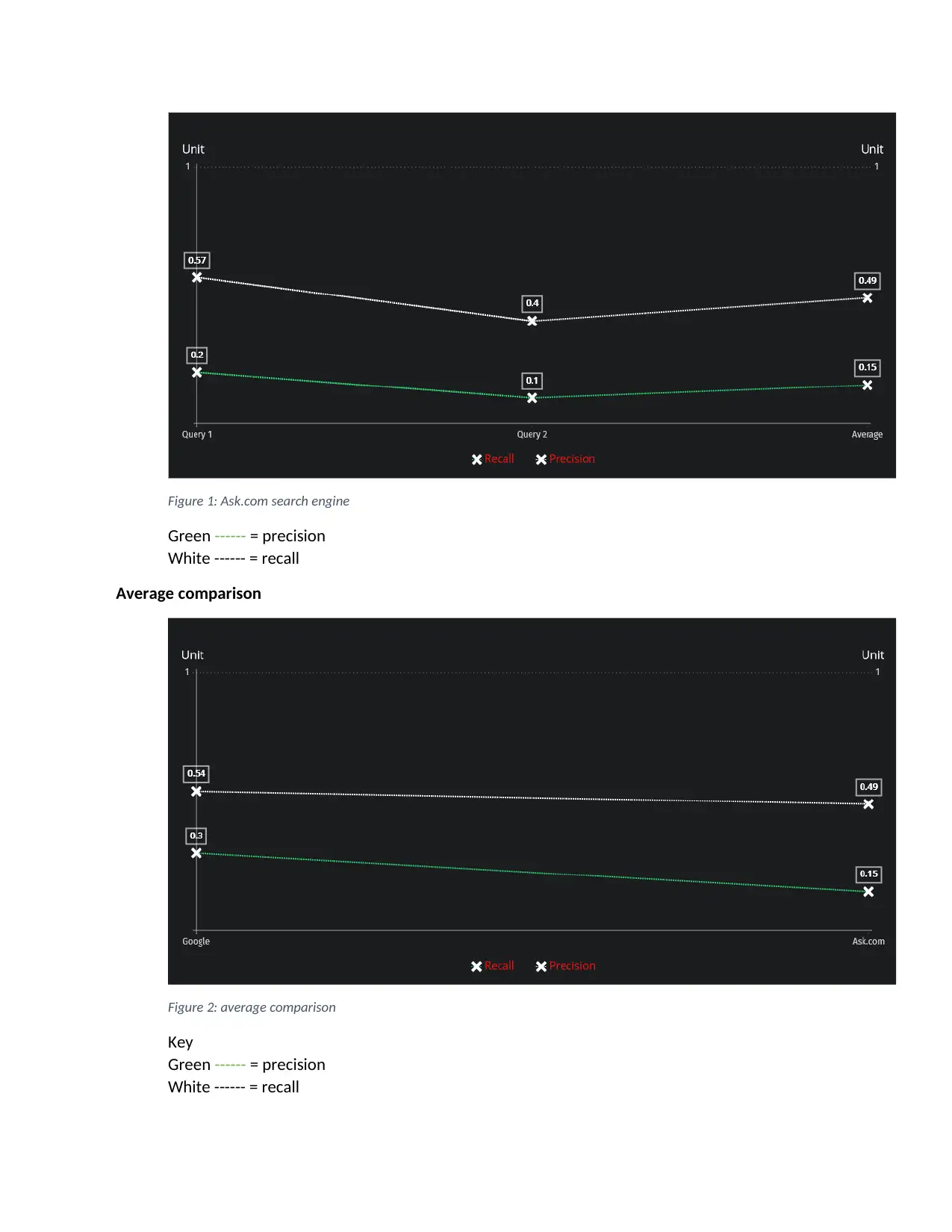
This assignment provides a comprehensive overview of inverted indexing techniques for information retrieval. It begins by detailing the process of creating an inverted index from a set of unstructured documents, including stop word removal and the application of Porter's stemming algorithm. The assignment then explains the creation of a merged inverted list and a posting file, demonstrating how to test the inverted index using keywords. Furthermore, it explores the Boolean and Vector models, including calculating cosine similarity for document retrieval. The report also includes a comparative analysis of the Boolean and Vector models, highlighting their differences in retrieving and ranking documents. Finally, the assignment evaluates search engine performance using precision and recall metrics, comparing the results of Ask.com and Google for specific queries, ultimately determining that Google provides better results based on the higher precision and recall values.








1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.